
摘要:本文是《大模型技术博客》系列的开篇之作。我们将从零开始,系统性地介绍什么是大语言模型(Large Language Model, LLM),它的发展历程、核心技术特点,以及它为什么是人工智能领域的一场"范式革命"。无论你是AI初学者,还是希望转型的开发者,这篇文章都将为你打开大模型技术的大门。
一、引言:为什么你需要了解LLM?
想象一下:
- 你有一个助手,能瞬间阅读百万本书籍,并回答你关于这些书籍的任何问题;
- 你有一个搭档,能用40多种语言与你对话,翻译、写作、编程样样精通;
- 你有一个顾问,能理解你的意图,帮你写邮件、做总结、生成代码、甚至创作诗歌。
这不是科幻电影,而是大语言模型(LLM) 已经实现的能力。
从2022年11月ChatGPT的惊艳亮相,到2023年GPT-4的史诗级进化,再到2024-2026年开源大模型的百花齐放------LLM正在以惊人的速度重塑我们的工作方式、学习方式和生活方式。
那么,问题来了:
- 大语言模型到底是什么?
- 它为什么突然变得这么强大?
- 它的"智能"从何而来?
- 作为开发者/技术人,我们该如何拥抱这场变革?
这篇文章,就是来回答这些问题的。
二、什么是大语言模型(LLM)?
2.1 直观理解:下一个词预测器
从技术本质 上说,大语言模型是一个"下一个词预测器"。
它的工作流程异常简单:
输入: "今天天气很"
输出: "好" (概率最高)是的,你没有看错。LLM的核心任务就是:给定前面的文字,预测下一个最可能出现的词(或词的片段)。
这个过程循环往复,就能生成整段文章、整篇代码、甚至整本书。
但别被这个"简单"的任务欺骗了。
当一个模型足够大(数千亿参数)、训练数据足够多(数万亿词)、训练时间足够长(数千GPU小时)时,这个"下一个词预测器"竟然涌现出了惊人的能力:
- 它能理解你的问题(语义理解)
- 它能推理问题的答案(逻辑推理)
- 它能创造新的内容(内容生成)
- 它能使用工具(Function Calling)
- 它甚至能反思自己的错误(Self-Correction)
这就是大语言模型:一个通过"预测下一个词"训练出来的、参数量巨大的、能够理解和生成自然语言的深度学习模型。
2.2 正式定义
大语言模型(Large Language Model, LLM):
指的是参数量达到数十亿(Billions)到数千亿(Hundreds of Billions) 级别,在海量文本数据 上训练得到的深度学习模型。它能够理解、生成、翻译、总结 自然语言,并且在没有显式训练的情况下,能够泛化到多种下游任务上。
关键词解读:
| 关键词 | 含义 | 典型值 |
|---|---|---|
| 大规模 | 参数量巨大 | 7B、13B、70B、175B、540B... |
| 预训练 | 在海量无标注数据上训练 | 数TB文本、数万亿词(Tokens) |
| 泛化能力 | 一个模型搞定多种任务 | 翻译、摘要、问答、代码... |
| 涌现能力 | 超过某个规模阈值后,突然出现的新能力 | 思维链推理、指令遵循... |
三、LLM发展历程:从NLP到AGI的奇点时刻
让我们用一张时间线图,快速回顾LLM的发展历程。
3.1 LLM发展时间线
下图展示了LLM从2017年Transformer诞生,到2026年规模化落地的发展历程。关键节点包括:2018年BERT发布、2020年GPT-3展示少样本学习能力、2022年ChatGPT破圈、2023年LLaMA开源引发开源生态爆发、2024年GPT-4o实现多模态融合、2026年具身智能与Agent应用崛起。
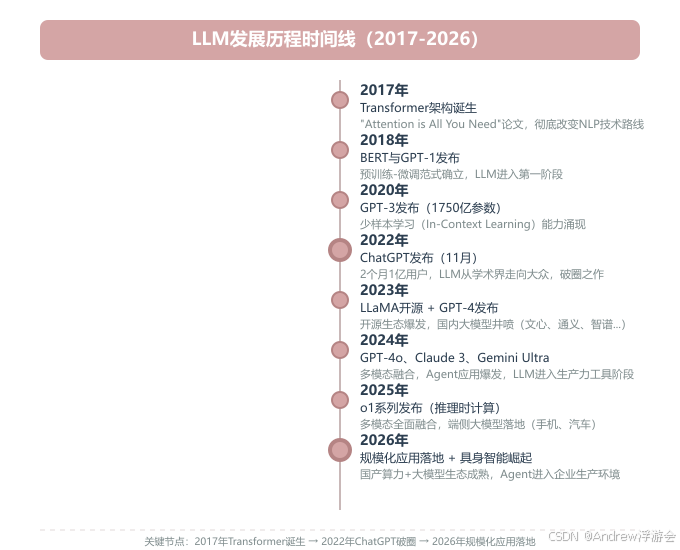
3.2 发展阶段的划分
从技术演进的角度,我们可以将LLM的发展划分为四个阶段:
| 阶段 | 时间 | 代表模型 | 核心突破 | 典型能力 |
|---|---|---|---|---|
| 第一阶段 | 2017-2019 | BERT、GPT-1/2 | Transformer架构、预训练-微调 | 单任务微调、阅读理解 |
| 第二阶段 | 2020-2021 | GPT-3、T5 | 规模化、Prompt工程 | 少样本学习、代码生成 |
| 第三阶段 | 2022-2023 | ChatGPT、GPT-4、LLaMA | 对齐(RLHF)、多模态 | 对话、推理、视觉理解 |
| 第四阶段 | 2024-至今 | o1、Claude 3、Gemini | 推理时计算、Agent | 深度推理、自主行动、多模态融合 |
关键洞察:
- 2017年是分水岭:Transformer架构的提出,让模型能够并行处理、捕捉长距离依赖,为规模化奠定了基础。
- 2020年是转折点:GPT-3证明了"规模至上"(Scaling Law)------模型越大、数据越多、计算越多,能力就越强。
- 2022年是破圈时刻:ChatGPT让普通人也能感受到AI的力量,LLM从此成为全社会的话题。
- 2024-2026年是落地元年:从"能聊天"到"能干活",LLM正在深入千行百业。
四、LLM的核心技术特点
4.1 自监督预训练:从海量数据中学习
传统的人工智能模型,需要大量人工标注的数据(比如,给每张图片打标签、给每个句子标情感)。
而LLM采用的是自监督学习(Self-Supervised Learning):
- 不需要人工标注
- 从海量无标注文本中自动学习
- 通过"预测下一个词"这个任务,学会语言的知识、逻辑、甚至常识
预训练数据规模(以GPT-3为例):
| 数据集 | 词数(Tokens) | 占比 |
|---|---|---|
| Common Crawl | 4100亿 | ~60% |
| WebText2 | 190亿 | ~3% |
| Books1 | 120亿 | ~2% |
| Books2 | 55亿 | ~1% |
| Wikipedia | 30亿 | <1% |
总计 :约3000亿词(经过质量过滤后)
这意味着什么?
- 如果一本书平均10万字,3000亿词 ≈ 300万本书
- LLM相当于"读过"了一个超大型图书馆
- 而且它"记得"这些内容的概率分布
4.2 规模定律(Scaling Law):越大越强
2020年,OpenAI在一篇题为《Scaling Laws for Neural Language Models》的论文中,提出了一个令人震撼的发现:
规模定律(Scaling Law):
模型的性能(用交叉熵损失衡量),与三个因素呈幂律关系:
- 模型参数量(N)
- 训练数据量(D)
- 计算量(C)
简单来说 :模型越大、数据越多、算得越久,性能就越好------而且这个提升是可预测的。
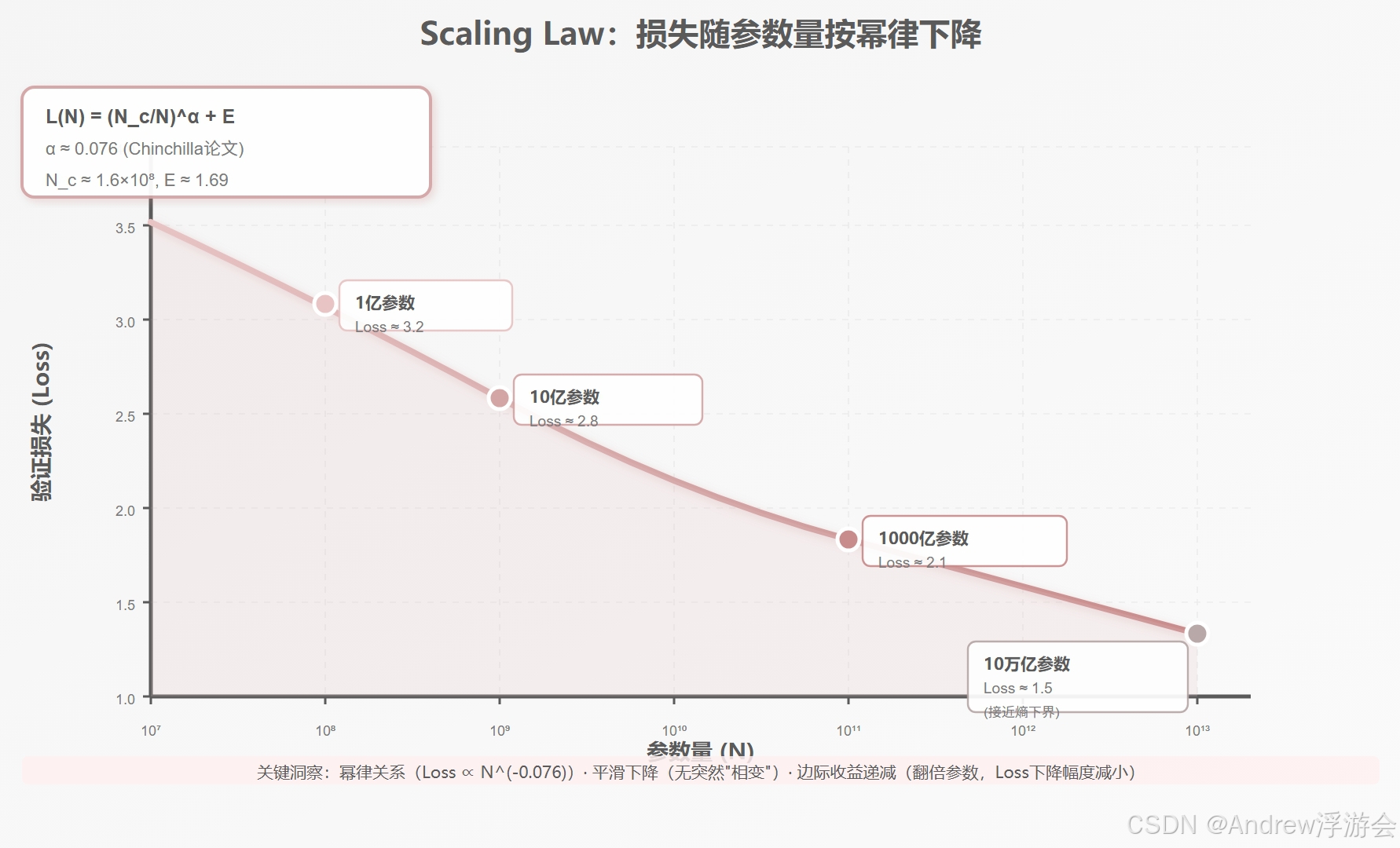
规模定律的深远影响:
- 投资有据可依:原来训练大模型是"砸钱换性能",现在有公式可以参考
- 涌现能力的解释:当模型规模超过某个阈值(比如70B),某些能力会"突然"出现
- 产业军备竞赛:全球科技公司都在训练更大的模型(GPT-5?、LLaMA 4?、Gemini 2?)
4.3 涌现能力(Emergent Abilities):规模带来的质变
涌现能力 指的是:当模型参数量超过某个阈值后,某些能力会突然出现,而在小模型上完全不存在。
典型涌现能力:
| 能力 | 出现阈值(约) | 说明 |
|---|---|---|
| 少样本学习(Few-Shot) | 10B+ | 不需要微调,给几个例子就能学会新任务 |
| 思维链推理(CoT) | 70B+ | 能够一步步推理,解决数学/逻辑问题 |
| 指令遵循(Instruction Following) | 70B+ | 能够理解并执行复杂的自然语言指令 |
| 代码生成 | 13B+ | 能够生成可运行的代码片段 |
| 多任务泛化 | 70B+ | 一个模型搞定翻译、摘要、问答、代码... |
重要洞察:
- 涌现能力不是线性增长 的,而是突然出现的
- 这解释了为什么7B模型 和70B模型的差距,不是"10倍",而是"质变"
- 也是为什么大模型竞赛如此激烈------因为领先者会获得不成比例的优势
4.4 对齐(Alignment):让模型"听话"
早期的LLM有一个问题:它们可能会生成有害、偏见、或完全不相关的内容。
为了解决这个问题,研究者提出了对齐技术,其中最具代表性的是:
RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)
RLHF的三步流程:
Step 1: 预训练一个基础模型(比如GPT-3)
↓
Step 2: 让人工标注员对模型的输出进行排名(哪个回答更好?)
↓
Step 3: 用这些排名训练一个"奖励模型"(Reward Model)
↓
Step 4: 用强化学习(PPO算法)优化基础模型,最大化奖励效果:
- ChatGPT(基于InstructGPT)就是RLHF的产物
- 对齐后的模型更安全、更有帮助、更听话
演进:
- 2023年:RLHF是主流
- 2024年:DPO(Direct Preference Optimization)提出,更简单、更稳定
- 2025年:RLAIF(AI反馈)兴起,减少人工标注成本
五、LLM的应用场景:它能做什么?
LLM的能力可以用一个公式来概括:
LLM = 理解(Comprehension) + 生成(Generation) + 推理(Reasoning)
基于这个核心能力,LLM正在赋能千行百业。
5.1 文本类应用
| 应用场景 | 说明 | 代表产品 |
|---|---|---|
| 智能对话 | 多轮对话、问答、客服 | ChatGPT、Claude、文心一言 |
| 内容创作 | 写文章、写剧本、写诗歌 | Jasper、Notion AI |
| 文本摘要 | 长文总结、会议纪要 | ChatPDF、Summarize.tech |
| 机器翻译 | 多语言翻译、本地化 | DeepL、Google Translate(AI增强) |
| 代码助手 | 代码生成、调试、解释 | GitHub Copilot、Cursor |
| 知识问答 | 搜索增强、知识库问答 | Perplexity、Bing Chat |
5.2 多模态应用
2023年以来,LLM正在从"纯文本"走向"多模态"。
| 应用场景 | 说明 | 代表模型/产品 |
|---|---|---|
| 图文理解 | 看图说话、视觉问答 | GPT-4V、LLaVA、Qwen-VL |
| 文生图 | 根据文字描述生成图片 | DALL-E 3、Stable Diffusion、Midjourney |
| 文生视频 | 根据文字描述生成视频 | Sora、Runway Gen-2 |
| 语音对话 | 语音输入、语音输出 | GPT-4o、Claude 3 Sonnet |
5.3 Agent(智能体)应用
2024-2026年,Agent是LLM应用的最前沿。
什么是Agent?
Agent = LLM(大脑) + 工具调用(手) + 记忆(数据库) + 规划(推理)
典型Agent应用:
| 应用场景 | 说明 | 代表框架/产品 |
|---|---|---|
| 自动编程Agent | 理解需求、写代码、测试、部署 | Devin、Cursor Composer |
| 研究助手Agent | 搜索、阅读、总结、生成报告 | Elicit、Consensus |
| 客服Agent | 多轮对话、调用API、完成订单 | 各大电商平台 |
| RPAAgent | 操作浏览器、填写表单、自动化流程 | Adept、Multion |
六、主流LLM模型对比
让我们用一张表格,快速了解当前主流的LLM模型。
6.1 闭源商用模型
| 模型 | 开发商 | 参数量 | 特点 | 访问方式 |
|---|---|---|---|---|
| GPT-4o | OpenAI | 未公开(估计~200B) | 多模态、速度快、生态好 | API、ChatGPT Plus |
| GPT-4 Turbo | OpenAI | 未公开 | 强推理、长上下文(128K) | API、ChatGPT Plus |
| o1-preview | OpenAI | 未公开 | 推理时计算、强数学/代码能力 | API、ChatGPT Plus |
| Claude 3 Opus | Anthropic | 未公开(估计~200B) | 长上下文(200K)、安全对齐好 | API、Claude Pro |
| Gemini Ultra | 未公开 | 多模态、与Google生态集成 | Gemini Advanced | |
| 文心一言4.0 | 百度 | 未公开 | 中文优化、国内合规 | 文心一言APP |
6.2 开源模型
| 模型 | 开发商 | 参数量 | 特点 | 开源协议 |
|---|---|---|---|---|
| LLaMA 3 | Meta | 8B/70B/400B | 开源旗舰、社区生态好 | LLAMA 3 License |
| Qwen 2 | 阿里云 | 7B/72B | 中文能力强、工具调用好 | Apache 2.0 |
| GLM-4 | 智谱AI | 9B/100B+ | 中文优化、开源商用友好 | Apache 2.0 |
| Mistral 7B | Mistral AI | 7B | 小模型高性能、MoE架构 | Apache 2.0 |
| DeepSeek-V3 | DeepSeek | 671B(激活37B) | MoE架构、性价比极高 | MIT |
| Yi | 零一万物 | 34B/100B | 中英文双语、长上下文 | Apache 2.0 |
如何选择?
- 研究/学习:优先选择开源模型(LLaMA 3、Qwen 2、GLM-4)
- 商用产品:闭源模型(GPT-4o、Claude 3)性能更稳定,但要考虑成本和合规
- 本地部署:小参数量开源模型(7B-13B)+ 量化(4bit/8bit)
七、LLM的技术栈:从训练到部署
为了让你对LLM有一个全景式的理解,我们用一张图展示LLM的技术栈。
7.1 LLM技术栈全景图
下图展示了LLM从底层算力、数据、训练、模型、服务到应用的完整技术栈。每一层都有其核心任务和技术选型。

技术栈解读:
- 算力层:训练大模型需要数千张GPU(比如A100/H100),单次训练成本千万美元级别
- 数据层:海量、高质量、多样化的文本数据,是模型性能的基础
- 训练层:分布式训练技术,让模型能够在数千GPU上高效训练
- 模型层:预训练模型 + 微调/对齐,是LLM的核心
- 服务层:推理优化技术(量化、KV Cache、连续批处理),让模型能够高效服务用户
- 应用层:基于LLM构建的各种应用,是技术落地的载体
八、LLM的局限性:它不是万能的
在结束本文之前,我们需要客观地认识LLM的局限性。
8.1 主要局限性
| 局限性 | 说明 | 缓解方法 |
|---|---|---|
| 幻觉(Hallucination) | 模型会"一本正经地胡说八道",生成错误但看似合理的内容 | RAG(检索增强)、事实核查、人类反馈 |
| 时效性 | 模型的知识截止于训练数据的时间点,无法获取最新信息 | 联网搜索、RAG、持续学习 |
| 数学/逻辑推理 | 复杂数学题、多步逻辑推理容易出错 | 思维链(CoT)、程序辅助(ToT)、推理时计算(o1) |
| 可解释性差 | 千亿参数模型的决策过程,人类难以理解 | 可解释性研究、Attention可视化 |
| 安全隐患 | 可能被用于生成虚假信息、恶意代码、垃圾内容 | 对齐技术(RLHF/DPO)、内容审核、使用政策 |
| 计算成本高 | 训练和推理都需要大量算力,中小企业难以承受 | 模型压缩(量化、剪枝、蒸馏)、云API、开源模型 |
8.2 幻觉问题详解
幻觉(Hallucination) 是LLM最突出的问题之一。
什么是幻觉?
幻觉指的是:LLM生成的 content,看似合理、流畅,但实际上与事实不符、或完全错误。
幻觉的例子:
用户: "请介绍一下2025年诺贝尔物理学奖得主。"
模型(幻觉): "2025年诺贝尔物理学奖得主是张三,以其在量子计算领域的贡献而获奖。"
(实际上:2025年诺贝尔物理学奖得主可能是其他人,或者尚未揭晓)
用户: "Python中如何反转一个字符串?"
模型(部分错误): "可以使用reverse()方法:s.reverse()"
(实际上:Python字符串没有reverse()方法,正确做法是s[::-1])幻觉的成因:
- 训练数据的局限性:模型只能"记住"训练数据中的知识,无法获取新信息
- 概率生成的本质:LLM生成的是"最可能出现的词",而不是"一定正确的词"
- 缺乏真实世界的 grounding:模型没有"亲身体验",只能基于统计模式生成内容
缓解幻觉的方法:
| 方法 | 说明 | 效果 |
|---|---|---|
| RAG(检索增强生成) | 让模型在生成前,先检索外部知识库 | ⭐⭐⭐⭐⭐ |
| 事实核查 | 对模型生成的内容进行自动/人工核查 | ⭐⭐⭐⭐ |
| 人类反馈 | 通过RLHF,让模型学会"不知道时就说不知道" | ⭐⭐⭐ |
| 提示工程 | 在Prompt中要求模型"如果不确定,请说明" | ⭐⭐ |
九、总结与展望
9.1 本文回顾
在这篇开篇文章中,我们系统地介绍了:
- LLM是什么:一个通过"预测下一个词"训练出来的、参数量巨大的深度学习模型
- LLM的发展历程:从2017年Transformer的诞生,到2026年规模化应用落地
- LLM的核心技术特点:自监督预训练、规模定律、涌现能力、对齐技术
- LLM的应用场景:文本生成、多模态、Agent等
- 主流LLM模型对比:闭源商用 vs 开源模型
- LLM的技术栈:从算力、数据、训练、模型、服务到应用
- LLM的局限性:幻觉、时效性、推理能力、安全隐患等
9.2 下一步学习路线
如果你希望深入学习LLM技术,我建议按照以下路线:
┌─────────────────────────────────────────────┐
│ 阶段一:基础认知(本文系列第1-12篇) │
│ ✓ 了解LLM的基本概念和发展历程 │
│ ✓ 理解Token、Embedding、Attention │
│ ✓ 掌握Transformer架构 │
└─────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────┐
│ 阶段二:技术原理(本文系列第13-36篇) │
│ ✓ 深入理解GPT、BERT、LLaMA等架构 │
│ ✓ 掌握预训练、微调、RLHF/DPO全流程 │
│ ✓ 学习推理优化、分布式训练等技术 │
└─────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────┐
│ 阶段三:应用实战(本文系列第37-60篇) │
│ ✓ 提示工程(Prompt Engineering) │
│ ✓ RAG(检索增强生成) │
│ ✓ Fine-tuning(微调) │
│ ✓ Agent开发(LangChain/LangGraph) │
└─────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────┐
│ 阶段四:工程实践(本文系列第61-84篇) │
│ ✓ 模型量化、蒸馏、剪枝 │
│ ✓ 推理框架(vLLM、TensorRT-LLM) │
│ ✓ 大模型服务化(API设计、监控、运维) │
└─────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────┐
│ 阶段五:前沿技术(本文系列第85-98篇) │
│ ✓ Mamba、RWKV等新型架构 │
│ ✓ 多模态大模型 │
│ ✓ 具身智能、Agent自主进化 │
└─────────────────────────────────────────────┘9.3 下期预告
下期文章(5月28日,周四):《大模型技术栈全景图:从训练到部署的完整链路》
在这篇文章中,我们将:
- 深入剖析LLM技术栈的每个环节
- 了解数据准备、预训练、微调、推理、部署的完整流程
- 掌握选择LLM技术栈的决策框架
十、参考资料
论文
-
Attention is All You Need (2017)
Vaswani et al., NeurIPS 2017
arXiv:1706.03762 -
BERT: Pre-training of Deep Bidirectional Transformers (2018)
Devlin et al., NAACL 2019
arXiv:1810.04805 -
Language Models are Few-Shot Learners (GPT-3, 2020)
Brown et al., NeurIPS 2020
arXiv:2005.14165 -
Scaling Laws for Neural Language Models (2020)
Kaplan et al., OpenAI
arXiv:2001.08361 -
Training language models to follow instructions with human feedback (InstructGPT, 2022)
Ouyang et al., OpenAI
arXiv:2203.02155 -
LLaMA: Open and Efficient Foundation Language Models (2023)
Touvron et al., Meta AI
arXiv:2302.13971
开源项目
- Hugging Face Transformers :github.com/huggingface/transformers
- LLaMA 3 :github.com/meta-llama/llama3
- LangChain :github.com/langchain-ai/langchain
- vLLM :github.com/vllm-project/vllm
推荐阅读
- Andrej Karpathy 的 YouTube 教程 :youtube.com/@karpathy
- 李沐的《动手学深度学习》 :zh.d2l.ai
- Hugging Face 课程 :huggingface.co/learn
十一、延伸讨论
思考题
- 为什么"预测下一个词"这么简单的任务,能够涌现出如此复杂的能力?
- 规模定律是否意味着"越大越好"?有没有可能通过算法创新,让小模型达到大模型的性能?
- LLM的"智能"与人类的智能,本质区别是什么?
实践作业(可选)
- 体验不同的LLM:分别试用ChatGPT、Claude、文心一言、通义千问,感受它们的异同。
- 观察幻觉现象:尝试让LLM回答一些冷门问题,观察它是否会"胡编乱造"。
- 尝试提示工程:在同一个LLM上,用不同的Prompt提问同一个问题,观察输出差异。
读者互动
欢迎在评论区留下你的:
- 疑问(我会定期整理并回答)
- 建议(你想在后续文章中看到什么内容?)
- 思考(对本文任何观点的补充或反驳)
作者简介:Andrew,商业航天公司AI CTO。致力于用通俗易懂的语言,系统讲解大模型技术。
博客主页 :Andrew浮游会
GitHub :Andrew's repo
如果这篇文章对你有帮助,请点赞、收藏、关注三连! 👍⭐🔔
你的支持,是我持续创作的动力!
系列文章目录(持续更新中):
- ✅ 什么是大语言模型(LLM)?从零认识AI新范式(本文)
- 📅 大模型技术栈全景图:从训练到部署的完整链路(5月28日)
- 📅 ...(更多文章,敬请期待)
最后更新时间:2026年5月27日
字数:约15000字
阅读时间:约30分钟