
一、Harness的演化
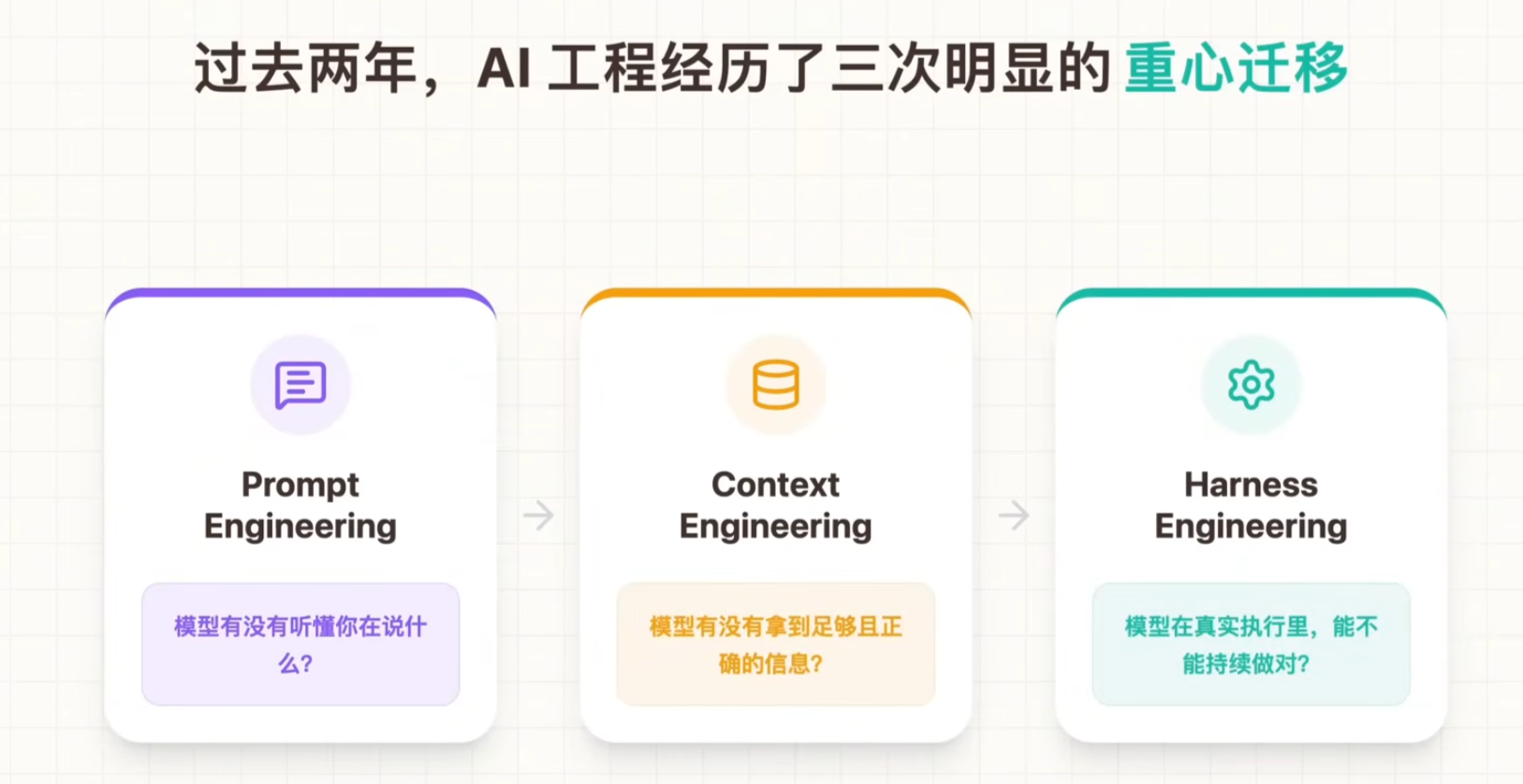
1、提示词工程
提示词工程(Prompt Engineering) ,就是在不改动 AI 模型参数 的前提下,通过系统化设计、测试、迭代输入文本(提示词) ,让大语言模型(LLM)稳定、准确、可控地输出符合预期结果的方法论与实践技能。
提示词的设计原则: 
提示词为何有效?
大模型本质上是一个对上下文非常敏感的概率生成系统。所以,你给它什么身份,它更容易沿着那个身份去回答;你给它什么样例,它更容易沿着那个范式去补全;你强调什么约束,它就更容易把那部分当成重点
所以 Prompt Engineering本质上不是"命令模型"而是塑造一个局部概率空间。这个阶段最重要的能力不是系统设计,而是语言设计。
但Prompt很快就遇到了天花板。因为很多任务不是"你说清楚就行",而是"你得真的知道"。

提示词擅长任务是:
1、澄清任务
2、约束输出
3、激发模型已有能力
不擅长任务是:
1、凭空补齐缺失知识
2、管理大量动态信息
3、处理长链路状态变化
提示词解决的是表达问题,不是信息问题。
在聊天机器人时代,场景的特征是:任务短、链路短、状态少,靠"把话说清楚"就能解决问题。
但Agent火了之后,场景发生了变化,需要处理多轮对话、需要调用外部工具,需要传递中间结果,还需要根据反馈修改计划。
这时候,问题就变了:从一次回答对不对 --> 整条任务链路能不能跑通?
 提示词已经无能为力了:
提示词已经无能为力了:

2、上下文工程
Context Engineering的核心:模型未必知道,所以系统必须在调用时把正确的信息送进去。Context不只是几段背景资料,从工程上讲,它是所有会影响模型当前决策的信息总和。
涉及:系统规范、安全约束、Agent结果等等。

也正因为如此,同样的模型、同样的Prompt放进不同系统里,效果可能差得非常大。
差别往往不在模型,而在上下文供给机制。
说到 Context Engineering,RAG算是一个比较典型的实践。
RAG的价值很直接: 模型参数里没有的知识怎么在运行时补进去?

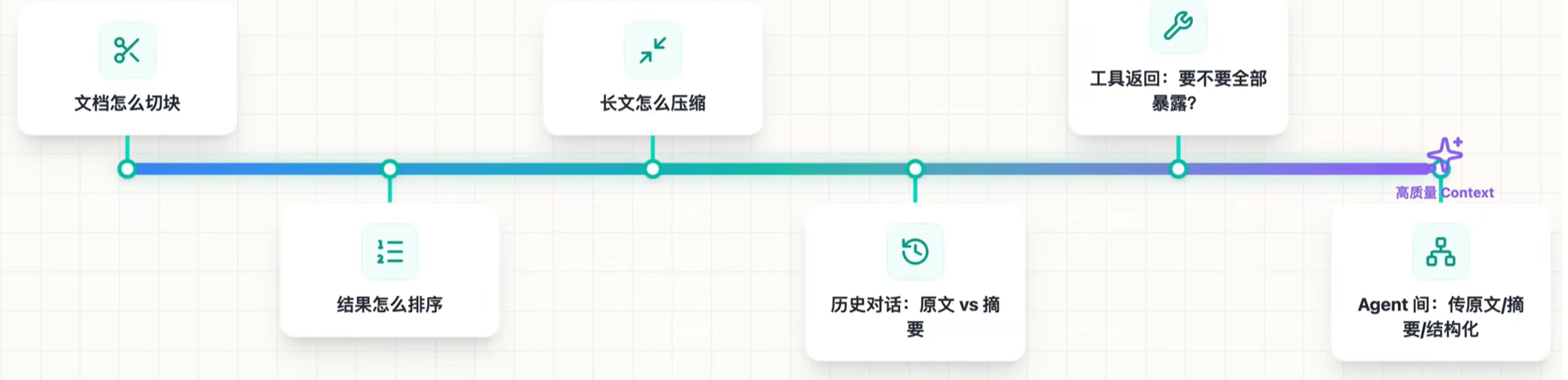
但真正成熟的Context Engineering关注的远不止"检索一下",它关心的是整条链路,如:
(1) 文档怎么切块?
(2)结果怎么排序?
(3)长文怎么压缩?
(4)历史对话怎么保存,什么时间使用原文,什么时间使用摘要。
(5)工具返回:要不要全部暴露给模型?
(6)多个Agent之间传输原文还是摘要,还是结构化的字段?
包括最近很火的Agent Skills本质上也是Context Engineering 的高级实践。
如果把所有工具、说明、参数全部一上来塞给模型效果并不佳,原因是:上下文窗口是稀缺资源,信息一多,注意力就散了。
所以Skills采用的是一种特别典型的思路:渐进式披露。 
但是新的问题也出现了,即使上下文信息给对了,模型也不一定能稳定执行。
你会发现,之前的努力都在解决输入侧的问题:
输入侧(Input):Prompt用于优化意图表达,Context用于优化信息供给。
但是对于执行侧(Execution):连续行动中的不确定性没有解决。
当模型开始连续行动的时候,谁来持续监督它、约束它、纠偏它。
3、Harness工程
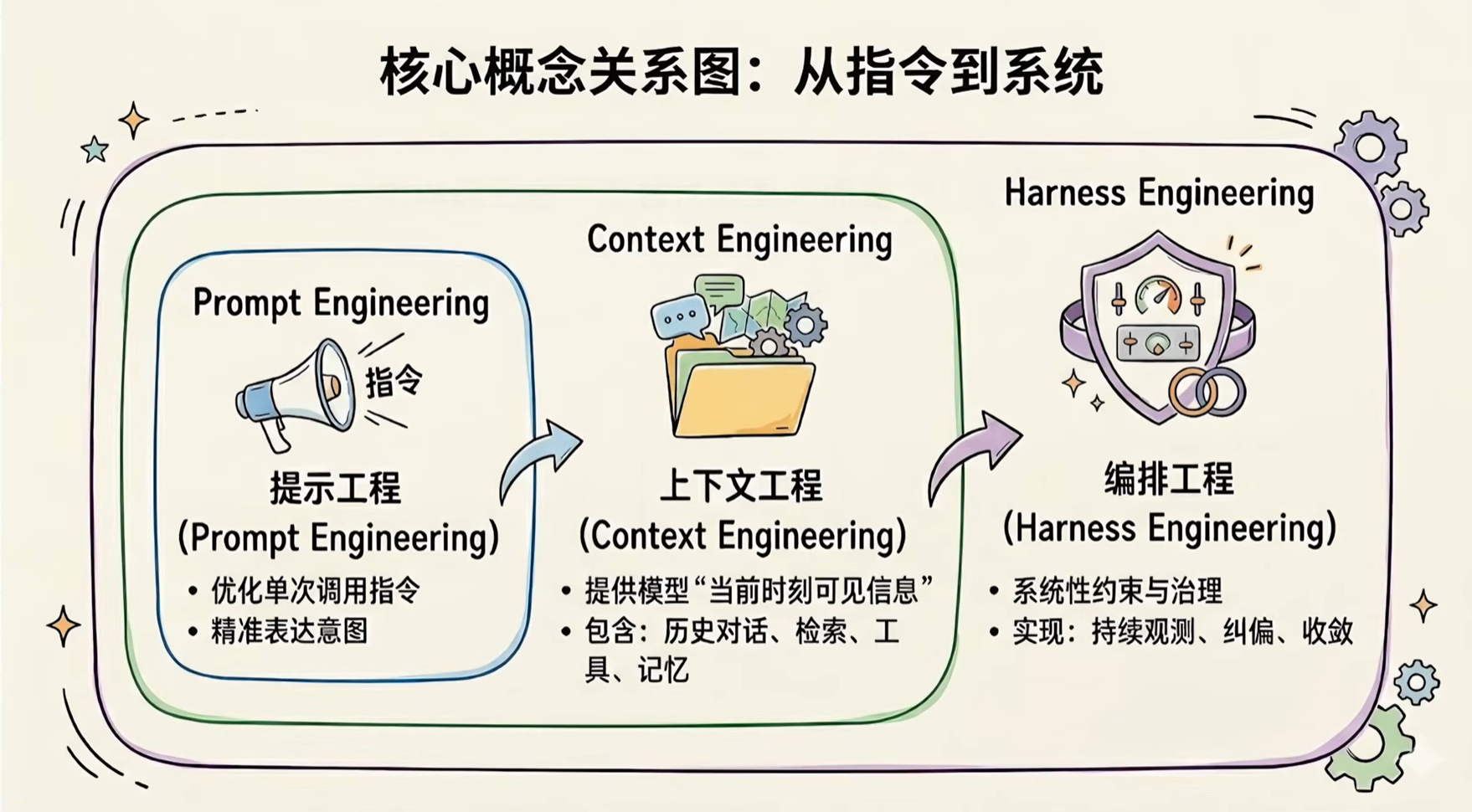
1和2解决的是怎么让模型更能思考?3解决的是模型别跑偏、跑得稳、出了错还能拉回来。
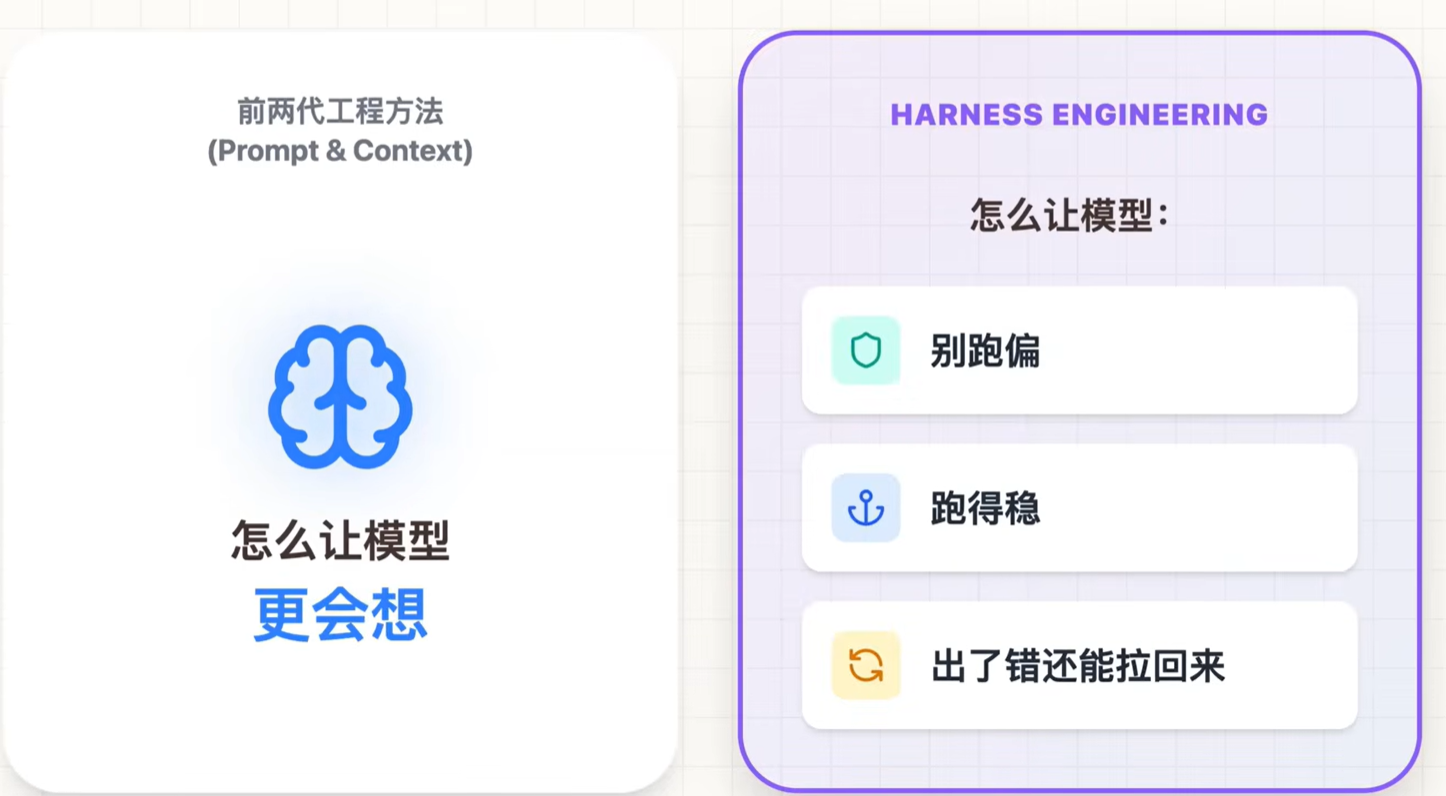
提示词工程重点是把话说明白,上下文工程重点是把资料准备齐,Harness就是有没有一套持续观测、持续纠偏、最终验收的机制。
三者的关系如下:
二、成熟的Harness包括哪些
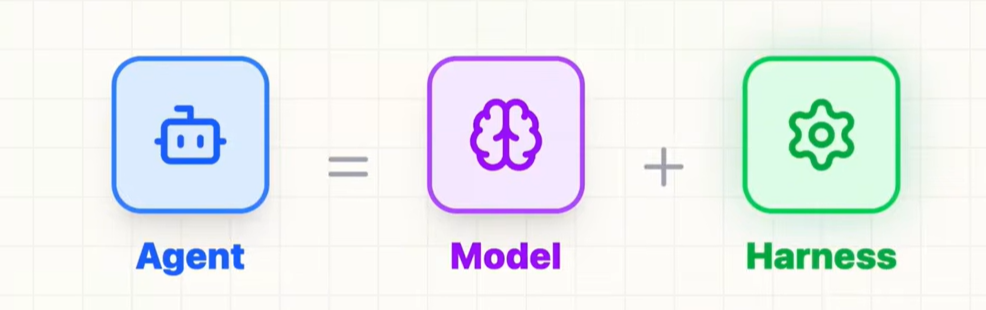
在一个Agent系统里,除了模型本身以外,几乎所有决定它能不能稳定交付的东西,都可以算进Harness。
一个成熟的Harness包括六层:
第一层: 上下文管理,从Harness视角去看Context。
模型能不能稳定发挥,很多时候不取决于它"聪不聪明"而取决于它看到了什么?Harness的第一职责:让模型在边界内思考。
(1)角色和目标定义:模型要知道自己是谁、任务是什么、成功标准是什么。
(2)信息选择和裁剪:上下文不是越多越好,而是越相关越好。
(3)结构化组织:固定规则放哪里,当前任务放哪里,运行状态放哪里,外部证据放哪里,最好分层清楚。
因为信息一旦乱,模型就很容易:漏重点、忘约束、甚至自我污染。
第二层:工具系统
没有工具系统,大模型本质上还是一个文本预测器,会解释、会总结、会推理,但接触不到真实世界。
Harness的功用不是简单把工具挂上去,而是要解决三个问题:
(1)给模型什么工具?
(2)什么时间该调用工具?
(3)工具结果怎么返回给大模型?

第三层:执行编排,解决大模型下一步如何工作
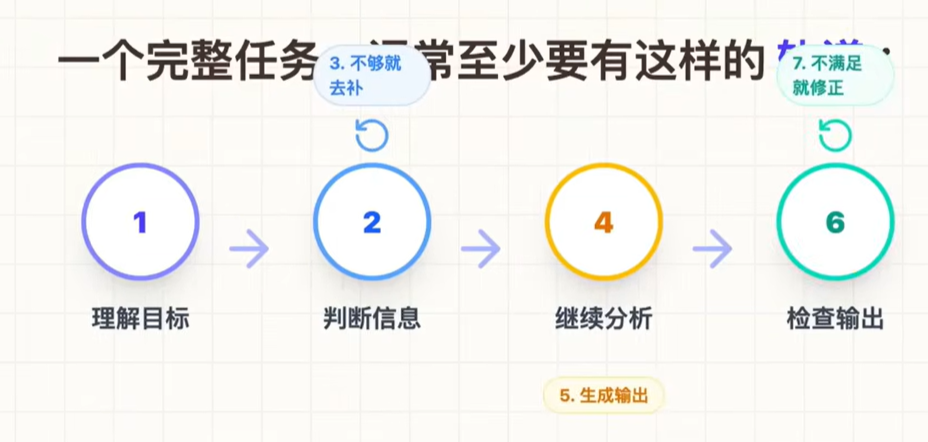
1、理解目标-> 2、判断信息-> 3、不够就去补充 -> 4、继续分析 -> 5、生成输出 -> 6、检查输出 -> 7、不满足进行修正。
第四层:状态和记忆
Harness需要处理:当前任务状态、会话中间结果、长期记忆与偏好。

第五层:评估与观测
这一层容易被忽视。很多系统不是"生成不出来"而是"生成完了以后,根本不知道自己做得好不好"?
通常包括:输出验收、环境验证、自动测试、日志和指标、错误归因。 
也就是说,系统不仅要会做,还要知道自己有没有真的做对。
第六层:约束、校验与失败恢复
成熟的Harness需要包括三部分:

三、Harness的工程实践
1、 Anthropic的工程实践
(1)Anthropic发现的第一个典型问题:长程任务的深度洞察
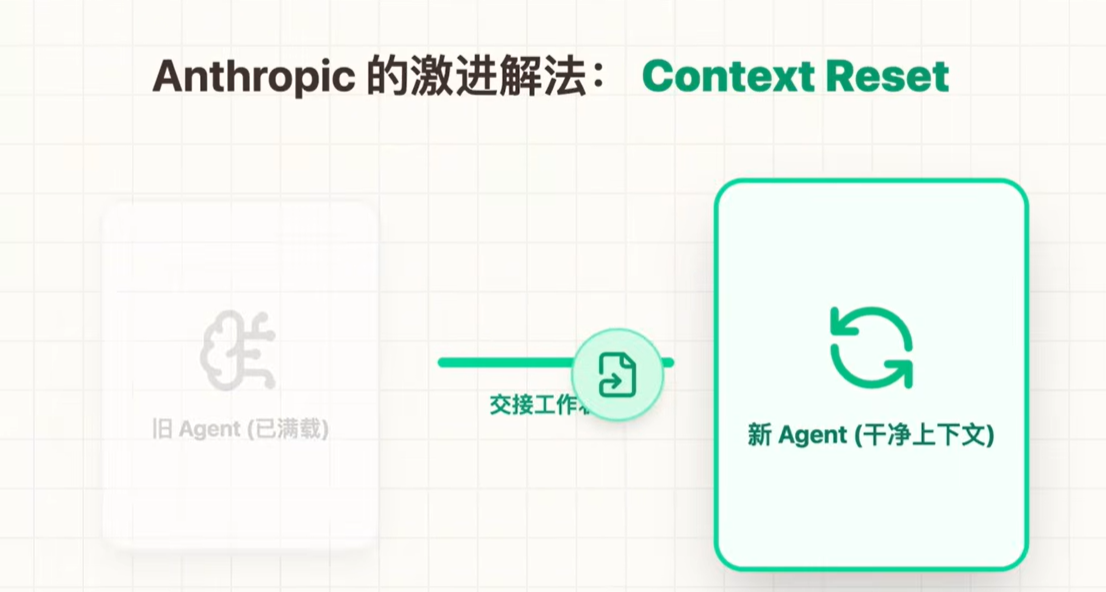
上下文焦虑问题:出现丢细节、丢重点;感觉装不下,着急收尾。
常用解法: Context Compaction,把历史压缩。
Anthropic发现压缩智能变短,不解决问题。
(2)Anthropic发现的第一个典型问题:自评失真

将问题拆分,分为2个独立的角色: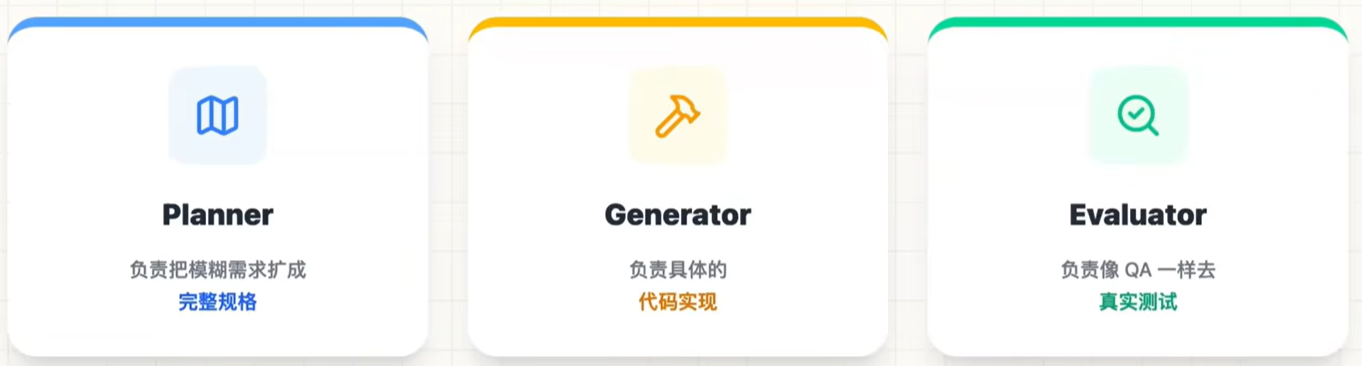
最关键的是,这个Evaluator不是只看代码,他会操作页面、看交互、检查结果。也就是说,它不是抽象审查,而是带环境的验证。实现"生产和验收分离"。

2、OpenAI的工程实践
(1)开发工程师的核心工作不再是写代码,而是变成拆解任务、补充能力和建立反馈。

当Agent出问题时,修复方案几乎从来不是"更努力"而是"缺了什么结构性的能力"?
(2)渐进式披露
摒弃超大的Agents.md,把这个文档变为目录页,AGENTS.md只保留最核心的索引。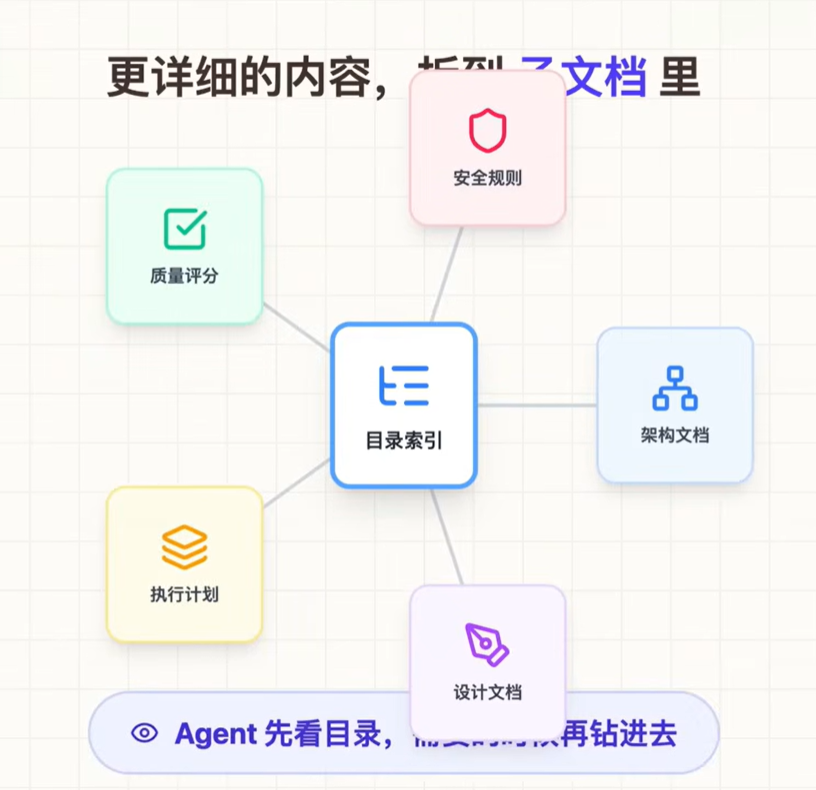
(3)让大模型看见整个工程
让Agent进行自我验证。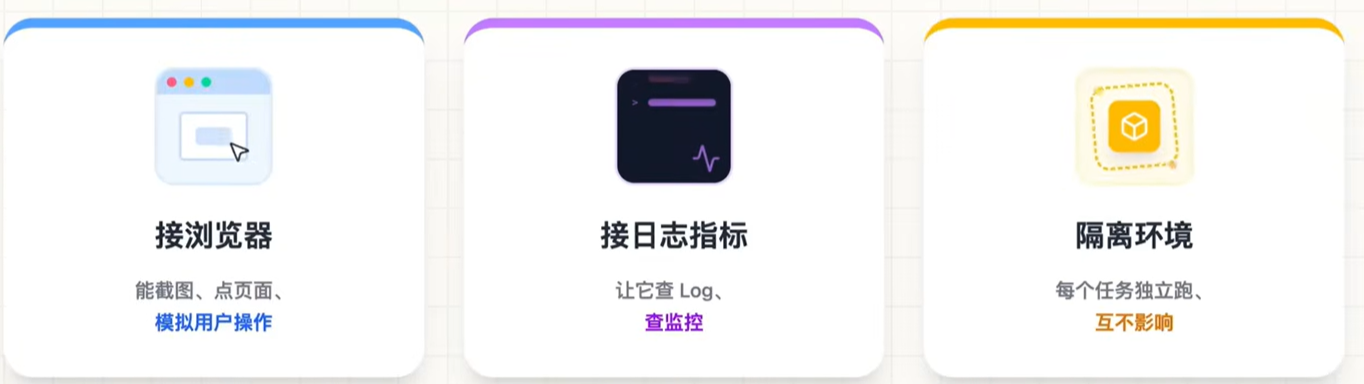
结果就是,Agent不再是"写完代码就说做完了",而是发现问题,验证后解决问题。

(3)OpenAI不是只靠人类Code Review来给代码质量兜底
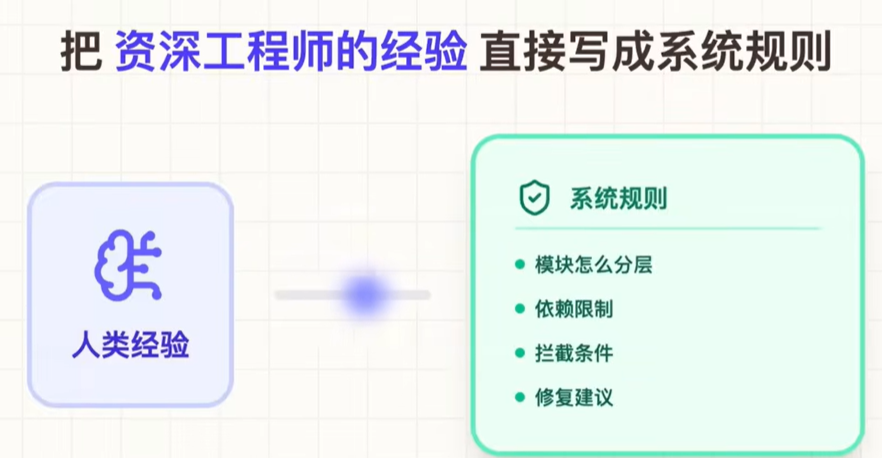
重点是这些规则不是只负责报错,而是会把"怎么修"也一起反馈给Agent。
四、小结
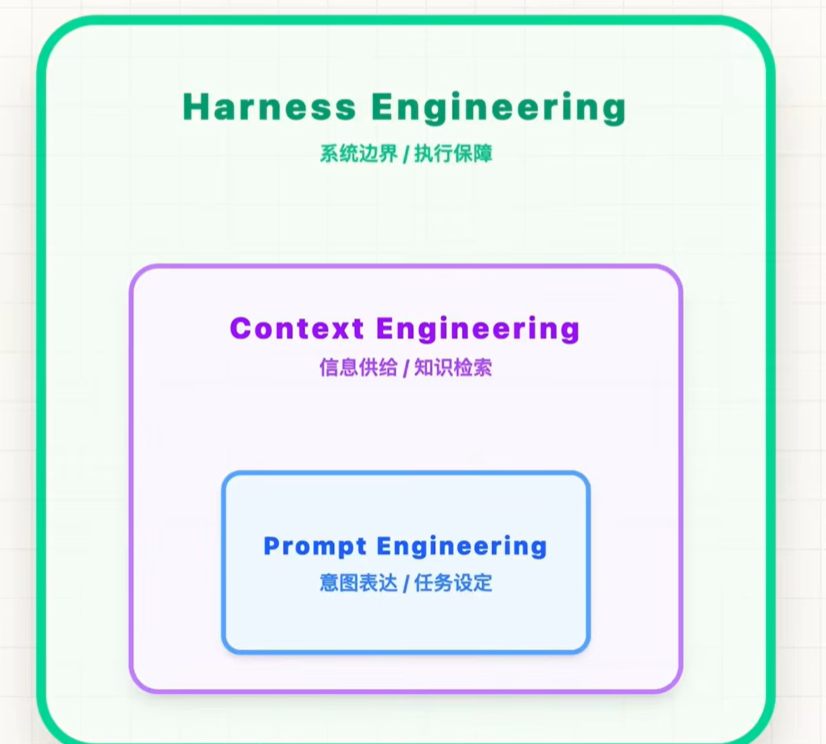
当任务还只是单轮生成时,Prompt 很重要;当任务开始依赖外部知识和运行时信息时
Context很关键;但当模型真的进入长链路、可执行、低容错的真实场景时,Harness几乎不可避免。
未来的重点是让大模型在真实世界里稳定工作。
参考资料: