本文记录了我从 C/C++ 转向 Go 过程中遇到的核心语法差异、思维转变和常见坑点,希望能帮助同样背景的读者快速上手。
本文是作者从自己的公众号转过来的,所以格式可能略有不对

1.变量定义
Go中定义变量是名字+类型,一句话结束不需要分号,编译器会自动加
因为编译器自动加;所以{ 必须跟在同一行
若:
javascript
func main()
{编译器后
cs
func main();
{同理for循环if条件语句那种都要求把{写在同一行
else 也必须跟在 } 同一行
Go:变量名在前,类型在后
cs
var age int
var name string
var scores []intC/C++:类型在前,变量名在后
cpp
int age;
string name;
vector<int> scores;函数声明也同理:
Go:参数类型后置,返回值类型在最后,全部颠倒
go
func add(a int, b int) int {
return a + b
}var 和 :
Go 有两种声明变量的方式:
go
// var ,可以只声明不赋值
var x int // x = 0(零值)
var name string // name = ""
// := ,必须声明+赋值同时进行
y := 10 // 自动推断类型为 int
name := "小明" // 自动推断为 string注意:
:= 只能在函数内部使用,在main函数外面也就是包级别必须用 var
var x int 相当于 c/c++中 int x
:= 约等于 C++ 的 auto,但更简洁
2.数组和切片
Go 数组与切片的对比(C++ 视角)
| 类型 | Go 写法 | 长度 | C++ 类比 |
|---|---|---|---|
| 数组 | [3]int |
固定 | int arr[3] |
| 切片 | []int |
动态 | std::vector<int> |
数组:
遍历数组:
perl
s1 := []int{123, 546, 67, 6786, 54, 46, 576, 7}
for index, value := range s1 {
fmt.Printf("%d-->%d \n", index, value)
}range遍历:
go
arr := [3]int{1, 2, 3}
// 1. 要索引也要值
for i, v := range arr {
fmt.Println(i, v)
}
// 2. 只要索引
for i := range arr {
fmt.Println(i)
}
// 3. 只要值(丢弃索引)
for _, v := range arr {
fmt.Println(v)
}不要索引的时候要用_占位,必须写 _ 占位,Go 不允许有未使用的变量
数组的长度是类型的一部分
[2]int 和 [3]int 是完全不同的类型,就像 int 和 string 的关系
提问:
下面的代码是否有问题?
go
func main() {
x := [2]int{1, 2}
y := [3]int{1, 2}
if x == y {
fmt.Println("x == y")
} else {
fmt.Pritnln("x != y")
}
}有问题,x 和 y分别是2int和3int类型,二者类型不匹配,故无法比较
再来讲切片:
切片的感觉特别像c++的vector动态数组,数组大小不固定那种感觉
go
s := make([]int, 0, 10)
s = append(s, 1) // 类似 push_back
go
s := []int{1, 2, 3} // 这是切片
arr := [3]int{1, 2, 3} // 这是数组创建切片使用make函数:
go
make([]int, 长度) // 只指定长度
make([]int, 长度, 容量) // 指定长度和容量
go
make([][]int, len, cap)len是现在有的元素长度(多少),cap是现在可以存元素(包括预留的)的全部位置(包含已经存了的还还没有存但是有位置的),超出预留的就将当前的cap翻倍
make(\[\]\[\]int,长度,总容量类似于预留) 预留位置可以超 这个是二维的
当元素超过当前cap时,cap会翻倍,也就是预留位置翻倍,假如make(\[\]int,1,3)当添加的元素加上之前原有的元素个数超过3个时,cap就变成了6,预留变成了6,当再添加元素,超过6个时,此时cap变成12,注意这里是6的倍数了
apache
s := make([]int, 0, 3) // len=0, cap=3
s = append(s, 1, 2, 3) // len=3, cap=3
s = append(s, 4) // len=4, cap=6(自动翻倍)s := make(\[\]\[\]int, 1, 10) 就是说现在预留了10行,但现在只有1行,s可以append9次,超过9次之后再次append会触发扩容(也是可以无限增加行数的,就和vector<vector>那个特别特别像),s0可以append无限次,但是s00现在还不存在 ,现在只是知道有一行,但是这一行还没有任何定义,s0可以输出,只不过输出的是空,而像s1这种输出就会报错,因为根本就不存在,s00输出也会报错,还是因为现在只有1行,但是这一行是空,这一行内不存在元素
切片删除:
ini
cartItems = append(cartItems[:k], cartItems[k+1:]...)删除索引为k的切片中的元素
: 是 Go 的切片操作符,用来从一个切片/数组中截取一部分元素。
格式:slice[起始位置:结束位置],规则是左闭右开(包含起始,不包含结束)。
默认左边start是从0开始,注意这里是左闭右开,c++的库函数几乎也全是左闭右开
提问:
下面的函数输出是什么
go
func main() {
s := "Go 语言"
for i,v := range s {
fmt.Printf("i = %v, v = %c\n", i, v)
}
}该题主要考点为汉字所占用的字节,在Go语言中汉字占用三个字节,故会输出:
ini
i = 0, v = G
I = 1, v = o
I = 2, v =
I = 3, v = 语
I = 6, v = 言下面代码会输出什么?
css
func main() {
s := "Hello Goland"
s1 := s[:]
s1 = "Hello JAVA"
fmt.Println(s)
fmt.Println(s1)
}会输出:
Hello Goland
Hello JAVA
因为字符串创建之后不可改变,而s1则是以s为基础创造的切片,故s1 = "Hello JAVA"实际是对s1的重新赋值,故会有此输出
下面的代码是否有问题:
go
func main() {
s := make([][]int, 1, 10)
s[0][0] = 1
fmt.Println(s[0][0])
}这里存在问题,因为仅对第一层数组进行的创建,而作为元素的数组此时还并没有进行创建,所以s00会报错,应为作为元素的数组也创建空间:s0 = make(\[\]int,1),现在s00输出就是1了
二维数组可以完全类比于c++的vector<vector>
深拷贝和浅拷贝:
深拷贝和浅拷贝的核心区别在于:复制后,新对象和原对象是否共享同一块底层数据

浅拷贝:
浅拷贝只复制了对象本身,内部引用的数据还是同一份
go
// 浅拷贝:slice 的赋值
a := []int{1, 2, 3}
b := a // b 和 a 指向同一个底层数组
b[0] = 999
fmt.Println(a) // [999, 2, 3] ← a 也被改了!
fmt.Println(b) // [999, 2, 3]因为切片的内部结构是一个指针 + 长度 + 容量 的结构体,赋值 b := a 只拷贝了这三个字段的值,指针仍然指向同一块底层数组;
go
a: [ptr → [1][2][3], len=3, cap=3]
b: [ptr → [1][2][3], len=3, cap=3] ← ptr 指向的是同一个底层数组深拷贝:
深拷贝会创建一份完全独立的新数据,修改新对象不会影响原对象
使用copy函数:
bash
a 的值逐个复制到 b 的底层数组里,其实就相当于c的b=a(数组不能这样写,字符串可以,这里就是说是这个感觉),只不过把等号写成copy
go
a := []int{1, 2, 3}
b := make([]int, len(a))
copy(b, a)
b[0] = 999
fmt.Println(a) // [1, 2, 3] ← a 没变!
fmt.Println(b) // [999, 2, 3]使用append只有扩容了才是深拷贝,扩容就是超过cap,cap自动翻倍了,没扩容还是浅拷贝
go
package main
import "fmt"
func main() {
// ========== 情况一:触发扩容 → 深拷贝 ==========
fmt.Println("=== 情况一:触发扩容 ===")
s1 := make([]int, 2, 2) // len=2, cap=2
s1[0], s1[1] = 1, 2
fmt.Println("s1:", s1, "len:", len(s1), "cap:", cap(s1))
s2 := append(s1, 3) // cap 不够,扩容!cap 从 2 → 4
fmt.Println("s2:", s2, "len:", len(s2), "cap:", cap(s2))
s2[0] = 999 // 改 s2
fmt.Println("s1 被影响了吗?", s1[0]) // 1,没变!底层数组独立了
fmt.Println("s2:", s2)
fmt.Println()
// ========== 情况二:没触发扩容 → 浅拷贝 ==========
fmt.Println("=== 情况二:没触发扩容 ===")
s3 := make([]int, 2, 4) // len=2, cap=4
s3[0], s3[1] = 10, 20
fmt.Println("s3:", s3, "len:", len(s3), "cap:", cap(s3))
s4 := append(s3, 30) // cap 还够,不扩容!
fmt.Println("s4:", s4, "len:", len(s4), "cap:", cap(s4))
s4[0] = 888 // 改 s4
fmt.Println("s3 被影响了吗?", s3[0]) // 888,被改了!底层数组共享
fmt.Println("s4:", s4)
}

go
package main
import "fmt"
func main() {
s1 := []int{1, 2, 3, 4}
s2 := make([]int, 0) // len=0,cap=0
// 逐个追加,每次可能扩容,s2 指向全新的底层数组
for i := 0; i < len(s1); i++ {
s2 = append(s2, s1[i])
}
fmt.Println("s1:", s1) // [1 2 3 4]
fmt.Println("s2:", s2) // [1 2 3 4]
// 修改 s1,s2 不受影响(因为 append 触发了扩容,底层数组独立)
s1[0] = 100
fmt.Println("修改后 s1:", s1) // [100 2 3 4]
fmt.Println("修改后 s2:", s2) // [1 2 3 4]
// 使用 copy 进行深拷贝
s3 := []int{7, 8, 9, 10, 11}
fmt.Println("s2:", s2) // [1 2 3 4]
fmt.Println("s3:", s3) // [7 8 9 10 11]
// copy(dst, src):把 s3 拷贝到 s2,从 s2 第 0 个位置开始,能装几个装几个
copy(s2, s3)
fmt.Println("copy 后 s2:", s2) // [7 8 9 10](s2 只有 4 个容量)
fmt.Println("copy 后 s3:", s3) // [7 8 9 10 11](s3 不变)
}map,切片这种原本默认赋值是浅拷贝,但是切片使用了copy函数可以变成深拷贝,但是map没有copy函数,只能手动深度拷贝
go
src := map[string]int{"a": 1, "b": 2}
dst := make(map[string]int)
for k, v := range src {
dst[k] = v
}
dst["a"] = 999
fmt.Println(src["a"]) // 1,不受影响int那种本来就是深拷贝
提问:
下面代码输出什么?
css
func main() {
a := [...]int{0,1,2,3,4,5,6}
b := make([]int, 2, 4)
c := a[0:3]
b = append(b,1)
b = append(b, c...)
fmt.Println(b)
fmt.Println(len(b))
fmt.Println(cap(b))
d := make([]int, 2, 2)
copy(d,c)
fmt.Println(d)
fmt.Println(len(d))
fmt.Println(cap(d))
}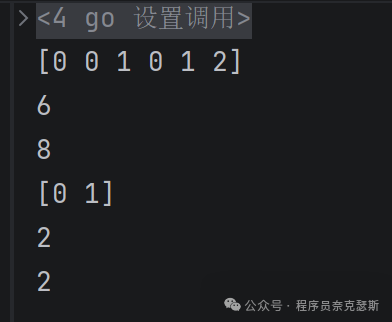
go
a := [...]int{0,1,2,3,4,5,6}
// 数组:长度 7,内容 [0,1,2,3,4,5,6]
b := make([]int, 2, 4)
// 切片:len=2,cap=4,内容 [0, 0](零值)
c := a[0:3]
// 切片:len=3,cap=7,内容 [0,1,2]b追加超出容量,cap翻倍
看d:
apache
d := make([]int, 2, 2) // len=2 cap=2 [0,0]
copy(d, c) // 把 c 的前 2 个元素拷进 dcopy把右边给左边,按照长度短的为标准
左边更短就把右边前几个给左边多余的就扔掉
右边更短的话,就覆盖左边的前几个:
go
dst := []int{10,20,30,40,50} // len=5
src := []int{1,2} // len=2
copy(dst, src)dst = 1,2,30,40,50
3.输入输出
输入
css
var a, b int
fmt.Scan(&a, &b) // 类似 cin >> a >> b
fmt.Scanf("%d %d\n", &a, &b) // 类似 scanf,注意 \n 吃掉换行符输出
javascript
fmt.Println("hello") // 自动换行
fmt.Printf("%d %.1f", a, b) // 格式化输出,类似 printffmt.Scan很像c++的cin
也有fmt.Scanf类似于scanf,需要注意的是这个容易在缓存区留下换行符,下一个输入可能出错
fmt.Scanln类似于getline可以读取空格,但是也需要注意这个不能和其他输入混合使用,因为其他输入会留下一个换行符,但是可以在使用完fmt.Scan之后再用一个fmt.Scanln这个直接吃掉那个换行符,然后下一个fmt.Scanln就正常输入了,如果和fmt.Scanf搭配,可以在Scanf后面加上\n或者不加\n但是多写一个Scanln
|------------|---------------------------------|----------------------------|
| 题目输入情况 | 推荐写法 | 备注 |
| 全是整数/浮点数 | fmt.Scan(&a, &b) | 最稳,啥都不用管 |
| 固定格式整数 | fmt.Scanf("%d %d\n", &a, &b) | 加 \n 吃掉换行 |
| 读一行带空格的字符串 | fmt.Scanln(&s) | 但前面如果有 Scan,先空读一行吃掉残留 |
| 混合:先整数后字符串 | Scan → 空 Scanln → Scanln(&s) | 中间那个空 Scanln 就是你的"getchar" |
| 复杂输入/不确定格式 | bufio.Scanner 逐行读 | 最通用,自己解析 |
4.字符串
Go 语言的字符串是不可变的,不能直接修改字符串中的某个字符
go
s := "hello"
s[0] = 'H' // 编译错误:cannot assign to s[0]那该怎么修改呢?
把字符串转换为切片,对切片进行修改,最后把切片重新赋值给原来的字符串
法1:转成 []byte,切片
go
s := "hello"
b := []byte(s) // 转成字节切片
b[0] = 'H' // 修改
s = string(b) // 转回字符串
fmt.Println(s) // Hello法2:转成 []rune,字符串有中文和emoji时
go
s := "你好"
r := []rune(s)
r[0] = '大'
s = string(r)
fmt.Println(s) // 大好byte :是 uint8 的别名,占 1 个字节,只能表示 ASCII 字符(英文、数字、符号)
rune:是 int32 的别名,占 4 个字节,能表示所有 Unicode 字符(中文、日文、emoji 等)
就是因为中文一个字占 3 个字节,而 byte 只能一次处理 1 个字节,所以会把一个中文字符拆成 3 个看不懂的乱码字节。rune 占 4 个字节,能完整装下一个中文字符。
4.1 strings包:
Go strings 包常用函数速查
| 函数 | 作用 | 示例 |
|---|---|---|
strings.Contains(s, substr) bool |
是否包含子串 | strings.Contains("hello", "ll") // true |
strings.ContainsAny(s, chars) bool |
是否包含 chars 中任意字符 | strings.ContainsAny("hello", "aeiou") // true |
strings.HasPrefix(s, prefix) bool |
是否以指定前缀开头 | strings.HasPrefix("hello", "he") // true |
strings.HasSuffix(s, suffix) bool |
是否以指定后缀结尾 | strings.HasSuffix("hello", "lo") // true |
strings.Index(s, substr) int |
子串首次出现的位置 | strings.Index("hello", "l") // 2 |
strings.IndexAny(s, chars) int |
chars 任意字符首次出现的位置 | strings.IndexAny("hello", "aeiou") // 1 |
strings.Count(s, substr) int |
子串出现的次数 | strings.Count("hello", "l") // 2 |
strings.Replace(s, old, new, n) string |
替换子串 n 次,-1 全替换 | strings.Replace("hello", "l", "x", -1) // "hexxo" |
strings.Split(s, sep) []string |
按分隔符切割 | strings.Split("a,b,c", ",") // "a","b","c" |
strings.Join(strs, sep) string |
用分隔符拼接 | strings.Join([]string{"a","b"}, "-") // "a-b" |
strings.TrimSpace(s) string |
去除首尾空白 | strings.TrimSpace(" hello ") // "hello" |
strings.ToLower(s) string |
转为小写 | strings.ToLower("HELLO") // "hello" |
strings.ToUpper(s) string |
转为大写 | strings.ToUpper("hello") // "HELLO" |
4.2 Strconv包:
Go 里不能随便 字符串+数字,+两边类型必须一样
4.2.1Atoi / Itoa:
这里的int指的是10进制,别的进制转换要用ParseInt
4.2.1.1 strconv.Atoi(s string) (int, error):
字符串转 int,Atoi = ASCII to int
go
num, err := strconv.Atoi("123")
// num=123传 "abc"、"12a3" 会报错,一定要接 error
4.2.1.2 strconv.Itoa(i int) string:
**int 转字符串,**Itoa = int to ASCII
css
s := strconv.Itoa(456)
// s = "456"4.2.2 Parse 系列:字符串 → 各种类型:
ParseInt 字符串转整数(可指定进制):
go
// 二进制 "1010" 转十进制
num, _ := strconv.ParseInt("1010", 2, 64)
// 结果 103个参数:
-
要转的字符串
-
进制:2/8/10/16
-
位大小:64、32
4.2.2.1 ParseFloat 字符串转小数:
go
f, _ := strconv.ParseFloat("3.14", 64)
// f = 3.144.2.2.2 ParseBool 字符串转布尔
css
b, _ := strconv.ParseBool("true")
// 支持:"true" "false" "1" "0"4.2.3: Format 系列:数字 / 布尔 → 字符串
和 Parse 反过来
4.2.3.1. FormatInt 整数转任意进制字符串
go
// 把 10 转 二进制字符串
s := strconv.FormatInt(10, 2)
// "1010"4.2.3.2. FormatFloat 小数转字符串
css
s := strconv.FormatFloat(3.1415, 'f', 2, 64)
// 保留2位小数 → "3.14"4.2.3.3FormatBool 布尔转字符串
nginx
s := strconv.FormatBool(true)
// "true"5.类型转换
Go语言中没有double这个类型,代替他的是float64,还有float32和c中的float一样,Go中不能用int类型直接乘除浮点数,必须强制类型转换之后才可以进行运算
java
var n int = 3
var t float64 = 500.0类型不匹配,编译器报错:
makefile
result := t / n强制类型转换后正确(应该叫显示类型转换)
go
result := t / float64(n)6.defer,下文把函数写完之后再写函数和defer之间的各种返回,对应大标题10
作用:把defer引用的内容推迟到return前执行
swift
func main() {
fmt.Println("开始")
defer fmt.Println("我是 defer")
fmt.Println("结束")
}输出:
swift
开始
结束
我是 defer一般在打开文件的时候后面立即写一个defer,保证不会忘记关闭文件
go
func readFile() {
f, _ := os.Open("data.txt") // 打开文件
defer f.Close() // 保证函数结束时关闭文件
// ... 读取处理数据 ...
// 不管这中间发生了啥,f.Close() 一定会执行
}defer的执行顺序类似于栈
swift
func main() {
defer fmt.Println("第 1 个 defer")
defer fmt.Println("第 2 个 defer")
defer fmt.Println("第 3 个 defer")
fmt.Println("函数体")
}输出:
swift
函数体
第 3 个 defer
第 2 个 defer
第 1 个 defer6.1.普通的defer就类似于拍照
当场就把上面最近的x值记录下来,以后x再怎么改变输出的还是最开始那个x值
defer 注册时立刻把 x 的值(10)拷进去,后面 x 怎么改都没用。
go
package main
import "fmt"
func main() {
x := 10
// 写法1:普通defer,定义瞬间就把 x 的值拷贝固定
defer fmt.Println("普通直接defer:", x)
x = 20 // 后面修改原变量,不影响已经拷贝的值
}
// 输出:普通直接defer: 10普通 defer fmt.Println(x)遇到这行,立刻把 x 当前的值拷贝下来,存的是数值
6.2.用闭包
6.2.1.defer+无参闭包
无参数函数的闭包底层记录的是x变量的地址,注意这里是地址,所以x的值是可以改变的,有点类似于c/c++的指针,修改x是修改x地址里面的值,所以最后的输出会改变
go
package main
import "fmt"
func main() {
x := 10
// 写法2:无参闭包,只记x的内存地址,不拷贝值
defer func() {
fmt.Println("无参闭包defer:", x)
}()
x = 20 // 修改的是原地址里的值
}
// 输出:无参闭包defer: 20无参闭包 defer func(){ fmt.Println(x) }()
只记住 **x 这个变量在内存里的位置(地址)**
**6.2.2.defer + 有参闭包**
**有参函数闭包就是把x的值直接复制给n了,最后输出的是n那个地址指的值**
```x作为参数传给n,,Go 的参数传递是值拷贝,所以 n得到的是x 当时的值(10),n是闭包自己的局部变量,有自己的地址,和原来的x` 已经没有关系了``
go
package main
import "fmt"
func main() {
x := 10
// 写法3:有参闭包,定义瞬间把当前x传进去,拷贝一份
defer func(n int) {
fmt.Println("有参闭包defer:", n)
}(x)
x = 20
}
// 输出:有参闭包defer: 10**所以输出后的是copy某个值的n,这种类似于函数参数的一般都是copy一份**
**提问:**
下面的函数输出结果是什么?
swift
func deferFuncParameter(){
var aInt = 1
defer fmt.Println(aInt)
aInt = 2
return
}这里是考察defer的注册调用,在defer注册时,会将变量的数值一并记录,即使变量在后来发生了改变,也不会影响已经注册的调用,故这里会输出 1
下面函数会输出什么?
go
func deferFuncReturn() (result int){
i := 1
defer func() {
result++
}()
return i
}
func main() {
res := deferFuncReturn()
fmt.Println(res)
}这里是defer的易错点 ,在deferFuncReturn函数中我们将i赋值给result,此时栈区的result被赋值为i,而此由于函数中没有重声明result,所以defer中的result++会将栈区上的result自增,故最后result的值为2,所以会输出2
这里会有疑惑,defer不是在return之前执行吗?
对,defer 在 return 之前执行。但这个"之前"容易有歧义。
return 不是一个瞬间完成的动作,它分两步走:
go
func test() (result int) {
i := 1
defer func() {
result++ // 步骤②:执行 defer,result 变成 2
}()
return i // 步骤①:result = i(把 i 的值赋给 result)
}Go 命名返回值函数的执行顺序
| 步骤 | 操作 |
|---|---|
| 步骤① | 把 return 后面的值(i)赋给返回值变量(result) |
| 步骤② | 执行所有 defer(后进先出) |
| 步骤③ | 函数真正返回(带着最终的 result) |
defer 在 return 语句"赋值"之后、函数"真正退出"之前执行
return 三步走:赋值 → defer → 返回
7.iota
iota 是 Go 语言里的一个 特殊常量生成器**,它只在 const 声明块里使用。**
****iota 在 `const` 块内从 0 开始,每出现一行常量声明就自动加 1****
go
const (
A = iota // 0
B = iota // 1
C = iota // 2
)
fmt.Println(A, B, C) // 0 1 2省略iota之后就是这样:
这个会继承上一行的表达式,赋值了的话就不会继承表达式了,就直接等于那个值了
go
const (
A = iota // 0
B // 1(继承上一行的表达式 = iota)
C // 2(同上)
)iota 的计数只看行数,不看是否使用:
go
const (
A = iota // 0
B = 100 // 1(iota 仍然是 1,但 B 的值是 100)
C = iota // 2
)
fmt.Println(A, B, C) // 0 100 2iota 只管计数,不管你用它来做什么 。B = 100 这行 iota 仍然从 0 涨到了 1,只是 B 自己没用它
位掩码
go
const (
Read = 1 << iota // 1 << 0 = 1
Write // 1 << 1 = 2
Execute // 1 << 2 = 4
)
fmt.Println(Read, Write, Execute) // 1 2 4数量级
go
const (
B = 1 << (10 * iota) // 1 << 0 = 1
KB // 1 << 10 = 1024
MB // 1 << 20 = 1048576
GB // 1 << 30 = 1073741824
)iota 可以参与复杂表达式
go
const (
a = iota * 2 // 0 * 2 = 0
b = iota * 2 // 1 * 2 = 2
c = iota * 2 + 1 // 2 * 2 + 1 = 5
d // 继承上一行:3 * 2 + 1 = 7
)
fmt.Println(a, b, c, d) // 0 2 5 7跳过某个值
用 _ 可以跳过一个 iota,不影响计数
go
const (
A = iota // 0
_ // 1(跳过)
C // 2
)
fmt.Println(A, C) // 0 2多个 iota 写在同行
同一行的 iota 值相同,下一行才会加 1:
go
const (
A, B = iota, iota + 1 // 0, 1
C, D // 1, 2
E, F // 2, 3
)
fmt.Println(A, B, C, D, E, F) // 0 1 1 2 2 3iota 按行 增长,如果iota起始值一样,同一行的两个 iota 值相等
提问:
下面函数的输出结果是什么?
go
const(
a = 1 << iota
b = 1 << iota
c = 3
d = 1 << iota
e // e = 1 << iota
f
)
func main() {
fmt.Println(a,b,c,d,e,f)
}这里考察iota的应用原理,iota在const的声明中会从0开始在每一行进行自增,同时如果仅声明变量而没有操作的话就会沿顺上一行的操作进行赋值,故会输出1,2,3,8,16,32
go
const (
a = 1 << iota // iota = 0, a = 1 << 0 = 1
b = 1 << iota // iota = 1, b = 1 << 1 = 2
c = 3 // iota = 2, c 直接赋值为 3
d = 1 << iota // iota = 3, d = 1 << 3 = 8
e // iota = 4, 继承上一行的表达式 "1 << iota" , e = 1 << 4 = 16
f // iota = 5, 继承上一行的表达式 "1 << iota" , f = 1 << 5 = 32
)8.map
键值对集合,类似于C++里的 unordered_map
创建时还是用make
go
// 创建一个键为 string,值为 int 的 map
m := make(map[string]int)
// 添加键值对
m["小明"] = 95
m["小红"] = 88或者也可以直接初始化:
go
m := map[string]int{
"小明": 95,
"小红": 88,
}未初始化的 map 是 `nil`,不能直接写入:
go
var m map[string]int // m == nil
m["小明"] = 95 // panic!必须先 make必须用 `make` 或字面量初始化后才能用,**`make` 在底层做了内存分配**
基本用法还是增删改查:
bash
增 / 改:Go 里的 map:key 不能重复,value 完全可以重复
-
键(key):唯一、不允许重复,重复赋值会覆盖旧值
-
值(value):随便重复,多个不同 key 可以存一模一样的 value
-
一个 key 只能对应一个 value
javascript
m["小刚"] = 76 // 增加新键
m["小明"] = 100 // 修改已有键的值查:
go
score := m["小明"] // 100
fmt.Println(score)如果查找了一个不存在的键,返回值为0
go
score2 := m["不存在"] // 0(int 的零值)
fmt.Println(score2)安全查找:用ok判断键是否存在,ok为bool类型
go
score, ok := m["不存在"]
if ok {
fmt.Println("存在,值为", score)
} else {
fmt.Println("不存在")
}删:
perl
delete(m, "小刚") // 删除键"小刚"遍历:
perl
for key, value := range m {
fmt.Printf("%s: %d\n", key, value)
}map 的遍历顺序是随机的,每次运行结构顺序可能不一样
go
package main
import "fmt"
func main() {
m := map[string]int{
"小明": 95,
"小红": 88,
"小刚": 76,
"小李": 82,
}
for k, v := range m {
fmt.Printf("%s: %d\n", k, v)
}
}第一次运行:
makefile
小李: 82
小红: 88
小明: 95
小刚: 76第二次运行:
makefile
小明: 95
小刚: 76
小红: 88
小李: 82map使用:
提问:如何统计一个数组中每个数字出现的次数?
go
func main() {
arr := []int{1, 2, 3, 2, 1, 3, 3}
count := make(map[int]int)
for _, v := range arr {
count[v]++ // 出现一次就 +1
}
for k, v := range count {
fmt.Printf("%d 出现了 %d 次\n", k, v)
}
}输出:
9.结构体
Go里面结构体定义使用type,同样类型名字放在最后面
go
type Student struct {
Name string
Age int
Score float64
}结构体变量:
css
s1 := Student{
Name: "小明",
Age: 18,
Score: 95.5,
}或者先声明后赋值:
javascript
var s2 Student
s2.Name = "小红"
s2.Age = 19修改j结构体变量:
apache
fmt.Println(s1.Name)
s1.Score = 10010.函数
基础类型:
和其他语言一样,只不过数据类型写到后面了
go
package main
import "fmt"
func add(a int, b int) int {
return a + b
}
func main() {
res := add(1, 2)
fmt.Println(res)
}输出3
Go语言的函数可以返回多个类型
css
package main
import "fmt"
func div(a, b int) (int, int) {
return a / b, a % b
}
func main() {
x, y := div(10,3)
fmt.Println(x, y)
}两个返回的值,分别给两个int
如果两个返回值只想要其中一个,可以把另外一个变成_下划线
apache
x,_:=div(10,3)命名返回值
go
func sum(a, b int) (res int) {
res = a + b
return
}
func main() {
res := sum(1, 2)
fmt.Println(res)
}func sum(a, b int) (res int)
注意这里的返回值不仅仅是个类型,还有个具体的变量,其实就相当于return res
命名返回值 / 无命名返回值+ return 带名 / 不带名 + defer
首先回忆上文return 不是一个瞬间完成的动作,它分两步走:
go
func test() (result int) {
i := 1
defer func() {
result++ // 步骤②:执行 defer,result 变成 2
}()
return i // 步骤①:result = i(把 i 的值赋给 result)
}| 步骤 | 操作 |
|---|---|
| 步骤① | 把 return 后面的值(i)赋给返回值变量(result) |
| 步骤② | 执行所有 defer(后进先出) |
| 步骤③ | 函数真正返回(带着最终的 result) |
defer 在 return 语句"赋值"之后、函数"真正退出"之前执行
return 三步走:赋值 → defer → 返回
无命名返回值说人话:函数快结束的时候,return后面的那个返回值在此时已经赋值给函数了,此时调用这个函数他就是现在return后面那个值的值,然后再执行defer,但是此时执行defer,不管再怎么改,函数的值早都固定了,defer改变不了函数的值了,最后后再执行return也就是结束函数
defer在函数里面,函数返回的最后是那个类型参数,无命名返回值没有类型参数,他那个顺序不是return后那个变量先赋值给那个类型参数吗,如果没有类型参数就直接给函数,其实可以假设给了个空的类型参数,赋值之后才执行defer,defer如果能影响那个类型参数,那个类型参数在函数结束之前是多少,函数就返回多少,无命名返回值那个是空的,所以defer肯定对其没有影响,所以肯定就返回return赋的那个值,命名返回值的那个类型参数如果被defer改了,最后就返回那个改了的,一句话就是函数返回那个类型参数的值
无命名返回值:只写类型,不写变量名,defer不可修改返回值
go
func test() int {
res := 0
defer func() { res++ }()
return res // 这里的res是局部变量
}局部变量哦
第一步:return res → 把局部变量 res 的值(0)复制到一个「临时返回空间」,这个空间的值就固定成 0 了
第二步:执行 defer → 只修改了局部变量 res,但临时返回空间的值还是 0
第三步:函数返回临时空间里的 0
命名返回值:写类型 + 变量名,变量会被自动初始化为零值,defer可以修改返回值,最后返回的是(res int)这里面的res,return可以赋值给这个,但是最后返回的始终是命名的这个参数的值,return赋值那部分如果赋值给那个类型参数了,后面defer改这个类型参数才会改变函数返回值,如果仅仅改变return后面的那个变量而没影响到这个类型参数,那么返回值是不会改变的
go
func test() (res int) { // res 是命名返回值,不是局部变量
defer func() { res++ }()
return res
}这里不是局部变量了
1.res 是函数的「返回值变量」,不是临时空间
,函数一开始就创建好了,初始值是 0
2.执行 return res → 把 res 当前的值(0)赋值给它自己 (res = res,相当于确认一下要返回的变量是 res 本身,而不是一个副本)
3.再执行 defer
→ res++,直接修改了这个「返回值变量」的值,res 变成 1
4.函数真正返回的时候,返回的是变量 res 的当前值 ,也就是 1
总结:就是说命名返回值再return之前res是什么就返回什么,整个函数返回前res是什么就返回什么,无命名返回值是不算defer之前的res,defer没影响
return 的两种写法(仅对命名返回值有区别):
return 不带名:直接写 return,自动返回命名返回值的当前值
return 带名:写 return a, b,会先把对应值赋值给命名返回值,再返回
4 种组合 + defer 执行逻辑:
情况 1:无命名返回值 + return 带值
go
func test() int { // 无命名返回值
res := 0
defer func() {
res++ // defer 修改的是局部变量res
}()
return res // 步骤:① 把res=0复制到临时返回空间 ② 执行defer(res变成1) ③ 返回临时空间的0
}最终返回值:0
情况 2:命名返回值 + return 不带名(defer 可修改)
go
func test() (res int) { // 命名返回值,res自动初始化为0
defer func() {
res++ // defer 修改的是命名返回值res
}()
return // 步骤:① 确认返回res的当前值(0) ② 执行defer(res变成1) ③ 返回res的最终值1
}最终返回值:1
情况 3:命名返回值 + return 带名(defer 可修改)
go
func test() (res int) { // res=0
defer func() {
res++
}()
return res // 步骤:① 把res=0赋值给返回值变量res ② 执行defer(res变成1) ③ 返回1
}最终返回值:1
情况 4:命名返回值 + return 带其他变量(defer 可修改)
go
func test() (res int) { // res=0
i := 1
defer func() {
res++
}()
return i // 步骤:① 把i=1赋值给res → res=1 ② 执行defer(res变成2) ③ 返回2
}最终返回值:2
再次总结这里,命名返回值最后整个函数结束的时候,他那个返回数据类型前面的参数是多少整个函数就返回多少,defer如果对那个参数有影响那么返回值是会改变的,无命名返回值是按照那个顺序执行,defer之前就把return后面的值给函数了,defer没影响
提问:
下面代码输出什么?
go
func f(index string, a,b int)(x int) {
ret := a+b
fmt.Println(index, a, b, ret)
defer func() {
ret++
}()
return ret
}
func main() {
x := 1
y := 2
defer f("A", x ,f("AA",x ,y))
x = 10
defer f("B", x, f("BB",x ,y))
y = 20
}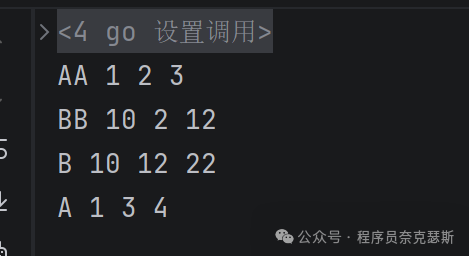
遇到defer的时候,先登记下来所有的参数,把括号里面的参数先全部算出来,然后固定,这个顺序走的时候碰到defer就这样登记,然后主函数走完的时候倒着(栈)往上运行defer
完整走一遍:
第一步遇到第一个defer,此时先登记,发现里面有个可运算的,也就是f("AA",x ,y),先计算这个此时输出 AA 1 2 3,此时标记固定登记第一个defer的三个参数,AA 1 2 3 这里多说一下,此时ret最后是4,但是在其++之前就赋值给x了,x是函数返回值,所以是3
继续走第二步,第二个defer,继续登记,遇到一个f,计算输出 BB 10 2 12
第三步:主函数结束前,倒着defer,输出 B 10 12 22
第四步:走上一个defer输出他登记的参数计算的结果 A 1 3 4
函数的参数传递:
go
package main
import "fmt"
func change(a int) {
a = 100 // 修改的是函数内部的副本
}
func main() {
x := 10
change(x) // 把 x 的值 10 拷贝一份传给 change
fmt.Println(x) // 输出:10(x 本身没被改)
}输出:10
遇到这种有类似于c中形参的基本上都是copy,上面这个a就类似于是形参
要改变和c也非常类似,直接取地址
go
package main
import "fmt"
func change(a *int) {
*a = 100
}
func main() {
x := 10
change(&x) // 把x的地址传给函数
fmt.Println(x)
}输出:100
有点特殊的是切片这种:
go
package main
import "fmt"
func change(s []int) {
s[0] = 100
}
func main() {
arr := []int{1, 2, 3}
change(arr)
fmt.Println(arr) // 输出:[100 2 3]
}这种之所以能改变,就是上文说的,遇到这种类似于形参的,其实就是拷贝,s:=arr,切片的拷贝是浅拷贝,会改变原切片的值的
原理就是把底层的那个指针也给拷贝了,两个切片指针指向的是同一个地方,指针指向的值也是一样的
函数还有一种写法:
go
package main
import "fmt"
func main() {
// 1. 定义一个匿名函数,并赋值给变量 x
x := func() {
fmt.Println("hello world")
}
// 2. 调用这个匿名函数
x()
}匿名函数:
匿名函数 = 没有名字的函数
普通函数有名字 func f1(),匿名函数不写函数名,直接定义、直接用
对比一下:
普通函数:
go
func hello() {
println("我是有名函数")
}有名字 hello,想用就调用 hello()
匿名函数(没名字):
go
func() {
println("我是匿名函数")
}()func(),后面没写函数名,最后加 () 就是当场直接执行
匿名函数定义完立马跑(自执行)
go
package main
import "fmt"
func main() {
// 匿名函数,定义完马上跑
func(a, b int) {
fmt.Println(a + b)
}(3, 5) // 括号里传参
}或者可以把把匿名函数赋值给变量:
go
// 返回一个匿名函数
func f1() func() int {
a, b := 0, 1
// 这个就是匿名函数:没有函数名
return func() int {
a, b = b, a+b
return a
}
}func() int { ... },就是**匿名函数,**后面赋值给 f1,f1就代表这个匿名函数
看这一行:
go
func
f1
()
func
()
intfunc() int 是发f1的返回类型,f1这个函数返回的就是这个匿名函数
闭包:
闭包:外层函数 + 内层函数 + 外层变量
外面一个函数,里面内层一个匿名函数,内层函数用了外层函数的变量,外层把内层****返回出去
局部变量生命周期:
普通函数:跑完就死,变量没了
闭包:变量被内层函数带走了,只要内层函数还在,变量就****一直活着,可以反复用、反复改
闭包 = 匿名函数 + 它抱着的外部变量
不是单独一个函数,是函数 + 变量绑在一起
编译器检测到闭包,把变量分配到堆上:
-
普通变量:栈 → 函数结束自动销毁
-
闭包变量:堆 → 不会自动销毁
-
只要有人用,就一直活着
每次调用外层函数,都会创建新的一套变量:返回多个闭包 = 多个副本,互不干扰
css
f1 := outer()
f2 := outer()f1 一套变量,f2 一套新变量,互相独立,不干扰,各算各的
多次调用闭包,会一直修改同一个变量,闭包修改外部变量,每次调用都有影响
css
f := outer()
f() // 变量变了
f() // 变量接着变
f() // 继续变永远用同一个变量,不会重置,一直叠加、一直保留状态
提问:下列代码输出什么?
go
func f1() func() int {
a, b := 0, 1
return func() int {
a, b = b, a+b
return a
}
}
func main() {
f := f1()
for i := 0; i < 10; i++ {
fmt.Printf("%d\n", f())
}
}这里a,b会被闭包捕获,在十次循环中反复执行a, b = b, a+b,故会输出:1,1,2,3,5,8,13,21,34,55
其实就是斐波那契数列
提问:下面代码输出什么?
go
func text(nums int) (func(int) int, func(int) int) {
f1 := func(i int) int {
nums += i
return nums
}
f2 := func(i int) int {
nums -= i
return nums
}
return f1, f2
}
func main() {
f1, f2 := text(12)
fmt.Println(f1(10), f2(20))
}分析:nums作为text函数的形参,也就是两个匿名函数的外层变量,闭包,两个匿名函数公用一个nums
第一步:执行 text(12),进入 text 函数,nums = 12,创建 f1 (加法闭包),创建 f2(减法闭包),f1 和 f2 都抱着同一个 nums!!!,返回 f1、f2 给 main
第二步:执行 f1(10)
makefile
nums += 10
nums = 12 + 10 = 22
返回 22现在nums是22了
最后:执行 f2(20)
注意:**nums 已经是 22 了!不是 12!**因为 f1 和 f2 共用同一个闭包变量!
makefile
nums -= 20
nums = 22 - 20 = 2
返回 2最后输出 22 2
11.方法
Go的方法,就是属于某个结构体的函数,结构体变量作为参数
和普通的函数不一样的是,方法就是在普通函数func ( 接收者) SayHello(),那个括号的位置写一个接收者
比如:
go
type Student struct {
Name string
Score float64
}现在想给 Student 加一个"自我介绍"的功能,就写一个方法:
swift
func (s Student) SayHello() {
fmt.Printf("我叫%s,考了%.1f分\n", s.Name, s.Score)
}
bash
这就是一个方法,和函数的区别就是前面多了 (s Student)
bash
调用:
apache
s := Student{Name: "小明", Score: 95.5}
s.SayHello() // 我叫小明,考了95.5分
bash
还可以这样调用:
go
func main() {
// 3. 创建Student实例
stu := Student{
Name: "zhangsan",
Age: 20,
}
// 4. 调用结构体的方法(和面向对象里调用类的成员函数一样)
stu.SayHello()
}
bash
如果改成指针接收者,就能修改原结构体:
bash
还是形参那个原理
bash
就算是指针类型也可以使用上面(stu.SayHello())那个调用方法,不用写成((&stu).SayHello()),go语言背后自动转换了
go
// 指针接收者:调用时传递结构体地址,修改的是原实例
func (stu *Student) SayHello() {
stu.Age = 30 // 这里修改会影响main里的stu
}
bash
接收者只能是结构体,那我想要接收者是int怎么办?
go
package main
import "fmt"
// 1. 自定义类型:把 int 定义成新类型 MyInt
type MyInt int
// 2. 给 MyInt 绑定一个方法 Double()
func (m MyInt) Double() MyInt {
return m * 2
}
func main() {
var m MyInt
m = 20
fmt.Println(m) // 输出:20
m = m.Double() // 调用方法,把 m 翻倍
fmt.Println(m) // 输出:40
}
bash
方法要区分形参和命名返回值:
bash
完整方法:
go
func (接收者) 方法名(形参列表) (命名返回值) {
// 函数体
}紧贴函数名字的括号里面是形参
go
// 这个 age 是【形参】
func (s *stu) setAge(age int) {
}
bash
函数后面的括号后面的返回值类型那个是命名返回值
go
// 这里 age 才是【命名返回值】
func (s stu) getAge() (age int) {
}
bash
如何调用:
go
func (s *stu) setAge(age int)
bash
正常语法糖调用(平时这么写):
javascript
var s stu
s.setAge(20)
bash
原生底层函数调用(无语法糖):
apache
stu.setAge(&s, 20)
bash
提问:下面代码是否有问题?
go
type stu struct {
Age int
Name string
}
func (s stu) getName() string {
return s.Name
}
func (s *stu) setAge(age int) {
s.Age = age
}
func (stu) getAge() int {
return stu.Age
}
func main() {
s := stu{Age : 16,Name: "Gopher"}
stu.getName(s)
stu.setAge(s, 20)
(*stu).getName(&s)
(*stu).setAge(&s, 30)
s.getAge()
}
javascript
stu.setAge(s, 20) // 错误
bash
setAge
bash
还有getAge方法接收者没写全
bash
改:
go
package main
type stu struct {
Age int
Name string
}
func (s stu) getName() string {
return s.Name
}
func (s *stu) setAge(age int) {
s.Age = age
}
func (s stu) getAge() int {
return s.Age
}
func main() {
s := stu{Age: 16, Name: "Gopher"}
stu.getName(s)
(*stu).setAge(&s, 20)
(*stu).getName(&s)
(*stu).setAge(&s, 30)
s.getAge()
}
bash
这里提出疑问?
bash
为什么在第二次调用getName的时候用的指针,他的参数明显不是指针类型啊
bash
不是指针类型也可以传指针啊,只不过会改变原来的值,传参数的话相当于copy一份,指针copy地址可以改值
bash
再问:两次调用setAge会不会覆盖?
bash
会,第二次赋值覆盖第一次12.接口
接口是一组方法的集合,只定义****方法签名**(方法名、参数、返回值),不写实现代码
定义接口:
interface,大括号里面写方法,可以多个方法,可以不写返回值(下面那个string)和参数,可以单纯写个Speak()
```typescript
type Animal interface {
Speak() string
}方法:
go
type Dog struct{}
func (d Dog) Speak() string {
return "汪汪"
}
type Cat struct{}
func (c Cat) Speak() string {
return "喵喵"
}接口接收:
javascript
func main() {
var a Animal // 接口类型变量
a = Dog{}
fmt.Println(a.Speak()) // 汪汪
a = Cat{}
fmt.Println(a.Speak()) // 喵喵
}谁实现了接口全部方法,谁就能赋值给接口变量
多接口实现 + 接口赋值:
我写两个、三个不同的接口一个结构体,把所有接口里的方法全都实现那这个结构体,就同时属于多个接口:
typescript
// 接口1:会叫
type Speaker interface {
Speak() string
}
// 接口2:会跑
type Runner interface {
Run() string
}
go
// 狗结构体
type Dog struct{}
// 实现 Speaker 的方法
func (d Dog) Speak() string {
return "汪汪叫"
}
// 实现 Runner 的方法
func (d Dog) Run() string {
return "四条腿快跑"
}接口赋值:
go
package main
import "fmt"
// 两个接口
type Speaker interface {
Speak() string
}
type Runner interface {
Run() string
}
type Dog struct{}
func (d Dog) Speak() string { return "汪汪叫" }
func (d Dog) Run() string { return "四条腿快跑" }
func main() {
// 1. 先造一个狗
myDog := Dog{}
// 2. 接口赋值:Dog 赋给 Speaker 接口
var s Speaker
s = myDog // 合法!Dog实现了Speaker
fmt.Println(s.Speak())
// 3. 接口赋值:Dog 赋给 Runner 接口
var r Runner
r = myDog // 合法!Dog实现了Runner
fmt.Println(r.Run())
}输出: 汪汪叫
四条腿快跑
赋值给 Speaker 时,只能用「叫」的方法
赋值给 Runner 时,只能用「跑」的方法
接口会屏蔽掉不属于自己的方法
空接口赋值(万能赋值):
所有类型都能赋值给空接口
go
package main
import "fmt"
func main() {
// 定义空接口变量x
var x interface{}
x = 100 // 赋值int
x = 3.14 // 赋值float64
x = "zhangsan" // 赋值string
x = true // 赋值bool
fmt.Println(x)
}输出true,后面的赋值覆盖前面的赋值
类型断言:
不安全写法:
go
package main
import "fmt"
func main() {
var x interface{} = true
// 不安全写法:如果类型不匹配,直接 panic 崩溃
num := x.(int)
fmt.Println(num)
}安全写法:使用ok
go
package main
import "fmt"
func main() {
var x interface{} = 10
// 安全写法:带 ok 检查,类型不匹配也不会崩溃
v, ok := x.(int)
if ok {
fmt.Println("x是int类型", v)
} else {
fmt.Println("x不是int类型")
}
}
go
package main
import "fmt"
// 接收任意类型,判断是否为 int
func CheckInt(x interface{}) bool {
_, ok := x.(int)
if ok {
return true
} else {
return false
}
}
func main() {
// 调用函数,检查 10 是否为 int
result := CheckInt(10)
fmt.Println(result) // 输出 true
}13.error
两种方法:
法1:errors.New这个只能返回固定的字符串,这个有返回值,是error类型
go
package main
import (
"errors"
"fmt"
)
func divide(a, b int) (int, error) {
if b == 0 {
return 0, errors.New("除数不能为0")
} else {
return a / b, nil
}
}
func main() {
res, err := divide(10, 0)
if err != nil {
fmt.Println("执行失败:", err)
} else {
fmt.Println(res)
}
}执行失败: 除数不能为0
法2:Errorf,类似于printf的感觉,可以格式化,也有返回值,类型也是error
go
package main
import (
"errors"
"fmt"
)
func divide(a, b int) (int, error) {
if b == 0 {
return 0, fmt.Errorf("%d/%d 除数不能为0", a, b)
} else {
return a / b, nil
}
}
func main() {
res, err := divide(10, 0)
if err != nil {
fmt.Println("执行失败:", err)
} else {
fmt.Println(res)
}
}执行失败: 10/0 除数不能为0,类似于printf的感觉不过Errorf有返回值类型为error
还可以这样写:
定义一个公开的、可被识别的错误常量
用 errors.Is 判断是否是同一个根错误
为什么不直接用err==ErrorDivideByZero判断呢,因为现在的err是被 fmt.Errorf 包装过的 新错误对象**,它和 ErrorDivideByZero 不是同一个变量,直接用 == 比较会返回 false,所以使用errors.Is库函数来判断**
go
package main
import (
"errors"
"fmt"
)
var ErrorDivideByZero = errors.New("divide by zero")
func divide(a, b int) (int, error) {
if b == 0 {
return 0, fmt.Errorf("%w", ErrorDivideByZero)
}
return a / b, nil
}
func main() {
res, err := divide(10, 0)
if err != nil {
fmt.Println("执行失败:", err)
if errors.Is(err, ErrorDivideByZero) {
fmt.Println("这是除零错误!")
}
} else {
fmt.Println(res)
}
}自己new的错误如何绑定到具体的错误中?
go
var ErrZero = errors.New("除数不能为0")
func div(a,b int)(int,error){
if b == 0 {
// 是你自己在这里主动用了 ErrZero
return 0, fmt.Errorf("%w", ErrZero)
}
return a/b, nil
}b==0 只是一个逻辑条件真正决定返回哪个根错误的,是你写代码的人****
kotlin
var ErrZero = errors.New("除数不能为0")
if b == 0 {
return 0, fmt.Errorf("%w", ErrZero)
}那根错误就是 ErrZero
kotlin
var ErrZero = errors.New("除数不能为0")
if b == 0 {
return 0, errors.New("我就随便写个错误")
}这里 b==0 报错,但根错误跟 ErrZero 一点关系都没有
javascript
var errA = errors.New("除数不能为0")
var errB = errors.New("除数不能为0")文字一模一样,但 完全是两个不同错误b==0 你选返回谁,谁才是根错误
总结:
提前用 errors.New 造好一个根错误变量
在函数出错的时候,用:
perl
fmt.Errorf("随便写外层提示:%w", 你提前造的那个根错误)只要把根错误放进 % w
外层新错误 和 你原来的根错误 就挂钩、绑定、连起来了
14.panic和recover
panic在英文里是慌张的意思,go语言中函数遇到panic就崩溃退出了,但是在退出之前,还是之前那个逻辑,defer不是在函数退出之前执行的吗,所以还会执行上面的defer,但是下面所有的代码就都跳过了,遇到panic,这个函数炸了,回到上一层的函数,上一层函数还是不会往下走
recover英文是恢复,挽回的意思,对应go语言中的挽回,函数遇到panic奔溃时,如果上面有defer,并且defer里面有recover的话,挽救panic,这个当前函数的下面的代码还是不会执行,但是跳出这个函数回到上一个函数,上一个函数还会继续往下走,recover () 会把你 panic (xxx) 括号里写的内容,原封不动拿回来,作为返回值
只有panic:
go
package main
import "fmt"
func testPanic() {
fmt.Println("执行testPanic函数第一步")
// 触发panic
panic("发生严重错误,触发panic")
// panic之后的代码,永远不会执行
fmt.Println("执行testPanic函数第二步")
}
func main() {
fmt.Println("main函数开始")
// 调用触发panic的函数
testPanic()
// 整个程序已崩溃,main后续代码不执行
fmt.Println("main函数结束")
}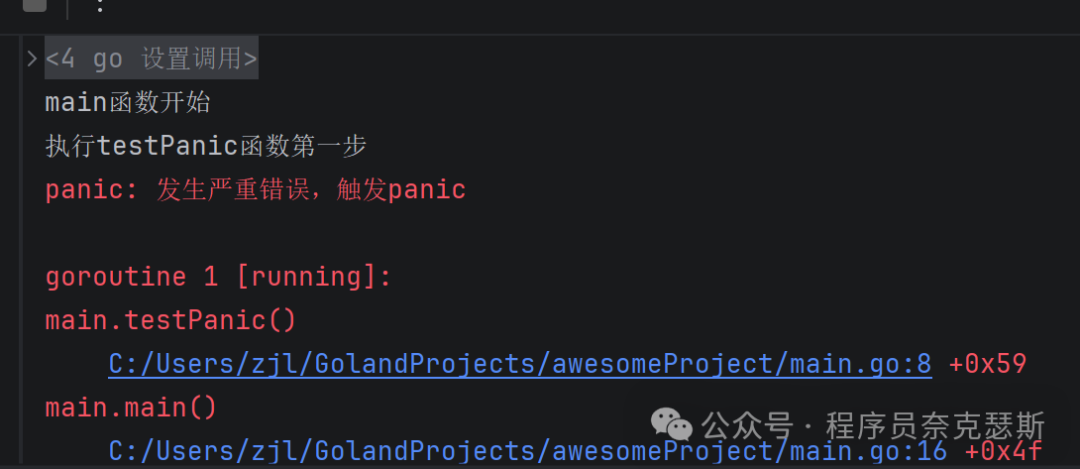
执行到panic后,当前函数后续代码直接终止,逐层向上回溯,导致 main函数后续代码也不执行,程序直接崩溃退出,打印 panic 错误信息
defer + recover 捕获 panic:
当前函数panic后面的内容还是不执行,跳出这个函数,上一层函数会往下走
recover () 会把 panic (xxx) 括号里写的内容,原封不动拿回来,作为返回值
go
package main
import "fmt"
func testRecover() {
// defer必须写在panic前,用于延迟执行+捕获panic
defer func() {
// recover() 捕获panic,返回panic的内容
if err := recover(); err != nil {
fmt.Println("捕获到panic:", err)
}
}()
fmt.Println("执行testRecover函数第一步")
// 触发panic
panic("发生严重错误,触发panic")
// panic之后的当前函数代码,依旧不执行
fmt.Println("执行testRecover函数第二步")
}
func main() {
fmt.Println("main函数开始")
// 调用函数,panic被recover捕获
testRecover()
// 程序未崩溃,main函数后续代码正常执行
fmt.Println("main函数结束")
}
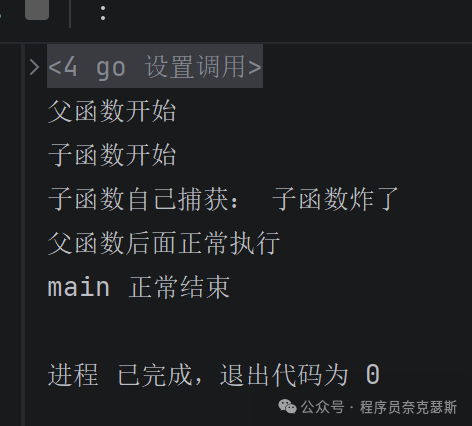
go
package main
import "fmt"
func child() {
// 子函数自己写defer+recover
defer func() {
if r := recover(); r != nil {
fmt.Println("子函数自己捕获:", r)
}
}()
fmt.Println("子函数开始")
panic("子函数炸了")
fmt.Println("子函数结束")
}
func father() {
fmt.Println("父函数开始")
child()
fmt.Println("父函数后面正常执行")
}
func main() {
father()
fmt.Println("main 正常结束")
}
跨函数recover:
go
package main
import "fmt"
func child() {
fmt.Println("child before panic")
panic("panic")
fmt.Println("child after panic") // 永远不会执行
}
func parent() {
fmt.Println("parent before panic")
defer func() {
if err := recover(); err != nil {
fmt.Println("child函数发生了panic")
}
}()
child()
fmt.Println("parent after panic") // 永远不会执行
}
func main() {
parent()
fmt.Println("main函数后续代码") // 会执行
}
提问:下面代码有无问题?
go
func main() {
defer func() {
if err := recover(); err != nil {
fmt.Println("recovered:", err)
}
}()
fmt.Println("Hello World")
panic()
}
panic()不能空调用,括号里面不能为空,因为这个括号里面的东西要返回给recover里面的err
提问:
代码输出什么
go
package main
import "fmt"
func main() {
deferCall()
}
func deferCall() {
defer func() {
fmt.Println("打印1")
}()
defer func() {
if err := recover() ; err != nil {
fmt.Println(err)
}
fmt.Println("打印2")
}()
defer func() {
fmt.Println("打印3")
}()
panic("触发异常")
defer func(){
fmt.Println("打印4")
}()
}
遇到panic,如果上面的defer里面有recover就倒着走一遍defer
15.Go并发和Goroutinte
并发:同一时间段做很多事,一个人干多件事,来回切换
并行:同一个时间点一起做事,多个人同时各干各的
Go的并发类似于java的多线程
Go 里怎么开启一个 "新线程(协程)":
Java 写法:
javascript
new Thread(() -> {
// 子线程干活
}).start();Go 超级简单,就一个关键字:go
语法:
nginx
go 你要执行的函数只要在函数前面加个 go 这个函数就单独开一条小路,并发跑,不和主程序挤一条路
和java不一样的是java里面主协程结束了,子协程还能自己走,go则是主协程结束了,全部就结束了,子协程若没完,剩下的也不会走了
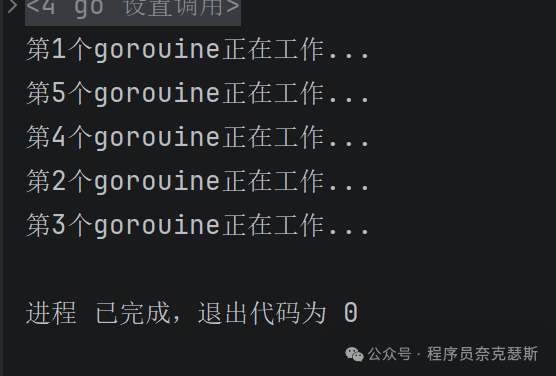
并发进行的行程,顺序是乱的,同时进行,谁先谁后都不一定
go
package main
import (
"fmt"
"time"
)
func Work(id int) {
fmt.Printf("第%d个gorouine正在工作...\n", id)
}
func main() {
// goroutine
for i := 1; i <= 5; i++ {
go Work(i)
}
time.Sleep(1 * time.Second)
}
time.Sleep:让主线程 睡一会儿,给子协程留时间干活,这样子协程就有时间在主协程走完前走完了
go
package main
import (
"fmt"
"time"
)
func work() {
fmt.Println("子协程在干活")
}
func main() {
fmt.Println("主协程开始")
go work()
// 让主协程休眠 100毫秒,等一下子协程
time.Sleep(100 * time.Millisecond)
fmt.Println("主协程结束")
}但是!我给你说缺点:
-
你不知道子协程要跑多久
-
写死睡眠时间,不标准,项目里不能用
WaitGroup:sync.WaitGroup
中文叫:等待组
这个比sleep好
wg.Add(数量):告诉它,我有几个协程要等,总数量
wg.Done():子协程干完活了,报个到,add那个数量减一
wg.Wait():主线程在这里卡住,乖乖等全部做完,add那个数字到0才结束,不然一直等待
go
package main
import (
"fmt"
"sync" // 引入sync包才能用WaitGroup
)
// 声明一个全局的WaitGroup变量
var wg sync.WaitGroup
func Work(id int) {
fmt.Printf("第%d个goroutine正在工作...\n", id)
wg.Done() // 子协程干完活,给WaitGroup打个"完成标记"
}
func main() {
// 2. 告诉WaitGroup:我要等5个协程完成
wg.Add(5)
// 3. 循环开启5个goroutine
for i := 1; i <= 5; i++ {
go Work(i)
}
// 4. 主协程在这里等待,直到所有子协程都调用了Done()
wg.Wait()
}16.channel
定义:使用make
go
// 直接定义并初始化,最常用
ch := make(chan int)或者使用var+make
1. 无缓冲通道
go
var ch chan int // 先声明
ch = make(chan int) // 再初始化- 有缓冲通道
go
var ch chan int
ch = make(chan int, 5) // 缓冲区大小5这个就很类似于切片那个cap,先预留一下
apache
s := make([]int, 0, 3) // len=0,cap=3 先预留3个位置Channel 写入数据、读出数据(发、收):
写入(发数据):ch <- 数据
意思:把 10 放进通道里
类比切片:相当于 append 往里加元素
apache
ch <- 10读出(收数据):变量 := <-ch
意思:从通道取出一个数据,赋值给 num
类比切片:相当于拿数组里的元素
从通道拿出来通道这个数据就没了
makefile
num := <- ch箭头往通道里走 = 写入箭头****
从通道往外走 = 读出
无缓冲通道(必须一发一收配对):
go
ch := make(chan int)你只写不读 → 卡住,你只读不写 → 卡住,必须一边写、一边读,两边对上才能跑
go
package main
import "fmt"
func main() {
// 无缓冲channel
ch := make(chan int)
ch <- 1 // 往通道写数据
<-ch // 从通道读数据
}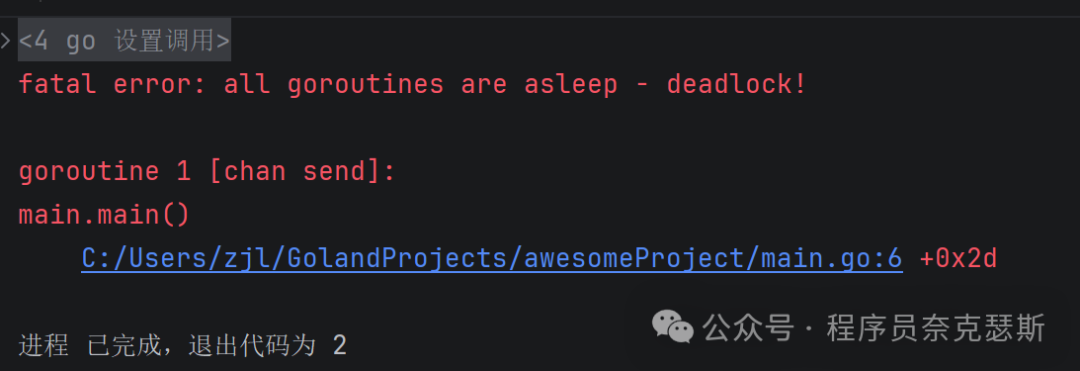
死锁,写数据必须同时读(取)数据,在一个goroutine中,当写入数据的时候还没来得及取就卡死了,必须在另外一个goroutine中取数据,两个goroutine同时进行读取同时进行才不会死锁卡住
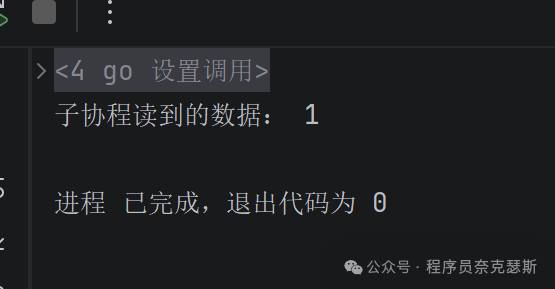
go
package main
import "fmt"
func main() {
// 无缓冲channel
ch := make(chan int)
// 开启一个goroutine负责接收数据
go func() {
// 从通道读取数据
data := <-ch
fmt.Println("子协程读到的数据:", data)
}()
// 主协程往通道发送数据
ch <- 1
}
有缓冲通道(跟切片 cap 一模一样):
读取数据和队列那个很像
go
ch := make(chan int, 3)缓冲区能存 3 个
可以先写,暂时不用读
apache
ch <- 1
ch <- 2
ch <- 3现在写满了,等于 cap 满了
再想写第 4 个 → 阻塞卡住
必须先读出来一个,才能继续写
读数据:类似于队列那样读取数据,先存什么先取什么
makefile
a := <- ch
b := <- ch演示:
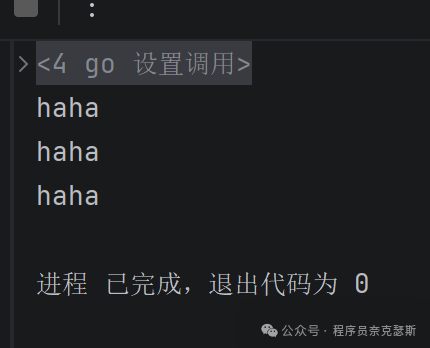
go
package main
import "fmt"
func main() {
// 缓冲容量设为3,可以存3个数据
ch := make(chan int, 4)
ch <- 1
fmt.Println("haha")
ch <- 2
fmt.Println("haha")
ch <- 3
fmt.Println("haha")
}
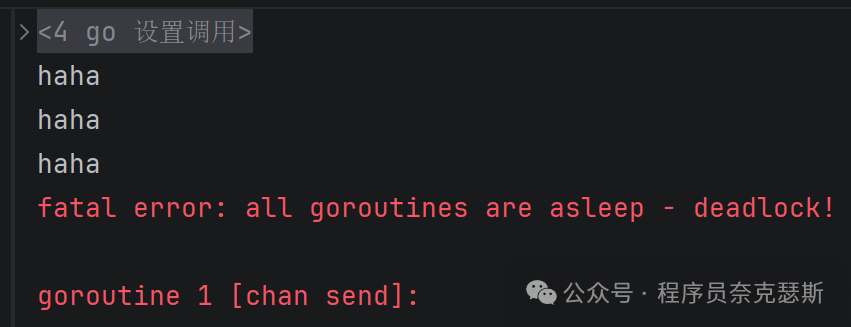
再加一个:
go
package main
import "fmt"
func main() {
// 缓冲容量设为3,可以存3个数据
ch := make(chan int,3 )
ch <- 1
fmt.Println("haha")
ch <- 2
fmt.Println("haha")
ch <- 3
fmt.Println("haha")
ch <- 4
}
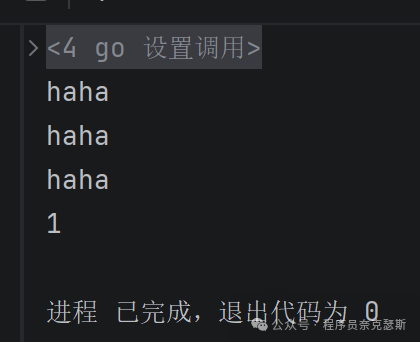
再写一个goroutine,读(取)数据,通道超的那个取出来
go
package main
import (
"fmt"
"time"
)
func main() {
// 有缓冲通道,容量为3
ch := make(chan int, 3)
// 先往通道里塞3个数据(缓冲区未满,不会阻塞)
ch <- 1
fmt.Println("haha")
ch <- 2
fmt.Println("haha")
ch <- 3
fmt.Println("haha")
// 开启子协程,负责接收数据
go func() {
fmt.Println(<-ch) // 从通道读取数据并打印
}()
// 主协程往已满的通道再发数据
ch <- 4
// 主协程休眠1秒,给子协程执行时间
time.Sleep(time.Second)
}
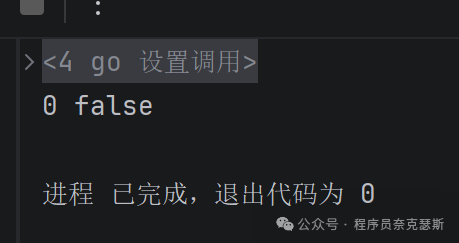
关闭通道channel了仍然可以从通道读取数据
ok表示的是能不能从通道取出数据,关闭了有数据能取出也是返回true
go
package main
import "fmt"
func main() {
// 创建无缓冲通道
ch := make(chan int)
// 关闭通道
close(ch)
// 接收数据(带ok判断)
v, ok := <-ch
fmt.Println(v, ok)
}
go
package main
import "fmt"
func main() {
ch := make(chan int, 3)
ch <- 1
close(ch)
v, ok := <-ch
fmt.Println(v, ok) // 第一次接收
v, ok = <-ch
fmt.Println(v, ok) // 第二次接收
}
第一次把通道里面的数据取出来,ok是true,第二次通道空了,v只能是0,ok就是false了
遍历通道:用range读取的话,他会不断从通道读取数据,如果不close通道,当把通道的数据读取完之后再次读取就会出现死锁
接收完数据记得通道被 close 关闭
go
for v := range ch {
fmt.Println(v)
}
go
package main
import "fmt"
func main() {
// 创建有缓冲通道,容量3
ch := make(chan int, 3)
// 往通道里塞数据
ch <- 1
ch <- 2
ch <- 3
// 关键:发送完数据后,必须 close 通道!
close(ch)
// 用 for range 遍历通道
for v := range ch {
fmt.Println("收到:", v)
}
}
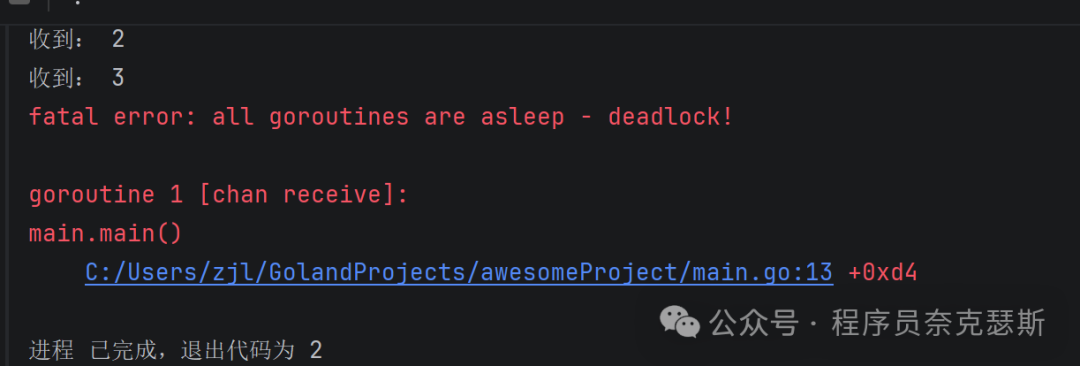
不close会死锁:
go
package main
import "fmt"
func main() {
ch := make(chan int, 3)
ch <- 1
ch <- 2
ch <- 3
// 没有 close(ch)
for v := range ch {
fmt.Println("收到:", v)
}
}
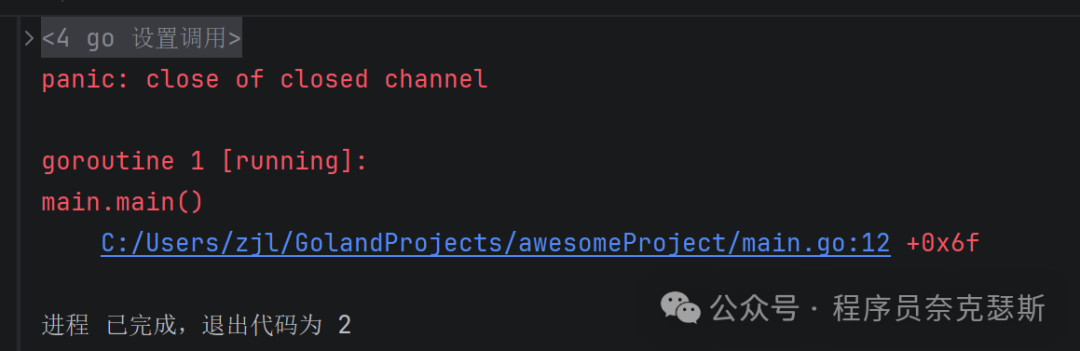
对已经关闭的channel再次进行关闭也会panic:
go
package main
import "fmt"
func main() {
ch := make(chan int, 3)
ch <- 1
ch <- 2
ch <- 3
close(ch)
close(ch)
for v := range ch {
fmt.Println("收到:", v)
}
}
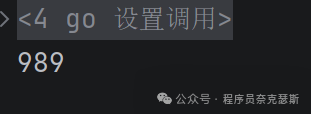
锁:类似于数据库的锁,原子性
不加锁:
go
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup
func add(num *int) {
*num = *num + 1
wg.Done()
}
func main() {
wg.Add(1000)
num := 0
for i := 0; i < 1000; i++ {
go add(&num)
}
wg.Wait()
fmt.Println(num)
}
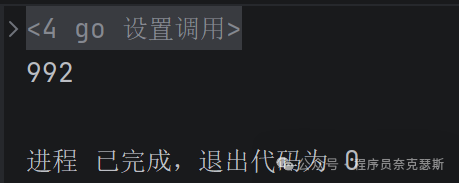
每次输出都不太一样,多个goroutine竞争,把几个就竞争没了
使用sync.Mutex加锁:
go
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup
var mu sync.Mutex // 互斥锁
func add(num *int) {
mu.Lock() // 进入临界区前加锁
*num = *num + 1
mu.Unlock() // 操作完成后解锁
wg.Done()
}
func main() {
wg.Add(1000)
num := 0
for i := 0; i < 1000; i++ {
go add(&num)
}
wg.Wait()
fmt.Println(num) // 稳定输出1000
}输出一定是1000
使用sync/atomic原子操作(更高效):
go
package main
import (
"fmt"
"sync"
"sync/atomic"
)
var wg sync.WaitGroup
func add(num *int32) {
atomic.AddInt32(num, 1) // 原子操作,无需手动加锁
wg.Done()
}
func main() {
wg.Add(1000)
var num int32 = 0 // 必须用int32类型
for i := 0; i < 1000; i++ {
go add(&num)
}
wg.Wait()
fmt.Println(num) // 稳定输出1000
}或者这样子:
利用有缓冲通道的缓冲容量,通道满了的话必须读取一个数据之后,有空间了才能进行下一个goroutine
go
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup
func add(num *int, ch chan bool) {
// 抢锁:往容量1的通道里塞一个值,塞不进去就阻塞等待
ch <- true
// 同一时间只有一个goroutine能执行这里
*num = *num + 1
// 释放锁:把通道里的值取出来,给下一个goroutine腾位置
<-ch
// 通知WaitGroup当前goroutine执行完毕
wg.Done()
}
func main() {
// 创建容量为1的有缓冲通道,作为互斥锁使用
ch := make(chan bool, 1)
// 设置WaitGroup计数器为1000,对应要启动的1000个goroutine
wg.Add(1000)
num := 0
for i := 0; i < 1000; i++ {
go add(&num, ch)
}
wg.Wait()
fmt.Println("最终num的值为:", num)
}提问:
下面代码输出什么?
go
func GoroutineTry06Func01(Arr []int, wg *sync.WaitGroup, ch1, ch2 chan int) {
defer wg.Done()
for _, value := range Arr {
ch1 <- value
if value%2 == 0 {
ch2 <- value
}
}
close(ch1)
close(ch2)
}
func ChanFunc01(wg *sync.WaitGroup, ch1 chan int) {
defer wg.Done()
for value := range ch1 {
fmt.Println("1-----", value)
time.Sleep(100 * time.Millisecond)
}
}
func ChanFunc02(wg *sync.WaitGroup, ch2 chan int) {
defer wg.Done()
for value := range ch2 {
fmt.Println("2-----", value)
time.Sleep(1000 * time.Millisecond)
}
}
func main() {
A := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
var wg sync.WaitGroup
wg.Add(3)
ch1 := make(chan int)
ch2 := make(chan int)
go GoroutineTry06Func01(A, &wg, ch1, ch2)
go ChanFunc01(&wg, ch1)
go ChanFunc02(&wg, ch2)
wg.Wait()
}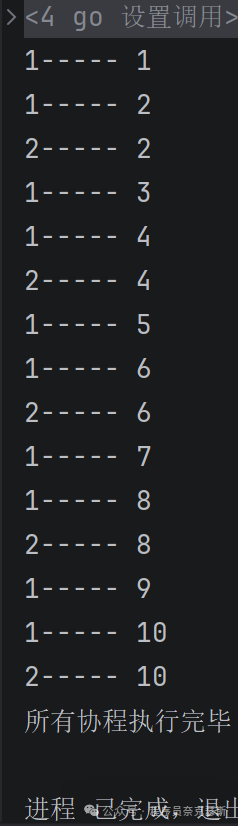
协程 1:遍历数组,把****所有数字 发给 ch1遇到偶数,额外发给 ch2,协程 2:从 ch1 读,打印所有数字,协程 3:从 ch2 读,只打印偶数
GoroutineTry06Func01这个负责把所有的A数组数字给ch1,偶数给ch2,剩下那两个协程负责从通道读取数据和打印数据
由于这里是无缓冲通道,所以存进去的数据要当场取出来才能进行下一步,所以存进去一个读取打印一个,然后由于第二个通道那个sleep的时间更久一点所以每次都在第一个通道的数据都被打印出来之后才被读取出来;
再问:consumer 1,consumer2可以做到直到程序运行结束前每次睡眠后直接接受数据吗?
无缓冲不行,无缓冲的话,接收和读取必须同时进行,如果接收的消费者睡着了,那给数据的就无法给了,就被空在那里了,可以加缓冲,就相当于给通道扩容,只要没有超过容量,发送者就可以一直往里面发送,接收者醒来就可以立即从通道取数据
