note
- 现有 MRAG 框架均采用文档级检索与重排,默认文档内所有内容同等有效,但是检索文档含大量无关、冗余、矛盾噪声,引发 MLLM 幻觉,图像仅小区域感兴趣(ROI)有用,文本仅少量句子相关。所以,搞了个Retrieve--Rerank--Select--Generate四阶段 pipeline,新增片段级筛选模块净化证据,目标是在量化证据的边际效用,从而能够过滤掉通常会损害下游推理的无关、冗余或矛盾噪声
- 多模态RAG去噪:碎片筛选阶段【使用训练完成的轻量学生选择器,对混合候选池中所有条目进行效用打分,按得分从高到低排序,选取Top-5最高效用碎片作为最终纯净上下文】
文章目录
一、Purifying Multimodal Retrieval
【多模态RAG进展】打的点一个去噪工作。是现有 MRAG 框架均采用文档级检索与重排,默认文档内所有内容同等有效,但是检索文档含大量无关、冗余、矛盾噪声,引发 MLLM 幻觉,图像仅小区域感兴趣(ROI)有用,文本仅少量句子相关。所以,搞了个Retrieve--Rerank--Select--Generate四阶段 pipeline,新增片段级筛选模块净化证据,目标是在量化证据的边际效用,从而能够过滤掉通常会损害下游推理的无关、冗余或矛盾噪声,工作在《Purifying Multimodal Retrieval: Fragment-Level Evidence Selection for RAG》,https://arxiv.org/pdf/2604.27600
核心思路是不直接用整段文档,而是把检索回来的图文切成最小有用单元 → 计算每个碎片的价值 → 只留高价值碎片 → 再给大模型生成,分成采用Retrieve--Rerank--Select--Generate四阶段 pipeline,也就是先把检索到的图文切成最小有用单元,用大模型算出每个碎片对生成答案的帮助,再蒸馏一个小模型快速挑出最有用的碎片,最后只给大模型喂这些纯净碎片生成答案。
1)具体步骤:
step1.粗检索阶段【采用Visualized BGE多模态稠密检索器,将用户查询与多模态数据库中的文档编码至统一向量空间,执行近似最近邻检索,召回Top-100候选文档构成初始候选集】
->step2.粗重排阶段【使用Jina-Reranker-m0跨编码器重排模型,对Top-100候选文档逐篇计算与查询的语义相关性得分,按得分从高到低排序,选取Top-15文档进入细粒度处理】
->step3.文本碎片分割阶段【对Top-15中的文本文档执行递归二元分割:以Jina-Reranker-m0为打分器,先计算整段文档得分,再按句子中点切分为左右两段,若分段后最高分高于整段得分则保留高分段并递归分割,直至分割为单句或分段无增益,得到句子级原子文本碎片】
->step4.视觉碎片分割阶段【对Top-15中的图像文档使用Grounding DINO模型,根据查询生成候选目标区域,按目标置信度>0.4、语义对齐分数>0.35、区域面积>2500像素三个条件过滤,裁剪保留符合条件的区域作为ROI视觉原子碎片】
->step5.碎片信息增益FIG计算阶段【以Qwen3-VL-32B作为教师MLLM,分别计算"仅输入查询"与"输入查询+单个碎片"两种条件下,模型生成真实答案的长度归一化对数似然概率,两者差值即为该碎片的Fragment Information Gain(FIG),用于量化碎片对生成的边际效用,这里的逻辑是FIG 用于量化每个文本 / 视觉片段对 MLLM 生成正确答案的边际贡献,计算逻辑是对比模型加入片段与不加片段时,生成真实答案的长度归一化对数似然差值,值越高代表片段对生成的支撑作用越强,为选择器提供精准监督信号】
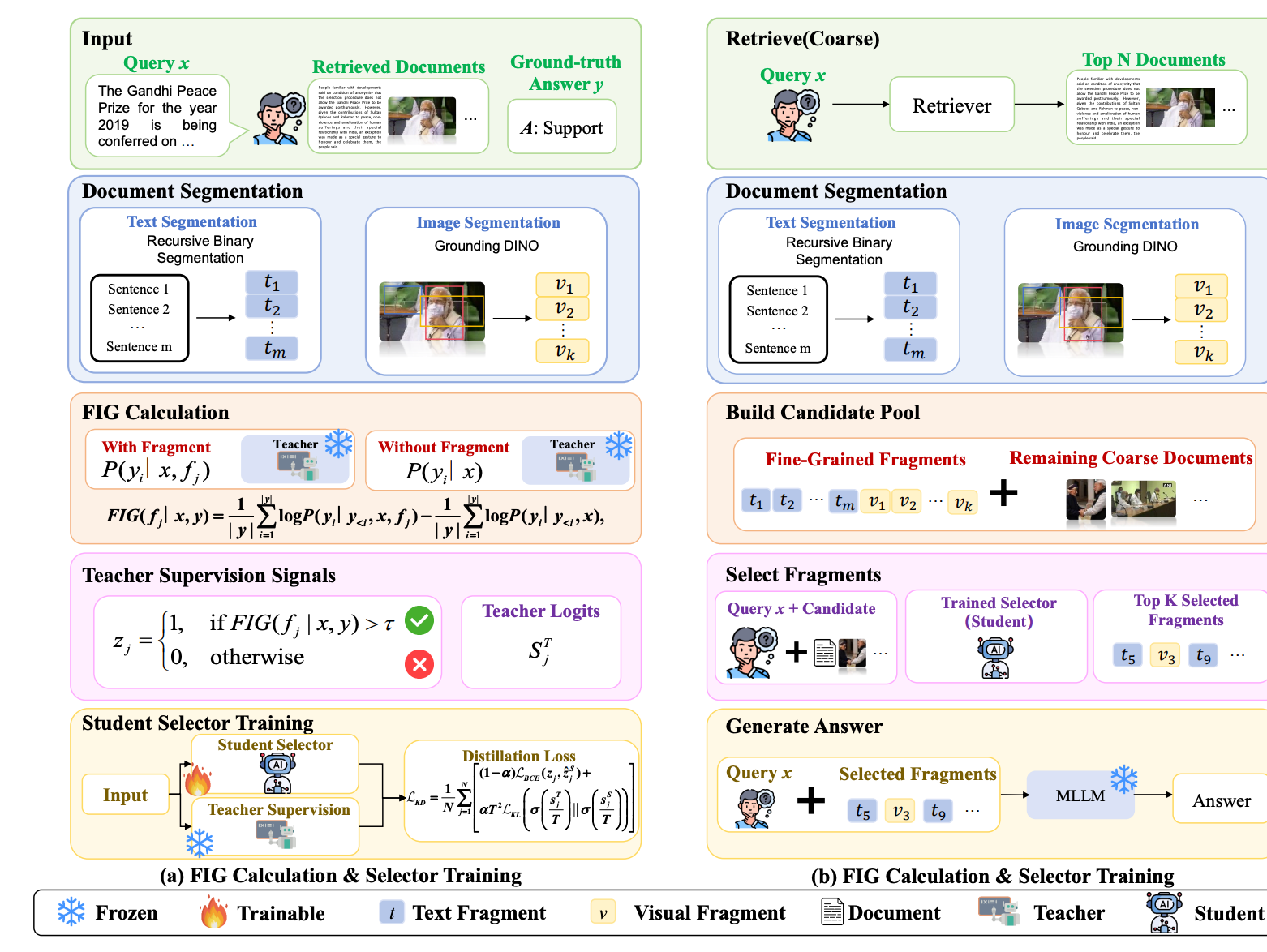
->step6.监督标签构建阶段【设定FIG阈值0.2,将FIG>0.2的文本/视觉碎片标记为有效证据(标签1),FIG≤0.2的碎片标记为无效噪声(标签0),构建(查询,碎片,二分类标签)的监督训练数据集】
->step7.轻量选择器蒸馏训练阶段【以Qwen3-VL-32B为教师模型、Jina-Reranker-2B为轻量学生模型,采用混合损失函数训练:包含拟合二分类标签的二元交叉熵损失,以及拟合教师软概率分布的KL散度损失,设置蒸馏温度T=2、蒸馏权重α=0.7,让学生模型学习碎片效用判别能力】
->step8.推理混合候选池构建阶段【将文本碎片、ROI视觉碎片与粗排阶段未分割的剩余文档合并,构建包含细粒度碎片与粗粒度文档的统一混合候选证据池】
->step9.碎片筛选阶段【使用训练完成的轻量学生选择器,对混合候选池中所有条目进行效用打分,按得分从高到低排序,选取Top-5最高效用碎片作为最终纯净上下文】
->step10.纯净生成阶段【将Top-5高效用碎片与用户查询拼接,输入MLLM生成器,模型仅基于高信息密度、低噪声的纯净上下文生成最终答案,降低幻觉并提升事实准确性】。2)看结果,在 M²RAG 基准上实现最高 27% 的 CIDEr 相对提升,同时降低 20.4%--33.1% 的上下文 token 消耗。
Reference
1 《Purifying Multimodal Retrieval: Fragment-Level Evidence Selection for RAG》,https://arxiv.org/pdf/2604.27600