文章目录
- 一、基础入门:二叉树(最简单的树,没啥实际生产大用)
-
- [1.1 通俗核心概念](#1.1 通俗核心概念)
- [1.2 核心优缺点](#1.2 核心优缺点)
- [1.3 适配场景总结](#1.3 适配场景总结)
- 二、进阶优化:红黑树(平衡二叉树,内存专属,Java高频在用)
-
- [2.1 通俗核心概念](#2.1 通俗核心概念)
- [2.2 核心适配场景:为什么适合内存,适合HashMap?](#2.2 核心适配场景:为什么适合内存,适合HashMap?)
- [2.3 为什么数据库坚决不用红黑树?](#2.3 为什么数据库坚决不用红黑树?)
- [2.4 适配场景总结](#2.4 适配场景总结)
- 三、硬盘专属过渡:B树(多叉矮胖树,为数据库设计,但仍有缺陷)
-
- [3.1 通俗核心概念](#3.1 通俗核心概念)
- [3.2 核心优点](#3.2 核心优点)
- [3.3 为什么数据库最终还是不用B树?](#3.3 为什么数据库最终还是不用B树?)
- [3.4 适配场景总结](#3.4 适配场景总结)
- 四、数据库终极王者:B\+树(B树魔改升级版,MySQL专属定制)
-
- [4.1 通俗核心概念](#4.1 通俗核心概念)
- [4.2 核心优势](#4.2 核心优势)
- [4.3 适配场景总结](#4.3 适配场景总结)
- 五、四种树快速对比,一眼分清适配方向
- 六、最终核心:MySQL为什么只选B\+树?
先记住贯穿全文的核心底层逻辑,所有树的选型全靠这一点判断:
内存里操作数据,优先树高合适、修改快;硬盘(数据库)里存索引,优先树越矮越好,磁盘翻页(磁盘IO)次数越少,查询速度越快。
一、基础入门:二叉树(最简单的树,没啥实际生产大用)
1.1 通俗核心概念
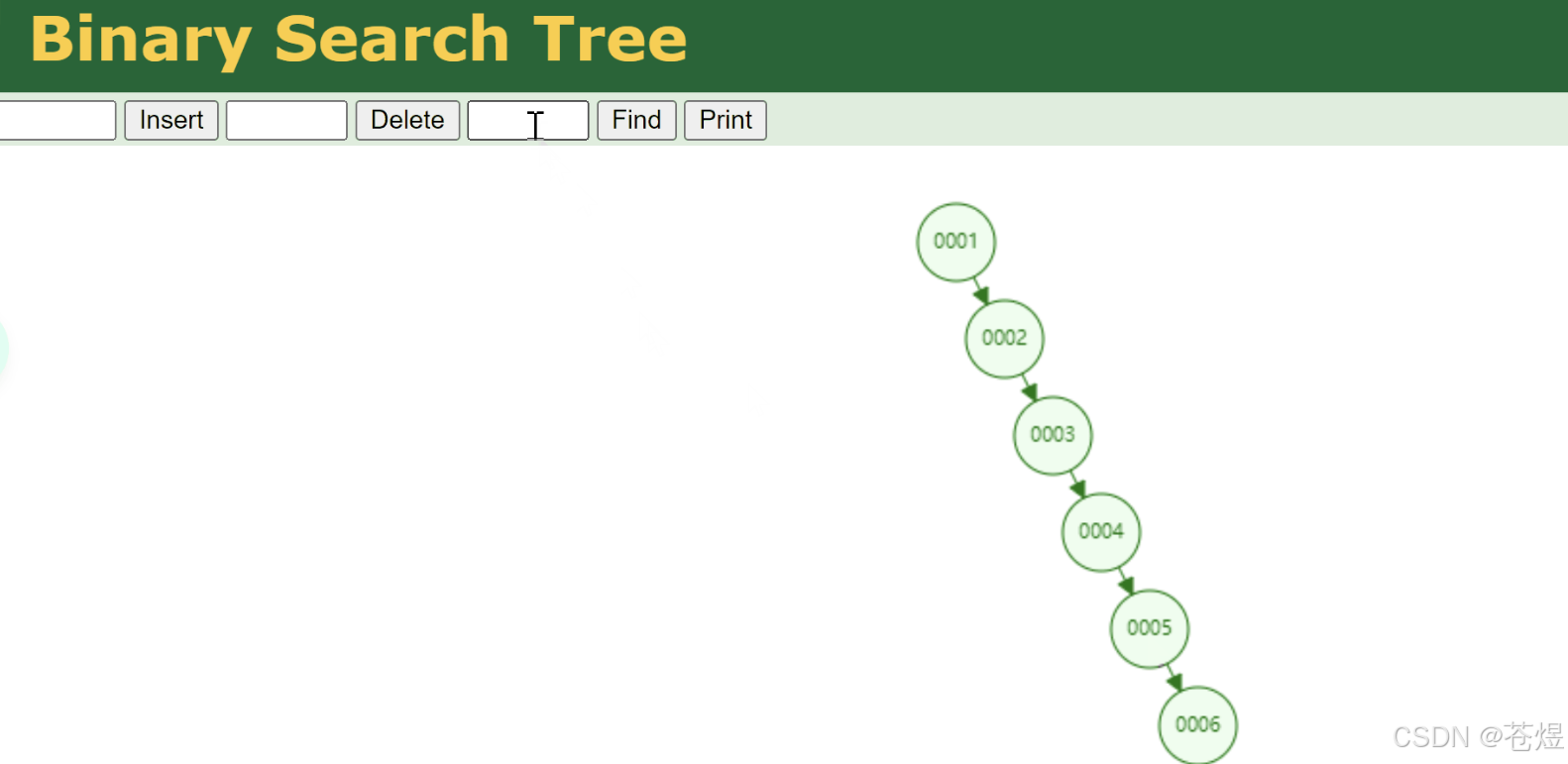
二叉树就是最简单的分支树,记住一句话就行:每一个节点,最多只有2个子节点,左边存小数据,右边存大数据。
就像一个分岔路口,不管多少数据,永远只分两条路走,结构简单易懂,是所有树的基础原型。
1.2 核心优缺点
优点就是结构简单、好理解、好实现,新手入门必学。
但有一个致命硬伤:特别容易"长歪"。如果按顺序插入1、2、3、4、5、6这种连续数据,二叉树会直接退化成一条直线链表。
一旦变成链表,查询数据就得从头到尾挨个遍历,和全表扫描没区别,索引直接废掉,性能拉胯。
1.3 适配场景总结
只适合教学入门学习,生产环境不管是内存程序,还是数据库存储,完全没人用。
一句话概括:二叉树简单但不稳定,容易长歪作废,实战直接淘汰。
二、进阶优化:红黑树(平衡二叉树,内存专属,Java高频在用)
2.1 通俗核心概念
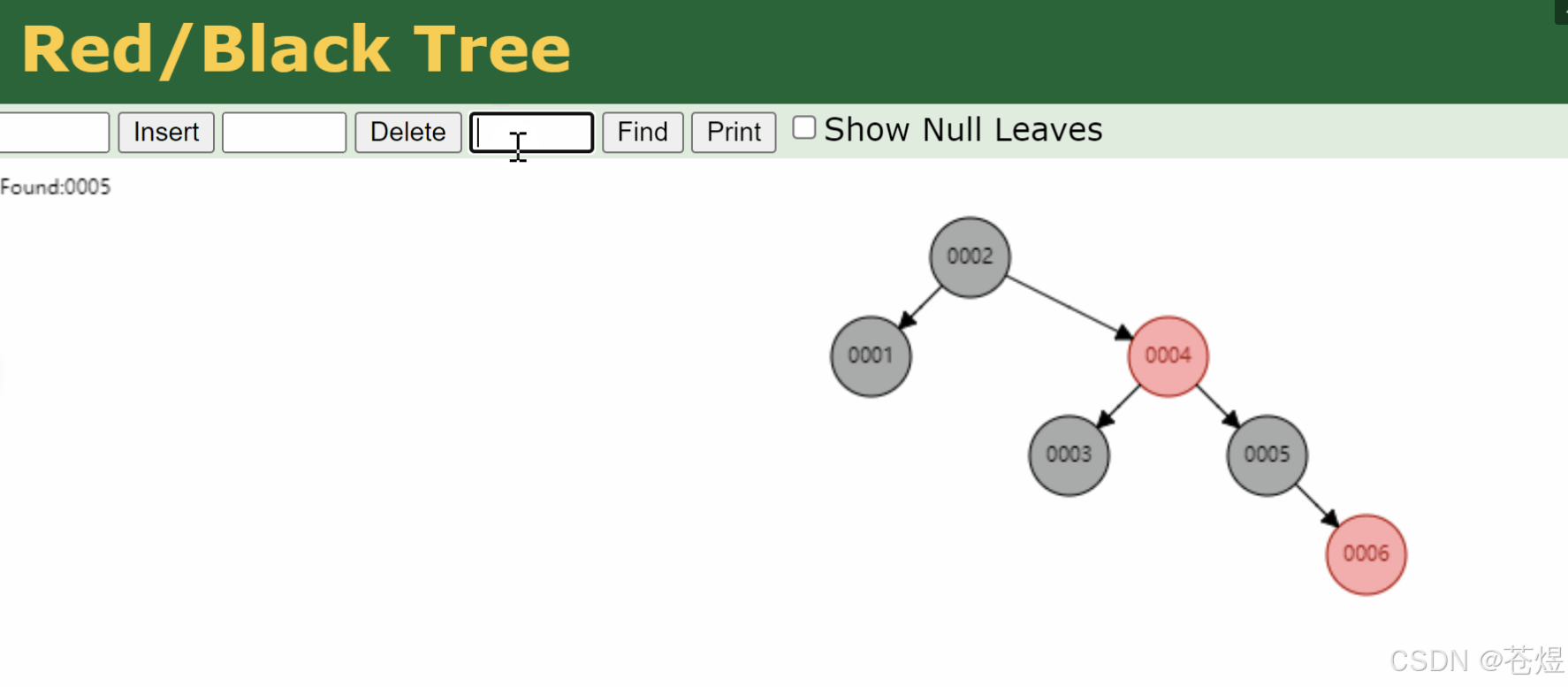
红黑树就是不会长歪的加强版二叉树。
普通二叉树容易变链表,红黑树通过颜色标记和自动旋转调整,不管你怎么新增、删除数据,树的整体高度永远保持平衡,不会出现一边高一边低的情况,彻底解决了二叉树长歪的致命问题。
2.2 核心适配场景:为什么适合内存,适合HashMap?
红黑树所有操作都在内存里完成,内存读写速度极快,不怕轻微的层级跳转损耗。
它的核心优势是:平衡稳定、增删改查性能均匀、不会出现性能忽快忽慢的情况。
所以Java里的HashMap、TreeMap 底层全都用红黑树,专门用来在内存里高效存数据、查数据。
2.3 为什么数据库坚决不用红黑树?
核心原因就一个:红黑树永远只有2个分叉,数据量一多,树就会长得又细又高。
数据库索引存在硬盘上,硬盘最怕频繁翻页读取数据,树越高,查找数据需要的磁盘IO次数就越多,查询速度就越慢。红黑树天生树形偏高,适配内存完美,适配硬盘数据库直接拉胯。
2.4 适配场景总结
红黑树=内存专用平衡树,适合Java集合类做内存存储,绝不适合硬盘数据库做索引。
三、硬盘专属过渡:B树(多叉矮胖树,为数据库设计,但仍有缺陷)
3.1 通俗核心概念
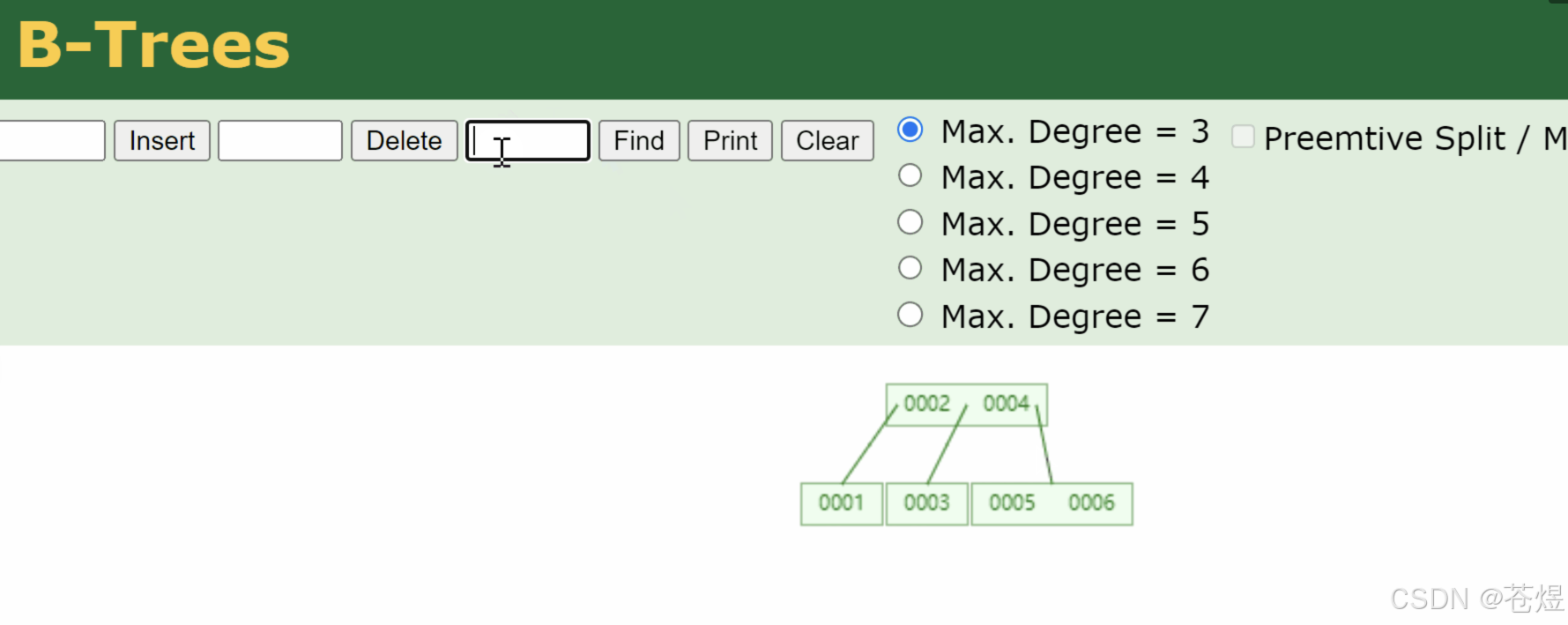
前面二叉树、红黑树都是最多2个分叉,树容易长高;B树彻底改了规则,不再限制2个分叉,一个节点能分几十上百个分叉。
简单说:B树就是一棵矮胖多叉树,不分细高分支,只做宽矮层级,专门为硬盘读写设计,减少磁盘翻页次数。
B树所有节点规则统一:每一层节点,既存索引key,又存真实完整数据。
3.2 核心优点
分叉多、树特别矮,查找数据只需少量磁盘IO,比红黑树适配硬盘好太多,完美解决树太高的问题。
3.3 为什么数据库最终还是不用B树?
两个核心硬伤,直接被后续B+树替代:
第一,节点既要存索引又要存真实数据,单页磁盘能放下的索引数量变少,树没办法做到极致的矮,性能还有提升空间;
第二,数据库日常业务高频用到范围查询、排序、分页,比如查询id在1~100之间的数据,B树需要来回跳转多个节点查找,效率特别低。
3.4 适配场景总结
B树=专为硬盘设计的过渡树,树矮IO少,但范围查询拉胯,被后续优化版B+树淘汰。
四、数据库终极王者:B+树(B树魔改升级版,MySQL专属定制)
4.1 通俗核心概念
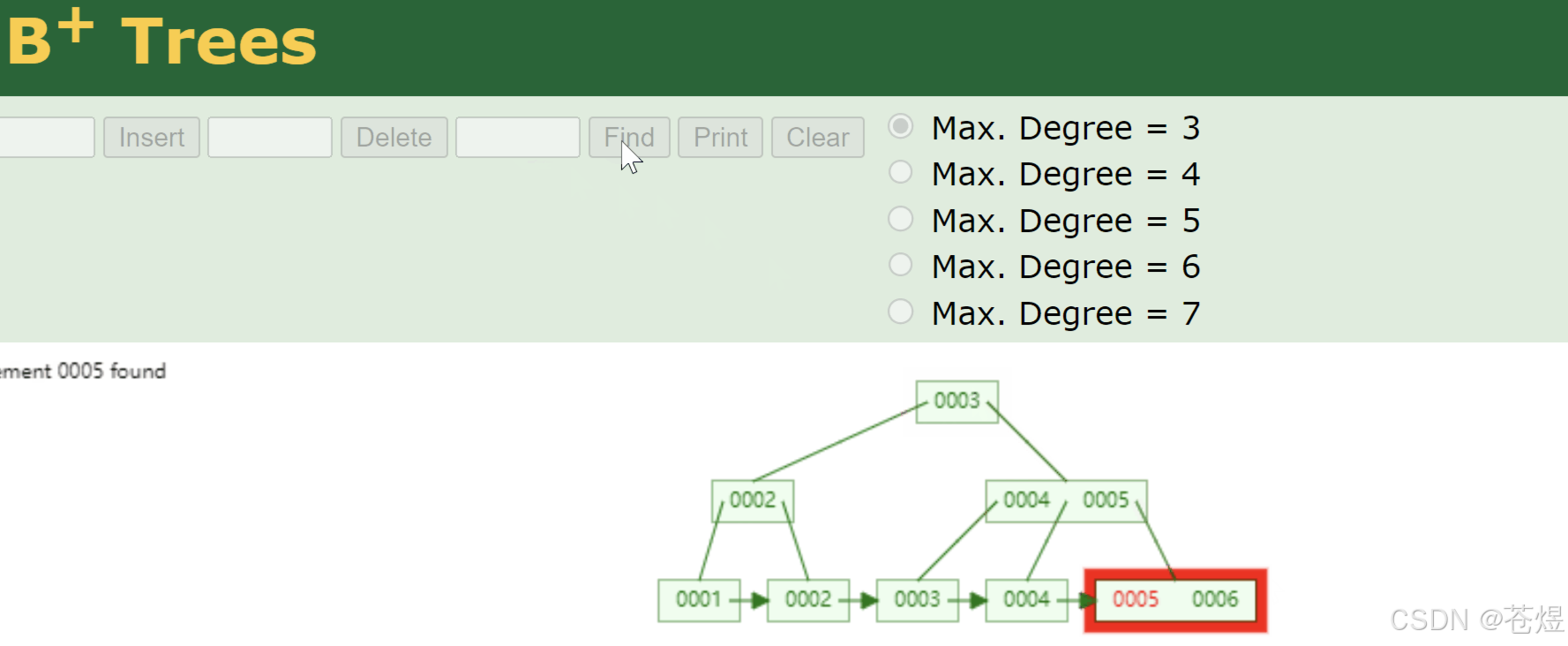
B+树不是全新结构,就是B树的超级魔改优化版,只改了两处核心规则,直接封神,完美适配数据库所有需求。
第一处改动:上层所有非叶子节点,只存索引key,不存任何真实数据,只做目录导航;
第二处改动:只有最底层叶子节点,才存完整真实数据,且所有叶子节点用链表从头到尾串起来,数据天然从小到大排序。
4.2 核心优势
一是上层只存索引,单页磁盘能塞海量索引数据,树变得极致矮,磁盘IO次数降到最少,查询速度拉满;
二是底层叶子节点链表有序串联,范围查询、排序、分页不用来回跳节点,顺着链表直接顺序读取,效率无敌。
4.3 适配场景总结
B+树=专为MySQL数据库索引量身定做,兼顾查询快、IO少、范围操作强,数据库专属终极树结构。
五、四种树快速对比,一眼分清适配方向
-
二叉树:双分叉、易长歪、性能不稳定,只适合教学学习,生产啥都不用;
-
红黑树:双分叉、平衡不歪、树形偏高,适合内存场景,Java HashMap专用,数据库不用;
-
B树:多分叉、树形矮、适配硬盘,但范围查询慢,属于过渡型树,现已淘汰;
-
B+树:多分叉、树形最矮、索引数据分离、底层链表排序,唯一适配MySQL数据库索引。
六、最终核心:MySQL为什么只选B+树?
1、B+树上层节点只存索引不存数据,树形最矮,磁盘IO读取次数最少,数据库查询速度最快;
2、底层叶子节点有序链表串联,完美适配数据库高频的范围查询、排序、分页业务场景,其他树都做不到;
3、所有查询最终都走叶子节点,查询性能稳定,不会出现忽快忽慢的情况,适配数据库高并发读写需求。