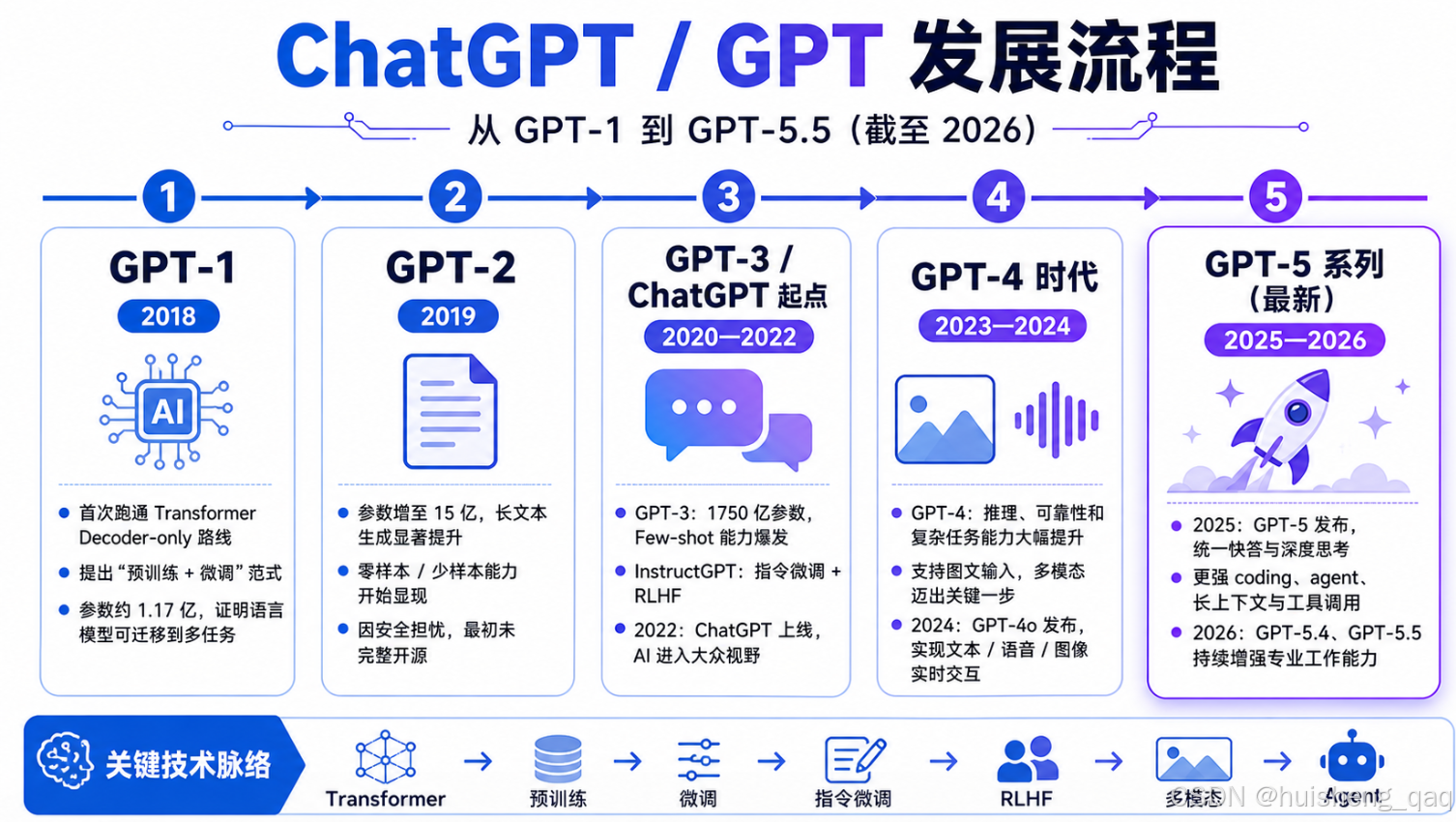
深入理解ChatGPT发展流程
- 一,深入理解ChatGPT发展流程
-
- 1,GPT-1时代(2018年)
-
- 1.1,初谈Transformer架构
- [1.2,预训练 + 微调](#1.2,预训练 + 微调)
- [1.3,GPT-1 的规模和局限](#1.3,GPT-1 的规模和局限)
- 2,GPT-2时代(2019年)
- 3,GPT-3时代(2020-2022年)
-
- [3.1,In-Context Learning(上下文学习)](#3.1,In-Context Learning(上下文学习))
- 3.2,涌现能力
- 3.3,GPT-3的规模和局限
- 4,GPT-3.5(2022年11月)
-
- [4.1,指令微调(Instruction Tuning)](#4.1,指令微调(Instruction Tuning))
- 4.2,RLHF(基于人类反馈的强化学习)
- 4.3,ChatGPT的诞生
- 4.4,GPT-3.5的规模和局限
- 5,GPT-4时代(2023-2024年)
- 6,GPT-5系列时代(2025年-2026年)
-
- [6.1,统一模型 + 自动路由](#6.1,统一模型 + 自动路由)
- 6.2,从回答问题到执行任务
- 6.3,代表版本
- 6.4,GPT-5.5:面向真实工作的进一步升级
- 6.5,GPT-5系列的意义和局限
如需转载,请附上链接:https://blog.csdn.net/zhenghuishengq/article/details/160751790
一,深入理解ChatGPT发展流程
上一篇讲解了AI从感知智能到认知智能的发展流程,接下来这篇,就以比较有代表性的chatgpt为例子,来讲解一下整个AI的发展流程,所以这篇文章不会只讲 ChatGPT 本身,而是会以 GPT 系列的发展为主线,把背后的 Transformer、预训练、微调、指令微调、RLHF、多模态、RAG、Agent 等关键概念串起来。至于为什么选chatgpt也显而易见,因为chatgpt是将大语言模型推向大众视野的标志性产品
1,GPT-1时代(2018年)
1.1,初谈Transformer架构
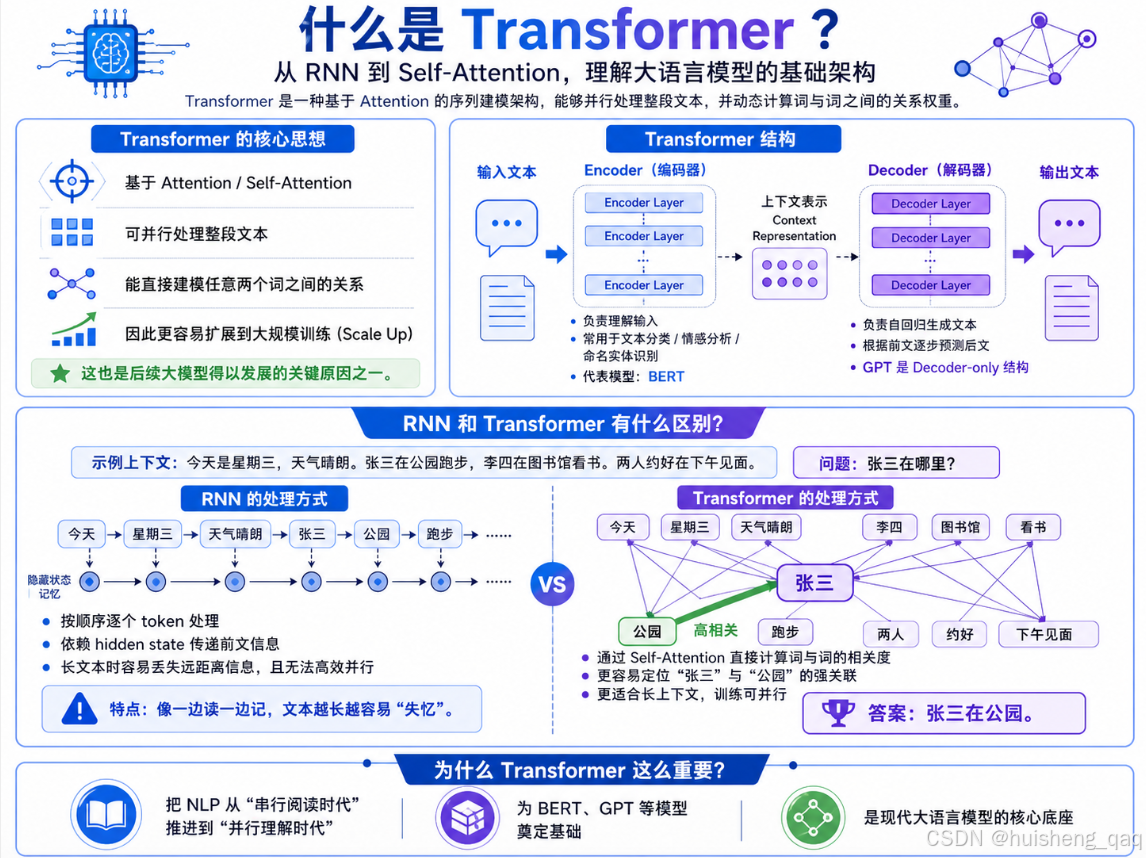
在讲解gpt1之前,需要先讲解一个比较重要的东西transformer ,官方对他的定义是: 一种基于注意力(Attention)的序列建模架构 ,可以并行处理整段文本,并动态计算词与词之间的关系权重 。transformer通过Self-Attention 方式优化传统的计算方式,通过直接建模可以得知任意两个词之间的关系,并且因为可以并行训练,使得模型能够 scale 到很大的规模,这也是后续大模型得以发展的根本原因。transformer由编码器(Encoder)和解码器(Decoder)两部分组成:编码器负责理解输入并生成上下文表示,可用于情感分析、文本分类、命名实体识别等理解类任务(代表模型是 BERT);解码器负责自回归地生成文本,是 GPT 系列的基础架构(GPT 实际上是 decoder-only 结构)。
先举个例子来说明一下RNN和transformer的区别,其上下文内容和如下:
今天是星期三,天气晴朗。张三在公园跑步,李四在图书馆看书。两人约好在下午见面
接下来一个提问:
张三在哪里?
针对于上面的问题,RNN的计算方式:他会按顺序逐个 token 处理上下文,通过隐藏状态(hidden state)将之前读到的信息一步步往后传递,相当于一边读一边在脑子里维护一份"记忆",最后基于这份记忆来回答问题。这种方式的问题是必须串行计算无法并行,而且当上下文较长时,前面的信息容易在传递过程中被稀释(即长距离依赖丢失),在短上下文场景下与 Transformer 差距没那么明显,但长文本下劣势会非常突出。
而transformer的计算方式会如下:他会通过 Self-Attention 直接计算任意两个词之间的相关度(基于矩阵和向量运算),每个词都能"看到"其他所有词。如针对于刚刚那个问题,Transformer 能通过注意力权重快速定位"张三"与"公园"的强关联,从而得出"张三在公园"。它对长上下文有明显优势,不会那么容易失忆,并且由于可以并行计算,训练和推理效率都更高。
1.2,预训练 + 微调
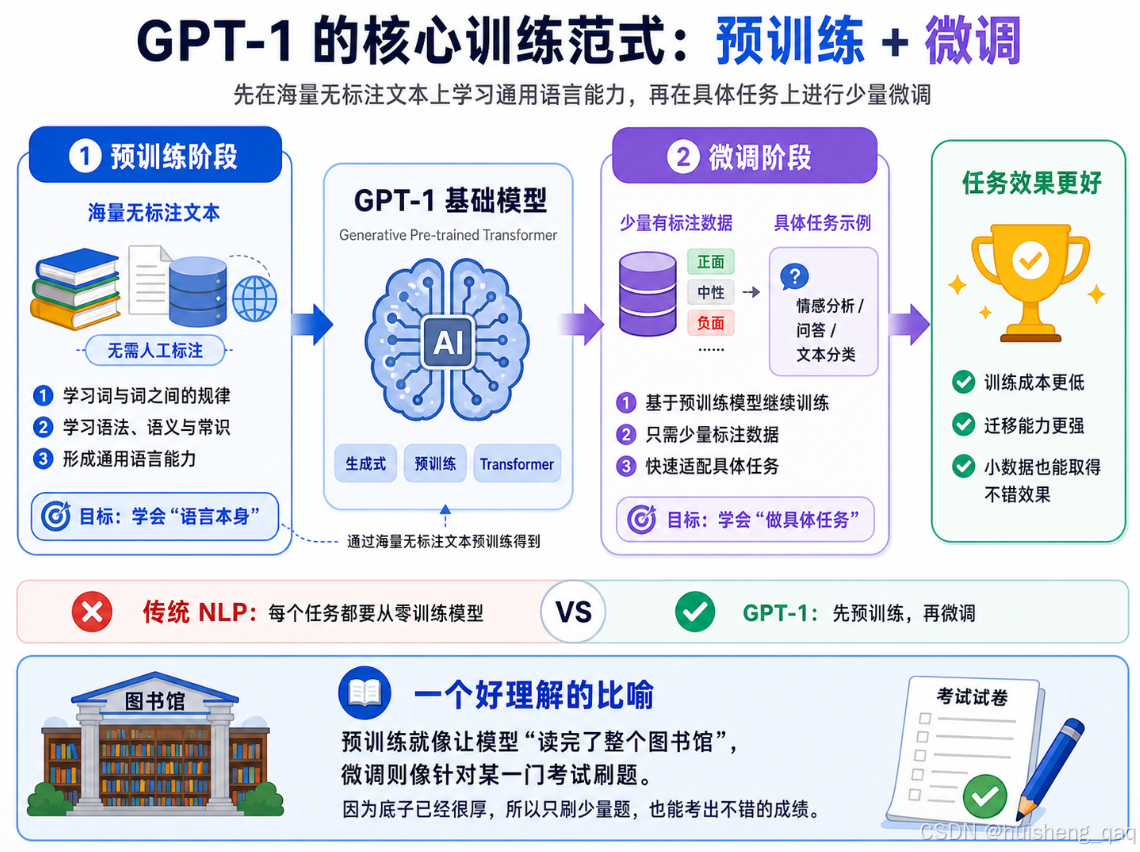
在上面初步的了解完Transformer之后,再来看 GPT-1 就比较好理解了。GPT 的全称是 Generative Pre-trained Transformer ,从名字就能看出三个关键词:生成式(Generative)、预训练(Pre-trained)、Transformer 。GPT-1在内部定义了一套训练范式:先在海量无标注文本上做预训练,再在具体任务的小数据集上做微调
在 GPT-1 之前,NLP 领域做任何一个任务(情感分析、问答、翻译......)基本都要从零开始训练一个模型,需要大量有标注的数据,成本非常高。而 GPT-1 的做法是:
- 预训练阶段:用海量互联网文本(无标注)训练一个通用语言模型,让模型学会"语言本身"------词与词之间的规律、语法、常识等。
- 微调阶段:针对具体任务(比如情感分类),只需要少量有标注数据,在预训练模型的基础上稍作调整即可。
打个比方:预训练就像让模型"读完了整个图书馆",微调则是针对某一门考试刷题。 因为底子已经很厚,所以刷少量题就能考出不错的成绩。
1.3,GPT-1 的规模和局限
GPT-1 的具体参数如下:其参数量约1.17亿,有12层的Transformer Decoder,训练数据约7000本未出版的图书,大概约5G文本。
以今天的标准看这个规模非常小,但在 2018 年已经是比较大的模型了。GPT-1 验证了"预训练 + 微调"这条路径的可行性,但它仍有明显局限:
- 仍然需要针对每个下游任务单独微调,没有展现出"一个模型解决所有问题"的能力。
- 生成能力有限,文本连贯性和逻辑性都一般。
小结: GPT-1最大的贡献就是跑通了"预训练 + 微调"这条路子,证明了先让模型在海量文本上自学,再用少量标注数据微调就能在各种任务上拿到不错的效果。但它的短板也很明显------每个任务还是得单独微调,模型规模也太小,生成出来的文本质量一般。总的来说,GPT-1更像是一次成功的概念验证,给后面的大模型铺好了路。
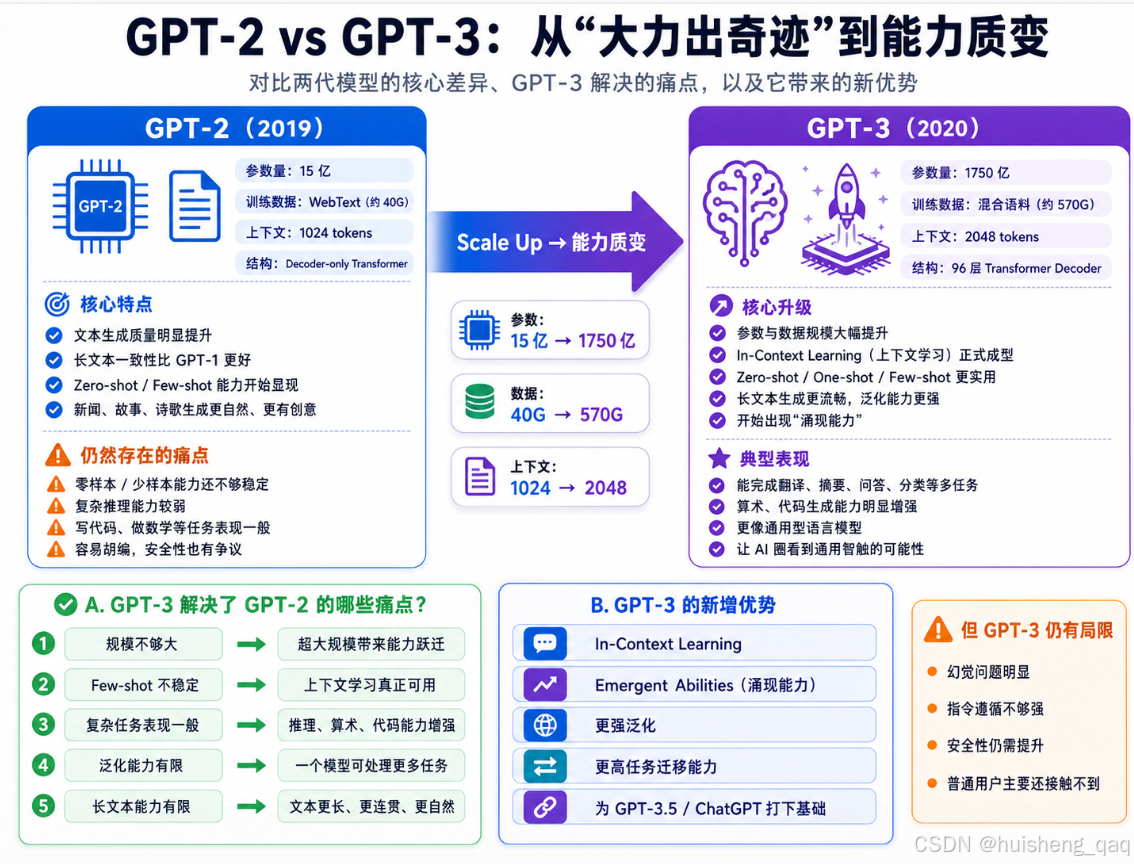
2,GPT-2时代(2019年)
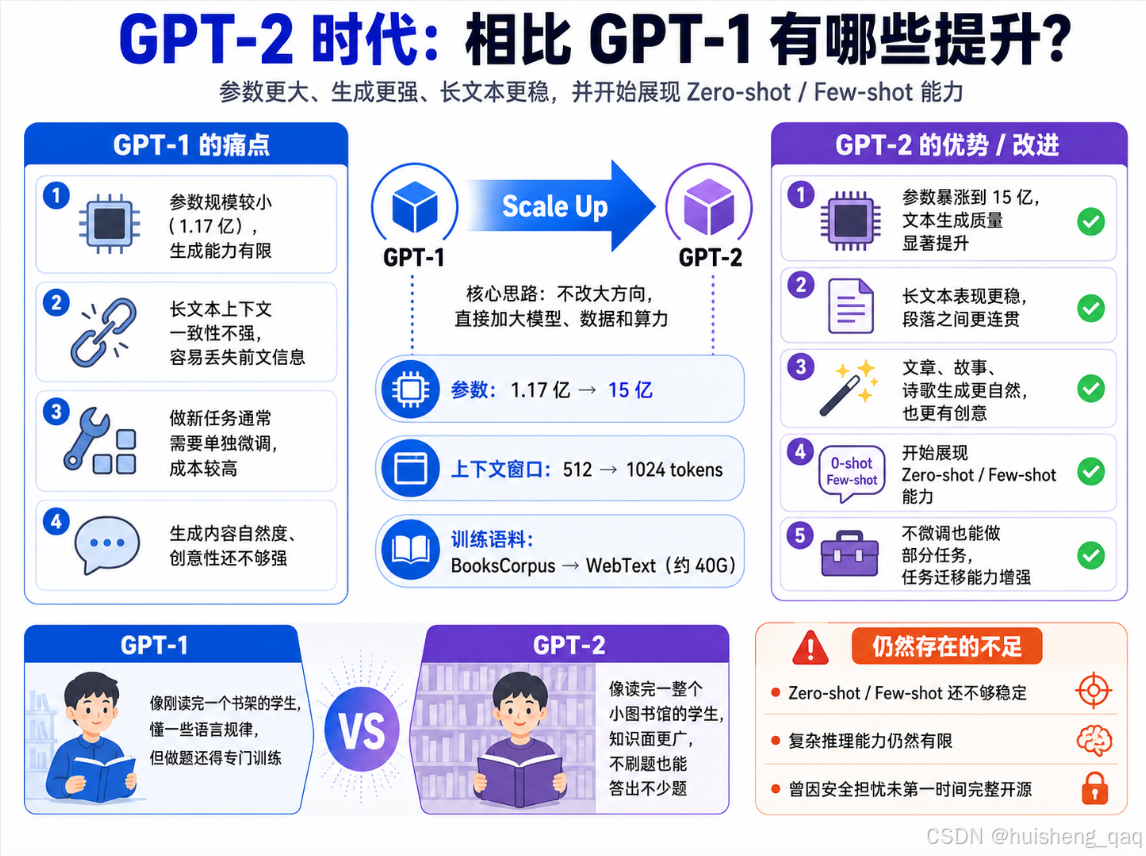
基于GPT-1的痛点,gpt-2时代首先针对于参数问题进行了优化,**将原本的1.17亿调整到了15亿,通过参数的增加对文本的生成有了显著的提升。虽然参数增加了,但是其上下文的长文本能力依旧能保持一致性,并且在此期间引入了零样本和少样本的学习能力。**GPT-2时代解决了GPT-1多参数的痛点,并且可以更加自然、更有创意的生成文章段落,在新闻、故事和诗歌等领域表现突出。
2.1,零样本和少样本学习
GPT-1的路子是先预训练一个大模型,然后针对每一个下游任务单独去微调一下。但这就有个很烦的问题:你每搞一个新任务,就得准备一批标注数据,再微调一轮,本质上还是"一个任务一个模型",成本并没有降下来多少。所以GPT-2就想了个更骚的操作:我能不能啥微调都不做,你直接把任务描述甩给模型,它就能干活? 这就是所谓的零样本(Zero-shot)学习------你啥例子都不给,直接下个指令,它就开整。
还有一种叫少样本(Few-shot)学习,就是你给它看那么几个例子,它照猫画虎也能整明白。比如你想让它翻译:
英文:hello → 中文:你好
英文:apple → 中文:苹果
英文:cat → 中文:
模型一看这规律,自然就知道下一个该填"猫"了。这种能力在之前的模型上基本是做不到的,而GPT-2第一次让大家看到:原来一个足够大的语言模型,不微调也能干不少活。
2.2,大力出奇迹
GPT-2其实在架构上没怎么折腾,基本就是把GPT-1"加大加量"了一波:参数量从1.17亿直接怼到15亿,翻了十几倍;训练数据也从7000本书升级成了从Reddit上抓下来的高赞外链,整了一个大概40G的WebText语料;上下文窗口也从512扩到了1024 tokens。
这里面藏着一个后来影响整个大模型圈的思路:模型越大、数据越多、算力越猛,模型能力就越强。这个想法在当时还只是个猜测,但GPT-2用结果把它给证明了------啥新结构都不加,光是scale up,就能带来肉眼可见的质变。这也为后来GPT-3直接干到1750亿参数埋下了伏笔。
还是打个比方:GPT-1相当于小学生读完了一个书架的书,GPT-2则是中学生把整个小图书馆都啃了一遍。 读的东西多了,知识面自然就广,很多以前不会做的题,现在不用专门刷题也能答个七七八八。
2.3,GPT-2的规模和局限
GPT-2的具体参数如下:参数量15亿(最大版本),48层Transformer Decoder,训练数据约40G WebText文本,上下文长度1024 tokens。
GPT-2 验证了"把模型做大"这条路子是走得通的,也第一次让大家看到了零样本 / 少样本学习的潜力。但它的问题也还是挺明显的:
- 零样本能力是有了,但还不够稳,很多任务的表现依然打不过那些专门微调过的小模型。
- 参数规模还是不够看,碰到稍微复杂一点的推理、长文本任务就有点力不从心。
不过GPT-2这一波已经把信号放出去了:只要继续加大规模,模型大概率还会"涌现"出更多意想不到的能力。这也直接推动了下一代GPT-3的诞生。
小结: GPT-2的核心思路其实就俩字------"加大"。参数怼到15亿、数据塞进40G,顺手把零样本和少样本学习这俩新玩法带出来了,让大家第一次看到不微调也能干活的模型长啥样,文本生成的自然度也上了一个台阶。缺点是零样本效果还不太稳,复杂任务依旧拉胯,规模上限也没真正摸到。但它最大的意义是把"大力出奇迹"这条路实锤了,为后面GPT-3的狂飙打好了地基。
3,GPT-3时代(2020-2022年)
上面谈到了GPT-2其实就是在GPT-1的基础上把参数和数据量往上怼,结果效果确实好了不少。那GPT-3的思路也很直接------既然加大管用,那就继续加,往死里加 。参数量从GPT-2的15亿直接飙到了1750亿 ,翻了100多倍,训练数据也从40G干到了接近570G(包括Common Crawl、Wikipedia、书籍等各种来源)。这一波下来,GPT-3不光是"更大"了,而是在能力上出现了质的飞跃。
3.1,In-Context Learning(上下文学习)
GPT-2的时候就已经展示了零样本和少样本学习的能力,但说实话效果还不太稳。到了GPT-3,这个能力被彻底拉满了,OpenAI给它起了个正式的名字叫In-Context Learning(上下文学习)。
简单来说就是:你不需要改模型的任何参数,只需要在提示词(prompt)里给它塞几个例子或者描述清楚任务,它就能直接干活。这跟传统的微调完全不一样------微调是要真的去改模型权重的,而上下文学习纯粹靠"读题"就能搞定。GPT-3把这个能力分成了三档:
- Zero-shot(零样本):啥例子都不给,直接说"帮我把这句话翻译成中文",它就翻了。
- One-shot(单样本):给一个例子,让它照着来。
- Few-shot(少样本):给几个例子,效果最好。
到了GPT-3这个规模,Few-shot的表现在很多任务上已经能跟那些专门微调过的模型打得有来有回了,有些任务甚至直接超过了。这就很恐怖了------一个通用模型,不做任何针对性训练,光靠"看几个例子"就能跟专用模型掰手腕。
3.2,涌现能力
GPT-3还带出了一个后来被反复讨论的概念------涌现能力(Emergent Abilities) 。意思是:当模型规模大到一定程度之后,会突然冒出一些小模型完全不具备的能力,而且这些能力不是渐进式提升的,更像是"突然开窍"。
比如GPT-2做简单的算术题基本是瞎蒙,但GPT-3突然就能做对不少了;GPT-2写代码基本是胡说八道,GPT-3居然能写出像模像样的代码片段。这些能力不是OpenAI专门训练出来的,而是模型"自己长出来的"。
打个比方:小孩子学说话,一开始就是蹦单词,突然有一天就能说整句话了,再过一阵子就能跟你讲道理了。 这个"突然"的过程就很像涌现------不是一点一点变好的,而是到了某个临界点一下子就通了。
这个发现对整个AI圈的影响非常大,因为它意味着:你没法通过小模型的表现来预测大模型能干啥。只有真的把模型做到那个规模,你才知道它会"涌现"出什么新能力。
3.3,GPT-3的规模和局限
GPT-3的具体参数如下:参数量1750亿,96层Transformer Decoder,训练数据约570G混合语料,上下文长度2048 tokens。
GPT-3在当时可以说是炸裂级别的存在,但它的问题也不少:
- 容易一本正经地胡说八道,生成的内容看着很像那么回事,但事实性经常翻车。
- 不太听话,你让它做A它可能给你整个B出来,指令遵循能力还不够强。
- 有时候会输出有害内容,比如带有偏见、歧视或者不当的言论,安全性没有保障。
- 只能通过API调用,普通用户根本接触不到,离"大众产品"还差得远。
小结: GPT-3把"大力出奇迹"这条路推到了一个新高度,1750亿参数带来了真正能打的上下文学习能力和各种涌现能力,让大家看到了通用人工智能的一丝曙光。但它本质上还是个"原始"的语言模型------能力很强但不太可控,像一个天赋异禀但没经过管教的天才少年,有本事但不太靠谱。这些问题,就留给后面的GPT-3.5来解决了。
4,GPT-3.5(2022年11月)
如果说GPT-3证明了"模型够大就能涌现出强大能力",那GPT-3.5要解决的问题就是:怎么让这个能力强大但不太听话的模型,变成一个真正好用、靠谱、安全的产品?
4.1,指令微调(Instruction Tuning)
GPT-3虽然能力很强,但有个很头疼的问题:它不太理解你到底想让它干嘛。你问它一个问题,它可能不回答你,反而继续往下编一段文字,因为它的本质就是"续写"------你给个开头,它接着往下写,至于你是在问问题还是在聊天,它其实分不太清。
所以GPT-3.5第一步就是做了指令微调(Instruction Tuning) ,也叫SFT(Supervised Fine-Tuning,有监督微调) 。做法很直接:找一批人类标注员,写一堆高质量的"指令-回答"对,然后拿这些数据去微调模型。
比如标注员会写这样的数据:
指令: 用一句话解释什么是光合作用。
回答: 光合作用是植物利用阳光、水和二氧化碳来制造养分并释放氧气的过程。
通过大量这样的数据训练之后,模型就学会了一件事:你给我指令,我就按你的要求来回答,而不是自顾自地往下编。这一步看起来简单,但效果立竿见影------模型一下子就从"自说自话的写作机器"变成了"能听懂指令的助手"。
4.2,RLHF(基于人类反馈的强化学习)
光做指令微调还不够。模型虽然学会了"听指令",但回答的质量参差不齐------有时候太啰嗦,有时候太敷衍,有时候还会输出一些不太合适的内容。所以GPT-3.5又加了第二步:RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)。
这个过程分三步走:
- 先用SFT微调出一个基础版本(上面说的那步)。
- 训练一个奖励模型(Reward Model):让模型对同一个问题生成多个回答,然后让人类标注员给这些回答排个序------哪个好哪个差。用这些排序数据训练出一个"打分器",它能自动判断一个回答的质量高低。
- 用强化学习(PPO算法)优化模型:让模型生成回答,奖励模型打分,模型根据分数调整自己的行为------得分高的回答方式多来点,得分低的少来点。
打个比方:SFT就像是老师教学生"题目要这么答",RLHF则是让学生写完作业之后,老师批改打分,学生根据分数不断改进自己的答题方式。 时间长了,学生就知道什么样的回答能拿高分了。
RLHF这一步的效果非常显著,它让模型学会了:
- 回答更有帮助:不再答非所问,而是真正解决你的问题。
- 更加安全:学会了拒绝不当请求,减少有害输出。
- 更符合人类偏好:回答的风格、详细程度、语气都更像一个靠谱的助手。
4.3,ChatGPT的诞生
2022年11月30日,OpenAI把经过指令微调和RLHF训练的GPT-3.5包装成了一个对话产品,取名ChatGPT,免费开放给所有人使用。
这一步看起来只是"套了个聊天界面",但它的意义远比技术本身要大得多:
- 第一次让普通人能直接跟大模型对话。之前GPT-3只有API,你得会写代码才能用。ChatGPT直接给你一个聊天框,打字就能聊,门槛降到了零。
- 5天注册用户破100万,2个月破1亿,成为历史上增长最快的消费级应用。
- 让全世界第一次真切感受到了AI的能力------它能写文章、写代码、翻译、总结、头脑风暴,几乎什么都能聊两句。
ChatGPT的爆火不是因为它的技术有多新(GPT-3.5的底层技术都是之前就有的),而是因为它第一次把这些技术组合成了一个人人都能用的产品。这就像智能手机之前触摸屏、GPS、摄像头都已经存在了,但iPhone把它们组合到一起,才真正改变了世界。
4.4,GPT-3.5的规模和局限
GPT-3.5的具体参数没有被OpenAI官方完全公开,但业界普遍认为:参数量与GPT-3相当(1750亿左右),但在训练流程上增加了代码数据的预训练(Codex)、指令微调(SFT)和RLHF三个关键步骤,上下文长度4096 tokens(后续版本扩展到16K)。
ChatGPT虽然火爆全球,但它的问题也很明显:
- 幻觉问题依然存在,会很自信地编造不存在的事实、论文、链接。
- 知识有截止日期,训练数据之后发生的事情它一概不知。
- 只能处理文本,看不了图片、听不了语音,是个纯文字选手。
- 上下文窗口有限,聊久了前面说的话就"忘了"。
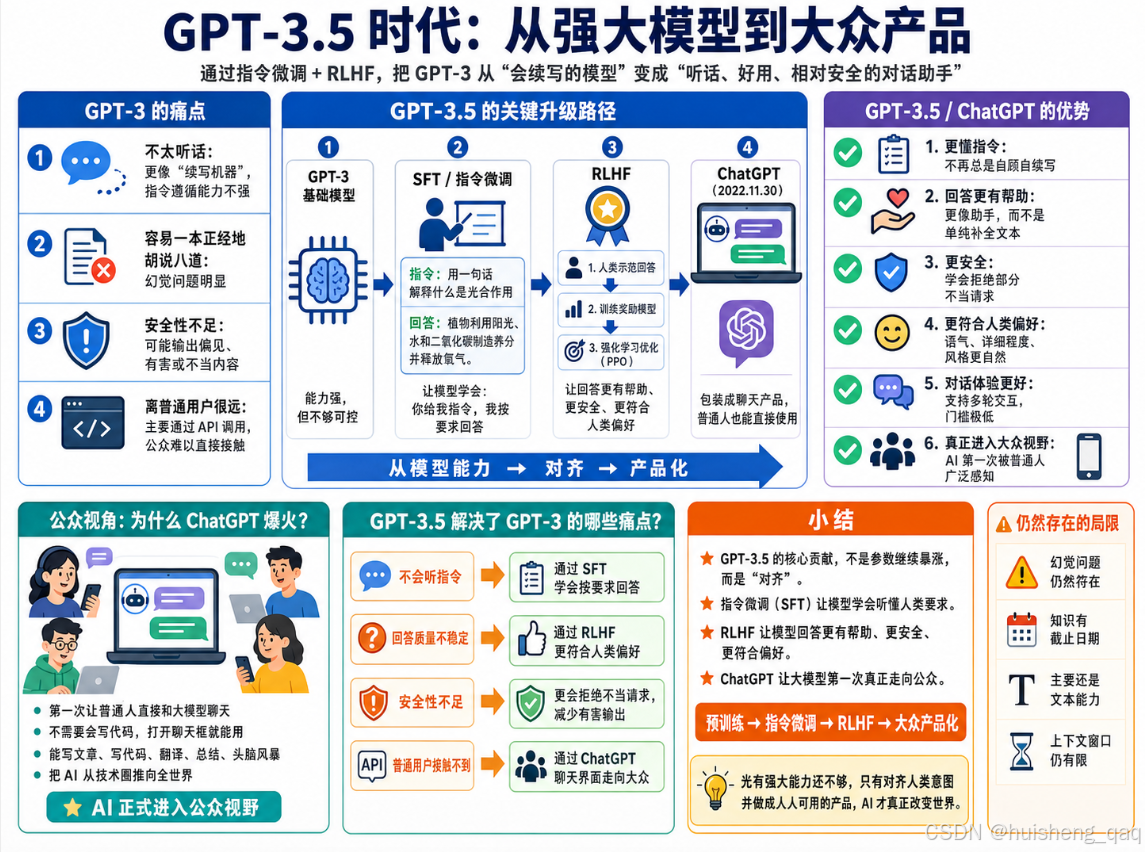
小结: GPT-3.5和ChatGPT的核心贡献不在于模型本身有多大的突破,而在于通过指令微调和RLHF这套"调教"流程,把一个原始的语言模型变成了一个听话、好用、相对安全的对话助手,再加上一个极低门槛的产品形态,一举把大模型从技术圈推向了全世界。它证明了一件事:光有强大的模型能力还不够,还得让模型"对齐"人类的意图和价值观,才能变成真正有用的产品。 这套"预训练 → 指令微调 → RLHF"的三步走流程,也成了后来几乎所有大模型的标准训练范式。
5,GPT-4时代(2023-2024年)
ChatGPT火了之后,全世界都在等OpenAI的下一手。2023年3月,GPT-4 正式发布。跟前面几代不太一样,GPT-4这次没走"参数无脑加大"的老路,而是在多模态、推理能力、可靠性这几个方向上做了全面升级。这一次OpenAI对训练细节披露得非常少,具体参数量、训练数据规模和架构细节都没有公开,更多是通过能力评测和实际体验来展示GPT-4相比GPT-3.5的提升。
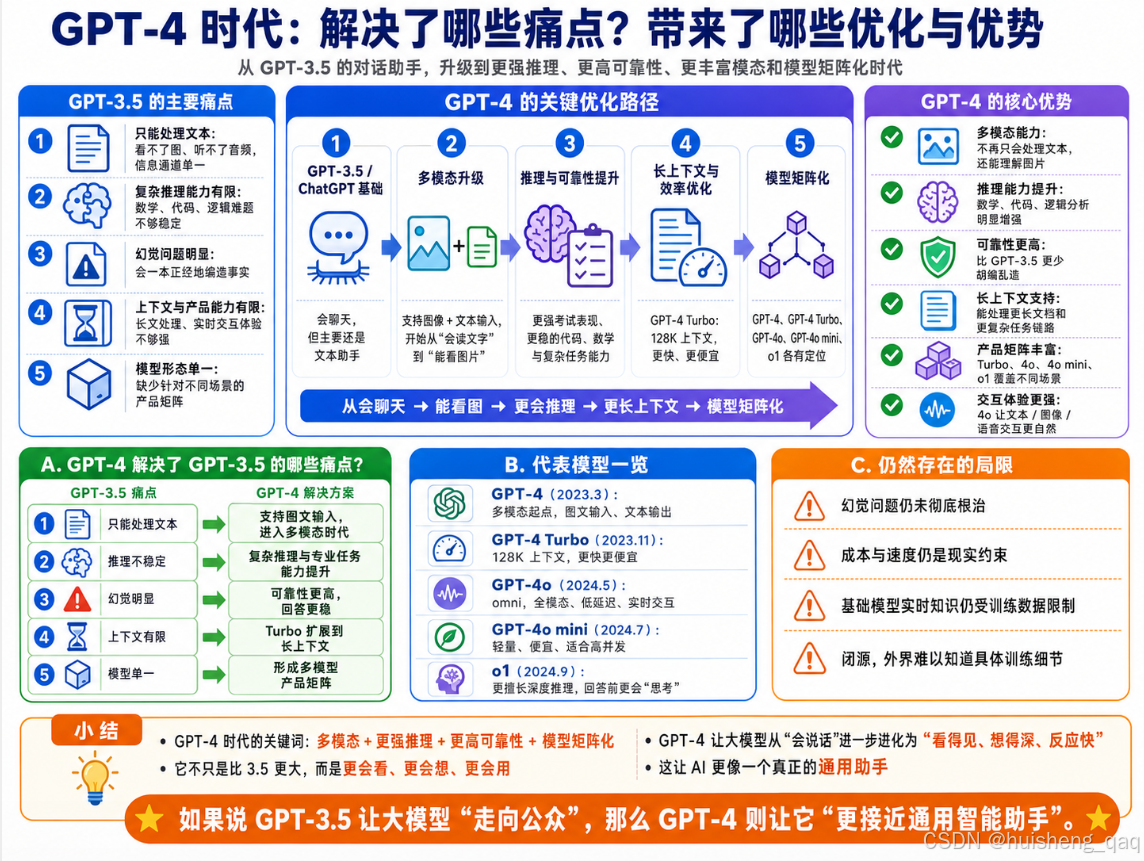
5.1,多模态能力
GPT-4最大的一个变化是:它不再只会看文字了,还能看图 。这就是所谓的多模态(Multimodal)------能同时处理文本、图片等多种形式的输入。
比如你可以丢一张照片给它,它能告诉你图里是啥、发生了什么;丢一张手写的草稿纸,它能帮你把上面的公式识别出来;甚至丢一张meme图,它还能解释笑点在哪。这个能力直接把大模型的应用场景拓宽了一大截------从"纯文本助手"变成了"看得见的助手"。
需要注意的是,GPT-4初代的多模态重点是**"图像 + 文本输入,文本输出"**。它已经能看图了,但还不是后面GPT-4o那种文本、语音、图像实时交互的原生全模态体验。GPT-4初代更像是"你给我看张图,我用文字告诉你我看到了啥"。
打个比方:GPT-3.5像一个只能用文字跟你交流的笔友,GPT-4则像一个能跟你面对面、看着你手里东西聊天的朋友。 信息通道一下子多了好几条。
5.2,推理能力的大幅提升
GPT-4在复杂推理上也有明显进步。很多人拿它去考各种标准化考试,结果非常夸张:
- 美国律师资格考试(UBE):GPT-3.5只能排在倒数10%,GPT-4直接冲到了前10%。
- SAT、GRE、AP考试:基本都能拿到优秀水平的分数。
- 数学、代码、逻辑推理:相比GPT-3.5有质的飞跃。
这也说明一件事:当模型规模 + 训练数据 + 对齐方法都做到位之后,模型的"智力"会继续往上涨。GPT-4这时候已经不只是"能说会道",而是真的能帮你分析问题、解决问题了。换句话说,GPT-4相比GPT-3.5,不只是"说得更像人",而是在复杂任务、专业考试、代码和逻辑分析上都有了更强的稳定性。
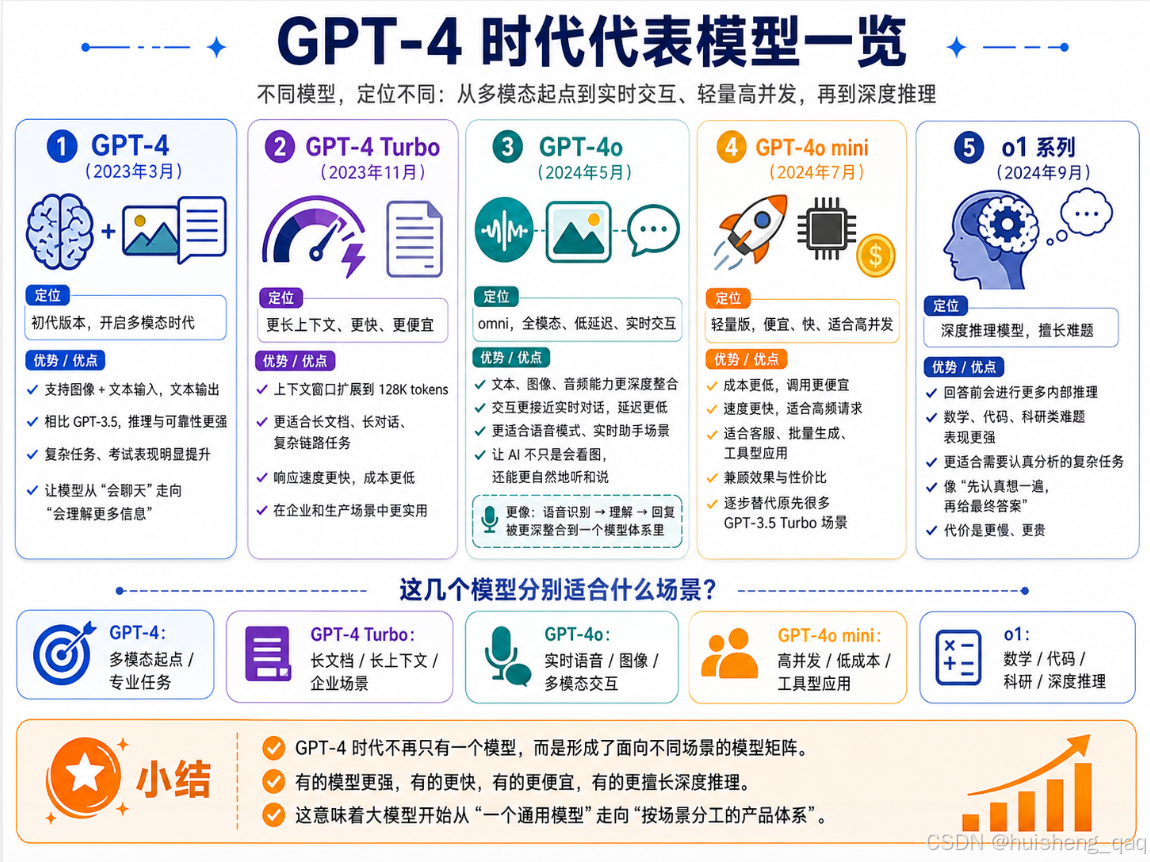
5.3,代表模型一览
GPT-4这一代OpenAI陆续放出了好几个版本,定位各有侧重,这里列几个比较有代表性的:
- GPT-4(2023年3月):初代版本,开启多模态时代。
- GPT-4 Turbo (2023年11月):上下文窗口直接拉到128K tokens,相当于能一次性读一本中篇小说,而且推理速度更快、价格更便宜。
- GPT-4o (2024年5月):o代表"omni"(全能) ,这是真正意义上的原生多模态模型------文本、图像、音频全部在一个模型里端到端处理。在GPT-4o之前,很多语音交互体验更像是"语音识别 → 文本模型处理 → 语音合成"的流水线。而GPT-4o的定位是omni,也就是把文本、图像、音频的理解和生成能力更深地整合到一个模型体系中,因此延迟更低,交互更接近实时对话。这个版本也是ChatGPT"语音模式"背后的主力模型。
- GPT-4o mini(2024年7月):4o的轻量版,便宜、快,适合高并发场景,替代了原来的GPT-3.5 Turbo。
- o1系列 (2024年9月):这个比较特殊,它不是单纯追求更快回答,而是被训练成在回答前花更多时间进行内部推理,尤其适合数学、代码、科研等复杂任务。普通模型更像"马上回答",o1更像"先认真想一遍,再给你最终答案"。代价是响应速度更慢、成本更高,但在难题上的表现暴涨。可以理解为把"想清楚再说话"这件事做到了模型里。
5.4,GPT-4的规模和局限
GPT-4的具体参数量、训练数据规模和架构细节,OpenAI并没有公开。所以网上流传的"1.8万亿参数""MoE架构"等说法不建议当成确定事实。更稳妥地说,GPT-4的训练细节整体比较保密,外界主要是通过公开评测和实际体验来判断它相比GPT-3.5的提升。上下文长度从初代的8K/32K逐步扩展到了GPT-4 Turbo的128K。
即便牛成这样,GPT-4也不是没毛病:
- 幻觉问题依然没根治,只是比3.5好一些,该编还是会编。
- 推理成本高,尤其是o1这种思考型模型,一次请求能烧不少token。
- 闭源,外面的人不知道它具体怎么训的,只能通过API用。
- 实时知识依然受限:基础模型本身仍然依赖训练数据。后来ChatGPT可以通过搜索、检索、工具调用等产品能力补充实时信息,但这属于产品和工具层的增强,不是GPT-4本体天然知道最新信息。
小结: GPT-4时代的核心关键词是多模态、更强推理、更高可靠性和模型矩阵化 。从GPT-4初代的图文理解,到GPT-4 Turbo的长上下文和低成本,再到GPT-4o的文本/语音/图像实时交互,以及o1系列开启的深度推理路线,OpenAI在这一代把大模型的能力边界拓展到了多个方向。如果说GPT-3.5/ChatGPT让大模型"会说话、能聊天、走向公众",那么GPT-4时代就是让它进一步变得看得见、想得深、反应快、用得广。这也意味着大模型开始从单纯的文本助手,逐渐走向真正的通用智能助手。
6,GPT-5系列时代(2025年-2026年)
2025年,GPT-5 正式发布,这是OpenAI在GPT-4之后最大的一次升级。跟GPT-4那种"放出一堆版本让你挑"的策略不一样,GPT-5更像是一个统一模型系统,而不是单纯一个模型。它把快速回答、深度推理和自动路由整合到一起,让用户不用再手动纠结"这个问题该用4o还是o1"------GPT-5会自己判断该用哪种模式。
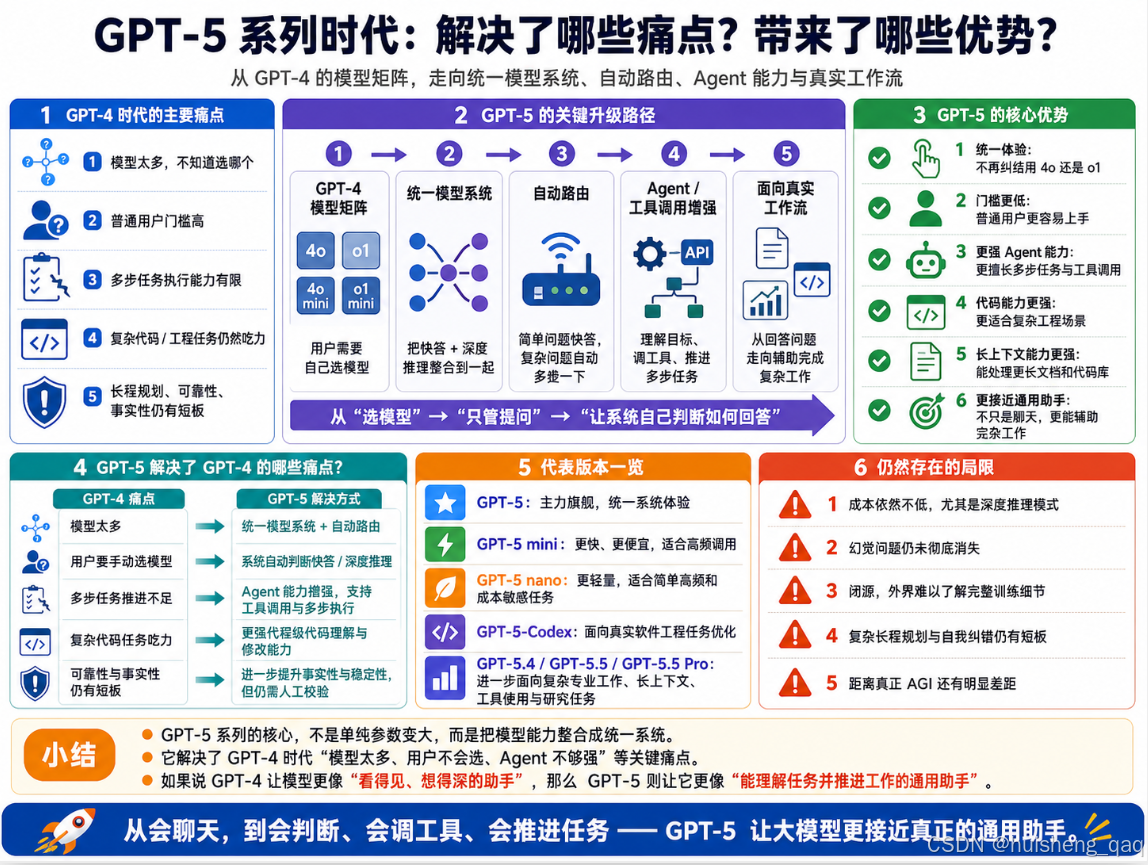
6.1,统一模型 + 自动路由
GPT-4时代用户有一个很实际的痛点:模型太多,不知道该选哪个。简单问题用4o就行,难题可能要切到o1,代码任务又可能要选更适合coding的模型。对专业用户来说,这还能理解;但对普通用户来说,这个门槛太高了。
GPT-5的核心变化之一,就是把这种选择尽量藏到系统内部。它可以理解为由**"快速响应模型 + 深度推理模型 + 自动路由器"** 组成:简单问题快速回答,复杂问题自动进入更深的推理模式。对用户来说,你只管问,它自己判断要不要"多想一下"。
打个比方:GPT-4那种选模型像是自己去选餐厅------得知道哪家做啥好吃;GPT-5则像是一个全能大厨,你说想吃啥,他自己判断该用啥锅、啥火候。 门槛再一次被降低了。
6.2,从回答问题到执行任务
GPT-5的能力提升,不只是"回答得更聪明",而是更接近"能帮你把事情往前推进":
- 幻觉问题进一步缓解:相比前代模型,GPT-5在事实性和可靠性上继续提升,但幻觉并没有被彻底根治,重要信息还是需要人工校验。
- Agent能力显著增强:能更好地理解任务目标、使用工具、调用外部API、执行多步任务,为Agent类应用打下了更扎实的基础。
- 代码能力:在实际工程场景(不是刷题那种)中的表现明显更强,能完成更复杂的代码重构、多文件修改等任务。
- 上下文进一步拉长,能一次性处理非常长的文档或代码库。
6.3,代表版本
GPT-5系列陆续放出了多个定位不同的版本:
- GPT-5:主力旗舰模型,在ChatGPT中体现为统一系统体验,能在快答和深度思考之间自动切换。
- GPT-5 mini:更快、更省成本,适合明确任务和高频调用场景。
- GPT-5 nano:更小、更轻量,适合简单、高频、极度关注成本和延迟的任务。
- GPT-5-Codex:面向真实软件工程任务优化,更适合复杂代码修改、代码审查、多文件重构和长程coding agent场景。
- GPT-5.4 / GPT-5.5 / GPT-5.5 Pro:2026年继续演进的版本,更强调复杂专业工作、长上下文、工具使用、研究和文档型任务。
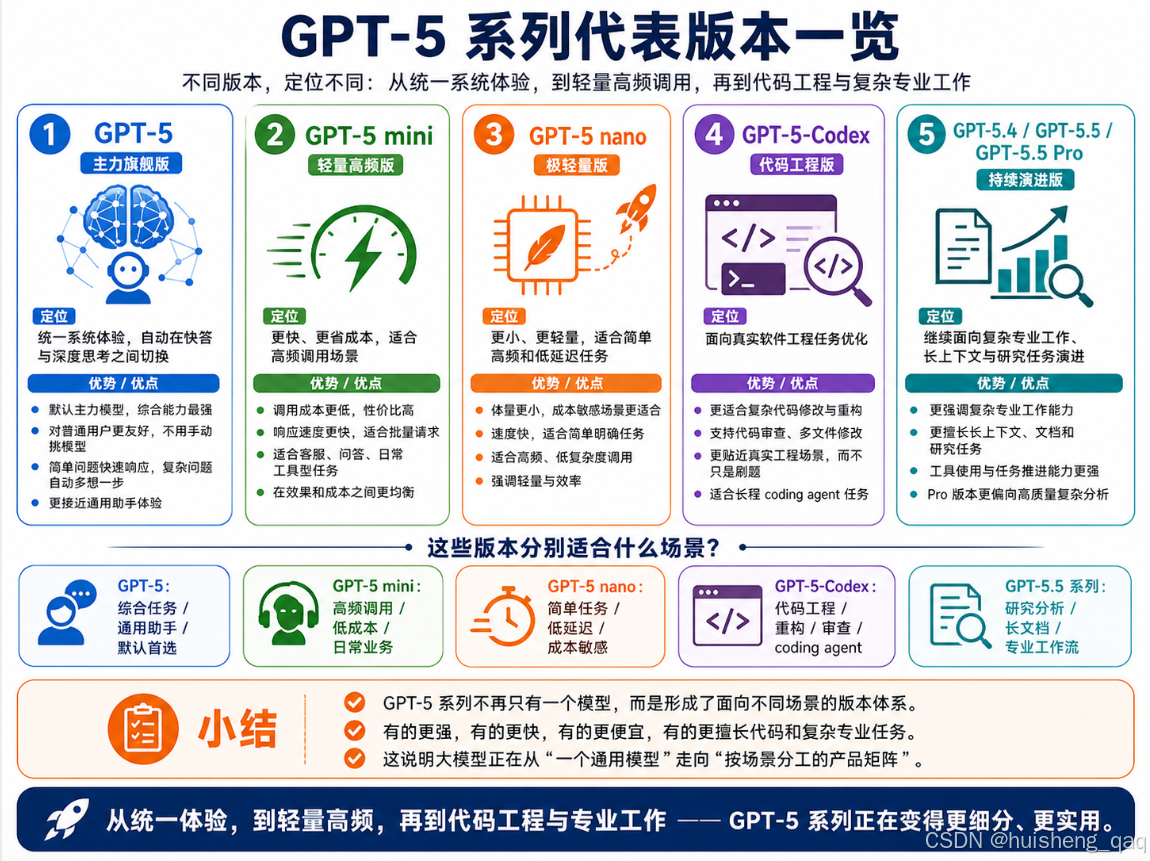
6.4,GPT-5.5:面向真实工作的进一步升级
到了2026年,OpenAI又发布了GPT-5.5。相比GPT-5,GPT-5.5的重点不是"再讲一个新概念",而是继续把模型往真实工作流里推进。
它更强调几个方向:
- 复杂专业工作:比如写代码、研究、数据分析、金融建模、文档处理等,在这些场景下的稳定性和完成度都有提升。
- 更强工具使用能力:模型更擅长理解任务目标、调用工具、检查结果并持续推进,而不是"调一次就完事"。
- 更长上下文能力:能够处理更长的资料、文档和代码上下文。
- Agent化能力增强:不只是回答问题,而是更接近"能执行任务的工作伙伴"。
如果说GPT-5是"统一快答和深度思考",那么GPT-5.5更像是把这个统一系统继续推向专业工作场景:让AI不只是能聊、能想,还能更稳定地完成复杂任务。
6.5,GPT-5系列的意义和局限
GPT-5系列的参数和架构细节OpenAI继续保密,但从产品层面能明显感觉到:它不再只是一个"聊天模型",而是更接近一个能理解任务、调用工具、进行多步推理,并辅助完成复杂工作的智能助手底座。
当然它也不是万能的:
- 成本依然不低,尤其是深度推理、长上下文和复杂工具调用场景。
- 幻觉仍然存在,事实性提升了,但不能完全替代人工校验。
- 闭源依旧,外界无法知道完整训练细节,只能围绕API和产品生态使用。
- 真正的AGI还没到,复杂的长程规划、自我纠错、持续学习这些能力依然有短板。
- Agent落地仍然依赖工程系统,模型能力增强了,但真正做产品还需要权限、工具、数据、记忆、审计、安全机制等配合。
小结: 如果把整个GPT系列的演进串起来看,会发现一条很清晰的主线:GPT-1跑通Transformer Decoder-only + 预训练路线 → GPT-2证明scale up有效 → GPT-3出现上下文学习和涌现能力 → GPT-3.5通过指令微调和RLHF完成对齐,并借助ChatGPT走向大众 → GPT-4扩展多模态、强推理和模型矩阵 → GPT-5统一快答与深度思考,强化代码、工具调用和Agent能力 → GPT-5.5继续走向真实专业工作流。 每一代解决的,都是上一代留下来的核心痛点。大模型也从最早"会续写文字的神经网络",一步步演进成"能看、能听、能想、能调用工具、能辅助完成复杂任务的通用助手"。不过它还不是万能的:成本、幻觉、闭源、长程规划、持续学习等问题依然存在。下一阶段的关键词,大概率会继续围绕Agent、多模态、端侧部署、长上下文、工具调用和持续学习展开。