前言
"全球校园人工智能算法精英大赛"是江苏省人工智能学会举办的面向全球具有正式学籍的全日制高等院校及以上在校学生举办的算法竞赛。其中的算法巅峰赛属于产业命题赛道,这是第二赛季,对最后一道优化题,采用遗传算法来评估一下。

回顾
第七届全球校园人工智能算法精英大赛-算法巅峰赛产业命题赛第二赛季--最后一题解读
大致题意如下
给定 N 个必选点,M 个可选点,请构建一个联通方案,使得包含 N 个必选点的图 G 其联通的代价(路径和)尽量小?
具体的题目描述和各种算法综述可具体参见上文,这边不再简单重复。
思路
本文的核心思路,即采用 遗传算法,因为对这类 斯坦纳树(Steiner Tree)问题,其实特别的自然。
1. 个体
M 个可选点,天然设计一个长度为 M 的 0-1 的子串,1 表示选,0 表示未选。
换句话说,对于任意的一个长度为 M 的 0-1 子串,即是自然的种群个体。
2. 适应度函数
定义 M' 为 0-1 子串中,标记为 1 构建的点集(M 的子集)
适应度函数 等价于 N + M ′ , M ′ ∈ M {N + M', M' \in M} N+M′,M′∈M,构建的最小生成树代价。
MST的求解,因为图G是稠密图,因此采用 Prim 算法,时间复杂度为 O ( ( n + m ) 2 ) O((n+m)^2) O((n+m)2)
3. 操作
- 变异
具体的个体(长度为 M 的0-1串),翻转某些位子上的 0-1 值。 - 交叉
2 个不同个体,按照某个规则生成一个新的 0-1 串,其一部分来自一个个体,剩余的来自另一个个体 - 选择
按照某个策略保留部分个体用于下一轮的迭代(比如根据适应度给于不同的权重概率)
这里的变异,交叉,选择有很多实现方式,具体看实际效果和个人喜好。
实践评估
代码
cpp
#include <bits/stdc++.h>
using namespace std;
const double inf = (double)1e12;
struct Robot {
int id;
int x;
int y;
string type;
};
struct Gene {
double score;
vector<int> genes;
Gene(int k) : genes(k, 0), score(inf) {}
};
struct Edge {
int u, v;
Edge() {}
Edge(int u, int v)
: u(u), v(v) {}
};
random_device rd;
mt19937 mt(rd());
uniform_int_distribution<int> ui01(0, 1);
uniform_real_distribution<double> ur01(0.0, 1.0);
class GA {
public:
static vector<Gene> create_instances(int pop, int k, double p = 0.1) {
vector<Gene> res;
uniform_real_distribution<double> urd(0, 1.0);
for (int i = 0; i < pop; i++) {
Gene g(k);
for (int j = 0; j < k; j++) {
double tp = urd(mt);
if (tp < p) {
g.genes[j] = 1;
}
}
res.push_back(g);
}
return res;
}
static Gene cross(Gene &a, Gene &b) {
int k = a.genes.size();
Gene r(k);
for (int i = 0; i < k; i++) {
if (a.genes[i] == b.genes[i]) {
r.genes[i] = a.genes[i];
} else {
r.genes[i] = ui01(mt);
}
}
return r;
}
static Gene mutation(Gene &a, double p) {
Gene r = a;
int k = r.genes.size();
for (int i = 0; i < k; i++) {
double tp = ur01(mt);
if (tp < p) {
r.genes[i] = 1 - r.genes[i];
}
}
return r;
}
};
class MST {
public:
double prim(Gene &gene, vector<Edge> &edges) {
// 对于稠密图, 使用prim算法更好
vector<int> &choice = gene.genes;
vector<int> vis(n + k, 0);
vector<double> dist(n + k, inf);
vector<int> from(n + k, -1);
dist[0] = 0;
double ans = 0;
for (int i = 0; i < n + k; i++) {
if (i >= n && choice[i - n] == 0) continue;
int pos = -1;
for (int j = 0; j < n + k; j++) {
if (j >= n && choice[j - n] == 0) continue;
if (vis[j] == 0 && (pos == -1 || dist[pos] > dist[j])) {
pos = j;
}
}
if (pos == -1) break;
if (from[pos] != -1) {
edges.push_back(Edge(from[pos], pos));
}
vis[pos] = 1;
ans += dist[pos];
for (int j = 0; j < n + k; j++) {
if (j >= n && choice[j - n] == 0) continue;
if (vis[j] == 0 && dist[j] > matrix[pos][j]) {
dist[j] = matrix[pos][j];
from[j] = pos;
}
}
}
return ans;
}
MST(int n, int k, vector<Robot> &robots)
: n(n), k(k), robots(robots), matrix(n+k, vector<double>(n + k, inf)) {
// 预处理
// 题目保证前n都是机器人,后k项都是中继器
for (int i = 0; i < n; i++) {
Robot &a = robots[i];
for (int j = i + 1; j < n + k; j++) {
Robot &b = robots[j];
// 这个不会被执行到
if (a.type == "C" && b.type == "C") continue;
double d = (a.x - b.x) * (a.x - b.x) + (a.y - b.y) * (a.y - b.y);
if ((a.type == "S" && (b.type == "S" || b.type == "R")) || (b.type == "S" && (a.type == "S" || b.type == "R"))) {
d = d * 0.8;
}
matrix[i][j] = matrix[j][i] = d;
}
}
}
int n, k;
vector<Robot> robots;
vector<vector<double>> matrix;
};
int main() {
time_t time_limit = 7;
time_t start = time(nullptr);
int n, k;
cin >> n >> k;
vector<Robot> robots(n + k);
for (int i = 0; i < n + k; i++) {
Robot &robot = robots[i];
cin >> robot.id >> robot.x >> robot.y >> robot.type;
}
int pop = 10;
double p = 0.1;
double mutation_prop = 0.1;
MST mst(n, k, robots);
GA ga;
// 初始化一个种群
vector<Gene> genes = ga.create_instances(pop, k, p);
Gene best_gene = genes[0];
vector<Edge> best_edges;
best_gene.score = mst.prim(best_gene, best_edges);
while (true) {
vector<Gene> next_genes = genes;
int cn = genes.size();
uniform_int_distribution<int> ud(0, cn - 1);
// cross 交叉
int max_round = min(100, cn * 2);
for (int i = 0; i < max_round; i++) {
int a = ud(mt), b = ud(mt);
if (a == b) continue;
Gene tg = ga.cross(genes[a], genes[b]);
next_genes.push_back(tg);
}
// mutation 变异
for (int i = 0; i < max_round; i++) {
int a = ud(mt);
Gene tg = ga.mutation(genes[a], mutation_prop);
next_genes.push_back(tg);
}
// compute fitness 计算适应度
for (Gene &g: next_genes) {
vector<Edge> tmp_edges;
g.score = mst.prim(g, tmp_edges);
if (best_gene.score > g.score) {
best_gene = g;
best_edges = tmp_edges;
}
}
// 选择, 保持种群数量
int nz = (int)next_genes.size();
if (nz <= pop) {
swap(genes, next_genes);
} else {
vector<int> idx(next_genes.size());
iota(idx.begin(), idx.end(), 0);
sort(idx.begin(), idx.end(), [next_genes](const int &a, const int &b) {
return next_genes[a].score < next_genes[b].score;
});
vector<Gene> tmp;
for (int i = 0; i < pop; i++) {
tmp.push_back(next_genes[idx[i]]);
}
swap(genes, tmp);
}
time_t end = time(nullptr);
if ((end - start) > time_limit) {
break;
}
}
// 结果输出
string str_ids;
for (int i = 0; i < k; i++) {
if (best_gene.genes[i] == 1) {
if (!str_ids.empty()) str_ids += "#";
str_ids += to_string(robots[n + i].id);
}
}
if (str_ids.empty()) str_ids = "#";
string str_edges;
for (Edge &e: best_edges) {
if (!str_edges.empty()) str_edges += "#";
str_edges += (to_string(robots[e.u].id) + "-" + to_string(robots[e.v].id));
}
cout << str_ids << "\n";
cout << str_edges << "\n";
return 0;
}这个代码纯照搬遗传算法的板子,未经任何优化改造,我们来看下具体的效果。
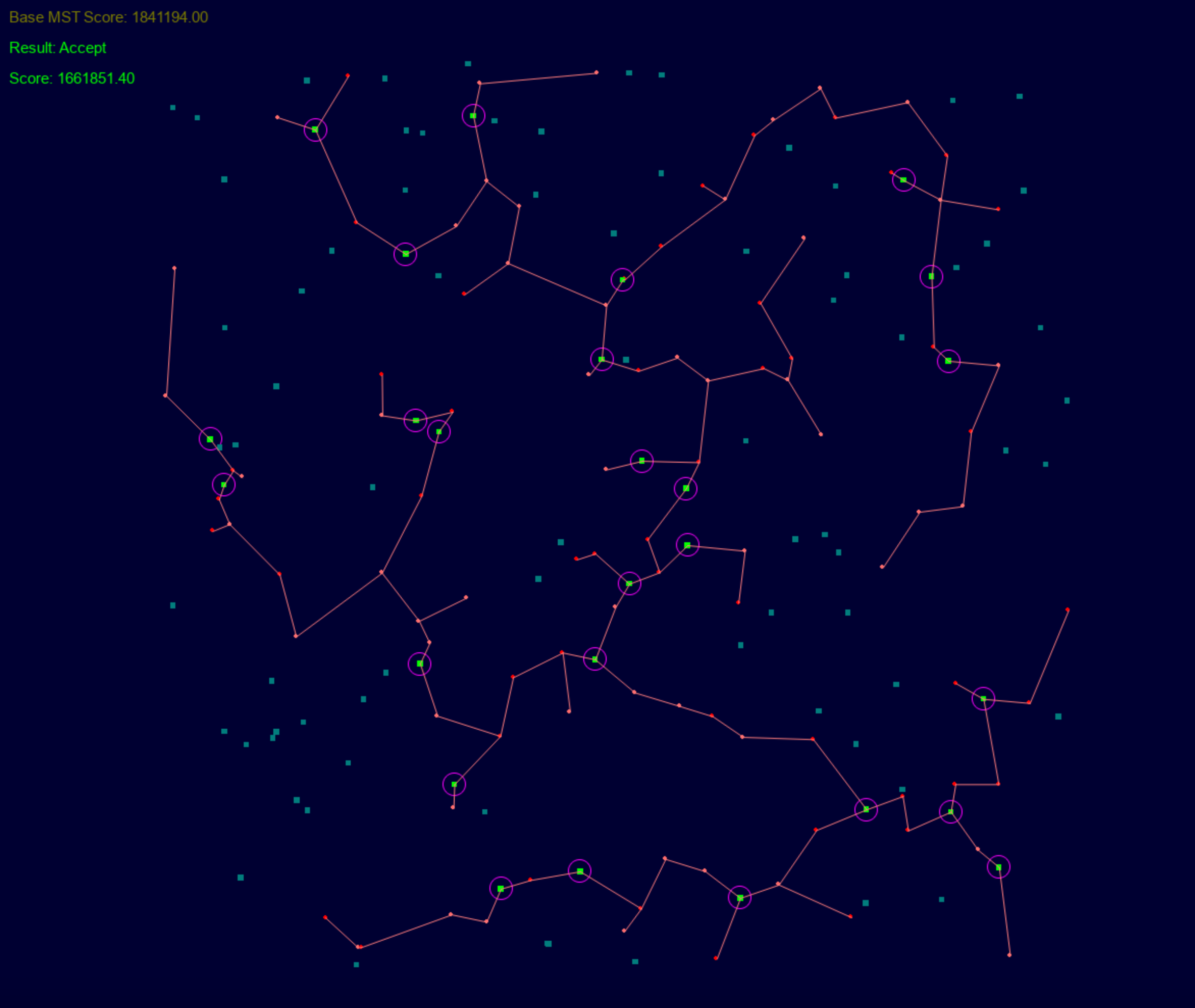
在 n = 100 , m = 100 n=100,m=100 n=100,m=100的数据规模下(数值越小越好):
| 算法 | 遗传算法 | 虚拟边(赛时第一) | 优化版模拟退火 | 裸 MST基准(只含必选点) |
|---|---|---|---|---|
| 得分 | 1661851.40 | 1663057.20 | 1642726.40 | 1841194.00 |
如下为遗传算法版本
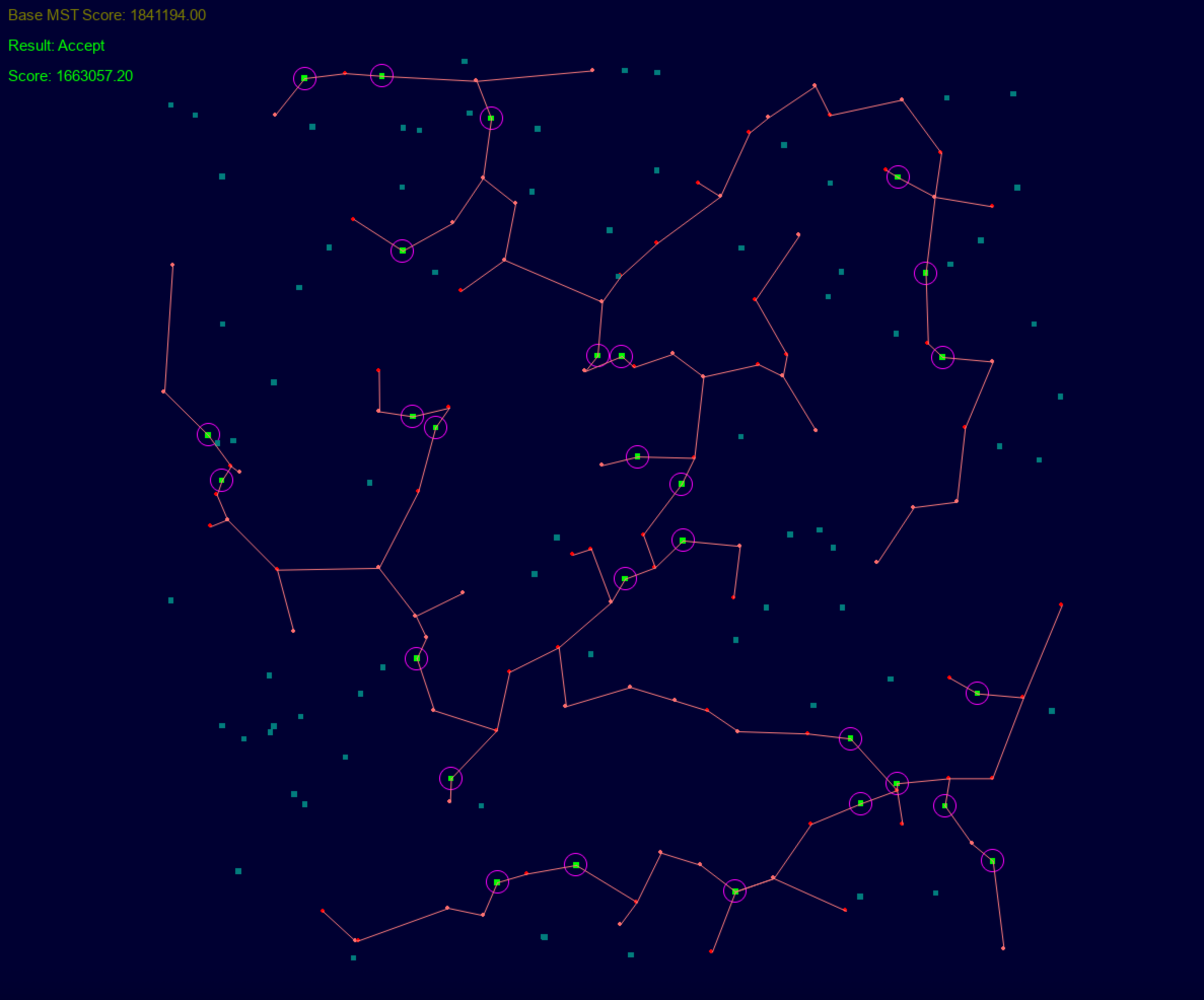
下图是虚拟边算法
进化趋势线
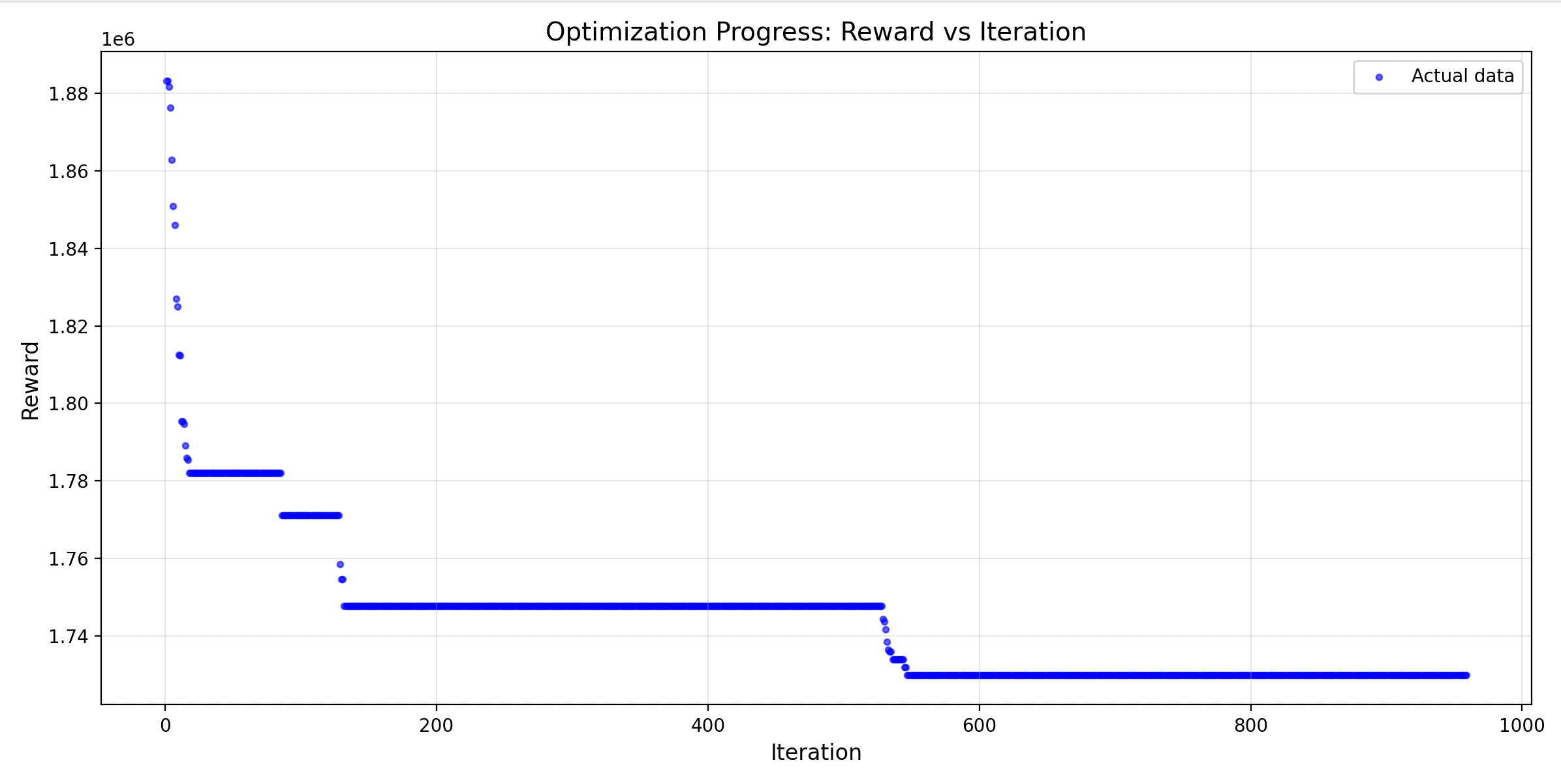
累计迭代了 959 轮,38360个体评估。
但是在 n=1500, m=1500的场景下(数值越小越好):
| 算法 | 遗传算法 | 虚拟边(赛时第一) | 优化版模拟退火 | 裸 MST基准(只含必选点) |
|---|---|---|---|---|
| 得分 | 176296223.00 | 158432605.60 | 157480901.20 | 176911403.40 |
累计只迭代了 6 轮,240 个体评估(限定在 10 秒之内)。
这个未经优化的遗传算法在大数据尺寸下表现并不好。
原因分析
赛时评测给定的时间限制为单case 10 秒(按照惯例和约定)
一次完整的 prim 算法时间复杂度为 O ( ( n + m ) 2 ) O((n+m)^2) O((n+m)2),随 n, m数量级变化,迭代次数呈平方反比。因此在 n,m 为 1500时,实际迭代次数就少的可怜。
而其进化,无论是变异,还是交叉,缺乏明确的正方向,试错成本高,进化效率低,其极度依赖个体实例数量和迭代次数。
以 n=20,m=50,限定迭代 1 轮(20个个体)为例,它不仅离基准解差很多,而且还引入了多余的悬挂点。
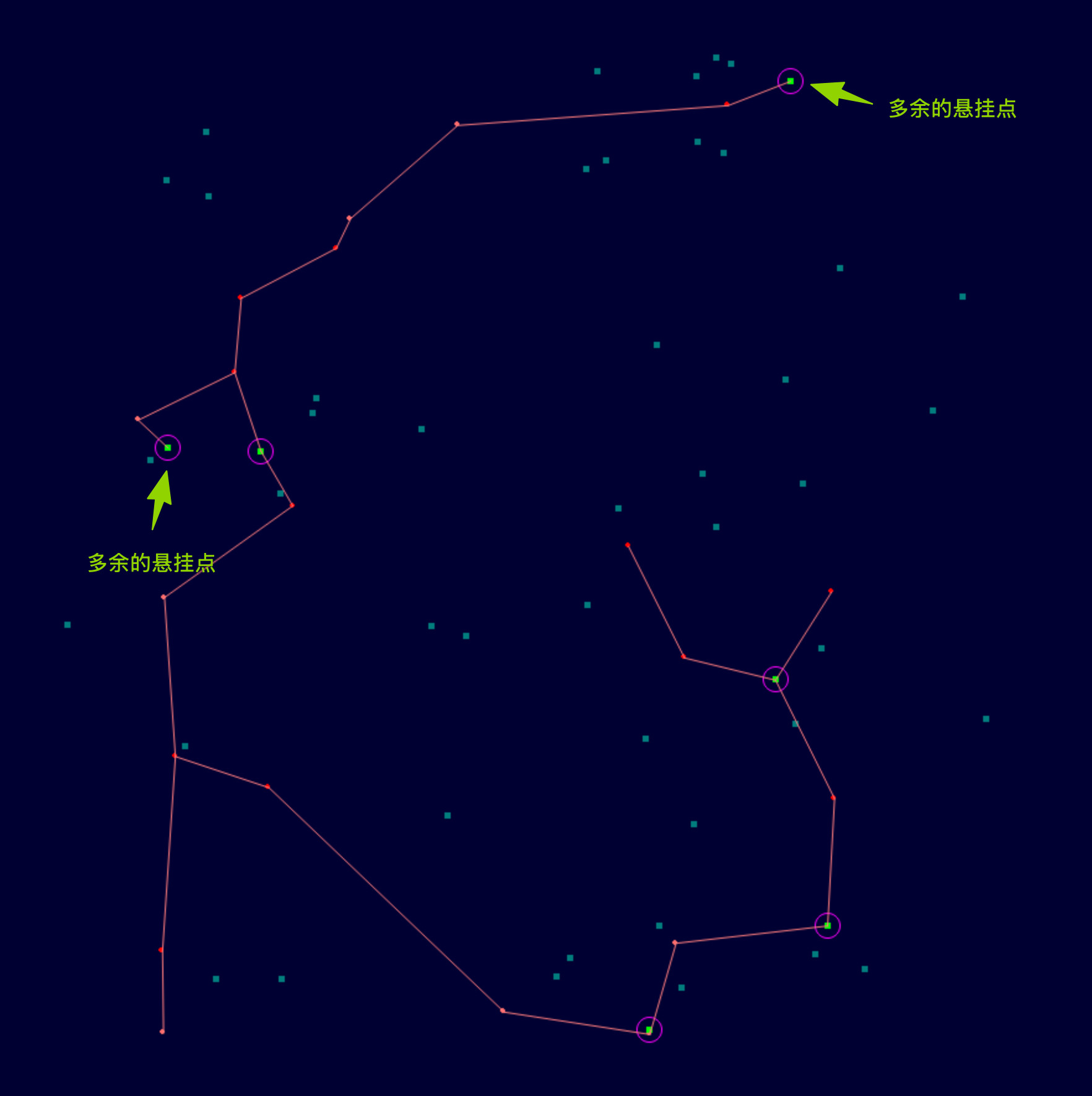
或者这么说,个体作为整体在进化,但是个体的局部有可能在倒退。
改进点
1. 引入快速评估机制
其在大数据集下表现不好,是因为其适应度函数时间复杂度过高,因此可以采用快速的近似评估算法代替。
比如对于某个可选点的引入,可以在原个体的最小生成树解的边集合中,快速测试引入的效果(即边加点操作),正收益则高概率引入,负收益则低概率引入\拒绝。其时间复杂度为 O ( n + m ) O(n+m) O(n+m).
这个机制会加速收敛,尤其是初期,避免来回震荡。
2. 全局引导
类似于 粒子群算法(PSO),构建一个全局打分机制,为M 长度的每一位 0-1 进行动态打分。
按动态分数,给予个体的基因 0-1 值的概率分布变化。
然后每一轮迭代反馈后,把分数反馈回全局的 0-1 打分表。
写在最后
