4. 输出解析器(Output parsers)
快速简单的解释一下输出解析器到底解决什么问题:
你调模型拿到的 result 是一个 AIMessage 对象,不是纯字符串:
python
result = model.invoke(messages)
print(type(result)) # <class 'langchain_core.messages.AIMessage'>
print(result.content) # "你好!"每次都要 .content 很烦,而且如果你想把模型输出传给下一个环节(比如存入数据库),你需要的是纯字符串。
输出解析器就是:把 AIMessage 对象 → 纯字符串。
4.1 概念
负责获取模型的输出,并将输出转换为更结构化的格式 。当使用 LLM 生成结构化数据或规范化聊天模型和 LLM 的输出时,这很有用。
大型语言模型(LLM)的输出本质上是非结构化的文本 。但在构建应用程序时,我们通常希望得到结构化的、机器可读的数据 ,这样可以将其转换为更适合下游任务的格式,比如:
• JSON 对象
• Python 字典或列表
• 一个特定的 Pydantic 模型实例
• 一个简单的布尔值或字符串枚举
输出解析器的作用就是架起这座桥梁:**它们将 LLM 的非结构化文本输出转换为结构化格式。**这使得与LLM 的交互从"模糊的文本对话"变成了"精确的数据 API 调用",是构建可靠、高效 LLM 应用不可或缺的组件。
4.1.1 与with_structured_output() 的区别
两个都能实现结构化输出,但维度不同:
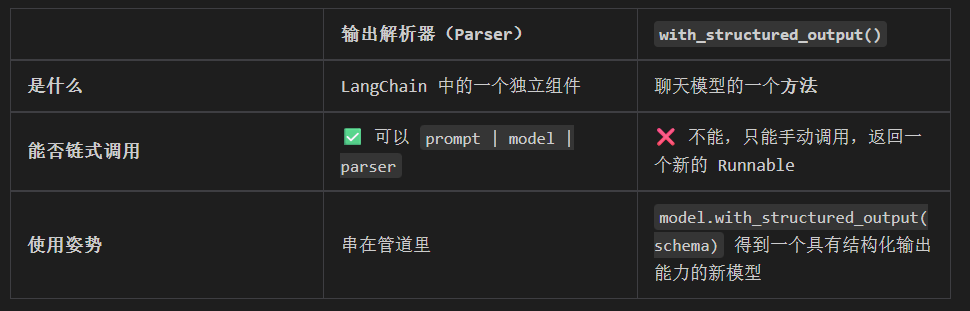
python
# 解析器方式:可以链式
chain = prompt | model | parser
result = chain.invoke(input)
# with_structured_output 方式:不能链式
structured_model = model.with_structured_output(Schema)
result = structured_model.invoke(input) # 必须手动调用可以根据自己的使用场景选择,想用链式调用就选输出解析器。两种都能达到目的,写法不同而已。
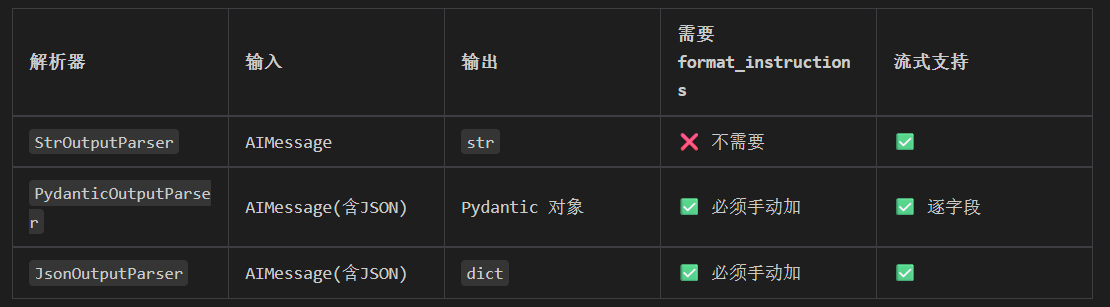
4.2 解析文本输出 --- StrOutputParser
StrOutputParser --- 最常用的输出解析器
它就是把 AIMessage 的 .content 取出来。
python
from langchain_core.output_parsers import StrOutputParser
from langchain_deepseek import ChatDeepSeek
model = ChatDeepSeek(model="deepseek-v4-flash")
chain = model | StrOutputParser()
for chunk in chain.stream("写一首夏天的诗词,50字以内。"):
print(chunk, end="|")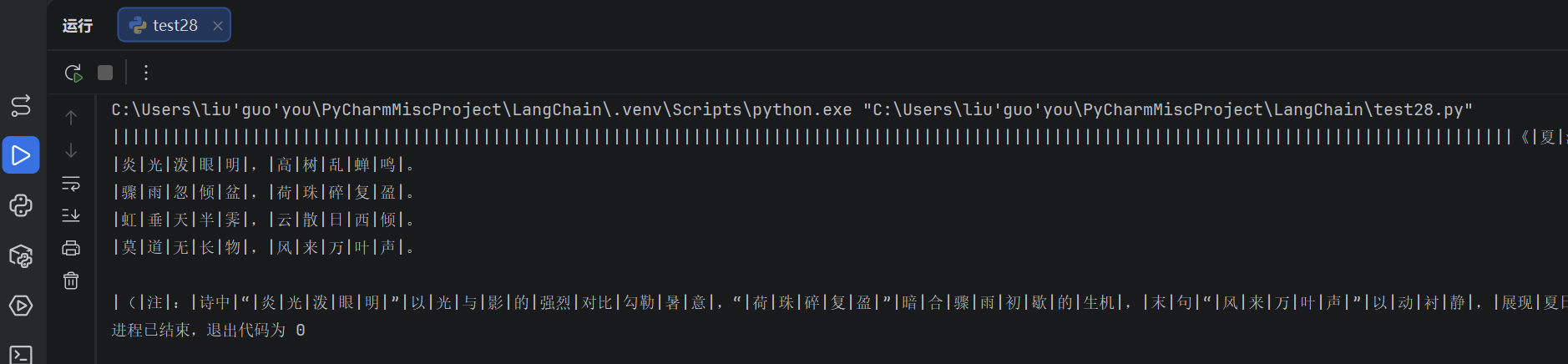
不用 parser :输出是 AIMessage,需要 .content ,流式时收到 AIMessageChunk
用 parser: 输出直接是 str, 流式时直接收到字符串 token
若是不使用输出解析器,而是直接得到聊天模型返回的 AIMessage,文本内容则需要从消息中的
content 字段获取。
为什么 parser 也能 .invoke()?
因为 StrOutputParser 也实现了 Runnable 接口,和聊天模型一样。所有实现了 Runnable 接口的组件,都可以:
4.3 解析结构化对象输出 --- PydanticOutputParser
如果你想拿到的不是字符串,而是一个带字段的 Python 对象(像之前 test23.py 那样),就用 PydanticOutputParser。
| 类别 | 项目 | 详细说明 |
|---|---|---|
| 类基本信息 | 完整路径 | langchain_core.output_parsers.pydantic.PydanticOutputParser |
| 核心作用 | 将大语言模型(LLM)的非结构化文本输出解析为强类型的 Pydantic 模型对象。利用 Pydantic 的数据验证机制,确保输出符合预定义的结构和类型约束,并自动处理格式错误。 | |
| 适用场景 | • 需要结构化 JSON 或类 JSON 输出的场景• 对字段类型有严格要求(如必须整数、枚举值、必填字段)• 希望利用 IDE 类型提示和自动补全进行下游开发• 需要优雅地处理 LLM 输出中的格式偏差或遗漏字段 | |
| 初始化参数 | pydantic_object |
类型 :Type[PydanticModel](继承自 BaseModel的类)作用:指定目标数据模型。Parser 会根据该类的定义(字段类型、描述、默认值、验证器)来:1. 生成格式指令(Format Instructions)2. 解析并验证 LLM 输出3. 实例化最终的对象 |
| 核心方法 | invoke(input: Union[str, dict, BaseMessage]) -> Any |
功能 :执行解析逻辑,将 LLM 的原始输出转换为结构化对象输入 :可以是字符串(LLM 纯文本响应)、字典(已部分解析)或 BaseMessage 对象输出 :解析后的 Pydantic 模型实例异常处理 :若输出无法解析或验证失败,会抛出 OutputParserException,包含原始输出和错误详情 |
get_format_instructions() -> str |
功能 :关键! 生成自然语言指令,指导 LLM 如何格式化输出返回 :包含 JSON 模式(JSON Schema)的字符串,描述了期望的输出结构典型用法 :必须将返回的字符串追加到 Prompt 的末尾 ,例如:```prompt = ChatPromptTemplate.from_template("请回答问题:{question}\n{format_instructions}")parser = PydanticOutputParser(pydantic_object=MyModel)chain = prompt |
|
| 底层机制 | Schema 生成 | 自动从 Pydantic 模型的字段类型(如 str, int, List[float], Literal['A','B'])生成对应的 JSON Schema,包含在 format instructions 中 |
| 容错处理 | 当 LLM 输出格式不匹配时(如缺少必填字段、类型错误、额外字段),默认行为取决于配置:• 严格模式:直接报错• 宽松模式:尝试提取可用字段,或填充默认值 | |
| 与 LLM 的交互 | 通常与 ChatPromptTemplate配合使用,将 get_format_instructions()的结果作为占位符注入提示,形成自描述的提示链(Self-describing Prompt) |
-
vs
JsonOutputParser:PydanticOutputParser基于类型系统,提供更强的类型安全和验证;JsonOutputParser仅确保输出是合法 JSON,不验证字段结构。 -
vs
StrOutputParser:后者直接返回字符串,不做任何结构化处理,适用于纯文本回答。 -
依赖 :需要安装
pydantic库(pip install pydantic)
案例代码:
python
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import PromptTemplate
from typing import Optional
from langchain_deepseek import ChatDeepSeek
from pydantic import BaseModel, Field
#1:定义你想要的输出结构(Pydantic 类)
class Joke(BaseModel):
"""给用户讲一个笑话。"""
setup: str = Field(description="这个笑话的开头")
punchline: str = Field(description="这个笑话的妙语")
rating: Optional[int] = Field(
default=None, description="从1到10分,给这个笑话评分"
)
# Field(description=...) 是给模型看的,告诉它每个字段什么意思
# 2:创建解析器
parser = PydanticOutputParser(pydantic_object=Joke)
#3:把格式化指令塞进提示词(关键)
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
# partial_variables 是什么?
# → 不需要每次 invoke 都传的"固定变量"。这里 format_instructions 只取决于 parser,
# 不随每次 query 变化,所以用 partial_variables 预先绑定,调用时只传 query 就行。
#4:串链
model = ChatDeepSeek(model="deepseek-v4-flash")
chain = prompt | model | parser
# 流程:模板填值 → 模型生成 JSON 字符串 → parser 把 JSON 转成 Joke 对象
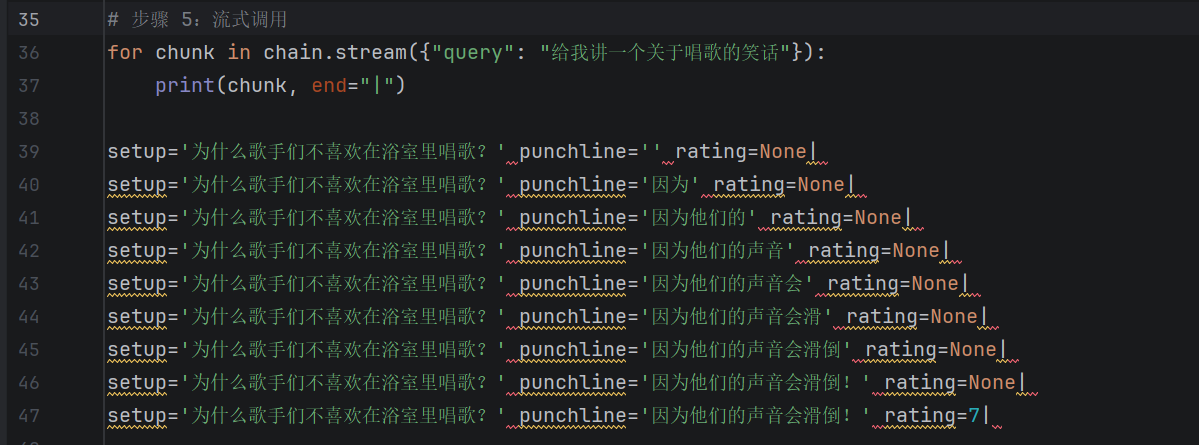
# 步骤 5:流式调用
for chunk in chain.stream({"query": "给我讲一个关于唱歌的笑话"}):
print(chunk, end="|")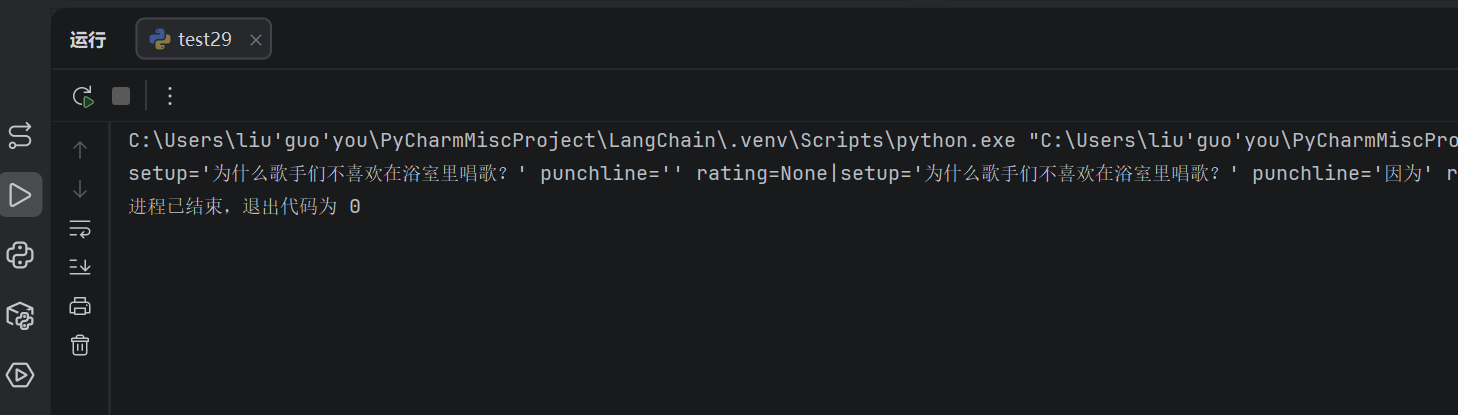
可以看到流式输出(逐 token 打出 Pydantic 对象的字段值)。注意流式时的特点: punchline 一开始是空字符串 '',然后一个字一个字地"长出来"------这就是流式解析的体现。
输出太长了,我复制换行下来看就明显了:
数据流:
{query: "给我讲一个笑话"}
│
▼
PromptTemplate → "Answer the user query.\n{format_instructions}\n给我讲一个笑话\n"
│ format_instructions = parser.get_format_instructions()(JSON schema 指令)
▼
model → AIMessage(content='{"setup": "...", "punchline": "...", "rating": 5}')
│ 模型遵照 format_instructions 输出了 JSON 字符串
▼
PydanticOutputParser → Joke(setup="...", punchline="...", rating=5)
│ parser 把 JSON 字符串反序列化成 Joke 对象
▼
你的代码可以直接 joke.setup, joke.punchline, joke.rating
和 with_structured_output() 的对比
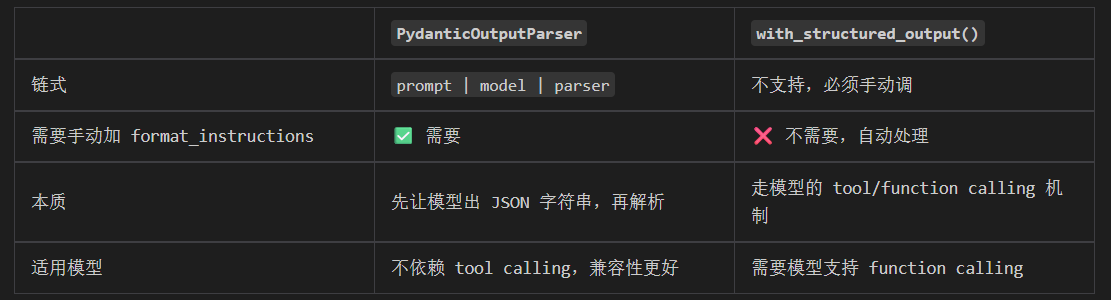
PydanticOutputParser 的优势在于它不依赖模型的 tool calling 能力------它只是在提示词里强行要求模型输出 JSON,然后解析。即使模型不支持 function calling,这套也能工作。
4.4 解析 JSON 输出 --- JsonOutputParser
PydanticOutputParser 把模型输出转成 Pydantic 对象。JsonOutputParser 把模型输出转成 Python 字典。
| 类别 | 项目 | 详细说明 |
|---|---|---|
| 类基本信息 | 完整路径 | langchain_core.output_parsers.json.JsonOutputParser |
| 核心作用 | 将 LLM 的输出解析为 JSON 格式 (Python dict或 list)。相比 PydanticOutputParser更轻量,专注于 JSON 语法解析,不强制依赖 Pydantic 模型进行类型验证(除非显式传入)。 |
|
| 适用场景 | • 需要灵活的 JSON 输出,结构可能随查询变化• 只需要基础的 JSON 解析,不需要严格的类型检查或数据验证• 作为 PydanticOutputParser的轻量级替代方案• 处理非严格的 JSON(如允许单引号、无引号键等宽松模式,取决于底层实现) |
|
| 初始化参数 | pydantic_object |
类型 :Optional[Type[PydanticModel]]]作用 :用于验证的 Pydantic 对象。如果为空(None) ,则不执行 任何数据验证,仅做 JSON 语法解析和字典转换;如果提供,则在解析后会用该模型验证数据结构并返回模型实例。 |
| 核心方法 | invoke(input: Union[str, dict, BaseMessage]) -> Any |
功能 :执行解析逻辑,将 LLM 输出转换为 Python 字典/列表或 Pydantic 对象输入 :LLM 的响应字符串(通常为 JSON 格式)、字典或 BaseMessage输出 :解析后的 Python 数据结构(若未传 pydantic_object)或 Pydantic 模型实例(若传入)异常处理 :若 JSON 语法错误或验证失败,抛出 OutputParserException |
get_format_instructions() -> str |
功能 :关键! 生成指导 LLM 输出 JSON 的自然语言指令返回 :包含 JSON 结构描述(或 JSON Schema)的字符串典型用法 :必须将返回的字符串追加到 Prompt 末尾,明确告知模型:"请以 JSON 格式输出,包含 'name' 和 'age' 字段" | |
| 与 PydanticOutputParser 对比 | 验证机制 | JsonOutputParser:基础 JSON 语法检查,可选 Pydantic 验证(非必需)PydanticOutputParser:强制 Pydantic 验证,强类型约束 |
| 灵活性 | JsonOutputParser:更高,适合动态结构PydanticOutputParser:更低,结构固定且严格 |
|
| 性能开销 | JsonOutputParser:更轻量,解析更快PydanticOutputParser:需实例化模型,验证开销略大 |
4.4.1 不带 Pydantic(纯字典)
和 PydanticOutputParser 的区别: 输出是 dict 不是 Pydantic 对象,字段名由模型自己决定(这里是 joke)。
python
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_deepseek import ChatDeepSeek
# 创建解析器(不传 pydantic_object,纯输出 dict)
parser = JsonOutputParser()
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
model = ChatDeepSeek(model="deepseek-v4-flash")
chain = prompt | model | parser
result = chain.invoke({"query": "给我讲一个关于唱歌的笑话"})
print(result)
4.4.2 带 Pydantic(有类型校验的字典)
带 Pydantic 时:
get_format_instructions() 会包含 Pydantic 定义的字段约束
输出虽然是 dict,但会按 Pydantic 定义的字段名和类型做校验
和 PydanticOutputParser 的区别:输出是 dict 而非 Joke 对象
python
from typing import Optional
import Field
from pydantic import BaseModel, Field
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_deepseek import ChatDeepSeek
# 定义输出结构:Pydantic 类
class Joke(BaseModel):
"""给用户讲一个笑话。"""
setup: str = Field(description="这个笑话的开头")
punchline: str = Field(description="这个笑话的妙语")
rating: Optional[int] = Field(
default=None, description="从1到10分,给这个笑话评分"
)
parser = JsonOutputParser(pydantic_object=Joke)
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
model = ChatDeepSeek(model="deepseek-v4-flash")
chain = prompt | model | parser
result = chain.invoke({"query": "给我讲一个关于唱歌的笑话"})
print(result)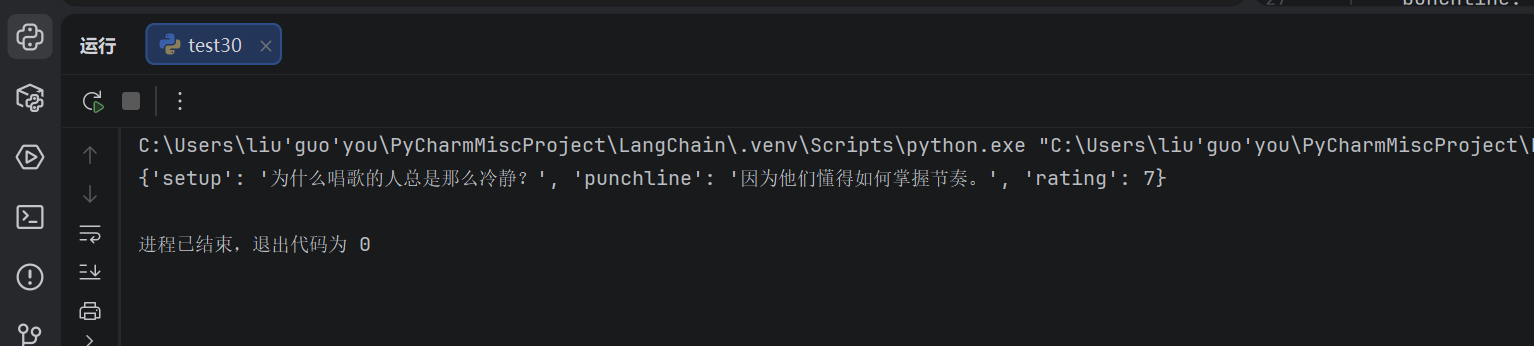
对比
你要什么?
├─ 只要文字内容 → StrOutputParser
├─ 要带类型的 Python 对象 → PydanticOutputParser
└─ 要字典,不想定义 Pydantic 类 → JsonOutputParser
除了上面讲的文本、对象、JSON解析器,其实 LangChain 官方还提供了更多类型的解析器,如:
• XML 解析器: XMLOutputParser
• Yaml 解析器: YamlOutputParser
• CSV 解析器: CommaSeparatedListOutputParser
• 枚举解析器: EnumOutputParser
• 日期解析器: DatetimeOutputParser 等等,更多类型参考离线 |LangChain 参考文档。
除此之外,LangChain 还支持我们自定义输出解析器,以将模型输出结构化为自定义格式,详细情况参考LangChain overview - Docs by LangChain
完毕,下一篇笔记文档加载器