基础RAG能解决80%的问题,但剩下20%的难题,需要更进阶的技术。
一、基础RAG碰到了什么天花板
基础RAG的套路很简单:文档切块 → Embedding → 向量检索 → 拼接Prompt → 大模型生成答案。
简单场景够用,但往深了用,三个问题绕不开。
孤立片段,处理不了关联。 文档切成Chunk后,每块独立,检索也只能捞出孤立内容。碰上"《论文A》和《论文B》观点有什么异同"这类问题,基础RAG就抓瞎了。
缺乏深层语义理解。 它只会找相关段落,多跳推理、跨文档对比这些复杂动作做不了。
搞不定领域特有的关系。 法律、医疗、金融里,实体之间的关系高度领域化,纯文本检索摸不到这层。
这几个问题把RAG逼出了几条进化路线。
二、GraphRAG:用知识图谱把关系显式建出来
2.1 为什么孤立片段是致命的
一个典型失败场景:法律AI里,用户问"这份合同里的保密条款,和《数据安全法》哪些规定相关?"
基础RAG会分别检索"保密条款"和"数据安全法"的文档,拼接在一起扔给大模型。但大模型根本不知道这两者之间有什么具体关系,很可能找错关联或遗漏关键条文。文档之间的关系是隐式的,基础RAG没有建模手段。
2.2 GraphRAG的核心做法
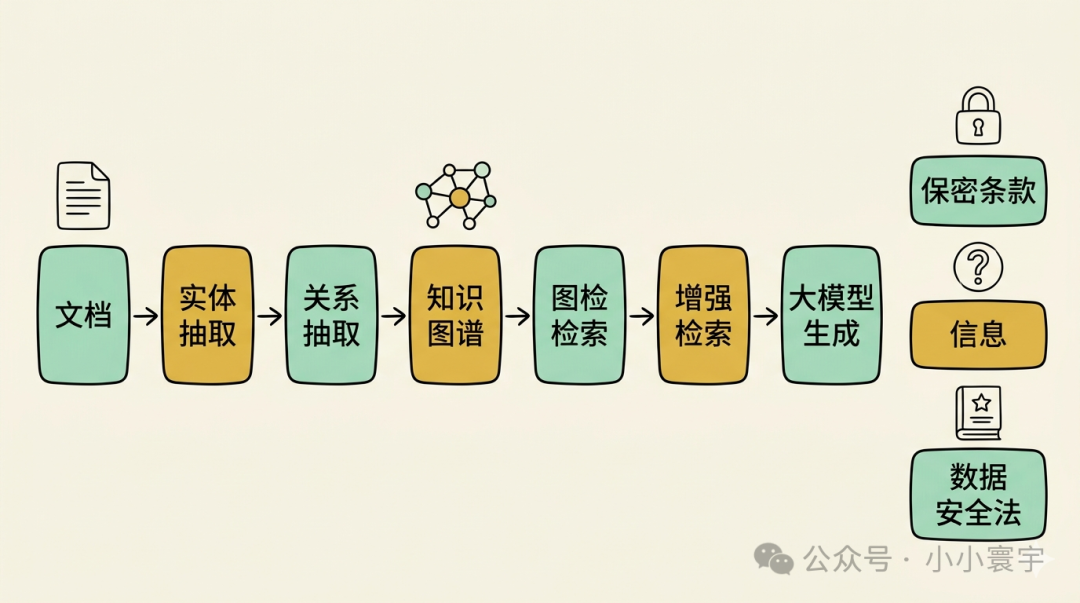
把文档之间的关联关系显式构建出来,作为检索的一部分。
实体抽取:用LLM或NER模型,从文档中提取实体------人物、组织、概念、法规条款。
关系抽取:用LLM分析实体之间的关系,例如"数据安全法"规范"个人信息","合同"包含"保密条款"。
知识图谱 + 图检索:用户提问时,不仅检索相关Chunk,还检索相关的实体和关系路径。比如问"哪些法规和合同保密条款相关",系统找到"保密条款"实体 → 沿关系路径找到相关实体("个人信息")→ 找到规范这些实体的法规("数据安全法")→ 返回关联路径和对应文档。
2.3 什么场景值得用
GraphRAG的优势在关联推理场景非常明显。效果数据:
| 问题类型 | 基础RAG | GraphRAG | 提升 |
|---|---|---|---|
| "A和B是什么关系?" | 33% | 71% | +38% |
| "涉及X的所有法规有哪些?" | 28% | 75% | +47% |
| "找出A→B→C的关联路径" | 15% | 68% | +53% |
| 简单事实问答 | 82% | 85% | +3% |
问题越依赖关联关系,GraphRAG优势越大。简单问答两者差别不大。
适合的场景:关联密切的领域(法律、医学、金融)、多跳推理问题、需要比较类回答。
不建议的场景:简单FAQ、单一文档问答、不依赖关联的检索场景。
务实的起步方式:先用基础RAG跑 → 找出高频的关联推理问题 → 优先为这些问题构建图谱,用"小图谱+大检索"的混合架构。全量图谱成本很高,不要一开始就铺。
三、HyDE:让大模型"猜"答案再检索
3.1 思路
HyDE(Hypothetical Document Embedding)的做法很巧妙:先让大模型生成一个假答案,再拿这个假答案去找相关文档。
bash
传统检索:Query → 向量检索 → 返回文档
HyDE检索:Query → 大模型生成假答案 → 向量检索 → 返回文档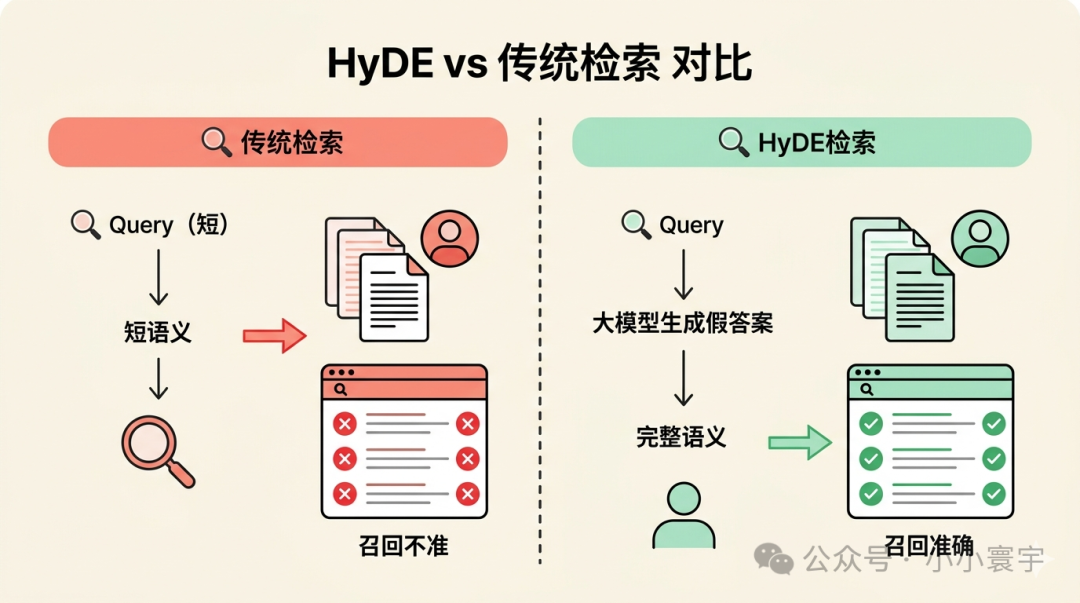
用户的问题往往很短,语义信息不足,直接检索容易召回不准。HyDE先生成一段完整的假答案------包含了完整语义的描述,拿去检索反而更容易命中真正相关的文档。
3.2 适用和局限
适合:用户问题表述模糊、问法和文档表述差异大(多语言场景、同义词多)、需要召回语义相近但字面不同的文档。
局限:多一次大模型调用,增加延迟和成本;大模型"猜错"时检索会跑偏。
建议HyDE作为混合检索的一路,和正常检索一起用,用RRF融合两路结果。这样HyDE出问题也不影响整体。
四、Self-RAG:让大模型自己决定要不要检索
4.1 核心问题
基础RAG有一个隐藏浪费:不是所有问题都需要检索。 有些问题大模型自己就能答好,但基础RAG一律走检索,既浪费资源又可能引入干扰。
Self-RAG解决的是这个问题:让大模型自己判断是否需要检索,以及检索结果有没有用。
4.2 机制
Self-RAG引入了特殊的Reflection Token,大模型在回答过程中输出:
- • Retrieve:我需要检索
- • Relevant:这条检索结果和问题相关
- • Supported:检索结果能支持我的回答
- • Utility:这个回答对我有帮助
最终回答可以附带这些Token的判断结果,可追溯、可解释。
4.3 效果和适用场景
- • 减少不必要的检索,降低延迟和成本
- • 只有真正相关的检索结果才会被使用,回答质量更高
- • 每个回答可追溯"是否检索了"、"检索是否有效"
适合:大规模知识库(检索成本高)、对回答质量要求高的场景。
局限:需要微调模型来识别Reflection Token,标准API无法直接实现。
五、Code-RAG:代码场景的专门设计
5.1 代码检索的特殊挑战
技术文档RAG里,代码检索有几个不一样的问题:
- • 上下文依赖:一个函数名单独出现没有意义,需要完整的函数定义
- • 版本和语法差异:Python 2和Python 3语法不同,混淆了会出问题
- • 层级结构:代码不是平铺文本,有函数、类、模块的层级
- • 语义和字面不匹配:用户问"如何并发处理",代码里可能写的是"threading实现"
5.2 关键设计
Chunk策略:按函数/类/文件边界切分,不要简单按行数切。整个函数作为最小单位,包含定义、注释、调用关系。破坏函数完整性的切分方式要避免。
Embedding模型:通用Embedding对代码效果差,需要专门的代码模型。常用方案:CodeBERT(微软出品)、GraphCodeBERT(加入AST结构信息)、Cohere/code(Cohere多语言代码Embedding)、国产的若问代码Embedding有中文优化。
检索多路并进:代码语义检索(Embedding)+ 关键词检索(文档注释、变量名)+ 文档检索(README、API文档)+ 示例检索(具体用法、完整可运行代码)。
5.3 建议
代码和文档分开处理,用不同的Chunk策略和Embedding模型。每个代码Chunk要包含完整的函数定义和必要的调用关系,检索结果最好能提供完整可运行的代码片段。
六、行业黑话文档怎么搞RAG
6.1 问题在哪
企业内部文档常有大量行业黑话和内部术语------外部人完全陌生,但内部人习以为常。
- • 外部Embedding模型不懂"Q1行动"、"三个一工程"是什么意思
- • 同一个词,内部和外部的理解完全不同
- • 理解这些术语需要背景知识,不是简单翻译能解决的
6.2 三种解法
解法一:术语词典 + Query扩展(最小成本,立即见效)
维护一个术语词典(术语 → 解释/同义词),检索前用词典扩展Query:
bash
用户Query:Q1行动是什么?
展开为:Q1行动 OR 第一季度重点行动方案同时在文档里标记术语,检索时也做展开,两端对齐。
解法二:领域自适应Embedding
用领域数据微调Embedding模型,让它"学会"内部术语。用对比学习(Contrastive Learning)微调后在内部Query上测试召回效果。
适合:内部术语量大、高频使用、效果收益明显的核心场景。成本高,不建议一开始就做。
解法三:知识图谱 + 术语映射
用知识图谱建立术语之间的关联关系,"三个一工程"节点连接集团年度重点项目、涉及部门、相关政策、历史沿革。检索时自动带上关联上下文。
这个方案和GraphRAG结合最好,适合复杂查询场景。
建议的建设顺序:先建术语词典 → 再考虑知识图谱 → 最后考虑微调Embedding。术语词典要持续维护,知识图谱需要领域专家参与定义关系。
七、多模态RAG:不止文本
7.1 需求
现代文档不只是纯文本,还有图片、表格、图表、流程图,甚至视频和音频。
- • 技术文档里,一张架构图胜过千字
- • 财务报告里,表格包含核心数据
- • 培训视频里,有大量讲解和演示
基础RAG只能处理文本,这些多模态内容全部浪费了。
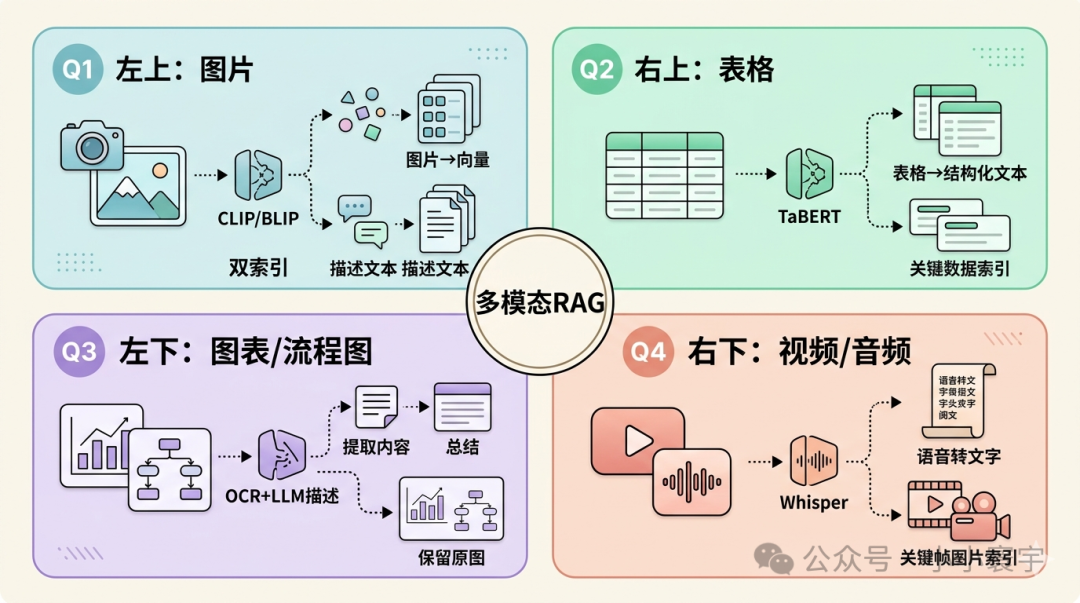
7.2 各个模态的处理方式
图片:用CLIP、BLIP等多模态模型将图片转成向量,同时提取图片描述文本存两份索引。检索时图片向量检索和图片描述文本检索两路并进。
表格:用专门的表格解析模型(如TaBERT)提取内容,转成结构化文本("表格:行1,列A是X,列B是Y"),或者把表格关键数据单独建索引。
图表和流程图:用OCR+图像描述模型提取内容,复杂图表可以让LLM做描述总结,同时保存原图,检索到描述后呈现原图。
视频/音频:用Whisper做语音转文字,提取关键帧做图片索引,检索时文字匹配、视频/音频呈现。
7.3 分阶段做
多模态RAG成本和复杂度都较高,建议分阶段:
八、写在最后
RAG还在快速演进,几个值得持续关注的方向:
Agent + RAG:RAG不只是"检索→生成",而是让Agent主动决定何时检索、检索什么、如何使用检索结果。RAG从一个被动工具变成主动推理组件,这是质变。
长上下文RAG:上下文窗口越来越大(100K+ tokens),RAG的形态会随之变化------不再需要激进的压缩和筛选,可以直接给大模型喂更多上下文,Chunk策略也会跟着调整。
实时学习RAG:知识库不再是静态的,而是可以实时更新、增量学习,和大模型同步演进。
多模态原生RAG:从一开始就把文本、图像、音频、视频作为原生输入,不是分别处理再融合------这是架构层面的变化。
基础RAG是起点,不是终点。选择哪个进阶方向,取决于你的场景瓶颈在哪里。
文章首发于 「小小寰宇」
