题目1:找出所有子集的异或总和再求和(LeetCode 1863)
- 题目描述

- 解法(递归/回溯)
1) 算法思路
所有子集可以解释为:每个元素选择"在"或"不在"一个集合中,因此子集总数为 2^n(n 为数组长度)。
因为异或操作满足交换律,我们可以定义一个变量直接记录当前状态的异或和,用递归保存当前集合的状态(异或和),并对每个元素做两种选择:选择将当前元素添加到当前状态中(异或更新状态);不选择当前元素(状态不变)
当递归到空元素(所有元素都已考虑)时,将当前状态的异或和添加到最终答案中。
示例:集合 1,2 的子集状态选择过程
cpp
[]
/ \
[] [1] // 第一个元素选择与否
/ \ / \
[] [2] [1] [1,2] // 第二个元素选择与否,每个状态到这一层时需要记录异或和2) 递归函数设计 void dfs(int val, int idx, vector<int>& nums)
参数:
val:当前状态的异或和
idx:当前需要处理的元素下标
nums:输入数组
作用:对当前元素进行"添加/不添加"两种分支处理,递归生成所有子集并统计异或和
3) 递归流程
- 递归结束条件:当前下标 idx 与数组长度相等(所有元素都已处理)
将当前异或和 val 添加到答案中,返回
-
选择添加当前元素:新状态为 val ^ numsidx,递归处理下一个元素 idx + 1
-
选择不添加当前元素:状态不变,直接递归处理下一个元素 idx + 1
4) C++ 完整代码
cpp
class Solution
{
int path; // 记录当前路径的异或和
int sum; // 记录所有子集异或和的总和
public:
int subsetXORSum(vector<int>& nums)
{
path = 0; // 初始状态:空子集的异或和为0
sum = 0; // 初始总和为0
dfs(nums, 0);
return sum;
}
void dfs(vector<int>& nums, int pos)
{
// 递归到当前位置时,当前路径的异或和是一个有效子集,加入总和
sum += path;
// 从pos开始遍历,避免重复子集(按顺序选择元素)
for(int i = pos; i < nums.size(); i++)
{
// 1. 选择当前元素:更新路径异或和
path ^= nums[i];
// 2. 递归处理下一个元素
dfs(nums, i + 1);
// 3. 回溯:恢复现场,取消当前元素的选择
path ^= nums[i];
}
}
};- 核心知识点整理
1) 子集生成与回溯算法
子集的本质是对每个元素做"选/不选"的二元决策,因此可以用回溯(DFS) 枚举所有可能
回溯的核心是"状态保存-递归-恢复现场",本题中 path ^= numsi 后再 path ^= numsi 就是恢复现场的操作
时间复杂度:O(2^n),n 为数组长度(本题 n \le 12,2^{12}=4096,完全可接受)
2) 异或运算的性质
交换律:a ^ b = b ^ a
结合律:(a ^ b) ^ c = a ^ (b ^ c)
自反性:a ^ a = 0,a ^ 0 = a
本题中利用异或的性质,直接用 path ^= numsi 就能快速更新当前子集的异或和,无需额外遍历计算
3) 递归终止条件与状态统计
递归终止条件不是处理完所有元素时才统计,而是进入函数时就先统计当前状态:
第一次调用 dfs(nums, 0) 时,path=0(空子集)就会被统计,符合题目中空子集异或和为0的定义
每一层递归都会把当前路径对应的子集异或和加入总和,避免遗漏
题目2:全排列 II (LeetCode 47)
- 题目描述

- 核心问题分析
全排列问题的核心难点在于处理重复元素,避免生成重复排列。
以 nums = 1,1,2 为例,若直接按下标进行全排列,会出现以下情况:
|------|--------|
| 下标排列 | 对应数字排列 |
| 123 | 1 1 2 |
| 132 | 1 2 1 |
| 213 | 1 1 2 |
| 231 | 1 2 1 |
| 312 | 2 1 1 |
| 321 | 2 1 1 |
可以看到,每个有效排列都重复出现了2次(因为两个1的下标不同,但数值相同),因此需要通过规则限制,让相同元素的排列顺序固定,从而避免重复。
- 算法思路与核心规则
1) 预处理:排序
首先对 nums 进行排序,将所有相同元素放在相邻位置,方便后续去重判断。
2) 去重核心规则
为了避免重复排列,需要对相同元素的使用顺序做限制:
若元素 s 出现 x 次,则排序后的第2个s必须出现在第1个s之后,第3个s必须出现在第2个s之后,以此类推。
通俗理解:
对于排序后的 nums = 1,1,2,两个1的下标为0和1。
若当前要选择下标1的1,必须保证下标0的1已经被使用(visited0 == true)。
这样可以保证相同元素的使用顺序固定,不会出现"先选下标1的1,再选下标0的1"的情况,从而避免重复排列。
3) 深度优先搜索(DFS)+ 回溯
通过DFS枚举每个位置的所有可能数字,并通过回溯恢复状态,同时结合去重规则剪枝,最终得到所有不重复的全排列。
- 递归函数设计与流程
函数定义 void backtrack(vector<int>& nums, int idx)
参数:idx(当前需要填入的位置,也表示已处理的数字个数)
作用:递归查找所有合法排列,并存储到结果列表中。
递归流程
1) 初始化变量:
ans:二维数组,存储所有不重复的排列结果。
perm:一维数组,存储当前递归路径中的排列。
visited:一维布尔数组,标记下标是否已被使用。
2) 递归终止条件:当 idx == nums.size() 时,说明已处理完所有数字,将当前 perm 存入 ans,并返回。
3) 递归过程(核心剪枝逻辑):
枚举所有下标 i,满足以下条件时,才选择 numsi 填入当前位置:
visitedi == false(该下标未被使用);
若 numsi == numsi-1,则必须保证 visitedi-1 == true(即前一个相同元素已被使用)。
执行步骤:
a. 标记 visitedi = true;
b. 将 numsi 加入 perm;
c. 递归调用 backtrack(nums, idx+1),处理下一个位置;
d. 回溯:将 numsi 从 perm 中移除,标记 visitedi = false。
4) 深度理解剪枝
排序的作用:以示例数组 1,1,1,2 为例,排序后相同元素会相邻排列,这是后续去重判断的基础。如果不排序,相同元素分散在数组中,无法通过下标关系快速判断重复分支。
剪枝的两个核心原则
-
同一个节点的所有分支中,相同的元素只能选择一次:避免在同一层递归中,重复选择相同数值的元素,生成重复的排列路径。
-
同一个数只能使用一次(通过check数组标记):保证每个下标对应的元素,在一个排列中只会被使用一次,符合全排列的定义。
剪枝逻辑的两种理解方式
- 「只关心不合法分支」的条件(排除法)
checki == true || (i > 0 && numsi == numsi-1 && checki-1 == false)
这个条件判断的是不合法的情况,只要满足其中任意一条,就跳过当前分支:
checki == true:当前元素已经被使用过,不能再选。
i > 0 && numsi == numsi-1 && checki-1 == false:当前元素和前一个元素相同,但前一个相同元素还没被使用。这时候如果直接选当前元素,就会出现重复的排列路径(比如先选第二个1,再选第一个1),属于不合法分支。
- 「只关心合法分支」的条件(包含法)
checki == false && (i == 0 || numsi != numsi-1 || checki-1 == true)
这个条件判断的是合法的情况,必须同时满足所有条件,才会选择当前元素:
checki == false:当前元素未被使用。
i == 0:是数组的第一个元素,无需和前一个元素比较。
numsi != numsi-1:当前元素和前一个元素不同,不存在重复风险。
checki-1 == true:当前元素和前一个元素相同,但前一个相同元素已经被使用,此时可以选择当前元素(保证相同元素按顺序使用,避免重复)。
这两个条件本质上是等价的,只是逻辑判断的方向相反:一个是「排除错误分支」,一个是「保留正确分支」。
cpp
class Solution
{
vector<int> path; // 存储当前递归路径的排列
vector<vector<int>> ret;// 存储最终结果
bool check[9]; // 标记下标是否被使用(nums长度≤8,所以大小设为9)
public:
vector<vector<int>> permuteUnique(vector<int>& nums)
{
// 1. 排序,将相同元素放在相邻位置
sort(nums.begin(), nums.end());
// 2. 初始化visited数组为false
memset(check, 0, sizeof(check));
// 3. 开始DFS,从第0个位置开始
dfs(nums, 0);
return ret;
}
void dfs(vector<int>& nums, int pos)
{
// 递归终止条件:已处理完所有数字
if(pos == nums.size())
{
ret.push_back(path);
return;
}
// 枚举所有可能的数字
for(int i = 0; i < nums.size(); i++)
{
// 剪枝条件:
// ① 当前下标未被使用
// ② 要么是第一个元素,要么当前元素与前一个元素不同,要么前一个相同元素已被使用
if(check[i] == false && (i == 0 || nums[i] != nums[i - 1] || check[i - 1] != false))
{
// 标记为已使用
check[i] = true;
// 加入当前路径
path.push_back(nums[i]);
// 递归处理下一个位置
dfs(nums, pos + 1);
// 回溯:恢复现场
path.pop_back();
check[i] = false;
}
}
}
};- 关键知识点总结
1) 排序预处理:将相同元素相邻排列,为后续去重判断提供基础。
2) DFS+回溯:通过递归枚举所有可能,回溯恢复状态,是排列问题的经典解法。
3) 剪枝与去重:核心是通过visited数组和"前一个相同元素必须已被使用"的规则,避免重复排列,大幅减少无效递归。
4) 时间复杂度:O(n * n!),其中n为数组长度。排序的时间复杂度为O(nlog n),DFS枚举的时间复杂度为O(n!),每次递归中处理排列的时间为O(n)。
5) 空间复杂度:O(n),递归栈深度为n,同时需要额外的path和visited数组。
题目3:电话号码的字母组合(LeetCode 17)
- 题目描述

- 算法思路
这是典型的组合型回溯问题:每个数字对应的字母是独立的,不同位置的字母选择互不影响,因此不需要标记已选元素。
核心逻辑:按顺序处理每个数字,递归穷举当前数字的所有字母,填入组合字符串;递归结束后通过回溯撤销操作。
递归函数设计 void backtrack(unordered_map<char, string>& phoneMap, string& digits, int index)
参数:
index:当前已经处理的数字个数(即组合字符串的长度)
path:当前正在构建的字母组合
res:存储所有合法组合的结果列表
作用:递归穷举所有合法的字母组合,并存入 res
递归流程
-
递归结束条件:当 index 等于 digits 的长度时,将当前 path 加入结果列表,返回。
-
取出当前数字:获取 digitsindex,并通过 phoneMap 取出它对应的所有字母列表。
-
遍历字母并递归:依次将每个字母加入 path,递归处理下一个数字(index+1)。
-
回溯撤销:递归返回后,将刚加入的字母从 path 末尾删除,恢复现场。
cpp
#include <vector>
#include <string>
using namespace std;
class Solution
{
// 数字与字母的映射,下标对应数字(0和1无对应字母,因此为空字符串)
string hash[10] = {"", "", "abc", "def", "ghi", "jkl", "mno", "pqrs", "tuv", "wxyz"};
string path; // 存储当前递归路径上的字母组合
vector<string> ret; // 存储所有合法的字母组合结果
public:
// 主函数:输入数字字符串,返回所有可能的字母组合
vector<string> letterCombinations(string digits)
{
// 边界情况:输入为空字符串,直接返回空结果
if (digits.size() == 0)
return ret;
// 从第0个数字开始,启动深度优先搜索(回溯)
dfs(digits, 0);
return ret;
}
private:
// 深度优先搜索(回溯)函数
// 参数:digits-输入的数字字符串,pos-当前正在处理的数字下标
void dfs(string& digits, int pos)
{
// 递归终止条件:已经处理完所有数字
if (pos == digits.size())
{
// 此时path已经是一个完整的字母组合,加入结果集
ret.push_back(path);
return;
}
// 获取当前数字对应的字母集合
// digits[pos]是字符型数字,减去'0'得到整型数字下标
for (auto ch : hash[digits[pos] - '0'])
{
// 1. 做选择:将当前字母加入路径
path.push_back(ch);
// 2. 递归:处理下一个数字
dfs(digits, pos + 1);
// 3. 回溯:撤销上一步的选择,恢复路径,以便尝试下一个字母
path.pop_back();
}
}
};- 代码核心流程说明
-
hash数组:预先定义电话数字到字母的映射,避免每次计算。
-
path和ret:path 是递归过程中正在构建的字母组合;ret 保存所有合法的最终组合。
-
主函数:先判断输入是否为空,为空直接返回;调用dfs从第0个数字开始回溯。
-
dfs递归过程:
终止条件:当pos等于输入数字的长度时,path已经是一个完整的组合,加入结果集。
遍历字母:对当前数字对应的每一个字母,依次执行「选择→递归→回溯」三步。
回溯操作:path.pop_back() 撤销上一步的选择,保证循环里下一次迭代时path是干净的。
题目4:括号生成(LeetCode 22)
- 题目描述

- 算法思路
这是典型的剪枝型回溯问题,核心是通过条件判断提前排除不合法的分支,避免无效递归:从左往右构建括号字符串,每个位置可以尝试添加左括号或右括号,但需要满足两个约束条件。
合法性判断条件
-
添加左括号:当前左括号的数量必须小于 n(最多只能有 n 个左括号)。
-
添加右括号:当前右括号的数量必须小于左括号的数量(否则会出现 ")(" 这种无效前缀)。
递归函数设计 void dfs()
成员变量参数:
left:当前路径中左括号的数量
right:当前路径中右括号的数量
path:当前正在构建的括号字符串
res:存储所有合法组合的结果列表
n:需要生成的括号对数
作用:递归穷举所有合法的括号组合,并存入 res
递归流程
-
递归结束条件:当 right == n(即右括号数量达到 n,说明括号已全部匹配完成),将当前 path 加入结果列表,返回。
-
尝试添加左括号:如果 left < n,则添加左括号,递归后回溯。
-
尝试添加右括号:如果 right < left,则添加右括号,递归后回溯。
cpp
#include <vector>
#include <string>
using namespace std;
class Solution {
// 成员变量:记录当前左右括号数量、总对数n、当前路径、结果集
int left, right, n;
string path;
vector<string> ret;
public:
// 主函数:生成n对括号的所有合法组合
vector<string> generateParenthesis(int _n) {
n = _n; // 初始化总括号对数
left = 0; // 初始左括号数量为0
right = 0; // 初始右括号数量为0
dfs(); // 启动深度优先搜索(回溯)
return ret;
}
private:
// 深度优先搜索(回溯)函数
void dfs() {
// 递归终止条件:右括号数量等于总对数n,说明括号已全部匹配完成
if (right == n) {
ret.push_back(path); // 将当前合法的括号组合加入结果集
return;
}
// 情况1:尝试添加左括号(剪枝条件:左括号数量未达到n)
if (left < n) {
path.push_back('('); // 1. 做选择:添加左括号
left++; // 更新左括号计数
dfs(); // 2. 递归:继续构建后续括号
path.pop_back(); // 3. 回溯:撤销添加的左括号,恢复现场
left--; // 恢复左括号计数
}
// 情况2:尝试添加右括号(剪枝条件:右括号数量小于左括号数量,保证前缀合法)
if (right < left) {
path.push_back(')'); // 1. 做选择:添加右括号
right++; // 更新右括号计数
dfs(); // 2. 递归:继续构建后续括号
path.pop_back(); // 3. 回溯:撤销添加的右括号,恢复现场
right--; // 恢复右括号计数
}
}
};- 两道题的核心知识点对比
|--------|-------------------------------------|-----------------------|
| 维度 | 电话号码的字母组合 | 括号生成 |
| 问题类型 | 组合型回溯(无剪枝,所有分支都合法) | 剪枝型回溯(有约束,提前排除无效分支) |
| 递归约束 | 无额外约束,仅按数字顺序穷举字母 | 需同时满足左右括号数量的合法性约束 |
| 递归结束条件 | 处理完所有数字(index == len) | 右括号数量达到 n(right == n) |
| 回溯操作 | 撤销上一步添加的字母 | 撤销上一步添加的括号 |
| 时间复杂度 | O(3^m * 4^n),m+n=digits长度 | (卡特兰数) |
| 空间复杂度 | (递归栈+路径存储) | (递归栈+路径存储) |
dfs回溯过程
终止条件:当right == n时,所有右括号已匹配完成,此时path是一个合法的括号组合,加入结果集。
添加左括号:只要左括号数量小于n,就可以添加左括号(因为左括号最多只能有n个)。
添加右括号:只有当右括号数量小于左括号数量时,才能添加右括号(否则会出现)(这种无效前缀)。
回溯操作:每次递归返回后,都通过pop_back()和变量自减,撤销上一步的选择,恢复到进入递归前的状态,以便尝试其他分支。
关键剪枝逻辑
这道题的核心就是两个剪枝条件,避免无效递归:
|-------|---------------|-------------------------------|
| 操作 | 剪枝条件 | 目的说明 |
| 添加左括号 | left < n | 限制左括号总数不超过n,避免出现多余的( |
| 添加右括号 | right < left | 保证任意前缀中左括号数量≥右括号,避免出现)在(前面的情况 |
题目5:组合(LeetCode 77)
- 题目描述

- 解法:回溯算法
1) 算法思路
组合问题不考虑元素顺序(如 1,2 和 2,1 视为同一个组合),为避免重复,我们规定:
后续选择的元素必须大于前一个元素,这样就不会产生重复组合。
整体流程:
-
以每个元素作为组合的首元素;
-
后续位置,只能选择比前一个元素更大的数;
-
当组合的长度等于 k 时,记录该组合并返回。
2) 递归函数设计
函数原型:void dfs(vector<vector<int>>& ans, vector<int>& v, int step, int &n, int &k)
ans:存储所有组合的二维数组;
v:存储当前路径的一维数组;
step:当前需要处理的位置/起始选择的数字;
n、k:题目给定的参数。
函数作用:以某个元素作为当前位置的数字,递归查找所有可能的组合。
3) 具体实现步骤
- 定义全局/类内变量:
vector<int> path:记录当前路径;
vector<vector<int>> ret:记录所有结果;
int n, k:题目参数。
- 递归流程:
结束条件:当前路径长度等于 k,将 path 加入 ret 并返回;
剪枝优化:当前位置到 n 的元素数量不足 k - path.size() 时,直接返回;
递归与回溯:选择当前元素 i,加入 path;递归调用 dfs(i+1)(下一次只能选比 i 大的数);回溯:将 i 从 path 中弹出,尝试下一个元素。
cpp
class Solution
{
// path:记录当前正在构建的组合路径
vector<int> path;
// ret:存储所有满足条件的组合结果
vector<vector<int>> ret;
// n:题目给定的数字范围上限,k:每个组合的元素个数
int n, k;
public:
// 主函数:处理输入并启动回溯
vector<vector<int>> combine(int _n, int _k)
{
// 初始化类内成员变量
n = _n;
k = _k;
// 从数字1开始,启动回溯
dfs(1);
// 返回所有组合结果
return ret;
}
// 回溯函数:start表示当前层可以选择的数字起始位置
void dfs(int start)
{
// 递归终止条件:当前路径的长度已经等于k
if (path.size() == k)
{
// 把当前合法的组合加入结果集
ret.push_back(path);
// 结束当前递归分支
return;
}
// 从start到n,遍历所有可能的数字作为当前位置的元素
for (int i = start; i <= n; ++i)
{
// 选择当前数字i,加入路径
path.push_back(i);
// 递归进入下一层:下一层只能选择比i大的数字(避免重复组合)
dfs(i + 1);
// 回溯:撤销上一步的选择,恢复路径状态,尝试下一个数字
path.pop_back();
}
}
};- 关键知识点补充
1) 为什么要从 start 开始遍历?
组合问题不考虑顺序(1,2 和 2,1 视为同一个),所以用 start 限制后续只能选比当前大的数,避免生成重复组合。
2) 回溯的核心流程
path.push_back(i):做出选择 dfs(i + 1):递归深入
path.pop_back():撤销选择(恢复现场),这是回溯算法的灵魂。
3) 剪枝优化(可选,原代码未写)
可以把 for 循环的上限改成 n - (k - path.size()) + 1,避免遍历那些"后续凑不够k个元素"的数字,大幅提升效率:
cpp
// 优化后的for循环
for (int i = start; i <= n - (k - path.size()) + 1; ++i)题目6:目标和(LeetCode 494)
- 题目描述

- 解法:回溯算法
算法思路
对于每个数,可以选择加上或减去它,依次枚举每一个数字,在每个数都被选择时检查得到的和是否等于目标值。如果等于,则记录结果。
为了优化时间复杂度,可以提前计算出数组中所有数字的和 sum,以及数组的长度 len。这样可以快速判断当前的和减去剩余的所有数是否已经超过了目标值 target,或者当前的和加上剩下的数的和是否小于目标值 target,如果满足条件,则可以直接回溯剪枝。
递归流程(直接枚举 +/-)
-
递归结束条件:index 与数组长度相等,判断当前状态的 sum 是否与目标值相等,若是计数加一;
-
选择当前元素进行加操作,递归下一个位置,并更新参数 sum;
-
选择当前元素进行减操作,递归下一个位置,并更新参数 sum。
进阶思路:转化为子集和问题
此问题可以转化为另一个问题:
若所有元素初始状态均为减,选择其中几个元素将它们的状态修改为加,计算修改后的元素和与目标值相等的方案个数。
-
选择其中 x 个元素进行修改,并且这 x 个元素的和为 y;
-
检查使得 -sum + 2*y = target(移项得:y = (sum + target) / 2)成立的方案个数,即选择 x 个元素和为 (sum + target)/2 的方案个数;
若 sum + target 为奇数,则不存在这种方案;
- 递归流程:
a. 传入参数:index(当前要处理的元素下标),sum(当前状态和),nums(元素数组),aim(目标值:(sum+target)/2);
b. 递归结束条件:index 与数组长度相等,判断当前 sum 是否与目标值相等,若是返回 1,否则返回 0;
c. 返回 递归选择当前元素 以及 递归不选择当前元素 函数值的和。
- C++ 代码(直接枚举版,含注释)
写法A:path 作为函数参数传递
cpp
class Solution
{
// ret:记录满足条件的方案总数
int ret = 0;
// aim:目标值,即题目中的target
int aim;
public:
int findTargetSumWays(vector<int>& nums, int target)
{
// 初始化目标值
aim = target;
// 从第0个元素、当前和为0开始回溯
dfs(nums, 0, 0);
// 返回所有方案数
return ret;
}
// 回溯函数
// nums:原数组
// pos:当前处理到的元素下标
// path:当前已经构造的表达式的和
void dfs(vector<int>& nums, int pos, int path)
{
// 递归结束条件:已经处理完所有元素
if (pos == nums.size())
{
// 如果当前和等于目标值,方案数+1
if (path == aim)
ret++;
return;
}
// 分支1:给当前元素添加 '+' 号
dfs(nums, pos + 1, path + nums[pos]);
// 分支2:给当前元素添加 '-' 号
dfs(nums, pos + 1, path - nums[pos]);
}
};✅ 写法A(参数传递)的优点
-
逻辑更安全:不需要手动恢复现场,完全避免了"忘记回溯"的bug。
-
代码更简洁:递归分支里只需要写一次调用,不用成对写修改+恢复的代码。
-
调试更轻松:每个递归分支的 path 都是独立的,不会因为其他分支的修改而变化,单步调试时一眼就能看到当前分支的状态。
❌ 写法A的缺点:会产生额外的栈空间开销,每个递归调用都会创建一个新的 path 副本,但在LeetCode的题目中,这种开销完全可以忽略。
写法B:path 作为全局/类成员变量
- 全局变量的作用
ret:用来统计所有满足条件的方案数量。
aim:保存题目给定的 target,避免每次递归都传递参数。
path:记录当前递归分支中,表达式的和,在回溯过程中动态修改。
- 回溯的核心流程
选择:path += numspos 或 path -= numspos,修改当前路径和。
递归:调用 dfs(nums, pos + 1),处理下一个元素。
撤销选择(恢复现场):递归返回后,执行 path -= numspos 或 path += numspos,让路径和回到递归前的状态,供其他分支使用。
- 递归终止条件
当 pos == nums.size() 时,说明所有元素都已经被赋予了 + 或 -,此时检查 path 是否等于 aim,如果相等则方案数 ret++。
cpp
class Solution {
// 全局变量:记录最终方案数
int ret = 0;
// 全局变量:目标和(题目中的target)
int aim;
// 全局变量:当前路径的和(回溯过程中动态变化)
int path = 0;
public:
// 主函数:处理输入,启动回溯
int findTargetSumWays(vector<int>& nums, int target)
{
aim = target; // 初始化目标和
dfs(nums, 0); // 从第0个元素、路径和为0开始回溯
return ret; // 返回最终方案数
}
// 回溯函数
// nums:原数组
// pos:当前处理到的元素下标
void dfs(vector<int>& nums, int pos)
{
// 递归结束条件:已经处理完所有元素
if (pos == nums.size())
{
// 如果当前路径和等于目标和,方案数+1
if (path == aim)
ret++;
return;
}
// --------------------------
// 分支1:给当前元素添加 '+' 号
// --------------------------
path += nums[pos]; // 做出选择:加上当前元素
dfs(nums, pos + 1); // 递归进入下一层
path -= nums[pos]; // 回溯:撤销选择,恢复路径和
// --------------------------
// 分支2:给当前元素添加 '-' 号
// --------------------------
path -= nums[pos]; // 做出选择:减去当前元素
dfs(nums, pos + 1); // 递归进入下一层
path += nums[pos]; // 回溯:撤销选择,恢复路径和
}
};✅ 写法B(全局变量)的优点
-
节省空间:全程只用一个变量,没有额外的参数拷贝开销。
-
适合复杂场景:如果后续需要在递归过程中多次修改路径状态,全局变量的修改方式更灵活。
❌ 写法B的缺点
-
容易出错:必须严格遵循「修改→递归→恢复」的流程,漏写恢复代码会直接导致结果错误。
-
调试难度大:全局变量的状态会被所有分支共享,一旦出现问题,很难定位是哪个分支的修改导致的。
|--------|-----------------------------------------|--------------------------------------------------|
| 对比维度 | 写法A:path 作为参数传递 | 写法B:path 作为全局变量 |
| 状态传递方式 | 每次递归调用,都会创建一个新的 path 副本,传递给下一层 | 全程共享同一个 path 变量,通过「修改→递归→恢复」来维护状态 |
| 回溯方式 | 不需要手动写 pop_back()/恢复代码,参数传递天然保留了上一层状态 | 必须手动写「修改后恢复」的代码(如 path -= numspos),否则会污染其他分支 |
| 代码简洁度 | 代码更短,不用写恢复现场的代码,逻辑更直观 | 代码更长,需要成对写修改和恢复的语句,容易漏写导致错误 |
| 空间复杂度 | 递归深度为 n,每层的 path 是独立副本,空间复杂度为 O(n)(栈空间) | 仅用一个 path 变量,额外空间为 O(1)(不算递归栈) |
| 调试友好度 | 每层递归的 path 是独立的,不会互相干扰,调试时更容易定位问题 | 所有分支共享同一个变量,一旦某一层忘记恢复,会导致所有分支的结果出错,调试难度更高 |
| 线程安全性 | 天然线程安全,不同调用之间的参数互不干扰 | 非线程安全,如果多个调用同时执行,会互相修改全局变量,导致结果混乱 |
- 补充:子集和优化版代码
cpp
class Solution
{
public:
int findTargetSumWays(vector<int>& nums, int target)
{
int sum = 0;
for (int num : nums)
sum += num;
// 剪枝1:目标值的绝对值超过数组总和,不可能实现
if (abs(target) > sum)
return 0;
// 剪枝2:sum + target 必须为偶数,否则不存在方案
if ((sum + target) % 2 != 0)
return 0;
// 转化为:求和为 aim 的子集个数
int aim = (sum + target) / 2;
return dfs(nums, 0, 0, aim);
}
// 回溯求子集和等于aim的方案数
int dfs(vector<int>& nums, int pos, int currentSum, int aim)
{
// 递归结束条件:处理完所有元素
if (pos == nums.size())
return currentSum == aim ? 1 : 0;
// 分支1:不选当前元素,currentSum不变
int notChoose = dfs(nums, pos + 1, currentSum, aim);
// 分支2:选当前元素(如果加上后不超过aim)
int choose = 0;
if (currentSum + nums[pos] <= aim)
choose = dfs(nums, pos + 1, currentSum + nums[pos], aim);
// 返回两种选择的方案数之和
return notChoose + choose;
}
};题目7:组合总和(LeetCode 39)
- 题目描述

提示:
1 <= candidates.length <= 302 <= candidates[i] <= 40candidates的所有元素 互不相同1 <= target <= 40
- 核心算法思路(回溯法/DFS)
核心思想
因为元素可以重复选取,所以对于每个元素,我们有两种分支选择:
1) 跳过当前元素:直接处理下一个元素(不选当前数)。
2) 选择当前元素:将其加入当前组合,继续保留当前元素的选择权限(因为可以重复选),直到和超过目标值,再回溯撤销选择。
递归函数设计
函数定义: void dfs(vector<int>& candidates, int target, vector<vector<int>>& ans, vector<int>& combine, int idx)
参数说明:
target:当前状态和与目标值的差(剩余需要凑的和)。
ans:存储所有合法组合的结果集。
combine:当前正在构建的组合路径。
idx:当前需要处理的元素下标(控制不回头选,避免重复组合)。
递归流程
1) 结束条件:
a. 当前需要处理的元素下标越界;
b. 当前状态的元素和已经与⽬标值相同;
2) 跳过当前元素,当前状态不变,对下⼀个元素进⾏处理;
3) 选择将当前元素添加⾄当前状态,并保留状态继续对当前元素进⾏处理,递归结束时撤销添加操作
- C++ 代码解析
cpp
class Solution {
vector<vector<int>> ret;
int aim;
vector<int> path;
public:
vector<vector<int>> combinationSum(vector<int>& candidates, int target)
{
aim = target;
dfs(candidates, 0, 0);
return ret;
}
void dfs(vector<int>& candidates, int pos, int sum)
{
// 【终止条件1】当前路径的和等于目标和
// 说明 path 是一个合法组合,保存到结果集并返回
if (sum == aim)
{
ret.push_back(path);
return;
}
// 【终止条件2】剪枝判断:
// 1. sum > aim:当前和已经超过目标和,继续选数字只会更大,直接返回
// 2. pos == candidates.size():已经遍历完所有数字,没有可选元素了,直接返回
if (sum > aim || pos == candidates.size())
{
return;
}
// 【核心循环】从 pos 开始遍历候选数字(避免回头选,防止出现 [2,3] 和 [3,2] 这类重复组合)
for (int i = pos; i < candidates.size(); i++)
{
// 【回溯步骤1:做选择】
// 将当前数字 candidates[i] 加入路径
path.push_back(candidates[i]);
// 【回溯步骤2:递归探索】
// 继续递归:
// - 下标仍传 i(不是 i+1),允许重复选取同一个数字
// - 更新当前和:sum + candidates[i]
dfs(candidates, i, sum + candidates[i]);
// 【回溯步骤3:撤销选择】
// 递归结束后,把刚加入的数字从路径中移除,恢复到上一层的状态
// 这样才能尝试下一个数字的所有可能组合
path.pop_back();
}
}
};关键注释点总结
-
为什么递归时传 i 而不是 i+1?因为题目允许数字重复选取,所以当前数字选完后,下一层递归还可以继续选它,所以下标要传 i。
-
为什么循环从 pos 开始?为了避免生成重复组合(比如 2,3 和 3,2),我们规定只能从当前下标往后选,不回头选之前的数字。
-
path.push_back 和 path.pop_back 为什么必须成对出现?
这是回溯的核心:先把当前数字加入路径,递归探索完所有包含它的组合后,再把它移除,恢复路径状态,才能继续尝试下一个数字。
cpp
class Solution {
vector<vector<int>> ret;
int aim;
vector<int> path;
public:
vector<vector<int>> combinationSum(vector<int>& candidates, int target)
{
aim = target;
dfs(candidates, 0, 0);
return ret;
}
void dfs(vector<int>& candidates, int pos, int sum)
{
// 【终止条件1】当前路径和等于目标和,保存路径并返回
if(sum == aim)
{
ret.push_back(path);
return;
}
// 【终止条件2】剪枝
// 1. sum > aim:当前和已超过目标和,继续选只会更大,直接返回
// 2. pos == candidates.size():已处理完所有元素,无后续可选,直接返回
if(sum > aim || pos == candidates.size())
return;
// ------------------------------
// 枚举当前元素 candidates[pos] 的选取次数 k(0次、1次、2次...)
// k=0 表示不选当前元素,k>=1 表示选 k 次
for(int k = 0; k * candidates[pos] + sum <= aim; k++)
{
// 只有 k>=1 时,才将当前元素加入路径
// k=0 时不加入,直接跳过当前元素
if(k != 0)
path.push_back(candidates[pos]);
// 递归处理下一个元素(pos+1)
// 注意:这里传 pos+1,因为当前元素的所有可能次数已经枚举完了,不再回头选
// sum + k * candidates[pos]:更新当前路径的和
dfs(candidates, pos + 1, sum + k * candidates[pos]);
}
// ------------------------------
// 恢复现场(回溯)
// 把上面循环中加入 path 的 candidates[pos] 全部移除
// 因为 path 中最多有 k_max 个当前元素,所以循环 k_max 次 pop_back
for(int k = 1; k * candidates[pos] + sum <= aim; k++)
{
path.pop_back();
}
}
};关键知识点说明
- 和「逐个选」写法的核心区别
这段代码是「一次性枚举当前元素的所有选取次数」,再直接跳到下一个元素处理,逻辑更显式。
之前的写法是「每次选1个,通过递归次数控制选几个」,代码更简洁。
两种写法都是正确的,都能通过所有测试用例。
- 为什么 k=0 不 push_back?
k=0 表示「不选当前元素」,所以不用把它加入路径,直接递归到下一个元素,相当于实现了「跳过当前元素」的分支。
k>=1 时,才把元素加入路径,相当于实现了「选当前元素k次」的分支。
- 为什么递归时传 pos+1?
因为当前元素的所有可能次数(0次、1次、2次...)已经在 for 循环里枚举完了,下一层递归只需要处理后面的元素即可,不需要再回头处理当前元素。
这样就避免了生成重复组合(比如 2,3 和 3,2)。
- 恢复现场的 for 循环
前面 for(k=0;...) 里,k=1 时 push_back 1次,k=2 时 push_back 第2次......
所以 path 里会有 k_max 个 candidatespos,需要用 for(k=1;...) 循环 pop_back k_max 次,把 path 恢复到进入函数前的状态。
- 剪枝优化
提前判断 sum > aim,一旦和超过目标值就停止递归,避免无效计算。
用 k * candidatespos + sum <= aim 限制循环次数,减少不必要的循环。
题目8:字母大小写全排列(LeetCode 784)
- 题目描述

- 核心算法思路(回溯法/DFS)
核心思想
对字符串的每个字符,按位置依次处理,根据字符类型分情况处理:
1)数字:只能保持原样,无其他分支。
2)字母:有两种分支选择:保持当前大小写不变;转换为相反的大小写(小写转大写,大写转小写)
递归函数设计
函数定义: void dfs(string& s, int pos)
参数说明:
s:输入的原始字符串;
pos:当前正在处理的字符下标。
递归流程
-
结束条件:pos == s.length(),表示所有字符处理完毕,将当前路径 path 加入结果集 ret,返回。
-
处理当前字符:
分支1:不做任何修改,直接将原字符加入 path,递归处理下一个字符 pos+1,递归结束后回溯(pop_back)。
分支2:如果当前字符是字母,转换其大小写,将转换后的字符加入 path,递归处理下一个字符 pos+1,递归结束后回溯(pop_back)。
cpp
class Solution
{
string path;
vector<string> ret;
public:
vector<string> letterCasePermutation(string s)
{
dfs(s, 0);
return ret;
}
void dfs(string& s, int pos)
{
if(pos == s.length())
{
ret.push_back(path);
return;
}
char ch = s[pos];
// 不改变当前字符,直接加入路径
path.push_back(ch);
dfs(s, pos + 1);
path.pop_back(); // 恢复现场
// 若当前字符不是数字(即字母),尝试转换大小写
if(ch < '0' || ch > '9')
{
char tmp = change(ch);
path.push_back(tmp);
dfs(s, pos + 1);
path.pop_back(); // 恢复现场
}
}
char change(char ch)
{
if(ch >= 'a' && ch <= 'z')
ch -= 32; // 小写字母转大写
else
ch += 32; // 大写字母转小写
return ch;
}
};- 关键知识点拆解
- 回溯的"选择-撤销"模型
path.push_back(ch):做选择,将当前字符(原字符/转换后的字符)加入路径。
dfs(...):递归处理后续字符。
path.pop_back():撤销选择,恢复到上一层状态,尝试其他分支。
- 大小写转换的实现
利用ASCII码的特性:小写字母 a-z 的ASCII值为97-122,大写字母 A-Z 为65-90,两者相差32。
小写转大写:ch -= 32;大写转小写:ch += 32。
- 数字的特殊处理
数字字符没有大小写之分,因此只有"不修改"这一个分支,无需额外处理。
- 终止条件的设计
当 pos 等于字符串长度时,说明所有字符都已处理完毕,此时的 path 就是一个完整的合法字符串,加入结果集即可。
题目9:优美的排列(LeetCode 526)
- 题目描述

- 核心算法思路(回溯法/DFS)
核心思想
通过深度优先搜索,按位置依次尝试填入数字,同时用 visited 数组标记已使用的数字,避免重复使用。在每个位置填入数字时,需要检查是否满足"优美排列"的条件。
递归函数设计
函数定义:void dfs(int pos, int n)
参数说明:
pos:当前正在处理的位置(下标从1开始);
n:排列的长度。
递归流程
1) 结束条件:当 pos == n + 1 时,表示所有位置都已处理完毕,此时得到一个合法的优美排列,计数 ret++,返回。
2) 遍历所有可能的数字:对于数字 i(从1到n),如果 i 未被使用(!checki),且满足条件 (pos % i == 0 || i % pos == 0),则:标记 checki = true;递归处理下一个位置 pos + 1;回溯,标记 checki = false,恢复状态。
cpp
class Solution {
bool check[16]; // 标记数字是否已被使用(n最大为15,数组大小16足够)
int ret; // 记录优美排列的数量
public:
int countArrangement(int n)
{
ret = 0; // 初始化计数为0
memset(check, 0, sizeof(check)); // 初始化标记数组为未使用
dfs(1, n); // 从位置1开始DFS
return ret;
}
void dfs(int pos, int n)
{
// 【终止条件】所有位置处理完毕,计数+1并返回
if (pos == n + 1)
{
ret++;
return;
}
// 遍历所有数字i(1~n),尝试填入当前位置pos
for (int i = 1; i <= n; i++)
{
// 条件:数字i未被使用,且满足"优美排列"条件
if (!check[i] && (pos % i == 0 || i % pos == 0))
{
// 做选择:标记数字i为已使用
check[i] = true;
// 递归处理下一个位置
dfs(pos + 1, n);
// 撤销选择:回溯,标记数字i为未使用
check[i] = false;
}
}
}
};- 关键知识点拆解
1) 回溯的"选择-撤销"模型
checki = true:标记数字 i 已被使用,做选择。
dfs(pos + 1, n):递归处理后续位置。
checki = false:撤销选择,恢复状态,尝试其他数字。
2) 条件判断的优化
题目要求的两个条件可以合并为 (pos % i == 0 || i % pos == 0),无需分开判断。
只有满足条件的数字才会被填入,提前剪枝,减少无效递归。
3) 标记数组的作用
check 数组用于记录哪些数字已经被使用,避免在排列中出现重复数字,这是排列类回溯题的核心。
题目10:N 皇后(LeetCode 51)
- 题目描述
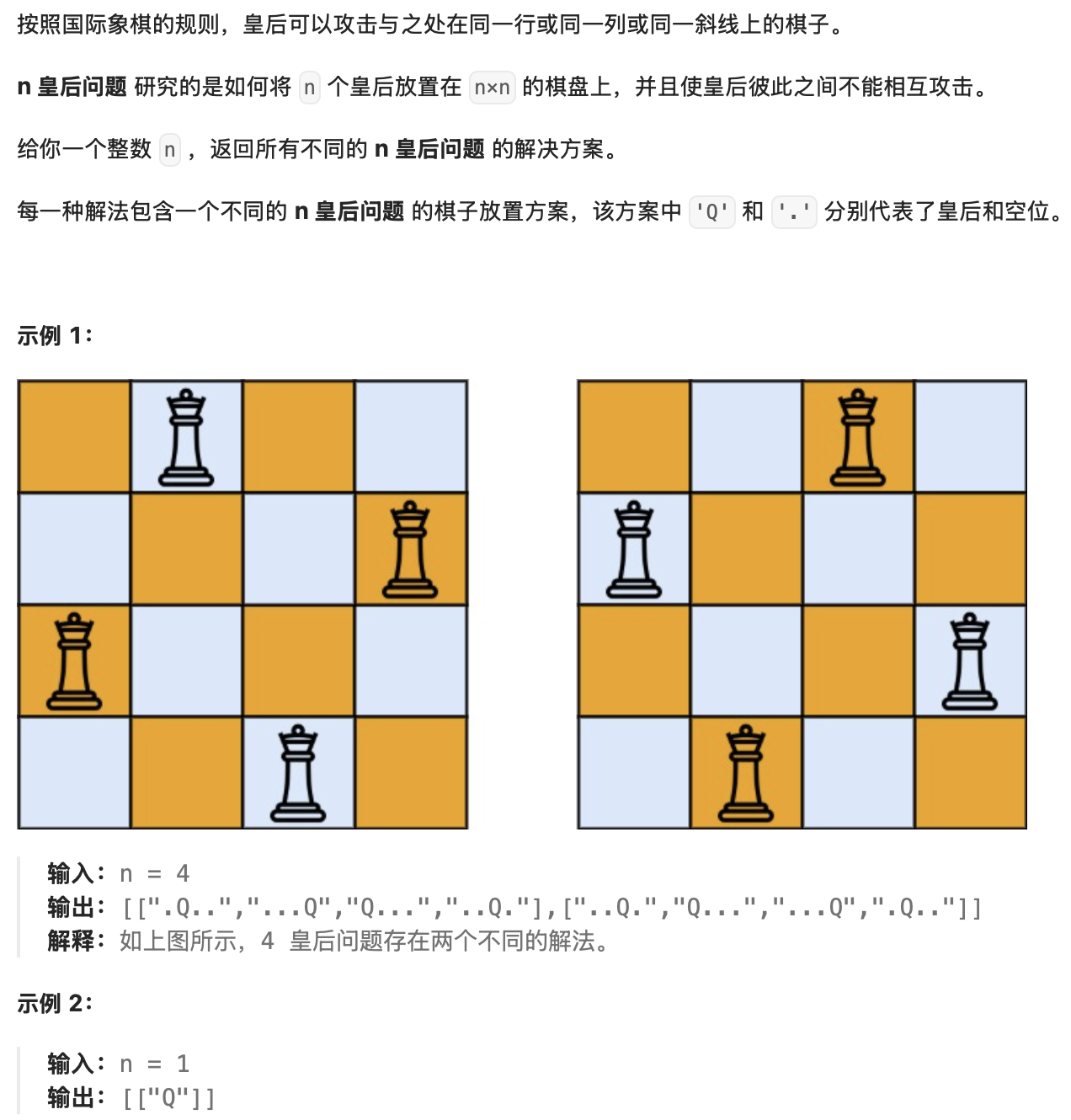
提示: 1 <= n <= 9
- 核心算法思路(回溯+DFS)
- 核心思想
采用逐行放置皇后的策略,在每一行尝试放置一个皇后,通过递归+回溯的方式探索所有合法摆放方案:
-
第一行放置第一个皇后,遍历第二行,在可行位置放置第二个皇后,以此类推,直到放置完n个皇后;
-
用数组记录每一行皇后的列数,放置时检查是否与已放置的皇后冲突;
-
若不冲突,递归放置下一行皇后;若所有皇后放置完成,记录方案;回溯时撤销当前放置,继续尝试其他位置。
- 冲突判断逻辑
皇后的攻击范围包括列、两条对角线,需分别记录这些位置是否已被占用:
|------------|-------------------|----------------------------------------------|
| 冲突类型 | 判断依据 | 记录数组 |
| 同一列冲突 | 同一列只能有1个皇后 | columns(长度为n,布尔数组,标记列是否被占用) |
| 左上→右下对角线冲突 | 同一条对角线上,行号-列号的值相同 | diagonals1(长度为2n-1,布尔数组,标记对角线是否被占用,偏移+n避免负数) |
| 右上→左下对角线冲突 | 同一条对角线上,行号+列号的值相同 | diagonals2(长度为2n-1,布尔数组,标记对角线是否被占用) |
- 递归DFS设计
函数定义 void dfs(vector<vector<string>> &solutions, vector<int> &queens, int &n, int row, vector<bool> &columns, vector<bool> &diagonals1, vector<bool> &diagonals2)
solutions:存储所有合法方案的二维字符串数组;
queens:一维数组,queensrow表示第row行皇后所在的列;
n:棋盘大小(皇后数量);
row:当前需要处理的行数;
columns/diagonals1/diagonals2:冲突标记数组。
递归流程
-
结束条件:当row == n时,表示所有行的皇后已合法放置完成,将当前方案转换为字符串格式存入solutions,返回;
-
枚举当前行的列:遍历当前行的每一列col,检查columnscol、diagonals1row-col+n、diagonals2row+col是否为false(无冲突);
-
放置皇后(标记占用):若无冲突,标记columnscol = true、diagonals1row-col+n = true、diagonals2row+col = true,并在棋盘对应位置设置'Q';
-
递归下一行:调用dfs(row+1, ...)处理下一行;
-
回溯(撤销操作):递归返回后,将标记数组恢复为false,棋盘位置恢复为'.',继续枚举下一列。
cpp
class Solution
{
bool checkCol[10], checkDig1[20], checkDig2[20];
vector<vector<string>> ret;
vector<string> path;
int n;
public:
vector<vector<string>> solveNQueens(int _n)
{
n = _n;
path.resize(n);
for(int i = 0; i < n; i++)
{
path[i].append(n, '.');
}
dfs(0);
return ret;
}
void dfs(int row)
{
// 递归终止条件:所有行都处理完了,找到一组解
if(row == n)
{
ret.push_back(path);
return;
}
// 枚举当前行的每一列,尝试放置皇后
for(int col = 0; col < n; col++)
{
// 剪枝:检查列和两条对角线是否冲突
if(!checkCol[col] && !checkDig1[row - col + n] && !checkDig2[row + col])
{
// 放置皇后
path[row][col] = 'Q';
checkCol[col] = true;
checkDig1[row - col + n] = true;
checkDig2[row + col] = true;
// 递归处理下一行
dfs(row + 1);
// 回溯:恢复现场
path[row][col] = '.';
checkCol[col] = false;
checkDig1[row - col + n] = false;
checkDig2[row + col] = false;
}
}
}
};- 关键知识点总结
-
回溯算法:核心是"尝试-递归-撤销",通过深度优先搜索探索所有可能的摆放方式,遇到冲突则剪枝,保证效率;
-
冲突优化:用布尔数组标记列和对角线的占用状态,避免每次都遍历已放置的皇后进行冲突检查,时间复杂度从O(n^n)优化为O(n!);
-
对角线偏移处理:row-col可能为负数,因此diagonals1的索引需要加上n,保证索引非负;
-
方案存储:用二维字符串数组存储最终结果,递归结束时将一维数组的皇后位置转换为棋盘格式。
-
pathi.append(n, '.'); pathi 是第 i 行的字符串;append(n, '.') 就是:给这一行追加 n 个 .;执行完之后,pathi 就变成了一个长度为 n 的字符串,全都是 .,比如 n=4 时就是 "...."。所以这几行代码的效果,就是把整个棋盘初始化为一个 n×n、全是 . 的空棋盘
题目11:有效的数独(LeetCode 36)
- 题目描述

- 核心算法思路
1) 核心思想
通过三个布尔数组分别标记「行、列、3×3宫」中数字 1-9 是否已出现,遍历整个数独棋盘,遇到数字时检查是否已被标记,若未标记则记录,否则直接返回 false。
2) 标记数组设计
|----------------------|-------------------|---------------------------------------------------------|
| 数组 | 作用 | 索引说明 |
| row910 | 标记每一行中数字是否出现 | rowinum 表示第 i 行数字 num 是否已出现 |
| col910 | 标记每一列中数字是否出现 | coljnum 表示第 j 列数字 num 是否已出现 |
| grid3310 | 标记每个 3×3 宫内数字是否出现 | gridi/3j/3num 表示第 (i/3,j/3) 个宫的数字 num 是否已出现 |
注:num 范围为 1-9,数组长度设为 10 是为了直接用数字作为下标,避免额外偏移计算。
cpp
class Solution
{
bool row[9][10]; // row[i][num] 表示第 i 行是否存在数字 num
bool col[9][10]; // col[j][num] 表示第 j 列是否存在数字 num
bool grid[3][3][10]; // grid[i/3][j/3][num] 表示第 (i/3,j/3) 个宫是否存在数字 num
public:
bool isValidSudoku(vector<vector<char>>& board)
{
// 初始化标记数组(全局变量默认初始化为 false,也可手动初始化)
memset(row, 0, sizeof(row));
memset(col, 0, sizeof(col));
memset(grid, 0, sizeof(grid));
// 遍历整个 9×9 棋盘
for(int i = 0; i < 9; i++)
{
for(int j = 0; j < 9; j++)
{
if(board[i][j] != '.') // 只处理已填入的数字
{
int num = board[i][j] - '0'; // 将字符转换为数字('1'~'9' → 1~9)
// 检查:当前行、列、宫是否已存在该数字
if(row[i][num] || col[j][num] || grid[i/3][j/3][num])
{
return false; // 存在重复,数独无效
}
// 标记当前数字已出现
row[i][num] = true;
col[j][num] = true;
grid[i/3][j/3][num] = true;
}
}
}
return true; // 所有数字均无重复,数独有效
}
};- 关键知识点解析
1) 宫索引计算:i/3 和 j/3
数独被分为 3×3 个宫,每个宫占 3 行 3 列;
对于行号 i,i/3 表示当前单元格属于第几行的宫(0/1/2);
对于列号 j,j/3 表示当前单元格属于第几列的宫(0/1/2);
例如:i=0,j=0 → grid00(左上角宫);i=4,j=5 → grid11(中心宫)。
2) 字符转数字:boardij - '0'
数独输入中数字以字符形式存储(如 '5'),需减去 '0' 的 ASCII 码值,得到对应的整数 5,才能作为数组下标使用。
3) 时间与空间复杂度
时间复杂度:O(1),固定遍历 9×9=81 个单元格,操作次数恒定;
空间复杂度:O(1),三个标记数组的大小固定,与输入无关。
题目12:解数独(LeetCode 37)
- 题目描述

- 核心知识点:回溯法解数独
算法思路:数独问题的核心是回溯法(暴力剪枝),通过递归尝试所有可能的数字,遇到冲突则回溯,直到找到唯一解。
关键步骤:
1) 预处理标记:用三个二维/三维数组记录每行、每列、每个 3×3 宫已出现的数字,避免重复校验。
rowinum:第 i 行是否已存在数字 num。
coljnum:第 j 列是否已存在数字 num。
gridi//3j//3num:坐标 (i,j) 所在的 3×3 宫是否已存在数字 num。
2) 递归填充:遍历每个空格,尝试填入 1-9,若不冲突则标记并递归下一个空格。
3) 回溯剪枝:若递归失败(后续无合法数字可填),则撤销当前数字,尝试下一个数字。
4) 提前终止:题目仅有一个解,找到合法解后立即终止递归,避免修改已正确的方案。
cpp
#include <vector>
using namespace std;
class Solution {
// 标记数组:记录每行、每列、每个3×3宫的数字是否已存在
bool row[9][10] = {false}; // row[i][num]:第i行是否有数字num
bool col[9][10] = {false}; // col[j][num]:第j列是否有数字num
bool grid[3][3][10] = {false}; // grid[i/3][j/3][num]:对应宫是否有数字num
public:
void solveSudoku(vector<vector<char>>& board) {
// 初始化标记数组:记录初始已填入的数字
for (int i = 0; i < 9; i++) {
for (int j = 0; j < 9; j++) {
if (board[i][j] != '.') {
int num = board[i][j] - '0';
row[i][num] = true;
col[j][num] = true;
grid[i / 3][j / 3][num] = true;
}
}
}
// 开始递归回溯
dfs(board);
}
private:
// 递归函数:尝试填充所有空格,找到解返回true
bool dfs(vector<vector<char>>& board) {
// 遍历整个数独棋盘
for (int i = 0; i < 9; i++) {
for (int j = 0; j < 9; j++) {
// 找到空格,尝试填入数字
if (board[i][j] == '.') {
for (int num = 1; num <= 9; num++) {
// 检查当前数字是否合法(行、列、宫均未出现)
if (!row[i][num] && !col[j][num] && !grid[i / 3][j / 3][num]) {
// 1. 标记当前数字已使用
board[i][j] = '0' + num;
row[i][num] = true;
col[j][num] = true;
grid[i / 3][j / 3][num] = true;
// 2. 递归下一个空格,若找到解则直接返回
if (dfs(board)) {
return true;
}
// 3. 回溯:撤销当前数字,恢复标记
board[i][j] = '.';
row[i][num] = false;
col[j][num] = false;
grid[i / 3][j / 3][num] = false;
}
}
// 所有数字都尝试失败,说明当前分支无解,返回false
return false;
}
}
}
// 所有空格都已填充,找到解,返回true
return true;
}
};- 代码关键细节解析
|--------------------|-------------------------------------------------|
| 关键部分 | 作用说明 |
| 标记数组初始化 | 提前记录初始数字,避免递归中重复遍历行/列/宫校验,提升效率 |
| gridi/3j/3 | 将 9×9 棋盘划分为 3×3 宫,坐标 (i,j) 所在宫的索引为 (i//3, j//3) |
| 递归返回值 bool | 找到解后直接返回 true,终止所有递归,防止解被后续回溯修改 |
| 回溯恢复现场 | 若当前数字后续无解,必须将标记数组和棋盘状态恢复,不影响后续数字尝试 |
题目13:单词搜索(LeetCode 79)
- 题目描述
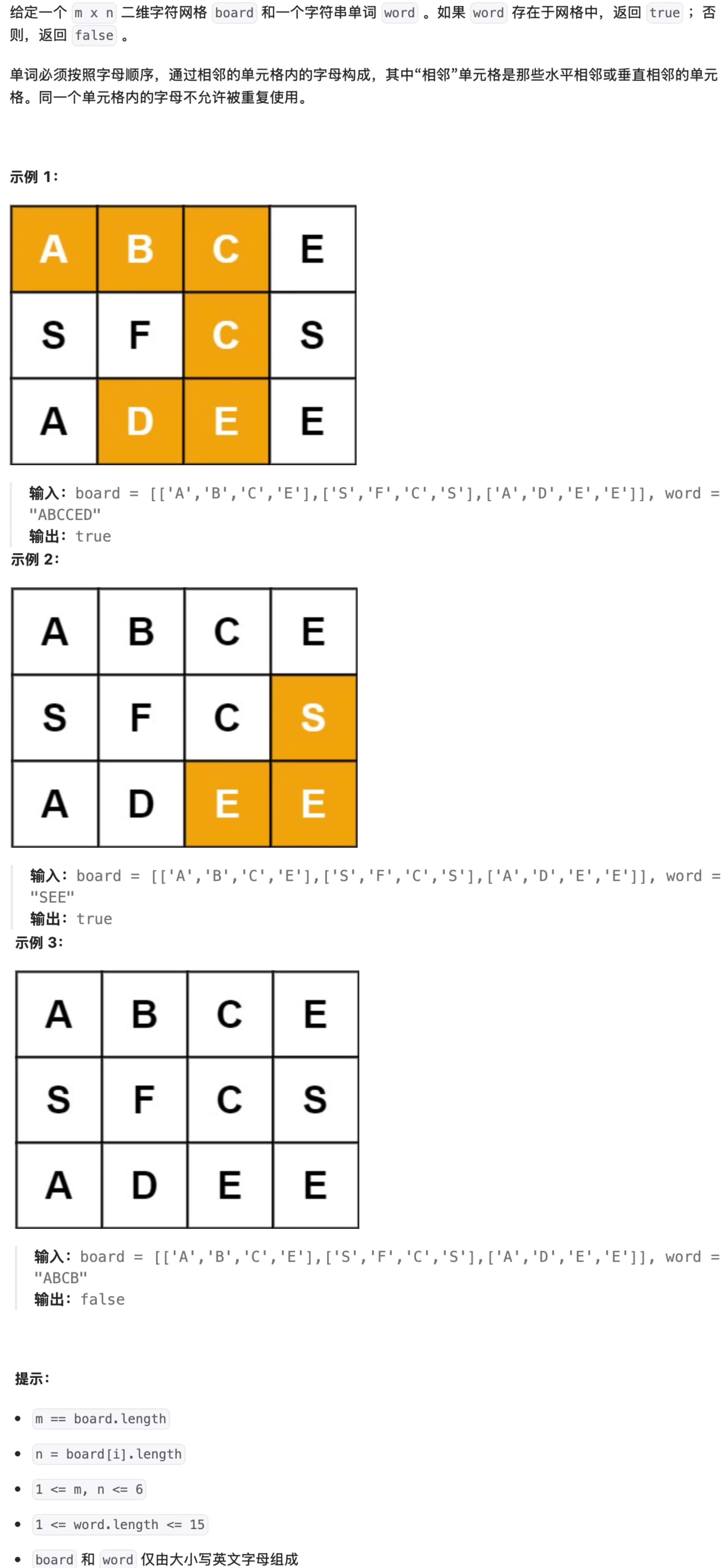
进阶: 你可以使用搜索剪枝的技术来优化解决方案,使其在 board 更大的情况下可以更快解决问题?
- 核心知识点:回溯法(DFS)
1) 算法思路
通过深度优先搜索(DFS)+ 回溯暴力枚举所有可能路径,核心逻辑如下:
-
起点枚举:遍历网格中每个单元格,若单元格字母与 word0 匹配,则以此为起点开始搜索。
-
递归搜索:从当前单元格向上下左右四个方向递归,匹配 word 的下一个字母。
-
路径去重:用标记数组(或修改原网格)记录已访问的单元格,避免重复使用。
-
回溯剪枝:若当前路径无法匹配,撤销标记,尝试其他方向;找到匹配路径后立即终止搜索,避免无效计算。
2) 递归函数设计 bool dfs(int x, int y, int step, vector<vector<char>>& board, string word, vector<vector<bool>>& vis, int &n, int &m, int &len)
参数说明:
x, y:当前正在处理的单元格的横纵坐标。
step:当前已经处理的字母个数(即 word 中已匹配到的下标)。
board:字符网格(引用传递,避免拷贝)。
word:目标单词。
vis:访问标记数组,记录已使用的单元格。
n, m:网格的行数和列数。
len:目标单词的长度。
返回值:bool 类型,表示当前路径是否能匹配完整单词。
函数作用:判断当前坐标的元素作为 wordstep 时,向四个方向传递,查找是否存在与 word 完全匹配的路径。
3) 递归流程
-
起点标记:遍历网格中每个单元格,若 boardij == word0,则标记 visij = true,并调用 dfs 开始递归。
-
终止条件:若 step == word.size(),表示所有字母已匹配,返回 true。
-
方向递归:对当前单元格的上下左右四个相邻位置进行递归:
若相邻位置在网格内、未被访问,且字母与 wordstep 匹配,则标记为已访问,继续递归。
若递归结果为 true,表示找到有效路径,直接返回 true。
-
回溯恢复:若当前方向递归失败,撤销该位置的访问标记,尝试下一个方向。
-
失败返回:若四个方向均递归失败,返回 false。
4) 无标记数组优化(可选)
可以通过修改原网格的方式实现访问标记,无需额外的 vis 数组:
递归时,将当前单元格的字母改为特殊字符(如 '#'),表示已访问。
回溯时,恢复单元格的原始字母,避免影响其他路径。
这种方式可以将空间复杂度从 O(mn) 降为 O(1)(忽略递归栈空间)。
cpp
#include <vector>
#include <string>
using namespace std;
class Solution {
// 上下左右四个方向的偏移量
int dx[4] = {0, 0, -1, 1};
int dy[4] = {1, -1, 0, 0};
int m, n; // 网格的行数和列数
public:
bool exist(vector<vector<char>>& board, string word) {
m = board.size();
n = board[0].size();
// 局部标记数组,每次调用都重置为false
vector<vector<bool>> vis(m, vector<bool>(n, false));
// 遍历所有可能的起点
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (board[i][j] == word[0]) {
vis[i][j] = true;
if (dfs(board, i, j, word, 1, vis)) {
return true;
}
vis[i][j] = false; // 回溯:撤销标记
}
}
}
return false;
}
private:
bool dfs(vector<vector<char>>& board, int i, int j, string& word, int pos, vector<vector<bool>>& vis) {
// 递归终止条件:已匹配所有字母
if (pos == word.size()) {
return true;
}
// 遍历四个方向
for (int k = 0; k < 4; k++) {
int x = i + dx[k];
int y = j + dy[k];
// 边界检查 + 未访问 + 字母匹配
if (x >= 0 && x < m && y >= 0 && y < n && !vis[x][y] && board[x][y] == word[pos]) {
vis[x][y] = true;
if (dfs(board, x, y, word, pos + 1, vis)) {
return true; // 找到有效路径,直接返回
}
vis[x][y] = false; // 回溯:撤销标记
}
}
return false;
}
};- 知识点拓展
- 回溯法核心思想
选择:从当前位置向四个方向选择下一步路径。
约束:不能越界、不能重复访问、字母必须与目标单词匹配。
剪枝:找到有效路径后立即返回,避免无效搜索;若当前路径无法匹配,及时回溯,尝试其他方向。
- 时间复杂度分析
最坏情况:每个单元格作为起点,递归遍历所有可能路径,时间复杂度为 O(m × n × 4^L),其中 L 为目标单词的长度。
优化技巧:提前统计 board 中每个字母的出现次数,若 word 中某个字母的数量超过 board 中的数量,直接返回 false,避免不必要的递归。
- 常见易错点
-
标记数组的初始化:必须使用局部标记数组,或每次调用 exist 时重置全局标记数组,避免残留状态影响结果。
-
回溯的完整性:每次递归返回后,必须撤销当前单元格的访问标记,否则会导致其他路径无法使用该单元格。
-
边界检查的顺序:必须先检查 x, y 是否在网格内,再访问 boardxy,否则会出现数组越界错误。
-
补充:无额外空间版本代码
cpp
class Solution {
int dx[4] = {0, 0, -1, 1};
int dy[4] = {1, -1, 0, 0};
int m, n;
public:
bool exist(vector<vector<char>>& board, string word) {
m = board.size();
n = board[0].size();
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (dfs(board, i, j, word, 0)) {
return true;
}
}
}
return false;
}
private:
bool dfs(vector<vector<char>>& board, int i, int j, string& word, int pos) {
// 边界或字母不匹配,直接返回false
if (i < 0 || i >= m || j < 0 || j >= n || board[i][j] != word[pos]) {
return false;
}
// 已匹配所有字母,返回true
if (pos == word.size() - 1) {
return true;
}
// 标记当前单元格为已访问
char temp = board[i][j];
board[i][j] = '#';
// 向四个方向递归
bool found = dfs(board, i+1, j, word, pos+1) ||
dfs(board, i-1, j, word, pos+1) ||
dfs(board, i, j+1, word, pos+1) ||
dfs(board, i, j-1, word, pos+1);
// 回溯:恢复单元格原始字母
board[i][j] = temp;
return found;
}
};题目14:黄金矿工(LeetCode 1219)
- 题目描述

提示:
1 <= grid.length, grid[i].length <= 150 <= grid[i][j] <= 100- 最多 25个单元格中有黄金。
- 核心知识点:回溯法(DFS)
1) 算法思路
本题是典型的网格路径型回溯问题,核心思路是:
-
枚举起点:遍历网格中所有非0单元格,以每个单元格作为起点开始深度优先搜索。
-
递归搜索:从当前单元格向上下左右四个方向递归,收集黄金并记录路径和。
-
路径去重:用标记数组 vis 记录已访问的单元格,避免重复开采。
-
回溯剪枝:每次递归返回后,撤销当前单元格的访问标记,尝试其他方向;同时更新全局最大黄金数。
2) 递归函数设计 void dfs(vector<vector<int>>& g, int i, int j, int path)
参数说明:
g:黄金网格(引用传递,避免拷贝)。
i, j:当前正在开采的单元格坐标。
path:当前路径已收集的黄金总数。
函数作用:从当前单元格出发,向四个方向递归,更新全局最大黄金数。
3) 递归流程
-
更新最大值:每次进入单元格时,先将当前路径和 path 与全局最大值 ret 比较,更新最大值。
-
方向递归:对当前单元格的上下左右四个相邻位置进行递归:
若相邻位置在网格内、未被访问,且黄金数不为0,则标记为已访问,继续递归。
递归时将路径和更新为 path + gxy,即加上下一个单元格的黄金数。
- 回溯恢复:若当前方向递归结束,撤销该位置的访问标记,尝试下一个方向。
cpp
#include <vector>
#include <algorithm>
using namespace std;
class Solution {
bool vis[16][16]; // 访问标记数组,记录已开采的单元格
int dx[4] = {0, 0, 1, -1}; // 上下左右四个方向的偏移量
int dy[4] = {1, -1, 0, 0};
int m, n; // 网格的行数和列数
int ret = 0; // 全局最大黄金数
public:
int getMaximumGold(vector<vector<int>>& grid) {
m = grid.size();
n = grid[0].size();
ret = 0; // 初始化最大值为0
// 遍历所有非0单元格作为起点
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (grid[i][j] != 0) {
vis[i][j] = true;
dfs(grid, i, j, grid[i][j]);
vis[i][j] = false; // 回溯:撤销标记
}
}
}
return ret;
}
private:
void dfs(vector<vector<int>>& g, int i, int j, int path) {
// 更新全局最大黄金数
ret = max(ret, path);
// 遍历四个方向
for (int k = 0; k < 4; k++) {
int x = i + dx[k];
int y = j + dy[k];
// 边界检查 + 未访问 + 黄金数不为0
if (x >= 0 && x < m && y >= 0 && y < n && !vis[x][y] && g[x][y] != 0) {
vis[x][y] = true;
dfs(g, x, y, path + g[x][y]);
vis[x][y] = false; // 回溯:撤销标记
}
}
}
};4) 关键细节解析
|----------------------|----------------------------------------------|
| 关键部分 | 作用说明 |
| vis1616 | 标记已访问的单元格,避免重复开采;因网格最大为 15×15,故数组大小设为 16×16。 |
| dx4, dy4 | 定义上下左右四个方向的偏移量,简化方向遍历代码。 |
| ret = max(ret, path) | 每次进入单元格时更新最大值,确保所有路径的黄金数都被统计。 |
| 回溯标记 | 递归前后对 vis 数组的标记与撤销,是保证路径正确的核心。 |
- 知识点拓展
1) 回溯法核心思想
选择:从当前位置向四个方向选择下一步路径。
约束:不能越界、不能重复访问、不能进入黄金数为0的单元格。
剪枝:题目无提前终止条件,需遍历所有可能路径,但通过回溯避免无效计算。
2) 时间复杂度分析
最坏情况:每个非0单元格作为起点,递归遍历所有可能路径,时间复杂度为 O(k × 4^k),其中 k 为非0单元格的数量(最多25个)。
优化点:题目中 k ≤ 25,且每个路径最多访问 k 个单元格,因此暴力回溯可通过。
3) 无标记数组优化(可选)
可以通过修改原网格的方式实现访问标记,无需额外的 vis 数组:
递归时,将当前单元格的黄金数改为 0,表示已开采。
回溯时,恢复单元格的原始黄金数,避免影响其他路径。
这种方式可以将空间复杂度从 O(mn) 降为 O(1)(忽略递归栈空间)。
优化版代码片段
cpp
void dfs(vector<vector<int>>& g, int i, int j, int path) {
ret = max(ret, path);
int temp = g[i][j];
g[i][j] = 0; // 标记为已开采
for (int k = 0; k < 4; k++) {
int x = i + dx[k], y = j + dy[k];
if (x >= 0 && x < m && y >= 0 && y < n && g[x][y] != 0) {
dfs(g, x, y, path + g[x][y]);
}
}
g[i][j] = temp; // 回溯:恢复黄金数
}题目15:不同路径 III(LeetCode 980)
- 题目描述

- 核心知识点:回溯法(DFS)
1) 算法思路
本题是典型的强制遍历所有节点的网格回溯问题,核心逻辑如下:
-
预处理:遍历网格,统计无障碍方格(包括起点1、终点2)的总数 step,同时记录起点坐标。
-
递归搜索:从起点开始,向上下左右四个方向递归,标记已访问的方格。
-
终止条件:当到达终点2时,若已访问的方格数等于 step,则路径合法,计数+1。
-
回溯剪枝:递归返回后,撤销当前方格的访问标记,尝试其他方向。
2) 递归函数设计 void dfs(vector<vector<int>>& grid, int i, int j, int count)
参数说明:
grid:网格(引用传递,避免拷贝)。
i, j:当前所在方格的坐标。
count:当前已访问的方格数(包括起点)。
函数作用:从当前方格出发,向四个方向递归,统计所有合法路径数目。
3) 递归流程
-
终止判断:若当前方格是终点2,且 count == step(已访问所有无障碍方格),则路径合法,ret++。
-
方向遍历:对当前方格的上下左右四个相邻位置进行递归:
若相邻位置在网格内、未被访问,且不是障碍(gridxy != -1),则标记为已访问,继续递归。
递归时将已访问计数更新为 count + 1。
- 回溯恢复:若当前方向递归结束,撤销该位置的访问标记,尝试下一个方向。
cpp
#include <vector>
using namespace std;
class Solution {
bool vis[21][21]; // 访问标记数组,最大网格为20×20
int dx[4] = {1, -1, 0, 0}; // 上下左右四个方向的偏移量
int dy[4] = {0, 0, 1, -1};
int m, n; // 网格的行数和列数
int ret = 0; // 合法路径总数
int step = 0; // 无障碍方格总数(包括起点、终点)
public:
int uniquePathsIII(vector<vector<int>>& grid) {
m = grid.size();
n = grid[0].size();
ret = 0;
step = 0;
int bx = 0, by = 0; // 记录起点坐标
// 预处理:统计无障碍方格数,找到起点
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (grid[i][j] == 0) {
step++;
} else if (grid[i][j] == 1) {
bx = i;
by = j;
}
}
}
// 加上起点和终点,总步数+2
step += 2;
// 标记起点为已访问,开始递归
vis[bx][by] = true;
dfs(grid, bx, by, 1);
return ret;
}
private:
void dfs(vector<vector<int>>& grid, int i, int j, int count) {
// 终止条件:到达终点,且已访问所有无障碍方格
if (grid[i][j] == 2) {
if (count == step) {
ret++;
}
return;
}
// 遍历四个方向
for (int k = 0; k < 4; k++) {
int x = i + dx[k];
int y = j + dy[k];
// 边界检查 + 未访问 + 不是障碍
if (x >= 0 && x < m && y >= 0 && y < n && !vis[x][y] && grid[x][y] != -1) {
vis[x][y] = true;
dfs(grid, x, y, count + 1);
vis[x][y] = false; // 回溯:撤销标记
}
}
}
};4) 关键细节解析
|-----------------|-------------------------------------------|
| 关键部分 | 作用说明 |
| step += 2 | 统计无障碍方格数时,0的数量+起点1和终点2,得到总需访问的方格数。 |
| vis2121 | 标记已访问的方格,避免重复通过;因网格最大为20×20,故数组大小设为21×21。 |
| count == step | 路径合法的核心条件:到达终点时,必须已访问所有无障碍方格。 |
| 回溯标记 | 递归前后对 vis 数组的标记与撤销,是保证路径不重复的关键。 |
- 知识点拓展
1) 回溯法核心思想
选择:从当前位置向四个方向选择下一步路径。
约束:不能越界、不能重复访问、不能进入障碍方格。
剪枝:到达终点时,必须已访问所有无障碍方格,否则直接返回,避免无效搜索。
2) 时间复杂度分析
最坏情况:每个无障碍方格都有4个方向选择,时间复杂度为 O(4^k),其中 k 为无障碍方格总数(最多20个)。
优化点:题目中 k ≤ 20,且路径必须经过所有方格,因此暴力回溯可通过。
3) 易错点总结
-
步数统计错误:总步数必须包括起点和终点,否则会导致合法路径计数为0。
-
回溯标记遗漏:每次递归返回后,必须撤销当前方格的访问标记,否则会导致其他路径无法通过该方格。
-
终止条件错误:到达终点时,未判断是否已访问所有无障碍方格,会导致错误计数。