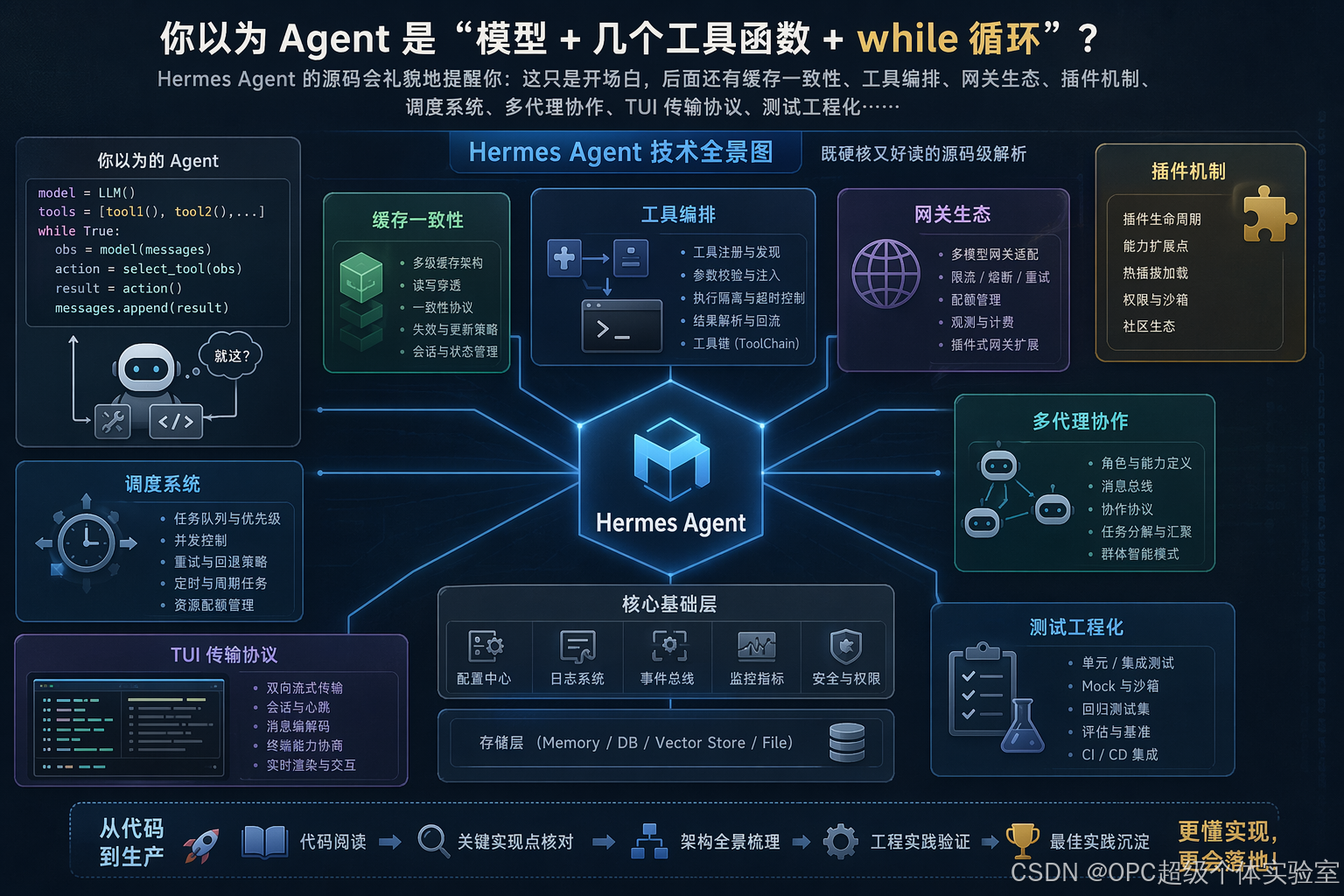
你以为 Agent 是"模型 + 几个工具函数 + while 循环"?
Hermes Agent 的源码会礼貌地提醒你:这只是开场白,后面还有缓存一致性、工具编排、网关生态、插件机制、调度系统、多代理协作、TUI 传输协议、测试工程化......
本文基于项目代码阅读与关键实现点核对,做一次"既硬核又好读"的技术全景解析。
一、先给结论:Hermes Agent 到底解决了什么问题?
如果你做过 AI 应用,应该很熟悉这三个痛点:
-
能力碎片化:聊天在一个地方,自动化在另一个地方,消息平台再来一套,最后系统像贴满便利贴的冰箱门。
-
会话不连续:每次重启都像失忆;要么上下文爆炸贵到心疼,要么历史信息压缩后"灵魂出窍"。
-
可扩展性虚高:口头上"插件化",实际每加一个能力都得改核心代码,越改越脆。
Hermes Agent 的核心价值,不是"它支持多少模型",而是它把 AI Agent 这件事做成了一个可长期运行、可持续进化、可跨平台协作 的工程系统。
从代码层看,它把"对话智能体"拆成了 8 个可以独立演进的子系统:
-
代理主循环(
run_agent.py) -
工具发现与分发(
model_tools.py+tools/registry.py) -
工具集策略层(
toolsets.py) -
命令中枢(
hermes_cli/commands.py+cli.py) -
消息网关(
gateway/) -
插件与记忆后端(
plugins/+agent/memory_manager.py) -
调度与协作(
cron/+kanban) -
终端 UI 双端架构(
ui-tui/+tui_gateway/)
一句话总结:
Hermes Agent 不是"单体聊天机器人",而是"可部署的 Agent 运行时平台"。
二、项目全景:它的技术框架不是"多",而是"有秩序"
很多项目喜欢堆关键词:CLI、Gateway、Plugin、Memory、Scheduler......看起来热闹,实际耦合复杂。Hermes 的有趣之处在于,它把这些组件做成了分层协同,而不是"混搭大杂烩"。
2.1 运行主轴:AIAgent 驱动一切
核心类 AIAgent 在 run_agent.py。它的 run_conversation() 不是简单"请求模型 -> 返回文本",而是一个完整的策略循环:
-
构建消息上下文
-
调用模型
-
识别工具调用
-
执行工具
-
写回工具结果
-
根据预算和迭代规则继续或收敛
这里最有工程味道的一点,是它把预算 和迭代 做成了显式边界。
主循环条件包含 max_iterations、iteration_budget.remaining 以及一次"grace call"兜底。这意味着它在架构层承认并处理了现实问题:模型不是每轮都能一次答对,工具链也不是每步都稳定。
2.2 工具系统:注册与暴露是两道门
tools/registry.py 负责"工具注册",toolsets.py 负责"工具授权可见"。
这在源码层是非常关键的架构选择:
-
discover_builtin_tools()会扫描tools/*.py,发现顶层registry.register(...)的模块并导入,完成"能力声明"。 -
但模型真正能看到的 schema,要经过
get_tool_definitions()按 toolset 组合后再输出。
这就像公司门禁:你有员工工牌(已注册)不代表你能进所有机房(已授权)。
2.3 命令系统:单一注册中心,避免多端分裂
hermes_cli/commands.py 的 COMMAND_REGISTRY 是命令"唯一事实来源"。
CLI、网关帮助、自动补全、平台映射都从这个注册表派生,而不是各写一份配置。
这个设计有两个好处:
-
减少维护漂移:新增命令只改一处,系统自动同步到多个消费端。
-
保证行为一致 :
resolve_command()同时支持名称和别名,不会出现"CLI 能用、网关失效"的经典事故。
2.4 网关层:同一代理,多平台接入
gateway/run.py 的 GatewayRunner 聚合平台适配器(Telegram、Slack、Discord、Signal、Email 等)。
这意味着 Hermes 的运行方式不是"为每个平台重写一个 bot",而是"平台只负责接入,代理逻辑统一复用"。
从工程视角看,这是"控制面统一,接入面分离"。
2.5 插件层:让扩展先于改核心
hermes_cli/plugins.py 提供通用插件发现与生命周期钩子,plugins/memory/ 则是记忆后端的专用插件体系。
官方思路很明确:能插件化就不要硬编码进核心。
这对长期维护非常关键。你现在可能觉得"改核心快",半年后会发现"每次升级都要拆雷"。
2.6 TUI 双进程:UI 与 Agent 解耦
ui-tui(Node/Ink)与 tui_gateway(Python)通过 JSON-RPC over stdio 通信。
这是一个非常现代的终端应用设计:UI 可以高频迭代,Agent 引擎保持稳定,两边边界清晰、故障隔离更好。
三、核心架构深潜:主循环为什么"看起来慢",其实是"故意稳"
很多人看 Agent 循环会问:为什么这么多判断?能不能"更快更短"?
答案是:能,但你会在生产环境里付出代价。
3.1 预算控制:不是为了省 token,而是为了防失控
run_conversation() 的迭代预算,不只是成本控制,更是防止以下问题:
-
工具反复失败导致死循环
-
模型在复杂任务上过度试探
-
单次会话长时间占用资源,影响并发
这类"软死锁"在 Demo 阶段不明显,一上生产就会频繁出现。Hermes 把它做成框架级规则,属于典型"早投资、少还债"。
3.2 中断能力:AI 系统必须支持"人类随时插话"
主循环中存在中断检查与活动触达更新。
它保证一个现实需求:当用户说"停一下,别删库了",系统要真的能停,而不是"等我跑完这个 60 秒命令先"。
这看似普通,实际上是很多 AI 工具最容易翻车的交互缺陷。
3.3 /steer 机制:把"微调方向"做成一等能力
Hermes 有个很实用的设计:/steer。
它不是粗暴打断当前执行,而是在下次 API 调用前将引导消息注入到合适位置(优先工具消息后),尽可能不破坏对话角色序列。
这背后体现的是一个成熟观念:
用户对 Agent 的控制,不应只有"开始/停止",还要有"中途导向"。
3.4 API 消息副本策略:缓存一致性的关键一招
api_messages 与持久 messages 分离,是 Hermes 非常值得学习的细节。
-
发送给模型前,可以临时注入记忆提示、插件上下文、缓存控制字段。
-
但这些注入不必污染会话存储,避免后续缓存前缀失效或语义偏移。
如果你做过高并发 LLM 系统,就会知道这有多重要:
"看起来一样的 prompt",只要前缀稍有波动,缓存命中率就会掉到怀疑人生。
3.5 确定性 call_id:细节里的工程尊严
工具调用 ID 若随机生成,会让请求前缀每轮变化,影响缓存稳定。
Hermes 在代码中明确采用确定性方案,这是那种"没有它系统也能跑,但有了它系统更像产品"的细节。
四、工具框架拆解:从"工具多"到"工具可治理"
AI Agent 的工具能力常见三种灾难:
-
工具名越来越乱,模型经常调用错。
-
环境不满足时还暴露 schema,导致调用必失败。
-
说明文案交叉引用不存在工具,引发幻觉调用。
Hermes 的治理方式,可以浓缩成四个词:发现、裁剪、门控、分发。
4.1 发现:自注册 + 自动导入
工具文件在顶层调用 registry.register(),再由 discover_builtin_tools() 扫描导入。
这减少了"新增工具忘记接线"的概率,开发体验更顺滑。
4.2 裁剪:toolset 作为策略层
toolsets.py 中,工具按场景打包(如 web、terminal、skills、kanban 等),支持 includes 组合。
启用/禁用发生在策略层,不需要删工具代码。
这让运营策略和实现逻辑解耦:
同一套引擎,企业 A 只开只读工具,企业 B 开自动化工具,代码都不用改。
4.3 门控:check_fn 拦住"明知不可用"的能力
例如某些工具依赖外部环境、token 或特定运行上下文(如 Kanban worker 环境变量)。
check_fn 能在 schema 暴露前提前过滤,避免模型"看见但用不了"。
4.4 分发:统一入口处理错误与扩展钩子
handle_function_call() 做了很多"你平时不想写,但线上必须有"的事:
-
参数预处理
-
插件前置拦截(可 block)
-
调用耗时统计
-
错误统一包装
这意味着业务工具实现可以专注本身,不必每个工具都复制异常处理模板。
五、命令系统:为什么说它是"交互层的中台"?
命令系统看起来像"UI 功能",其实它是协同运行时策略的重要一环。
5.1 单一注册中心,解决的是组织复杂度
COMMAND_REGISTRY 并不炫技,但它解决了一个团队协作的大问题:
新功能接入路径统一,评审和测试边界明确。
当命令分散在多个文件时,代码会慢慢出现:
-
文档与实现不一致
-
别名冲突
-
平台分支行为分裂
Hermes 的做法是"入口统一 + 派生结构自动生成"。
5.2 活跃会话旁路:避免"命令被吞"这类隐蔽 Bug
系统里明确维护了 active session bypass 逻辑,防止运行中命令被错误排队或丢弃。
这一块看似边角,实则关系到用户信任:你发了 /stop,系统如果不马上停,体验会直接塌。
5.3 命令不仅是控制台语法,更是产品能力映射
从命令列表可以看出 Hermes 的能力边界已经超出聊天:
-
/cron:定时作业 -
/kanban:多代理协作板 -
/curator:技能生命周期维护 -
/reload-mcp:外部能力热更新
这说明它在产品定位上已经不是"问答助手",而是"AI 自动化操作系统"。
六、网关架构:多平台消息入口如何不把系统拖垮?
"一个机器人对接十个平台"听起来很爽,但工程上最容易变成事故现场。
Hermes 网关的可取之处,是它坚持了适配器分层与统一调度。
6.1 适配器职责单一
gateway/platforms/base.py + 各平台实现文件,强调的是:
-
平台协议差异在适配器里吸收
-
业务流程和 agent 调度不散落到平台代码里
这就是经典"变化隔离"。
6.2 GatewayRunner 统一编排
GatewayRunner 管理消息处理流程与会话状态,典型链路包括:
-
接收平台消息
-
命令识别
-
活跃会话处理
-
调用 agent
-
回传结果
你可以把它理解为"Agent API 网关 + 会话路由器"。
6.3 插件前置拦截让治理更灵活
pre_gateway_dispatch 钩子允许在消息进入核心流程前做 rewrite/skip。
这非常适合企业场景中的审计、策略过滤、灰度控制。
七、插件与记忆:Hermes 的"长期主义"体现在哪?
短期看,插件像"可选功能";长期看,它决定了你的系统能不能健康迭代。
7.1 通用插件:功能扩展不污染主干
hermes_cli/plugins.py 支持多来源插件发现(仓库内、用户目录、项目目录、pip entry points)。
并提供生命周期钩子(如 tool 调用前后、LLM 调用前后、会话生命周期等)。
它的意义在于:
复杂需求可以外挂,不必每次都去改 run_agent.py 或 cli.py。
7.2 记忆插件:把"长期上下文"做成可替换后端
plugins/memory/ 是专门的内存后端扩展面,MemoryManager 负责统一编排。
源码中对外部 provider 数量、流式记忆片段清洗等都有明确约束。
这说明 Hermes 对"记忆"不是停留在概念层,而是认真处理了三个现实问题:
-
多后端冲突
-
输出污染(记忆片段泄漏)
-
运行时性能
7.3 为什么说这比"把历史全塞 prompt"更高级?
因为它承认并解决了两个事实:
-
上下文窗口是有限且昂贵的
-
长期记忆需要检索策略,而不是机械拼接
所以 Hermes 的思路不是"多喂点历史",而是"在正确时机喂正确信息"。
八、调度系统:Cron 与 Kanban 不是附属功能,而是第二增长曲线
很多 Agent 项目只做到"有人提问我回答"。
Hermes 明显在走更高一层:无人值守自动化 + 多代理协同生产。
8.1 Cron:把一次性能力变成持续价值
cron/scheduler.py 体现的关键设计:
-
tick.lock防止并发 tick -
作业工具集可精细裁剪
-
skip_memory=True避免 cron 任务污染用户主会话心智模型 -
基于"无活动超时"而不是一刀切 wall-clock
这说明它针对生产环境中的"挂死任务、假成功、隐性资源占用"做了直接治理。
8.2 Kanban:多代理协作不是"并发调用 API"那么简单
Kanban 模块的价值在于任务边界与隔离:
-
worker 启动时注入任务/板级环境变量
-
工具层检查 task ownership,避免越权修改其他任务
-
dispatcher 循环推进任务状态
这比"开几个线程跑子任务"成熟得多。
因为协作系统的核心不是并发,而是状态一致性和责任清晰。
九、TUI 架构:终端也可以有"前后端分离"
9.1 JSON-RPC over stdio 的现实意义
ui-tui 与 tui_gateway 采用换行分隔 JSON-RPC 通信。
这带来的好处:
-
协议可测试、可演进
-
UI 与引擎独立崩溃域
-
不同客户端(stdio / WebSocket)可复用同一 dispatch 语义
一句人话:
你的终端 UI 不再是"黑盒脚本",而是有契约的客户端。
9.2 为什么不是"全 Python 一把梭"?
可以,但会牺牲交互层迭代速度与生态。
Node/Ink 在终端交互体验上更灵活,Python 侧保留 agent 核心逻辑,两边各做擅长的事,这就是工程上的"专业分工"。
十、配置与测试体系:决定项目能不能"久跑不崩"
10.1 配置加载是三套路径,不是一把钥匙
Hermes 同时存在 CLI、框架级与网关场景的配置读取路径。
这提醒我们:新增配置项时,不只改默认值,还要确认它在不同运行面都可见。
10.2 Profile 机制:多实例隔离不是"多份配置文件"那么浅
通过尽早设置 HERMES_HOME,让配置、记忆、会话、日志等都按 profile 隔离。
这是面向团队/多租户/多业务环境非常实用的能力。
10.3 测试脚本的"强约束"值得抄作业
scripts/run_tests.sh 强制:
-
统一 worker 数
-
统一时区与 locale
-
清理 credential 类环境变量
-
统一入口执行 pytest
这类约束会减少"本地过、CI 挂"的无效沟通,属于工程效率放大器。
十一、怎么用起来?从 0 到 1 的实战路径(Windows 用户友好版)
说明:Hermes 官方建议在 Linux/macOS/WSL2 环境运行。
你是 Windows 用户的话,最佳实践是 WSL2 里部署,IDE 可以继续用 Windows 侧。
11.1 基础启动链路
-
进入项目并安装依赖(或按官方安装脚本)
-
配置模型提供商
-
启动 CLI(
hermes) -
根据业务启用工具集(
hermes tools) -
需要多平台消息接入时启动 gateway
11.2 日常高频命令思路
-
hermes model:模型切换与验证 -
hermes tools:按场景启停工具集 -
hermes gateway:消息入口编排 -
/compress:长会话上下文治理 -
/cron:将一次性流程转定时任务 -
/kanban:复杂协作任务拆解与跟踪
11.3 什么时候该用插件而不是改核心?
满足任一条件就建议插件化:
-
需求只服务于你的组织,不具备普适性
-
迭代频率高,随业务变化快
-
需要快速试错,不能频繁动核心链路
一句调侃:
改核心像"动承重墙",插件像"换家具"------前者要审批,后者要审美。
十二、三类典型应用场景:把源码能力变成业务价值
场景 A:企业内部智能运维与日报自动化
目标:每天 9 点自动生成系统健康日报并推送到 Slack/Telegram。
可落地链路:
-
通过
cron创建每日任务 -
任务中调用终端/检索工具采集指标
-
汇总后由消息网关推送指定频道
-
出现异常时可触发审批或人工接管
为什么靠谱:
Cron 的活动超时与失败守卫避免"卡死还显示成功"的伪稳定。
场景 B:个人开发者"全天候编程搭子"
目标:在 CLI/TUI 中连续开发,跨会话保留习惯与上下文。
可落地链路:
-
开启技能与记忆能力
-
在复杂任务后沉淀技能模板
-
用
/compress管理长上下文成本 -
必要时用
delegate_task并行处理子任务
为什么好用:
主会话与临时注入上下文分离,既能"记住你",又不至于"记忆污染"。
场景 C:多团队项目交付(Kanban + 子代理)
目标:把一个大任务拆成多个可并行子任务,自动汇总状态。
可落地链路:
-
在 Kanban 中建立主任务与子任务关系
-
dispatcher 自动 claim 与派发
-
worker 基于任务所有权执行并回写状态
-
orchestrator 汇总结果并生成交付报告
为什么可控:
worker 受任务与板级环境约束,不会乱改隔壁任务。
十三、从架构视角看 Hermes 的"高级感"到底在哪?
这里给出 10 条我认为最值得借鉴的设计判断:
-
把缓存一致性当一等公民,而不是性能优化的附属品。
-
把工具注册和工具暴露分离,减少"声明即授权"的风险。
-
命令系统中心化,避免多端行为漂移。
-
网关层只做适配与编排,不吞业务逻辑。
-
插件优先于核心硬编码,给演进留出空间。
-
记忆采用检索与注入策略,而不是上下文无限堆叠。
-
调度系统显式处理失败与锁,避免"快乐路径幻觉"。
-
多代理协作强调所有权与隔离,而不只是并发数量。
-
UI 与引擎协议化通信,提高可维护性和可替换性。
-
测试运行环境工程化约束,把一致性写进脚本而不是写进口号。
十四、常见误区与避坑指南(非常实用)
误区 1:新增工具后,模型却调用不到
原因通常是:你只做了 registry.register(),没把工具放进对应 toolset。
解决:检查 toolsets.py 以及启用/禁用配置。
误区 2:网关里插件逻辑不生效
原因可能是发现时机问题。
解决:确认插件发现路径与加载时序,必要时显式 discover。
误区 3:长会话越来越贵,回答质量还下降
原因往往是上下文治理策略缺失。
解决:使用压缩、记忆检索注入、明确任务边界,不要无限堆历史。
误区 4:多代理"看起来很忙",结果不可控
原因是只有并发,没有状态规范。
解决:用 Kanban 的任务模型、所有权约束、生命周期信号。
误区 5:测试总是本地过 CI 挂
原因是环境不一致。
解决:统一用 scripts/run_tests.sh,不要各自"自由发挥"。
十五、未来趋势:Hermes 这类架构会往哪走?
结合当前源码形态与行业方向,我判断未来会沿着五条线增强:
15.1 工具调用将进入"策略编排时代"
不是"模型想调谁就调谁",而是根据任务类型、成本预算、风险等级动态编排。
Hermes 已有 toolset 与 check_fn 基础,下一步会是更细粒度策略引擎。
15.2 记忆系统会从"可用"走向"可解释"
未来不仅要能注入记忆,还要回答"为什么注入这条、没注入那条"。
这对企业审计与高风险场景非常重要。
15.3 多代理协作会标准化接口
Kanban 已展示任务模型雏形。后续趋势是跨系统协作协议化,让不同 agent runtime 能互通任务状态与责任链。
15.4 Gateway 会成为 AI 的"统一入口层"
平台越来越多,业务不会愿意多套逻辑重复开发。
统一网关 + 平台适配器的模式会成为标配。
15.5 终端 UI 会继续向"可编程客户端"演进
TUI 与 WebSocket 共用 JSON-RPC dispatch 的思路,天然支持多终端共享同一核心能力。
将来你会看到更多"一个 Agent 内核,多形态前端"。
十六、给开发者的落地建议(拿来就能用)
如果你准备二次开发 Hermes 或借鉴其架构,建议按这个顺序推进:
-
先确定运行边界:单机、团队内网、云端多租户?
-
再定义工具策略:默认开哪些 toolset,哪些必须审批?
-
然后做插件扩展:优先插件化,不急着改核心。
-
最后做自动化调度:从一个 cron 任务开始,逐步扩展。
工程上最怕的不是"慢",而是"快但返工"。
Hermes 的设计给我们的最大启发是:
先把演进路径设计出来,再让功能增长。
十七、写给普通读者:看不懂代码也能理解这件事
你可以把 Hermes 想成一家"超级自动化公司":
-
run_agent.py是总经理,负责决策循环; -
工具系统是各部门员工;
-
toolset 是权限系统;
-
gateway 是客服与渠道团队;
-
plugin 是外部顾问;
-
cron 是日程秘书;
-
kanban 是项目管理办公室;
-
TUI 是前台大屏。
真正厉害的公司,不是员工会聊天,而是流程能跑、知识能留、系统能扩、风险可控。
Hermes 正在做的,就是把这些"公司治理能力"移植到 AI Agent 里。
十八、结语:当我们谈 Agent 架构时,我们到底在谈什么?
不是在谈"模型参数有多大",也不是在谈"能连多少 API"。
我们真正该谈的是:
-
它能否稳定运行?
-
能否长期进化?
-
能否被团队协作?
-
能否在成本与风险之间找到平衡?
Hermes Agent 的源码给出了一个很务实的答案:
把 Agent 当系统工程做,而不是当提示词魔法做。
这也是它最值得技术人深入研究的地方。
附录 A:适合 CSDN 发布的摘要文案(可选)
这不是一篇"AI Agent 入门科普",而是一篇"源码级工程拆解"。
从
run_agent.py主循环到工具注册分发,从网关适配到插件机制,从 cron 调度到 kanban 多代理协作,再到 TUI JSON-RPC 双端通信,完整呈现 Hermes Agent 如何从"会聊天"走向"可长期运行的 AI 自动化平台"。适合:架构师、AI 工程师、平台工程团队、想搭建企业级 Agent 基础设施的技术负责人。
附录 B:建议配图清单(发布时可补)
-
架构总览图:AIAgent / Tool Registry / Gateway / Plugins / Scheduler / TUI
-
工具调用时序图:模型响应 -> tool_calls -> dispatch -> tool result -> next turn
-
多平台接入图:Telegram/Slack/Discord -> GatewayRunner -> AIAgent
-
多代理协作图:Kanban dispatcher -> worker agents -> task state transitions
-
配置隔离图:profiles 与
HERMES_HOME的关系
如果你愿意,我可以下一步直接给你生成:
-
一版"更偏面试与简历输出"的 3000 字精华版;
-
一版"偏 CTO 决策"的架构评估版(含成本、风险、ROI);
-
一版"偏实操教程"的从安装到跑通的图文版(按 Windows + WSL2 路线)。