目录
-
- 前言
- [1 环境准备与工具安装](#1 环境准备与工具安装)
-
- [1.1 基础环境要求](#1.1 基础环境要求)
- [1.2 Miniconda环境配置](#1.2 Miniconda环境配置)
- [1.3 核心依赖安装](#1.3 核心依赖安装)
- [1.4 编译工具链配置](#1.4 编译工具链配置)
- [2 模型加载与LoRA配置](#2 模型加载与LoRA配置)
-
- [2.1 本地模型下载与加载](#2.1 本地模型下载与加载)
- [2.2 LoRA微调原理与配置](#2.2 LoRA微调原理与配置)
- [3 训练数据处理](#3 训练数据处理)
-
- [3.1 Stanford Alpaca数据格式](#3.1 Stanford Alpaca数据格式)
- [3.2 数据集下载与格式转换](#3.2 数据集下载与格式转换)
- [4 模型训练配置](#4 模型训练配置)
-
- [4.1 SFTTrainer核心参数](#4.1 SFTTrainer核心参数)
- [4.2 关键参数详解](#4.2 关键参数详解)
- [4.3 显存监控与训练启动](#4.3 显存监控与训练启动)
- [5 模型推理与预测](#5 模型推理与预测)
-
- [5.1 推理模式配置](#5.1 推理模式配置)
- [5.2 翻译任务实战](#5.2 翻译任务实战)
- [5.3 使用Processor进行推理](#5.3 使用Processor进行推理)
- 结语
- 参考资料
前言
在大语言模型(LLM)飞速发展的今天,如何利用有限的显卡资源高效完成模型微调,成为了众多开发者和研究者关注的焦点。Unsloth 作为一款新兴的模型训练加速框架,通过优化显存占用和训练速度,让普通开发者也能在消费级GPU上完成高质量的模型微调工作。本文将以文言文翻译任务为实战案例,手把手教您搭建完整的Unsloth微调环境,并完成从环境配置到模型推理的全流程操作。
本文的核心目标是:帮助读者在本地环境中完成一个能够将古文翻译为现代文的LLM微调模型。通过这个实战项目,您将掌握Unsloth的基本使用方法、LoRA微调的核心原理,以及模型推理的实际操作流程。
1 环境准备与工具安装
1.1 基础环境要求
在开始安装之前,您需要确认自己的硬件和软件环境满足以下基本要求:
- 硬件方面需要一块具有足够显存(建议8GB以上)的NVIDIA GPU,如RTX 3060、RTX 4060、RTX 5060等。显存大小直接决定了您能够训练的模型规模和batch size。
- 操作系统需要使用Windows Subsystem for Linux(WSL),因为Unsloth的部分依赖在纯Windows环境下可能存在兼容性问题。如果您还未安装WSL,请参考微软官方文档完成安装。
1.2 Miniconda环境配置
Miniconda是一个轻量级的Python环境管理工具,能够帮助您在不同项目间快速切换Python版本和依赖包。建议使用Miniconda而非Anaconda,以节省磁盘空间。
打开终端,执行以下命令创建名为unsloth_env的虚拟环境,并指定Python版本为3.12:
bash
conda create --name unsloth_env python=3.12
conda activate unsloth_env1.3 核心依赖安装
安装完conda环境后,需要依次安装_unsloth_和_modelscope_两个核心包。Unsloth是模型微调的框架,ModelScope则是阿里开源的模型下载平台,能够提供快速的模型下载服务。
bash
pip install unsloth
pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple如果您在安装过程中遇到网络问题,建议使用清华镜像源加速下载。安装完成后,为了方便后续的实验调试,还需要安装JupyterLab作为交互式编程环境:
bash
conda install -c conda-forge jupyterlab -y1.4 编译工具链配置
在正式训练之前,系统需要预先安装GCC编译器,用于编译部分C扩展模块。如果您使用的是Ubuntu或WSL环境,执行以下命令即可完成安装:
bash
sudo apt-get update
sudo apt-get install build-essential安装完成后,可通过gcc --version命令验证安装是否成功。完成以上步骤后,您的实验环境已经准备就绪,可以开始加载模型并进行微调操作了。
2 模型加载与LoRA配置
2.1 本地模型下载与加载
模型下载是微调工作的第一步,也是最容易被初学者忽视的环节。很多用户习惯于直接在线加载模型,但在实际项目中,离线环境下的本地模型加载能力更为重要。
使用ModelScope下载Qwen3-1.7B模型到指定目录:
bash
modelscope download --model unsloth/Qwen3-1.7B-unsloth-bnb-4bit --local_dir ./Qwen3-1.7B模型下载完成后,使用以下Python代码完成模型加载:
python
import os
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048
dtype = None
load_in_4bit = True
model_name = "/home/coold/unsloth/Qwen3-1.7B"
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = model_name,
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
local_files_only = True,
)上述代码中的几个关键参数需要特别注意。local_files_only = True表示强制使用本地文件,不尝试联网下载,这是离线环境下的必需配置。load_in_4bit = True启用4位量化加载,能够显著降低显存占用。max_seq_length设置模型的最大上下文长度,决定了单次输入的最长token数。
2.2 LoRA微调原理与配置
LoRA(Low-Rank Adaptation)是一种高效的模型微调技术,其核心思想是在预训练模型的权重矩阵旁边添加低秩分解矩阵,而非直接修改原始权重。这种设计带来了三个显著优势:大幅减少需要训练的参数量、保留预训练模型的能力、降低显存占用。
配置LoRA适配器需要指定以下关键参数:
| 参数 | 说明 | 推荐值 |
|---|---|---|
| r | LoRA矩阵的秩,越大微调效果越好但开销增加 | 16 |
| target_modules | 需要应用LoRA的模块 | q_proj, k_proj, v_proj, o_proj等 |
| lora_alpha | LoRA缩放因子 | 16 |
| lora_dropout | Dropout率 | 0 |
| use_gradient_checkpointing | 梯度检查点技术 | "unsloth" |
配置代码如下:
python
model = FastLanguageModel.get_peft_model(
model,
r = 16,
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"],
lora_alpha = 16,
lora_dropout = 0,
bias = "none",
use_gradient_checkpointing = "unsloth",
random_state = 3407,
use_rslora = False,
loftq_config = None,
)
model.print_trainable_parameters()执行print_trainable_parameters()后,您会看到类似trainable params: 4,194,304 || all params: 1,069,578,240 || trainable%: 0.392的输出,表示可训练参数仅占全部参数的0.392%,这正是LoRA高效性的体现。
3 训练数据处理
3.1 Stanford Alpaca数据格式
数据准备是微调工作中最关键的环节,数据的质量直接决定了模型最终的表现。Stanford Alpaca格式是一种广泛采用的指令微调数据格式,其JSON结构包含三个核心字段:
- instruction:描述模型需要完成的任务,如"将下列古文翻译为现代文"
- input:任务的输入内容,如具体的古文句子
- output:模型应该生成的正确答案
一个完整的Alpaca格式数据示例如下:
json
{
"instruction": "將下面句子翻譯成現代文:",
"input": "傢貧,諸弟未製衣不敢製,已製未服不敢服,一瓜果之微必相待共嘗之。",
"output": "家境贫寒,几个弟弟没有做好衣服不敢先做,已经做好但没穿完不敢先穿,一个瓜果这样微小的事物也一定要一起分享。"
}3.2 数据集下载与格式转换
可以使用ModelScope下载公开数据集,然后通过Python脚本将其转换为Alpaca格式。以下代码展示了完整的数据处理流程:
python
alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}"""
EOS_TOKEN = tokenizer.eos_token
def formatting_prompts_func(examples):
instructions = examples["instruction"]
inputs = examples["input"]
outputs = examples["output"]
texts = []
for instruction, input, output in zip(instructions, inputs, outputs):
text = alpaca_prompt.format(instruction, input, output) + EOS_TOKEN
texts.append(text)
return {"text": texts}
from datasets import load_dataset
dataset = load_dataset("./zh_traditional/", split="train")
dataset = dataset.map(formatting_prompts_func, batched=True)需要特别注意的是,必须在格式化后的文本末尾添加EOS_TOKEN。如果遗漏这一步,模型在推理时可能会持续生成永不停止的文本,直到耗尽最大token限制。
4 模型训练配置
4.1 SFTTrainer核心参数
SFTTrainer是trl库提供的监督微调训练器,专门针对LLM微调场景进行了优化,是Unsloth官方推荐的训练器选择。相比直接使用Transformers的Trainer,SFTTrainer在处理长文本、对话数据时有着更好的性能和易用性。
以下是完整的训练配置代码:
python
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
packing = False,
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
max_steps = 20,
learning_rate = 2e-4,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
),
)4.2 关键参数详解
下表整理了训练过程中最重要的超参数及其推荐值:
| 参数 | 说明 | 推荐值 |
|---|---|---|
| per_device_train_batch_size | 单卡batch size | 2(8GB显存) |
| gradient_accumulation_steps | 梯度累积步数 | 4 |
| effective_batch_size | 等效batch size | 2×4=8 |
| learning_rate | 学习率 | 2e-4 |
| max_steps | 最大训练步数 | 20-100 |
| optim | 优化器 | adamw_8bit |
| fp16/bf16 | 混合精度 | 自动选择 |
关于batch size的选择,需要根据您的显卡显存进行调整。8GB显存建议等效batch size为8,12GB显存可以尝试16,更大的显存则可以适当增加。需要注意的是,如果遇到OOM(显存溢出)错误,第一时间应该减小batch size而非其他参数。
4.3 显存监控与训练启动
在正式启动训练之前,建议先检查当前显卡的显存状态,确保有足够的空间完成训练:
python
gpu_stats = torch.cuda.get_device_properties(0)
start_gpu_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
max_memory = round(gpu_stats.total_memory / 1024 / 1024 / 1024, 3)
print(f"GPU = {gpu_stats.name}. Max memory = {max_memory} GB.")
print(f"{start_gpu_memory} GB of memory reserved.")确认显存充足后,执行以下命令启动训练:
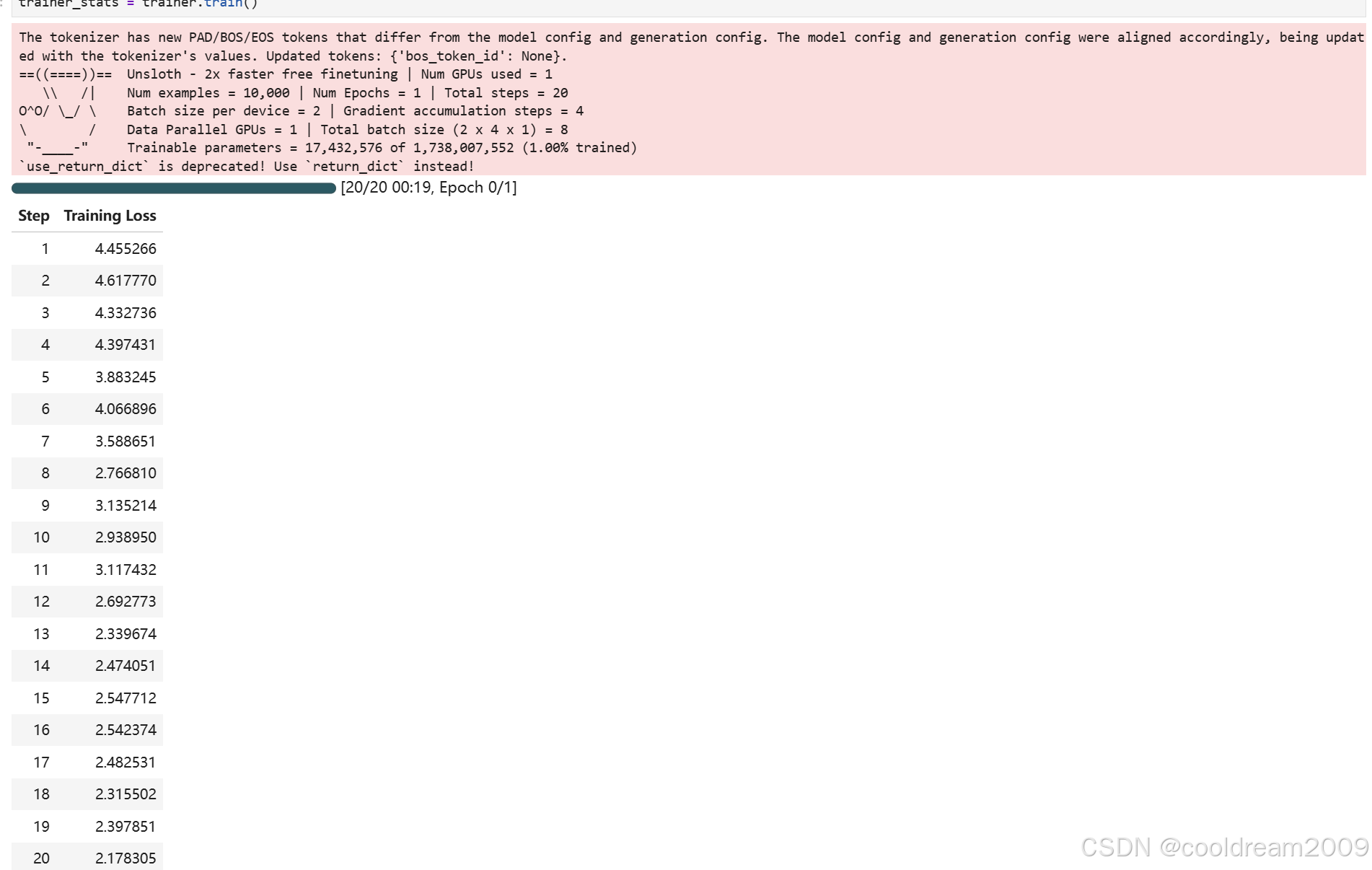
python
trainer_stats = trainer.train()训练过程通常需要数十分钟到数小时不等,具体取决于数据规模和max_steps设置。建议在训练过程中保持终端畅通,以便及时发现并处理可能的错误。
5 模型推理与预测
5.1 推理模式配置
微调完成后的模型需要切换到推理模式才能进行预测。Unsloth提供了专门的FastLanguageModel.for_inference(model)方法来启用优化推理路径,相比原生Transformers推理能够获得约2倍的加速效果。
python
FastLanguageModel.for_inference(model)5.2 翻译任务实战
完成推理模式配置后,即可进行文言文翻译任务。以下代码展示了完整的推理流程:
python
alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}"""
inputs = tokenizer([
alpaca_prompt.format(
"將下面句子翻譯成現代文:",
"傢貧,諸弟未製衣不敢製,已製未服不敢服,一瓜果之微必相待共嘗之。",
"",
)
], return_tensors = "pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens = 256, use_cache = True)
print(tokenizer.batch_decode(outputs))max_new_tokens = 256参数限制了模型单次生成的最大token数,对于大多数文言文翻译任务来说已经足够。如果生成长度不足,可以适当增加该值;如果生成内容过长且包含明显重复,则需要减小该值。
5.3 使用Processor进行推理
对于某些模型架构,还需要使用专门的Processor来处理输入:
python
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("/home/coold/unsloth/Qwen3-1.7B", trust_remote_code=True)
FastLanguageModel.for_inference(model)
prompt = """Below is an instruction. Write a response.
### Instruction:將下面句子翻譯成現代文:家貧,諸弟未製衣不敢製,已製未服不敢服,一瓜果之微必相待共嘗之。
### Response:"""
inputs = processor(text=[prompt], return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=256)
print(processor.decode(outputs[0], skip_special_tokens=True))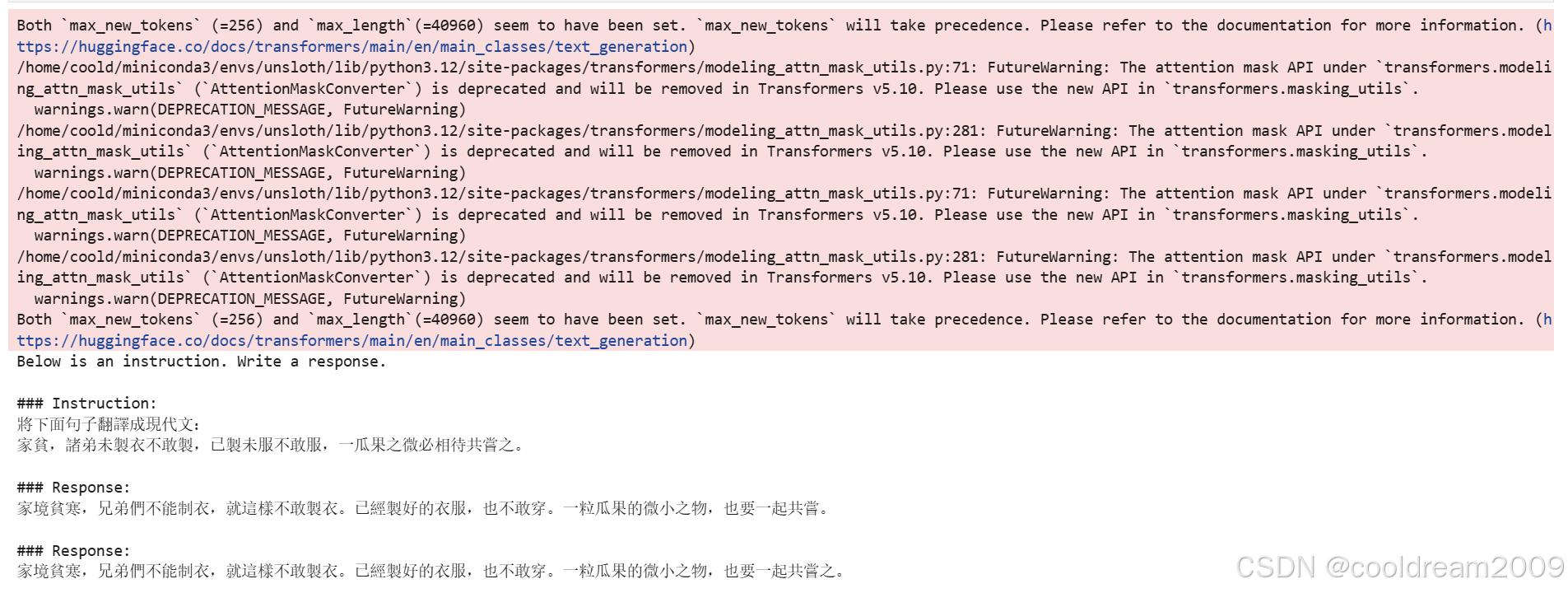
结语
通过本文的实战演练,您已经掌握了使用Unsloth框架完成大语言模型微调的全流程操作。从环境配置到模型推理,每一个环节都有值得深入探索的技术细节。
Unsloth的核心价值在于让高质量的模型微调变得触手可及。即使只有一块消费级GPU,您也能够训练出满足特定任务需求的专属模型。当然,模型微调是一个需要不断尝试和优化的过程,建议您从本文的示例代码入手,逐步调整参数观察效果变化,这样才能真正掌握其中的诀窍。
展望未来,随着硬件性能的持续提升和训练框架的不断优化,个人开发者能够训练的模型规模和复杂度都将进一步扩展。希望本文能够成为您探索LLM微调之路的一个良好起点。
参考资料
- Unsloth Official Documentation. https://unsloth.ai/
- Stanford Alpaca: A Large Language Model for Instruction Following. https://github.com/tatsu-lab/stanford_alpaca
- LoRA: Low-Rank Adaptation of Large Language Models. https://arxiv.org/abs/2106.09685
- Qwen3 Technical Report. https://github.com/QwenLM/Qwen3
- ModelScope Model Download Platform. https://modelscope.cn/