论文信息
- 标题:Auto-Encoding Variational Bayes
- 会议:ICLR 2014
- 单位:阿姆斯特丹大学
- 代码:https://github.com/dpkingma/vae
- 论文:https://arxiv.org/pdf/1312.6114.pdf
一、前言:生成模型的"不可能三角"
在VAE出现之前,深度生成模型一直被三个难题卡住:
- 后验概率不可算 : p ( z ∣ x ) p(z|x) p(z∣x) 无法直接求解
- 大规模数据训不动:传统变分推断不支持小批量SGD
- 采样与推断割裂:生成和编码不能一套模型搞定
这篇论文直接用变分推断+重参数化 一把梭哈,从此VAE成为生成模型三大支柱之一。
二、核心思想一句话讲透
- 编码器(Encoder) :输入图片 x x x,输出隐变量 z z z的分布 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x)
- 解码器(Decoder) :输入隐变量 z z z,输出重建图片 p θ ( x ∣ z ) p_\theta(x|z) pθ(x∣z)
- 训练目标 :让边缘似然下界最大,既保证重建准,又保证生成真实
通俗解释:
不是普通自编码器只学"编码→解码",而是学概率分布,能从噪声随机采样生成全新图片。
三、整体架构
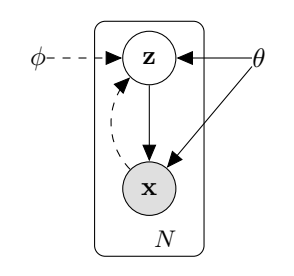
图1 VAE概率图模型
- 实线:生成模型 p θ ( z ) p θ ( x ∣ z ) p_\theta(z)p_\theta(x|z) pθ(z)pθ(x∣z)
- 虚线:近似后验 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x)
- θ \theta θ:解码器参数
- ϕ \phi ϕ:编码器参数
四、核心公式全解析
4.1 对数似然下界(ELBO)
log p θ ( x ( i ) ) ≥ L ( θ , ϕ ; x ( i ) ) \log p_\theta(x^{(i)}) \ge \mathcal{L}(\theta,\phi;x^{(i)}) logpθ(x(i))≥L(θ,ϕ;x(i))
L = − D K L ( q ϕ ( z ∣ x ) ∥ p θ ( z ) ) + E q ϕ ( z ∣ x ) log p θ ( x ∣ z ) \mathcal{L} = -D_{KL}(q_\phi(z|x) \parallel p_\theta(z)) + \mathbb{E}{q\phi(z|x)}\\log p_\\theta(x\|z) L=−DKL(qϕ(z∣x)∥pθ(z))+Eqϕ(z∣x)logpθ(x∣z)
- L \mathcal{L} L:证据下界(越大越好)
- D K L D_{KL} DKL:KL散度,衡量分布差异
- q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x):编码分布(近似后验)
- p θ ( z ) p_\theta(z) pθ(z):先验分布(标准高斯)
- p θ ( x ∣ z ) p_\theta(x|z) pθ(x∣z):解码分布(生成图像)
- E \mathbb{E} E:期望
通俗解释:
左边让编码靠近先验(规范分布),右边让重建尽可能准。
4.2 重参数化技巧(VAE能训的关键)
z = μ + σ ⊙ ϵ , ϵ ∼ N ( 0 , I ) z = \mu + \sigma \odot \epsilon,\quad \epsilon \sim \mathcal{N}(0,I) z=μ+σ⊙ϵ,ϵ∼N(0,I)
- z z z:隐变量采样
- μ \mu μ:编码器输出均值
- σ \sigma σ:编码器输出标准差
- ϵ \epsilon ϵ:标准高斯噪声
- ⊙ \odot ⊙:按元素相乘
通俗解释:
把随机性甩给固定噪声 ϵ \epsilon ϵ,让 z z z可导,才能用反向传播训练。
4.3 高斯先验下的KL闭式解
− D K L = 1 2 ∑ j = 1 J ( 1 + log σ j 2 − μ j 2 − σ j 2 ) -D_{KL} = \frac{1}{2}\sum_{j=1}^J \left(1+\log\sigma_j^2 - \mu_j^2 - \sigma_j^2\right) −DKL=21j=1∑J(1+logσj2−μj2−σj2)
- J J J:隐变量维度
- μ j , σ j \mu_j,\sigma_j μj,σj:第 j j j维的均值、方差
五、核心PyTorch代码
5.1 VAE Encoder(输出μ, logvar)
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class Encoder(nn.Module):
def __init__(self, in_dim=784, hidden_dim=400, latent_dim=20):
super().__init__()
self.fc1 = nn.Linear(in_dim, hidden_dim)
self.fc_mu = nn.Linear(hidden_dim, latent_dim)
self.fc_logvar = nn.Linear(hidden_dim, latent_dim)
def forward(self, x):
h = F.relu(self.fc1(x))
mu = self.fc_mu(h)
logvar = self.fc_logvar(h)
return mu, logvar5.2 VAE Decoder
python
class Decoder(nn.Module):
def __init__(self, latent_dim=20, hidden_dim=400, out_dim=784):
super().__init__()
self.fc2 = nn.Linear(latent_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, out_dim)
def forward(self, z):
h = F.relu(self.fc2(z))
x_recon = torch.sigmoid(self.fc3(h))
return x_recon5.3 重参数化 + 损失函数
python
class VAE(nn.Module):
def __init__(self):
super().__init__()
self.encoder = Encoder()
self.decoder = Decoder()
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def forward(self, x):
mu, logvar = self.encoder(x)
z = self.reparameterize(mu, logvar)
x_recon = self.decoder(z)
# 损失:重构损失 + KL散度
recon_loss = F.binary_cross_entropy(x_recon, x, reduction='sum')
kl_loss = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return recon_loss + kl_loss六、实验结果与对比
6.1 对数似然下界对比(表格1 出处:原论文Figure 2)
| 模型 | MNIST(测试集下界) |
|---|---|
| Wake-Sleep | 约105 |
| VAE(AEVB) | 约140 |
表格1 训练收敛速度对比
分析:
VAE收敛更快、更高、更稳,完爆传统Wake-Sleep。
6.2 隐空间可视化

图2 2维隐空间分布
分析:
VAE学到光滑连续的流形,数字之间平滑过渡,可插值生成。
6.3 不同隐维度采样效果

图3 不同维度隐变量生成的MNIST
分析:
隐维度≥10即可生成清晰数字,维度越高细节越丰富。
七、关键创新点
- SGVB估计器:变分下界可微、可小批量训练
- 重参数化技巧:解决采样不可导问题
- AEVB算法:编码解码联合训练,一套框架搞定生成与推断
- 理论优美:为后续CV、NLP生成模型奠定基础
八、总结
VAE是深度生成模型的里程碑:
- 第一次把变分推断 和深度网络完美结合
- 用重参数化解决采样不可导的世纪难题
- 支持大规模数据、端到端训练、随机采样生成
今天几乎所有可控生成、隐空间分析、概率建模,都能看到VAE的影子。