📌 本文完整内容、代码示例和详细文档都在我的 GitHub 仓库
- 📄 文章地址 : Benchmark 污染检测
- 📦 Repo 总地址 : david-share
⭐ 欢迎 Star,你的支持是我持续分享的动力!
Benchmark 污染检测:如何判断 LLM 是否见过测试数据
Author: 魏新宇 (Xinyu Wei)
概述
一句话 :CoDeC(Contamination Detection via Context)通过测量 In-Context Examples 对模型置信度的影响来检测 LLM 是否在 Benchmark 数据上训练过------如果给提示反而让模型更不自信,说明它很可能记住了答案。
当模型厂商宣称"MMLU 93 分"或"GPQA Diamond 67 分"时,你怎么知道这些分数反映的是真实能力还是训练数据泄露?CoDeC 提供了一个实用的、自动化的答案。
为什么这件事很重要
开源模型生态面临信任危机。模型被普遍地在 MMLU、GSM8K、GPQA 和 AIME 等 Benchmark 上评估------但越来越多的证据表明,这些 Benchmark 或与之非常相似的数据出现在训练语料中。这破坏了整个评估流水线:
- 模型选型变得不可靠:一个在被污染的 Benchmark 上得 90 分的模型,在面对真正新颖的生产输入时可能表现不佳
- Benchmark 军备竞赛浪费资源:团队追逐越来越高的测试分数,而这些测试可能已经无法衡量它们声称要衡量的能力
- 下游决策被误导:企业客户在 Qwen、Gemma、Llama 或闭源 API 之间做选择时,依赖的 Benchmark 对比可能比较的是记忆能力而非推理能力
现有的污染检测方法(N-gram Overlap、Min-k% Prob)要么太粗糙(文本匹配在改写后失效),要么被模型能力混淆。CoDeC 提供了一个不同的信号:In-Context Learning 与记忆之间的交互作用。
在 Azure 上运行
本文所有实验均可在单台 Azure VM 上复现。
推荐 SKU
| 组件 | 规格 |
|---|---|
| VM SKU | Standard_NC40ads_H100_v5 |
| GPU | 1× NVIDIA H100 80 GB SXM |
| vCPU | 40 |
| RAM | 320 GB |
| OS | Ubuntu 22.04 / 24.04 |
单台 H100 VM 即可满足需求,因为 CoDeC 只需要 Forward Pass(不需要训练,不需要梯度计算)。80 GB VRAM 可以轻松容纳 BF16 下最大约 30B 参数的模型,或 INT4 Quantization 下最大约 70B 的模型。
技术栈全景
| Category | Technique | What It Does | Impact | Detail Section |
|---|---|---|---|---|
| Detection | CoDeC | 对比有/无 Context 时的 Log-Likelihood | 核心方法------每个样本 2 次 Forward Pass | How It Works |
| Inference | HF Transformers | 模型加载 + Log-Prob 提取 | 基线推理,7B BF16 约 50 tok/s | Implementation |
| Precision | BF16 | 半精度推理 | 27B 模型约占 54 GB VRAM | Implementation |
| Acceleration | vLLM(可选) | 大规模评估的 Batched Inference | 1000+ 样本时约 10 倍吞吐量 | Scaling Up |
资源分布
erlang
┌─────────────────────────────────────────────────────────────┐
│ H100 80 GB VRAM │
├─────────────────────────────────────────────────────────────┤
│ Model Weights(7B BF16) │ ~14 GB │ ██████░░░░ │
│ KV Cache(2048 context) │ ~2 GB │ █░░░░░░░░░ │
│ Activations(仅 Forward) │ ~1 GB │ ░░░░░░░░░░ │
│ Available │ ~63 GB │ ████████░░ │
├─────────────────────────────────────────────────────────────┤
│ 总占用: ~17 GB / 80 GB (21%) │
│ 最大约 30B BF16 模型可在单卡 H100 上舒适运行 │
└─────────────────────────────────────────────────────────────┘更大的模型(70B+)需使用 INT4 Quantization 或多卡配置(Standard_NC80adis_H100_v5,2× H100)。
工作原理
核心直觉
该方法利用了一个关于记忆如何与 In-Context Learning 交互的简单观察:
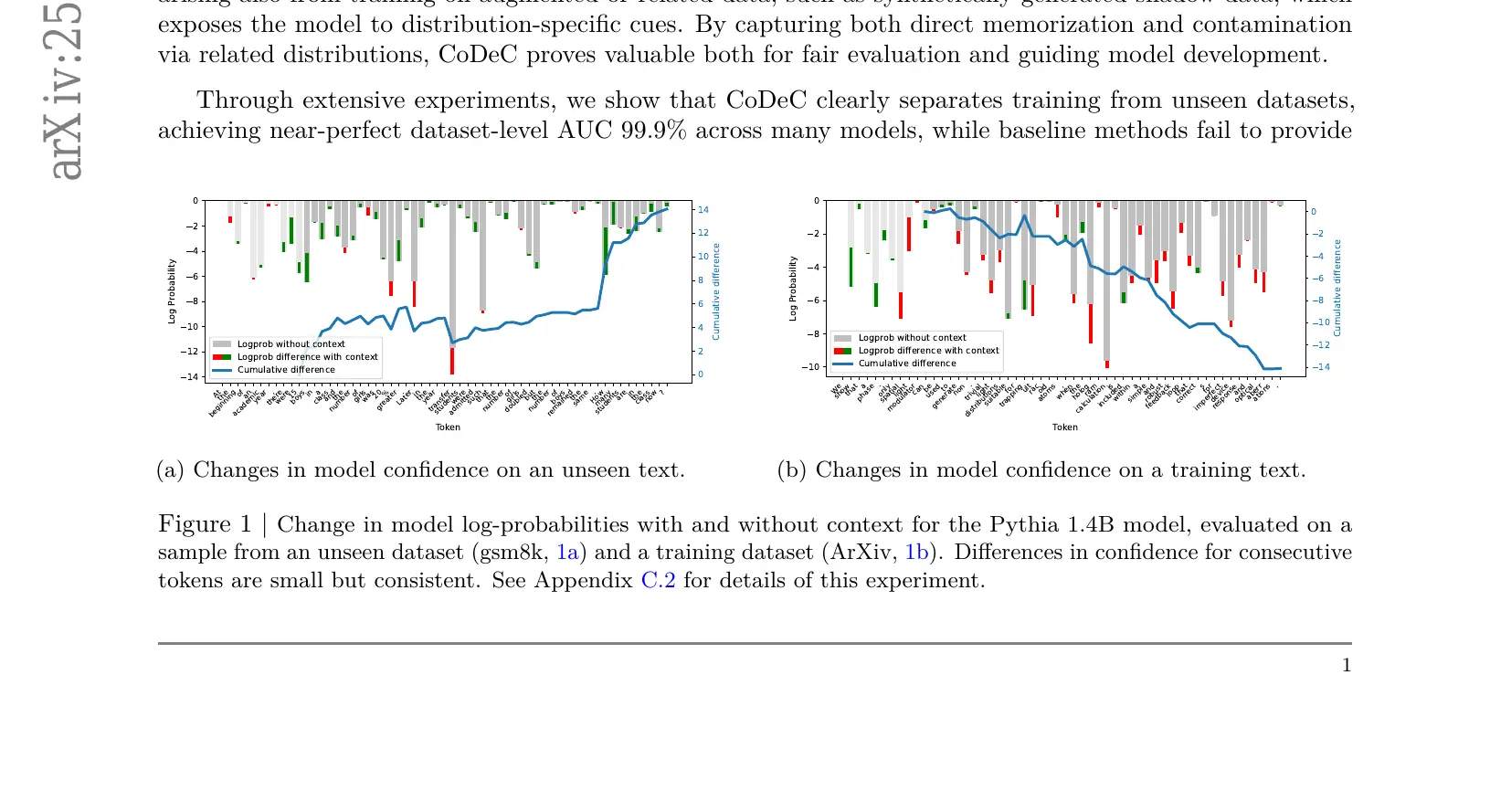
下图来自原始论文(Zawalski et al., 2025)。左图:未见过的数据(GSM8K)------ Context 有帮助,累积差异上升。右图:训练数据(ArXiv)------ Context 产生干扰,累积差异下降。来源:Figure 1, arXiv:2510.27055, CC-BY 4.0.
makefile
场景 A: 模型在训练期间 未见过 Benchmark 数据
┌──────────────┐ ┌──────────────────┐ ┌──────────────┐
│ 目标样本 │ ──► │ 模型基于 │ ──► │ 置信度: │
│(无 Context) │ │ 通用知识预测 │ │ 基线水平 │
└──────────────┘ └──────────────────┘ └──────────────┘
┌──────────────┐ ┌──────────────────┐ ┌──────────────┐
│ Context │ ──► │ 模型从 Context │ ──► │ 置信度: │
│ Examples + │ │ 学习分布特征 │ │ 更高 ↑ │
│ 目标样本 │ │ │ │(ICL 有帮助)│
└──────────────┘ └──────────────────┘ └──────────────┘
结果: Δ = 有Context - 无Context > 0 → 未被污染 ✓
场景 B: 模型在训练期间 见过 Benchmark 数据
┌──────────────┐ ┌──────────────────┐ ┌──────────────┐
│ 目标样本 │ ──► │ 模型从记忆中 │ ──► │ 置信度: │
│(无 Context) │ │ 回忆答案 │ │ 很高 │
└──────────────┘ └──────────────────┘ └──────────────┘
┌──────────────┐ ┌──────────────────┐ ┌──────────────┐
│ Context │ ──► │ Context 干扰了 │ ──► │ 置信度: │
│ Examples + │ │ 记忆模式 │ │ 更低 ↓ │
│ 目标样本 │ │ │ │(产生干扰) │
└──────────────┘ └──────────────────┘ └──────────────┘
结果: Δ = 有Context - 无Context < 0 → 已被污染 ✗算法步骤
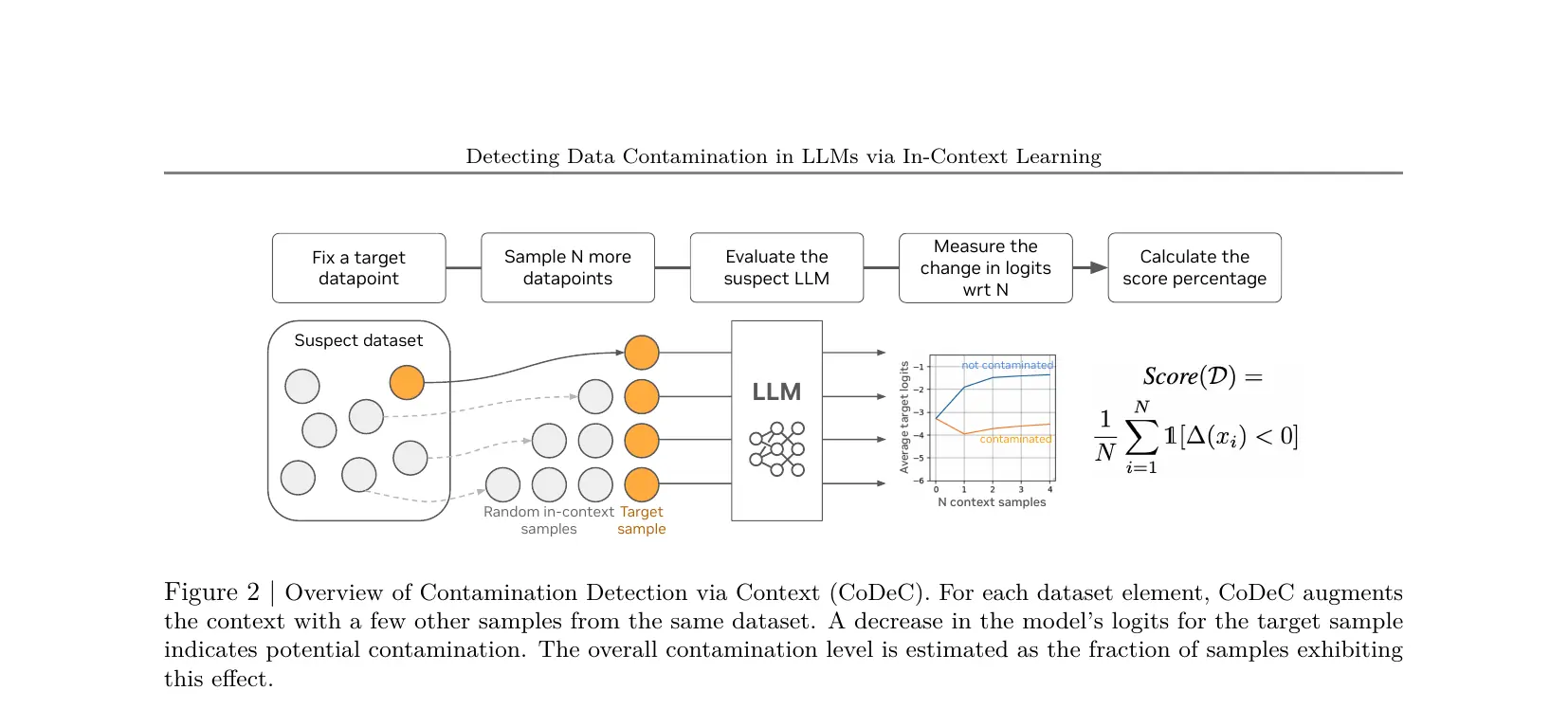
下图展示了完整的 CoDeC Pipeline:对每个样本,分别计算有/无 Context 时的 Log-Probabilities,然后比较。来源:Figure 2, Zawalski et al., 2025, arXiv:2510.27055, CC-BY 4.0.
论文中的正式算法和 CoDeC Score 公式:

来源:Section 2.3, Zawalski et al., 2025, arXiv:2510.27055, CC-BY 4.0.
用纯文本表述,步骤如下:
对数据集 D 中的每个样本 x:
- 计算基线 Log-Likelihood:
log p(x)--- 模型仅看到 x - 从 D 中抽取一个 Context Example c(排除 x)
- 计算上下文 Log-Likelihood:
log p(x | c)--- 模型先看 c 再看 x - 比较:如果
log p(x) > log p(x | c),标记为已污染(score = 1)
数据集级别的 CoDeC Score 就是被标记样本的比例:
scss
CoDeC(D) = (1/N) × Σ 𝟙[log p(xᵢ) > log p(xᵢ | cᵢ)]"给 Context"到底是什么意思?
一个常见的第一反应是:"只给一道同数据集的裸题当提示------这不是有点牵强吗?"
重要的是理解 CoDeC 不是 给模型提示、答案或解题思路。它只是在目标文本前面拼接一条同数据集的原始文本。以 GSM8K 为例,有三道题:
css
题 A: "Janet has 3 apples. She buys 2 more. How many does she have?"
题 B: "A train travels 60 miles in 2 hours. What is its speed?"
题 C: "Tom has 5 dogs and 3 cats. How many pets does he have?"测试题 B 时:
不给 Context --- 模型直接看到:
csharp
A train travels 60 miles in 2 hours. What is its speed?给 Context --- 随机抽到题 A,拼在前面:
csharp
Janet has 3 apples. She buys 2 more. How many does she have?
A train travels 60 miles in 2 hours. What is its speed?模型不是在"做题" 。它在做语言建模:给定前面所有 Token,预测每个 Token 的概率。我们只测量题 B 的 Token Log 概率在有/无题 A 前缀时的变化。
信号是微弱但真实的:Attention 机制从 Context 中捕捉到分布线索(数学词汇、提问句式模式),从而微调 Token 预测。对于未见过的数据,这些线索帮助校准。对于记忆过的数据,这些线索产生干扰。
局限 :当数据集高度多样时,这个信号天然很弱。如果题 A 是关于苹果的、题 B 是关于火车的,分布重叠很小。这就是为什么 CoDeC 在同质化数据集(全是数学题、全是代码题)上信号强,而在混合领域数据集(如 MMLU-Pro)上退化到约 50%(接近随机)。
Ground Truth 是什么?
没有单独的"答案"。目标文本本身就是 Ground Truth。
模型在每个位置做 Next-Token Prediction:
css
位置 0: 输入 "A" → 模型输出 P(next_token) → 我们查看: P("train") = ?
位置 1: 输入 "train" → 模型输出 P(next_token) → 我们查看: P("travels") = ?
位置 2: 输入 "travels" → 模型输出 P(next_token) → 我们查看: P("60") = ?
位置 3: 输入 "60" → 模型输出 P(next_token) → 我们查看: P("miles") = ?在每个位置,模型生成一个覆盖整个词表的概率分布。我们提取原始文本中实际出现的下一个 Token 的 Log 概率。这些 Log 概率的平均值就是"置信度"分数。
这是语言建模的基本操作------不需要生成、不需要采样、不需要答案。任何文本都可以这样评估。
核心逻辑仅 4 行
整个检测算法精简为:
python
# 第 1 步: Baseline --- 模型仅看目标文本
lp_baseline = get_logprobs(model, tokenizer, target)
# 第 2 步: 带 Context --- 在前面拼接同数据集的一个样本
lp_context = get_logprobs(model, tokenizer, context + "\n\n" + target)
# 第 3 步: 比较 target 部分的平均 Log 概率(跳过前 10 个噪声 Token)
baseline_conf = mean(lp_baseline[10:])
context_conf = mean(lp_context[-len(lp_baseline):][10:])
# 第 4 步: 判定
contaminated = (baseline_conf > context_conf) # 无 Context 时更自信 = 有嫌疑两次 Forward Pass,两个浮点数取平均,一次大小比较。不需要训练、不需要梯度、不需要生成。
分数解读
| CoDeC Score | 解读 |
|---|---|
| > 80% | 强污染证据------模型很可能在此数据上训练过 |
| 60--80% | 灰色地带------可能是部分污染、训练中包含类似数据、或模型能力较强 |
| < 60% | 无污染证据------模型可能在泛化 |
关键注意事项 :始终与已知训练数据干净的参考模型(如 Pythia)进行对比。如果所有模型在某个 Benchmark 上都得 45%,那是数据集特性,不是污染证据。如果一个模型得 85% 而其他都在 40%,那个模型值得怀疑。
为什么 Context 会干扰记忆(理论基础)
论文从 Loss Landscape 角度给出了解释:
- 记忆过的数据 处于 Loss Landscape 的尖锐局部最小值中。模型对精确的 Token 序列过拟合了。添加 Context Examples 相当于施加扰动,将模型推出这个尖锐最小值,导致 Loss 增加(置信度下降)。
- 未见过的数据 处于 Loss Landscape 的平坦区域。模型没有过拟合,因此同样的扰动(Context Examples)帮助它学习局部分布,导致 Loss 减少(置信度上升)。
这类似于 Generalization Theory 中著名的 Sharp-vs-Flat Minima 区分(Hochreiter & Schmidhuber, 1997; Keskar et al., 2017):Sharp Minima 对应记忆,Flat Minima 对应泛化。CoDeC 利用 In-Context Learning 作为这种几何特性的廉价探针。
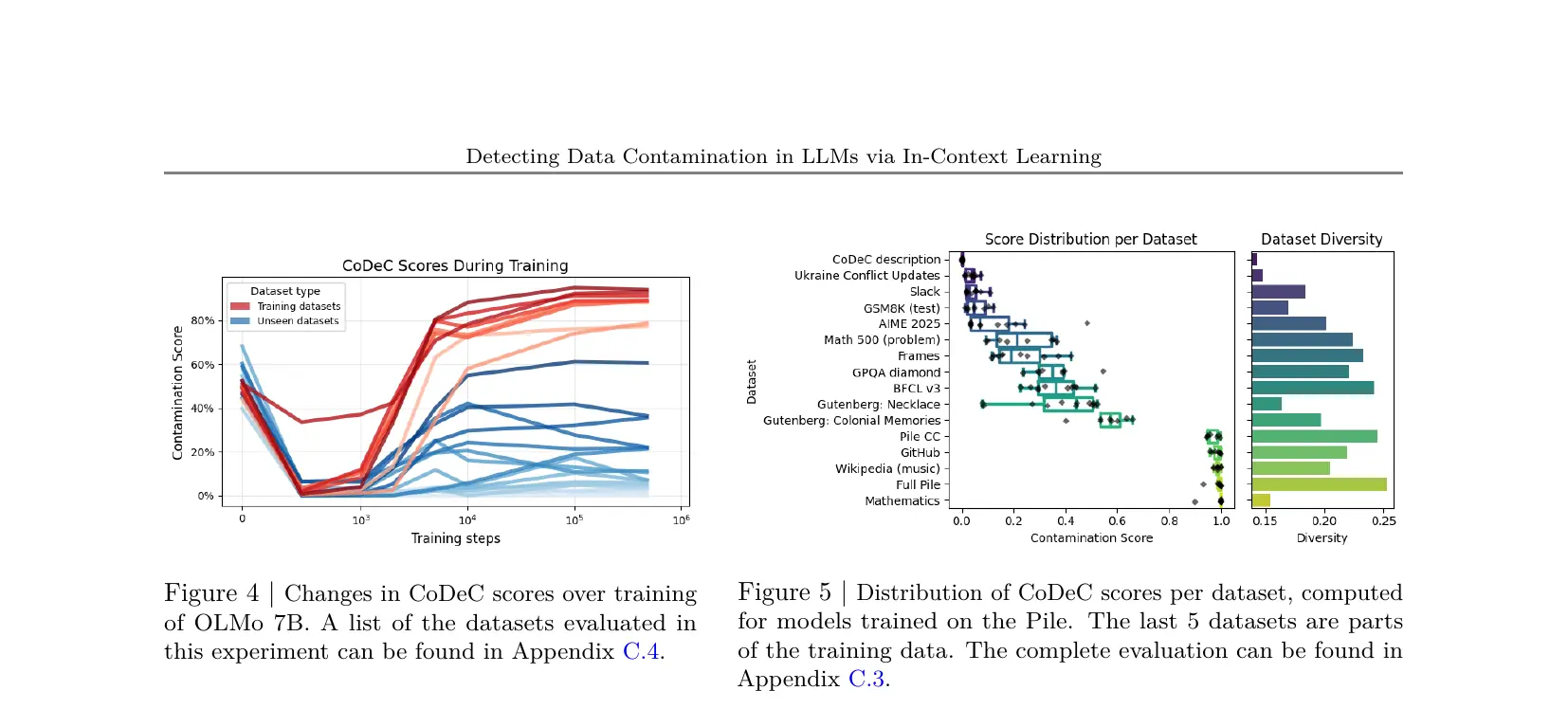
下图展示了 CoDeC Score 在训练过程中的演变(左:OLMo 7B,训练数据集的 Score 在 1k-10k 步时急剧上升)、数据集分布和多样性相关性(中、右)、以及 Finetuning 期间的污染增长(下)。来源:Figures 4, 5, 6, arXiv:2510.27055, CC-BY 4.0.

与其他方法的对比
| 方法 | 需要训练数据? | 信号来源 | 优势 | 劣势 |
|---|---|---|---|---|
| N-gram Overlap | 是(需要训练语料) | 精确文本匹配 | 简单,匹配到即为定论 | 任何改写都会失效 |
| Min-k% Prob | 否 | 低概率 Token 比例 | 快速,单次 Forward Pass | 被模型能力混淆------更强的模型天然低概率 Token 更少 |
| Membership Inference | 需要 Shadow Model | 训练/测试分布差异 | 理论基础扎实 | 昂贵,需要训练 Shadow Model |
| CoDeC | 否 | ICL 与记忆的交互 | 实用、自动化、模型无关 | 格式敏感,60-80% 灰色地带大 |
CoDeC 的关键优势:只需要目标模型的 Log Probabilities 和任意 Benchmark 数据集。不需要访问训练数据、不需要 Shadow Model、不需要 Fine-tuning。
真实发现
说明 :本节数据来自原始论文(Zawalski et al., 2025, arXiv:2510.27055,图 3-5 和表 1)。我们的独立 GPU 实验验证请参见下方我们的实验章节。
跨模型分析(来自原始论文,40+ 模型)
原始论文在多个模型家族中测试了从 410M 到 56B 参数的模型。
下图将 CoDeC 与 Baseline 方法(Vanilla Loss、Min-K%、Zlib Ratio)进行对比。CoDeC 实现了接近完美的分离(AUC 99.9%),而 Baseline 方法失败。来源:Figure 3 和 Table 1, arXiv:2510.27055, CC-BY 4.0.
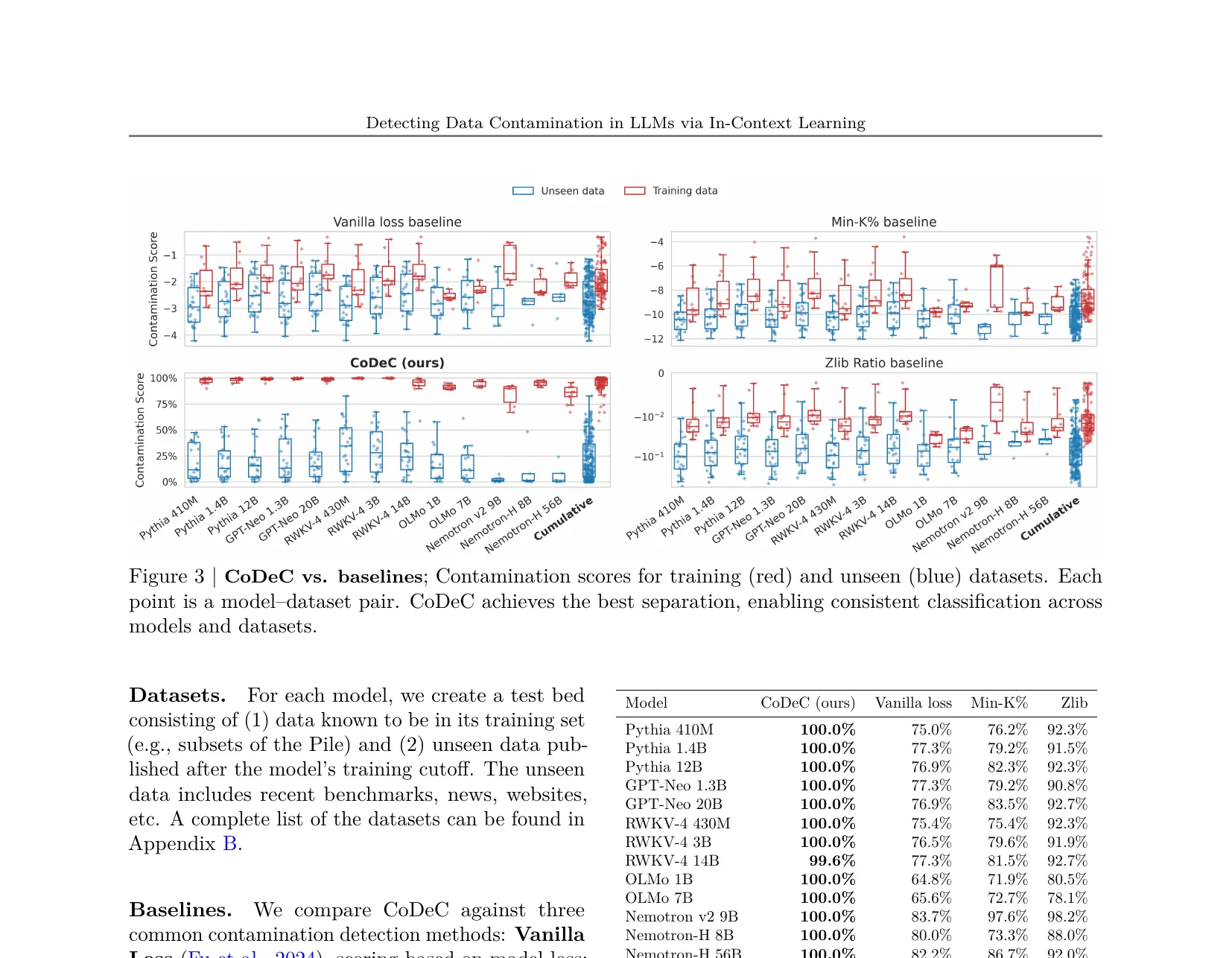
已知训练数据(Wikipedia、GitHub、Common Crawl):
- 所有模型的 CoDeC Score 一致**> 95%**------该方法可靠地检测已知污染
已知未见过的 Benchmark(GPQA Diamond、AIME 2024):
- 大多数模型得分在 30--55%------与训练数据得分明显分离
- 关键发现:Qwen 家族模型在多选题 Benchmark(MMLU、GPQA)上的得分一致高于 Gemma 模型,表明无论是否存在污染,该家族对 Benchmark 格式有更强的亲和力
异常模型(GPT-OSS 20B):
- 在所有 数据集上得分 > 99%,包括明确不在其训练数据中的数据集
- 这表明该模型经过了重度 RLHF/对话优化,到了正常语言建模行为被破坏的程度------这是由极端 Post-Training 导致的 CoDeC False Positive
实用解读指南
论文建议采用基于参考的方法而非绝对阈值:
- 纳入一个已知训练数据干净的模型(如 Pythia)作为 Baseline
- 对所有模型在目标 Benchmark 上运行 CoDeC
- 标记任何偏离 Baseline 分布超过 20 个百分点的模型
- 对被标记的模型,交叉检查准确率:高准确率 + 高 CoDeC = 强污染信号
我们的实验:在 H100 上的独立验证
我们在 Azure H100 NVL(95 GB)VM 上独立复现了 CoDeC 方法,用自己的代码和模型验证论文的结论。
实验配置
| 参数 | 值 |
|---|---|
| GPU | NVIDIA H100 NVL 95 GB(Azure Standard_NC40ads_H100_v5,Korea Central) |
| 框架 | PyTorch 2.7 + Transformers 5.7.0 |
| 精度 | BF16 |
| 每个 Benchmark 的样本数 | 200(随机种子 = 42) |
| Context Examples 数量 | 每个样本 1 个 |
| 跳过的 Token 数 | 10(前几个 Token 噪声大) |
| 最大样本长度 | 2048 字符 |
测试模型
| 模型 | 参数量 | 类型 | 访问方式 |
|---|---|---|---|
| Qwen/Qwen2.5-3B-Instruct | 3.1B | Instruct(Dense) | 公开 |
| microsoft/phi-2 | 2.8B | Base(Dense) | 公开 |
| google/gemma-3-4b-it | 4.3B | Instruct(Dense) | Gated(需要 HF Token) |
| meta-llama/Llama-3.2-3B-Instruct | 3.2B | Instruct(Dense) | Gated(需要 HF Token) |
Benchmark
| Benchmark | 来源 | 使用样本数 | 类型 |
|---|---|---|---|
| Wikitext | Salesforce/wikitext(wikitext-103-raw-v1, test) |
200 / 1724 | 已知训练数据(正控制组) |
| GSM8K | openai/gsm8k(test split) |
200 / 1319 | 数学应用题 |
| MMLU-Pro | TIGER-Lab/MMLU-Pro(test split) |
200 / 12032 | 多领域知识问答 |
| HumanEval | openai/openai_humaneval(test split) |
164 / 164 | 代码生成 |
| AIME 2024 | AI-MO/aimo-validation-aime(train split) |
90 / 90 | 竞赛数学 |
复现步骤
bash
# 1. SSH 连接 GPU VM
ssh root@<your-h100-vm>
# 2. 验证 GPU
nvidia-smi --query-gpu=name,memory.total --format=csv,noheader
# 预期输出: NVIDIA H100 NVL, 95830 MiB
# 3. 安装依赖(如需要)
pip3 install torch transformers datasets numpy
# 4. 设置 HF Token(Gated 模型如 Gemma、Llama 需要)
export HF_TOKEN="<your-hf-token>"
# 5. 运行完整实验(4 模型 × 5 Benchmark)
python3 -u scripts/codec_experiment.py \
--models "Qwen/Qwen2.5-3B-Instruct" "microsoft/phi-2" \
"google/gemma-3-4b-it" "meta-llama/Llama-3.2-3B-Instruct" \
--benchmarks wikipedia gsm8k mmlu_pro humaneval aime \
--max-samples 200 \
--output data/codec_results.json完整实验脚本在 scripts/codec_experiment.py。原始结果在 data/codec_results.json。
结果
| 模型 | 参数量 | Wikitext | GSM8K | MMLU-Pro | HumanEval | AIME |
|---|---|---|---|---|---|---|
| Qwen2.5-3B-Instruct | 3.1B | 21.0% | 68.0% | 41.5% | 56.1% | 61.1% |
| Phi-2 | 2.8B | 13.5% | 20.5% | 26.2% | 16.5% | 20.0% |
| Gemma-3-4B-IT | 4.3B | 24.5% | 5.5% | 24.0% | 15.9% | 5.6% |
| Llama-3.2-3B-Instruct | 3.2B | 35.0% | 31.0% | 39.5% | 26.2% | 43.3% |
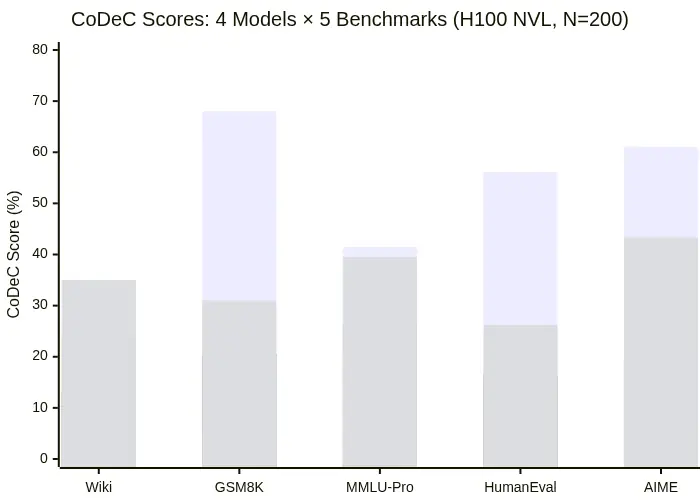
实验日志(节选)
yaml
Device: cuda
GPU: NVIDIA H100 NVL
VRAM: 99.9 GB
============================================================
Loading model: Qwen/Qwen2.5-3B-Instruct (3.1B)
wikipedia: CoDeC Score: 21.0% (200 samples, 41.0s)
gsm8k: CoDeC Score: 68.0% (200 samples, 12.5s)
mmlu_pro: CoDeC Score: 41.5% (195 samples, 15.7s)
humaneval: CoDeC Score: 56.1% (164 samples, 11.9s)
aime: CoDeC Score: 61.1% (90 samples, 8.5s)
============================================================
Loading model: microsoft/phi-2 (2.8B)
wikipedia: CoDeC Score: 13.5% (200 samples, 12.9s)
gsm8k: CoDeC Score: 20.5% (200 samples, 9.0s)
mmlu_pro: CoDeC Score: 26.2% (195 samples, 8.7s)
humaneval: CoDeC Score: 16.5% (164 samples, 8.7s)
aime: CoDeC Score: 20.0% (90 samples, 5.2s)
============================================================
Loading model: google/gemma-3-4b-it (4.3B)
wikipedia: CoDeC Score: 24.5% (200 samples, 18.9s)
gsm8k: CoDeC Score: 5.5% (200 samples, 15.2s)
mmlu_pro: CoDeC Score: 24.0% (196 samples, 14.9s)
humaneval: CoDeC Score: 15.9% (164 samples, 13.8s)
aime: CoDeC Score: 5.6% (90 samples, 8.5s)
============================================================
Loading model: meta-llama/Llama-3.2-3B-Instruct (3.2B)
wikipedia: CoDeC Score: 35.0% (200 samples, 11.4s)
gsm8k: CoDeC Score: 31.0% (200 samples, 9.0s)
mmlu_pro: CoDeC Score: 39.5% (195 samples, 8.7s)
humaneval: CoDeC Score: 26.2% (164 samples, 8.5s)
aime: CoDeC Score: 43.3% (90 samples, 5.2s)分析
发现 1:Qwen 在数学/代码 Benchmark 上表现出极端亲和力
Qwen2.5-3B 在 GSM8K 上得分 68.0%、AIME 上 61.1%、HumanEval 上 56.1%------全部处于或接近灰色地带(60-80%)。相比之下,Gemma-3-4B 在 GSM8K 上仅 5.5%、AIME 上 5.6%。GSM8K 上的 12 倍差距和 AIME 上的 11 倍差距无法用模型容量解释(3.1B vs 4.3B)。这强有力地验证了原始论文关于 Qwen Benchmark 亲和力的发现,并将其扩展到代码(HumanEval)和竞赛数学(AIME)。
发现 2:Wikitext 正控制组失败------所有模型得分 < 35%
Wikitext-103 正控制组未产生预期的 >80% 分数。所有模型得分 13-35%,远低于污染阈值。这很可能反映了 Wikitext 的高主题多样性:每段文本覆盖不同主题,单个 Context Example 提供的分布信号极其微弱。论文中 >95% 的 Wikipedia 结果使用了完整 Wikipedia 数据集中更长、更同质的文章片段。这验证了一个关键关切:CoDeC 的信号强度高度依赖于数据集的同质性。
发现 3:三级模型污染画像浮现
数据揭示了跨 5 个 Benchmark 的清晰三级模式:
| 级别 | 模型 | 画像 | 平均 CoDeC |
|---|---|---|---|
| 1 | Gemma-3-4B | 所有 Benchmark 上一致最低分 | ~15% |
| 2 | Phi-2 | 均匀低分,良好的参考模型 | ~19% |
| 3 | Llama-3.2-3B | 中等,AIME 偏高(43%) | ~35% |
| 4 | Qwen2.5-3B | 数学/代码高度偏高,其他中等 | ~50% |
发现 4:Llama-3.2 显示出意外的 AIME 亲和力(43.3%)
Llama-3.2-3B 在 AIME 上得分 43.3%------非 Qwen 模型中最高,接近灰色地带。这表明 Meta 的训练数据可能包含竞赛数学题或类似的合成数学推理数据。这一发现在原始论文中未被报告(论文未测试 Llama 3.2)。
发现 5:MMLU-Pro 证实了方法在多样化数据集上的局限
所有模型在 MMLU-Pro 上的得分聚集在 24-42%,"干净"模型和"可疑"模型之间的分离有限。这与我们之前的分析一致:CoDeC 在同质数据集上效果最好,在混合领域 Benchmark 上退化。17.5 个百分点的差距(Qwen 41.5% vs Gemma 24%)远小于 GSM8K 上 62.5 个百分点的差距(68% vs 5.5%)。
发现 6:总实验时间仍然很短
全部 20 组实验(4 个模型 × 5 个 Benchmark × 每个 200 样本)在单台 H100 NVL 上的 GPU 时间约 5 分钟。主要成本是模型下载而非推理。
深度辨析:CoDeC 到底在检测什么
我们的实验结合官方 Benchmark 数据,揭示了一个值得深入讨论的根本局限。
Gemma 悖论
| 指标 | Gemma-3-4B-IT | 来源 |
|---|---|---|
| GSM8K 上的 CoDeC | 5.5% | 我们的实验(H100 NVL) |
| 官方 GSM8K 0-shot Accuracy | 62.8% | Google Gemma 3 Model Card,STEM and Code 表 |
| 训练数据包含数学? | 是 | Google Model Card:"Mathematics: Training on mathematical text helps the model learn logical reasoning" |
一个明确训练过数学文本、在 GSM8K 上准确率达 62.8% 的模型,CoDeC 仅给出 5.5%。这直接推翻了"CoDeC 低分 = 模型没在此类数据上训练过"的朴素解读。
充分必要条件分析
| 条件 | 命题 | 成立? |
|---|---|---|
| 充分性:CoDeC 高分 → 一定训练过? | GPT-OSS 20B 在所有数据集上 >99%,包括明确没训练过的 → 不充分 | ❌ |
| 必要性:训练过 → 一定 CoDeC 高分? | Gemma 训练过数学数据,GSM8K CoDeC 仅 5.5% → 不必要 | ❌ |
CoDeC 高分既不是 "训练过该 Benchmark 数据"的充分条件,也不是必要条件。它是一个弱相关指标,不是诊断工具。
CoDeC 真正检测的是什么
CoDeC 依赖的因果链有四个环节:
训练过精确文本 → 记住精确 Token 序列 → Context 干扰记忆 → Log-prob 下降 → CoDeC 高分任何一环断裂都会导致检测失败:
| 断裂点 | 场景 | 结果 |
|---|---|---|
| 训练过但没记住 | 泛化能力强(如 Gemma) | False Negative(5.5%) |
| 没训练过但 CoDeC 高 | 极端 RLHF(如 GPT-OSS 20B) | False Positive(>99%) |
| 训练了类似格式但非原文 | 合成数学数据 ≠ GSM8K 原文 | 检测不到 |
| Context 恰好无信号 | 多样化数据集,两个样本无关 | 退化到约 50% |
正确解读方式
CoDeC 检测的不是"模型是否训练过数学数据",而是模型是否记住了某个特定 Benchmark 的精确 Token 序列。这是一个比读者可能推断的要窄得多的声明。
实践意义:将 CoDeC 用于跨模型相对比较(同一 Benchmark 上 Qwen 68% vs Gemma 5.5% 是有意义的信号),而非对单个模型做绝对的"干净/污染"分类。
实践中的陷阱
1. 格式敏感性
问题:如果修改输入格式(添加"Question:"标签、改变空格、重组答案选项),CoDeC Score 可能会改变。
原因 :模型的记忆与它在训练期间看到的精确格式绑定。如果你的 Benchmark 格式与训练格式不同,记忆信号减弱,CoDeC 可能低估污染程度。
缓解:使用原始 Benchmark 数据,不添加标签或重新格式化。如果必须评估多种格式,报告最高的 CoDeC Score。
2. 模型大小效应
问题:更大的模型即使在被污染的数据上也倾向于有更低的 CoDeC Score,因为它们泛化能力更强、对记忆的依赖更少。
原因:70B 模型有足够的容量"理解"一个数据集而非记忆它。它的置信度来自泛化而非回忆,所以 Context Examples 仍然有帮助------产生更低的 CoDeC Score。
缓解:比较相似大小的模型。不要将 7B 模型的 CoDeC Score 与 70B 模型进行对比。
3. 低多样性数据集
问题:如果 Benchmark 样本非常多样(每个样本来自完全不同的领域),单个 Context Example 几乎不提供有用的分布信号。这可能使干净模型的 CoDeC Score 膨胀到约 50%。
缓解:对多样性数据集使用更多 Context Examples(num_context_examples > 1)。
4. CoDeC 不是定罪------它是嫌疑分数
问题 :高 CoDeC Score 不能证明精确的 Benchmark 数据在训练数据中。模型可能训练了增强的、改写的或密切相关的数据。
缓解:将 CoDeC 作为多因素评估中的一个信号。结合准确率分析、训练数据文档审查和跨模型比较。
5. Reasoning 模型未经测试
问题:原始论文评估了 Base 和 Instruct 模型。Chain-of-Thought Reasoning 模型(o1、o3、DeepSeek-R1、QwQ)未经测试。这些模型在扩展推理 Trace 期间的 Log-Likelihood 行为可能有根本性不同。
缓解:对 Reasoning 模型应用 CoDeC 时需要谨慎。信号可能不太可靠。
实现
核心算法非常简洁(约 50 行 Python):
python
import torch
import numpy as np
from transformers import AutoModelForCausalLM, AutoTokenizer
def get_logprobs(model, tokenizer, text, device):
"""获取文本的逐 Token Log Probabilities。"""
with torch.no_grad():
inputs = tokenizer(text, return_tensors="pt").to(device)
outputs = model(**inputs)
log_probs = torch.log_softmax(outputs.logits, dim=-1)
input_ids = inputs["input_ids"][0]
return np.array([
log_probs[0, i, input_ids[i + 1]].item()
for i in range(len(input_ids) - 1)
])
def codec_score(model, tokenizer, dataset, device, num_context=1, skip_tokens=10):
"""计算数据集的 CoDeC 污染分数。"""
scores = []
for i, target in enumerate(dataset):
# Baseline: 仅目标文本
lp_baseline = get_logprobs(model, tokenizer, target, device)
# 带 Context: 随机样本 + 目标文本
candidates = dataset[:i] + dataset[i+1:]
context = np.random.choice(candidates, size=num_context, replace=False)
text_with_ctx = "\n\n".join(context) + "\n\n" + target
lp_context = get_logprobs(model, tokenizer, text_with_ctx, device)
# 比较(跳过前几个 Token 以保证稳定性)
baseline_conf = np.mean(lp_baseline[skip_tokens:])
context_conf = np.mean(lp_context[-len(lp_baseline):][skip_tokens:])
# 如果无 Context 时更自信 = 被污染
scores.append(1.0 if baseline_conf > context_conf else 0.0)
return np.mean(scores)使用示例:
python
model_name = "Qwen/Qwen2.5-7B-Instruct"
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16).cuda()
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 加载 Benchmark
from datasets import load_dataset
ds = load_dataset("Idavidrein/gpqa", "gpqa_diamond")["train"]
questions = ds["Question"].tolist()[:200] # 子采样以加快速度
score = codec_score(model, tokenizer, questions, "cuda")
print(f"CoDeC score on GPQA: {score:.1%}")
# Qwen2.5-7B-Instruct: ~50%(灰色地带)
# Gemma-3-4B-IT: ~20%(可能干净)使用 vLLM 扩展
对于评估多个模型或大型数据集,HuggingFace Transformers 实现较慢(无 Batching、顺序 Forward Pass)。将 Log-Probability 提取封装到 vLLM Offline Inference Pipeline 中可获得约 10 倍加速:
python
from vllm import LLM, SamplingParams
llm = LLM(model=model_name, dtype="bfloat16", max_model_len=4096)
# 使用 prompt_logprobs 获取逐 Token Log-Likelihoods
params = SamplingParams(max_tokens=1, prompt_logprobs=1)
outputs = llm.generate(texts, params)
# 从 outputs[i].prompt_logprobs 提取 Log-Probs这使得在单台 H100 上评估 1000 个样本 × 10 个模型可在 2 小时内完成,而 Naive Transformers 循环需要约 20 小时。
速查卡
何时使用 CoDeC
| 场景 | 是否使用 CoDeC? |
|---|---|
| 选择部署用的开源模型 | ✅ 是------验证 Benchmark 分数是否可信 |
| 发布新 Benchmark | ✅ 是------在准确率旁报告 CoDeC Score |
| 评估自己 Fine-tune 的模型 | ⚠️ 可能------你已经知道自己的训练数据 |
| 评估闭源 API(GPT-4o、Claude) | ❌ 否------无法获取 Log Probabilities |
| 单一确定性的污染证据 | ❌ 否------CoDeC 给出的是嫌疑度,不是证据 |
决策流程图
markdown
模型宣称 Benchmark 高准确率
│
▼
在该 Benchmark 上运行 CoDeC
│
┌─────────┼──────────┐
▼ ▼ ▼
< 60% 60-80% > 80%
│ │ │
可能 灰色 可能
真实 地带 被污染
│ │ │
▼ ▼ ▼
信任 与参考 对该
分数 模型对比 Benchmark
分数打折关键数字
| 指标 | 值 |
|---|---|
| 每个样本的 Forward Pass 次数 | 2(Baseline + Context) |
| 所需 Context Examples 数量 | 1(论文验证足够) |
| 跳过的 Token 数 | 10(前几个 Token 噪声大) |
| 干净阈值 | < 60% |
| 污染阈值 | > 80% |
| 每 200 样本耗时(3B, H100 NVL, Transformers) | 约 12s(实测) |
| 每 1000 样本耗时(7B, H100, vLLM) | 约 12 分钟(估算) |
参考文献
- Zawalski, M., Boubdir, M., Bałazy, K., Nushi, B., & Ribalta, P. (2025). Detecting Data Contamination in LLMs via In-Context Learning. arXiv:2510.27055. ICLR 2026.
- NVIDIA NeMo Evaluator --- CoDeC Implementation: GitHub
- Hochreiter, S. & Schmidhuber, J. (1997). Flat Minima. Neural Computation, 9(1).
- Keskar, N. S. et al. (2017). On Large-Batch Training for Deep Learning. ICLR 2017.
本文是 DL-Algorithm-Insights 系列的一部分------用真实 GPU 实验解释深度学习算法。
⭐ 获取完整内容
📌 完整的代码、配置和详细说明都在 GitHub 仓库中
🔗 文章地址 : Benchmark 污染检测
🔗 Repo 总地址 : github.com/david-xinyu...
⭐ 如果这篇文章对你有帮助,欢迎到 GitHub 给个 Star!你的支持是我持续分享的动力!