目录
[4.1 塞贝克效应与TEG电气模型](#4.1 塞贝克效应与TEG电气模型)
[4.2 电压补偿目标](#4.2 电压补偿目标)
[4.3 双Q学习算法](#4.3 双Q学习算法)
[4.4 启发式动作策略](#4.4 启发式动作策略)
[4.5 奖励函数设计](#4.5 奖励函数设计)
[4.6 状态空间与动作空间设计](#4.6 状态空间与动作空间设计)
✨1.课题概述
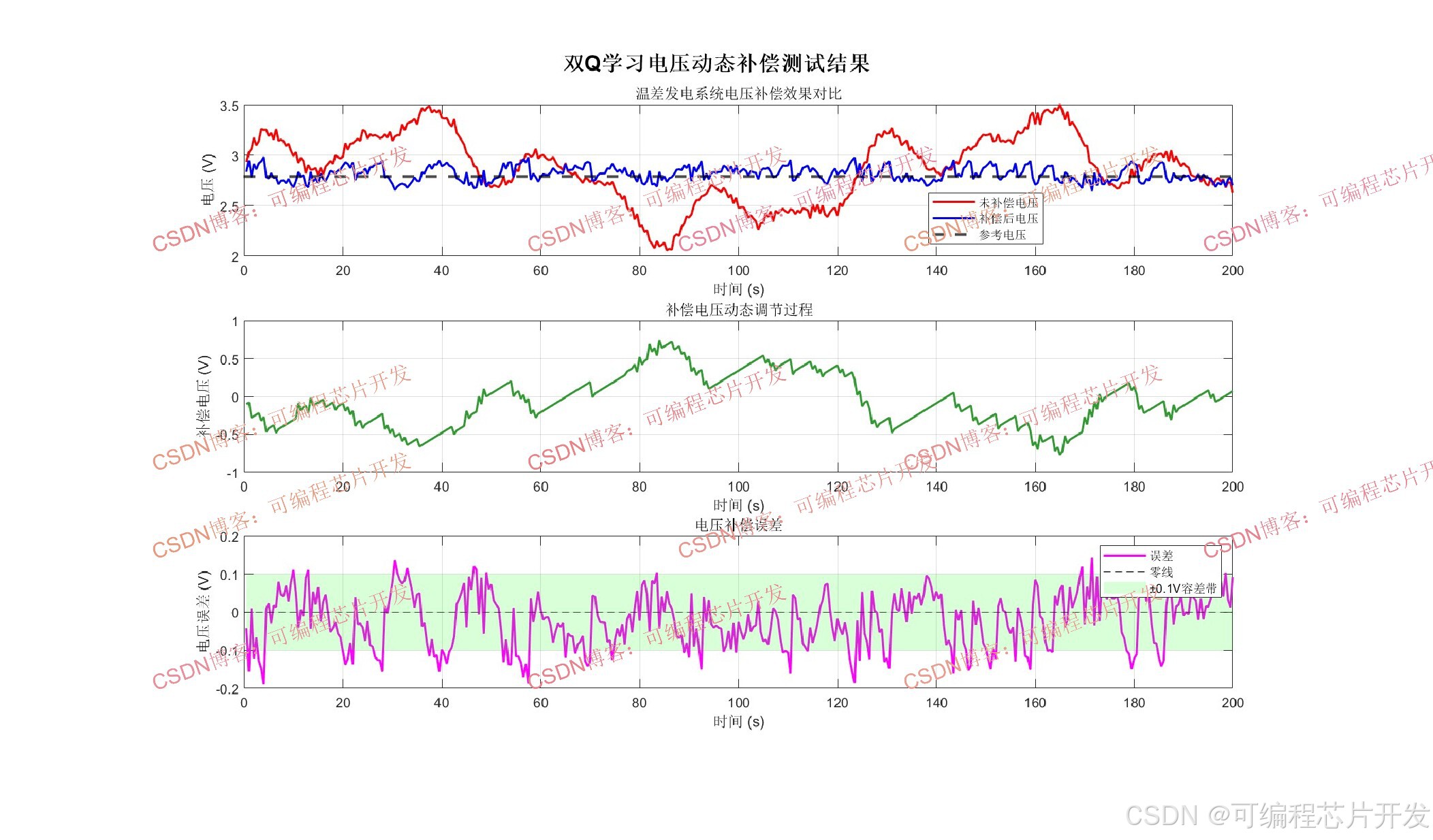
温差发电系统(Thermoelectric Generation System, TEG)利用塞贝克效应将热能直接转化为电能,在工业余热回收、可穿戴设备供电以及航天器电源等领域具有广泛应用前景。然而,在实际工程应用中,温差发电系统常常面临热源温度波动、冷端散热条件变化以及非均匀温度分布等问题,导致输出电压产生剧烈波动,严重影响系统的供电质量和能量转换效率。传统的PID控制方法在面对温差发电系统这种高度非线性、时变参数的控制对象时,往往难以实现理想的电压补偿效果。基于模型的控制方法则受限于温差发电系统精确数学模型的建立难度。
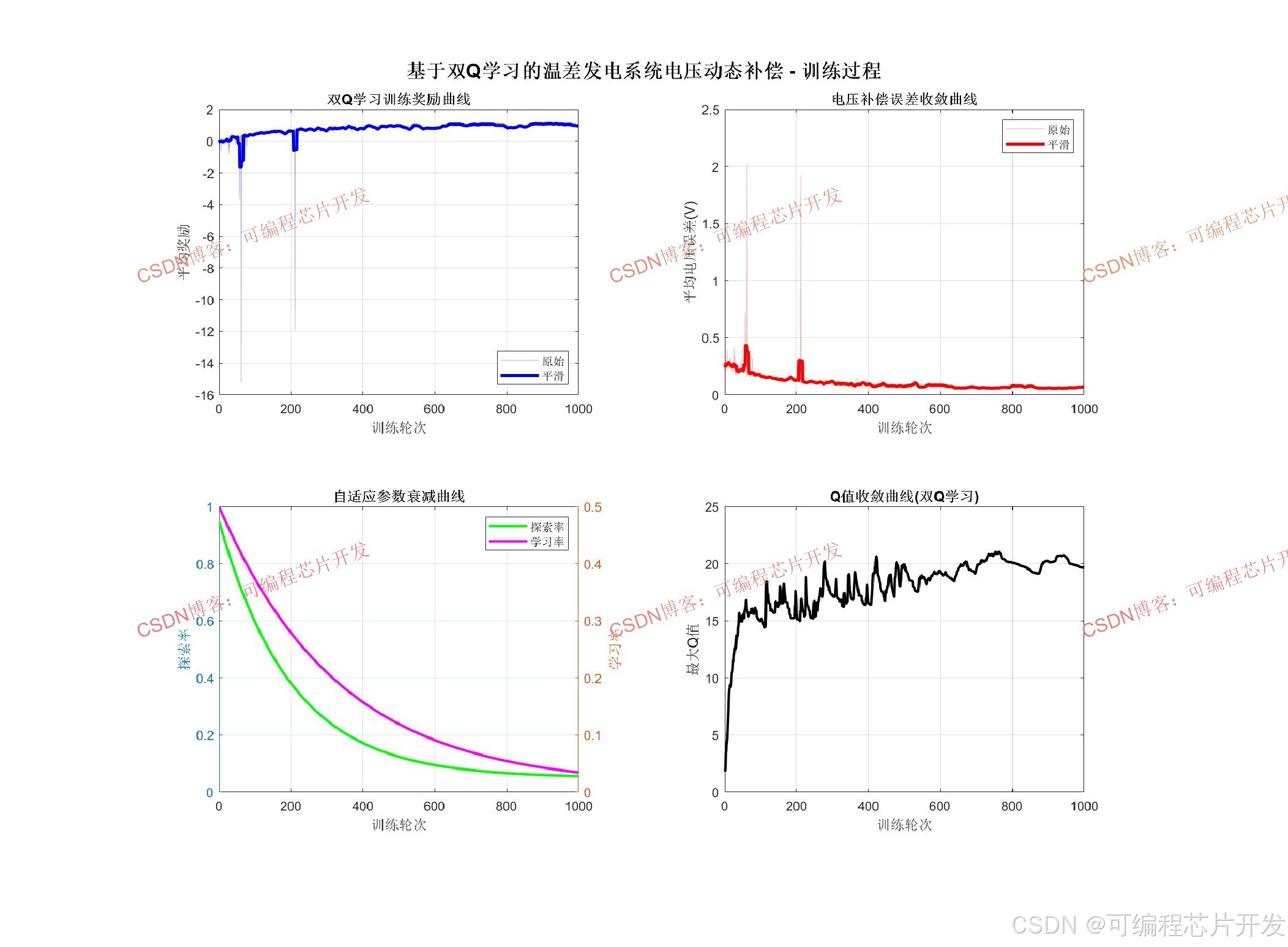
针对上述挑战,强化学习作为一种无模型的自适应优化方法,能够通过与环境的交互学习最优控制策略,成为解决温差发电系统电压动态补偿问题的有力工具。然而,经典Q学习算法存在Q值过高估计的固有缺陷,会导致学习策略次优、补偿效率下降。为此,本文提出一种基于双Q学习(Double Q-Learning)的温差发电系统电压动态补偿方法,通过解耦动作选择与价值评估过程,有效抑制Q值高估现象,并结合自适应探索率、自适应学习率以及启发式动作策略,显著提升电压补偿的精度与收敛速度。
📊2.系统仿真结果
✅3.核心程序或模型
版本:Matlab2024b
%温差发电系统参数设置
TEG.N = 127;
TEG.alpha = 0.00022;
TEG.Rin = 3.5;
TEG.RL = 3.5;
TEG.Tc = 300;
TEG.Th0 = 500;
TEG.A1 = 30;
TEG.A2 = 15;
TEG.omega1 = 0.05;
TEG.omega2 = 0.2;
TEG.noise_std = 5;
deltaT_ref = TEG.Th0 - TEG.Tc;
Voc_ref = TEG.N * TEG.alpha * deltaT_ref;
V_ref = Voc_ref * TEG.RL / (TEG.Rin + TEG.RL);
fprintf('参考电压 V_ref = %.4f V\n', V_ref);
%状态空间与动作空间设计
Ne = 21;
e_min = -3.0; e_max = 3.0;
e_edges = linspace(e_min, e_max, Ne + 1);
Nde = 11;
de_min = -1.0; de_max = 1.0;
de_edges = linspace(de_min, de_max, Nde + 1);
num_states = Ne * Nde;
actions = [-0.5, -0.3, -0.2, -0.1, -0.05, -0.02, 0, ...
0.02, 0.05, 0.1, 0.2, 0.3, 0.5];
num_actions = length(actions);
fprintf('状态数: %d, 动作数: %d\n', num_states, num_actions);
%双Q学习参数初始化
QA = zeros(num_states, num_actions);
QB = zeros(num_states, num_actions);
eps_max = 0.95; eps_min = 0.05; eps_decay = 0.005;
lr_max = 0.5; lr_min = 0.01; lr_decay = 0.003;
gamma = 0.95;
w1 = 1.0; w2 = 2.0; w3 = 0.3;
p_heuristic = 0.6;
🚀4.系统原理简介
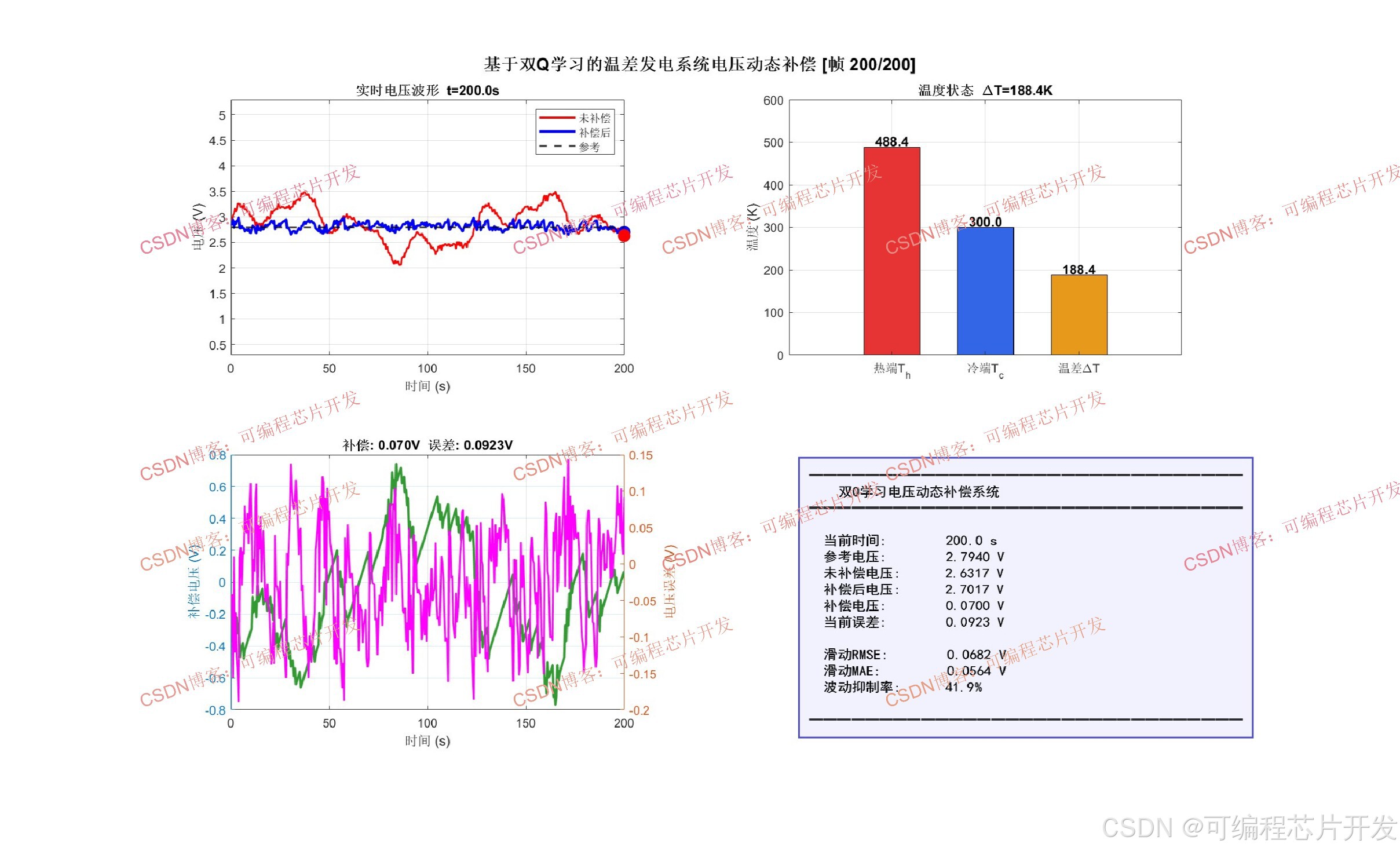
4.1 塞贝克效应与TEG电气模型
温差发电系统的核心工作原理基于塞贝克效应。当温差发电模块的热端温度Th与冷端温度Tc之间存在温度差ΔT时,系统产生开路电压。温差发电模块的开路电压表达式为:

其中,N为热电偶对数,α为塞贝克系数。考虑模块内阻Rin后,温差发电系统在负载RL下的输出电压为:

在非均匀温度条件下,热端温度会随时间和空间位置发生变化,导致开路电压波动。本文将热端温度建模为包含确定性趋势分量和随机扰动分量的动态过程:
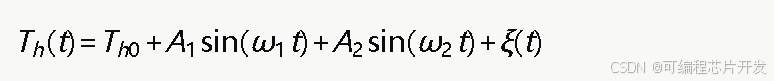
其中,Th0为基准热端温度,A1、A2分别为不同频率温度波动的幅值,ω1、ω2为角频率,ξ(t)为零均值高斯白噪声。
4.2 电压补偿目标
电压动态补偿的目标是通过调节补偿电压Vcomp,使得最终输出电压尽可能接近期望参考电压 Vref:
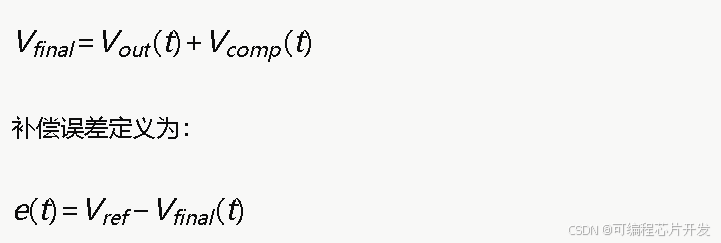
4.3 双Q学习算法
经典Q学习算法通过维护一个状态-动作价值函数Q(s,a) 来评估在状态s下执行动作a的长期累计回报。Q值更新规则为:
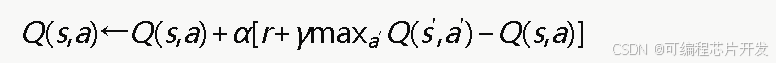
其中,α为学习率,r为即时奖励,γ为折扣因子,s′为下一状态。由于更新过程中使用max操作同时进行动作选择和价值评估,在存在噪声的估计环境中,会系统性地高估Q值,导致策略偏向次优动作。
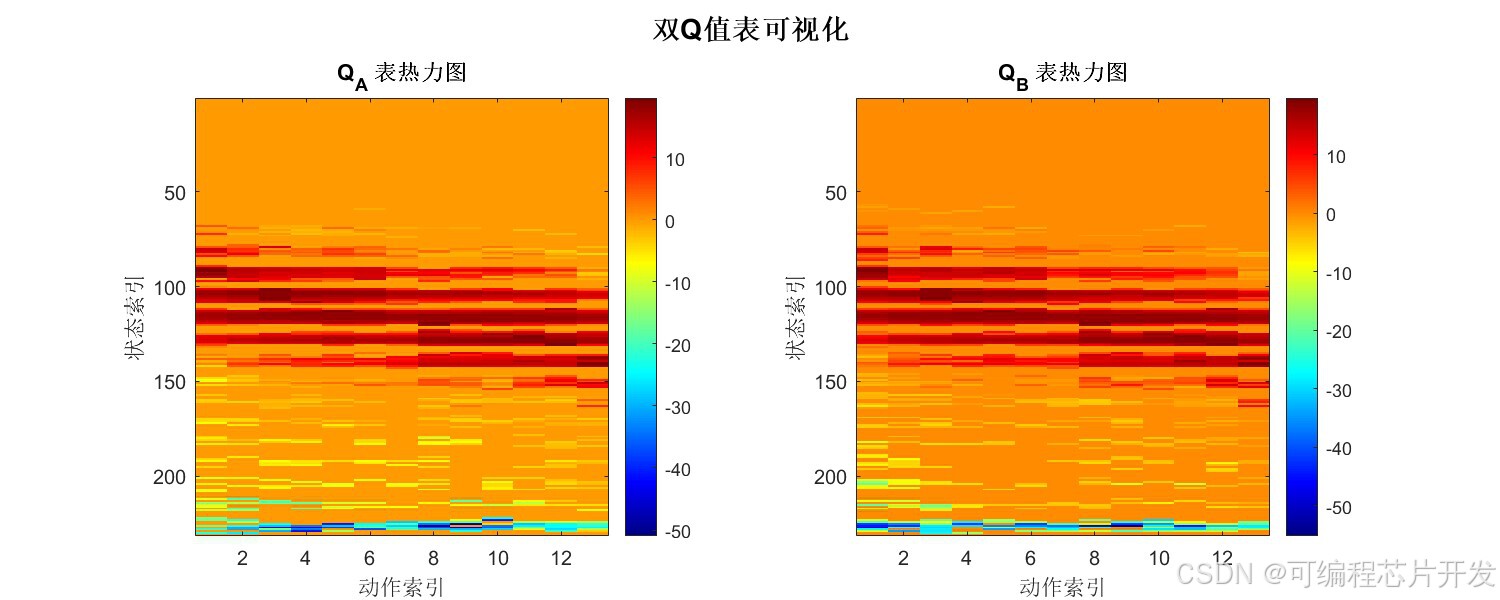
双Q学习算法通过维护两个独立的Q值表QA(s,a)和QB(s,a),将动作选择与价值评估解耦。在每次更新时,以等概率随机选择更新其中一个Q表:
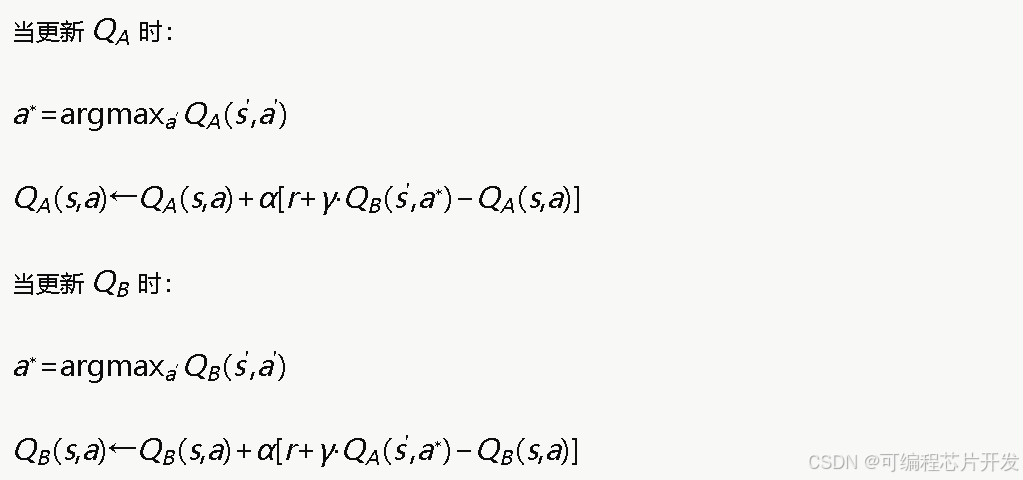
这种机制使得选择动作所用的Q表与评估该动作价值所用的Q表不同,有效消除了Q值高估偏差,提升了学习策略的准确性和稳定性。
4.4 启发式动作策略
在电压补偿场景中,当电压误差为正(输出电压低于参考值)时,补偿电压应增大;反之亦然。基于此物理直觉,本文设计启发式动作选择策略。在探索阶段,以概率ph选择与误差方向一致的动作,而非完全随机选择,从而在保持探索多样性的同时提升搜索效率:

4.5 奖励函数设计
奖励函数是引导强化学习算法优化方向的关键。本文设计了包含误差惩罚项和动作平滑项的复合奖励函数:
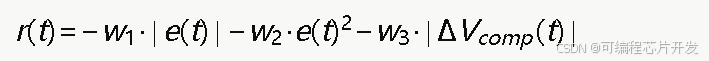
其中,w1、w2、w3为权重系数,第一项为绝对误差惩罚,第二项为平方误差惩罚以强化对大误差的抑制,第三项为补偿电压变化量惩罚以避免控制信号剧烈波动。
4.6 状态空间与动作空间设计

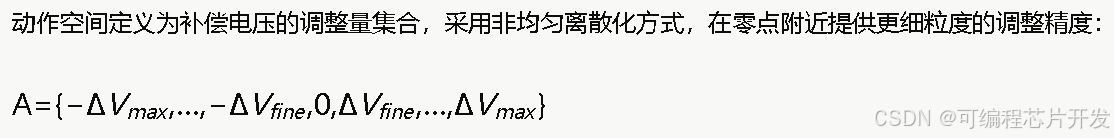
💢5.完整工程文件
v v
关注后,GZH回复关键词:a41