我们之前学完了MySQL的索引,今天我们要翻过第二个大难关 --- MySQL的事务
一、为什么需要事务
在日常开发中,我们对数据库的操作本质就是 CRUD(增删改查)。如果这些操作不加任何控制,会带来很多问题,比如:
- 数据更新了一半程序崩溃
- 多个用户同时修改同一条数据导致混乱
- 数据写入后丢失(比如服务器宕机)
- 数据前后状态不一致
举个经典例子:买票系统的流程
- 扣库存
- 生成订单
- 支付
如果执行到一半失败,比如库存扣了但订单没生成,就会造成严重问题
因此,我们需要一种机制,让一组操作要么全部成功,要么全部失败
这就是 事务(Transaction) 的意义
二、什么是事务?
事务本质上是一组 SQL 语句的集合,这些语句:
- 在逻辑上是相关的
- 要么全部执行成功
- 要么全部失败回滚
简单理解:
事务 = 一组"绑定在一起"的 SQL 操作
例如:
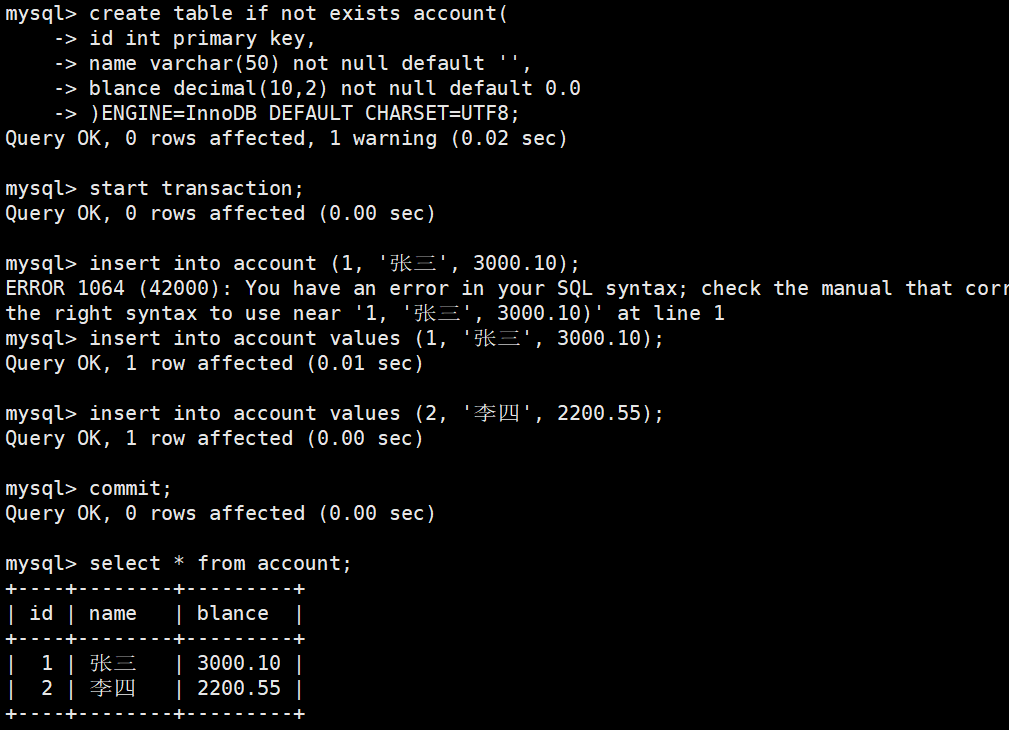
如果中间任何一步失败,就可以:
ROLLBACK;
也可以savepoint [回滚点],之后rollback to [回滚点]即可回滚到该位置| 操作 | 是否结束事务 | 是否需要commit |
|---|
|-------------|---|-----|
| ROLLBACK | 是 | 不需要 |
|-------------------------|---|--------|
| ROLLBACK TO savepoint | 否 | 需要(通常) |
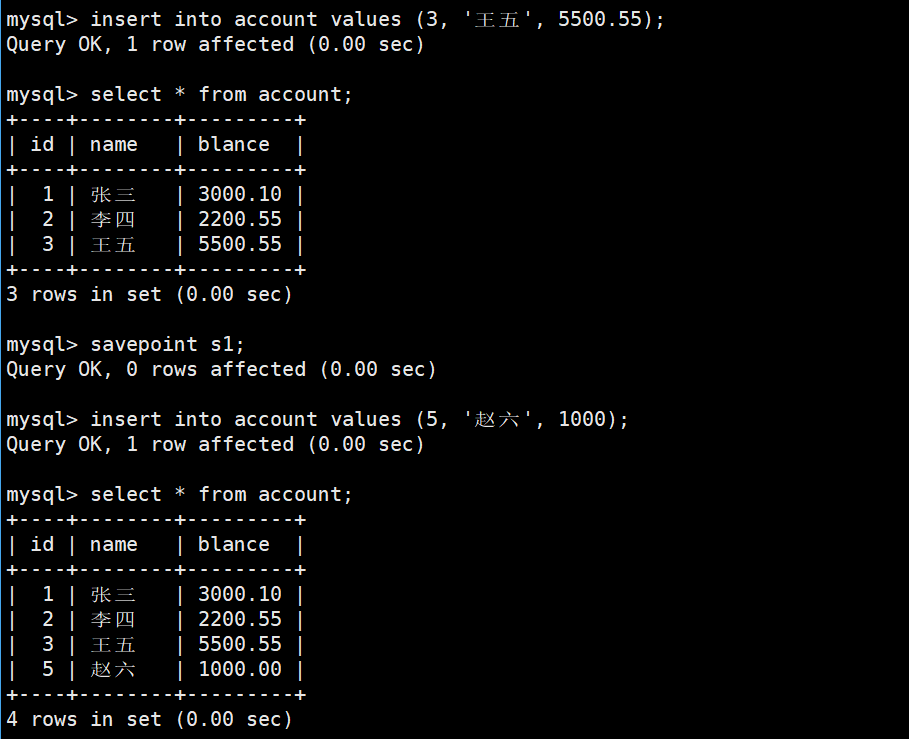
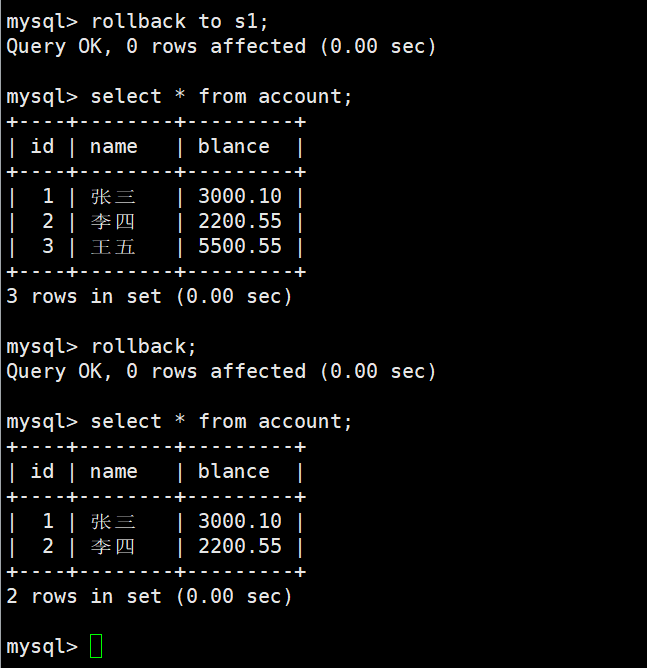
三、事务的四大特性(ACID)
事务之所以可靠,是因为它满足四个核心特性:
1. 原子性(Atomicity)
事务是不可分割的整体:
- 要么全部成功
- 要么全部失败
如果执行过程中出错,会自动回滚到最初状态。
2. 一致性(Consistency)
事务执行前后,数据库必须保持一致状态。
例如:
- 转账前总金额 = 转账后总金额
- 数据必须符合约束(主键、外键等)
3. 隔离性(Isolation)
多个事务可以同时执行,但互不干扰。
否则会出现:
- 读到别人未提交的数据
- 数据被反复修改导致不一致
4. 持久性(Durability)
事务一旦提交:
- 数据会永久保存
- 即使数据库宕机也不会丢失
四、事务是如何实现的?
事务并不是数据库"天生就有"的,而是为了简化应用开发而设计的机制。
它帮我们解决:
- 并发问题
- 异常回滚
- 数据一致性
开发者只需要:
BEGIN(这里也可以使用start transaction);
...
COMMIT;就可以编写事务
五、MySQL中事务的支持
注意:不是所有存储引擎都支持事务
| 引擎 | 是否支持事务 |
|---|---|
| InnoDB | ✅ 支持 |
| MyISAM | ❌ 不支持 |
| MEMORY | ❌ 不支持 |
查看方式:
SHOW ENGINES;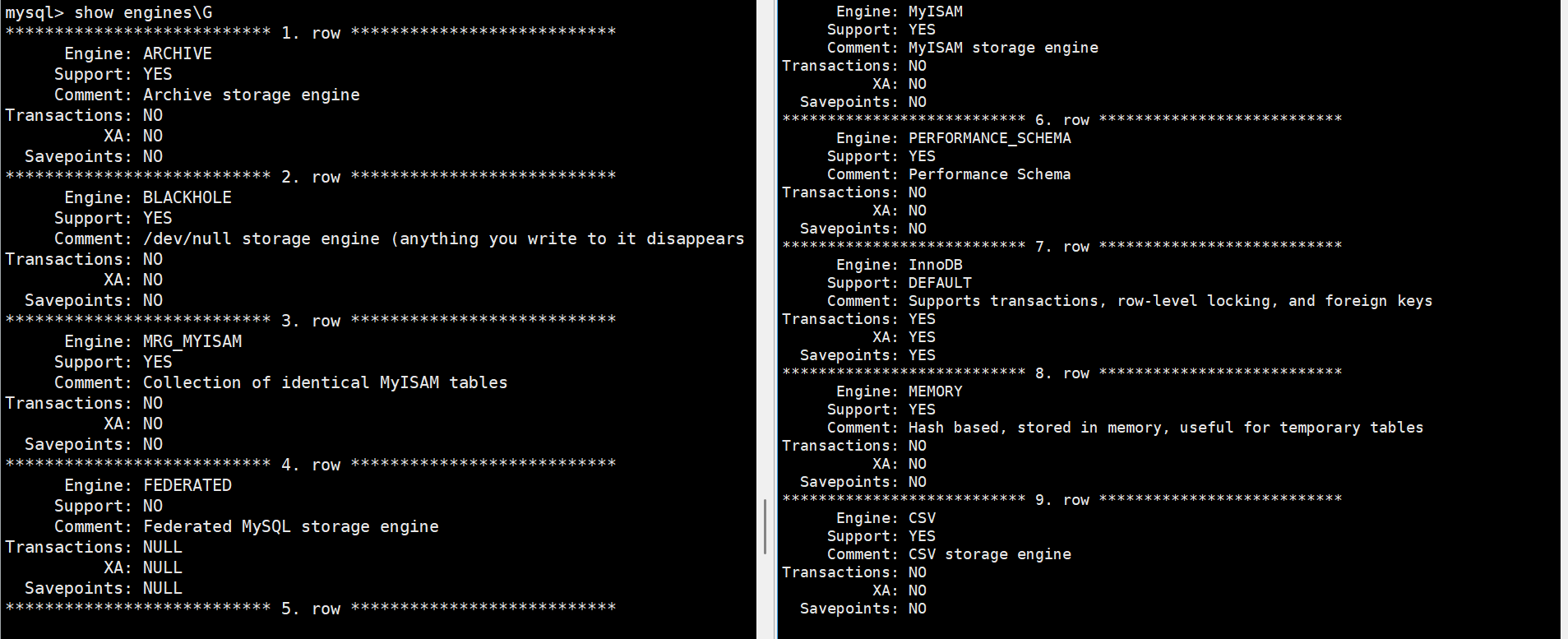
实际开发中必须使用 InnoDB,因为只有该引擎支持事务,而事务在实际开发中十分重要
六、事务的提交方式
MySQL事务有两种提交方式:
1. 自动提交(默认)
SHOW VARIABLES LIKE 'autocommit';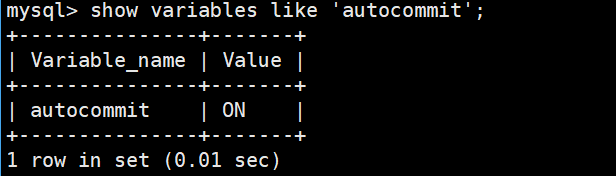
默认:
autocommit = ON意味着:
每一条 SQL 都是一个独立事务,并自动提交
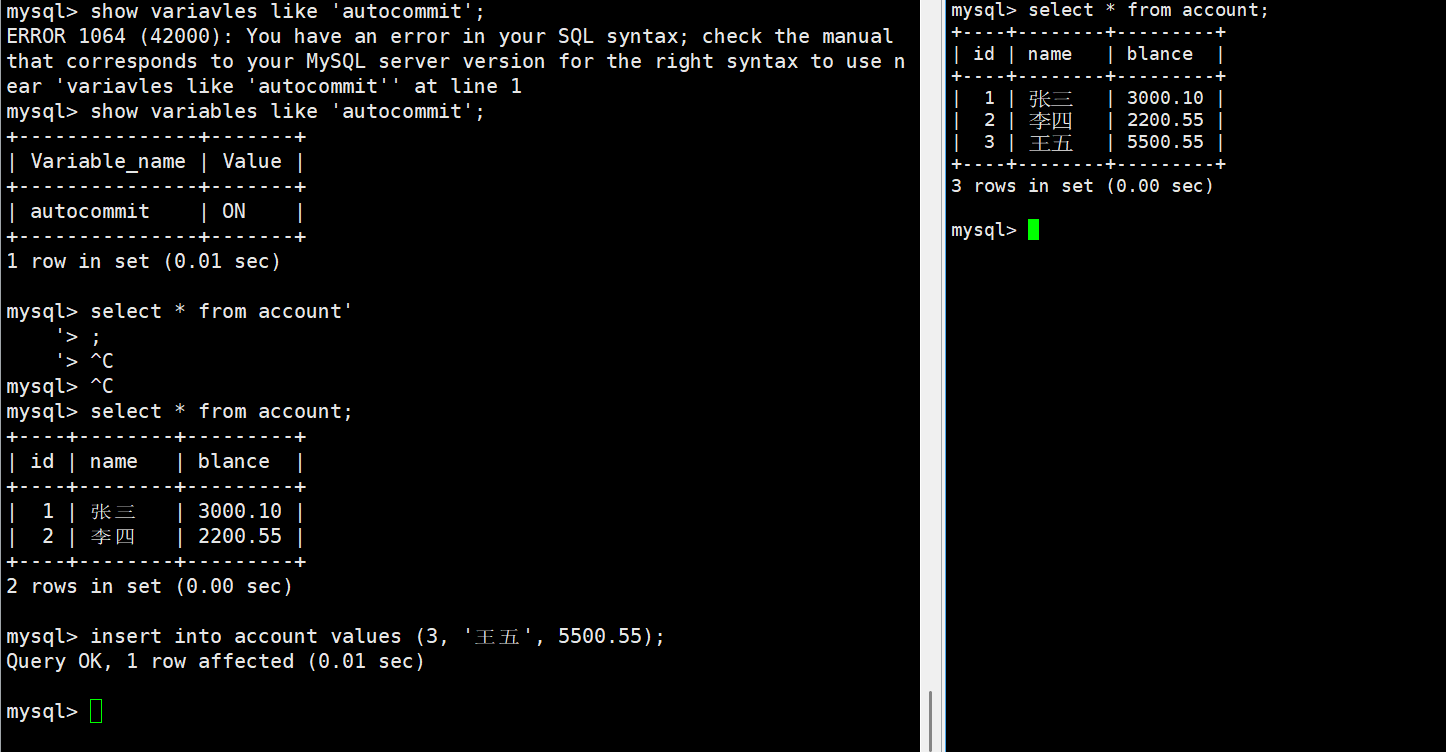
2. 手动提交
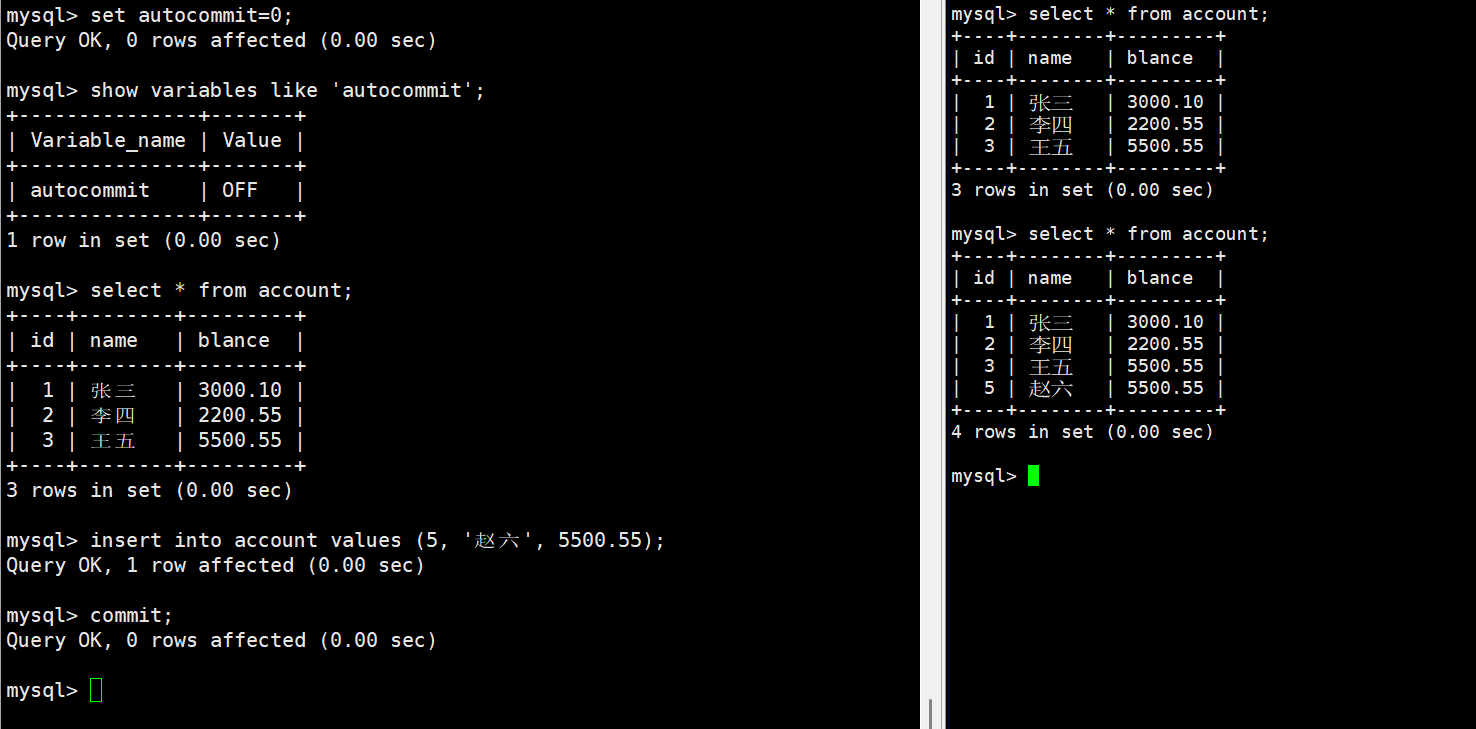
关闭自动提交:
SET AUTOCOMMIT = 0;意味着:
在 autocommit=0 的情况下,多个 SQL 会自动归属于同一个事务,必须显式执行 COMMIT 才会提交
七、事务的基本操作
1. 开启事务
BEGIN;
-- 或
START TRANSACTION;2. 提交事务
COMMIT;只要commit之后数据永久生效
3. 回滚事务
ROLLBACK;回到事务开始前
4. 保存点(Savepoint)
可以实现"局部回滚"
SAVEPOINT s1;
-- 执行操作
ROLLBACK TO s1;八、事务的重要结论(非常关键)
通过实验可以得到几个重要结论:
1. 事务必须提交才会生效
BEGIN;
INSERT ...
-- 没有 COMMIT其他会话看不到数据(前提是隔离等级不是读未提交,在该隔离登记下就算不commit其他会话也可以看到)
2. 客户端异常退出会自动回滚
如果事务未提交:
MySQL 会自动回滚
3. COMMIT 后数据永久生效
即使:
- 程序崩溃
- 客户端断开
数据依然存在
4. BEGIN 会打破自动提交
即使:
autocommit = ON只要执行:
BEGIN;就进入手动事务模式
这就说明autocommit 只影响隐式事务(未显式使用 BEGIN)的提交行为;
一旦使用 BEGIN / START TRANSACTION 显式开启事务,就完全不受 autocommit 影响。
5. 单条 SQL 也是事务
在自动提交模式下:
INSERT INTO table VALUES (...);本质上等价于:
BEGIN;
INSERT ...
COMMIT;为什么平时我们感到这样呢,因为系统默认是autocommit=no的~~
九、为什么需要隔离性?
数据库通常是多用户并发访问的:
- 多个事务同时执行
- 操作同一张表甚至同一行数据
如果没有隔离:
数据会混乱
例如:
- A 修改数据
- B 同时读取
问题来了:
B 是否应该看到 A 未提交的数据?
这就是 隔离性要解决的问题
十、事务隔离级别与更改
MySQL 提供了四种隔离级别:
| 隔离级别 | 特点 |
|---|---|
| Read Uncommitted | 可以读未提交数据 |
| Read Committed | 只能读已提交数据 |
| Repeatable Read | 可重复读(MySQL默认) |
| Serializable | 串行执行 |
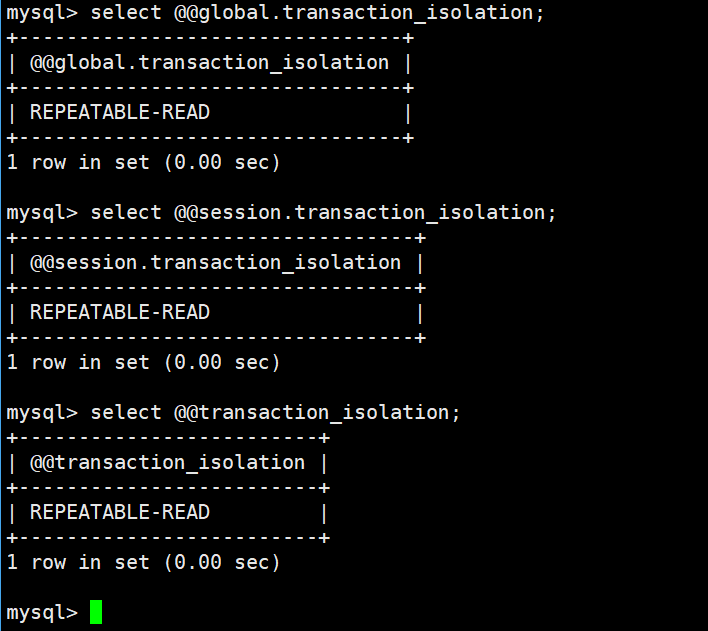
如何查看当前是什么隔离级别呢:
| 写法 | 含义 |
|---|
|----------------------------------|------|
| @@global.transaction_isolation | 全局默认 |
|-----------------------------------|------|
| @@session.transaction_isolation | 当前连接 |
|---------------------------|----------|
| @@transaction_isolation | 当前连接(简写) |
如何更改呢:
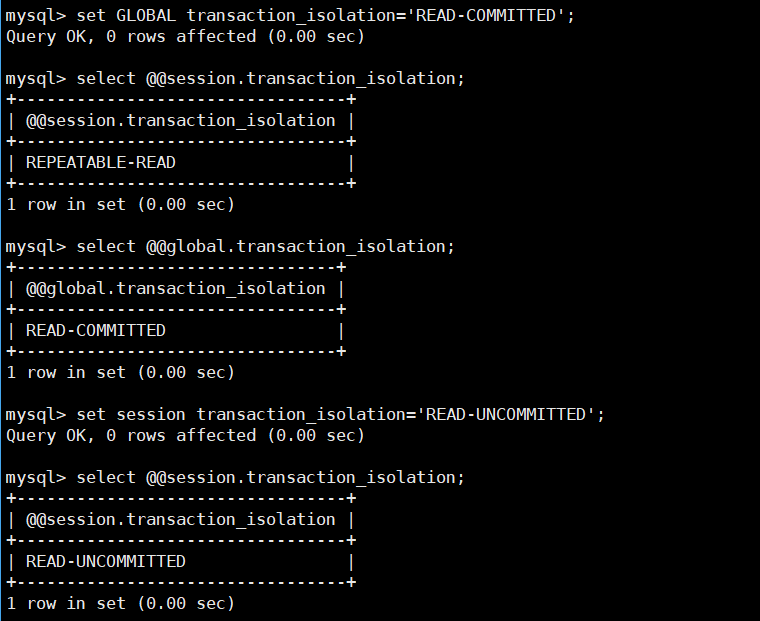
下次进入MySQL就会默认成为global.transaction_isolation设置的状态
十一、Read Uncommitted(读未提交)
特点:
可以读取其他事务未提交的数据
这会导致:
脏读(Dirty Read)
示例:
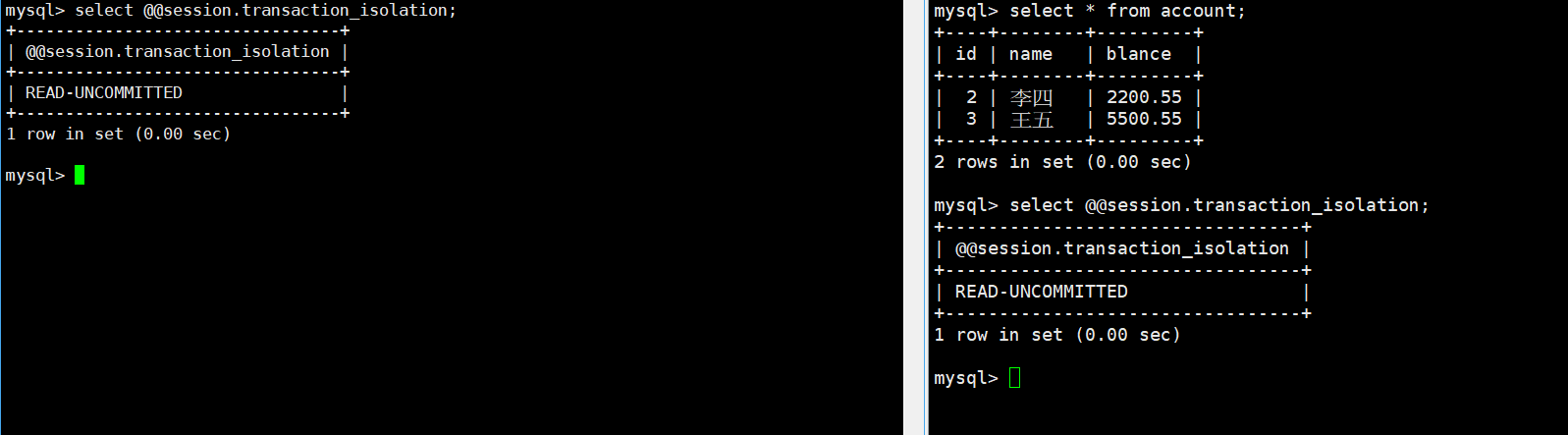
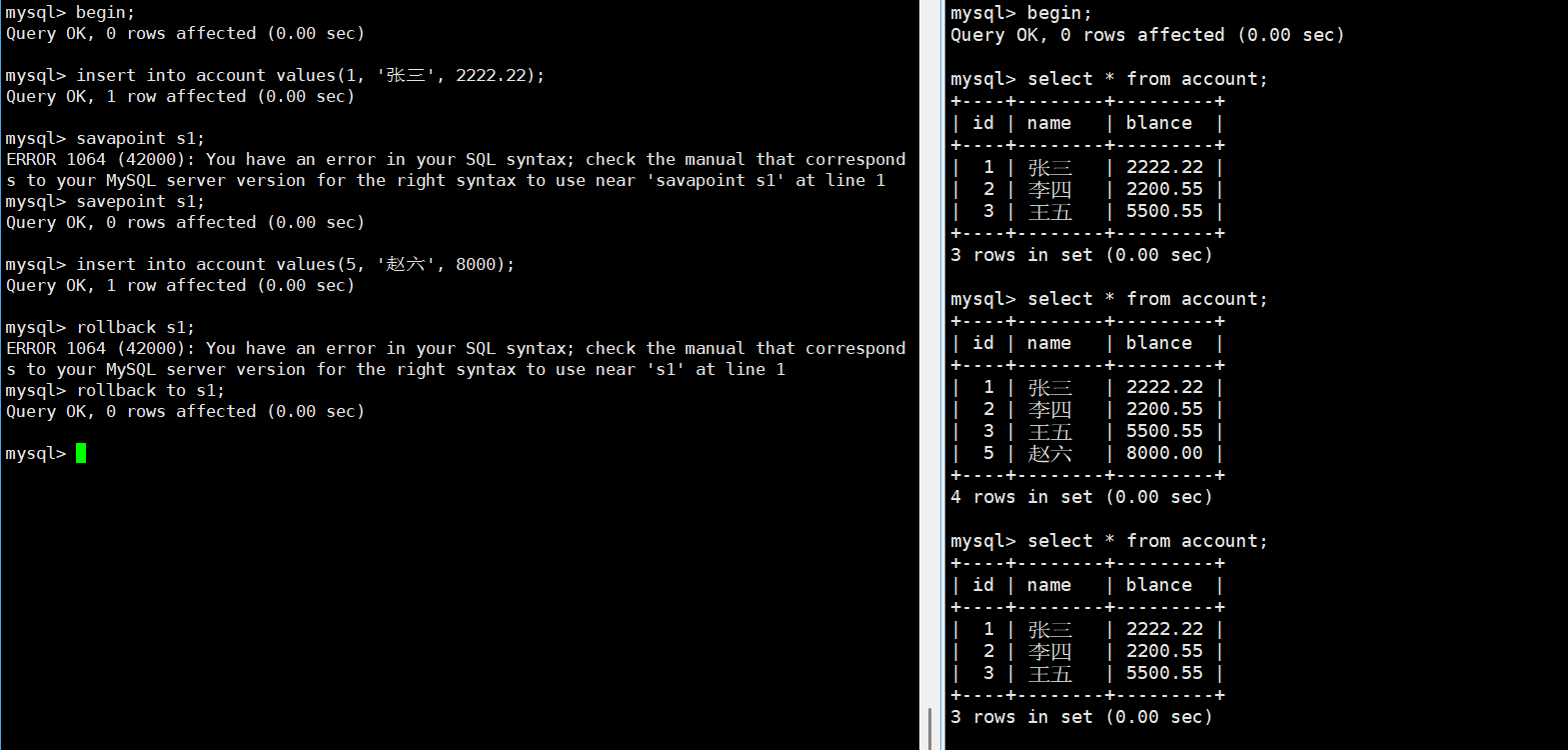
B(右边) 读到了 A(左边) 未提交的数据
如果 A 回滚:
B 读到的是"错误数据"
总结
- 几乎没有隔离
- 性能高
- 风险极大
- 实际生产基本不用
十二、Read Committed(读已提交)
特点:
只能读取 已经提交的数据
解决的问题
✔ 避免脏读
仍然存在的问题
不可重复读(Non-repeatable Read)
示例:
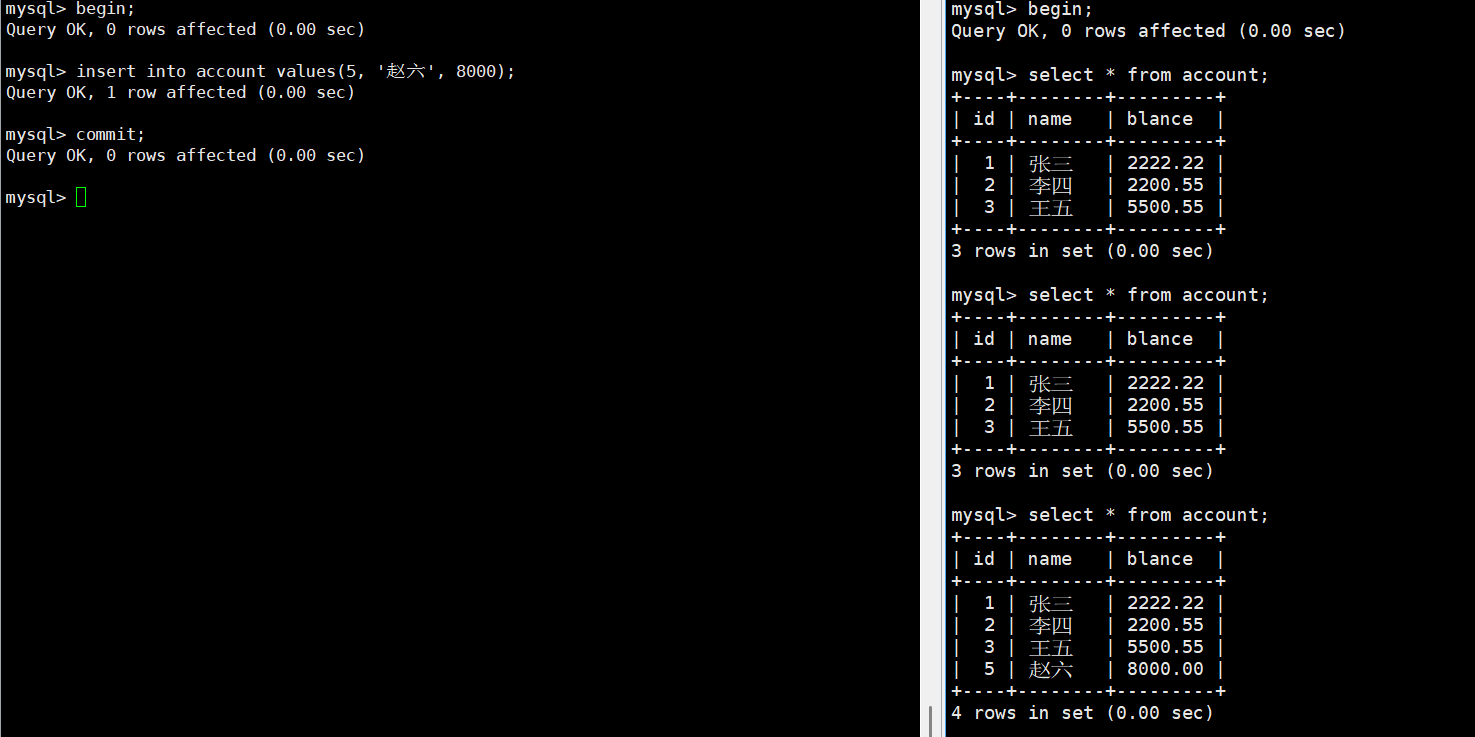
同一个事务中,两次读取结果不同
原因
因为:
每次 SELECT 都读取"最新已提交数据"
总结
| 特性 | 是否支持 |
|---|---|
| 脏读 | ❌ 不会发生 |
| 不可重复读 | ✅ 会发生 |
| 幻读 | ✅ 可能发生 |
十二、小结
到目前为止,我们已经掌握:
事务基础
- 什么是事务
- ACID特性
- 事务操作(BEGIN / COMMIT / ROLLBACK)
事务行为
- 自动提交 vs 手动提交
- 崩溃回滚机制
- 单条SQL本质也是事务
隔离性核心问题
- 并发访问带来的数据问题
两种隔离级别
- Read Uncommitted(脏读)
- Read Committed(解决脏读,但有不可重复读)
下一部分,我们将进入:
Repeatable Read(可重复读)与MVCC机制
这是 MySQL 中的核心内容,我们下一篇博客不见不散啦~~