同样用 AI,有人 18 点下班,有人 21 点加班------差在 1 个动作
AI 时代的调度力

一、那 30 分钟,你在干嘛?
作为开发者,你大概率有过这样的体验:让 Claude Code / Cursor / Codex 跑一个 30 分钟的代码生成任务,比如重构模块、生成样板、跑端到端测试,你就坐着盯进度条,期间什么都没干。
或者更常见的:让 AI 跑测试,跑完改 bug,改完写文档。三件串行下来 1.5 小时,而你全程在场。
其实那 30 分钟可以多做一件别的事,只要你会用 subagents 和多终端调度。
会调度的开发者一天能让 AI 多跑一份活;不会的还在原地干等。差距不在 prompt 写得花不花哨,差在调度。
二、同样用 AI,差距在哪?两种"并行"
AI 在跑,你也在跑。会的人把每段空白都接上下一份产出,不会的人只能干等。这个差距有个名字,叫调度力------同一段时间里,你能让多少件事同时往前走。
调度力分两层,下面整篇都绕着它转。
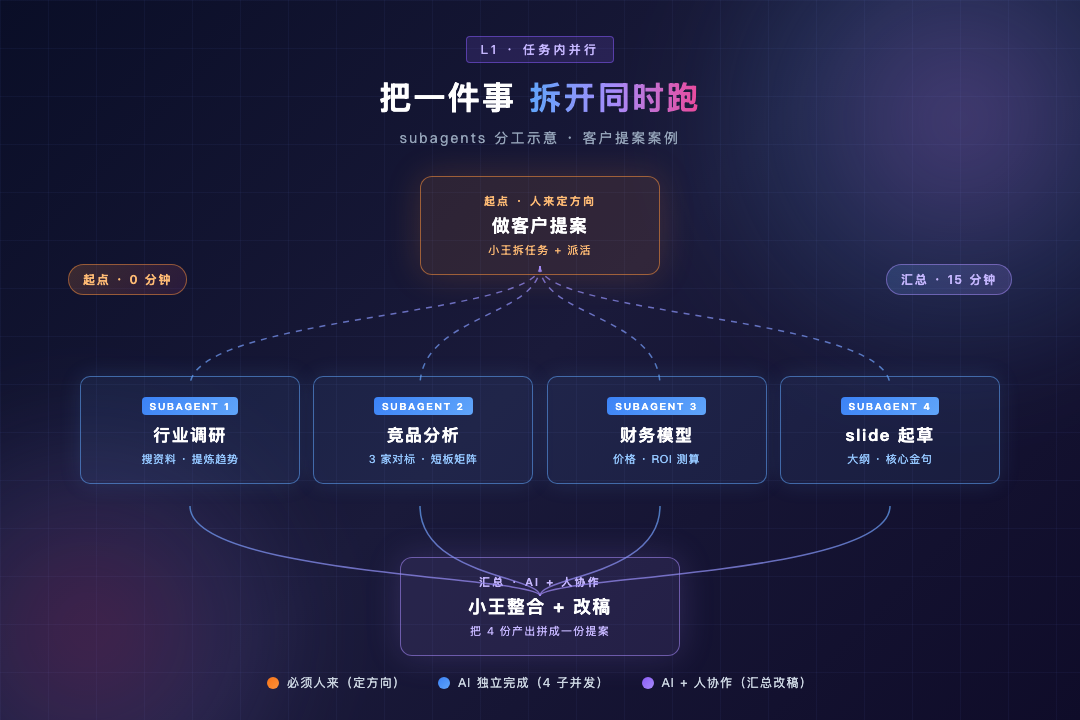
第一层是 L1 · 任务内并行 :把一件事 拆成几个互相没有依赖的子任务,让 AI 同时跑。比如做一份客户提案,行业调研、竞品、财务模型、slide 起草------这四件互不干涉,本来就该一起出活,不该一件接一件磨。
第二层是 L2 · 任务间并行 :多个项目交错推进,把"AI 在跑 A"的那段等待,套利成 B 项目的产出。第 1 节说的那 30 分钟,就是 L2 的素材。
两层并行的坐标系画好了,下面两节具体落地------L1 怎么派活,L2 怎么把"等 AI"换成产出。
三、第一层 · 任务内并行:让 AI 自己分头干
举个例子:系列主角小王是 PM,他不写代码,用 Claude Code / WorkBuddy 让 AI 替他写。这次任务是一份客户提案。
很多人对 L1 有个误解:以为调度的关键是在 prompt 里手动列出 4 个子任务清单------其实不是。
L1 的真正功夫在前一步------方案阶段。
小王做这份提案时,先跟 AI 来回讨论了一阵:客户痛点是什么、最终产出长什么样、必须包含哪几章、哪些事不要做。讨论完,AI 给出拆分建议------整体分四步:行业调研、竞品分析、财务模型、slide 起草。
这时小王主动追问了一句:"这四步之间有依赖吗?哪些可以并行?" AI 会标出来:前三步互不依赖,slide 起草要等前三步出结论再细化,但 slide 框架可以先搭。
小王审了一遍,调了两个细节,方案就敲定了。
到了派活阶段,他只说一句:
按刚才方案执行,无依赖的子任务并行处理,整合完成后停下来让我审。
AI 立刻派出 3 个 subagents(子代理) 并发跑前三步、slide 同步搭框架。15 分钟后四份产出回来,他整合 + 改稿 20 分钟。整件事 35 分钟搞定。
如果他没做方案阶段那一步对齐,直接说"帮我做一份客户提案",AI 会顺着往下一步步写,1 小时还不一定方向对。
1 小时 vs 35 分钟,差的不是 AI 的算力,是他派活前那 5 分钟把方案讲清楚了。
🔧 prompt 配方 · 直接复制可用
一个完整的 L1 调度 prompt 长这样(方案审完之后用):
text按我们刚才对齐的方案执行: 1. 把任务拆成无依赖子任务,每个子任务派一个 subagent 并行跑 2. 子任务清单(参考,可调整): - <子任务 A:例如行业调研,输出 markdown> - <子任务 B:例如竞品分析,输出对比表格> - <子任务 C:例如财务模型,输出关键数字 + 假设> 3. 每个 subagent 完成后,把产出汇总到一份总文档 4. 整合完成后停下来等我审,不要直接进下一步 5. 不可逆操作(发邮件 / 写库 / 删文件)一律先问我关键不在这段 prompt 的措辞------而在前面的方案阶段 。如果方案没审透,AI 拆出来的"无依赖"全是错的,并行只是把烂尾放大 N 倍:4 个 subagents 各自跑歪 4 种方向,整合时全要重做,比串行还慢。
一句话总结:派活前 5 分钟跟 AI 对齐方案,胜过 prompt 写 50 行。
L1 说穿了就这一件事:方案审到位,AI 自己会把无依赖的部分并行跑起来。但调度力不止这一层------多个项目之间也能并行,这就是 L2。
四、第二层 · 任务间并行:把"等 AI"的时间,再赚一份产出
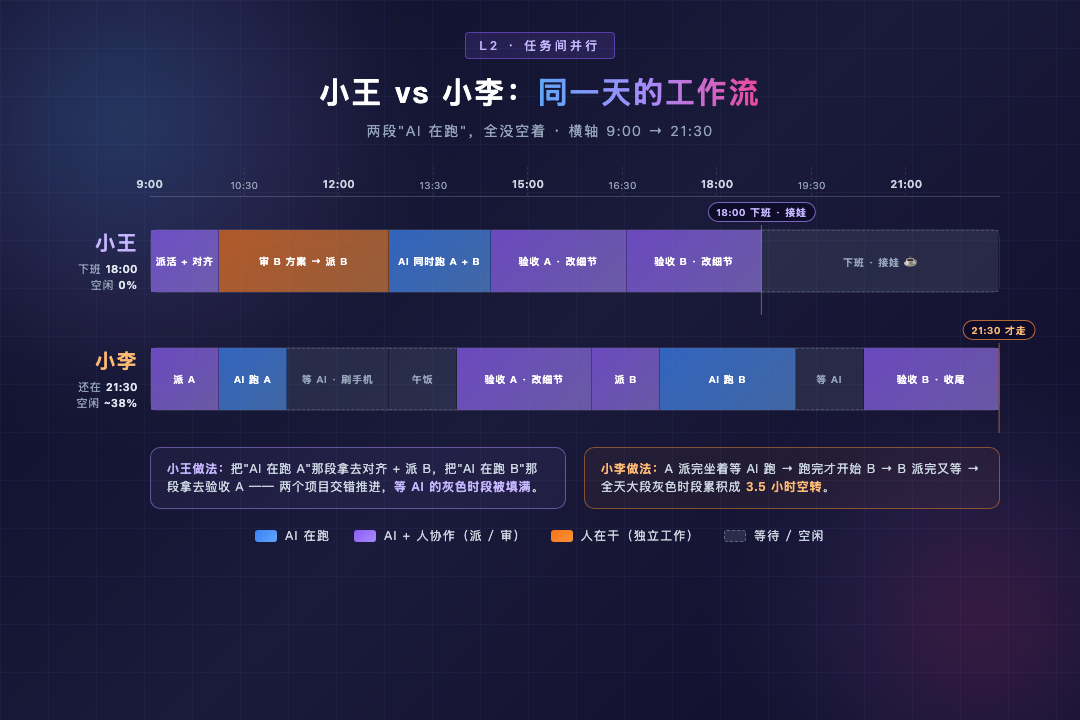
L1 是一件事拆开同时跑,L2 是几件事交错跑。看小王周三。
他手上两个活,两个都让 AI 干 。A 项目 :Excel 汇总小工具------需求和样例丢给 AI 全程生成 + 测试,AI 跑 1.5 小时 。B 项目 :成本优化方案------同样套路,方案对齐之后丢给 AI 跑,也 1.5 小时。
常规做法:A 派活 → A 跑完 → 审 A → B 派活 → B 跑完 → 审 B。两段"AI 在跑"你都干等,加起来 4 个多小时。
小王做法是这样的:
- 5 分钟把 A 的需求/验收/边界讲清楚,派给 AI 开始跑
- A 一开始跑,立刻打开第二个对话推 B ------ 跟 AI 来回对齐 B 的方案,15 分钟敲定,派活
- A 跑完时(前后约 1.5 小时),B 还在跑------ 乘 B 跑的时间去审 A,30 分钟改细节
- B 跑完,再审 + 整合
总耗时 ~2.5 小时。
省下来的不是 AI 算力,是"AI 在跑 A"那段被他拿去对齐 B 的方案、派 B;是"AI 在跑 B"那段被他拿去审 A 的成果。两段"等 AI"全没空着。
💡 工具配合心法 · Claude Code 三 mode 配三阶段
L2 关键:等 AI 时你能放心走开。Claude Code 用户最该掌握的就是 mode 切换:
- 讨论 / 拆任务 :用 default,AI 每步确认,方案不跑歪。讨论慢------慢是为了审透
- 派活 / 执行 :
Shift+Tab切 auto mode (accept-edits / bypass-permissions 视风险等级选),AI 一路跑完,你切去推下个项目。执行快- 验收 / 整合 :再按
Shift+Tab关回 default,产出人审;不可逆操作 (发邮件 / 上线 / 删文件 /git push --force/rm -rf)绝不放 auto。验收稳六字口诀:讨论慢,执行快,验收稳。讨论慢不是耽误------方案审透了,执行才敢 auto。
多终端推进时建议每个项目独立 worktree(
git worktree add),避免改动互相覆盖;Cursor / Codex 用户用多窗口或多 chat 标签,思路一致。
两层讲完,下节给两个上手动作------下周一就能开始。
五、两种并行实践,下周一就能上手
落到操作上就两件事------对应文章里的两层。
实践 1 · L1:方案阶段就让 AI 拆好
周一选一个手头最重的项目,开个新对话:
- 跟 AI 把任务讲清楚(业务背景 / 最终产出 / 必须包含什么 / 不要做什么),让它先给出拆分建议
- 主动追问一句:"这几项之间有依赖吗?哪些可以并行?"------AI 会标
- 在方案文档里把"可并行"标记好;执行阶段提一句"无依赖部分并行处理",AI 自己分头跑
不需要你手动列 4 个子任务清单,功夫全在前两步。
实践 2 · L2:A 在跑的时候去做 B
找一件"AI 在跑你能走开 30 分钟以上"的任务,比如长上下文重构、批量代码生成、深度调研、跑端到端测试:
- 派活前对齐方案(同上),开始执行后立刻打开第二个对话或终端推 B 项目
- 期间偶尔回头瞄一眼 A 的进度,B 写到合适节点就切回 A 验收
- 下班前看一眼:今天有几段"AI 在跑"的时间被你套利成了别的产出?记下数字
下周这个数字翻倍,你就摸到调度的门道了。
两个实践都是同一个套路:先把方案审到位,再让执行跑起来。
说到底,差距就在这一个动作------会不会调度 。L1 / L2 是场景,方案审到位是心法,贯穿一切的是这一个动词:调度。标题里那"1 个动作",到这里收成一个字。
这篇要是说到你了
觉得有用:收藏 + 点赞,下次 AI 跑长任务时翻出来当 cheatsheet。
觉得不对:评论区聊聊------你目前的并行场景是什么样?踩过哪些坑?多终端 worktree 你怎么管?