PyTorch强化学习实战(6)------交叉熵方法详解与实现
0. 前言
我们已经学习了PyTorch 的基础知识。本节将介绍强化学习 (Reinforcement Learning, RL) 方法中的一种重要技术:交叉熵法。
尽管交叉熵方法在 RL 中的知名度不及深度Q网络 (Deep Q-Network, DQN) 或优势演员-评论家 (Advantage Actor-Critic, A2C) 等方法,但它具有独特优势。首先,交叉熵方法实现极其简单------其 PyTorch 实现甚至不足 100 行代码,这使其成为最易上手的 RL 方法之一。
其次,该方法具有出色的收敛性。在那些不需要学习复杂多步策略、且具有短周期高频奖励的简单环境中,交叉熵法通常表现优异。虽然许多实际问题并不符合这些特征,但对于符合条件的场景(无论是独立应用还是作为大型系统的一部分),交叉熵法往往是最佳选择。
1. 强化学习方法的分类
交叉熵方法属于无模型 (model-free)、基于策略 (policy-based) 和同策略 (on-policy) 的方法类别。
强化学习方法有三大分类标准:
- 无模型 (
model-free) 或基于模型 (model-based) - 基于价值 (
value-based) 或基于策略 (policy-based) - 同策略 (
on-policy) 或异策略 (off-policy)
虽然还有其他方式 RL 分类方法,但上述三类最为关键,问题的具体特性会影响方法的选择。
"无模型"意味着该方法不构建环境或奖励的模型;它只是直接将观察结果与动作(或与动作相关的值)联系起来。换句话说,智能体获取当前观察结果并对其进行一些计算,计算结果就是它应该采取的动作。相比之下,基于模型的方法试图预测下一个观察结果和/或奖励会是什么。基于这种预测,智能体尝试选择可能采取的最佳动作,通常会多次进行此类预测,逐步展望未来的多个步骤。
这两种方法各有优缺点,但纯粹的基于模型的方法通常用于确定性环境,例如具有严格规则的棋盘游戏。另一方面,无模型方法通常更容易训练,因为很难为具有丰富观察结果的复杂环境构建良好的模型。最近,研究人员开始将两种方法的优势结合起来(例如,AlphaGo Zero 和 MuZero 方法对棋盘游戏和 Atari 采用了基于模型的方法)。
基于策略的方法直接近似智能体的策略,即智能体在每一步应该执行什么动作。策略通常表示为可用动作的概率分布。另一种方法是基于价值的方法。在这种情况下,智能体不是计算动作的概率,而是计算每个可能动作的价值,并选择具有最佳价值的动作。
异策略是指该方法能够从历史数据中学习(由智能体的先前版本获得、通过人类演示记录或由同一智能体在几轮前看到的数据)策略更新当前策略。而同策略方法需要用当前策略生成的数据更新当前策略。它们无法在旧的历史数据上进行训练,更新一次策略后,旧数据立即失效,必须重新采样,这使得此类方法的数据效率较低(需要与环境进行更多的交互),但在某些情况下,这不是问题(例如,如果环境非常轻量级且快速,可以快速与其交互)。
因此,交叉熵方法是无模型、基于策略和同策略,这意味着:
- 它不构建环境模型;它只是告诉智能体在每一步该做什么
- 它近似智能体的策略
- 它需要从环境中获得的新数据
2. 交叉熵方法在实践中的应用
交叉熵方法的解释可以分为两部分:实际应用和理论部分。实际应用直观易懂,而关于交叉熵方法为何有效及其背后原理的理论解释则更为复杂。因此,本节首先介绍交叉熵方法的实际应用,并在最后介绍其理论背景。
强化学习中最核心的部分在于智能体------它试图通过与环境的交互来积累尽可能多的总奖励。实践中,我们遵循常见的机器学习思路,用一个非线性可训练函数替代智能体的所有复杂性,该函数将智能体的输入(来自环境的观察结果)映射为某种输出。此函数输出的具体细节取决于特定方法或方法类别(如基于价值的方法或基于策略的方法)。
由于交叉熵方法是基于策略的,因此非线性函数(神经网络)会产生策略,本质上即为每个观察结果指明智能体应采取的动作。策略用 π ( a ∣ s ) \pi(a | s) π(a∣s) 表示,其中 a a a 表示动作, s s s 表示当前状态。下图展示了这一过程:
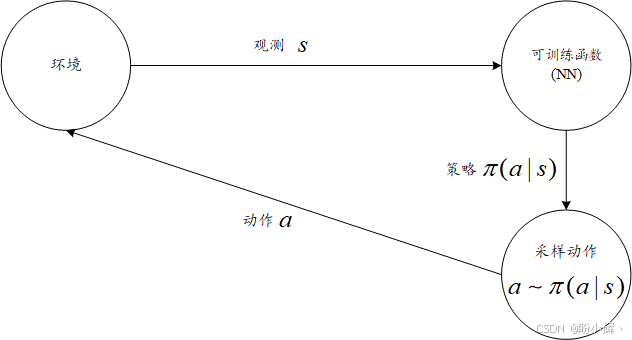
简而言之,交叉熵方法通过直接优化策略(动作概率分布)来指导智能体决策,而无需建模环境动态。其优势在于简单高效,尤其适用于动作空间离散且环境反馈明确的场景。
实践中,策略通常表现为动作的概率分布------这与分类问题非常相似,其类别数量等同于可执行动作的数量。
这种抽象化设计使得智能体极为简洁:只需将环境观测输入神经网络,获取动作概率分布,再通过随机抽样确定待执行动作。这种随机性机制为智能体注入了探索能力,这在训练初期尤为重要------当网络权重尚未优化时,智能体本质上处于随机行为状态。确定动作后,智能体将其反馈至环境,继而获取新观测值及上一步动作的奖励。如此循环往复(如下图所示)。
智能体的交互经验以"回合"为单位组织。每个回合包含观测序列、执行动作序列及对应奖励序列。假设智能体已完成若干回合,我们可以计算每个回合获得的总奖励。总奖励可以是使用折扣因子的,也可以是不使用折扣因子的;为了简单起见,我们假设折扣因子 γ = 1 \gamma = 1 γ=1,这意味着所有局部奖励的不做衰减处理。该总奖励直观反映回合对智能体而言的优劣程度。如下图所示,其中包含了四个回合(不同回合的观测值 o i o_i oi、动作 a i a_i ai 及奖励 r i r_i ri 的值存在差异):
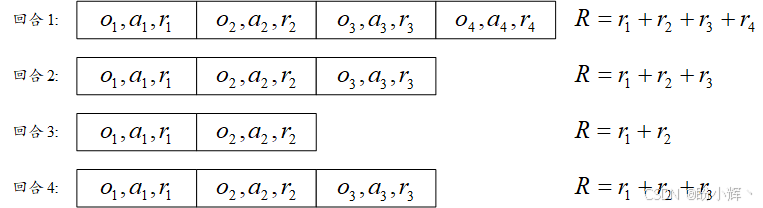
每个单元格代表智能体在回合中的一步。由于环境随机性及智能体动作选择策略的差异,某些回合的表现会优于其他回合。交叉熵方法的核心思想是舍弃劣质回合,仅用优质回合进行训练。其具体实施步骤如下:
- 采样阶段:使用当前模型与环境交互,生成
N个回合数据 - 评估筛选:计算每个回合的总奖励,设定奖励阈值(通常取所有奖励的分位数,如
50%或70%) - 精英筛选:丢弃所有奖励低于阈值的回合
- 策略优化:以剩余"精英回合"的观测数据为输入,对应动作为目标输出,训练神经网络
5.循环迭代:重复上述过程直至达到预期效果
通过这种机制,神经网络逐步学会复现高奖励动作,从而持续提升奖励阈值。虽然方法简单,但其在简单环境中表现良好,容易实现,对超参数变化具有强鲁棒性,因此是一种理想的基准方法。接下来我们将该方法应用于 CartPole 平衡杆环境进行实践验证。
3. 交叉熵方法在 CartPole 中的应用
(1) 我们的模型采用单隐藏层神经网络,使用 ReLU 激活函数和隐藏层使用 128 个神经元。其他超参数虽未经严格调优,但由于方法本身具备强鲁棒性和快速收敛性,仍能取得良好效果。定义常量:
python
import numpy as np
import gymnasium as gym
from dataclasses import dataclass
import typing as tt
from torch.utils.tensorboard.writer import SummaryWriter
import torch
import torch.nn as nn
import torch.optim as optim
HIDDEN_SIZE = 128
BATCH_SIZE = 16
PERCENTILE = 70常量包括隐藏层神经元的数量 (128)、每次迭代时运行的回合数 (16) 以及用于精英回合筛选的每个回合总奖励百分位阈值 (70)。我们采用第 70 百分位意味着将保留按奖励排序前 30% 的优质回合。
(2) 该神经网络结构设计简明,输入层接收环境观测向量( CartPole 的 4 维状态数据),输出层生成每个可选动作(左/右移动)的原始评分:
python
class Net(nn.Module):
def __init__(self, obs_size: int, hidden_size: int, n_actions: int):
super(Net, self).__init__()
self.net = nn.Sequential(
nn.Linear(obs_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, n_actions)
)
def forward(self, x: torch.Tensor):
return self.net(x)神经网络的输出是动作的概率分布,因此一种直接的处理方式是在最后一层后加入 softmax 非线性变换。然而在代码实现中,我们并未应用 softmax 以提升训练过程的数值稳定性。相较于先计算 softmax (涉及指数运算)再计算交叉熵损失(涉及概率对数运算),后续我们将直接使用 PyTorch 的 nn.CrossEntropyLoss 类------它将 softmax 与交叉熵合并为单个数值稳定性更高的运算表达式。CrossEntropyLoss 要求输入神经网络输出的原始未归一化值(亦称 logits)。这种方式的缺点在于,每当需要从神经网络输出获取概率时,必须手动应用 softmax 变换。
(3) 定义两个辅助数据结构类:
python
@dataclass
class EpisodeStep:
observation: np.ndarray
action: int
@dataclass
class Episode:
reward: float
steps: tt.List[EpisodeStep]这些数据类的作用如下:
EpisodeStep:用于表示智能体在单次回合中的一个步骤,存储了环境观测值和智能体执行的动作。我们将从精英回合中提取这些单步记录作为训练数据Episode:存储一个完整的回合,包括该回合的总非折现奖励 (total undiscounted reward) 以及由多个EpisodeStep组成的集合
(4) 定义用于生成回合批次数据的函数:
python
def iterate_batches(env: gym.Env, net: Net, batch_size: int) -> tt.Generator[tt.List[Episode], None, None]:
batch = []
episode_reward = 0.0
episode_steps = []
obs, _ = env.reset()
sm = nn.Softmax(dim=1)上述函数接收三个参数:环境( Gym 库中的 Env 类实例)、神经网络、以及每次迭代需要生成的回合数。变量 batch 用于累积批次数据(即由多个 Episode 实例组成的列表)。我们还声明了记录当前回合奖励的计数器,以及存储单步记录的列表(由 EpisodeStep 对象构成)。
(5) 接着,我们重置环境以获取初始观测值,并创建一个 softmax 层------用于将神经网络的输出转换为动作的概率分布。至此准备工作就绪。这些准备工作完成后,接下来进入环境交互循环:
python
while True:
obs_v = torch.tensor(obs, dtype=torch.float32)
act_probs_v = sm(net(obs_v.unsqueeze(0)))
act_probs = act_probs_v.data.numpy()[0]在每次迭代中,我们将当前观测值转换为 PyTorch 张量并输入神经网络以获取动作概率。需要注意的是:
PyTorch中所有nn.Module实例都期望接收批次数据,本节的神经网络也不例外。因此我们将观测值(在CartPole环境中是包含四个数字的向量)转换为1×4大小的张量,在张量上调用unsqueeze(0)函数,添加一个额外的维度- 由于我们未在神经网络输出端使用非线性激活函数,网络输出的是原始动作分数,需要通过
softmax函数进行处理 - 神经网络和
softmax层返回的张量都带有梯度追踪功能,因此我们需要通过访问tensor.data字段来解包,然后将张量转换为NumPy数组。该数组会保持与输入相同的二维结构(批次维度位于axis 0),所以需要获取第一个批次元素来得到一维的动作概率向量
(6) 在获得动作概率分布后,就可以据此确定当前步骤要执行的具体动作:
python
action = np.random.choice(len(act_probs), p=act_probs)
next_obs, reward, is_done, is_trunc, _ = env.step(action)使用 NumPy 的 random.choice() 函数对概率分布进行采样。随后,我们将采样得到的动作输入环境,从而获取下一时刻的观测值 (next_observation)、奖励 (reward)、回合终止标志 (done) 以及截断标志 (truncated)。step() 函数返回的最后一个值是环境的附加信息,本节直接丢弃。
(7) 这一步的即时奖励会添加到当前回合的总奖励中,同时我们会在回合步骤列表 (episode_steps) 中追加一个 (observation, action) 对:
python
episode_reward += float(reward)
step = EpisodeStep(observation=obs, action=action)
episode_steps.append(step)需要注意的是,我们保存的是选择动作时使用的观测值,而非执行动作后环境返回的新观测值。
(8) 处理当前回合终止的情况(在 CartPole 环境中,回合结束的条件包括:杆子倾倒,或达到环境设定的时间上限):
python
if is_done or is_trunc:
e = Episode(reward=episode_reward, steps=episode_steps)
batch.append(e)
episode_reward = 0.0
episode_steps = []
next_obs, _ = env.reset()
if len(batch) == batch_size:
yield batch
batch = []将完成的回合添加到批次中,保存总奖励(因为回合已完成且已累计所有奖励)及已执行的步骤。接着重置奖励累计器并清空步骤列表。随后重置环境以重新开始。
当批次达到预设的回合数量时,使用 yield 将批次返回给调用者进行处理。该函数生成器函数,每次执行 yield 操作符时,控制权会转移至外部迭代循环,而后从 yield 语句之后继续执行。处理完成后,我们将清理当前批次。
(9) 循环中最后的步骤是:将从环境获取的新观察值赋给当前观察变量:
python
obs = next_obs之后,循环整个过程------我们将观察数据输入神经网络,采样要执行的动作,请求环境处理该动作,并记录处理结果。
iterate_batches() 函数逻辑中需要理解的一个关键点是:神经网络的训练与回合数据的生成是同步进行的。它们并非完全并行,但每当循环累积足够数量的回合( 16 个)时,就会将控制权移交给这个函数的调用者,调用者使用梯度下降训练神经网络。因此,当 yield 返回时,神经网络的策略行为将发生变化。交叉熵法属于同策略 (on-policy) 类算法,因此使用最新训练数据对方法效果至关重要。
(10) 由于训练与数据收集在同一线程中进行,因此不需要额外的同步。但需注意神经网络训练与应用之间的频繁切换。接下来我们还需定义另一个函数,之后便可转入训练循环:
python
def filter_batch(batch: tt.List[Episode], percentile: float) -> tt.Tuple[torch.FloatTensor, torch.LongTensor, float, float]:
rewards = list(map(lambda s: s.reward, batch))
reward_bound = float(np.percentile(rewards, percentile))
reward_mean = float(np.mean(rewards))该函数是交叉熵方法的核心------它根据给定的回合批次和百分位值,计算出边界奖励 (boundary reward),用于筛选出精英回合 (elite episodes) 进行训练。
为了获得边界奖励,我们将使用 NumPy 的 percentile 函数,该函数可以根据给定的数值列表和百分位数,计算出对应的百分位值。此外,我们还会计算平均奖励,该值仅用于监控训练过程。
(11) 接下来,对回合进行筛选:
python
train_obs: tt.List[np.ndarray] = []
train_act: tt.List[int] = []
for episode in batch:
if episode.reward < reward_bound:
continue
train_obs.extend(map(lambda step: step.observation, episode.steps))
train_act.extend(map(lambda step: step.action, episode.steps))对于批次中的每个回合,检查其总奖励是否高于边界值。若满足条件,则将该回合的观察值和动作存入列表,用于后续训练。
(12) 以下是函数 filter_batch() 的最终处理步骤:
python
train_obs_v = torch.FloatTensor(np.vstack(train_obs))
train_act_v = torch.LongTensor(train_act)
return train_obs_v, train_act_v, reward_bound, reward_mean将精英回合的观察值和动作转换为张量,并返回一个四元组:观察值张量、动作张量、奖励边界值和平均奖励值。后两个值不参与训练过程,仅用于写入 TensorBoard 以监控智能体表现。
(13) 整合所有组件:
python
if __name__ == "__main__":
env = gym.make("CartPole-v1")
assert env.observation_space.shape is not None
obs_size = env.observation_space.shape[0]
assert isinstance(env.action_space, gym.spaces.Discrete)
n_actions = int(env.action_space.n)
net = Net(obs_size, HIDDEN_SIZE, n_actions)
print(net)
objective = nn.CrossEntropyLoss()
optimizer = optim.Adam(params=net.parameters(), lr=0.01)
writer = SummaryWriter(comment="-cartpole")初始化阶段会创建所有必要对象:环境实例、神经网络、目标函数、优化器以及 TensorBoard 的记录器。
(14) 在训练循环中,遍历批次数据(由多个 Episode 对象组成的列表):
python
for iter_no, batch in enumerate(iterate_batches(env, net, BATCH_SIZE)):
obs_v, acts_v, reward_b, reward_m = filter_batch(batch, PERCENTILE)
optimizer.zero_grad()
action_scores_v = net(obs_v)
loss_v = objective(action_scores_v, acts_v)
loss_v.backward()
optimizer.step()使用 filter_batch 函数筛选精英回合 (elite episodes),得到观察值张量、执行动作张量、用于筛选的奖励边界值以及平均奖励值。随后,我们将神经网络的梯度归零,将观察值输入网络以获取动作评分 (action scores)。这些评分被传入目标函数,用于计算神经网络输出与智能体实际执行动作之间的交叉熵 (cross-entropy)。其核心思想是强化神经网络对那些能带来高回报的精英动作的学习。接着,我们计算损失函数的梯度,并通过优化器调整神经网络参数。
(15) 监控训练进度:
python
print("%d: loss=%.3f, reward_mean=%.1f, rw_bound=%.1f" % (
iter_no, loss_v.item(), reward_m, reward_b))
writer.add_scalar("loss", loss_v.item(), iter_no)
writer.add_scalar("reward_bound", reward_b, iter_no)
writer.add_scalar("reward_mean", reward_m, iter_no)在控制台上,显示当前迭代次数、损失值、批次平均奖励及奖励边界值。同时将这些数据写入 TensorBoard,以便可视化智能体学习性能。
(16) 循环中的最后一步是检查批次回合的平均奖励值:
python
if reward_m > 475:
print("Solved!")
break
writer.close()当平均奖励超过 475 时,我们将停止训练。在 CartPole-v1 环境中,当最近 100 个回合的平均奖励超过 475 时,即认为该任务已被解决。然而,交叉熵方法收敛得非常快,通常仅需约 100 个回合就能达标。经过良好训练的智能体理论上可以无限长时间保持杆子平衡(获得任意高分),但 CartPole-v1 环境将每个回合的最大步数限制为 500 步。考虑到这一点,当批次中的均值奖励超过 475 时终止训练,这充分证明智能体已掌握专业级的平衡技巧。训练过程输出结果如下所示:
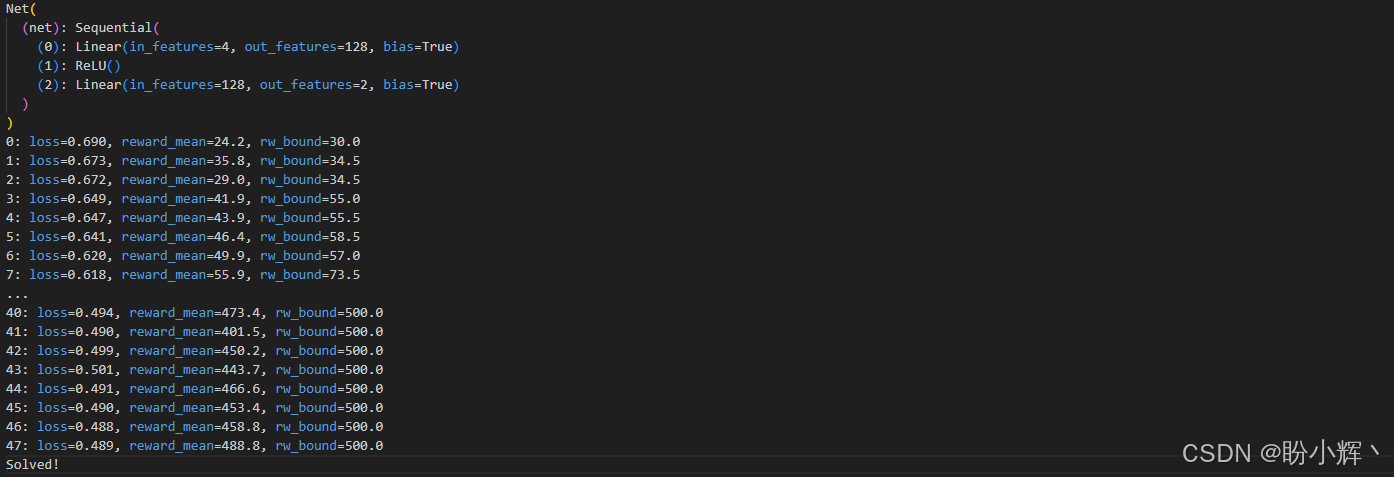
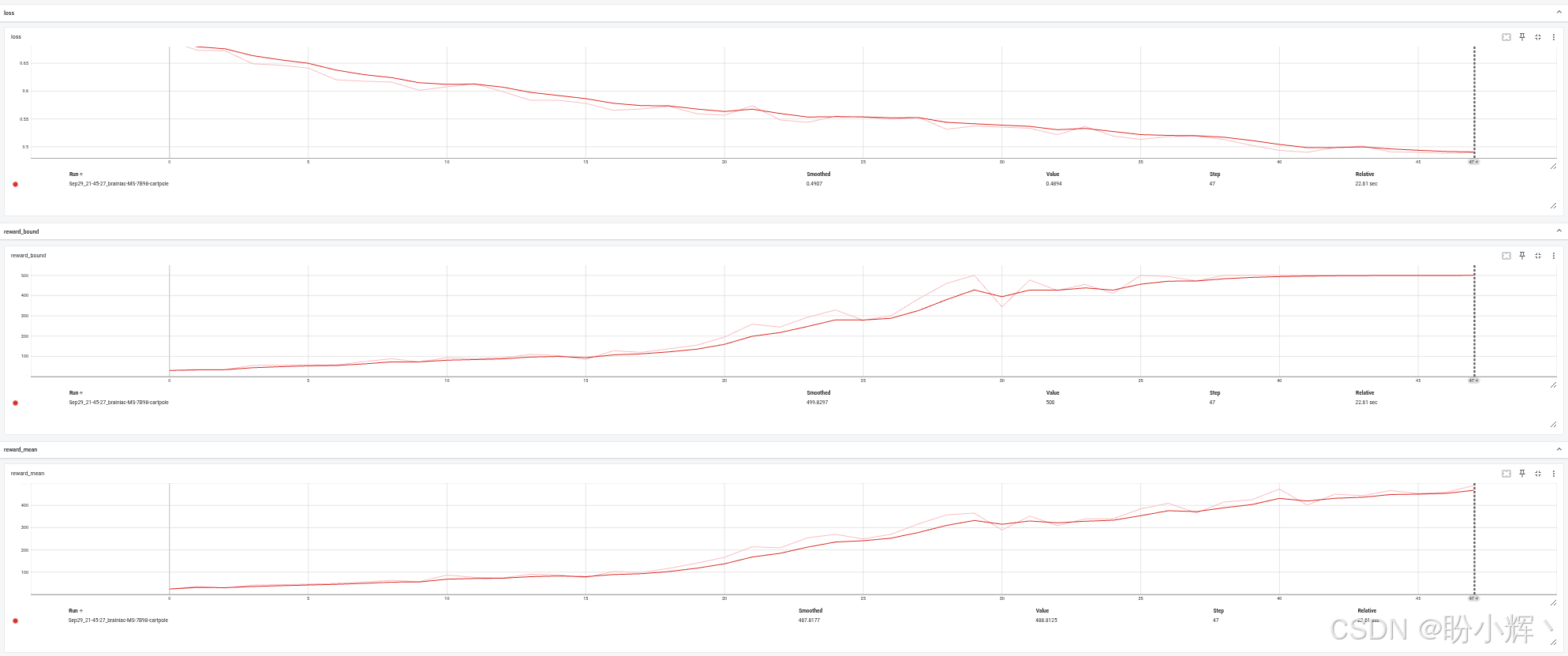
实际运行中,智能体通常能在 50 个批次内解决问题。实验表明,所需回合数在 30 至 60 次之间(每个批次仅需 16 个回合),表现出卓越的学习效率。TensorBoard 的监控数据显示,智能体的表现持续提升------几乎每个批次都能刷新奖励上限(虽然偶有波动,但总体呈上升趋势):
(17) 为了监控训练过程,可以通过设置 CartPole 环境中的渲染模式并添加 RecordVideo 包装器来调整环境创建:
python
env = gym.make("CartPole-v1", render_mode="rgb_array")
env = gym.wrappers.RecordVideo(env, video_folder="video")训练过程中,系统会自动创建视频目录并生成一系列 MP4 格式的训练过程记录,便于对比智能体的学习进展。生成的 MP4 视频内容如下所示:
神经网络学会了仅通过观察值和奖励信号就学会了如何应对环境,完全不需要对观测值进行任何人工解读。虽然本节使用平衡杆环境,但完全可以替换为其他场景,如以商品库存量为观察值、以营业收入为奖励的仓储模型。实现并不依赖于环境的具体细节,这正是强化学习模型的精妙之处。
4. 交叉熵方法的理论背景
交叉熵方法的核心建立在重要性采样定理之上,该定理表述如下:
E x ∼ p ( x ) H ( x ) = ∫ x p ( x ) H ( x ) d x = ∫ x q ( x ) p ( x ) q ( x ) H ( x ) d x = E x ∼ q ( x ) p ( x ) q ( x ) H ( x ) \begin{aligned} \mathbb E_{x\sim p(x)}H(x)&=\int_xp(x)H(x)dx=\int_xq(x)\frac {p(x)}{q(x)}H(x)dx \\ &=E_{x\sim q(x)}\\frac {p(x)}{q(x)}H(x) \end{aligned} Ex∼p(x)H(x)=∫xp(x)H(x)dx=∫xq(x)q(x)p(x)H(x)dx=Ex∼q(x)q(x)p(x)H(x)
在强化学习中, H ( x ) H(x) H(x) 表示策略x获得的奖励值, p ( x ) p(x) p(x) 是所有可能策略的分布。我们并不希望通过穷举所有策略来最大化奖励,而是试图通过 q ( x ) q(x) q(x) 来近似 p ( x ) H ( x ) p(x)H(x) p(x)H(x),并通过迭代最小化二者之间的距离。两个概率分布之间的距离通过 Kullback-Leibler (KL) 散度计算,其表达式为:
K L ( p 1 ( x ) ∣ ∣ p 2 ( x ) ) = E x ∼ p 1 ( x ) l o g p 1 ( x ) p 2 ( x ) = E x ∼ p 1 ( x ) l o g p 1 ( x ) − E x ∼ p 1 ( x ) l o g p 2 ( x ) \begin{aligned} KL(p_1(x)||p_2(x))&=E_{x\sim p_1(x)}log\frac {p_1(x)}{p_2(x)} \\ &=E_{x\sim p_1(x)}logp_1(x)-E_{x\sim p_1(x)}logp_2(x) \end{aligned} KL(p1(x)∣∣p2(x))=Ex∼p1(x)logp2(x)p1(x)=Ex∼p1(x)logp1(x)−Ex∼p1(x)logp2(x)
KL 散度的第一项称为熵,由于该项不依赖 p 2 ( x ) p_2(x) p2(x),在最小化过程中可省略。第二项即交叉熵,这正是深度学习中最常见的优化目标。
结合这两个公式,可以得到一个迭代算法,从 q 0 ( x ) = p ( x ) q_0(x) = p(x) q0(x)=p(x) 开始,每一步通过下式更新来改进对 p ( x ) H ( x ) p(x)H(x) p(x)H(x) 的近似:
q i + 1 ( x ) = a r g m i n q i + 1 ( x ) − E x ∼ q i ( x ) q ( x ) q i ( x ) H ( x ) l o g q i + 1 ( x ) q_{i+1}(x)=\underset {q_{i+1}(x)}{argmin} -\mathbb E_{x\sim q_i(x)}\frac {q(x)}{q_i(x)}H(x)logq_{i+1}(x) qi+1(x)=qi+1(x)argmin−Ex∼qi(x)qi(x)q(x)H(x)logqi+1(x)
这是一个通用的交叉熵方法,但在强化学习场景中可以大幅简化。将 H ( x ) H(x) H(x) 替换为指示函数------当回合奖励超过阈值时取值为 1,低于阈值时取值为 0。此时策略更新公式变为:
π i + 1 ( a ∣ s ) = a r g m i n π i + 1 − E z ∼ π i ( a ∣ s ) R ( z ) ≥ ψ i l o g π i + 1 ( a ∣ s ) \pi_{i+1}(a|s)=\underset {\pi_{i+1}}{argmin} -\mathbb E_{z\sim \pi_i(a|s)}R(z)\\geq\\psi_ilog\pi_{i+1}(a|s) πi+1(a∣s)=πi+1argmin−Ez∼πi(a∣s)R(z)≥ψilogπi+1(a∣s)
严格来说,上述公式省略了归一化项,但实践中仍能有效工作。该方法的核心逻辑非常清晰:我们使用当前策略(初始为随机策略)采样多个回合,然后通过最小化最成功样本与策略之间的负对数似然来优化策略。
小结
在本节中,介绍了交叉熵方法,尽管有其局限性但简单高效。我们将其应用于 CartPole 环境,并讨论了强化学习方法的分类体系------不同方法具有的特性差异将影响其适用场景。
系列链接
PyTorch强化学习实战(1)------强化学习(Reinforcement Learning,RL)详解
PyTorch强化学习实战(2)------强化学习环境库Gymnasium
PyTorch强化学习实战(3)------Gymnasium API扩展功能
PyTorch强化学习实战(4)------PyTorch基础
PyTorch强化学习实战(5)------PyTorch Ignite 事件驱动机制与实践