
💡Yupureki:个人主页
✨个人专栏:《C++》 《算法》《Linux系统编程》《高并发内存池》《MySQL数据库》
《个人在线OJ平台》《Linux网络编程》《CMake自动化构建工具》《Redis数据库》
🌸Yupureki🌸的简介:

目录
[1. UDP报头格式](#1. UDP报头格式)
[2. UDP的特点](#2. UDP的特点)
[3. UDP缓冲区](#3. UDP缓冲区)
1. UDP报头格式
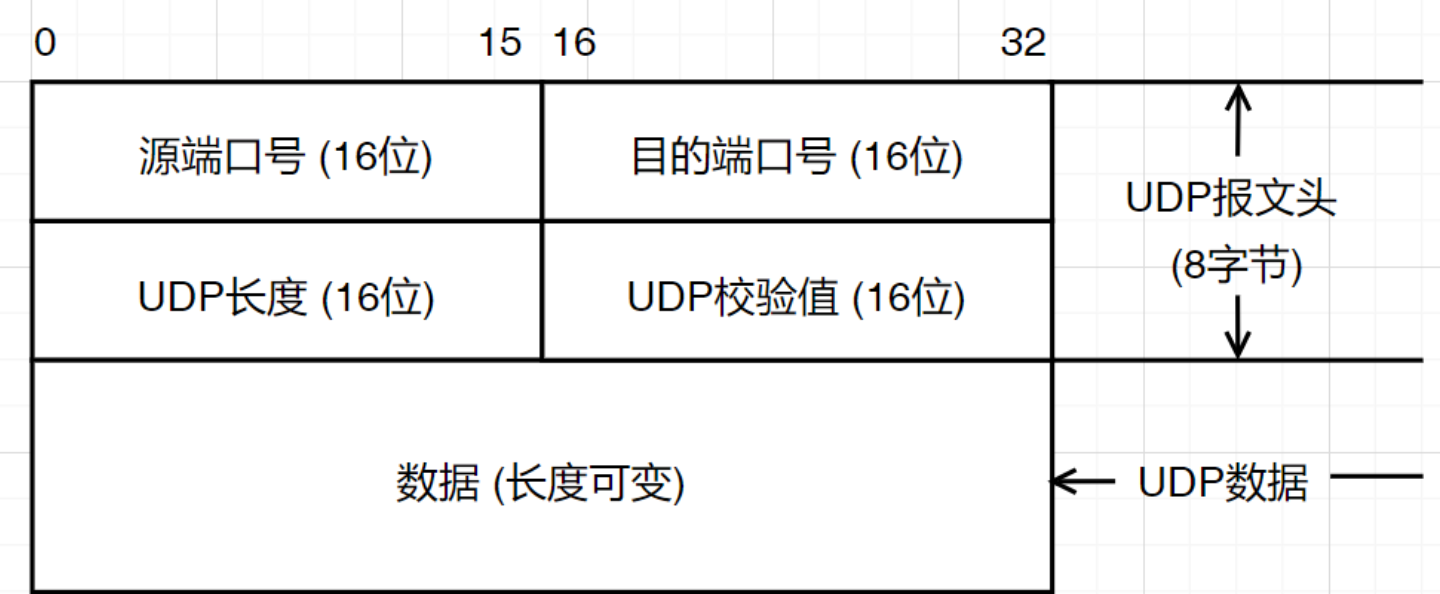
UDP 的头部结构固定,没有 TCP 那些复杂的选项字段:
-
源端口:发送进程绑定的端口,用于回复。可为 0(表示不需要回复)。
-
目的端口:接收进程的端口,是 UDP 实现多路分用的唯一核心依据。
-
长度:整个 UDP 数据报的长度(头部+数据),最小为 8(即无数据)。
-
校验和:覆盖 UDP 头部、数据和从 IP 层提取的部分信息(伪首部),用于差错检测。在 IPv4 中可选(可全为 0 表示不校验),IPv6 中则强制计算。
2. UDP的特点
1. 无连接
发送方在发送数据之前,不需要与接收方建立端到端的连接。每次通信都是独立的。
2. 不可靠传输
这是 UDP 最著名的特点,意味着它将网络本身的"尽力而为"特性直接暴露给应用。
-
不保证送达:没有确认和重传机制。如果数据报在网络中因拥塞、错误或超时被丢弃,发送方不会得到通知,数据将永久丢失。
-
不保证顺序:每个数据报独立路由,后发的可能先到达。接收方收到的顺序可能与发送顺序完全不同。
-
不保证不重复:在极端情况下(如路由环路),一份数据报可能在网络中被复制,接收方可能会收到多份相同报文。
3.面向数据报
UDP 忠实保留了应用层报文的边界,这是它与 TCP 字节流模型的根本区别。
-
一次发送,一次完整接收 :发送方调用一次
sendto,发送的是一个完整的消息。接收方调用一次recvfrom,拿到的也一定是这同一个完整消息(假设缓冲区足够)。绝不会出现TCP中常见的"粘包"或"半包"现象。 -
IP 分片依赖:这种"整报交付"的代价是,UDP 自身不对大数据块做分段。如果整个数据报超过路径 MTU,就会强依赖 IP 层分片。任何一个 IP 分片丢失,整个 UDP 数据报就会被丢弃,这大大增加了大报文的丢包风险。
4.支持广播与多播
这是 UDP 独有的能力,TCP 完全无法做到。通过一个 sendto 调用,就能将数据报发给局域网内所有主机(广播)或某个特定组播组的所有成员。这在大规模服务发现、IPTV 直播等场景中不可替代。
UDP 所有特点的本质是 "传输层功能的极端简化",它把数据传输的可靠性、顺序、拥塞管理全盘转嫁给了应用开发者。
因此,UDP 很适合:
-
需要极低时延且能容忍少量丢包的通信:在线游戏、VoIP、视频会议。
-
需要灵活控制发送节奏或自定义可靠机制的:QUIC / HTTP/3、自定义长连接协议。
-
请求-响应模型简单、数据量小的:DNS、NTP、SNMP。
-
需要一对多数据分发的:直播推流、局域网组播服务、IoT 设备发现。
UDP 不适合:
- 要求数据完整、准确、有序传输且不愿自行实现可靠机制的:文件传输、邮件、网页(这些默认由 TCP 承载)。
3. UDP缓冲区
与 TCP 那种"字节流缓存"不同,UDP 的缓冲区完全是另一套逻辑,直接体现了它无连接、不可靠的本质。
UDP无发送缓冲区,只有接收缓冲区
UDP 的发送侧没有 真正存储待确认数据的缓冲区(不重传)。每调用一次 sendto,内核就立刻将数据封装、下交 IP 层。
那通过 SO_SNDBUF 设置的"发送缓冲区"是什么?它本质上是一个限制单套接字在"发送途中"占用内核内存总量的配额。
-
作用机制:当数据报提交给 IP 层到网卡硬件真正完成发送之间,会短暂占用内核内存(如排队在流量控制 qdisc 中)。如果应用发得过快,占用内存会持续增长。一旦"在途"内存总量超过该配额:
-
阻塞套接字 :
sendto会阻塞,直到内存释放。 -
非阻塞套接字 :立即返回
EAGAIN/EWOULDBLOCK错误。
-
-
实质:它为无节制的 UDP 发送提供了一个本地的"背压"机制,防止一个进程耗尽所有内核内存。