✍✍计算机毕设指导师**
⭐⭐个人介绍:自己非常喜欢研究技术问题!专业做Java、Python、小程序、安卓、大数据、爬虫、Golang、大屏等实战项目。
⛽⛽实战项目:有源码或者技术上的问题欢迎在评论区一起讨论交流!
⚡⚡有什么问题可以在主页上或文末下联系咨询博客~~
⚡⚡Java、Python、小程序、大数据实战项目集](https://blog.csdn.net/2301_80395604/category_12487856.html)
⚡⚡文末获取源码
温馨提示:文末有CSDN平台官方提供的博客联系方式!
温馨提示:文末有CSDN平台官方提供的博客联系方式!
温馨提示:文末有CSDN平台官方提供的博客联系方式!
诺贝尔学奖可视化分析系统-简介
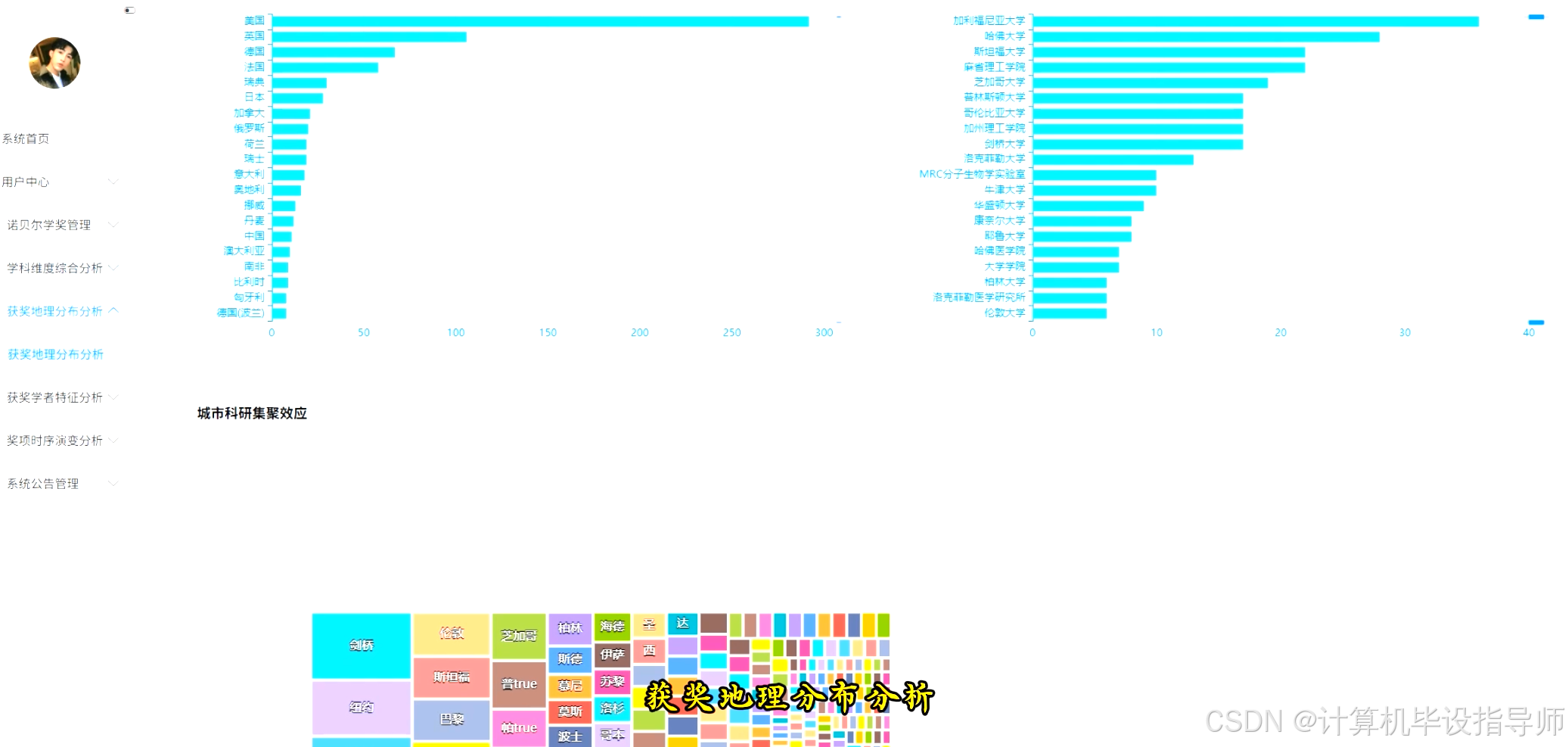
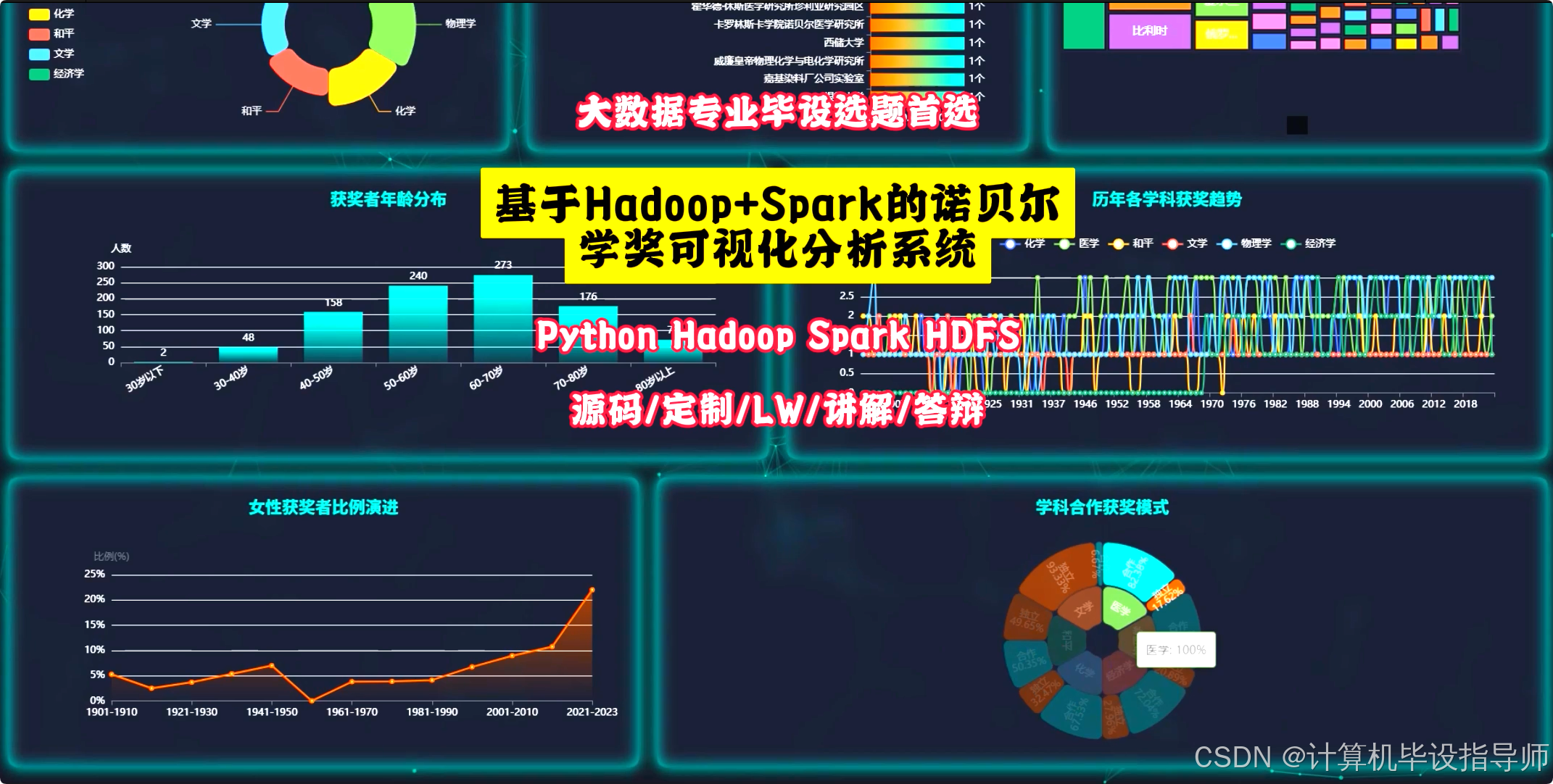
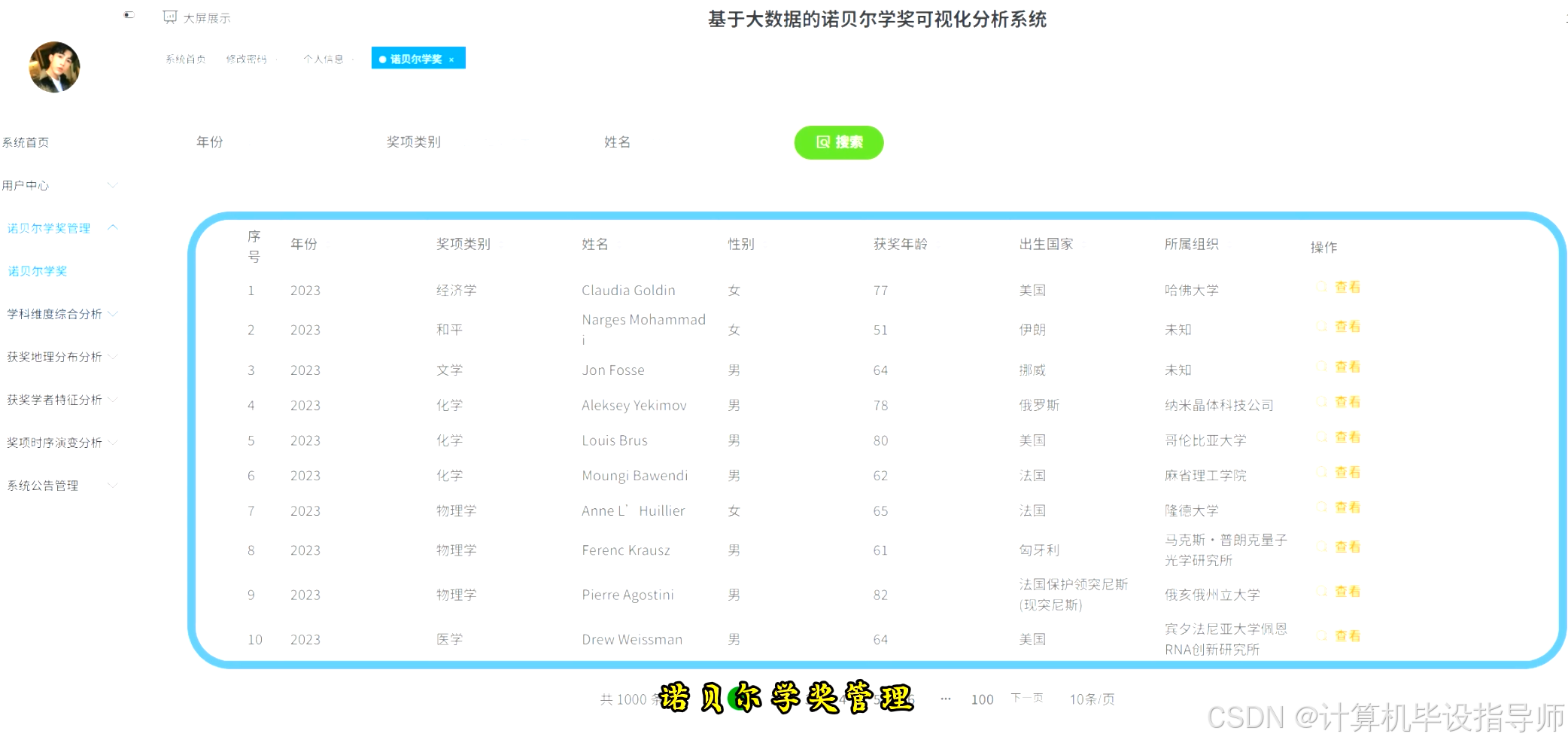
本系统基于Hadoop与Spark大数据架构,采用Python语言进行开发,后端选用Django框架提供接口支持,前端整合Vue、ElementUI及Echarts实现数据动态展示。系统核心数据源为诺贝尔奖历史数据,利用HDFS进行分布式存储,通过Spark SQL与Pandas进行大规模数据清洗与计算。功能层面,系统构建了四个主要分析维度:一是时间演变分析,涵盖历年获奖趋势、获奖者年龄分布及女性获奖比例变化,直观呈现科研发展规律;二是地理分布分析,通过各国获奖数量、机构影响力及人才流动模式展示全球科研格局;三是学科特征分析,对比不同学科的获奖年龄、性别比例及合作模式差异;四是获奖者特征分析,统计寿命分布及多次获奖情况。所有分析结果均生成CSV文件存入MySQL数据库,前端Echarts图表精准映射数据特征,为用户提供了一个集数据采集、处理、可视化于一体的完整大数据分析平台。
诺贝尔学奖可视化分析系统-技术
大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
开发语言:Python+Java(两个版本都支持)
后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
数据库:MySQL
诺贝尔学奖可视化分析系统-背景
选题背景
诺贝尔奖作为全球公认的顶尖科学奖项,其历史数据沉淀了百余年的人类智慧结晶,是研究科学发展规律的重要素材。以往大家关注点都在具体的获奖者身上,很少从宏观的大数据角度去审视这些信息。随着大数据时代的到来,面对如此庞大的科研历史记录,传统的数据处理方式显得有些吃力,很难快速挖掘出数据背后的关联。对于科研管理或学术研究来说,如何利用现代技术手段,从海量杂乱的诺奖数据中理清头绪,发现科研产出的时空分布规律,成了一个很实际的需求。这就需要借助大数据技术手段,对诺奖数据进行一次全面的梳理和展现,这也是目前很多学术分析领域正在尝试的方向,正好契合了当下数据驱动决策的大环境。
选题意义
本课题的研究意义主要在于实践应用和技术锻炼两个层面。对于大数据学习者来说,这不仅仅是一个简单的毕业设计,更是一次将Hadoop和Spark技术落地的实战机会,能让人实实在在地摸清大数据处理的全流程。从实际应用角度看,把枯燥的诺奖数据变成直观的图表,能帮我们更清晰地看到各国科研实力的消长和学科发展的脉络,这对于了解科研人才流动趋势多少有点参考价值。这个系统做出来后,能让复杂的数据分析变得通俗易懂,就算是普通用户也能一眼看懂数据背后的故事。虽然作为一个本科毕设项目,没法做到非常深奥的预测模型,但通过这个系统,能把大数据技术从书本上的理论变成看得见摸得着的应用,这本身就是一件很有意义的事情,也能为后续的学习打点基础。
诺贝尔学奖可视化分析系统-视频展示
基于Hadoop+Spark的诺贝尔学奖可视化分析系统
诺贝尔学奖可视化分析系统-图片展示



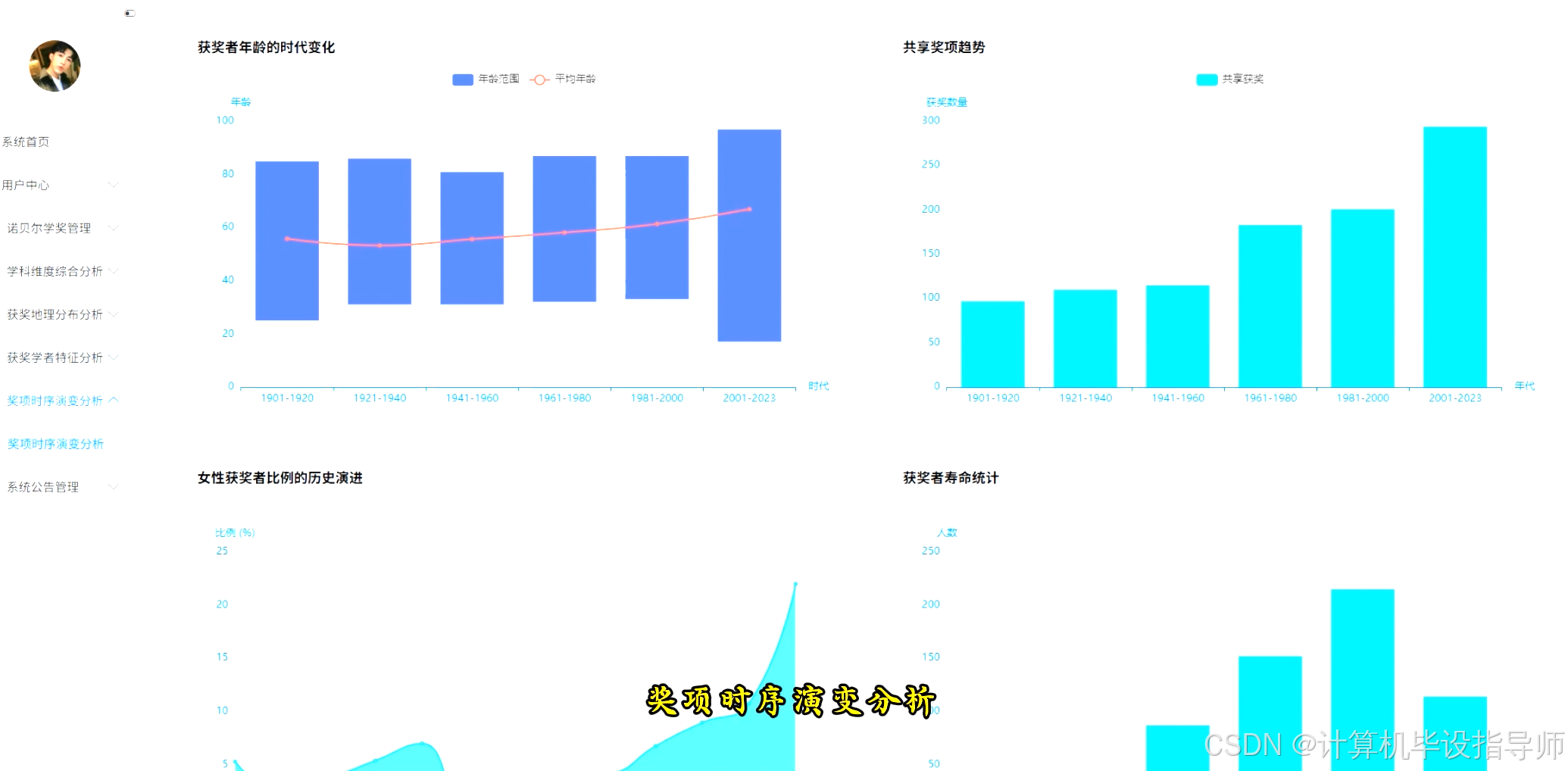
诺贝尔学奖可视化分析系统-代码展示
python
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, count, avg, year, to_date
import pandas as pd
spark = SparkSession.builder.appName("NobelPrizeAnalysis").master("local[*]").getOrCreate()
sc = spark.sparkContext
# 核心功能一:历年各学科获奖数量趋势分析
# 读取HDFS上的诺贝尔奖数据集CSV文件,header=True表示第一行为表头
df_time = spark.read.csv("hdfs://localhost:9000/data/nobel_prize.csv", header=True, inferSchema=True)
# 注册为临时视图,方便后续使用SQL语句进行复杂查询
df_time.createOrReplaceTempView("nobel_prize_data")
# 执行Spark SQL查询,按年份和学科分组统计获奖数量,并按年份排序
trend_result_df = spark.sql("""
SELECT year, category, COUNT(*) as prize_count
FROM nobel_prize_data
WHERE year IS NOT NULL AND category IS NOT NULL
GROUP BY year, category
ORDER BY year ASC, prize_count DESC
""")
# 将Spark DataFrame转换为Pandas DataFrame,便于后续Django接口调用或生成CSV
pd_trend_result = trend_result_df.toPandas()
# 将结果保存为CSV文件,供前端Echarts直接调用或导入MySQL数据库
pd_trend_result.to_csv("yearly_category_trend.csv", index=False)
print(f"历年学科趋势分析完成,共生成 {len(pd_trend_result)} 条数据记录")
# 核心功能二:获奖者年龄分布与时代变化分析
# 筛选出出生日期和获奖年份都不为空的有效数据记录
age_df = df_time.filter((col("birth_date").isNotNull()) & (col("year").isNotNull()))
# 使用Spark的日期函数从出生日期中提取出生年份
age_df = age_df.withColumn("birth_year", year(to_date(col("birth_date"), "yyyy-MM-dd")))
# 计算获奖时的年龄:获奖年份减去出生年份
age_df = age_df.withColumn("age_when_won", col("year") - col("birth_year"))
# 按学科分组,计算每个学科获奖者的平均年龄,分析不同学科的成熟度
avg_age_by_category = age_df.groupBy("category").agg(avg("age_when_won").alias("average_age"))
# 按平均年龄降序排列,查看哪些学科更需要长时间的积累
sorted_avg_age = avg_age_by_category.orderBy(col("average_age").desc())
# 收集结果并打印,这部分数据将用于前端柱状图展示
age_list = sorted_avg_age.collect()
print("各学科平均获奖年龄统计:")
for row in age_list:
print(f"学科: {row['category']}, 平均年龄: {row['average_age']:.2f}")
# 核心功能三:各国获奖数量排名与人才流动分析
# 读取原始数据并缓存,因为后续会进行多次聚合操作
country_df = df_time.filter(col("birth_country").isNotNull()).cache()
# 统计各个国家的获奖总人数,评估国家的科研实力
country_rank_df = country_df.groupBy("birth_country").agg(count("*").alias("total_prizes"))
# 按获奖数量降序排列,取前20个国家作为主要分析对象
top_20_countries = country_rank_df.orderBy(col("total_prizes").desc()).limit(20)
# 分析人才流动:筛选出出生国和工作国不一致的记录,代表人才跨国流动
flow_df = df_time.filter((col("birth_country") != col("organization_country")) & (col("organization_country").isNotNull()))
# 统计从出生国流出到工作国的数量,分析人才流失情况
talent_flow_df = flow_df.groupBy("birth_country", "organization_country").count()
# 将排名结果转为字典列表,方便后端Django返回JSON数据给前端地图组件
top_countries_list = top_20_countries.collect()
map_data = []
for row in top_countries_list:
map_data.append({"name": row["birth_country"], "value": row["total_prizes"]})
print(f"各国获奖排名分析完成,数据已准备用于地图可视化: {len(map_data)} 个国家")
spark.stop()诺贝尔学奖可视化分析系统-结语
到这里,基于Hadoop+Spark的诺贝尔奖可视化分析系统就介绍完了。这个项目主要是为了练习大数据处理流程,虽然分析逻辑不算特别复杂,但涵盖了从数据存储到清洗再到展示的全过程,对理解大数据技术很有帮助。如果大家觉得这个选题对自己有帮助,或者正在找类似的毕设项目参考,希望这个案例能给你们提供一点思路。做毕设关键还是要把流程跑通,技术选型要合适。
咱们这个系统非常适合做大数据方向的毕业设计,源码和文档我都整理好了。如果你对技术细节还有疑问,或者想了解更多关于Python大数据开发的毕设选题,欢迎去我的主页查看联系方式,咱们一起交流学习。觉得内容有帮助的同学,别忘了动动小手点个赞、投个币,顺手点个关注支持一下UP主,评论区留下你们想看的内容,我会尽量回复大家的每一条留言。
⛽⛽实战项目:有源码或者技术上的问题欢迎在评论区一起讨论交流!
⚡⚡如果遇到具体的技术问题或其他需求,你也可以问我,我会尽力帮你分析和解决问题所在,支持我记得一键三连,再点个关注,学习不迷路!~~