1.概述
Linux 的性能问题,依赖于各类性能工具,针对不同性能场景,选择合适的工具,可以大大提高整个性能优化的效率,下图是性能问题和工具图谱:
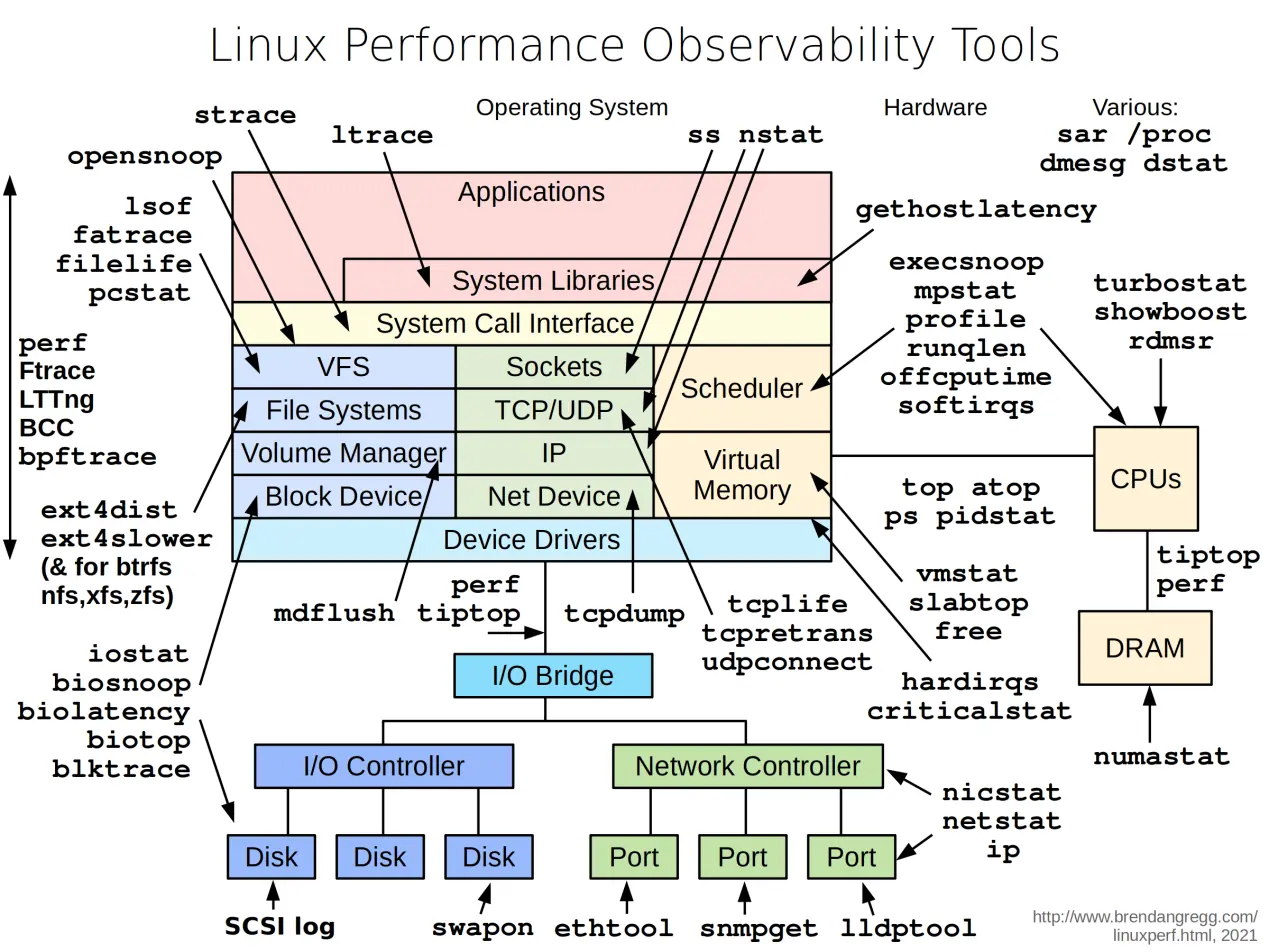
受限本文篇幅和侧重,结合征程系列 SoC 调优实践,主要展开介绍下面的工具及使用。
1.1. top
top 命令可以动态地持续监听系统及进程的运行状态,为用户提供 CPU 使用率、内存使用情况、CPU 负载信息,除此之外,该命令还提供了一个交互界面,用户可以根据需要进行调整。
- 通过 top 命令分析内存使用状态比较简单清晰,本文就不做赘述。
- 由于智能驾驶的应用场景复杂,CPU 处于较高水平的逻辑和运算占用,导致系统的负载和使用率长期处于较高水平,是性能优化的主要方向之一。
注:
智能驾驶应用场景中系统负载是和使用率同步升高,基本不存在 IO 或其他导致的负载提升,所以本文提到的负载和使用率的描述均可理解为使用率。
使用 top 命令监控系统及各进程的 CPU 使用率,是分析 CPU 占用高问题的主要方法,在使用前需要了解 top 的原理和限制,从而正确的使用和提取有效信息,进行有效分析。
1.1.1. top 的原理
top 命令的实现是通过采样 proc 下系统和进程的 stat 下的各类时间信息,经过计算得出来的平均使用率等信息。
- CPU 时间信息(单位为 jiffies):

- /proc/stat
记录了 CPU 从系统启动开始累计到当前时刻各类事件信息。
- /proc/$PID/stat
记录了进程从启动开始累计到当前时刻各类事件信息。
- 使用率计算方法
stat 节点记录了的是从开机/进程启动后累计的时间信息,但这不能体现在当前时间段的实际负载情况,实际 CPU 使用率的计算方法如下(system、user、irq、softirq 等类似):
采样的开始时间 T1,结束时刻 T2:
- Total(T1-T2) = (user2+ nice2+ system2+ idle2+ iowait2+ irq2+ softirq2) - ( user1+ nice1+ system1+ idle1+ iowait1+ irq1+ softirq1)
- Idle(T1-T2) = (idle2 - idle1)
- CPU Usage (T1-T2) = 1 - Idle / Total
不难理解,最终 CPU 使用率主要受到从 CPU 获取到的时间信息,和采样周期时间的影响。
1.1.2. top 的限制
- CPU 负载显示模式
Linux 上 top 命令的 CPU 占用率显示有两种模式:
- Irix 模式,按单个 CPU 上的算力计算。
- Solaris 模式,按所有 CPU 做平均计算。
例如一个 8 核系统,CPU0 上一个进程 CPU 占用率是 100%,其它 CPU 是 idle:
- Irix 模式,CPU0 占用显示 100%,进程的 CPU 也是 100%。
- Solaris 模式,CPU0 占用显示 12.5%,进程的 CPU 也是 12.5%。
当前 Busybox 的 top 命令,PER CPU 的显示默认是 Irix 模式,进程显示是 Solaris 模式。
- top 周期的选定
CPU 的使用率受到周期的影响,在 CPU 繁忙时使用"top -d1"和"top -d5"的结果差异是非常大的,周期越大,越接近实际平均负载。 考虑这样的一种极端场景,在 1s 的时间内,前 100ms 负载 100%,后 900ms CPU 全部 idle,以 1s 为周期,负载就是 10%,以 100ms 为周期,负载就出现了 100% 的情况,基于以上情况考虑,我们一般建议以 5s 作为 top 的周期("top -d5")。
另外,需要特别注意的是,top 命令适用于长时间的负载检测,对于一次性负载检查("top -n1"),top 实现中第一次 top 计算的周期是 200ms,以 200ms 周期计算出来的 CPU 使用率非常不准,会对整体分析产生误导。
- CPU 使用率中包含 iowait
一般理解中 CPU 使用率是指 CPU 忙占 CPU 总时间的比值,处于 iowait 的线程实际并不占用 CPU,但是目前几乎所有的统计工具中,都把 iowait 统计到 CPU 使用率中。
1.1.3. top 的使用
征程系列系统软件默认集成了 top 命令,使用方法如下:
Plain
Usage:
top [options]
Options:
-b, --batch-mode run in non-interactive batch mode
-c, --cmdline-toggle reverse last remembered 'c' state
-d, --delay =SECS [.TENTHS] iterative delay as SECS [.TENTHS]
-E, --scale-summary-mem =SCALE set mem as: k,m,g,t,p,e for SCALE
-e, --scale-task-mem =SCALE set mem with: k,m,g,t,p for SCALE
-H, --threads-show show tasks plus all their threads1.2. df
用于显示系统磁盘使用情况,当磁盘/文件系统快满的时候,文件系统及磁盘硬件性能都会受到影响。
1.3. free&procrank
- free 用于显示系统级内存使用情况,通过/proc/meminfo 可检查系统内存使用的细节。
- procrank 用于显示系统各进程的内存使用情况,查找内存使用超载或泄漏进程。
- 当内存紧张时,系统性能表现将会受到较大影响,iowait 的提升也会导致 CPU 使用率也会明显上升。
1.4. Perf
Perf 是内置于 Linux 内核源码树中的性能剖析(profiling)工具,作为一款强大的综合性分析工具,能够提供从硬件到软件、从应用到内核的全栈性能分析方法,常用于性能瓶颈的查找与热点代码的定位。
1.4.1. Perf 原理
Perf 工具功能强大,通过下面的软、硬件能力实现性能 profiling。
- Hardware Event 由 PMU 部件产生,在特定的条件下探测性能事件是否发生以及发生的次数。比如 cache 命中。
- Software Event 是内核产生的事件,分布在各个功能模块中,统计和操作系统相关性能事件。比如进程切换,tick 数等。
- Tracepoint Event 是内核中静态 tracepoint 所触发的事件(ftrace),这些 tracepoint 用来判断程序运行期间内核的行为细节,perf 在这种应用场景下,可理解为 ftrace 的一种前端工具。
1.4.2. Perf 使用
Perf 命令非常多,每个命令下又有很多子命令,所以本文只针对性介绍一些常用命令。
1.4.2.1. perf list
查看当前系统软、硬件支持的性能事件。
1.4.2.2. perf stat
统计 cache、branch、context-switches 等软硬件底层性能指标。
- 使用 ctrl+c 退出。
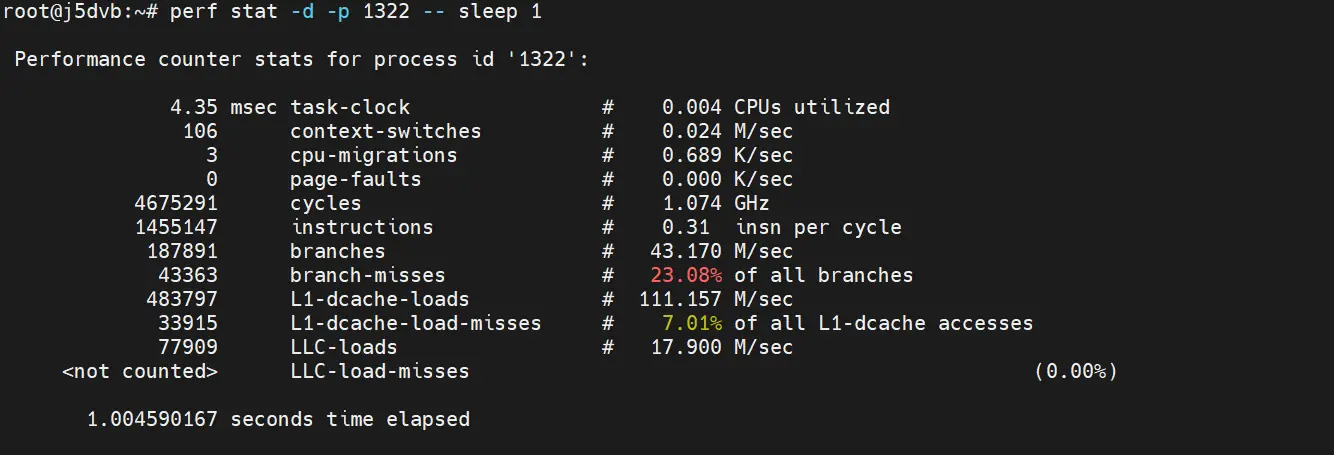
- perf stat -p 追踪指定进程的性能指标:
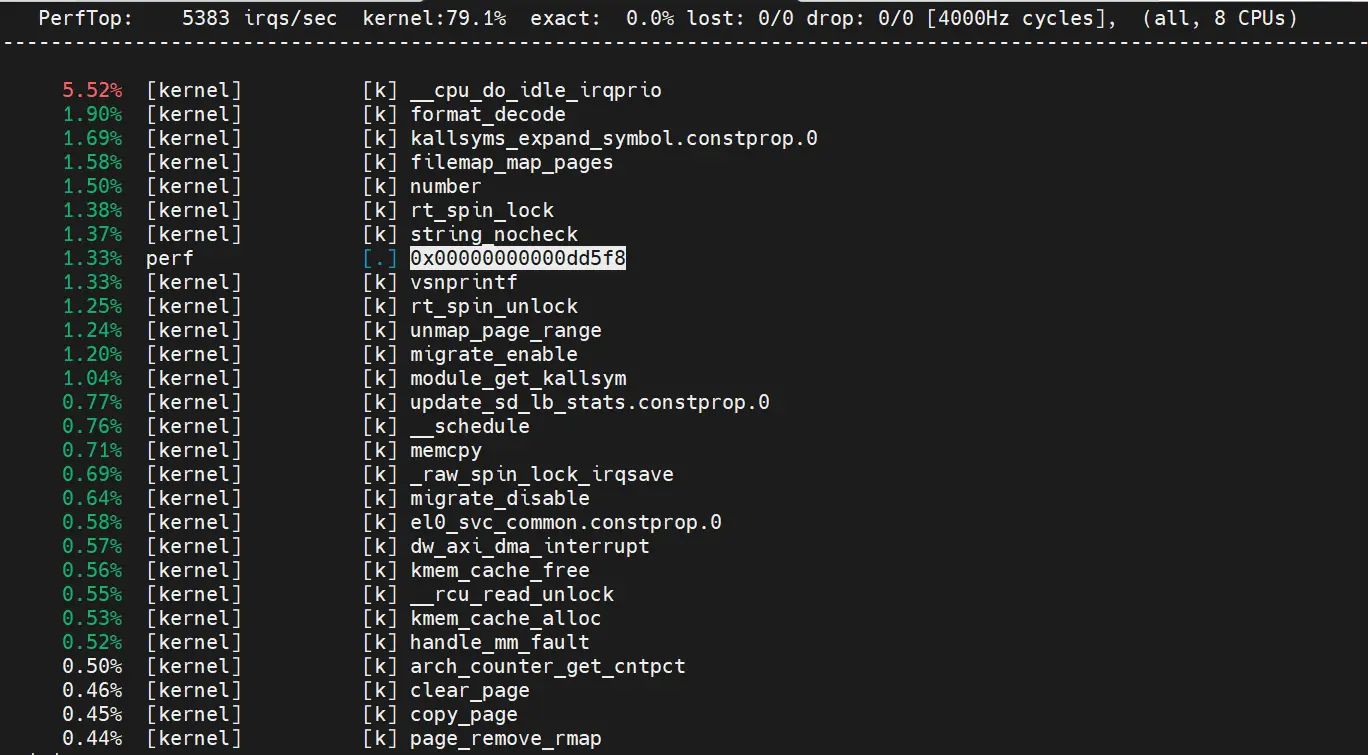
1.4.2.3. perf top
- 实时查看当前系统中所有(kernel,app)函数占用率情况,及 irq 统计。
- "perf top -U",U 统计 kernel 中符号占用率。
- "perf top -K",K 统计应用符号占用率。
- "perf top -p ",统计制定进程的符号占用情况。
- "perf top -g",记录占用率的同时保存函数调用栈情况。
- "perf top -s dso",以 library&executed 进行占用排序。
- "perf top -s pid",以 pid 进行占用排序。
1.4.2.4. perf sched
- perf sched 依赖开启 ftrace,用于统计分析调度相关信息。
- perf sched record -p ,可抓取指定进程调度信息。
- perf sched latency --sort max,对 record 的数据进行 runtime、delay 等时间分析。
- perf sched timehist -wM,对 record 的数据进行调度时延的分析。
Plain
root@hobot:~# perf sched record -- sleep 1
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 1.066 MB perf.data (7233 samples) ]
root@hobot:~#
root@hobot:~# perf sched latency --sort max
-------------------------------------------------------------------------------------------------------------------------------------------
Task | Runtime ms | Switches | Avg delay ms | Max delay ms | Max delay start | Max delay end |
-------------------------------------------------------------------------------------------------------------------------------------------
sleep:2329 | 1.120 ms | 1 | avg: 0.000 ms | max: 0.000 ms | max start: 0.000000 s | max end: 0.000000 s
rcuc/9:92 | 0.002 ms | 1 | avg: 0.000 ms | max: 0.000 ms | max start: 0.000000 s | max end: 0.000000 s1.4.2.5. 火焰图
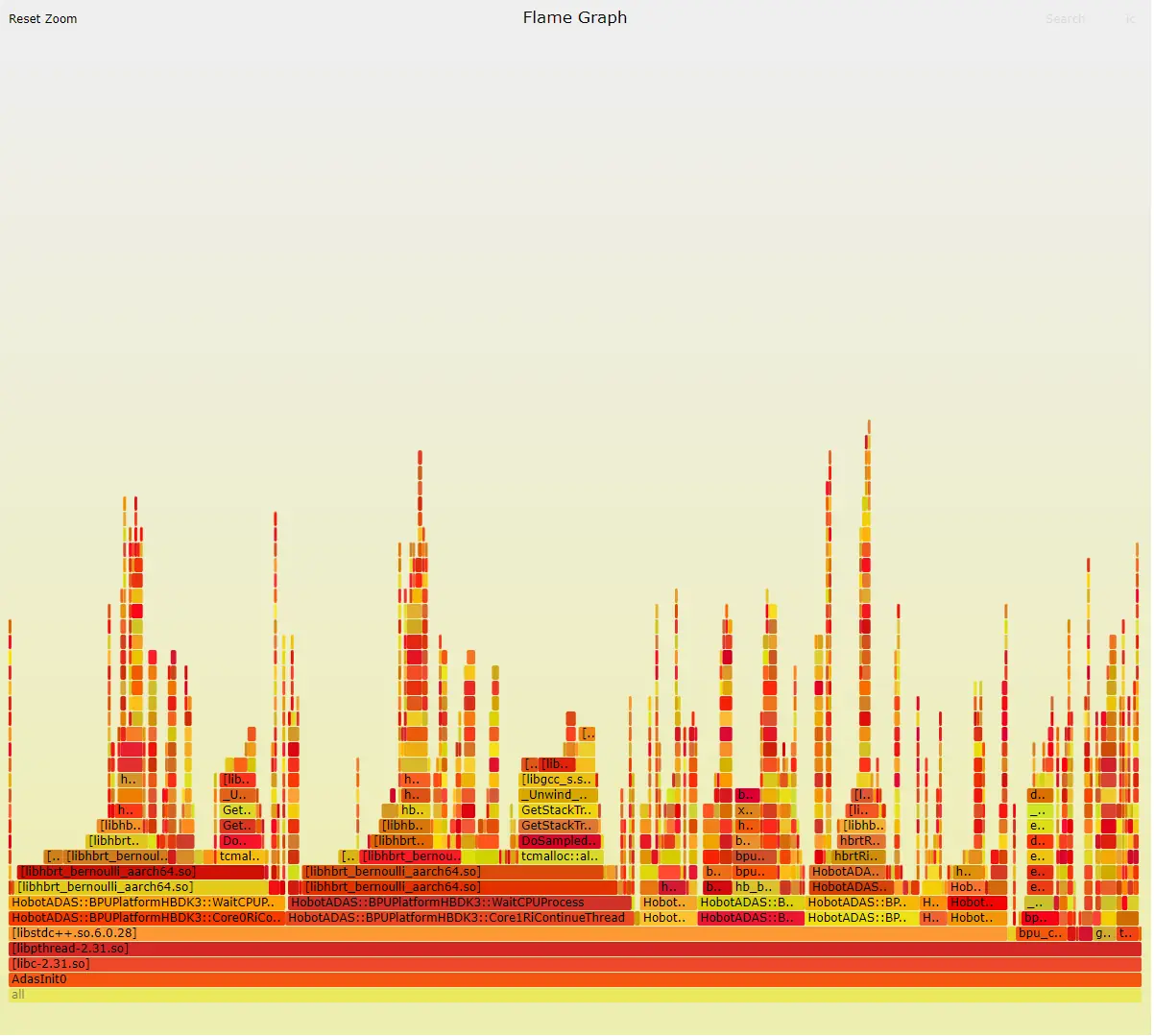
火焰图是分析系统、进程热点的强大工具,原理是通过 PMU 对 CPU 当前运行符号(PC)进行采样,再通过火焰图工具还原整个调用栈。
通过火焰图可以查看 kernel+app 的调用栈耗时状态,查找性能瓶颈。
- perf record -g -p ,记录系统/进程的堆栈采样数据,默认 perf.data。
- perf script > perf.unflod,对 record 的调用栈等信息进行解析。
- 将 perf.unflod 导入 PC 机,使用火焰图工具出解析 perf.svg。
- FlameGraph/stackcollapse-perf.pl perf.unflod FlameGraph/flamegraph.pl > perf.svg. FlameGraph 工具从 github.com/brendangreg... 获取。
- 使用 chrome 浏览器打开。
1.5. Ftrace 功能
Ftrace 功能的作用是帮助开发人员了解 Linux 内核的运行时行为,以便进行故障调试或性能分析。
- Ftrace 通过静态和动态插装,实现对内核核心及热点函数的 profiling,对于调度、io 等问题是最重要的分析手段。
- Ftrace 需要使能内核 CONFIG_FTRACE,当前默认打开。
- Ftrace 使用 per-cpu 的 ring-buffer,内容为二进制格式,执行效率高。设置 CONFIG_DYNAMIC_FTRACE 后,加入的 trace 功能在不使用时对运行时系统性能几乎没有影响(初始化会对开机时间有一定影响),动态使能 ftrace 后,对运行时性能会有一定副作用。
- Ftrace 的调度 profiling 在内核中对热点函数大量埋点,导致系统会在几秒内产生百兆以上的 log,通过 log 直接分析性能难度较大,所以一般会引入一些 ftrace 前端工具。
- perf、trace-cmd、systemtap、bcc、kernelshark 都是优秀的 ftrace 前端工具。可以通过这些工具去分析 ftrace 日志。