注:以下习题参考 计算机网络(第八版)谢希仁 编著,数据结构与算法 王曙燕 主编。
一、计算机网络习题与解答
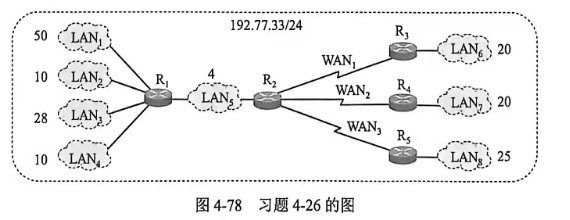
4-26 一个大公司有一个总部和三个下属部门。公司分配到的网络前缀是 192.77.33/24。公司的网络布局如图 4-78 所示。总部共有 5 个局域网,其中的 LAN₁ ~ LAN₄ 都连接到路由器 R₁ 上,R₁ 再通过 LAN₅ 与路由器 R₂ 相连。R₂ 和远地的三个部门的局域网 LAN₆ ~ LAN₈ 通过广域网相连。每一个局域网旁边标明的数字是局域网上的主机数。试给每一个局域网分配一个合适的网络前缀。
答案:
本题解答有很多种,下面是其中一种答案(先选择需求较大的网络前缀):
| 网络 | 地址块 | 前缀 |
|---|---|---|
| LAN₁ | 192.77.33.0/26 | /26 |
| LAN₃ | 192.77.33.64/27 | /27 |
| LAN₆ | 192.77.33.96/27 | /27 |
| LAN₇ | 192.77.33.128/27 | /27 |
| LAN₈ | 192.77.33.160/27 | /27 |
| LAN₂ | 192.77.33.192/28 | /28 |
| LAN₄ | 192.77.33.208/28 | /28 |
| LAN₅ | 192.77.33.224/29 | /29 |
| WAN₁ | 192.77.33.232/30 | /30 |
| WAN₂ | 192.77.33.236/30 | /30 |
| WAN₃ | 192.77.33.240/30 | /30 |
4-27 以下地址中的哪一个和 86.32/12 匹配?请说明理由。
(1) 86.33.224.123; (2) 86.79.65.216; (3) 86.58.119.74; (4) 86.68.206.154。
答案:
-
86.32/12 的前 12 位:86 的二进制 01010110,32 的二进制 00100000,前 12 位为 01010110 0010
-
第二字节的前 4 位在前缀中
-
各地址第二字节的前 4 位:
-
(1) 33 → 0010 0001 → 前4位 0010 符合
-
(2) 79 → 0100 1111 → 前4位 0100
-
(3) 58 → 0011 1010 → 前4位 0011
-
(4) 68 → 0100 0100 → 前4位 0100
-
答案:(1) 86.33.224.123
4-28 以下地址前缀中的哪一个与地址 2.52.90.140 匹配?请说明理由。
(1) 0/4; (2) 32/4; (3) 4/6; (4) 80/4。
答案:
-
2.52.90.140 的第一字节:2 → 00000010
-
4 位掩码:
-
(1) 0/4:0 → 00000000,前4位 0000,匹配
-
(2) 32/4:32 → 00100000,前4位 0010
-
(3) 4/6:6位掩码,4 → 00000100,前6位 000001,2 的前6位 000000
-
(4) 80/4:80 → 01010000,前4位 0101
-
答案:(1) 0/4
4-29 下面前缀中的哪一个和地址 152.7.77.159 及 152.31.47.252 都匹配?请说明理由。
(1) 152.40/13; (2) 153.40/9; (3) 152.64/12; (4) 152.00/11。
答案:
-
152.7.77.159:152 = 10011000,7 = 00000111
-
152.31.47.252:152 = 10011000,31 = 00011111
-
需要同时匹配两个地址,前11位相同:
-
152 = 10011000
-
7 = 00000111 → 前3位 000
-
31 = 00011111 → 前3位 000
-
前11位为 10011000 000
-
-
(4) 152.00/11:152.0.0.0 的前11位为 10011000 000 匹配
答案:(4) 152.00/11
4-30 与下列掩码相对应的网络前缀各有多少位?
(1) 192.0.0.0; (2) 240.0.0.0; (3) 255.224.0.0; (4) 255.255.255.252。
答案:
| 掩码 | 二进制 | 前缀长度 |
|---|---|---|
| 192.0.0.0 | 11000000 00000000 00000000 00000000 | /2 |
| 240.0.0.0 | 11110000 00000000 00000000 00000000 | /4 |
| 255.224.0.0 | 11111111 11100000 00000000 00000000 | /11 |
| 255.255.255.252 | 11111111 11111111 11111111 11111100 | /30 |
答案:(1) /2; (2) /4; (3) /11; (4) /30
4-31 已知地址块中的一个地址是 140.120.84.24/20。试求这个地址块中的最小地址和最大地址。地址掩码是什么?地址块中共有多少个地址?相当于多少个 C 类地址?
答案:
-
地址掩码:255.255.240.0
-
最小地址:140.120.80.0/20
-
最大地址:140.120.95.255/20
-
地址数:2^(32-20) = 2^12 = 4096
-
C 类地址有 256 个地址,4096 / 256 = 16
答案:最小地址 140.120.80.0/20,最大地址 140.120.95.255/20,地址数 4096,相当于 16 个 C 类地址
4-32 已知地址块中的一个地址是 190.87.140.202/29。重新计算上述题。
答案:
-
地址掩码:255.255.255.248
-
最小地址:190.87.140.200/29
-
最大地址:190.87.140.207/29
-
地址数:2^(32-29) = 2^3 = 8
-
相当于 8/256 = 1/32 个 C 类地址
答案:最小地址 190.87.140.200/29,最大地址 190.87.140.207/29,地址数 8,相当于 1/32 个 C 类地址
4-33 某单位分配到一个地址块 136.23.12.64/26。现在需要进一步划分为 4 个一样大的子网。试问:
(1) 每个子网的网络前缀有多少长?
(2) 每一个子网中有多少个地址?
(3) 每一个子网的地址块是什么?
(4) 每一个子网可分配给主机使用的最大地址和最小地址是什么?
答案:
(1) 4 个子网需要 2 位,前缀长度 = 26 + 2 = /28
(2) 地址数 = 2^(32-28) = 16
(3) 四个子网的地址块:
-
136.23.12.64/28
-
136.23.12.80/28
-
136.23.12.96/28
-
136.23.12.112/28
(4) 每个子网可分配的最小/最大地址:
| 子网 | 地址块 | 最小地址 | 最大地址 |
|---|---|---|---|
| 1 | 136.23.12.64/28 | 136.23.12.65 | 136.23.12.78 |
| 2 | 136.23.12.80/28 | 136.23.12.81 | 136.23.12.94 |
| 3 | 136.23.12.96/28 | 136.23.12.97 | 136.23.12.110 |
| 4 | 136.23.12.112/28 | 136.23.12.113 | 136.23.12.126 |
4-34 IGP 和 EGP 这两类协议的主要区别是什么?
答案:
| IGP(内部网关协议) | EGP(外部网关协议) | |
|---|---|---|
| 使用范围 | 自治系统内部 | 自治系统之间 |
| 路由目标 | 发现和计算内部路由 | 在 AS 之间交换路由可达信息 |
| 典型代表 | RIP、OSPF | BGP |
| 与 AS 关系 | 与 AS 内部拓扑强相关 | 策略性路由,与拓扑弱相关 |
4-35 试简述 RIP、OSPF 和 BGP 路由选择协议的主要特点。
答案:
| 协议 | 特点 |
|---|---|
| RIP | 距离向量算法,以跳数为度量,最大跳数15,周期性广播,适用于中小型网络 |
| OSPF | 链路状态算法,使用洪泛法,收敛快,支持分层区域,适用于大型网络 |
| BGP | 路径向量算法,策略路由,用于 AS 之间,使用 TCP 传送 |
4-36 RIP 使用 UDP,OSPF 使用 IP,而 BGP 使用 TCP。这样做有何优点?为什么 RIP 周期性地和邻站交换路由信息而 BGP 却不这样做?
答案:
优点:
-
RIP 使用 UDP:UDP 开销小,可以满足 RIP 定期交换的要求
-
OSPF 直接使用 IP:灵活性好,开销更小
-
BGP 使用 TCP:需要交换整个路由表,TCP 保证可靠交付,减少带宽消耗
RIP 周期性交换 vs BGP 不周期性交换:
-
RIP 使用不保证可靠交付的 UDP,必须周期性地和邻站交换信息才能使路由信息及时更新
-
BGP 使用保证可靠交付的 TCP,不需要周期性交换
4-37 假定网络中的路由器 B 的路由表有如下项目:
| 目的网络 | 距离 | 下一跳路由器 |
|---|---|---|
| N₁ | 7 | A |
| N₂ | 2 | C |
| N₆ | 8 | F |
| N₈ | 4 | E |
| N₉ | 4 | F |
现在 B 收到从 C 发来的路由信息(目的网络、距离):
-
N₂:4
-
N₃:8
-
N₆:4
-
N₈:3
-
N₉:5
试求出路由器 B 更新后的路由表(详细说明每一个步骤)。
答案:
更新后的路由表:
| 目的网络 | 距离 | 下一跳 | 操作 |
|---|---|---|---|
| N₁ | 7 | A | 不变 |
| N₂ | 5 | C | 相同的下一跳,更新 |
| N₃ | 9 | F | 新的下一跳,添加 |
| N₆ | 5 | E | 不同的下一跳,距离更短,更新 |
| N₈ | 4 | F | 不同的下一跳,距离一样,不变 |
| N₉ | 4 | 无 | 不同的下一跳,距离更大,不变 |
4-38 网络如图 4-79 所示。假定 AS,和 AS:运行协议 RIP,AS,和 AS,运行协议 OSPF。AS之间运行协议 eBGP和 iBGP。目前先假定在 AS,和 AS,之间没有物理连接(图中的虚线表示这个假定)。
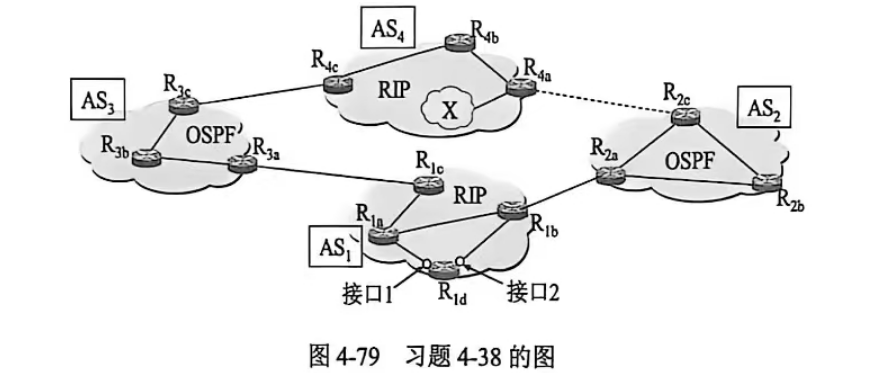
(1)路由器 R₃c使用哪一个协议知道前缀X(X在 AS 中)?
(2)路由器 R₃a使用哪一个协议知道前缀X?
(3)路由器 R₁c使用哪一个协议知道前缀X?
(4)路由器R₁d使用哪一个协议知道前缀X?
答案:
(1) 路由器 R₃c 使用 eBGP 知道前缀 X
(2) 路由器 R₃a 使用 iBGP 知道前缀 X
(3) 路由器 R₁c 使用 eBGP 知道前缀 X
(4) 路由器 R₁d 使用 iBGP 知道前缀 X
4-39 网络同上题。路由器 R 知道前缀X,并将前缀X写入转发表。
(1)试问路由器Ri应当从接口1还是接口2转发分组呢?请简述理由。
(2)现假定 AS和 AS4之间有物理连接,即图中的虚线变成了实线。假定路由器 R知道到达前缀 X 可以经过 AS,,但也可以经过 AS;。试问路由器 R应当从接口1还是接口2转发分组呢?请简述理由。
(3)现假定有另一个 ASs处在 AS,和 AS之间(图中的虚线之间未画出 AS)。假定路由器 R知道到达前缀X可以经过路由ASASSAS4,但也可以经过路由AS;ASA。试问路由器 Ru应当从接口1还是接口2转发分组呢?请简述理由。
答案:
(1) 从接口 1 转发(路径更短)
(2) 从接口 2 转发(经过 AS₂ 更优)
(3) 从接口 1 转发(经过 AS₃ 更优)
4-40 IGMP 协议的要点是什么?隧道技术在多播中是怎样使用的?
答案:
IGMP(互联网组管理协议)的要点:
-
作用:IGMP 用于主机和本地多播路由器之间,报告多播组成员关系。
-
报文类型:
-
成员报告:主机加入多播组时发送,表示要接收该组的多播数据。
-
成员查询:多播路由器定期发送,询问网段内哪些组还有成员。
-
离开报告:主机主动离开多播组时发送(可选)。
-
-
工作过程:
-
主机加入多播组时,向路由器发送成员报告。
-
路由器定期发送查询报文,主机收到后随机延迟回送报告,避免拥塞。
-
若某组没有主机响应,路由器认为该组无成员,停止转发。
-
-
版本:IGMPv1(基本)、IGMPv2(支持离开)、IGMPv3(支持源过滤)。
隧道技术在多播中的使用:
-
问题:当多播数据报需要穿越不支持多播的网络(如Internet)时,普通路由器会丢弃多播包。
-
解决方案 :封装隧道(IP-in-IP 封装)
-
在多播网络边界(如路由器R1)将多播数据报封装成单播IP数据报,目的地址为另一边界路由器(R2)的IP地址。
-
封装后的单播包在中间网络中正常路由(中间路由器只做单播转发)。
-
到达R2后,解封装还原多播数据报,再继续多播分发。
-
-
典型应用 :MBONE(多播骨干网) 利用隧道技术将分散的多播岛连接起来。
意义:隧道技术使多播流量能够穿越非多播网络,实现跨域多播通信。
4-41 什么是 VPN?VPN 有什么特点和优缺点?VPN 有几种类别?
答案:
VPN(虚拟专用网络):
-
利用公共网络(如Internet)为远程用户或分支机构建立私有、安全的网络连接的技术。
-
它是"虚拟"的(没有专用物理线路)、"专用"的(数据加密隔离)。
VPN 的特点:
-
安全性:通过加密、认证保障数据机密性和完整性。
-
虚拟性:共享公共网络资源,用户感知不到物理差异。
-
灵活性:支持移动办公、远程接入。
-
经济性:相比租用专线大幅降低成本。
VPN 的优点:
| 优点 | 说明 |
|---|---|
| 成本低 | 替代昂贵的专线 |
| 扩展性好 | 易增加新节点 |
| 安全性高 | 加密隧道保护数据 |
| 跨地域 | 连接全球分支机构 |
VPN 的缺点:
| 缺点 | 说明 |
|---|---|
| 性能瓶颈 | 依赖公网带宽和延迟 |
| 稳定性 | 公网故障影响连接 |
| 管理复杂 | 需要管理证书、密钥、防火墙等 |
| 安全风险 | 若加密被破解或配置不当,存在泄漏风险 |
VPN 的类别:
| 分类方式 | 类型 | 说明 |
|---|---|---|
| 按连接模式 | 站点到站点 VPN | 连接两个固定网络(如总部与分公司) |
| 远程访问 VPN | 单个用户连接到企业内网(如员工在家办公) | |
| 按协议层次 | 二层 VPN | 基于 L2TP、PPTP 等 |
| 三层 VPN | 基于 IPsec、GRE 等 | |
| 按部署模式 | IPsec VPN | 标准安全协议,广泛应用 |
| SSL VPN | 基于浏览器访问,无需安装客户端 |
4-42 什么是 NAT?什么是 NAPT?NAT 的优点和缺点有哪些?NAPT 有哪些特点?
答案:
NAT(网络地址转换):
- 一种将私有IP地址映射为公有IP地址的技术,允许多个使用私有IP的主机共享一个或多个公有IP访问Internet。
NAT 的工作方式:
-
出方向:将源IP(私有→公有)和端口号(可选)进行映射
-
入方向:将目的IP(公有→私有)还原
-
路由器维护NAT转换表映射关系
NAPT(网络地址端口转换):
-
NAT的一种特殊形式,同时转换IP地址和传输层端口号。
-
允许多个私有主机共享单个公有IP地址(通过不同端口区分)。
NAT 的优点:
| 优点 | 说明 |
|---|---|
| 缓解IPv4地址短缺 | 一个公有IP可支撑数千台主机 |
| 内部网络隐私 | 内部IP不暴露在公网 |
| 简化IP管理 | 内部可使用任意私有地址段 |
| 实现负载均衡 | 可将外部请求分发到多台内部服务器 |
NAT 的缺点:
| 缺点 | 说明 |
|---|---|
| 破坏端到端通信 | 外部无法主动访问内部服务器(需端口映射) |
| 不支持某些协议 | 如SIP、FTP、IPsec需要应用层网关辅助 |
| 增加延迟 | 需要修改IP和端口,增加处理时间 |
| 无法端到端加密 | 修改IP地址会破坏IPsec完整性 |
NAPT 的特点:
-
端口复用:多个内网主机共享同一个公有IP,通过端口号区分。
-
动态映射:临时为每个会话分配一个公有端口,会话结束后回收。
-
广泛适用:家用路由器和企业出口常用NAPT。
-
节省IP地址:单个公有IP可服务整个局域网。
-
影响服务器映射 :外部访问内网服务器需要静态端口映射 或DMZ。
NAT 与 NAPT 对比:
| 对比项 | NAT | NAPT |
|---|---|---|
| 转换对象 | IP地址 | IP地址 + 端口号 |
| 公有IP数量 | 需要多个公有IP | 只需要1个公有IP |
| 区分会话 | 靠IP | 靠端口 |
| 常见场景 | 静态地址映射 | 家庭/企业共享上网 |
4-43 IPv4 地址二进制转点分十进制
答案:
(1) 10000001 00001011 00000101 11101111 → 129.11.5.239
(2) 11000001 10000011 00010110 11111111 → 193.131.22.255
(3) 11100111 11010101 10001011 01101111 → 231.213.139.111
(4) 11111001 10010111 11111011 00001111 → 249.151.251.15
4-44 假设一段地址的首地址为 146.102.29.0,末地址为 146.102.32.255,求这个地址段的地址数。
答案:1024
4-45 已知一个/27 网络中有一个地址是 167.199.170.82,问这个网络的网络掩码、网络前缀长度和网络后缀长度是多少?网络前缀是多少?
答案:
-
网络掩码:255.255.255.224
-
网络前缀长度:27
-
网络后缀长度:5
-
网络前缀:167.199.170.64/27
4-46 已知条件同上题,试求这个地址块的地址数、首地址以及未地址各是多少?
答案:
-
首地址:167.199.170.64
-
末地址:167.199.170.95
-
地址数:32
4-47 某单位分配到一个地址块 14.24.74.0/24。该单位需要用到三个子网,它们对三个子地址块的具体要求是:子网N;需要120个地址,子网N,需要60个地址,子网N,需要10个地址。请给出地址块的分配方案。
答案:
-
N₁(/25):14.24.74.0 ~ 14.24.74.127
-
N₂(/26):14.24.74.128 ~ 14.24.74.191
-
N₃(/28):14.24.74.192 ~ 14.24.74.207
4-48 如图 4-80 所示,网络 145.13.0.0/16划分为四个子网N₁,N₂,N₃,和 N₄。这四个子网与路由器R连接的接口分别是m0,m1,m2和m3。路由器R的第五个接口 m4连接到互联网。
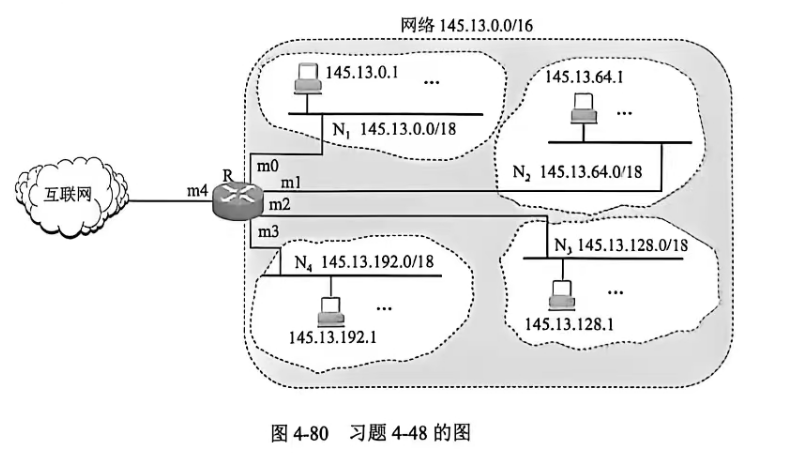
(1)试给出路由器R的路由表。
(2)路由器R收到一个分组,其目的地址是145.13.160.78。试解释这个分组是怎样被转发的。
(1) 路由表:
| 网络前缀 | 下一跳 |
|---|---|
| 145.13.0.0/18 | 直接交付,接口 m0 |
| 145.13.64.0/18 | 直接交付,接口 m1 |
| 145.13.128.0/18 | 直接交付,接口 m2 |
| 145.13.192.0/18 | 直接交付,接口 m3 |
| 0.0.0.0/0 | 默认路由,接口 m4 |
(2) 目的地址 145.13.160.78 属于 145.13.128.0/18 → 从接口 m2 转发
4-49 收到一个分组,其目的地址D=11.1.2.5。要查找的路由表中有这样三项:
路由1 到达网络 11.0.0.0/8 路由2 到达网络 11.1.0.0/16 路由3 到达网络 11.1.2.0/24
试问在转发这个分组时应当选择哪一个路由?
答案:
目的地址 11.1.2.5:
-
路由1:11.0.0.0/8
-
路由2:11.1.0.0/16
-
路由3:11.1.2.0/24
最长前缀匹配 → 路由3
4-50 同上题。假定路由1的目的网络11.0.0.0/8中有一台主机 H,其 IP 地址是 11.1.2.3.当我们发送一个分组给主机 H时,根据最长前级匹配准则,上面的这个转发表却这个分组转发到路由3的目的网络11.1.2.0/24。是长前级配准则有时会出吗?
答案:
原则没有错。问题在于主机 H 的 IP 地址 11.1.2.3 属于子网 11.1.2.0/24,网络 11.0.0.0/8 在分配主机地址时,不应再分配已被子网占用的地址,否则会引起地址混乱。
二、数据结构习题与解答
(1) 编写算法,在以二叉链表存储的二叉树中,求度为2的结点的个数。
核心思路
递归遍历二叉树:若当前结点既有左孩子又有右孩子,则计数为1,否则为0;再加上左子树和右子树中度为2的结点数。
C语言代码
int countDegree2(BiTree T) {
if (!T) return 0;
int cnt = (T->lchild && T->rchild) ? 1 : 0;
return cnt + countDegree2(T->lchild) + countDegree2(T->rchild);
}C++代码
与C语言代码一致
(2) 编写算法,在以二叉链表存储的二叉树中,交换二叉树各结点的左右子树。
核心思路
递归交换:对于每个结点,交换其左右孩子指针,然后递归处理左右子树。
C语言代码
void swapTree(BiTree T) {
if (!T) return;
BiTree temp = T->lchild;
T->lchild = T->rchild;
T->rchild = temp;
swapTree(T->lchild);
swapTree(T->rchild);
}C++代码
与C语言代码一致
(3) 编写算法,在以二叉链表存储的二叉树中,利用叶子结点的空链域,将所有叶子结点自左至右链接成一个单链表,算法返回最左叶子结点(链头)的指针。
核心思路
中序遍历二叉树,遇到叶子结点时,将其右孩子指针(原为空)指向下一个叶子结点,用全局变量记录链表头和尾。
C语言代码
BiTree leafHead = NULL, leafTail = NULL;
void linkLeaves(BiTree T) {
if (!T) return;
if (!T->lchild && !T->rchild) {
if (!leafHead) leafHead = leafTail = T;
else {
leafTail->rchild = T;
leafTail = T;
}
}
linkLeaves(T->lchild);
linkLeaves(T->rchild);
}C++代码
与C语言代码一致
(4) 设已建立的二叉树的三叉链表存储结构中,结点的数据域、孩子域已填好内容,现要求编写算法给双亲域填上指向其双亲的指针。
核心思路
先序遍历二叉树,将当前结点的双亲指针指向传入的父结点,然后递归处理左右孩子。
C语言代码
void setParent(TriTree T, TriTree parent) {
if (!T) return;
T->parent = parent;
setParent(T->lchild, T);
setParent(T->rchild, T);
}
// 调用方式:setParent(root, NULL);C++代码
与C语言代码一致
(5) 借鉴书中6.5节介绍的不使用递归和栈的中序遍历线索二叉树算法,设计一个不使用递归和栈的先序遍历线索二叉树算法。
核心思路
先访问根结点,然后一直向左走;当左孩子为空时,利用线索(右孩子指向后继)跳到下一个结点。
C语言代码
void preOrderThread(ThrTree T) {
ThrTree p = T;
while (p) {
while (p->ltag == 0) {
visit(p);
p = p->lchild;
}
visit(p);
p = p->rchild;
}
}C++代码
与C语言代码一致
(6) 编写算法,在以二叉链表存储的二叉树中,输出从根结点到每个叶子结点的路径。如图 6-40所示的二叉树,其所对应的输出结果如下。
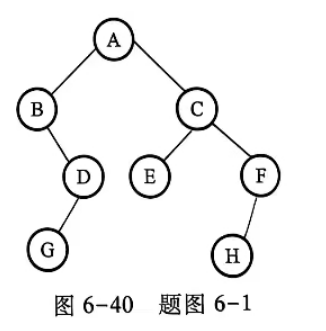
G A B D
E A C
H A C F
核心思路
先序遍历,用数组或栈记录当前路径,遇到叶子结点时输出路径,回溯时恢复。
C语言代码
void printPath(BiTree T, char* path, int len) {
if (!T) return;
path[len++] = T->data;
if (!T->lchild && !T->rchild) {
for (int i = 0; i < len; i++) printf("%c ", path[i]);
printf("\n");
}
printPath(T->lchild, path, len);
printPath(T->rchild, path, len);
}
// 调用方式:char path[100]; printPath(root, path, 0);C++代码
void printPath(BiTree T, vector<char>& path) {
if (!T) return;
path.push_back(T->data);
if (!T->lchild && !T->rchild) {
for (char c : path) cout << c << " ";
cout << endl;
}
printPath(T->lchild, path);
printPath(T->rchild, path);
path.pop_back();
}(7) 编写算法,在以二叉链表存储的二叉树中,按先序次序输出各结点的内容及相应的层次数,要求以二元组的形式输出。如图6-40所示的二叉树,其所对应的输出结果如下:
(A,1) (B,2) (D,3) (G,4) (C,2) (E.3) (F.3) (H,4)
C语言代码
void printGenList(BiTree T) {
if (!T) return;
printf("%c", T->data);
if (T->lchild || T->rchild) {
printf("(");
printGenList(T->lchild);
if (T->rchild) {
printf(",");
printGenList(T->rchild);
}
printf(")");
}
}C++代码
void printGenList(BiTree T) {
if (!T) return;
cout << T->data;
if (T->lchild || T->rchild) {
cout << "(";
printGenList(T->lchild);
if (T->rchild) {
cout << ",";
printGenList(T->rchild);
}
cout << ")";
}
}(8) 编写算法,在以孩子兄弟二叉链表存储的树中,求树(或森林)的叶子结点数。
核心思路
递归遍历:若无孩子结点则为叶子(计数1),否则递归计算孩子和兄弟的叶子数之和。
C语言代码
int countLeaves(CSTree T) {
if (!T) return 0;
if (!T->firstchild) return 1 + countLeaves(T->nextsibling);
return countLeaves(T->firstchild) + countLeaves(T->nextsibling);
}C++代码
与C语言代码一致
(9) 编写算法,在以孩子兄弟二叉链表存储的树中,求树(或森林)的高度。
核心思路
树的高度 = max(孩子子树高度+1, 兄弟子树高度)
C语言代码
int getHeight(CSTree T) {
if (!T) return 0;
int h1 = getHeight(T->firstchild) + 1;
int h2 = getHeight(T->nextsibling);
return h1 > h2 ? h1 : h2;
}C++代码
与C语言代码一致
(10) 编写算法,实现对顺序存储在一维数组的完全二叉树的先序遍历。
核心思路
递归:先访问当前结点(下标 i),然后遍历左孩子(2i)和右孩子(2i+1),需判断下标是否超出数组长度。
C语言代码
void preOrderSeq(char A[], int i, int n) {
if (i > n) return;
printf("%c ", A[i]);
preOrderSeq(A, 2 * i, n);
preOrderSeq(A, 2 * i + 1, n);
}
// 调用方式:preOrderSeq(arr, 1, n);C++代码
与C语言代码一致
// A0 为占位,从 A1 开始存根结点
注:以上习题的解答基于作者自己的理解和计算,如果有任何错误,希望各位读者和大佬指出改正,非常感谢!!!