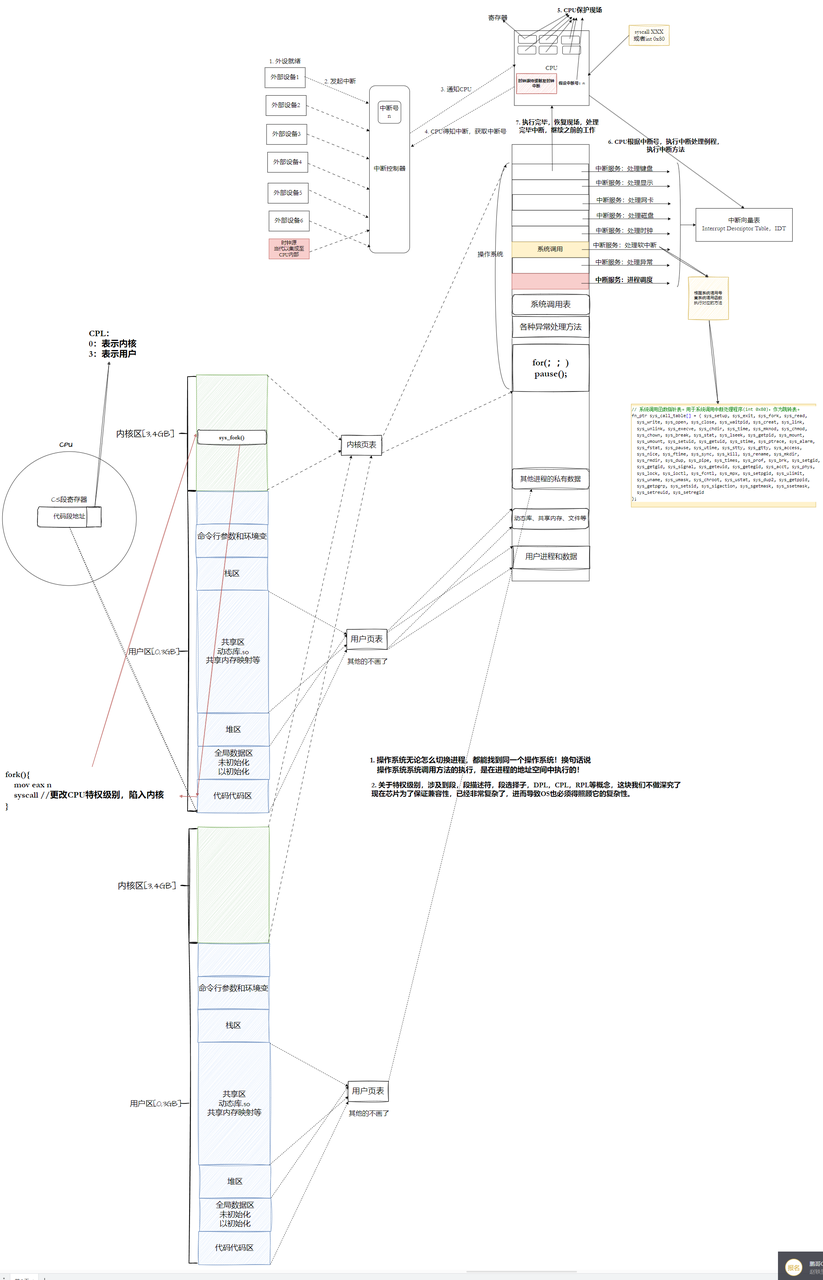
一、虚拟地址空间
注:1、进程的所有函数调用都是在自己的虚拟地址空间内完成的。
2、每一个进程有自己的一套用户级页表,但是内核级页表只有一份。
3、进程在任何时候进行调度的时候,想找到OS,随时可以找到。
cs
cscode ,准确的名字叫 CS(Code Segment,代码段寄存器)。
CPU 内部有很多寄存器(用来存数据的、存地址的),而 CS 是一个非常特殊的寄存器,它的作用是:告诉 CPU,当前正在执行的代码,存放在内存的哪个区域。
CPL
CPL 的全称是 Current Privilege Level(当前特权级)。
这就是我们在前面说的"Ring 0"和"Ring 3"在 CPU 硬件层面的真正载体!
这里有一个非常硬核的细节:CPU 内部其实并没有一个单独叫"CPL寄存器"的东西。CPL 是寄生在 CS 寄存器里面的!
以下为AI生成:
0 和 3 到底代表什么?
Intel 在设计 x86 架构 CPU 时,设计了一个**"保护环"**模型,分了 4 个级别(这就是著名的 Ring 0 ~ Ring 3):
- Ring 0(CPL = 0):最高特权级,内核态。
- 拥有对一切硬件(内存、硬盘、网卡)的绝对控制权。
- 操作系统的核心代码(进程管理、内存管理、驱动程序)都在这个级别运行。
- Ring 1 和 Ring 2(CPL = 1, 2):中间特权级。
- Intel 原本设想把这些级别留给设备驱动程序或者一些特殊的服务,这样即使驱动崩溃了,内核也不会挂。
- 但是! 现代操作系统(Windows、Linux、macOS)觉得这么搞太复杂了,为了简化设计和提高性能,直接把 Ring 1 和 2 废弃不用了。
- Ring 3(CPL = 3):最低特权级,用户态。
- 普通的应用程序(微信、浏览器、你写的 C 代码)全都在这个级别运行。
- 被严格限制,不能直接碰硬件,不能访问内核区的内存
1、什么是 CPL?
在 x86 架构中,CPL(Current Privilege Level,当前特权级) 是存放在 CS(代码段)寄存器中的最低两位。CPL = 0 代表最高特权级(内核态),CPL = 3 代表最低特权级(用户态)。(1和2在现代操作系统中基本不用)
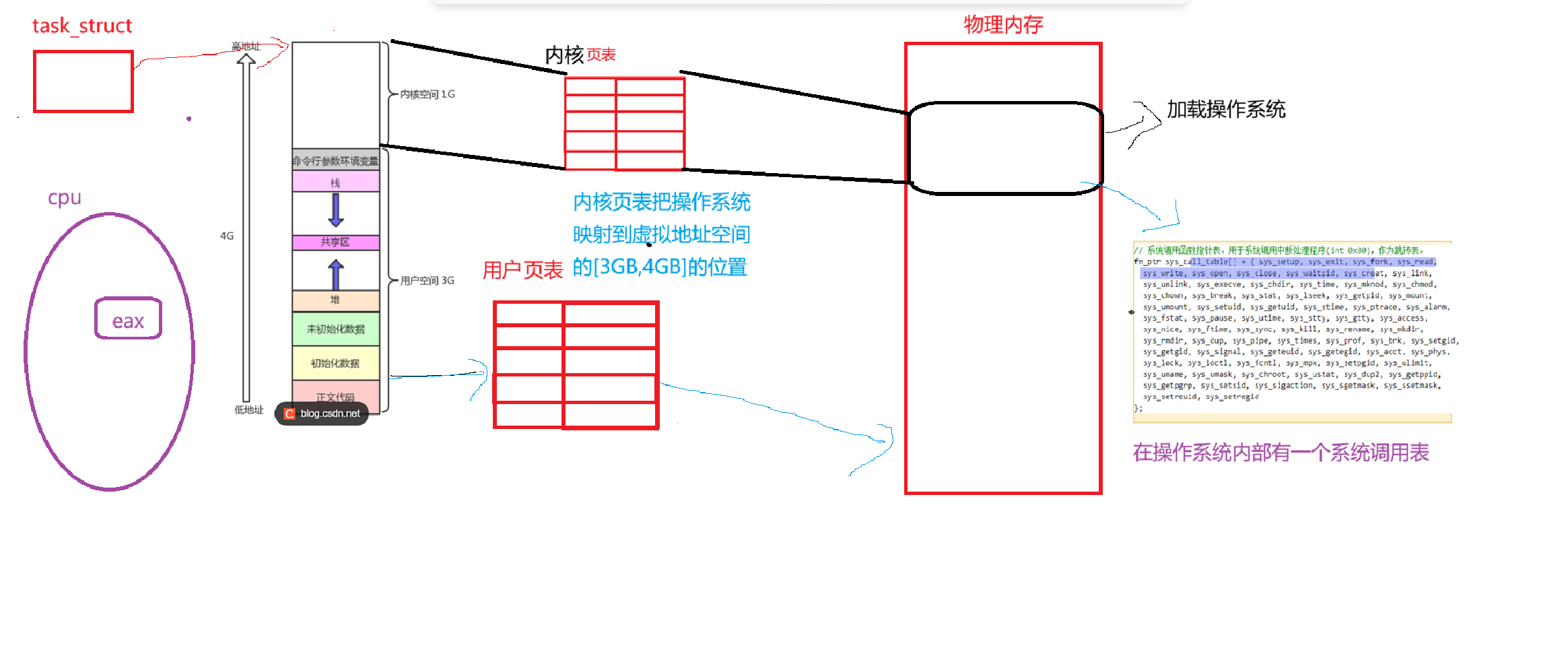
2、页表项(PTE)里存的是什么?
页表映射条目(PTE)里并没有直接存一个0或3这样的特权级数字。它存的是标志位,最核心的是 U/S 位(User/Supervisor bit,第2位)。U/S = 0 代表 Supervisor(超级用户/内核态),只有特权级高于 2 的(也就是 CPL=0,1,2)才能访问。U/S = 1 代表 User(用户态),所有特权级(CPL=0,1,2,3)都可以访问。
3、MMU 真正的对比逻辑是怎样的?
MMU 在进行地址翻译时,硬件电路会自动执行类似下面这样的逻辑判断(而不是判断相等):
如果 CPL 小于等于 2(即在内核态),不管页表的 U/S 是 0 还是 1,一律放行。内核可以访问内核空间,也可以访问用户空间。
如果 CPL 等于 3(即在用户态),MMU 去检查页表的 U/S 位。如果 U/S = 1,放行(用户访问用户空间)。如果 U/S = 0,触发页错误!这也就是为什么用户程序不能直接读写内核内存的原因。
- 发起调用前(用户态):程序在用户态跑,CPL = 3。如果此时代码试图访问 U/S=0 的内核内存,MMU 瞬间报错。
- 发生系统调用(例如 int 0x80 或 syscall 指令):CPU 硬件开始工作,把当前 CS 寄存器里的 CPL 从 3 改写成 0,并跳转到内核代码。此时进入了内核态。
- 内核执行中(核心点):此时 CPL 已经是 0 了。内核代码如果需要读取用户传进来的指针(比如 read(fd, user_buf, size) 中的 user_buf),MMU 会拿着现在的 CPL=0 去查 user_buf 对应的页表项。因为 user_buf 的 U/S=1,而 CPL=0 满足 CPL小于等于2 的条件,所以 MMU 允许内核读写这块用户内存。
- 返回用户态:系统调用结束,执行 iret 或 sysret 指令,CPU 硬件把 CPL 从 0 改回 3。
进行系统调用的步骤
- 放编号与参数: 程序把要调用的功能"编号"放进专用寄存器(如 x86 的
rax),把参数放进其他通用寄存器。 - 触发陷阱: 程序执行
syscall指令,CPU 硬件强行将权限从"用户态"提升为"内核态"。 - 内核查表: 内核代码接管,直接拿出那个专用寄存器里的"编号",去内核中那张巨大的函数指针数组(
sys_call_table)里当索引查表,找到对应的真正内核函数。 - 执行并返回结果: 执行该内核函数,把执行结果再次塞回寄存器。
- 切回用户态: 执行返回指令,CPU 权限降级回"用户态",你的程序从寄存器里拿出结果,继续执行下一行代码。
在Linux中,会存在很多地方需要进行权限管理,用户态和内核态,需要硬件支持。
用户态和内核态是CPU的两种执行级别。
CPL 定身份(我现在是谁),U/S 定页归属;用户态要比对,内核态随便过。
例如:
当前 CPL = 3(我在用户态)
MMU 拿 CPL=3 和 U/S 比对:
- 若 U/S = 1 → 匹配允许,正常访问
- 若 U/S = 0 → 不匹配,直接抛页故障,禁止访问
当前 CPL = 0(我在内核态)
MMU 直接不严格比对 U/S 不管 U/S 是 0 还是 1,全都放行内核谁的内存都能访问。
捕捉信号
sigaction
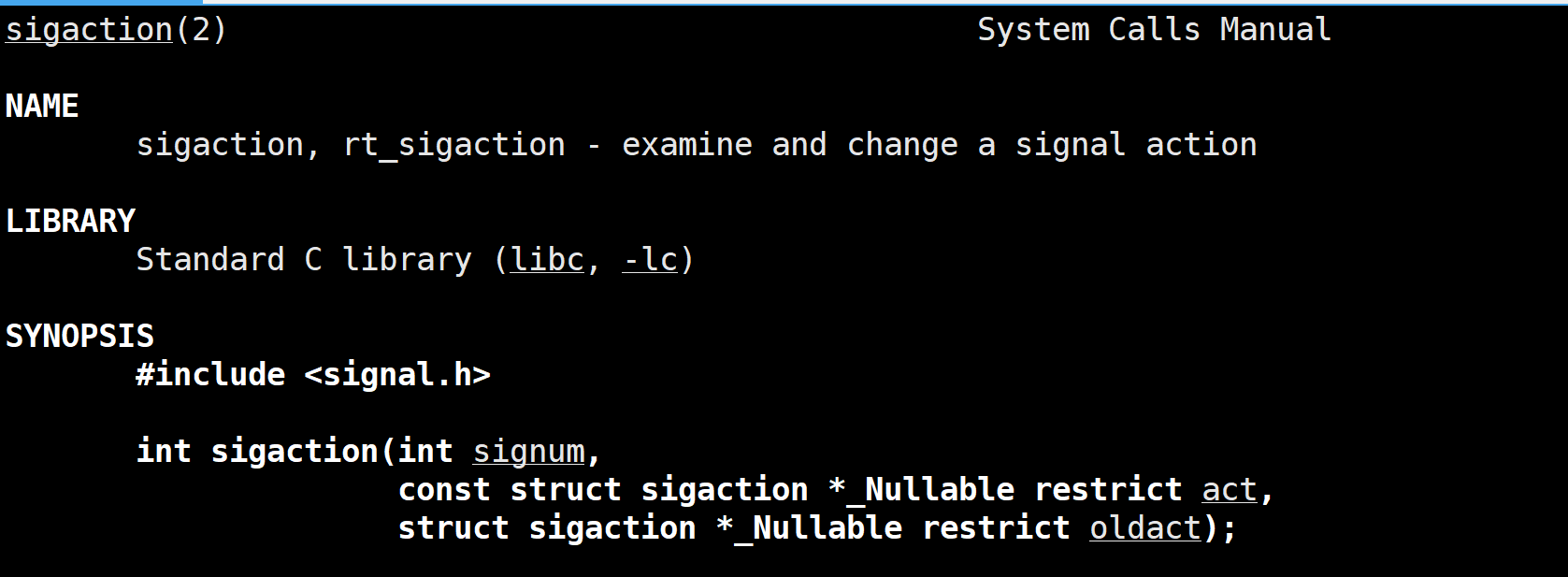
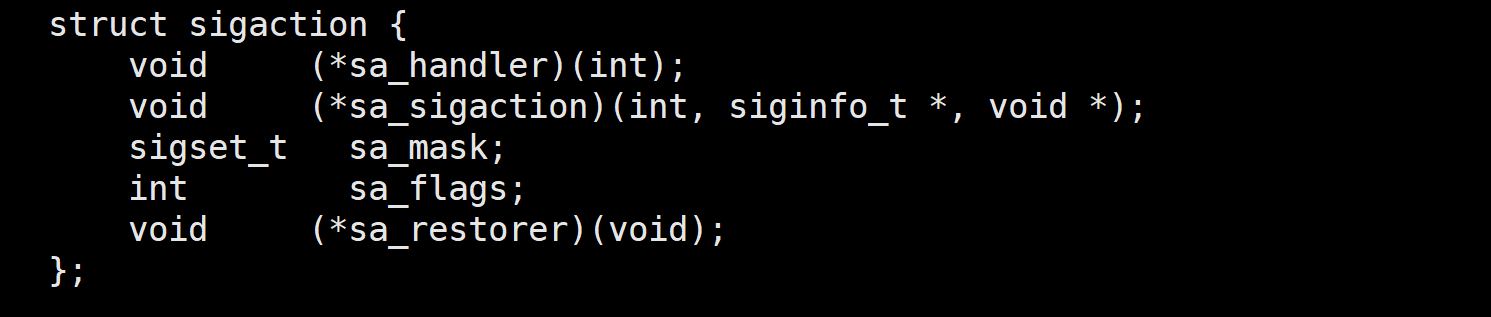
当某一个信号的处理函数被调用时,内核自动将该信号加入进程的信号屏蔽字,并同时屏sa_mask字段中指定的信号集合,直到信号处理函数执行完毕后再恢复原信号屏蔽状态。
可重入函数
它不满足可重入函数的核心要求,原因有两点:
- 读写了全局共享变量
head两个独立的调用(主线程的insert(&node1)和信号处理函数的insert(&node2))都修改同一个全局变量head,且操作不是原子的。 - 函数执行可以被打断并交错执行 主线程执行到
p->next = head时,被信号打断,信号处理函数里的insert又执行了一遍p->next = head和head = p,再回到主线程继续执行head = p,就会把信号处理函数的修改覆盖掉。
这正是不可重入函数的典型后果:并发调用导致数据丢失 / 错乱。
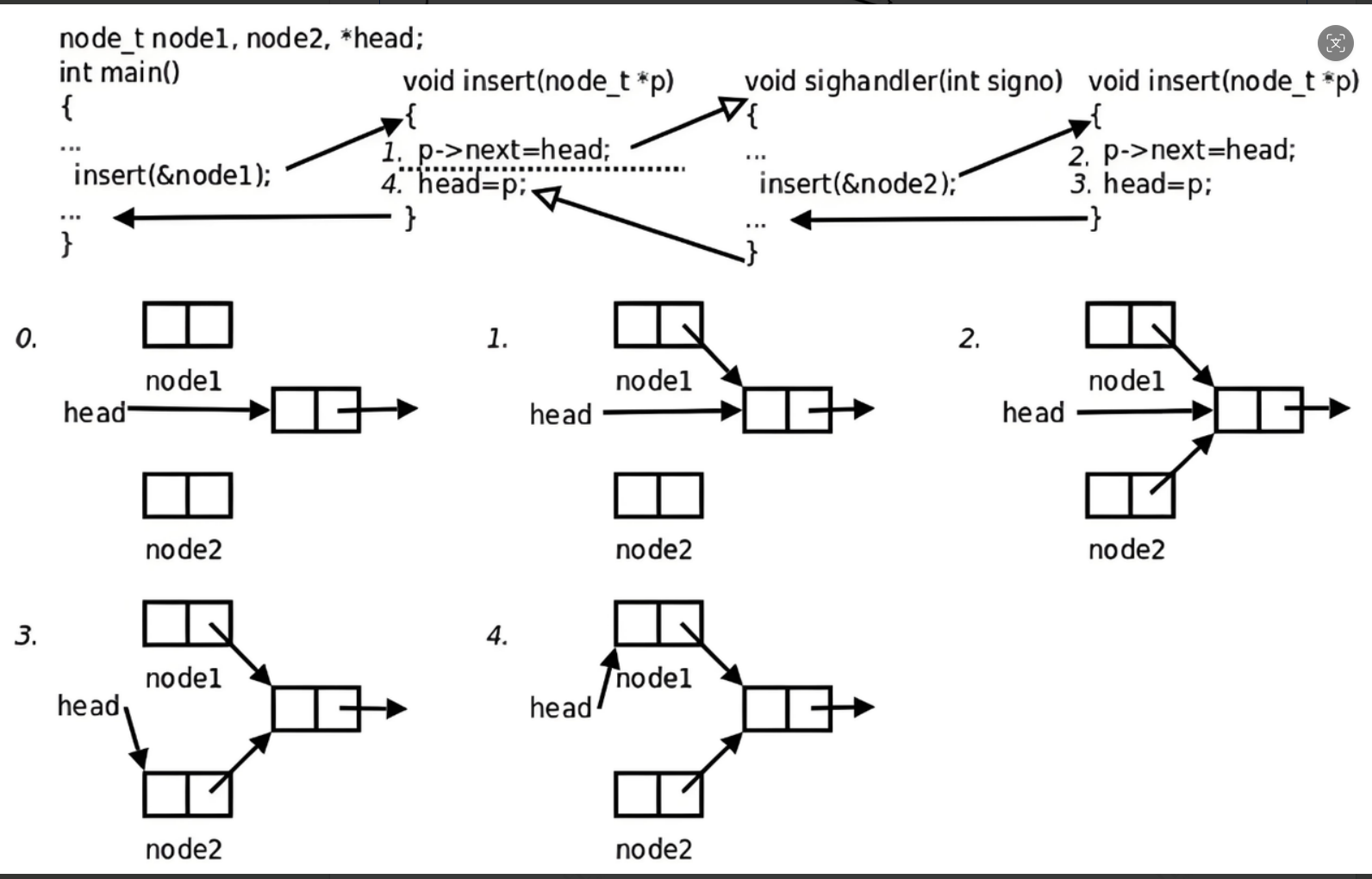
如果函数符合以下条件之一,则是不可重入的:
调用了malloc或free,因为malloc也是用全局链表来管理堆的。
调用了标准I/O库函数。标准I/O库的很多实现都以不可重入的方法使用全局数据结构。
总结:
重入 = 函数跑到一半,没跑完
突然被打断 ,又从头再调用一次这个函数。
不是退出,是:旧的一次还没结束,又新开了一次调用。
volatile
volatile 告诉编译器:这个变量别优化,每次都老老实实从内存读,别放寄存器缓存。
为啥要有 volatile?
编译器会自作聪明优化代码 :一个变量如果反复用,编译器会把它放到 CPU 寄存器 里,不再每次去内存读,速度快。
但问题来了:
- 中断、信号、多线程 会偷偷改内存里的变量
- 可寄存器里还是旧值,程序永远看不到变化,卡死、逻辑错乱
volatile 就是强制:每次必须从原始内存读取,不许缓存、不许优化。
volatile 三大使用场景
- 中断 / 信号 共享全局变量(上图那张链表那张图就属于这种场景)
- 多线程共享变量
- 硬件寄存器地址(外设寄存器随时自己变,必须 volatile)
SIGCHLD信号
父进程创建子进程,如果子进程退出,子进程是安静的退出吗?
子进程退出的时候,会向父进程发送SIGCHLD信号。
- 子进程退出 必然发送 SIGCHLD 给父进程,不是安静退出;
- 父进程默认 忽略 SIGCHLD ,导致僵尸进程;
- 捕获
SIGCHLD+wait/waitpid= 异步回收子进程,消灭僵尸。