边权相等(边权为1)的最短路径问题知识点整理
一、问题定义
适用场景:图中所有边的权值全部相等(最常见为权值=1的无权图),求从起点到终点的最短路径。
核心特点:这类问题不能用迪杰斯特拉(Dijkstra)算法(不是不能用,而是BFS更高效),BFS是最优解法。
二、核心原理
- BFS的天然优势
BFS(广度优先搜索)是按层遍历的:
第0层:起点本身(距离起点为0)
第1层:起点的直接邻居(距离起点为1)
第2层:邻居的邻居(距离起点为2)
...
第k层:距离起点为k的节点
因此,第一次到达目标节点时,对应的层数就是最短路径长度,无需回溯。
- 关键结论
扩展的层数 = 最短路径的长度(计数方式可根据题目要求调整,如包含起点则长度=层数+1)
时间复杂度:O(V+E)(V为节点数,E为边数),远优于Dijkstra算法在无权图上的效率。
三、解题步骤
-
预处理:用邻接表/邻接矩阵存储图结构,方便遍历邻居节点。
-
初始化:
队列queue:存储待访问的节点,用于BFS层序遍历。
访问标记集合/数组vis/hash:标记已访问的节点,避免重复访问、死循环。
距离数组/变量dist:记录每个节点到起点的最短距离,初始时起点距离为0(或1,根据计数规则)。
- BFS遍历:
起点入队,标记为已访问,初始化距离。
按层遍历:每处理完一层,距离+1。
遍历当前层每个节点的所有邻居,若未访问则入队、标记访问、更新距离。
- 终止条件:第一次访问到目标节点时,直接返回当前距离(即为最短路径长度);若遍历完所有节点仍未到达目标,则说明无路径。
四、常见误区&注意事项
- 计数方式:
若题目要求路径包含起点,则初始距离为1,每遍历一层+1;
若题目要求边数,则初始距离为0,每遍历一层+1。
-
访问标记时机:必须在入队时标记,不能在出队时标记,否则会导致同一节点多次入队,降低效率甚至死循环。
-
适用范围:仅适用于边权相等的图,若边权不相等(如带权图),需使用Dijkstra等算法。
模版代码
cpp
#include <iostream>
#include <vector>
#include <queue>
#include <unordered_set>
using namespace std;
// 图节点用 int 表示,可根据题目换成 string/坐标对等
int shortestPath(int start, int end, const vector<vector<int>>& adj) {
int n = adj.size();
vector<bool> vis(n, false); // 访问标记数组
queue<int> q;
// 初始化:起点入队,标记已访问,边数初始为0
q.push(start);
vis[start] = true;
int step = 0;
while (!q.empty()) {
int sz = q.size(); // 当前层节点数
step++; // 进入下一层,边数+1
// 遍历当前层所有节点
for (int i = 0; i < sz; i++) {
int cur = q.front();
q.pop();
// 遍历所有邻居
for (int next : adj[cur]) {
if (!vis[next]) {
// 到达终点,直接返回当前边数
if (next == end) return step;
vis[next] = true;
q.push(next);
}
}
}
}
// 遍历完仍未到达终点,无路径
return -1;
}题目1:迷宫中离入口最近的出口(LeetCode 1926)
- 题目描述

提示:
maze.length == mmaze[i].length == n1 <= m, n <= 100maze[i][j]要么是'.',要么是'+'。entrance.length == 20 <= entrancerow < m0 <= entrancecol < nentrance一定是空格子。
- 核心解法:BFS(广度优先搜索)求最短路径
1) 算法核心思路
BFS(层序遍历)是解决无权图最短路径的经典算法,原理是:
从起点开始,按「距离起点的步数」分层遍历(第1层是起点的所有相邻格子,第2层是第1层格子的相邻未访问格子,以此类推)
第一次遍历到出口时,当前的层数就是最短路径长度(因为BFS按层遍历,先到达的一定是最近的)
2)关键实现细节
(1)方向数组
用 dx、dy 数组表示上下左右4个移动方向:
int dx4 = {0, 0, 1, -1};
int dy4 = {1, -1, 0, 0};
每一组 (dxj, dyj) 代表一个方向:(0,1) → 向右 (0,-1) → 向左 (1,0) → 向下 (-1,0) → 向上
(2)访问标记数组
用 vis 数组标记已访问的格子,避免重复遍历(防止死循环,比如来回走)
初始化时将入口格子标记为已访问
(3)队列存储BFS的当前层
队列中存储 (x,y) 坐标对,代表当前待遍历的格子
每次遍历「当前队列的所有元素」(即当前层的所有格子),再处理下一层
(4)出口判断条件
遍历到新格子 (x,y) 时,判断是否满足:
if (x == 0 || x == m-1 || y == 0 || y == n-1)
return step;
只要格子在迷宫的边界(行号为0/最后一行,或列号为0/最后一列),就是出口,直接返回当前步数
cpp
class Solution
{
// 方向数组:上下左右
int dx[4] = {0, 0, 1, -1};
int dy[4] = {1, -1, 0, 0};
public:
int nearestExit(vector<vector<char>>& maze, vector<int>& e)
{
int m = maze.size(); // 迷宫行数
int n = maze[0].size(); // 迷宫列数
bool vis[m][n]; // 访问标记数组
memset(vis, 0, sizeof(vis)); // 初始化标记为未访问
queue<pair<int, int>> q; // BFS队列,存储坐标(x,y)
// 1. 初始化:将入口入队,并标记为已访问
q.push({e[0], e[1]});
vis[e[0]][e[1]] = true;
int step = 0; // 当前步数(BFS层数)
while (!q.empty()) // 队列不为空,继续遍历
{
step++; // 进入下一层,步数+1
int sz = q.size(); // 当前层的格子数量
// 遍历当前层的所有格子
for (int i = 0; i < sz; i++)
{
auto [a, b] = q.front(); // 取出队首格子坐标
q.pop();
// 尝试4个方向移动
for (int j = 0; j < 4; j++)
{
int x = a + dx[j];
int y = b + dy[j];
// 条件判断:坐标合法 + 不是墙 + 未被访问
if (x >= 0 && x < m && y >= 0 && y < n
&& maze[x][y] == '.' && !vis[x][y])
{
// 检查是否到达出口(边界格子)
if (x == 0 || x == m - 1 || y == 0 || y == n - 1)
return step;
// 不是出口,标记为已访问,加入队列,准备下一层遍历
q.push({x, y});
vis[x][y] = true;
}
}
}
}
// 遍历完所有可能的路径,未找到出口
return -1;
}
};- 知识点总结
1) BFS的适用场景
无权图/网格的最短路径问题(迷宫、地图寻路等)
按层遍历的场景(如二叉树层序遍历、岛屿数量)
状态空间搜索(如八数码问题)
2) BFS的核心优势
天然保证「第一次到达目标时的路径是最短的」,无需额外记录所有路径再比较长度
时间复杂度:O(m×n),每个格子最多被访问一次
空间复杂度:O(m×n),最坏情况下队列存储所有格子(如全是空格子)
3) 本题易错点
入口格子不算出口:即使入口在边界,也不能直接返回0,必须移动到其他格子
边界判断:出口是「边界上的空格子」,但入口所在的边界格子不算,必须移动后再判断
访问标记的时机:必须在格子入队时就标记为已访问,避免多个路径重复入队同一格子
步数计数:BFS的层数就是步数,入口所在的层步数为0,每遍历一层步数+1
题目2:最小基因变化(LeetCode 433)
- 题目描述

提示:
start.length == 8end.length == 80 <= bank.length <= 10bank[i].length == 8start、end和bank[i]仅由字符['A', 'C', 'G', 'T']组成
- 核心算法思路
如果将「每次字符串的变换」抽象成图中的「两个顶点和一条边(边权为1)」,那么问题就转化为:
求从 start 节点到 end 节点的最短路径问题。
这类边权为1的最短路径问题,最适合用广度优先搜索(BFS)解决,因为BFS天然具备"按层遍历"的特性,第一次到达目标节点时,经过的层数就是最少变化次数。
cpp
class Solution
{
public:
int minMutation(string startGene, string endGene, vector<string>& bank)
{
// 1. 初始化数据结构
unordered_set<string> vis; // 记录已经搜索过的基因序列,避免重复访问(防死循环)
unordered_set<string> hash(bank.begin(), bank.end()); // 将bank存入哈希表,快速判断序列是否有效
string change = "ACGT"; // 基因序列的所有可能字符,用于生成所有可能的变化
// 2. 边界情况处理
if(startGene == endGene) return 0; // 起点和终点相同,无需变化
if(!hash.count(endGene)) return -1; // 终点不在基因库中,直接无法完成变化
// 3. BFS初始化:队列存储当前层的所有基因序列
queue<string> q;
q.push(startGene);
vis.insert(startGene);
int ret = 0; // 记录变化次数(BFS的层数)
// 4. BFS主循环
while(q.size())
{
ret++; // 进入下一层,变化次数+1
int sz = q.size(); // 当前层的节点数量(需要遍历完当前层再进入下一层)
while(sz--)
{
string t = q.front(); // 取出当前层的一个基因序列
q.pop();
// 遍历序列的每一个位置(共8个字符)
for(int i = 0; i < 8; i++)
{
string tmp = t; // 复制当前序列,避免修改原序列(细节问题)
// 遍历所有可能的替换字符(A/C/G/T)
for(int j = 0; j < 4; j++)
{
tmp[i] = change[j]; // 将第i位替换为change[j]
// 检查条件:新序列在基因库中,且未被访问过
if(hash.count(tmp) && !vis.count(tmp))
{
if(tmp == endGene) return ret; // 找到终点,直接返回当前层数(最少次数)
q.push(tmp); // 加入队列,进入下一层遍历
vis.insert(tmp); // 标记为已访问
}
}
}
}
}
// 遍历完所有可能仍未找到终点,返回-1
return -1;
}
};- 关键知识点拆解
1) BFS 为什么适合解决"最少变化次数"问题?
BFS 是按层遍历的:第0层是start(0次变化),第1层是所有1次变化的序列,第2层是所有2次变化的序列......
第一次到达end时,当前的层数就是最少变化次数,因为BFS不会"绕路",找到的第一条路径就是最短的。
2) 为什么需要两个哈希表?
hash(存储bank):快速判断一个序列是否是"有效序列"(O(1)时间复杂度),避免每次都遍历bank数组(O(n))。
vis(已访问序列):避免重复访问同一个序列,否则会出现循环(比如A→B→A),导致死循环和超时。
3) 如何生成所有"一次变化"的序列?
对当前序列的每一位字符,尝试替换成A/C/G/T中的其他3个字符,共 8 × 4 = 32 种可能的变化(包含和原字符相同的情况,会被后续的!vis.count(tmp)过滤掉)。
4) 边界情况的处理
start == end:直接返回0,无需变化。
end不在bank中:直接返回-1,因为任何有效的变化都必须以bank中的序列为中间状态,终点不在bank中则无法完成。
- 易错点总结
1) 忘记标记已访问:会导致序列被反复加入队列,造成死循环或超时。
2) 修改原序列t:代码中用tmp = t复制序列,是为了避免修改当前层的原序列,影响后续遍历。tmp 就是为了保证每次修改都只改一位,且不污染原始的当前序列,确保BFS中生成的所有邻居节点都是"合法的一次变化"。如果没有tmp,内层循环修改 t 后,会影响后续的外层循环(i 增加时),导致生成的所有变化都基于"被修改过的 t",而不是"原始的当前序列",最终生成的变化序列完全错误。
3) 未检查end是否在bank中:如果终点不在bank中,无论如何都无法完成变化,直接返回-1即可,避免无效搜索。
4) BFS层数计数错误:必须先遍历完当前层的所有节点,再将层数+1,否则会出现计数偏差。
题目3:单词接龙(LeetCode 127)
- 题目描述

wordList中的所有字符串 互不相同
- BFS 算法思路详解
1) 核心原理
这道题本质上是无权图的最短路径问题:每个单词是图的一个节点;两个单词若只差一个字母,则它们之间有一条边;我们需要找从 beginWord 到 endWord 的最短路径,BFS 是这类问题的最优解(天然保证第一次到达目标节点时路径最短)
2) 关键实现细节
(1)字典与访问标记
用 unordered_set<string> hash 存储 wordList,O(1) 时间判断单词是否合法
用 unordered_set<string> vis 标记已访问的单词,避免重复遍历(防止死循环)
(2)队列与层序遍历
队列存储当前层的所有单词,每一层代表一次转换
用 ret 记录序列长度,初始值为 1(包含 beginWord),每遍历一层长度+1
(3)单词生成方式
对当前单词的每个位置,尝试替换为 a-z 中的其他字母,生成所有可能的下一个单词
例如单词 hit,第0位替换可生成 ait, bit, ..., zit;第1位替换可生成 hat, hbt, ..., hzt,以此类推
cpp
class Solution
{
public:
int ladderLength(string beginWord, string endWord, vector<string>& wordList)
{
// 1. 把单词列表存入哈希集合,方便O(1)判断单词是否在字典中
unordered_set<string> hash(wordList.begin(), wordList.end());
// 2. 访问标记集合,避免重复访问同一个单词(防止死循环、重复入队)
unordered_set<string> vis;
// 3. 边界判断:如果目标单词根本不在字典里,直接返回0,无法完成转换
if (!hash.count(endWord)) return 0;
// 4. BFS队列,用于按层存储待探索的单词
queue<string> q;
// 初始化:把起始单词入队,并标记为已访问
q.push(beginWord);
vis.insert(beginWord);
// 记录最短序列的长度,初始为1(序列包含beginWord本身)
int ret = 1;
// 当队列不为空时,继续BFS层序遍历
while (!q.empty())
{
// 进入下一层,序列长度+1(代表又多了一步转换)
ret++;
// 当前层的单词数量(必须提前记录,因为队列大小会动态变化)
int sz = q.size();
// 遍历当前层的所有单词
while (sz--)
{
// 取出队首单词(当前层的一个节点)
string t = q.front();
q.pop();
// 遍历单词的每一个字符位置,尝试修改它
for (int i = 0; i < t.size(); i++)
{
// 每次修改前先复制原单词,避免修改原单词影响后续循环
string tmp = t;
// 尝试用a-z替换当前位置的字符,生成所有可能的新单词
for (char ch = 'a'; ch <= 'z'; ch++)
{
tmp[i] = ch;
// 条件判断:
// 1. 新单词必须在字典中(hash.count(tmp))
// 2. 新单词必须未被访问过(!vis.count(tmp))
if (hash.count(tmp) && !vis.count(tmp))
{
// 如果新单词就是目标单词,直接返回当前序列长度ret
// 因为BFS是层序遍历,第一次到达endWord就是最短路径
if (tmp == endWord) return ret;
// 不是目标单词:入队,标记为已访问,等待下一层遍历
q.push(tmp);
vis.insert(tmp);
}
}
}
}
}
// 遍历完所有可能的转换路径,仍未找到endWord,返回0
return 0;
}
};- 关键知识点与易错点
1) BFS 层序遍历的核心作用
每一层代表一次单词转换,ret 记录的层数就是最短序列长度
第一次遇到 endWord 时,当前的 ret 就是最短长度,无需继续遍历
2) 单词生成的优化
对每个字符位置遍历 a-z,而不是和字典中所有单词比较,时间复杂度从 O(NL) 优化为 O(26L)(L为单词长度)
替换后记得恢复原字符,避免影响后续位置的遍历
3) 易错点提醒
endWord 不在字典中:必须提前判断,否则会返回错误结果
访问标记时机:单词入队时就标记为已访问,避免多个路径重复入队同一单词
序列长度计数:初始值为 1(包含 beginWord),每处理一层再+1,不要少算或多算
字符替换恢复:遍历完一个字符位置后,要恢复原字符,否则会生成错误的单词
- 拓展与优化思路
1) 双向 BFS 优化
从 beginWord 和 endWord 同时开始 BFS,相遇时就是最短路径
大幅减少搜索空间,时间复杂度从 O(N) 降低到 O(√N),适合字典规模大的场景
2) 时间复杂度分析
每个单词最多被访问一次,每个单词生成 26*L 个可能的新单词
时间复杂度:O(N * L * 26),N 为字典单词数,L 为单词长度
空间复杂度:O(N),队列和哈希集合的空间开销
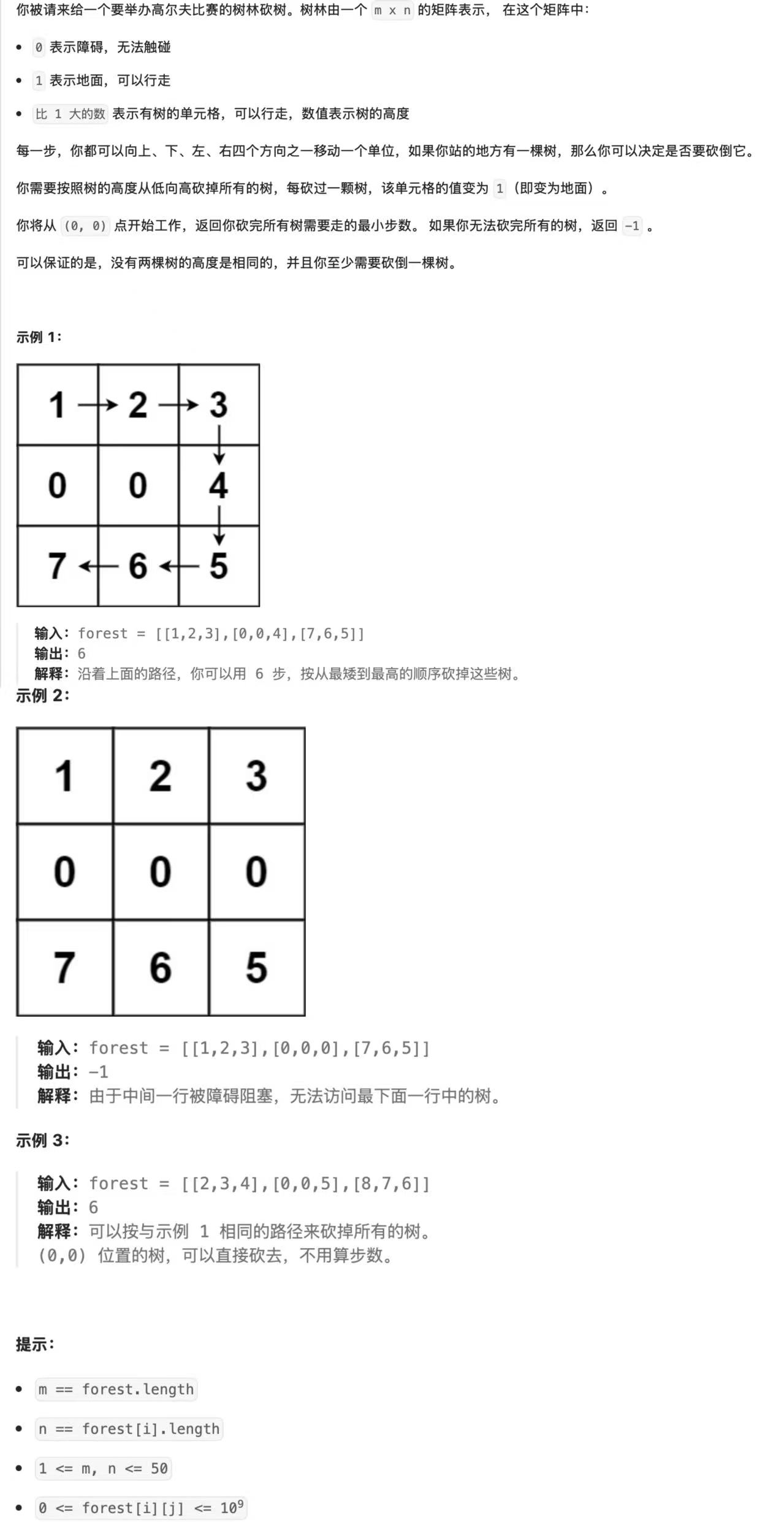
题目4:为高尔夫比赛砍树(LeetCode 675)
- 题目描述
- 核心算法思路
整体逻辑
1) 预处理:确定砍树顺序
遍历矩阵,收集所有树(值>1)的坐标。
按树的高度从小到大排序,得到必须遵守的砍树顺序。
2) 分段BFS求最短路径
从起点 (0,0) 出发,按排序后的顺序,依次用BFS求出从当前位置到下一棵树的最短路径。
若任意一段路径无法到达,直接返回 -1;否则累加所有路径的步数,即为总最少步数。
为什么用BFS?
BFS天然适合求网格中无权图的最短路径,因为它按层遍历,第一次到达目标节点时的步数就是最短路径长度。
每一段路径都是独立的,用BFS分段求解,既保证了每一步的最优性,也符合题目"按顺序砍树"的约束。
cpp
class Solution
{
int m, n;
bool vis[51][51]; // 标记访问状态(网格最大50×50)
// 上下左右四个方向偏移量
int dx[4] = {0, 0, 1, -1};
int dy[4] = {1, -1, 0, 0};
// BFS:求从(bx,by)到(ex,ey)的最短路径,无法到达返回-1
int bfs(vector<vector<int>>& f, int bx, int by, int ex, int ey)
{
// 起点就是终点,无需移动
if(bx == ex && by == ey) return 0;
queue<pair<int, int>> q;
memset(vis, 0, sizeof(vis)); // 每次BFS前清空访问标记
q.push({bx, by});
vis[bx][by] = true;
int step = 0;
while(!q.empty())
{
step++; // 进入下一层,步数+1
int sz = q.size();
// 遍历当前层所有节点
while(sz--)
{
auto [a, b] = q.front();
q.pop();
// 尝试四个方向移动
for(int i = 0; i < 4; i++)
{
int x = a + dx[i];
int y = b + dy[i];
// 边界检查 + 不是障碍 + 未访问过
if(x >= 0 && x < m && y >= 0 && y < n && f[x][y] && !vis[x][y])
{
// 到达目标树的位置,返回当前步数
if(x == ex && y == ey) return step;
q.push({x, y});
vis[x][y] = true;
}
}
}
}
// 遍历完仍未到达,说明无法到达
return -1;
}
public:
int cutOffTree(vector<vector<int>>& forest)
{
m = forest.size();
n = forest[0].size();
// 1. 收集所有树的坐标
vector<pair<int, int>> trees;
for(int i = 0; i < m; i++)
{
for(int j = 0; j < n; j++)
{
if(forest[i][j] > 1)
trees.push_back({i, j});
}
}
// 2. 按树的高度从小到大排序
sort(trees.begin(), trees.end(), [&](const pair<int, int>& p1, const pair<int, int>& p2)
{
return forest[p1.first][p1.second] < forest[p2.first][p2.second];
});
// 3. 按顺序砍树,累加每段路径的步数
int bx = 0, by = 0; // 当前位置,初始为(0,0)
int ret = 0;
for(auto& [a, b] : trees)
{
int step = bfs(forest, bx, by, a, b);
if(step == -1) return -1; // 任意一段无法到达,直接返回-1
ret += step;
bx = a, by = b; // 更新当前位置为刚砍完的树的位置
}
return ret;
}
};- 关键知识点拆解
1) 排序砍树顺序的必要性
题目强制要求"按树的高度从低到高砍树",所以必须先把所有树按高度排序,后续的BFS必须严格按照这个顺序执行,否则就不符合题目规则。
2) 分段BFS的优势
每一段BFS只负责从"当前位置"到"下一棵树"的最短路径,逻辑清晰,避免了一次性全局搜索的复杂度。
每一段BFS都是独立的,每次都清空vis数组,不会受到之前路径的影响,保证了每一步的正确性。
3) 边界与有效性检查
移动时必须检查:x和y是否在网格内、forestxy是否不为0(不是障碍)、visxy是否为false(未访问过)。
起点和终点相同的情况(如(0,0)本身就是树),直接返回0,避免不必要的BFS。
4) 理解sort和lambda
为什么这里一定要 sort?题目有一个硬性规则:必须按照树的高度 从低到高 砍树,不能乱序。比如你有3棵树,高度分别是 5、3、7,你必须先砍 3,再砍 5,最后砍 7,否则不符合题目要求。所以,我们必须先把所有树的坐标,按照它们的高度排好序,这样后面BFS的时候,才能按顺序"从这棵树走到下一棵树",保证砍树顺序正确。
cpp
sort(trees.begin(), trees.end(), [&](const pair<int, int>& p1, const pair<int, int>& p2)
{
return forest[p1.first][p1.second] < forest[p2.first][p2.second];
});我们拆成三部分理解:
- 排序的对象:trees 是什么?前面我们收集了所有树的坐标:
cpp
vector<pair<int, int>> trees;
for(int i = 0; i < m; i++)
for(int j = 0; j < n; j++)
if(forest[i][j] > 1)
trees.push_back({i, j});trees 里存的是 (行号, 列号),比如 (0,1) 代表第0行第1列的那棵树。但我们不知道这些树的高度顺序,所以需要排序。
- 排序的规则:lambda 表达式 \& (...) { ... }
sort 函数的第三个参数,是一个比较函数,用来告诉它"怎么比两个元素的大小"。
这里的 lambda 表达式就是这个比较函数:
\&(const pair<int, int>& p1, const pair<int, int>& p2)
{
return forestp1.firstp1.second < forestp2.firstp2.second;
}
p1 和 p2 是 trees 里的两个元素(两个树的坐标)
forestp1.firstp1.second:根据坐标 p1,拿到这棵树的高度
forestp2.firstp2.second:根据坐标 p2,拿到另一棵树的高度
return 高度1 < 高度2:告诉 sort,按高度从小到大排
举个例子: p1 = (0,1),forest01 = 2; p2 = (0,2),forest02 = 3; 比较时 2 < 3,返回 true,所以 p1 会排在 p2 前面。
- \& 是什么意思?
这是 lambda 表达式的捕获列表:\& 表示"以引用方式捕获当前作用域的所有变量",所以 lambda 里可以直接用 forest 这个外部变量。这里我们需要用 forest 来获取树的高度,所以必须捕获它。
- 换一种写法,如果不用 lambda,我们可以写一个单独的比较函数,效果完全一样:
cpp
// 定义一个全局变量(或者用类成员变量)存储forest
vector<vector<int>> f;
bool compare(const pair<int, int>& p1, const pair<int, int>& p2)
{
return f[p1.first][p1.second] < f[p2.first][p2.second];
}
// 在函数里调用:
sort(trees.begin(), trees.end(), compare);lambda 只是把这个比较函数"内联"写在了 sort 里,更简洁而已。
-
总结:trees 存的是所有树的坐标,但顺序是乱的。sort 用 lambda 作为比较函数,按树的高度从小到大给这些坐标排序。排序后的 trees 顺序,就是题目要求的砍树顺序,后面BFS按这个顺序走,才能得到正确结果。
-
易错点与优化
常见易错点
1) 忘记清空vis数组:每次BFS前必须用memset(vis, 0, sizeof(vis))清空,否则上一次BFS的访问标记会影响本次搜索,导致错误。
2) 排序规则错误:必须按forestij的大小排序,而不是按坐标排序,否则砍树顺序不符合题目要求。
3.) 步数计数错误:BFS中step++必须在遍历当前层之前,否则会少算一步或多算一步。
优化方向
本题中m和n最大为50,树的数量最多为50×50=2500,每段BFS的时间复杂度为O(mn),整体时间复杂度为O(k×mn)(k为树的数量),对于题目数据来说是可接受的。
若数据规模更大,可以考虑双向BFS优化,进一步降低时间复杂度。