目录
在进入MySQL数据库基础前,我们需要先在我们的操作系统上面安装好MySQL(centos或ubuntu),做好准备后,我们会进入命令行

我使用的是Ubuntu系统(具体的安装教程兄弟们可以网上搜哈)

我们只需输入上面的命令,输入密码, 即可进入MySQL
当然,除了上面简单的进入命令以外,MySQL也给了我们用户其他相应的选项

这里需要注意的是:
1.目前是密码登陆的,也就是你之前安装mysql时设置的密码
2.密码输入的时候,是不会显的
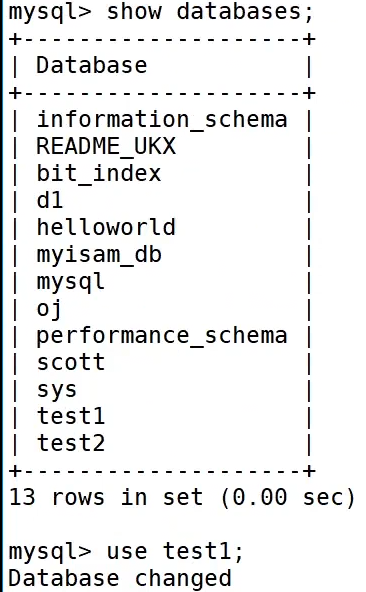
什么是数据库
在刚开始呢,我们需要做一件与后面学习强相关的事情

输入这一段命令

我们可以得到如图正在运行的进程
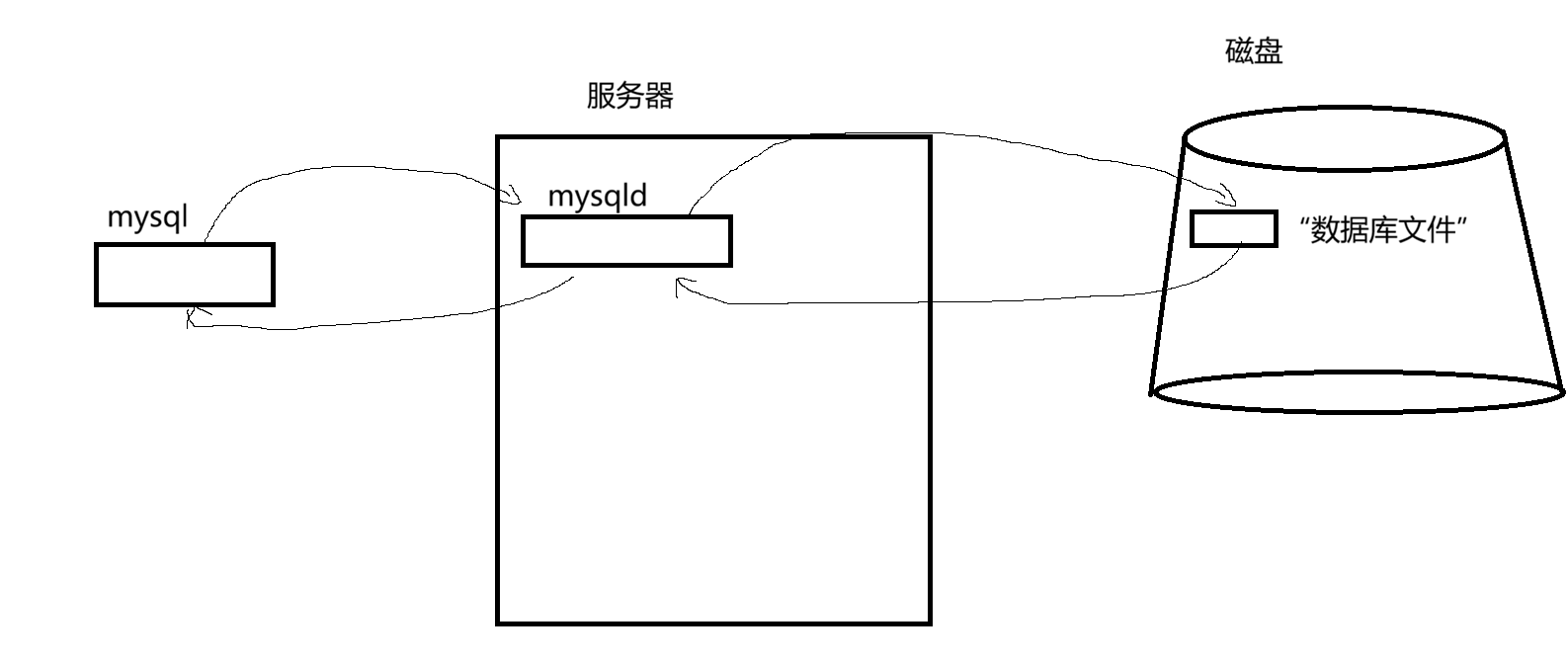
我们需要弄懂mysql和mysqld的区别
1.mysql就是数据库服务的客户端
2.mysqld就是数据库服务的服务器端(在后台一直以守护进程的形式一直运行)
3.mysql本质:基于C(mysql)S(mysqld)模式的一种网络服务
mysql是一套给我提供数据存取的服务的网络程序
数据库一般指的是,在磁盘或者内存中存储的特定结构组织的数据----将来在磁盘上存储的一套数据库方案
一般的文件确实提供了数据的存储功能,但是文件并没有提供非常好的数据管理能力(用户角度)
数据库本质:对数据内容存储的一套解决方案,你给我字段或者要求,我直接给你结果就行从而形成一套存储解决方案
文件的缺点:
1.不具有安全性(谁都可以访问,需要添加权限)
2.不利于查询海量数据
3.文件在程序中控制不方便
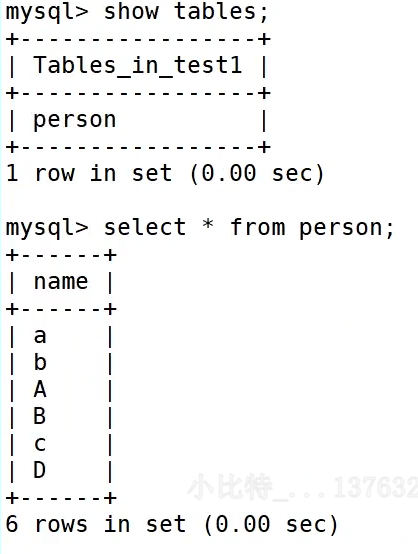
数据库样例
使用MySQL建立一个数据库,建立一张表,插入一些数据----对比一下MySQL在Linux是如何表现的
1.建立数据库,本质就是Linux下的一个目录
2.在数据库内建立表,本质就是在Linux下创建对应的文件即可
3.数据库的本质其实也是文件,只不过这些并不由我们直接操作,而是由数据库服务帮我们进行操作
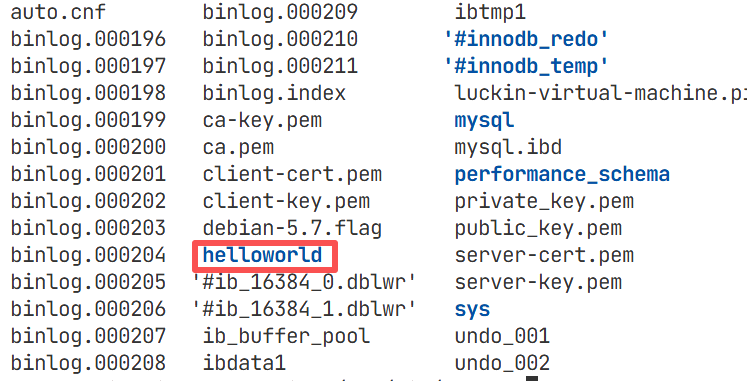

存入表中的数据如图按逻辑以行列进行存储(二维)

主流数据库
1.SQL Sever: 微软的产品,.Net程序员的最爱,中大型项目。
2.Oracle: 甲骨文产品,适合大型项目,复杂的业务逻辑,并发一般来说不如MySQL。
3.MySQL:世界上最受欢迎的数据库,属于甲骨文,并发性好,不适合做复杂的业务。主要用在电商,SNS,论坛。对简单的SQL处理效果好。
4.PostgreSQL :加州大学伯克利分校计算机系开发的关系型数据库,不管是私用,商用,还是学术研究使用,可以免费使用,修改和分发。
5.SQLite: 是一款轻型的数据库,是遵守ACID的关系型数据库管理系统,它包含在一个相对小的C库中。它的设计目标是嵌入式的,而且目前已经在很多嵌入式产品中使用了它,它占用资源非常的低,在嵌入式设备中,可能只需要几百K的内存就够了。
6.H2: 是一个用Java开发的嵌入式数据库,它本身只是一个类库,可以直接嵌入到应用项目中。
服务器,数据库,表的关系
- 所谓安装数据库服务器,只是在机器上安装了一个数据库管理系统程序,这个管理程序可以管理多个数据库,一般开发人员会针对每一个应用创建一个数据库。
- 为保存应用中实体的数据,一般会在数据库中创建多个表,以保存程序中实体的数据。
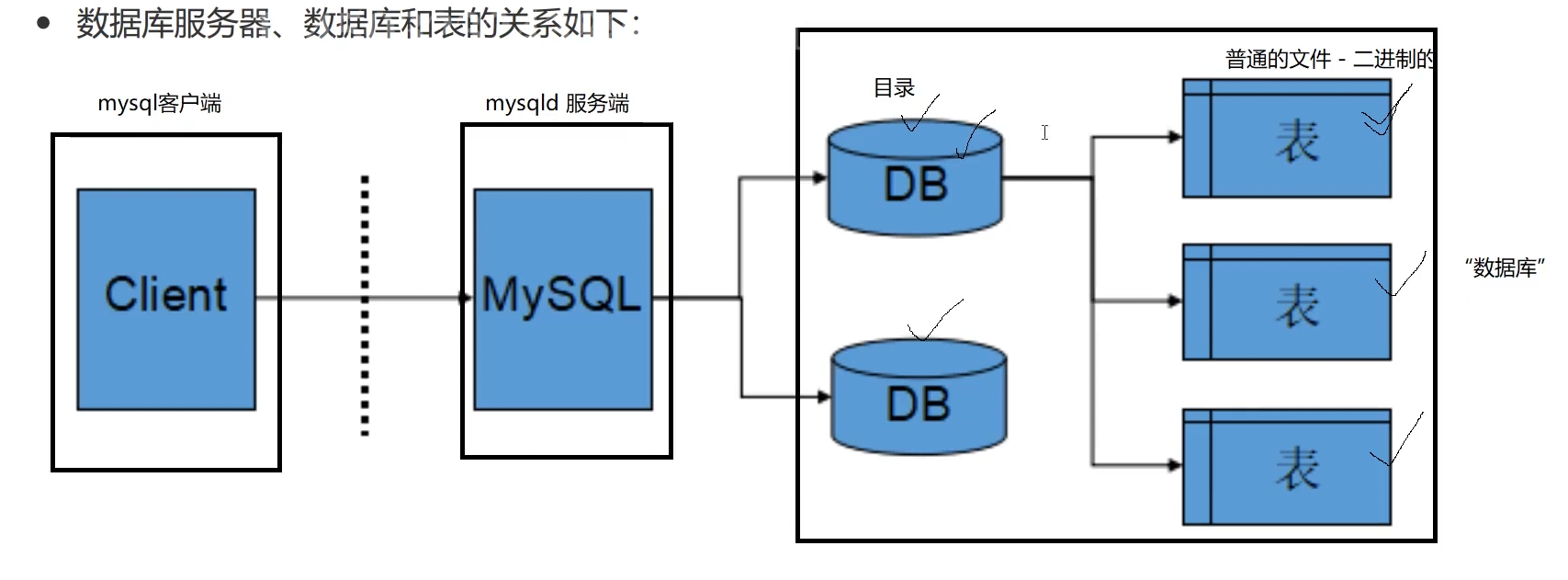
在Linux中,图中DB呈现为目录形式,表则为二进制的普通文件
MySQL架构
MySQL 是一个可移植的数据库,几乎能在当前所有的操作系统上运行,如 Unix/Linux、Windows、Mac 和 Solaris。各种系统在底层实现方面各有不同,但是 MySQL 基本上能保证在各个平台上的物理体系结构的一致性。
MySQL依旧是个文件系统,MySQL是基于操作系统提供的文件系统之上的一套存储解决方案
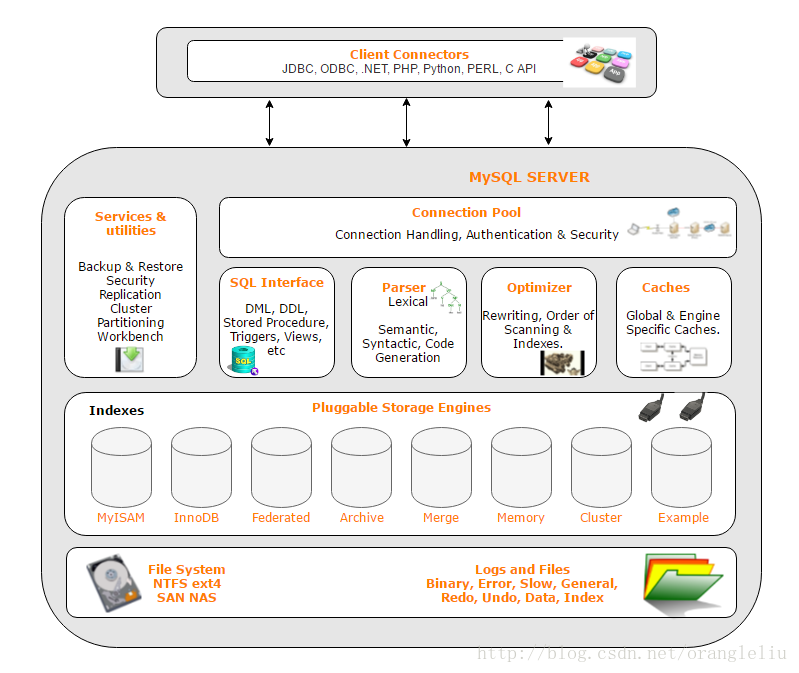
第一层的功能主要连接管理和鉴权,还有安全方面的策略
第二层的功能主要是对客户端下达下来的SQL指令进行词法分析和语法分析,对查询SQL语句进行优化,且根据相关的SQL协议来向下传递(类似编译器)
第三层(支持热拔插)对应的是一个一个的存储引擎(作用类似计算体中的驱动),接收上面下传下来的SQL语句(因为存储数据类型(如文档类型,二进制类型等)的差别,才有这么多不同的存储引擎),如MyISAM可以对大文本进行读取,并发度比较高,适合大量进行select读取,InnoDB有丰富的索引支持,可进行快速搜索查找
最后一层帮我们访问指定的数据库,访问指定的文件或者指定的表结构,把我们的数据进行增删查改,以二进制的方式存储到特定的目录下
在操作系统视角下,上三层属于用户进程,最后一层属于操作系统
网络视角下,上三层属于应用层,最后一层属于内核层
SQL语句的分类
- DDL【data definition language】 数据定义语言,用来维护存储数据的结构,代表指令: create, drop, alter
- DML【data manipulation language】 数据操纵语言,用来对数据进行操作,代表指令: insert,delete,update
- DML中又单独分了一个DQL,数据查询语言,代表指令: select
- DCL【Data Control Language】 数据控制语言,主要负责权限管理和事务,代表指令: grant,revoke,commit
DDL可以理解为创建一个表结构(或者想要创建一个链表结果,定义节点和指针)
DML可以理解为对表结构中的数据进行增删查改(对链表中进行头插,尾插,逆置,找数据最大或者最小的节点)
DCL主要为鉴权
存储引擎
存储引擎存在最底层,与我们的操作系统打交道,存在一大堆文件的系统调用(如对文件进行修改)
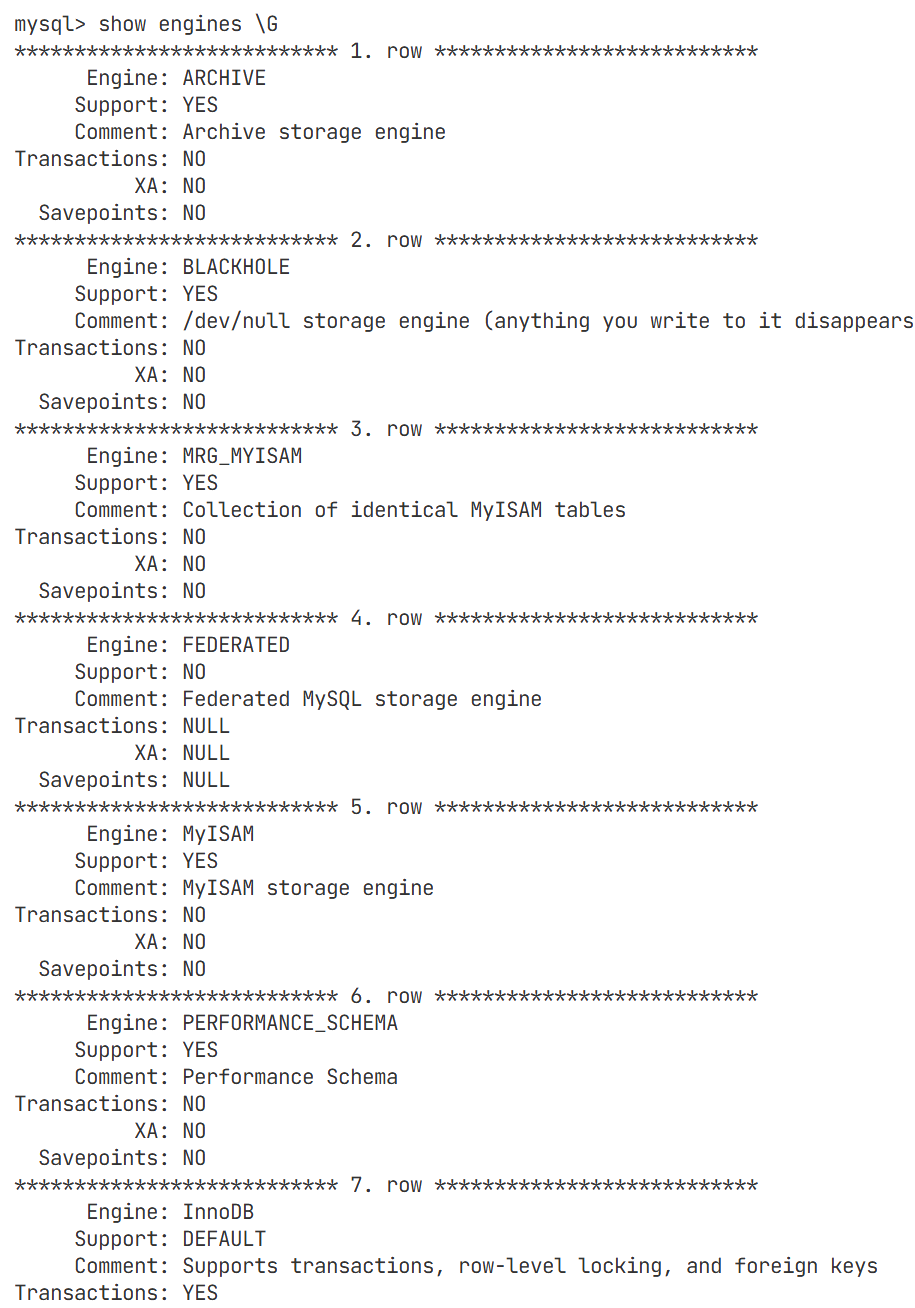
我们这里主要使用的时InnoDB
InnoDB支持事务,MyISAM不支持
库的操作
创建数据库
登陆进入我们的MySQL,并打开另外一个终端
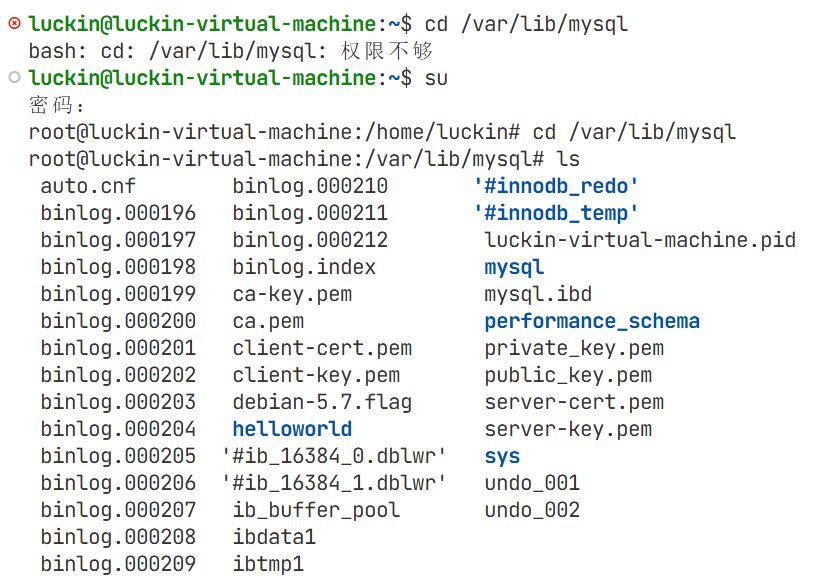
需要变成root用户,才能看该目录下所有的文件

该指令是展示具有的数据库有哪一些
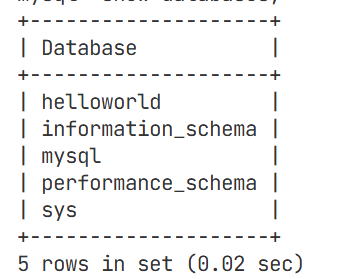
该指令为创建数据库的指令

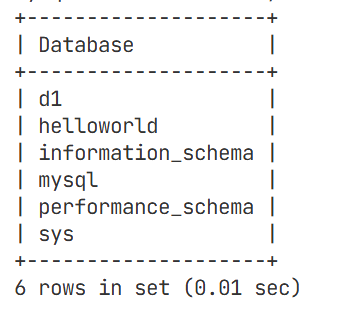
该指令为删除数据库指令


该指令为修改数据库
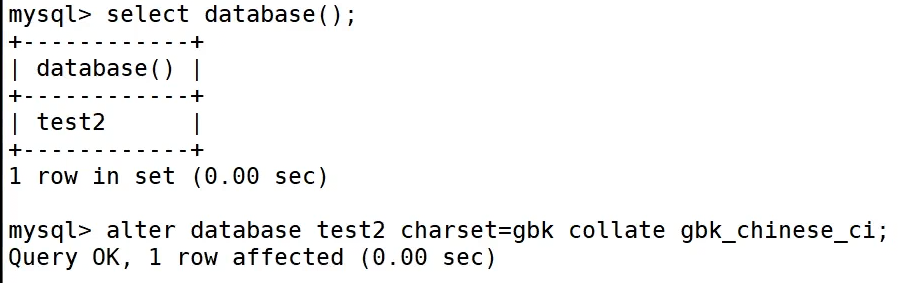


想知道自己目前在哪个数据库中
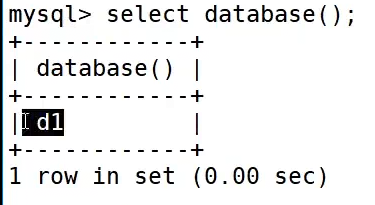
查看该数据库是怎么创建的

红框中的语句的意思是使用的MySQL版本超过4.01则采用后面的语句
创建数据库:create databases db_name;-----在Linux系统下本质就是在/var/lib/mysql创建一个目录
删除数据库:drop databases db_name; -----在Linux系统下就是删除了一个目录
系统编码
创建数据库的时候,有两种编码集:
1.数据库编码集:数据库未来存储数据
2.数据库校验集:支持数据库,进行字段比较使用的编码,本质也是一种读取数据库中数据的采用的编码格式
数据库无论对数据做任何操作,都必须保证操作和编码都必须编码一致的
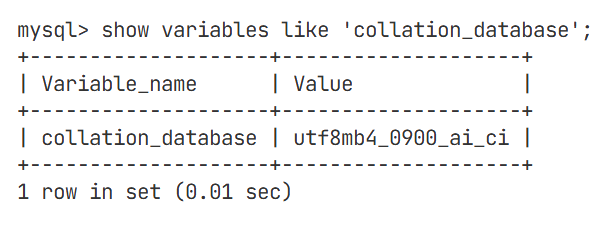
该指令可以查看你的数据库中的编码规则

该指令可以查看你的数据库中的校验规则
我们也可以在创建数据库的时候指定编码集格式




我们也可以在创建数据库的时候设置指定编码集格式的同时设置指定的校验集格式


我们默认的编码规则和校验规则是utf8,想要使用其他的编码校验格式,我们可以进行手动修改,如不手动修改,就还是使用默认的编码校验规则


注意
这里所展现的是适用于MySQL8之前版本的方式存储,MySQL8之后把数据库元数据从文件系统迁移到了内置的数据字典里
编码之间的区别

此处使用校验规则的区别来区分(utf8_general_ci不区分大小写,utf8_bin区分大小写)


建表(test1)

查看person的表结构,并向里面插入数据
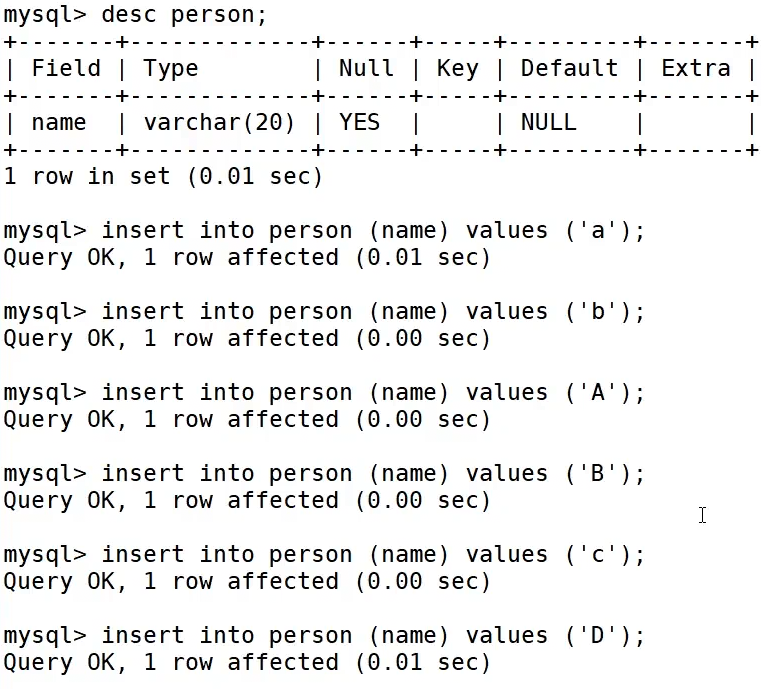
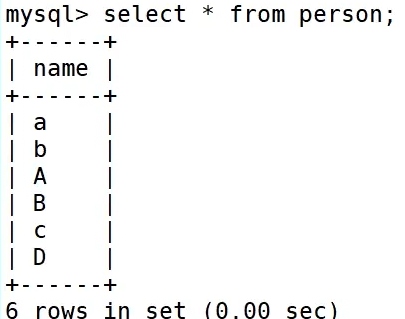

我们插入数据是使用的编码规则,查找数据是使用的校验规则
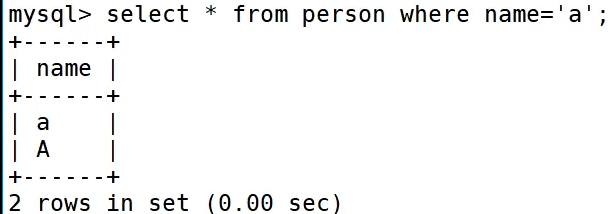
utf8_general_ci不区分大小写
使用test2重复上面操作
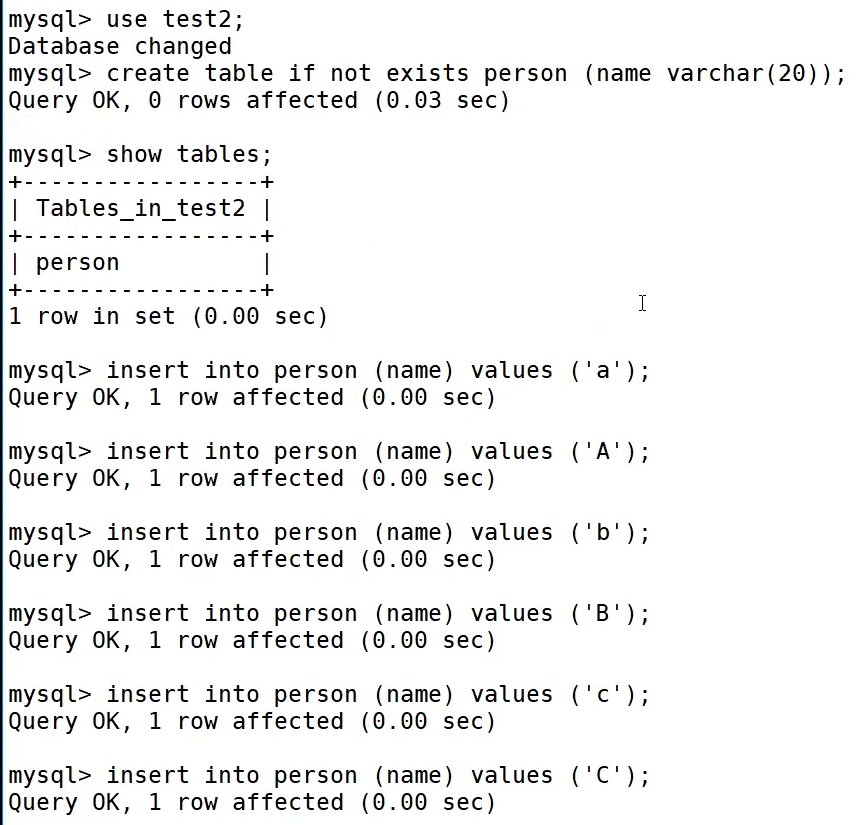
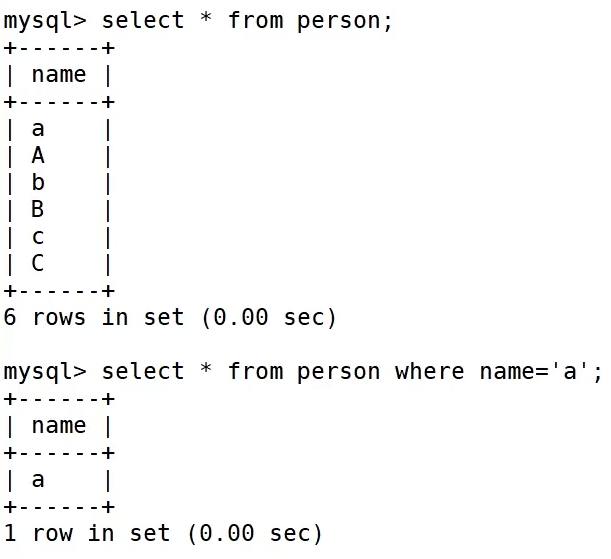

utf8_bin区分大小写
通过以上案例我们可以发现,不同的校验规则查出来的数据格式就不同,排序也是如此
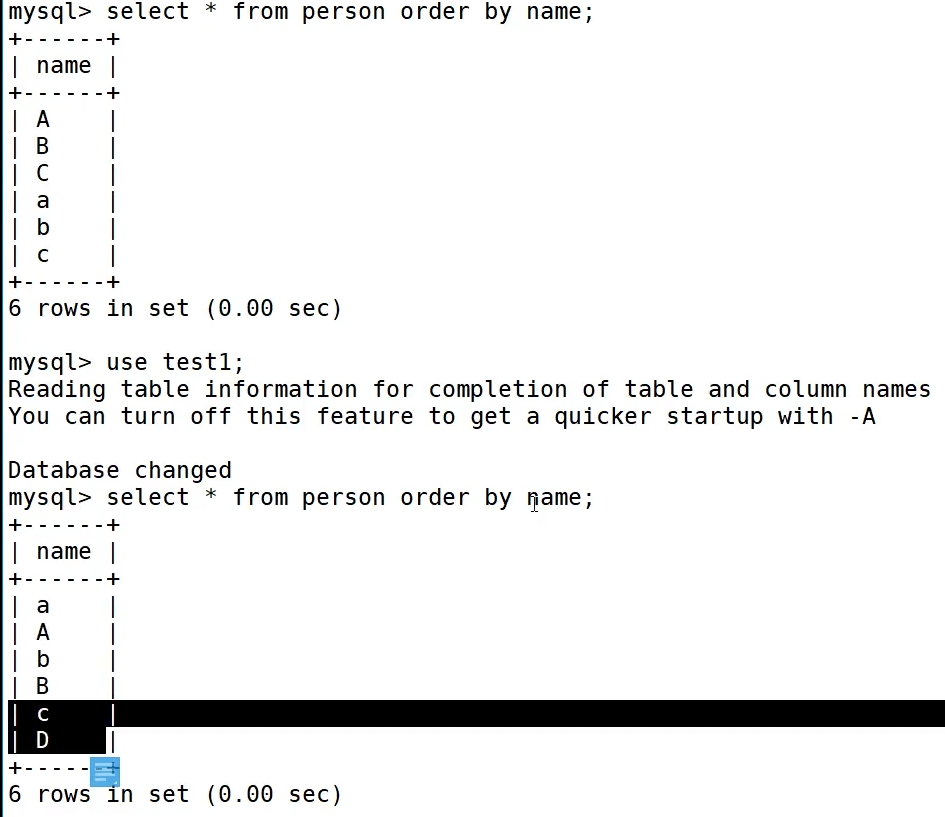
库的备份与恢复
先创建一个目录,在该目录下输入下面命令行
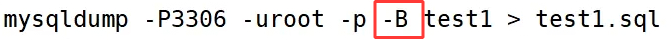
-B的意思是指定数据库
再返回MySQL,将备份文件进行删除
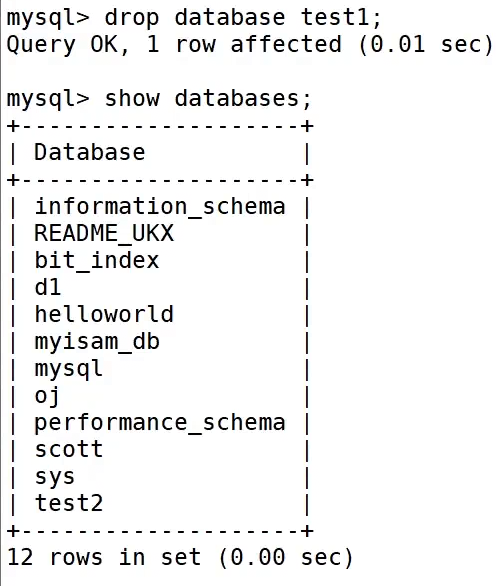
执行之后想要恢复删除的test1数据库
只需要再MySQL命令行处输入source+sql文件的路径即可
注意事项:
1.如果备份的不是整个数据库,而是其中的一张表,怎么做?
# mysqldump -u root -p 数据库名 表名1 表名2 > D:/mytest.sql2.同时备份多个数据库
# mysqldump -u root -p -B 数据库名1 数据库名2 ... > 数据库存放路径3.如果备份一个数据库时,没有带上-B参数, 在恢复数据库时,需要先创建空数据库,然后使用数据库,再使用source来还原。
如果想看除了我们之外还有谁连接了我们的数据库

表的操作
创建表
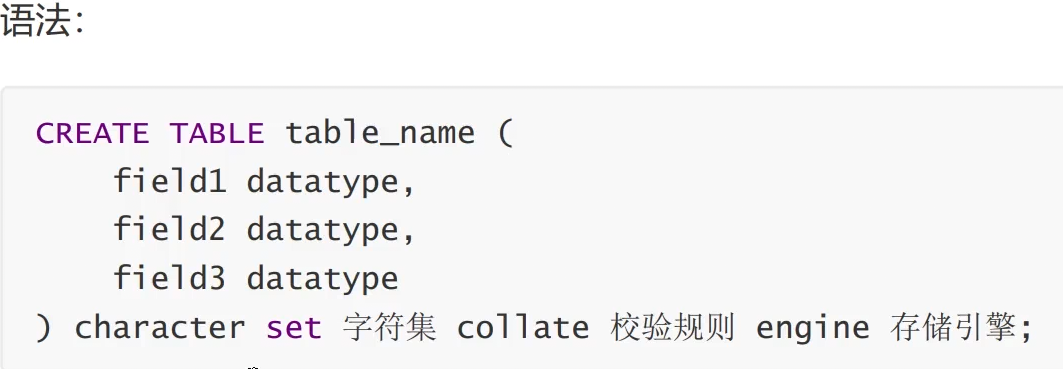
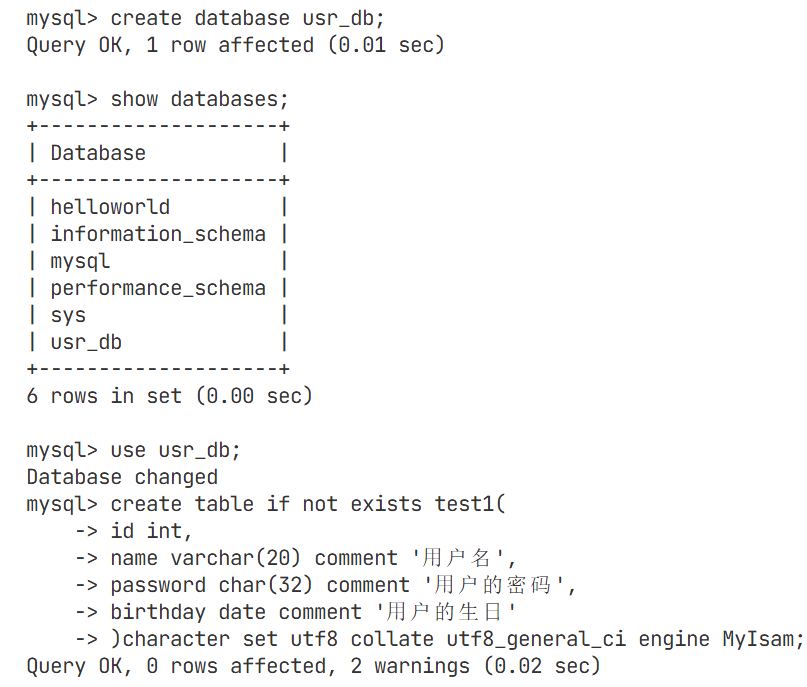

细节:再MySQL中空格当分隔符使用

MyIsam将数据和索引文件分开,InnoDB将两个文件合并
查看表
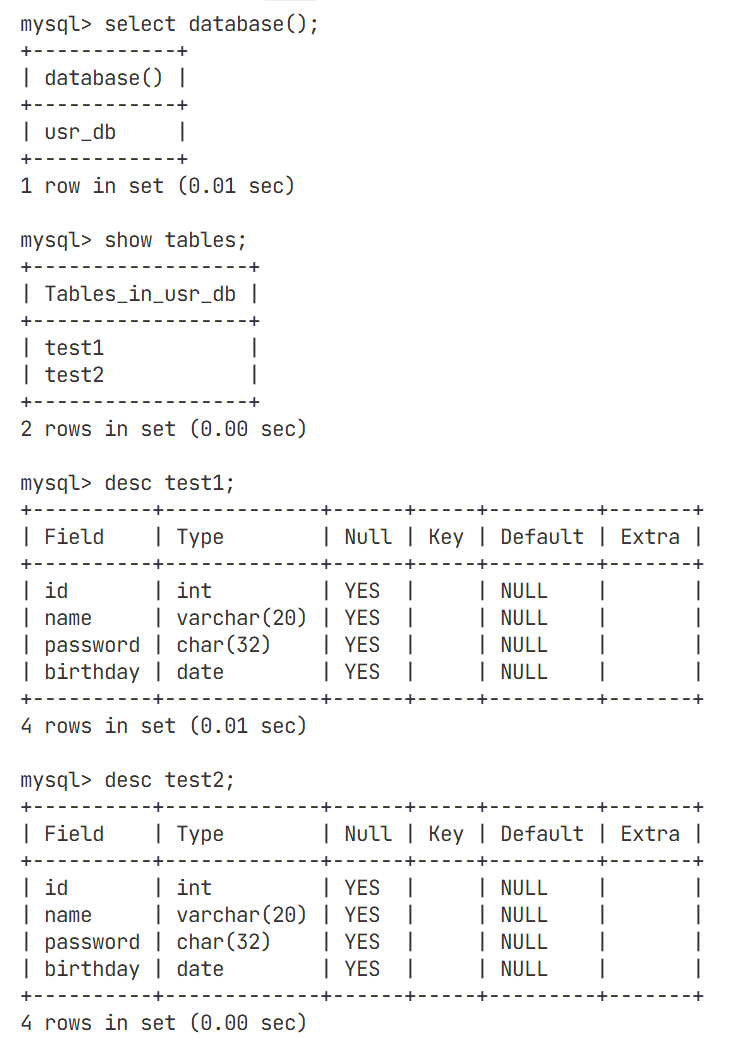
想要查看数据可中表是如何创建的
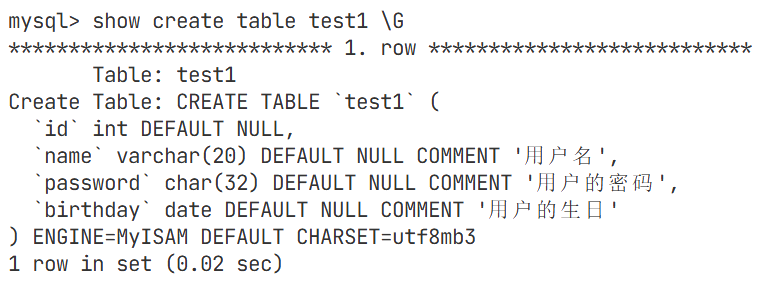
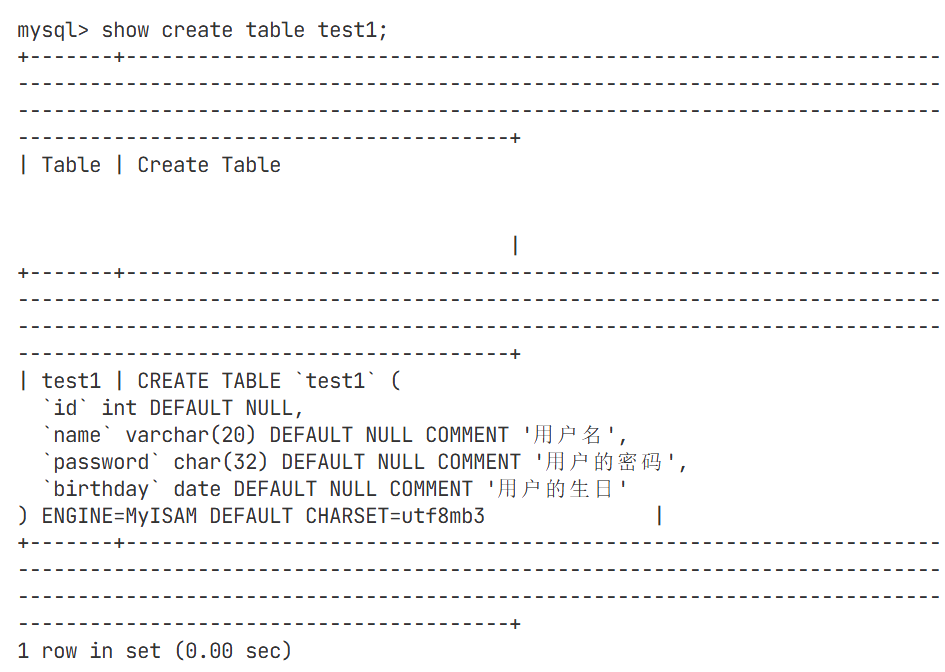
修改表
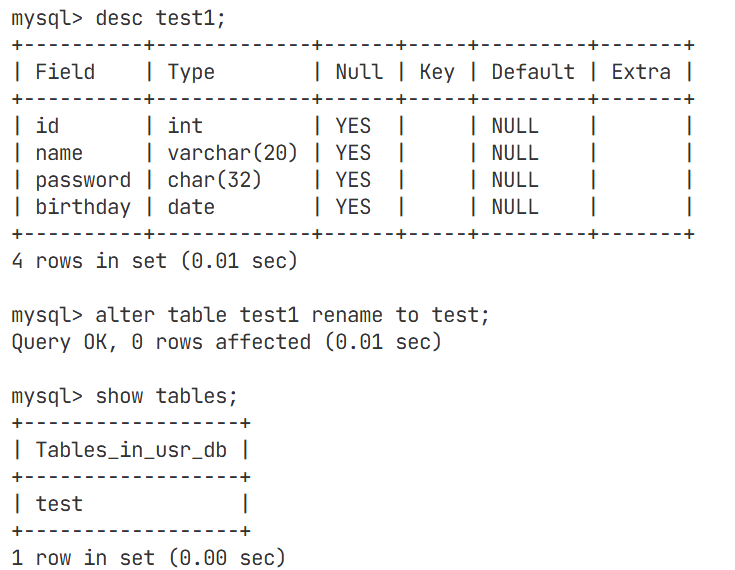
修改表的名字(此处的to可以省略)
向表中各属性插入数据,并查看数据
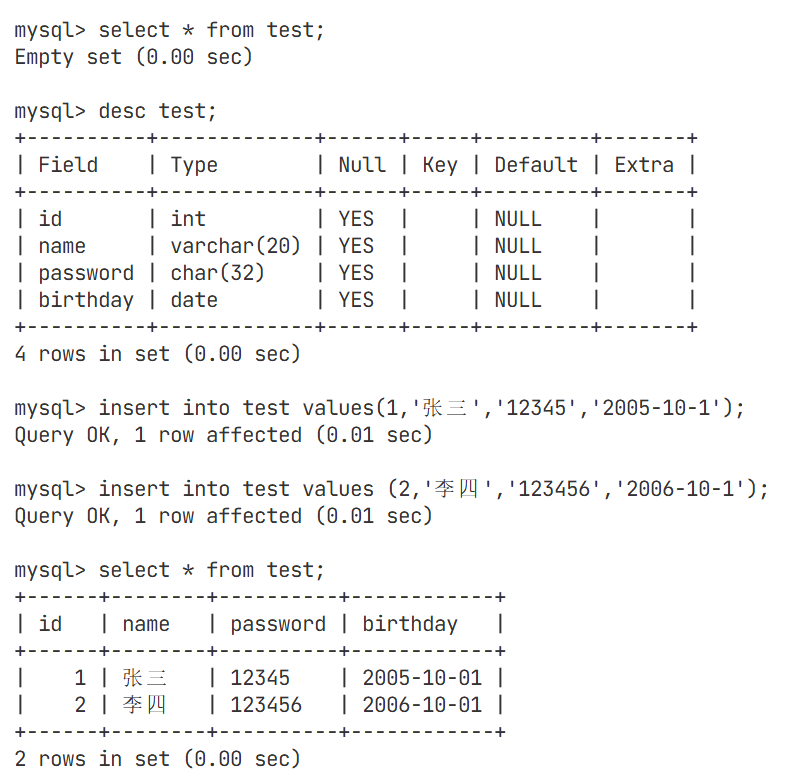
向birthday属性后面插入图像路径(image_path)属性
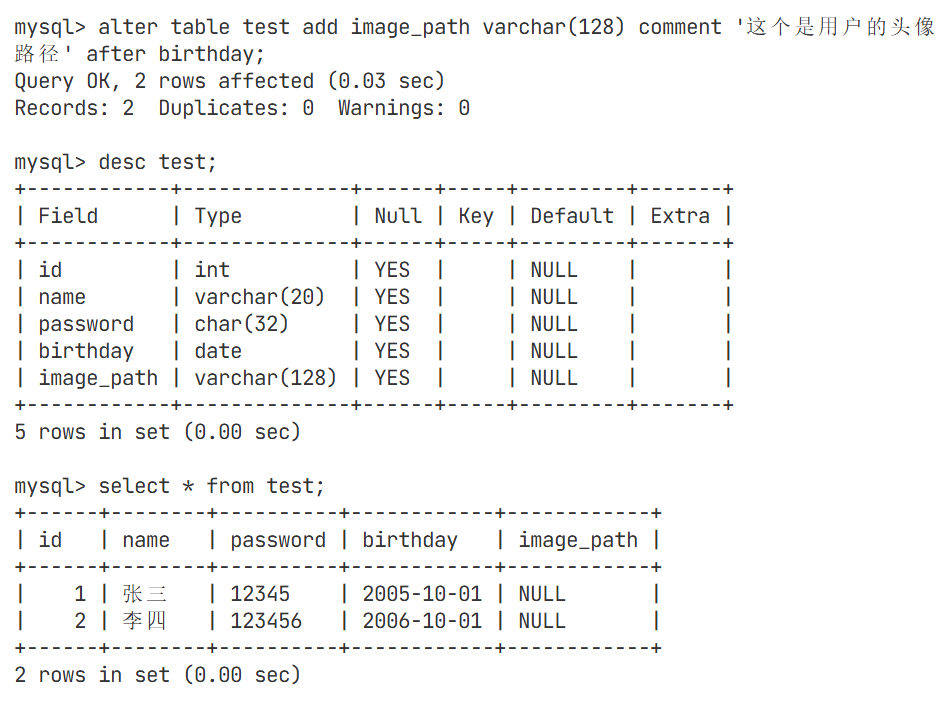
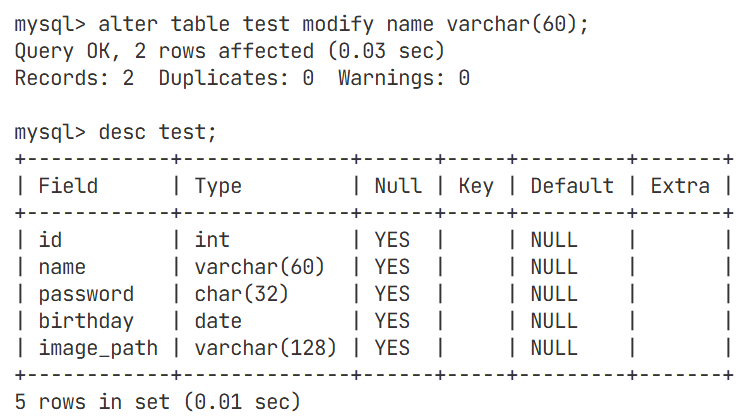
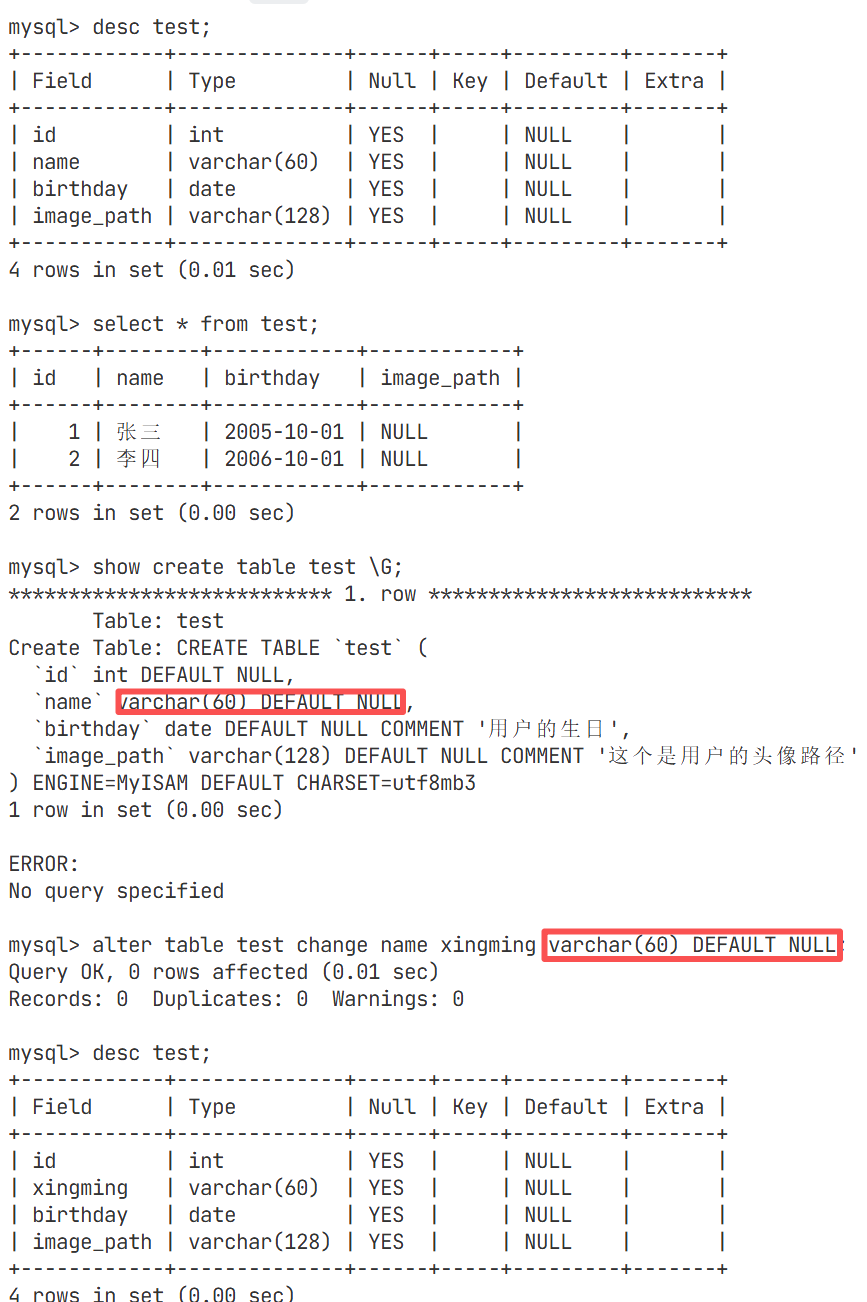
修改属性中名字的长度,从20改成60
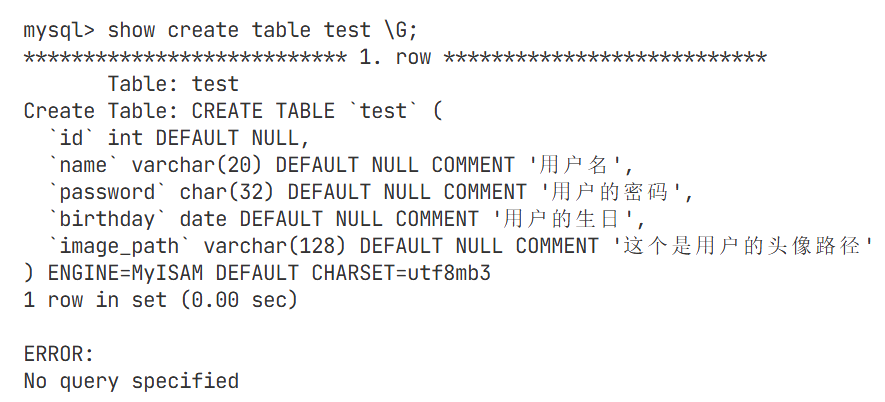
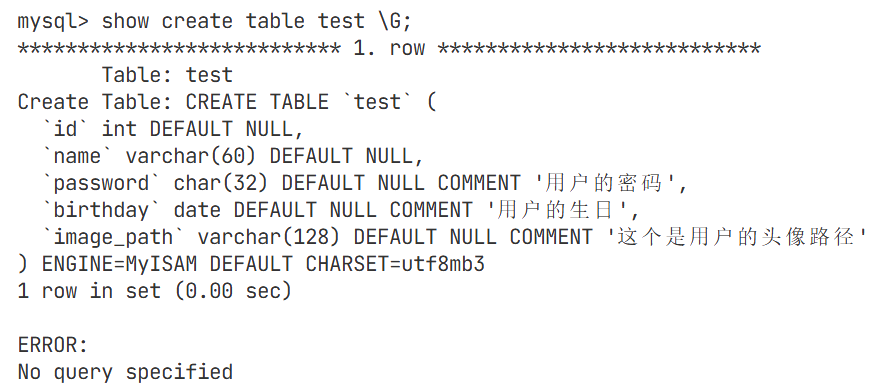
看定义name的那一行后面的comment'用户名'被直接替换掉了,去除了
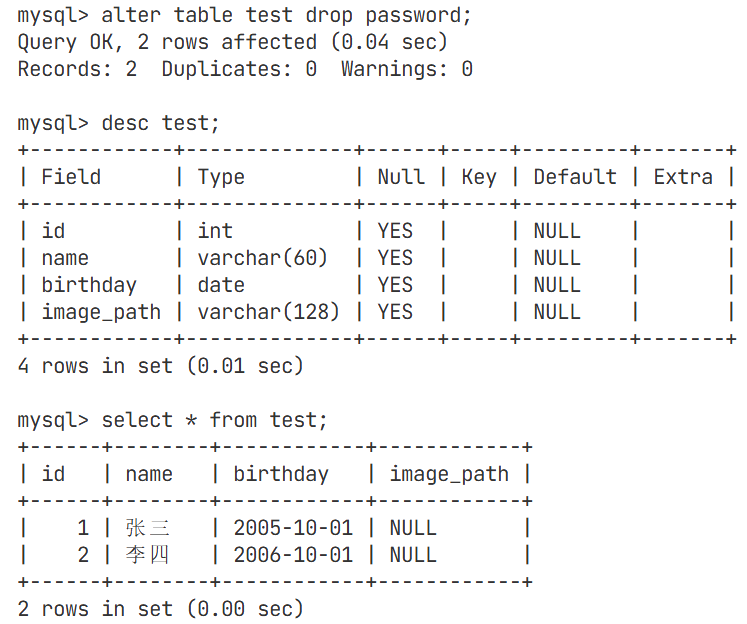
删除password属性(此处以password为例,也可以删除其他属性)
修改表中属性的名字(图中红框处的属性必须得带上)
删除表
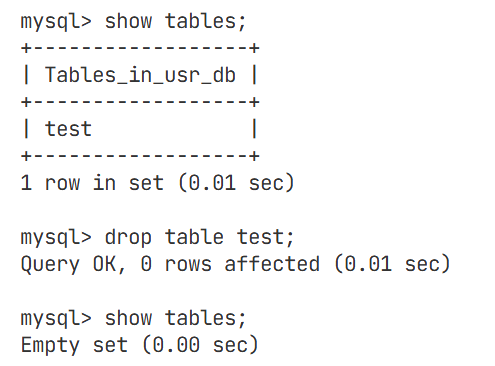
以上操作中修改表和删除表操作尽量少用,毕竟MySQL数据库在我们日常使用中是处于下层,修改或删除操作后影响的方面会很多,如上层的各种语言需要访问下层,下层一旦进行修改,上层使用到下层的各种软件也需要随着修改
数据类型

数值类型
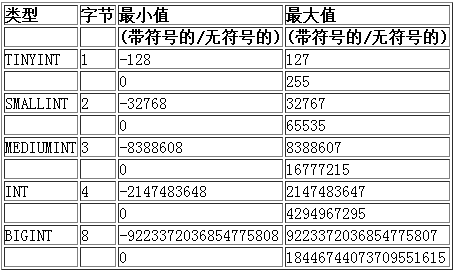
tinyint类型
例子(以tinyint为例)

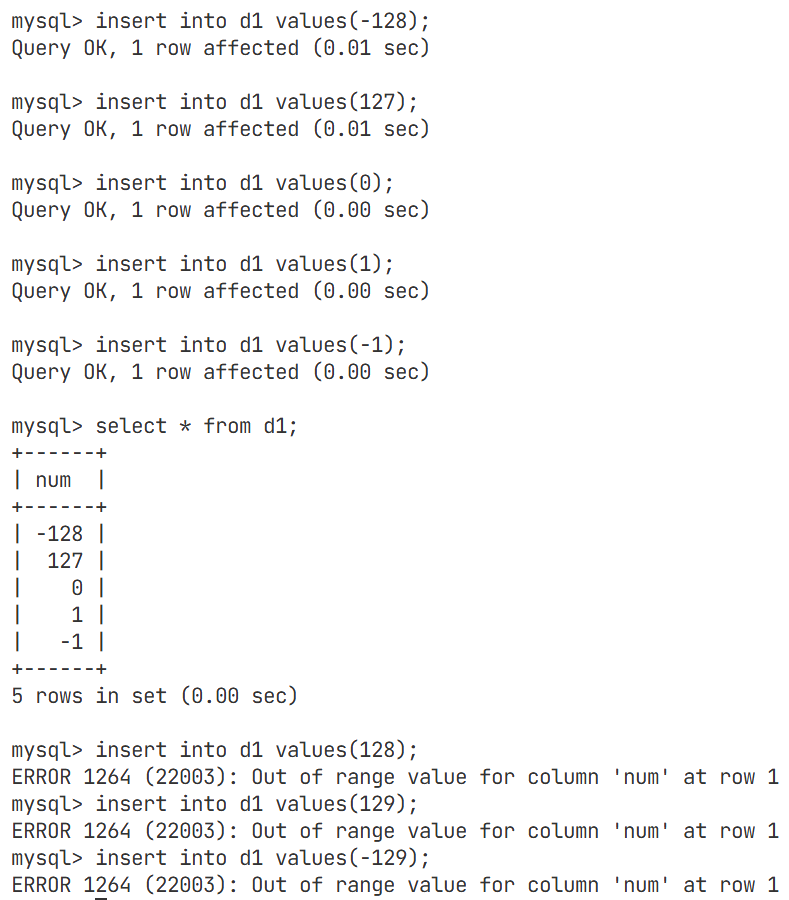
数据类型加上unsigned
如果我们向MySQL特定的类型中插入不合法的数据,MySQL一般都是直接拦截我们,不让我们做对应的操作
反过来,如果我们已经有数据被成功插入到MySQL中了,一定插入的时候是合法的
所以,MySQL中一般而言,数据类型的本身也是一种约束
约束就能倒逼使用者可能进行正确的插入,约束使用者,另外,如果你不是一个很好的使用者,MySQL也能保证数据插入的合法性,就能保证数据库中的数据是可预期,完整的
bit类型
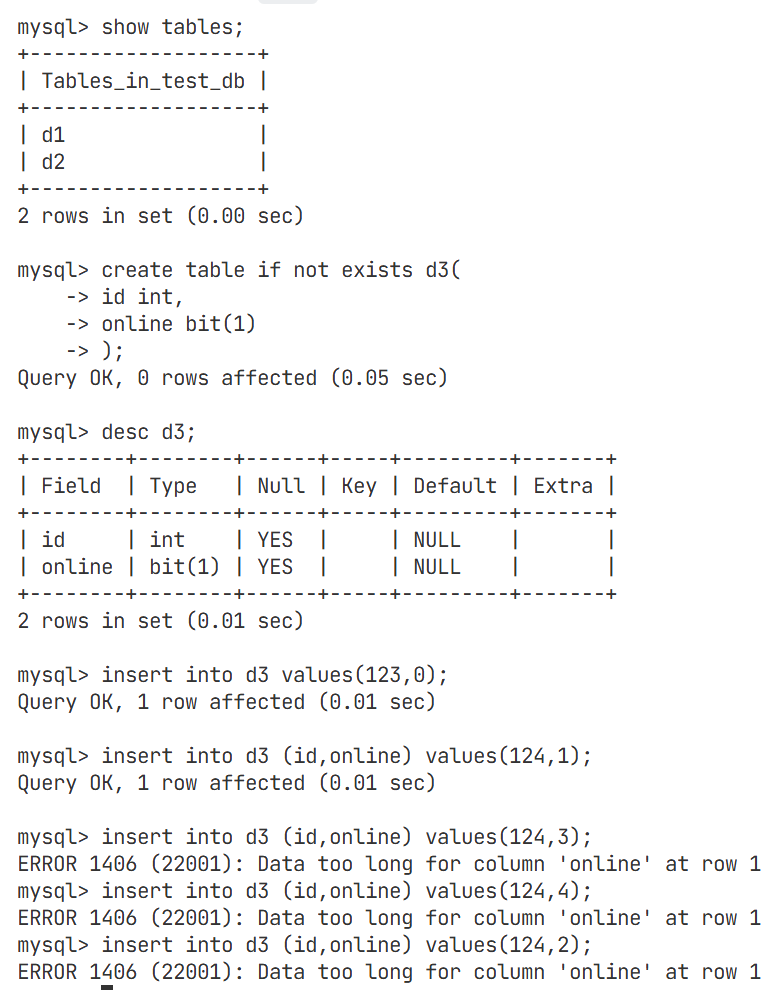
再online的位置处,因为插入的数据的数据类型为bit,所以是以ascll码值的形式存在的,是一种位图结构
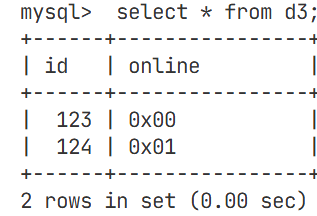
以十进制的形式产生
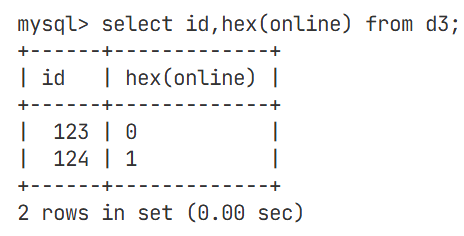
我们改一下bit类型的大小,可以更直观的看出是以ascll码值的形式存在的
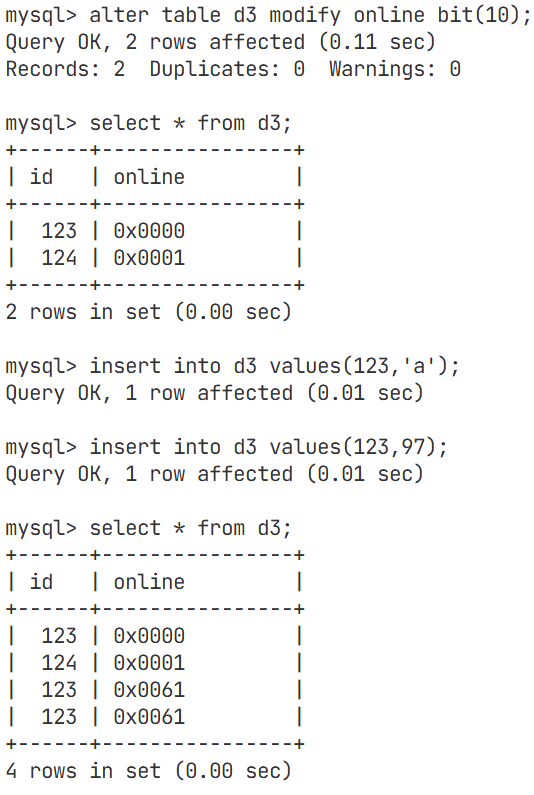
在创建表的时候,bit类型超过64也会被拦截

float类型
语法
float[(m, d)] [unsigned] : M指定显示长度,d指定小数位数,占用空间4个字节定义了一个总长度为4,精度为2的浮点类型(默认为有符号signed)
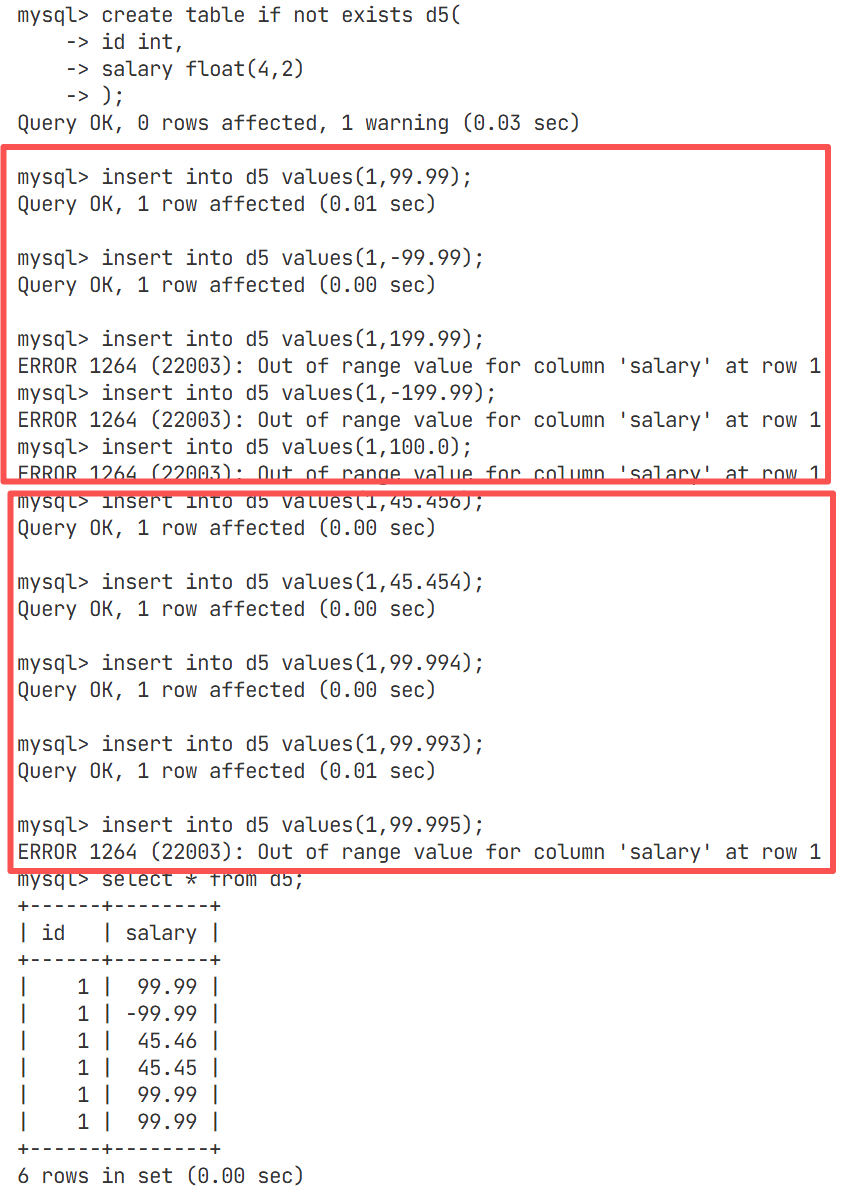
上面的红框表示所定义的浮点类型的取值范围为(-99.99至99.99),而且取值总位数为4,其他位数定义可以自行测试
下面的红框表示当小数部分超出所定义的两位精度时,会进行四舍五入
接下来我们换成无符号位(unsigned)进行测试,看看取值范围为多少


由此可以看出,float无符号位(unsigned)的取值范围位(0~99.99),当小数部分超出所定义的两位精度时,会进行四舍五入
对于浮点数,我们也需要对他的精度进行一定的测试,精度都会产生一定的偏差
我们将数据类型从变成默认的float

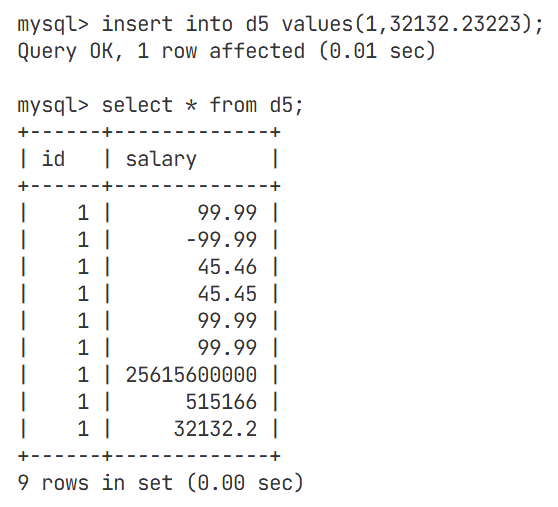
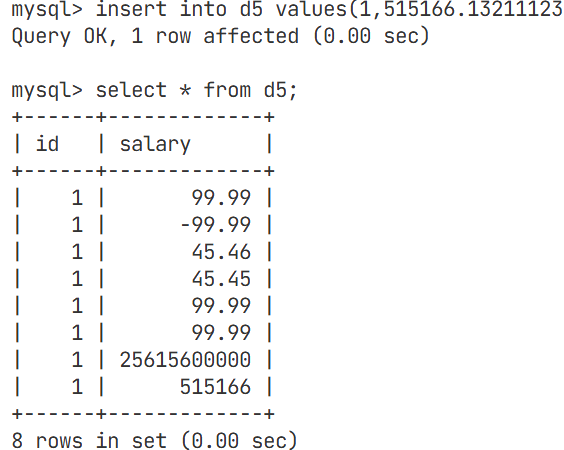
上述例子中可以看出,大一点的数据使用float类型会造成精度下降,会有精度损失
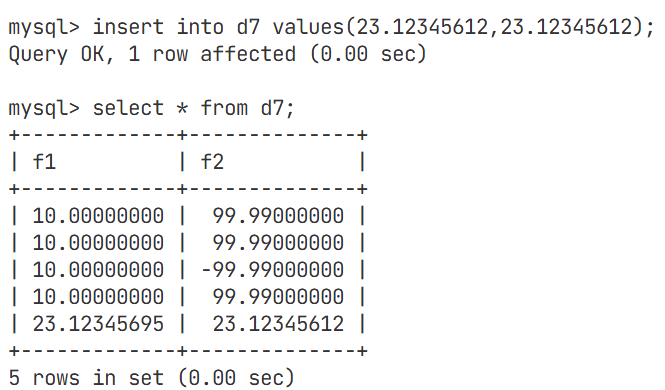
decimal类型
对于float类型会造成的精度损失,decimal能够很好地规避这一点
decimal整数最大位数m为65。支持小数最大位数d是30。如果d被省略,默认为0,如果m被省略,
默认是10
decimal(m, d) [unsigned] : 定点数m指定长度,d表示小数点的位数float的精度大约是7位,我们这里故意将其小数点的位数设置成8,观察是否能精准到8位呢?
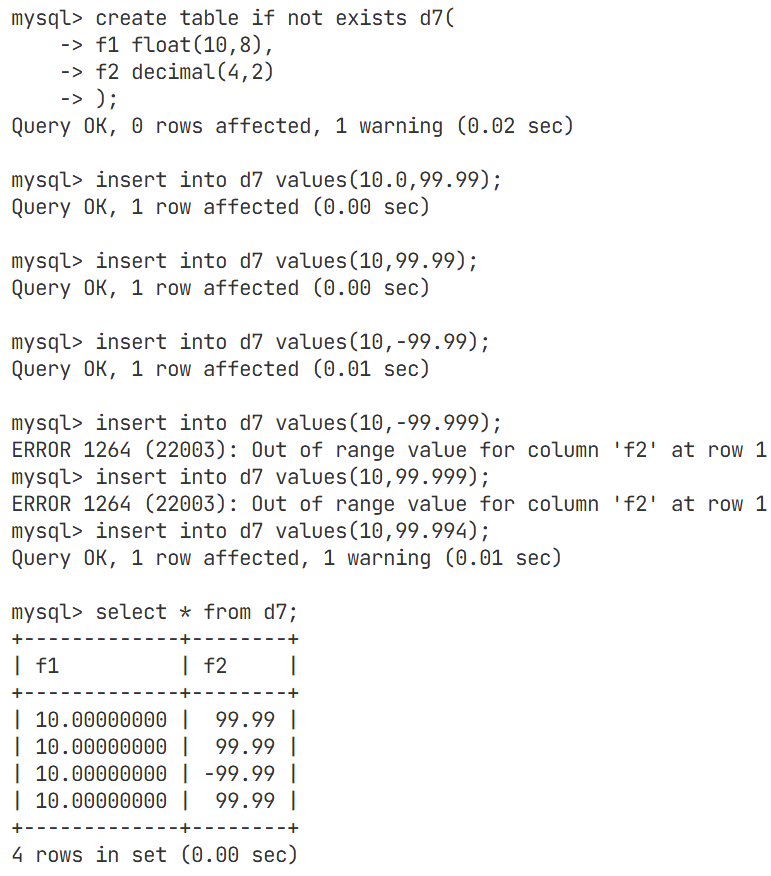
我们再将f2修改成跟f1数据类型一样
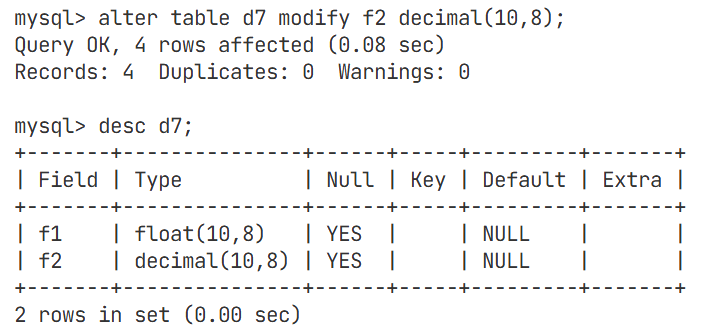
将float和decimal进行比较,发现数据大的使用decimal精度不会损失,float仍然会损失
char类型

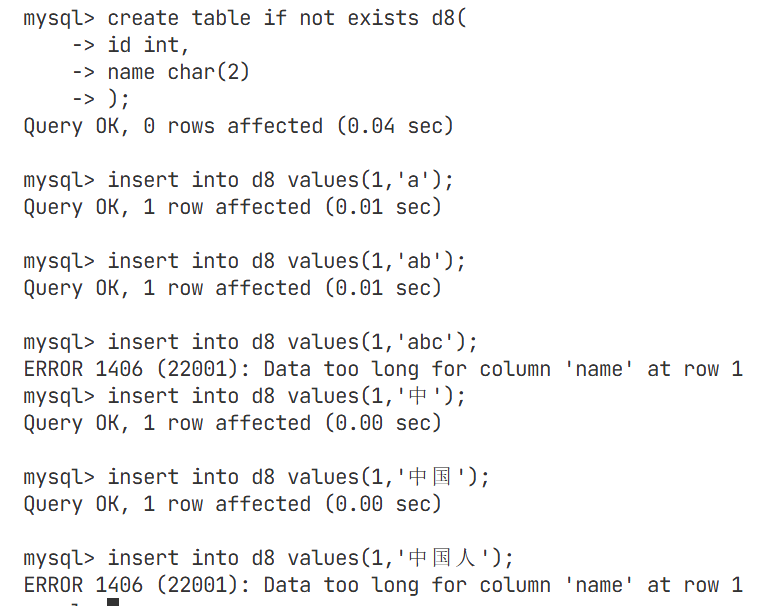
MySQL处的单位字符就真的只是单位,不同于我们C/C++语言中的字符占一个字节,utf8编码下占用3个字节,超过规定的长度,MySQL直接截断,不能插入
最大的可设置长度为255,超过也自动截断,不让你创建表
varchar类型
varchar(L): 可变长度字符串,L表示字符长度,最大长度65535个字节关于varchar(len),len到底是多大,这个len值,和表的编码密切相关:
varchar长度可以指定为0到65535之间的值,但是有1 - 3 个字节用于记录数据大小,所以说有效字节数是65532。
当我们的表的编码是utf8时,varchar(n)的参数n最大值是65532/3=21844因为utf中,一个字符占
用3个字节,如果编码是gbk,varchar(n)的参数n最大是65532/2=32766(因为gbk中,一个字符
占用2字节)。
mysql> create table tt11(name varchar(21845))charset=utf8; --验证了utf8确实是不
能超过21844
ERROR 1118 (42000): Row size too large. The maximum row size for the used
table type, not counting BLOBs, is 65535. You have to change some columns to
TEXT or BLOBs
mysql> create table tt11(name varchar(21844)) charset=utf8;
Query OK, 0 rows affected (0.01 sec)严谨的来说,最大长度为21844,而不是21845,因为varchar类型需要1~3各字节用于记录数据大小
与char相同,超过规定的长度就会产生报错
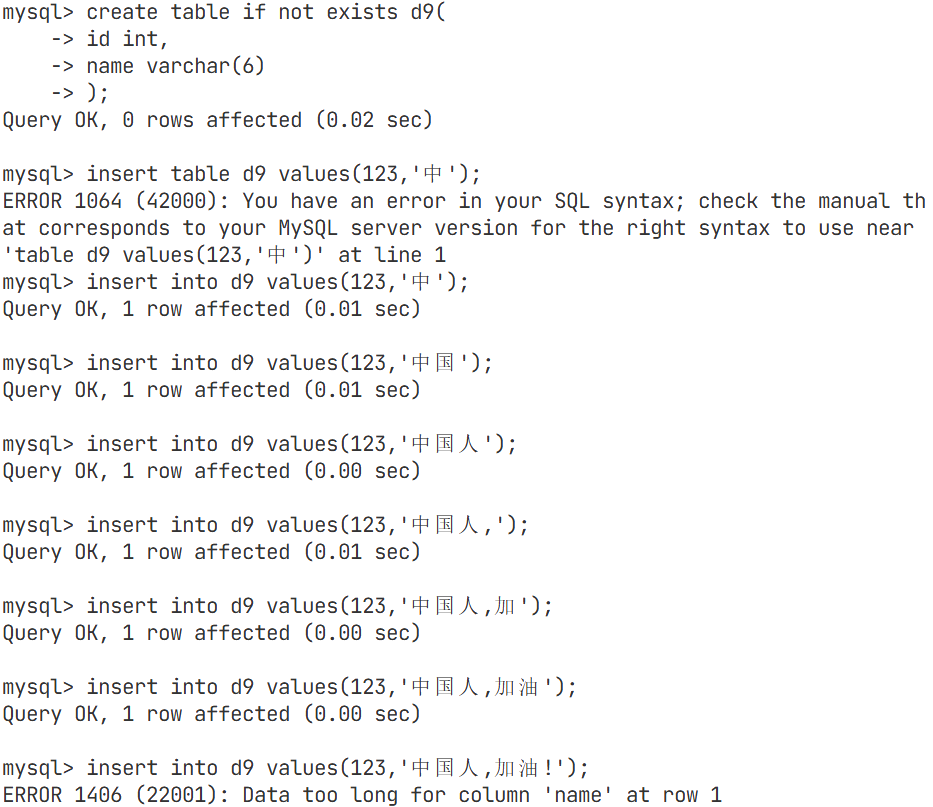
此处的max=16383的由来,是由65536除以3来的,因为此处的编码为utf8,一个字符占三个字节(varchar规定长度为65536字节)

char就相当于C/C++中的数组一般,一次空间就给定你
varchar就相当于C/C++中的string,用多少给你多少,长度需要维护,有效字符个数也需要维护

如何选择定长或变长字符串?
- 如果数据确定长度都一样,就使用定长(char),比如:身份证,手机号,md5
- 如果数据长度有变化,就使用变长(varchar), 比如:名字,地址,但是你要保证最长的能存的进去。
- 定长的磁盘空间比较浪费,但是效率高。
- 变长的磁盘空间比较节省,但是效率低。
- 定长的意义是,直接开辟好对应的空间
- 变长的意义是,在不超过自定义范围的情况下,用多少,开辟多少。
日期和时间类型

定义一个表
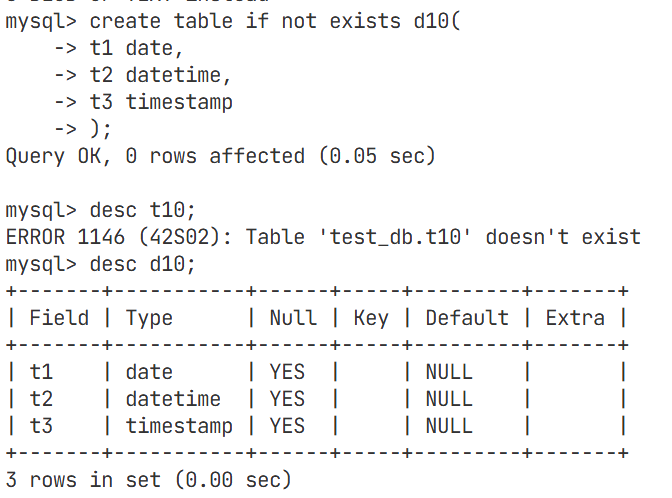

date主要用于记录生日之类的
datetime用于记录固定时间(比如进入公司的入职时间)
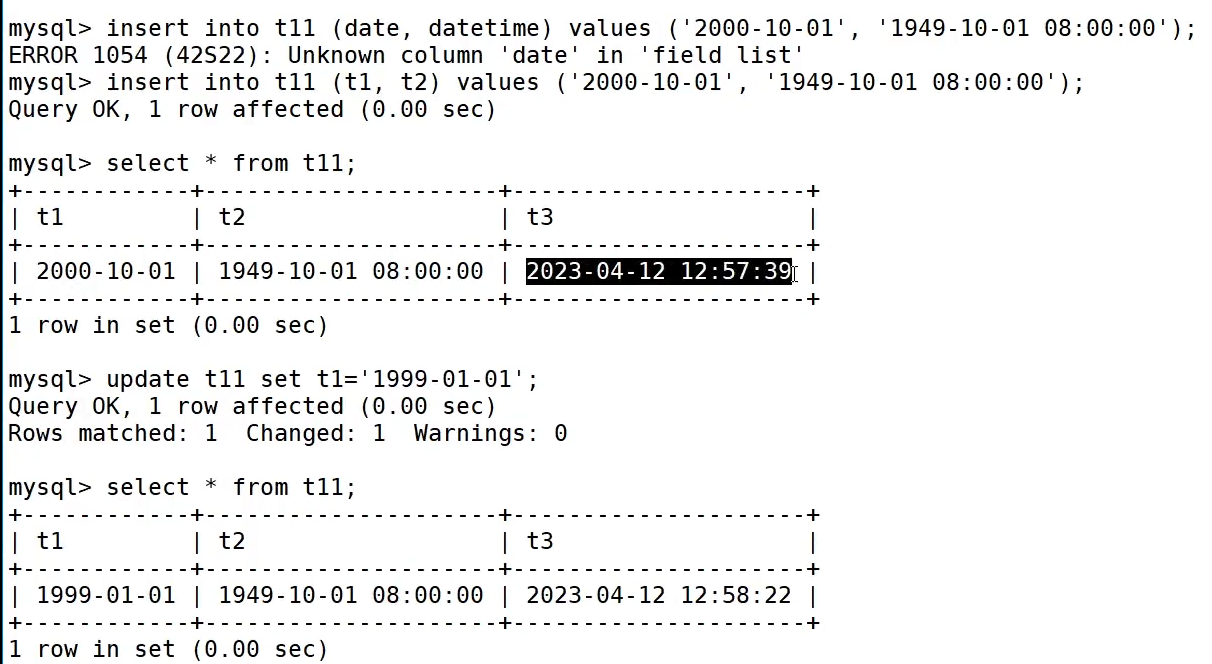
timestamp不需要我们做任何动作,会自动更新
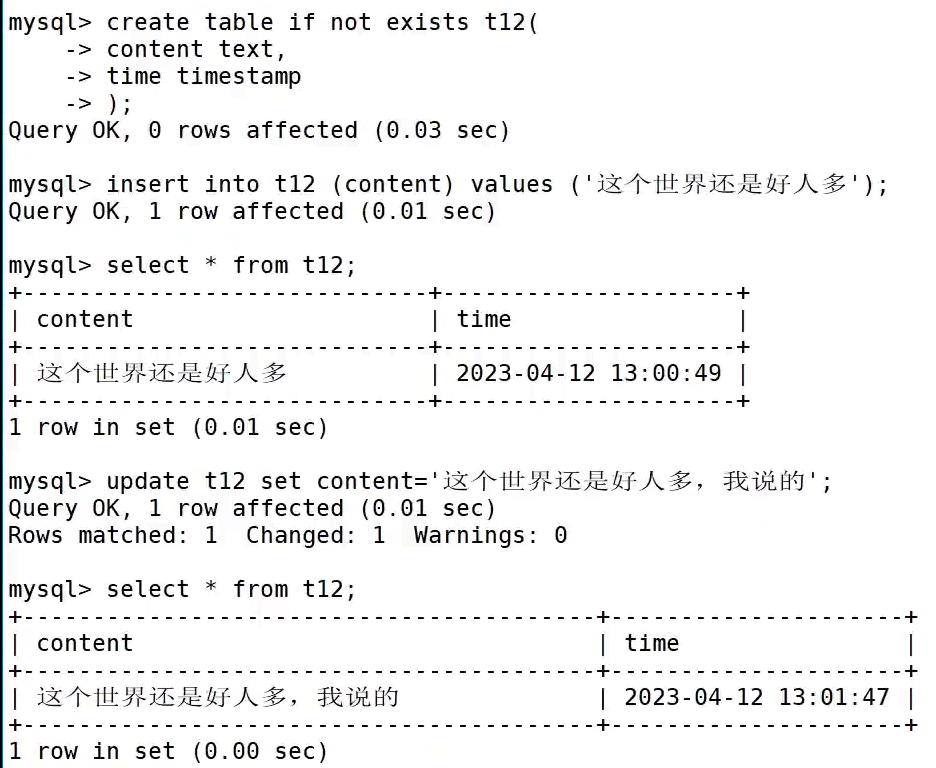
以下是用到timestamp的例子(评论)
enum和set类型


例子

NULL和' ' ,前者代表什么都没有,后者代表里面有东西但是是空串(例如发工资时前者没有相应需要的银行卡,后者有银行卡但是里面没钱)

往enum和set中插入数据的时候,enum可通过下标插入(从1开始),set相当于位图,代表比特位的位图,从右向左,从低向高,代表爱好(hobby)的从左向右

查找方式
gender是枚举类型,hobby是集合类型
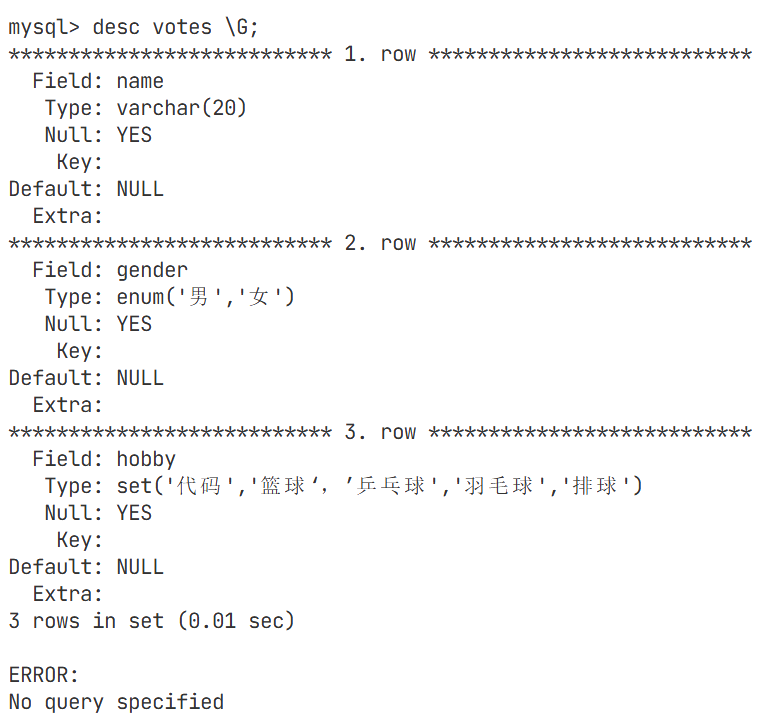

但是这样查找太过于简单,而且有很多有着多个爱好,在这里查找的条件太过于单一
MySQL中也是存在函数的
返回的是下标,即为0则为假,非0则为真
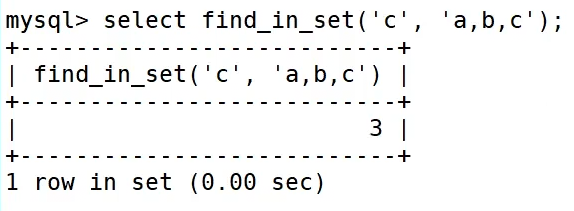
MySQL中的筛选函数(集合查询使用find_ in_ set函数)

这种查找方式是不对的,在这里我们要查找拥有着'羽毛球'和'代码'两种爱好的人(这样的人肯定还有其他爱好,就是只要有这两个爱好的人都查出来)

就应该像在写代码时一般,用且来进行连接
