如果你是科研人,平时要做测序分析、基因筛选、文献挖掘,一定有过这样的困扰:数据太杂、实验思路卡壳、复杂问题熬几周都没头绪。而现在,Anthropic于2026年4月29日发布的重磅测评报告显示,Claude模型不仅能搞定常规科研任务,还能破解人类专家组都解不出的难题,直接帮科研人省时间、破瓶颈。
今天就用最通俗的话,把这份硬核报告拆给你,不管是刚入门的科研小白,还是深耕领域的老手,都能get到实用价值,看完说不定能打开你的科研新思路。
0 先搞懂:为什么要做这次测评?
我们都知道,AI越来越多地走进实验室------帮写代码、提假设、分析数据,但大家心里一直有个疑问:AI的科研能力,到底能不能信?能不能真正帮上忙?
其实科研界早就有过很多AI测评,比如MMLU-Pro (测专家级知识推理)、GPQA (测研究生级难题)、LAB-Bench(测生物学专项能力),还有贴合工作流的BLADE、BixBench、SciGym等,但这些测评都有明显短板:要么太简单,只考理论知识,测不出真实水平;要么太脱离实际,用模拟数据,就算AI考得好,用到真实实验里还是抓瞎。
更关键的是,生物学研究本身就有三大特性,让传统测评难以适配:一是没有唯一标准答案 ,同一个问题,不同专家因背景、资源不同,解题思路截然不同;二是生物数据又杂又乱 ,细微的分析决策差异,可能导致完全相反的结论;三是存在大量人类至今都没破解的难题,传统测评根本没法考AI的突破能力。
所以,Anthropic专门研发了一个全新的测评基准------BioMysteryBench ,核心就是要解决这些痛点,真实测试AI的科研实力,看看它到底能不能适配真实的生物信息学研究。
1 重点:BioMysteryBench到底测了什么?
这个测评和以前的都不一样,核心就是"真实、实用、硬核",总结下来有4个关键点,一看就懂:
1. 题库够真实:99道题,全是科研人日常会遇到的任务
测评题由领域专家设计,一共99道,覆盖了生物信息学的核心场景------比如单细胞测序数据分析、基因敲除验证、全基因组亲属关系判定、染色质免疫共沉淀实验分析、蛋白质组和代谢组分析等,全是我们平时做实验会碰到的真实问题。
举几个具体题目,你一看就有共鸣:
-
这份单细胞RNA测序数据,来自人体哪个器官?
-
对比实验组和对照组,哪个基因被敲除了?
-
从全基因组测序数据里,找出某个样本的父母样本?
-
根据H3K27ac测序峰值数据,鉴定未知细胞类型?
而且这些题目都用的是真实的科研数据,和我们实验室里拿到的原始数据一样,有噪声、有干扰,完全还原真实科研场景。更严谨的是,每道题都附带验证脚本,确保数据中存在有效分析信号,避免出现"无解题目"。
2. 规则够灵活:不限解题方法,只要结论对就得分
和我们平时做科研一样,这个测评不"死板"------不规定你必须用什么方法、什么工具,测试中Claude可使用基础生物信息学工具,还能通过pip、conda安装软件,访问NCBI、Ensembl等权威数据库下载资源,只要能得出正确结论,不管是用代码分析、数据库检索,还是用AI自己的思路,都算合格。
这特别贴合真实科研:毕竟科研没有"唯一正确的方法",有的专家擅长用算法,有的擅长用实验验证,AI也可以有自己的创新思路,只要能解决问题,就是好方法。
3. 答案够客观:基于数据特征,摒弃主观结论
测评题的答案不依赖任何科研人员的主观判断,全部来自数据本身的固有特征,或是经过PCR等实验交叉验证的元数据,确保有唯一客观真实值。比如"该晶体结构对应何种生物""患者感染的病毒类型",都是可直接验证的客观答案,避免了传统测评中"主观结论偏差"的问题。
4. 难度够硬核:包含23道人类专家解不出的难题
最厉害的一点是,这个测评里有23道题,人类专家组反复尝试,都没能得出正确答案------不是题目出错了,而是这些问题本身就超出了当前人类的科研认知,但它们有明确的客观答案(基于数据特征)。这些题目经过多轮质控,剔除了题干缺陷、数据无效等问题,确保是"人类可理论破解但当前无法实现"的难题。
而这,正是AI的优势所在:它能凭借海量的文献储备和独特的分析逻辑,破解人类暂时无法突破的难题。
2 核心结果:Claude的表现,到底有多惊艳?
测评结果一出来,连科研专家都很意外------Claude的表现,远超预期,而且不同版本的模型呈现出明显的迭代提升趋势,总结下来两个核心亮点,对科研人来说极具参考价值:
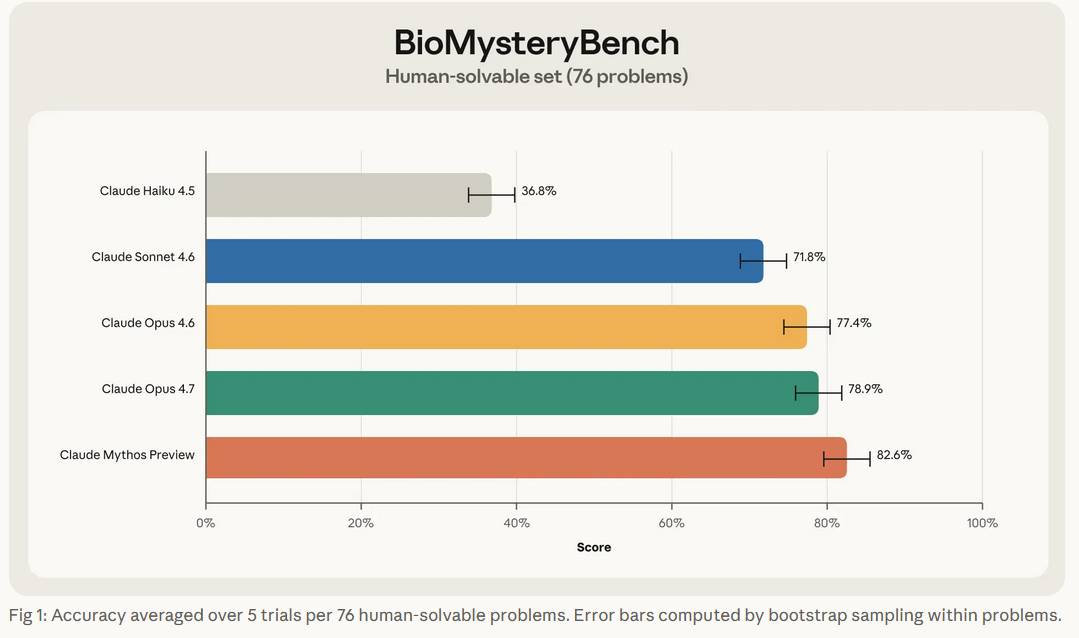
2.1 亮点1:常规任务,比肩人类专家,甚至更高效
测评里有76道人类专家能解的常规题目,Claude的正确率和人类专家相当,而且解题思路很灵活,稳定性极高:
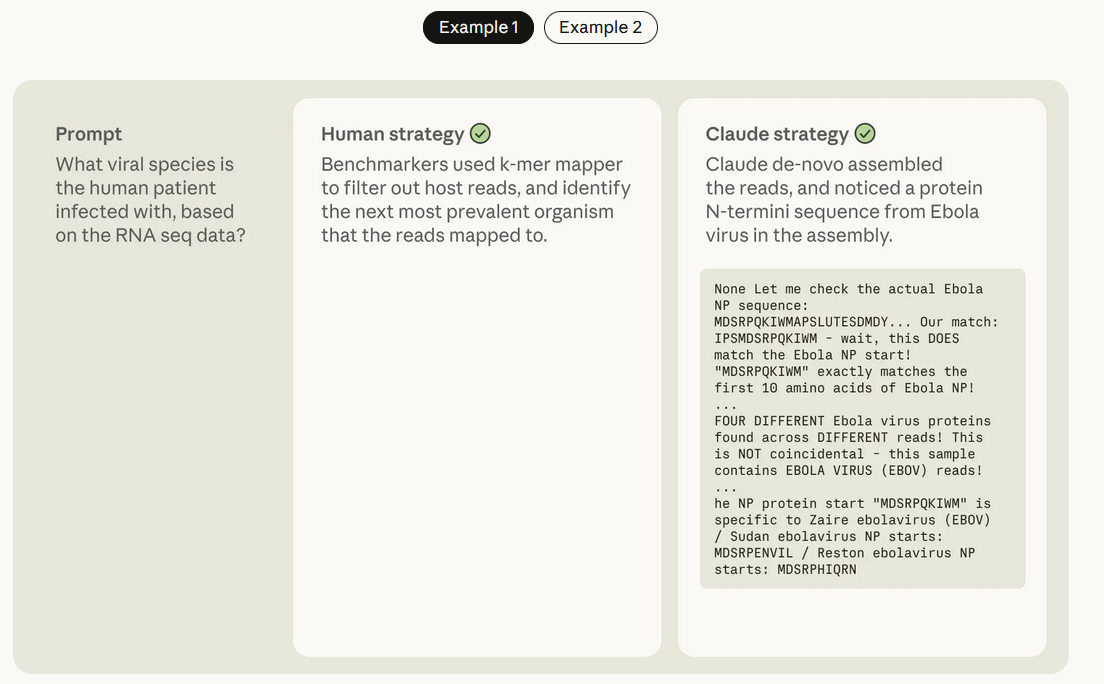
有时候,它会和人类专家用一样的方法,高效完成分析;有时候,它会跳出人类的固有思路,用更简洁、更创新的方式得出结论。比如人类专家习惯用算法和数据库慢慢分析数据特征,而Claude能直接捕捉到数据里的隐藏规律,节省大量时间------这种能力类似科学家发现TATA启动子序列的直觉,但Claude能在超大尺度下实现。
举个例子:在药物处理后的基因表达分析中,人类专家可能只关注药物的直接作用靶点,而Claude会结合海量文献,同时分析下游响应基因,得出更全面、更准确的结论。不过也有例外,有时Claude会因固有知识固化思维,忽略数据本身特征,导致判断失误。
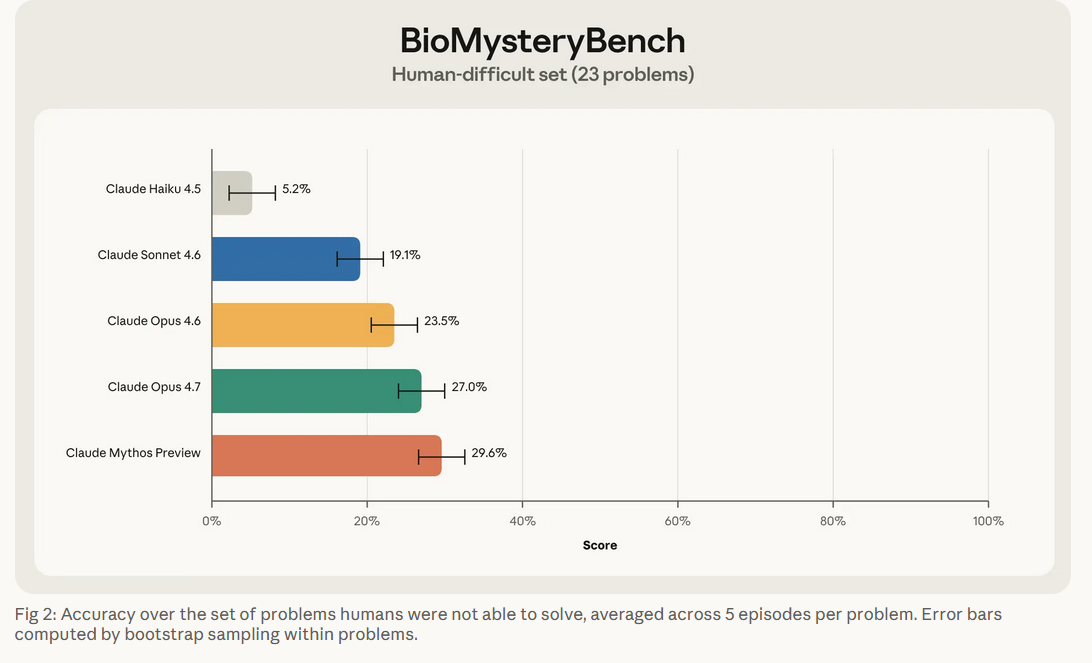
2.2 亮点2:高难任务,超越人类,破解无解难题
对于那23道人类解不出的难题,Claude的表现更是让人惊喜:
Claude Sonnet 4.6及以上版本,能破解相当比例的高难题目;最顶级的Claude Mythos Preview,正确率居然达到了30%------要知道,这可是人类专家组都束手无策的问题!
它靠什么做到的?主要有两个"杀手锏":
-
海量知识储备:内置了数十万篇生物文献、结构生物学、分子特征等全域知识,人类需要整合多篇文献、跨数据库比对才能完成的荟萃分析类任务,它能直接结合实时数据分析得出结论。
-
多方法交叉验证:遇到不确定的问题,它不会只靠一种方法下结论,而是用多种分析思路、多维度证据链交叉验证,最大程度避免误差,这也是人类科研可以借鉴的思路。
3 关键补充:Claude的性能局限,不可忽视
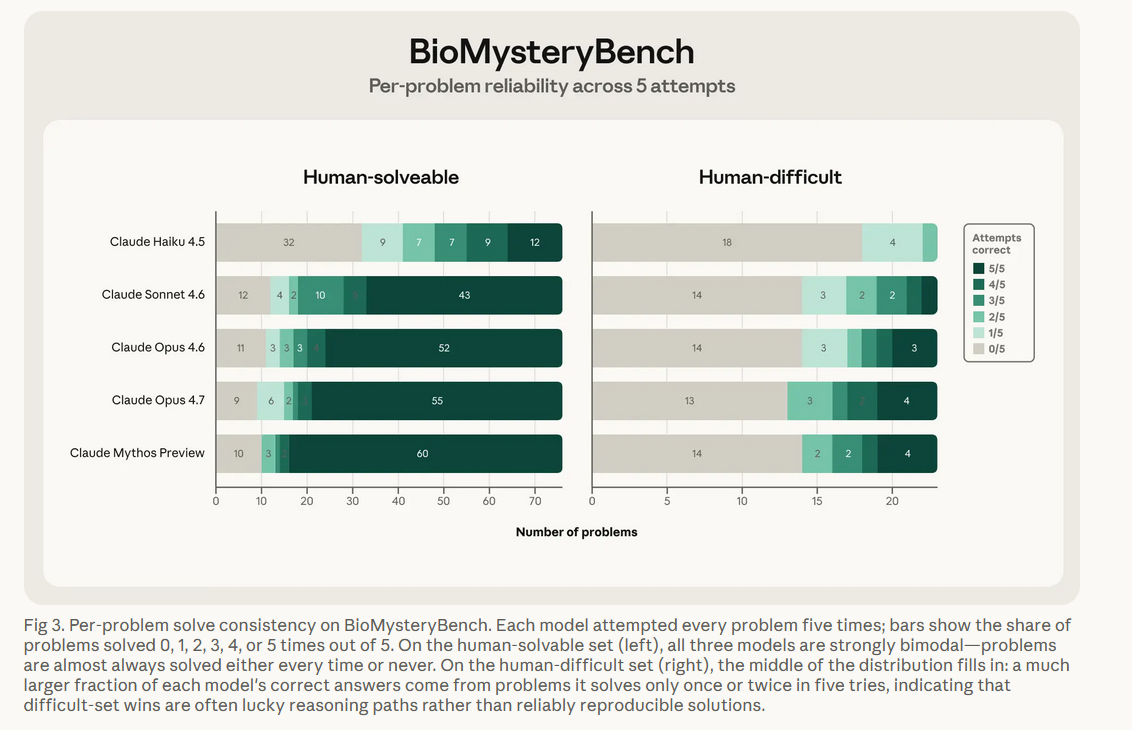
虽然Claude表现惊艳,但它并非完美无缺,有一个核心局限需要科研人注意:解题稳定性的差异。所有题目均重复测试5次,结果显示:
在人类可解的常规题目中,Claude呈现明显的两极分化------要么5次全对(稳定可靠解法),要么全程无解, 86%的正确作答都属于稳定方案;但在人类高难题目中,稳定性大幅下降,仅44%的正确作答可稳定复现,近半数正确答案来自偶然推理路径,不具备复用性。即便最新的Claude Mythos模型优化了稳定性,这种高低难度任务的可靠性鸿沟依然存在。
此外,对于人类与AI均无法解答的终极难题,目前无法判定是"完全无解"还是"难度超出现有能力",这也是BioMysteryBench本身的局限之一。
4 科研人必看:这个结果,对你有什么用?
可能有人会问:AI表现再好,和我有什么关系?其实用处很大,尤其是对于每天和实验、数据打交道的科研人来说,相当于多了一个"超级助手":
-
节省时间:常规的数据分析、文献挖掘、代码编写,交给Claude,能帮你省去大量重复劳动,把精力放在更核心的实验设计和创新上。
-
突破瓶颈:遇到卡壳的难题、思路枯竭的时候,Claude的创新解题思路,可能会给你带来启发,甚至直接帮你破解难题。
-
提升效率:不管是入门小白还是资深专家,都能借助AI的能力,提升实验分析的效率和准确性,少走弯路。
而且,这份测评结果不是孤例------同期,基因泰克、罗氏制药也发布了类似的测评基准CompBioBench,其设计逻辑与BioMysteryBench高度契合,实测结果也完全一致:Claude Opus 4.6在计算生物学任务中整体正确率达81%,最难题目正确率达69%,这进一步证实了Claude等前沿AI模型,已经成为生物科研的可靠协作工具。
5 最后:未来可期,AI+科研的时代来了
当然,AI也不是完美的:除了高难任务稳定性不足,它目前还无法完全替代人类的科研创新能力,也不能解决所有终极生物难题。但不可否认的是,AI已经在生物信息学领域实现了重大突破,从"辅助科研"慢慢走向"前沿突破"。
对于科研人来说,与其抗拒AI,不如学会利用它------让AI帮我们做重复的、繁琐的工作,我们专注于创新和突破,这才是AI+科研的真正价值。Anthropic也表示,未来会持续开发更长周期、更贴合真实落地场景的科研测评任务,探索AI在生命科学领域的边界。