过去谈 MCU,大家想到的是 GPIO、ADC、PWM、UART、SPI、I2C、定时器、中断、低功耗、状态机。它负责把设备控制稳定,把传感器数据采回来,把指令执行下去。
AI 推理通常被认为是另一个世界的事情:要么在云端服务器,要么在 GPU,要么在更高性能的 MPU 或边缘计算盒子里。
现在这个边界开始变化。越来越多 MCU 和小型 SoC 开始把神经网络加速能力、DSP 指令、向量指令、模型部署工具链、端侧推理库做进产品体系里。它们不是为了让单片机训练大模型,而是为了让设备在本地完成轻量推理。
这件事对嵌入式工程师很关键。因为未来很多设备不再只是"采集数据并上传"的节点,而会变成"能在现场先做判断"的智能终端。
一、MCU 的角色正在变化:不只是控制,还要承担本地推理
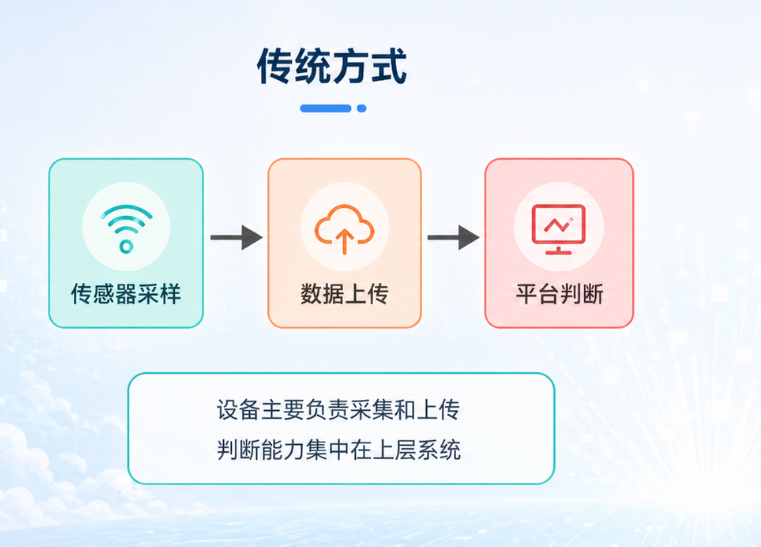
1. 过去:MCU 负责采集和控制,智能判断交给上层
在传统嵌入式系统里,MCU 的任务非常清楚:采集传感器数据、执行控制逻辑、完成通信上传、管理功耗和设备状态。
例如一个电机监测终端,过去通常会采集振动 RMS、峰值、电流、温度,然后把这些数据上传到上位机、网关或云平台。真正的异常判断往往放在平台侧:平台根据阈值、规则、趋势或更复杂算法判断是否异常。
这种架构可以工作,但有几个问题很明显:设备本体没有判断能力,上传数据缺少筛选,网络不稳定时现场能力变弱,大量正常数据会占用通信和平台资源。
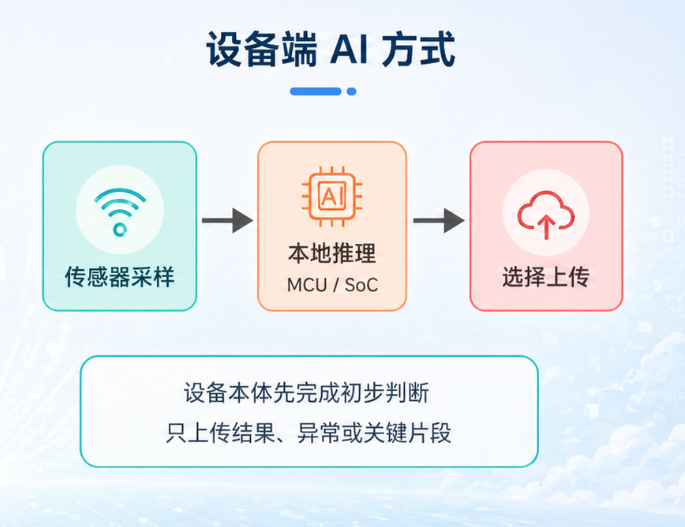
2. 现在:MCU 可以先在设备端做第一层判断
当 MCU 具备一定的神经网络推理能力后,设备端可以先完成一次本地初筛。
还是以电机监测为例,设备可以先读取加速度传感器数据,做滑窗、滤波、特征提取,然后在 MCU 上运行一个小型异常检测模型。模型输出"正常、疑似异常、明显异常"等状态后,设备再决定是否上传原始波形、是否触发告警、是否进入更高频采样模式。
**具体变化:**过去设备上传的是一堆传感器值;现在设备可以先输出一个"判断结果"。设备从数据搬运节点,变成了现场判断节点。
这不是要把云端取消。云端仍然适合做长期趋势分析、复杂诊断、模型训练和多设备管理。变化在于:现场第一层判断可以由设备端完成。
传统架构和设备端 AI 架构的差异
二、芯片厂商已经开始把 AI 能力放进 MCU 产品线
1. STM32N6:把 NPU 放进 STM32 MCU
STM32N6 是一个非常典型的信号。ST 官方资料中明确提到,STM32N6 是第一款集成 ST Neural-ART Accelerator 的 STM32 MCU,这个神经网络处理单元面向高能效边缘 AI 应用,运行频率 1GHz,最高提供 600 GOPS,用于计算机视觉和音频等实时神经网络推理场景。
这说明一个方向:以前需要更高性能处理器完成的部分视觉、音频、传感器 AI 推理,正在被尝试放到 MCU 级设备端。
2. NXP MCX N:通用 MCU 产品线开始集成机器学习加速器
NXP 的 MCX N 系列同样值得关注。NXP 官方资料显示,MCX N 是面向高性能、低功耗的 Arm Cortex-M33 MCU,部分 MCX N 家族集成 eIQ Neutron NPU,用于机器学习应用。
这类产品真正有意义的地方,不是把 MCU 变成服务器,而是把低功耗控制器的能力边界往前推了一步:在采样、通信、控制之外,增加本地状态识别和本地轻量推理。
3. ESP32-S3:不一定要有 NPU,也可以用向量指令加速 AI 工作负载
ESP32-S3 是另一类代表。它不是传统意义上带 NPU 的 MCU,但 Espressif 官方资料明确说明,ESP32-S3 在 MCU 内增加了向量指令,可用于加速神经网络计算和信号处理工作负载,开发者可以通过 ESP-DSP、ESP-NN 等库进行优化。
这类芯片的价值在于成本、无线连接和轻量推理能力的结合,适合智能家居、小型语音交互、低成本 IoT 终端和部分传感器类应用。
典型产品和方向
| 产品/平台 | 搬到设备端的能力 | 更适合关注的场景 | 工程关注点 |
|---|---|---|---|
| STM32N6 这类带 NPU 的 MCU | 在 MCU 内加速神经网络推理,让视觉、音频、传感器模型更靠近终端运行 | 简单视觉识别、音频事件检测、工业检测、状态判断 | NPU 支持算子、模型转换工具链、片上 RAM、摄像头接口 |
| NXP MCX N 这类带 NPU 的 MCU | 把机器学习加速器放进通用低功耗 MCU 产品线 | 工业 IoT、智能仪表、传感器节点、边缘状态识别 | 低功耗策略、推理耗时、eIQ 工具链、外设组合 |
| ESP32-S3 这类带向量指令的小型 SoC | 用向量指令加速神经网络和 DSP 工作负载,同时具备 Wi-Fi / BLE 连接能力 | 智能家居、语音交互、低成本 IoT 终端、小型传感器设备 | ESP-NN、ESP-DSP、模型大小、无线和推理的功耗平衡 |
**必须说清楚的一点:**这些芯片不是为了在设备端训练大模型,而是为了在设备本体上完成轻量推理,例如关键词识别、动作识别、简单视觉判断、声音事件检测、设备异常检测和状态分类。