目录
[什么是 HTTP 协议?](#什么是 HTTP 协议?)
[HTTP 协议的核心作用](#HTTP 协议的核心作用)
[二、URL (统一资源定位符)](#二、URL (统一资源定位符))
[五、https:// 和端口号](#五、https:// 和端口号)
[六、urlencode 和 urldecode](#六、urlencode 和 urldecode)
[七、HTTP 请求与响应格式](#七、HTTP 请求与响应格式)
[HTTP 请求格式 (HTTP Request)](#HTTP 请求格式 (HTTP Request))
[举例子 :](#举例子 :)
[HTTP 响应格式 (HTTP Response)](#HTTP 响应格式 (HTTP Response))
[举例子 :](#举例子 :)
[八、从输入关键词到看到图片 ------HTTP 全链路复盘](#八、从输入关键词到看到图片 ——HTTP 全链路复盘)
一、认识应用层协议HTTP
在网络编程的学习中,HTTP 绝对是绕不开的核心协议,作为典型的应用层协议,它早已渗透到我们日常上网的每一个环节,那 HTTP 协议到底是干什么的?
什么是 HTTP 协议?
HTTP 全称超文本传输协议(HyperText Transfer Protocol),是运行在 OSI 七层模型应用层的网络协议,它基于可靠的传输层 TCP 协议实现,是客户端与服务器之间沟通的标准化语言。
简单来说,网络上的设备想要传递数据,必须遵循统一的规则,否则客户端发出的信息,服务器无法识别;服务器返回的内容,客户端也无法解析。而 HTTP,就是专门为网页浏览、接口通信、数据传输等场景,制定的一套通用、规范、全球统一的数据传输规则。
从本质上来看,HTTP 协议和我们上一篇网络计算器代码中实现的 Protocol 类一样。我们自定义的 Protocol 类负责完成数据序列化、封包解包、格式转换,为客户端与服务端约定私有通信格式;而 HTTP 协议作为标准的应用层协议,它的内部实现了报文格式定义、数据解析规则、传输规范等核功能。二者底层都是通过 TCP 完成字节流传输,核心工作都是为通信双方定义统一的数据封装与解析规则,区别在于 Protocol 是我们自己手搓实现的一个简单的协议类,而 HTTP 是一套全球通用、标准化的协议。
HTTP 协议的核心作用
-
HTTP 协议实现了客户端与服务器的双向通信,这是 HTTP 最核心的功能。我们日常使用浏览器打开网页、手机 APP 加载数据、小程序获取内容,本质都是客户端(浏览器 / APP)通过 HTTP 协议向服务器发起请求,服务器接收请求后处理数据,再通过 HTTP 协议把结果返回给客户端。没有 HTTP 协议,客户端和服务器就无法高效、规范地传递数据,我们就无法正常浏览网页、使用网络应用。
-
HTTP 协议规范了数据的传输格式,HTTP 严格定义了请求报文和响应报文的格式,规定了请求方式、请求地址、请求头、请求体、响应状态、响应数据等内容的传输规范。不管是电脑、手机、平板,不管是 Windows、Linux、iOS 系统,只要遵循 HTTP 协议,就能进行通信,解决了不同设备、不同系统之间的数据传输兼容问题,这也是 HTTP 能成为最通用网络协议的关键。
-
HTTP 协议支撑超文本数据传输,因为 HTTP 最初就是为传输超文本 (文本文字和超出文本文字以外),包含文字、图片、音频、视频、链接等的复合内容设计的,我们浏览的网页里的图文、视频、样式文件,都是通过 HTTP 协议从服务器传输到本地客户端,再由客户端解析渲染出来的。这也是 HTTP 叫做超文本传输协议的原因。
-
HTTP 协议是一个无连接、无状态的协议,即每次请求都需要建立新的连接,且服务器不会保存客户端的状态信息。
补充
HTTP 协议本质上就是一套客户端与服务器之间约定好的通信标准规则,它只是一套抽象的、文字化的规范,本身并不是代码。真正能让网络通信跑起来的,是那些严格依照 HTTP 协议规范编写的程序代码。
我们日常使用的浏览器、手机 APP 这类客户端程序,内部都已经封装好了 HTTP 客户端代码;而 Nginx、Apache 以及各类后端服务程序,也内置了对应的 HTTP 服务端代码。这些底层代码会严格遵循 HTTP 协议的格式要求,负责完成请求报文组装、响应报文解析、数据传输等核心工作。
绝大多数开发场景下,我们直接调用编程语言提供的现成网络库即可,这些库内部已经帮我们封装好了符合标准的 HTTP 代码,我们只需要关注业务逻辑开发。不过后面我们会自己手搓实现一个极简版的 HTTP 通信代码,通过自己动手写报文封装、解析逻辑,帮助我们理解 HTTP 协议的底层原理,搞懂这套通信标准是如何一步步落地成可运行代码的。
还有要补充的就是我们电脑上装的浏览器 (Chrome、Edge、Firefox、360浏览器等) ,都属于客户端程序。它们是安装在我们用户自己的设备 (电脑、手机) 上,负责发起请求、展示结果。而服务端则是跑在远程服务器上,负责接收请求、处理逻辑、返回数据。
我们打开浏览器访问网站时,完整的流程是这样的:
- 我们在浏览器 (客户端) 上主动发请求:"我要看xxx网页";
- 对方网站的服务器 (服务端) 接收请求、查数据、拼网页;
- 服务器把网页内容发回来;
- 浏览器 (客户端) 再解析代码、渲染页面,呈现给我们看。
所以浏览器是主动发起请求的一方,也就是客户端。
二、URL (统一资源定位符)
我们已经知道 HTTP 协议是客户端和服务器之间通信的标准化规则。但这里有一个很关键的问题:客户端拿着 HTTP 这套 "语言",到底该和谁对话?又该告诉服务器想要什么东西呢?
这就需要一个精准的 "地址标识",来指明 HTTP 请求的目标,这个核心标识,就是我们今天要讲的URL (统一资源定位符)。我们日常在浏览器地址栏输入、用来访问网页的那一串字符,本质就是 URL,它最直观的特点,就是几乎都会以 http:// 或者 https:// 开头,这直接表明了这段地址,是基于 HTTP/HTTPS 协议去定位网络资源的。所以我们平时聊天、上网说的 "网址",就是 URL,二者是同一个东西。
下面我们举个例子 :
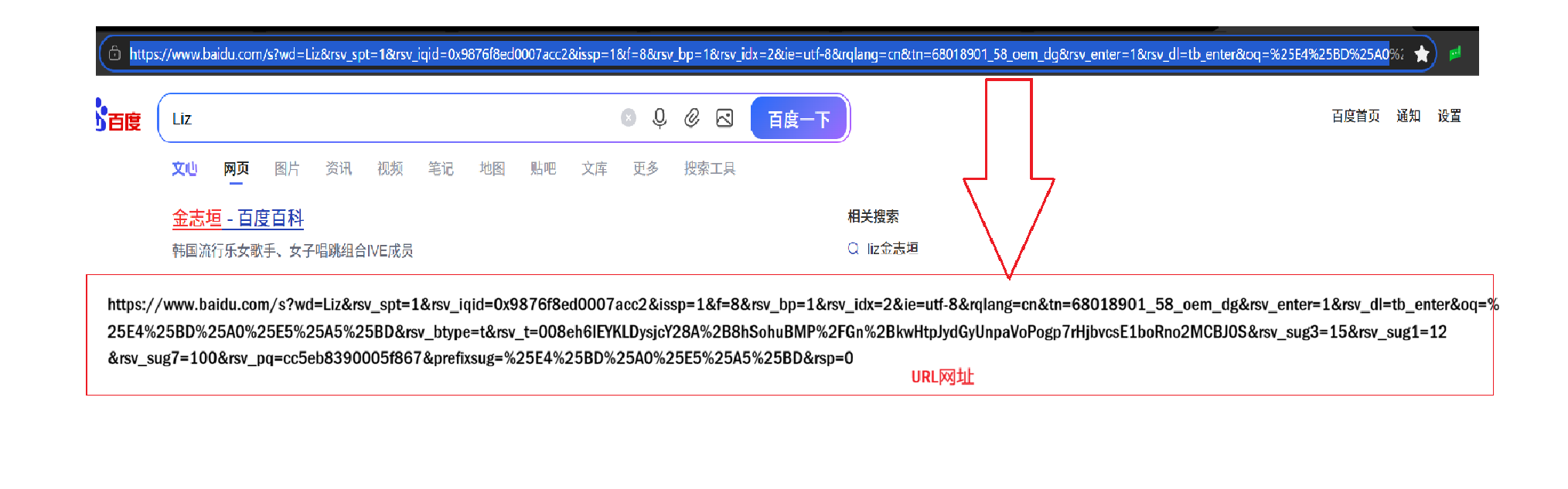 我们在百度搜索框输入 "Liz",点击 "百度一下" 的瞬间,浏览器就自动生成了这串 URL 网址,然后用 HTTP 协议,带着这串地址去百度服务器,精准请求 "搜索 Liz 的结果页面"。
我们在百度搜索框输入 "Liz",点击 "百度一下" 的瞬间,浏览器就自动生成了这串 URL 网址,然后用 HTTP 协议,带着这串地址去百度服务器,精准请求 "搜索 Liz 的结果页面"。
三、域名
那域名又是什么?
接着上面内容,我们搜索 Liz 时浏览器地址栏里那一大串完整的地址,就是 URL。这里面,www.baidu.com 这一段,就是 域名。如下:
 域名,就是服务器 IP 地址的 "别名",是 URL 里专门用来定位服务器地址的核心部分。
域名,就是服务器 IP 地址的 "别名",是 URL 里专门用来定位服务器地址的核心部分。
我们都知道,两台电脑在网络里通信,需要依靠 IP 地址(比如 180.101.49.11) 定位具体的服务器,但 IP 是一串枯燥的数字,人类根本记不住,于是就有了 域名 ------ 用好记的字母,给 IP 起一个别名;所以,www.baidu.com 本质就是百度服务器 IP 地址的别名。浏览器拿到 URL 后,会先把域名解析成真实 IP,再和这个 IP 建立 TCP 连接,最后发送 HTTP 请求。
再比如我们之前写客户端代码时,要手动输入服务端 IP:124.222.xxx.xxx;而浏览器访问百度时,不用记 IP,直接记域名 www.baidu.com;二者的本质完全一样:都是为了找到要通信的那台服务器。
域名解析服务器
域名解析系统,又叫 DNS,它的作用就是负责接收浏览器发来的域名 (如www.baidu.com),然后查询数据库并转换成对应的服务器 IP 地址,最好把 IP 返回给浏览器。
那域名解析服务器的 IP 又是怎么来的呢?
我们电脑、手机操作系统里,原本就内置了本地 DNS 服务器地址。我们的设备出厂时,系统就预先配置好了默认的 DNS 服务器 IP(比如运营商 DNS、114DNS、阿里云 DNS),所以也就不需要我们自己解析域名找它。
三、URI (统一资源标识符)
URI 是统一资源标识符,它是 URL 中域名后面的那一大串东西。也就是说 URL 包含 URI。
简单说:URI = 资源路径 + 查询参数
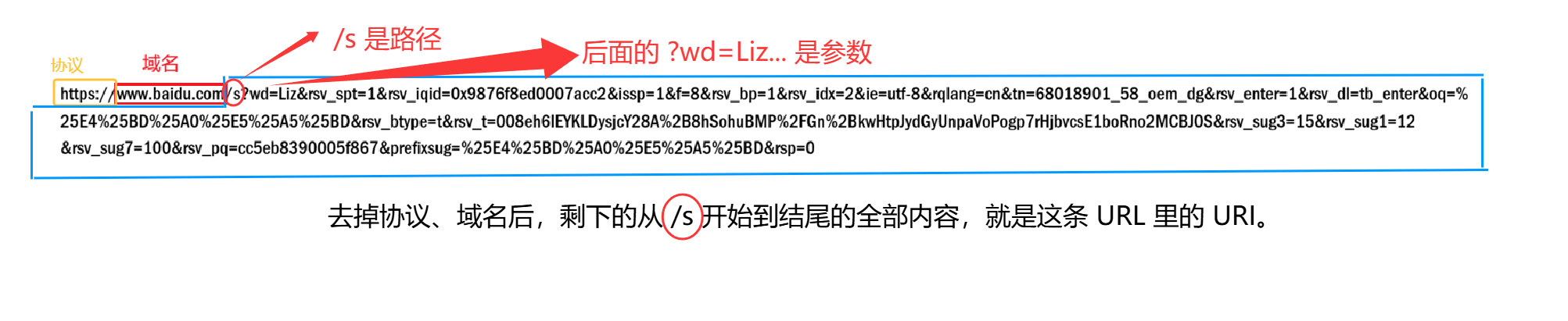
斜杠后面,一直到网址结尾的所有内容,全都是 URI。任何网址,都长这样,不管是百度、淘宝、B 站,还是其他网址,无一例外,全部符合这套对应规则。本质原因是:全世界所有浏览器、所有服务器,都严格遵守 HTTP 协议的统一语法。

网址里的层级路径
带分割符的层级路径 : 域名后面,用 / 一层一层分割、用来定位服务器里文件位置的路径。
举个例子 :这里的 /zhidao/question/ 就是用路径分割符 / 组成的层级路径,它的作用就是告诉服务器在服务器里,先找 zhidao文件夹,再进里面的 question文件夹,找 123456.html 这个文件。这种网址,是静态资源网址,比如官网、文章、图片、网页文件,一般都是这种结构。属于服务器按路径找文件,直接返回文件内容。
我们再看看这个网址,这个网址没有带分割符的层级路径,因为它是一个单级路径。因为我们要查找的不是文件,它是百度服务器里一个叫 s 的动态接口。动态接口就是服务器里没有这个文件,它是一段程序代码。浏览器访问 /s 这个接口,同时带上 wd=Liz;百度服务器收到后,执行这段搜索代码,去数据库查 Liz 的信息;代码把查出来的结果,临时拼成一个网页,返回给你。所以不需要多层路径!因为它不是找文件,是调用一段代码接口,只需要 /s 这一个接口入口就行,后面全是给这段代码传的参数(wd、rsv_spt这些)。


五、https:// 和端口号

那 URL 最前面的 https:// 又是什么?
-
我们平时打开任意一个网址,最前面总会看到 http:// 或者 https:// ,这就是我们之前反复提到的应用层通信协议,它规定了浏览器和服务器之间该如何 "对话"、数据如何传输。我们熟知的 HTTP 协议是基础的明文版本,传输的数据没有任何保护,相当于 "裸奔",一旦被中途拦截,所有信息都会被直接看到;而 HTTPS 是 HTTP 的安全升级版本,在 HTTP 的基础上增加了一层加密保护,浏览器和服务器之间传输的所有数据都会被加密处理,就算数据被拦截,别人也无法解读内容,这也是现在绝大多数正规网站都采用 HTTPS 协议的原因。
-
https 是协议名字,后面的 :// 是固定的语法符号,专门用来分隔 "协议" 和 "后面的地址"。URL 里的 :// 是全世界统一的固定格式,意思就是:"前面这个是协议,后面跟着的是服务器地址"。少了 ://,浏览器就分不清哪个是协议、哪个是地址。
-
并且网址里的 https 必须是小写,不是随便规定的,核心原因是 URL 这套标准本身就强制规定:协议名必须用小写字母。网络世界里的官方标准文档,明确写死:协议部分(http/https)必须是小写。浏览器、服务器都是照着这套标准做的。
那端口号呢? 端口号在 URL 中是怎么体现出的?
-
我们已经清楚,IP (域名) 能帮我们定位到网络中的某一台服务器。但一台服务器上可能同时运行着网页服务、文件服务、聊天服务等多个程序,我们如果要精准的访问到网页服务的程序,就必须依靠端口号。端口号和 IP 搭配使用,才能实现对某个网络程序的精确定位。
-
而 HTTP 协议默认使用 80 端口,而它的加密版本 HTTPS 默认使用 443 端口,这也是我们平时访问百度、淘宝这类网站时,URL 里看不到端口号的原因 ------ 浏览器会自动默认补上对应协议的端口号。
-
就像我们之前写的 TCP 网络计算器,服务端指定 8080 端口运行,客户端必须通过 "服务器 IP+8080 端口" 才能精准连接到计算器程序。同理,当浏览器解析完域名拿到服务器 IP 后,会根据 URL 开头的 https,自动使用 443 端口和服务器建立连接,确保精准送到处理网页的程序上。
六、urlencode 和 urldecode
URL 里的 /、?、:、& 这些符号都有特殊含义:比如说 :// 用来分隔协议和地址,/ 用来分隔路径,? 用来分隔路径和参数,& 用来分隔多个参数,如果我们要搜索的内容文本里也出现了这些符号,浏览器就会 "搞混",不知道它到底是 URL 语法的一部分,还是我们要传的普通文本。
举个例子:我们要搜索的关键词是 a&b,直接写进 URL 会变成:https://www.baidu.com/s?wd=a\&b,浏览器会把它解析成两个参数:wd=a 和 b,完全不是我们想要的 wd=a&b。这时候就必须用 urlencode 和 urldecode,把这些特殊字符修改成浏览器能安全识别的格式。
什么是 urlencode 和 urldecode?
urlencode 和 urldecode 是专门服务于 URL 传输的一对配套工具,核心定位就是解决特殊字符冲突、保证浏览器与服务器之间参数传递无歧义、能被正确解析,是网络请求里专门处理 URL 参数的 "格式转换器"。urlencode 是编码工具 ,urldecode 是解码工具。
那 urlencode 是怎么编码的呢? 很简单,它的编码规则只有三步:
-
把要转义的字符,先转成它对应的 ASCII 码 (或 UTF-8 编码值),比如空格的 ASCII 码是 32,转成十六进制就是 20;& 的 ASCII 码是 38,转成十六进制就是 26。
-
把十六进制值前面加上 %,空格就变成了 %20,& 就变成了 %26。
-
如果是中文,就按 UTF-8 编码,每个字节单独转义,比如 "你" 字的 UTF-8 编码是 E4 BD A0,转义后就变成了 %E4%BD%A0。
所以刚才的例子 a&b,编码后会变成 a%26b,浏览器就能正确识别这是一个完整的参数,不会把 & 当成分隔符了。
urldecode 就是 urlencode 的反向操作 :
urlencode 是 "把特殊字符转成 %XY 格式",那 urldecode 就是 "把 %XY 格式还原成原来的字符"。
服务器收到 URL 参数后,会自动执行 urldecode,把 %26 还原成 &,把 %E4%BD%A0 还原成 "你",这样就能拿到真正要传的原始数据了。
UrlEncode编码/UrlDecode解码 - 站长工具![]() https://tool.chinaz.com/tools/urlencode.aspx
https://tool.chinaz.com/tools/urlencode.aspx
这是工具的网址。
七、HTTP 请求与响应格式
什么是 HTTP 请求格式与响应格式?
浏览器和服务器的沟通内容,必须遵循一套统一、严谨的书写规范,这就是 HTTP 请求格式与 HTTP 响应格式。简单来说,HTTP 协议就是一本通用手册,规定了客户端怎么写信、服务器怎么回信,这两种格式就是手册里定义好的、必须严格遵守的标准书信模板,没有模板,双方就无法读懂彼此的信息。
HTTP 请求格式 (HTTP Request)
HTTP 请求格式是浏览器、APP 这类客户端,向服务器发起沟通时,按照 HTTP 协议规范封装好的数据包,核心作用是向服务器说明自己的访问意图、身份信息、携带的数据。
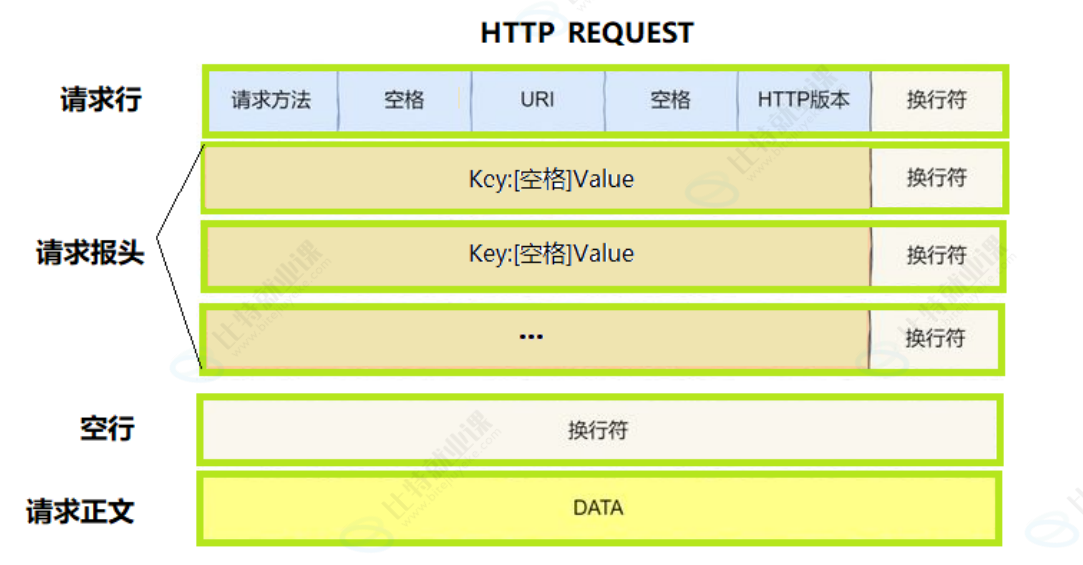 这张图是 HTTP 请求报文的底层物理结构,它把浏览器发给服务器的请求包,拆成了 4 个部分,每个部分、每个空格、每个换行符都有严格规定,错一个字符服务器就无法解析。
这张图是 HTTP 请求报文的底层物理结构,它把浏览器发给服务器的请求包,拆成了 4 个部分,每个部分、每个空格、每个换行符都有严格规定,错一个字符服务器就无法解析。
第一部分:请求行
请求方法 + 空格 + URI + 空格 + HTTP 版本 + 换行符
1. 请求方法:动作指令,告诉服务器 "我要干什么"。最常用 2 个请求方法 : GET 获取资源 (查网页、搜内容),POST 提交数据 (登录、上传)。
2. 空格:必须有,且只能是 1 个空格,用来分隔三个字段,多一个少一个都不行。
3. URI:资源路径 + 参数,就是域名后面的部分,告诉服务器 "我要找哪个资源、带什么参数"。
4. HTTP 版本:协议版本,几乎全是 HTTP/1.1版本,规定双方对话规则。
5. 换行符:必须带,代表请求行结束,跳到下一行。
举个例子 :
GET是方法,/index.html是 URI,HTTP/1.1是版本,\r\n是换行符。

第二部分:请求报头
Key : 空格 Value + 换行符

可以写多行,每行都是「键:值」格式,冒号后面必须跟 1 个空格。每行末尾必须带换行符,代表这一行报头结束。
举个例子 :
第一行 Host 告诉服务器访问哪个域名,
第二行 User-Agent 告诉服务器浏览器类型,每行都是 Key: 空格 Value + 换行符。

第三部分:空行
这个空行必须有,它是 HTTP 协议强制规定的分隔符。
空行的本质就是一个换行符 \r\n ,代表 "报头部分全部结束,后面开始是正文"。
前面是请求行 + 请求报头,后面是请求正文 (数据内容),中间用空行分割。哪怕没有请求正文 (比如 GET 请求),这个空行也必须带,服务器就是靠这个空行判断 "报头读完了"。
第四部分:请求正文
纯数据,没有格式要求,图里标为DATA

GET 请求:没有请求正文,所有数据都放在请求行的 URI 里
POST 请求:才有请求正文,登录的账号密码、提交的表单数据,全部放在这里
举个例子 : 如果是登录请求,正文里就会写:

举例子 :
下面我们举个西安交通大学就业网登录请求与响应交互的示例:
这就是一个完整的 HTTP POST 登录请求,浏览器把登录表单数据,按协议规定的格
式,封装成请求行 + 请求报头 + 空行 + 请求正文的结构,发给服务器。服务器收到后,会按同样的格式解析请求,读取账号密码,然后返回登录成功 / 失败的响应。
HTTP 响应格式 (HTTP Response)
上面是客户端发出去的请求格式,现在来看服务器收到请求后,原路返回给客户端的响应格式。HTTP 响应格式和请求格式是对称的结构,同样由 4 个部分组成,每个换行、空格、字段顺序都有规定。

第一部分:状态行
HTTP 版本 + 空格 + 状态码 + 空格 + 状态描述 + 换行符

1. HTTP 版本:必须和请求里的版本保持一致 (一般都是 HTTP/1.1),代表双方对话规则统一;
2. 空格:协议强制分隔符,用来分开三个核心字段;
3. 状态码:三位数数字,是服务器给客户端的处理结果,最常用 3 个状态码如下:
- 200:OK → 请求成功,我们要的东西找到了;
- 404:Not Found → 我们要找的资源不存在(网页打不开);
- 500:Internal Server Error → 服务器崩了;
4. 状态描述:状态码的英文解释,是给我们人类看的,服务器主要识别数字状态码;
5. 换行符\r\n:状态行结束标记,跳到下一行。
举个例子 :
精准对应:版本 + 空格 + 状态码 + 空格 + 描述 + 换行。

第二部分:响应报头
Key: 空格 Value + 换行符

每行都是「键:值」格式,冒号后面必须跟空格;每行换行符代表该行结束,多行报头用来告诉浏览器返回数据的细节;请求报头是浏览器告诉服务器「我是谁、我要啥」,响应报头是服务器告诉浏览器「我给你的东西是什么样的」。
第三部分:空行
这个空行也必须有!空行本质就是一个换行符\r\n,专门用来分隔报头信息和正文数据。哪怕响应正文为空,这个空行也必须存在,因为浏览器就是靠这个空行判断前面的报头信息完毕,下来是响应正文 (服务端给浏览器的内容)。
第四部分:响应正文
就是纯数据,无格式要求。
请求正文是浏览器发给服务器的提交数据;
响应正文是服务器真正返回给浏览器的内容资源,是整个响应的目的。
当我们访问百度搜索后,响应正文里就是完整的网页 HTML 代码、CSS 样式、JS 脚本,浏览器拿到正文后,会渲染成我们肉眼看到的搜索结果页面。
举例子 :
这就是服务器收到我们上一条登录请求后,原路返回给浏览器的标准 HTTP 响应报文,和我们之前讲的状态行 + 响应报头 + 空行 + 响应正文格式对应,而且和上一条请求是严格配对的。
这就是一次完整的 HTTP 请求 - 响应交互:浏览器按协议格式发请求,服务器按同样的协议格式回响应,一来一回,完成了一次登录并获取网页的过程。
八、从输入关键词到看到图片 ------HTTP 全链路复盘
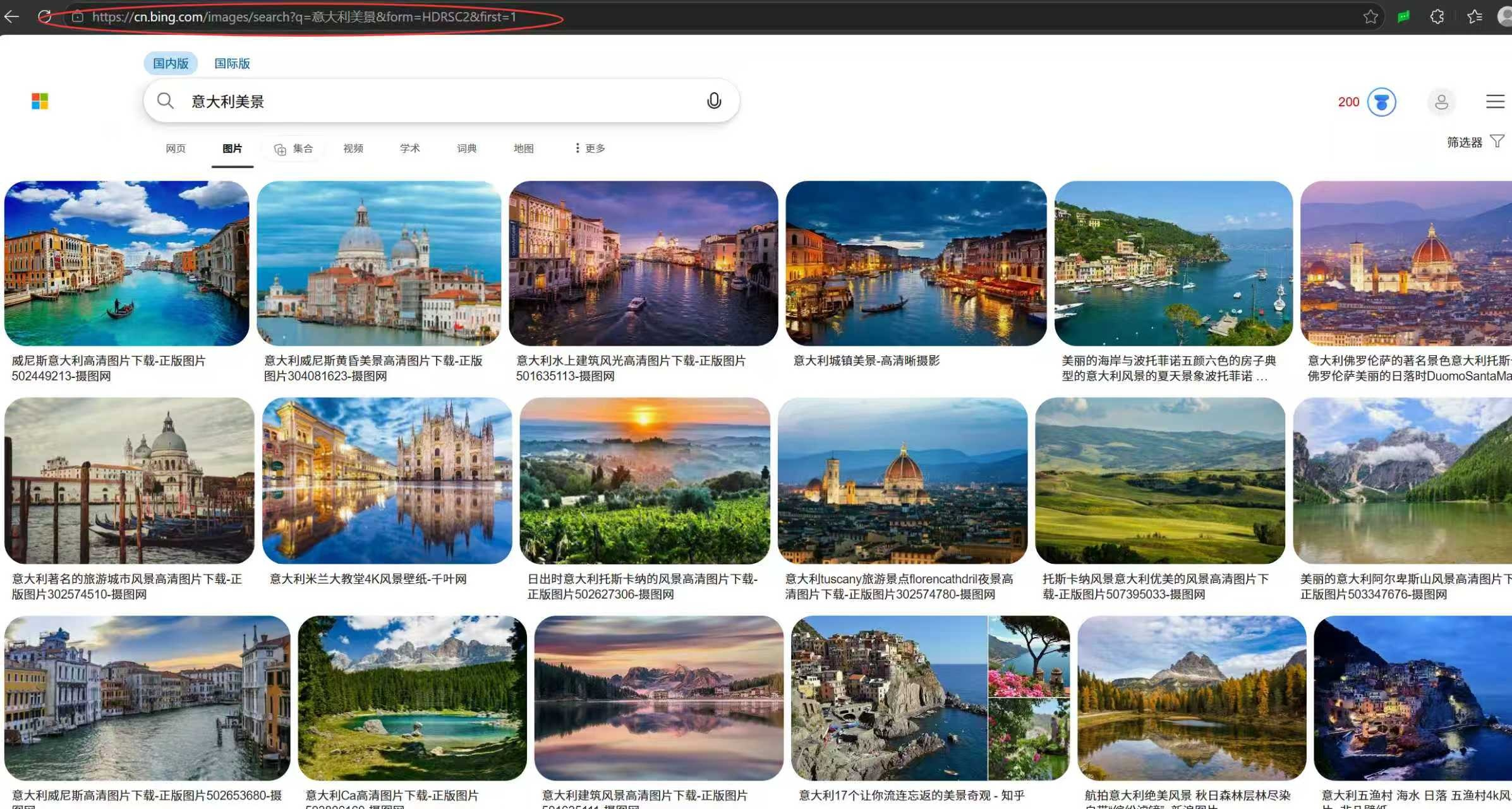
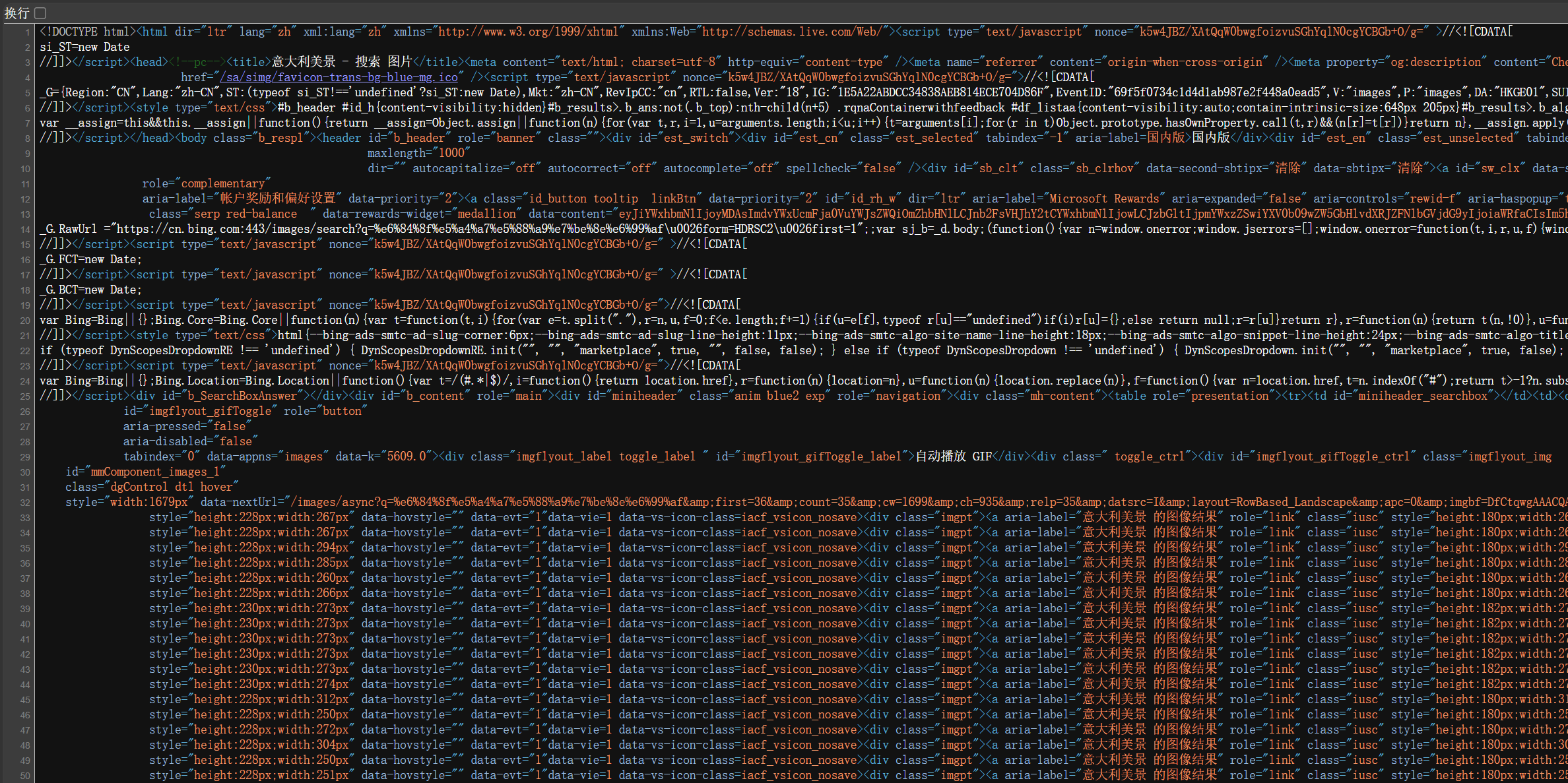
我们把从在搜索框输入 "意大利美景",到页面加载出满屏图片的全过程总结一下 :整个上网行为的本质,就是人触发行为、浏览器翻译、服务器回应、浏览器渲染的循环,而我们学的 URL、HTTP 请求、HTTP 响应,就是这条链路里每一步的核心载体。
第一步,我们在搜索框输入关键词 "意大利美景",点击搜索,这是整个流程的起点。我们的输入是最原始的行为,没有这个动作,后面所有流程都不会触发。
第二步,浏览器接收输入后,会立刻自动生成一条完整的 URL 网址,也就是红框标注的那串地址。浏览器会把输入的中文关键词,通过 urlencode 编码规则处理,再拼接上域名、搜索路径和参数,实时生成这个网址,网址是浏览器对搜索行为的第一步 "翻译",把人的语言,转换成服务器能识别的地址格式。
第三步,浏览器拆解这条生成的 URL,按照 HTTP 协议的强制格式,封装成标准的 HTTP 请求报文。它会从网址里拆分出协议、域名、URI,把 URI 填入请求行,域名填入请求头,遵循 "请求行、请求报头、空行、请求正文" 的结构,生成客户端发往服务端的请求信,通过网络通道发送给必应服务器,这一步是浏览器把地址,进一步翻译成服务器能读懂的对话格式。
第四步,服务器收到 HTTP 请求报文后,解析请求里的 URI,提取出我们要搜索的关键词,在服务器资源库中检索匹配的图片资源。检索完成后,服务器按照 HTTP 响应格式,封装成包含状态行、响应报头、空行、响应正文的回信,返回给浏览器,响应正文里是包含所有图片链接的 HTML 网页代码。
第五步,浏览器接收响应报文,先解析响应正文里的 HTML 代码,识别出里面每一张图片的独立 URL 地址。随后浏览器会对每个图片地址,再次发起独立的 HTTP 请求,获取图片的二进制数据,最终把所有图片渲染、展示在页面上,也就是我们看到的满屏意大利美景。
九、相关问题
1. 仅聚焦应用层,HTTP 协议会顺带完成序列化与反序列化操作吗?
是的。HTTP 协议本身就定义了一套完整的序列化、反序列化规则,浏览器和服务器在遵循 HTTP 协议组装、解析报文的过程中,会自动、顺带完成这两个操作,无需额外执行其他序列化逻辑。
在 HTTP 应用层里,序列化就是客户端(浏览器)将抽象的访问意图,严格按照 HTTP 请求格式(请求行、请求报头、空行、请求正文),拼装成一段规范、可在网络中传输的文本字符串的过程。比如搜索 "意大利美景" 时,浏览器把搜索关键词、访问路径等信息,按 HTTP 格式拼成标准请求报文,这个拼装动作就是序列化,而拼装的格式规则,正是 HTTP 协议本身定义的。
反序列化就是服务端收到 HTTP 报文后,严格按照 HTTP 协议的格式规则,拆解、解析报文内容,还原出客户端访问意图的过程。服务器识别请求行的请求方法、URI,读取请求报头的补充信息,跳过空行解析正文,最终读懂客户端要搜索资源、提交数据等需求,整个解析还原的过程,就是反序列化。
2. 为什么说 HTTP 是顺带完成序列化、反序列化的?
因为序列化、反序列化的格式规范,已经被写进了 HTTP 协议的核心定义里。浏览器组装请求报文、服务器解析响应报文,本质上都是在遵守 HTTP 协议的格式要求,这个遵守格式的动作,天然就完成了序列化与反序列化,不是额外附加的步骤,是 HTTP 通信必须完成的核心环节。
3. 结合分层思想,HTTP 的序列化、反序列化和底层 TCP/IP 拆包解包有什么区别?
答:两者分属不同网络层级,分工明确。序列化、反序列化是应用层 HTTP 协议负责,解决 "通信内容该怎么组织、双方怎么读懂" 的问题;而拆包、解包是传输层、网络层TCP/IP 协议负责,解决 "数据该怎么在网络中运输、打包" 的问题。底层只管运输,不管内容;应用层 HTTP 只管内容格式,顺带完成序列化、反序列化。
十、总结
HTTP 全称超文本传输协议(HyperText Transfer Protocol),是运行在 OSI 七层模型应用层的网络协议,它基于可靠的传输层 TCP 协议实现,是客户端与服务器之间沟通的标准化语言。简单来说,网络上的设备想要传递数据,必须遵循统一的规则,否则客户端发出的信息,服务器无法识别;服务器返回的内容,客户端也无法解析。而 HTTP,就是专门为网页浏览、接口通信、数据传输等场景,制定的一套通用、规范、全球统一的数据传输规则。
谢谢大家的观看!