前言
使用 Claude Code 有很长一段时间了,从 25 年初接触 Cursor,再到后来的 Windsurf、再到 Claude Code、Codex,和 CC 也算是老朋友了。
真心想说,工具简单使用 和真正会用之间差距特别大。只有把工具吃透、用得熟练精通,才能真正事半功倍。这段时间我从入门摸索到吃透全部命令,期间踩过不少坑,也沉淀了很多实操经验。
今天整理分享一波 Claude Code 常用命令和工程配置,不管是新手还是老玩家,都值得认真读一读、收藏起来慢慢用,把这个工具真正用好、用精,做事真的真的真的能巨提效。
ps:这篇更像一份 Claude Code 实战手册,建议先收藏,后面配置项目、排查问题、实践指南、踩坑、查命令时可以直接翻。
全文主要分四块:
- 命令大全:CLI 命令、斜杠命令、快捷键、多模型配置、CLAUDE.md、Hooks。
- 高频黄金命令:精选我个人认为最实用的命令,重点讲怎么用。
- 踩坑记录:我踩过的坑,你不用再踩。
- 最佳实践:把命令串成工程工作流,适合直接照着用。
另外,Claude Code 不建议一直"裸用"。命令、配置、Hooks 是基础,后面真正拉开差距的是 Skills + MCP 生态。我之前还写过一篇专门讲 Skills 和 MCP 的实战文章: 《别再裸用 Claude Code 了!32 个亲测 Skills + 8 个 MCP,开发效率直接拉满!》,这篇可以和本文配套看。
所有命令都经过 claude 终端验证(我会为自己的每一篇文章负责),大部分都会配插图,不存在编造或者臆想的情况。建议先点赞、收藏,后面用到时直接回来查;如果你有更好的命令组合,也欢迎评论区一起讨论。废话不多说,开干!
本文基于 cc 2.1.131 (Claude Code) 编写和演示。Claude Code 更新很快,如果你本地看到的命令和截图略有差异,优先以你当前版本的
/help、claude --help和实际终端输出为准。
先搞懂:Claude Code 到底能干啥?
一句话 :Claude Code 是 Anthropic 出的终端 AI 编程助手 ,不是代码补全插件,而是任务驱动型代理------你说目标,它自己规划步骤、读代码、跑命令、改文件。
| 能力维度 | 具体表现 |
|---|---|
| 代码生成 | 实时生成、解释、优化代码,支持 Python/JS/Java/Go 等 |
| 命令执行 | 直接跑 Shell 命令、操作 Git、执行测试 |
| 文件操作 | 读写项目文件、批量修改、目录管理 |
| 外部集成 | MCP 协议扩展,连接数据库、浏览器、第三方工具 |
| 自然语言 | 说人话就行,不用记语法 |
💡 实测感受:它不是帮你补全代码的,是帮你干活的。你说"帮我重构这个模块",它自己去看代码、规划方案、动手改、跑测试,全程你只需要确认。
第一部分:命令大全
一、CLI 命令(终端直接执行)
1.1 安装与更新
bash
# npm 全局安装(最常用)
npm install -g @anthropic-ai/claude-code
# 原生二进制安装
claude install stable # 安装稳定版
claude install latest # 安装最新版
claude install 2.1.92 # 安装指定版本
# 一键安装(省心省力 推荐!):
curl -fsSL https://claude.ai/install.sh | bash
# 更新
claude update
# 查看版本
claude -v由于我已经安装了,这里就不做安装演示了,只给个更新演示: 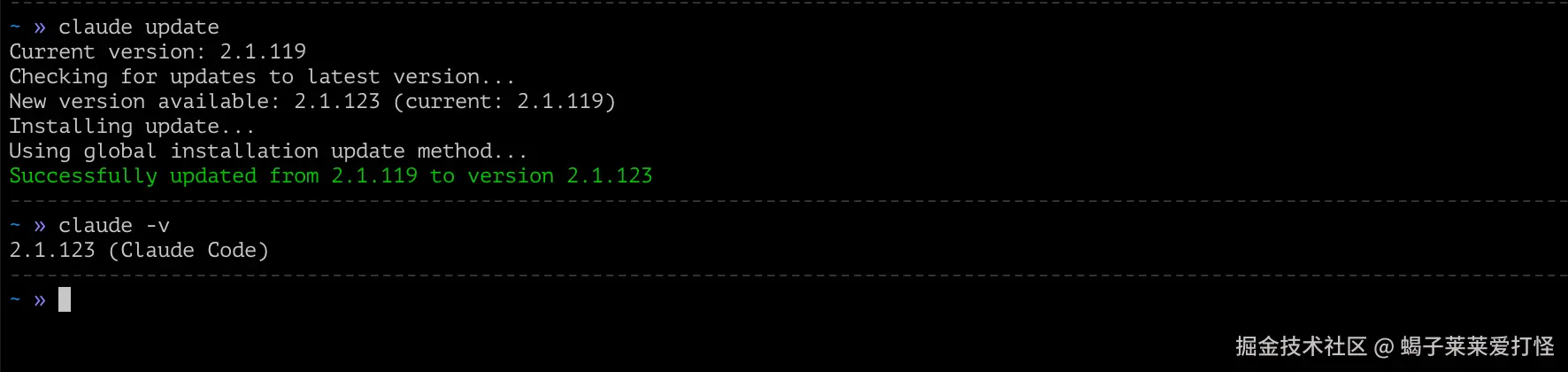
1.2 登录认证
bash
# 登录(浏览器OAuth,Pro/Max用户)
claude auth login
# 用 API Key 登录(Console 用户)
claude auth login --console
# 企业 SSO 登录
claude auth login --sso
# 查看登录状态
claude auth status # JSON 格式
claude auth status --text # 人类可读格式
# 登出
claude auth logout💡 注意 :以上登录方式适合有 Claude 官方账号的用户,但是目前这情况。。你懂得。。。 so , 大部分伙伴可能用的是国内其他模型,往下看 👇
1.2.1 第三方模型配置(这里我以智谱为例)
方式一:环境变量配置
bash
# 智谱 GLM
export CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC="1"
export API_TIMEOUT_MS="3000000"
export ANTHROPIC_AUTH_TOKEN="xxxxxxxxxxxxx"
export ANTHROPIC_BASE_URL="https://open.bigmodel.cn/api/anthropic"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="glm-5.1"
export ANTHROPIC_DEFAULT_SONNET_MODEL="glm-5.1"
export ANTHROPIC_DEFAULT_OPUS_MODEL="glm-5.1"方式二:配置文件(推荐)
编辑 ~/.claude/settings.json:
json
{
"env": {
"CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": "1",
"API_TIMEOUT_MS": "3000000",
"ANTHROPIC_AUTH_TOKEN": "xxxxxxxxxxxxx",
"ANTHROPIC_BASE_URL": "https://open.bigmodel.cn/api/anthropic",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-5.1",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-5.1",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-5.1"
}
}其他国内模型配置,在其官网都有示例。这里给几个链接,直接跳过去就能看到接入 CC 的示例:
-
DeepSeek:api-docs.deepseek.com/zh-cn/quick...
1.3 启动方式
| 命令 | 用途 | 说明 |
|---|---|---|
claude |
启动交互式会话 | 最基础的启动方式 |
claude "帮我分析这个项目" |
带初始提示启动 | 直接进入对话 |
claude -p "解释这个函数" |
非交互模式(print mode) | 执行完就退出,适合脚本 |
claude -c |
继续上次会话 | 接着上次的对话继续 |
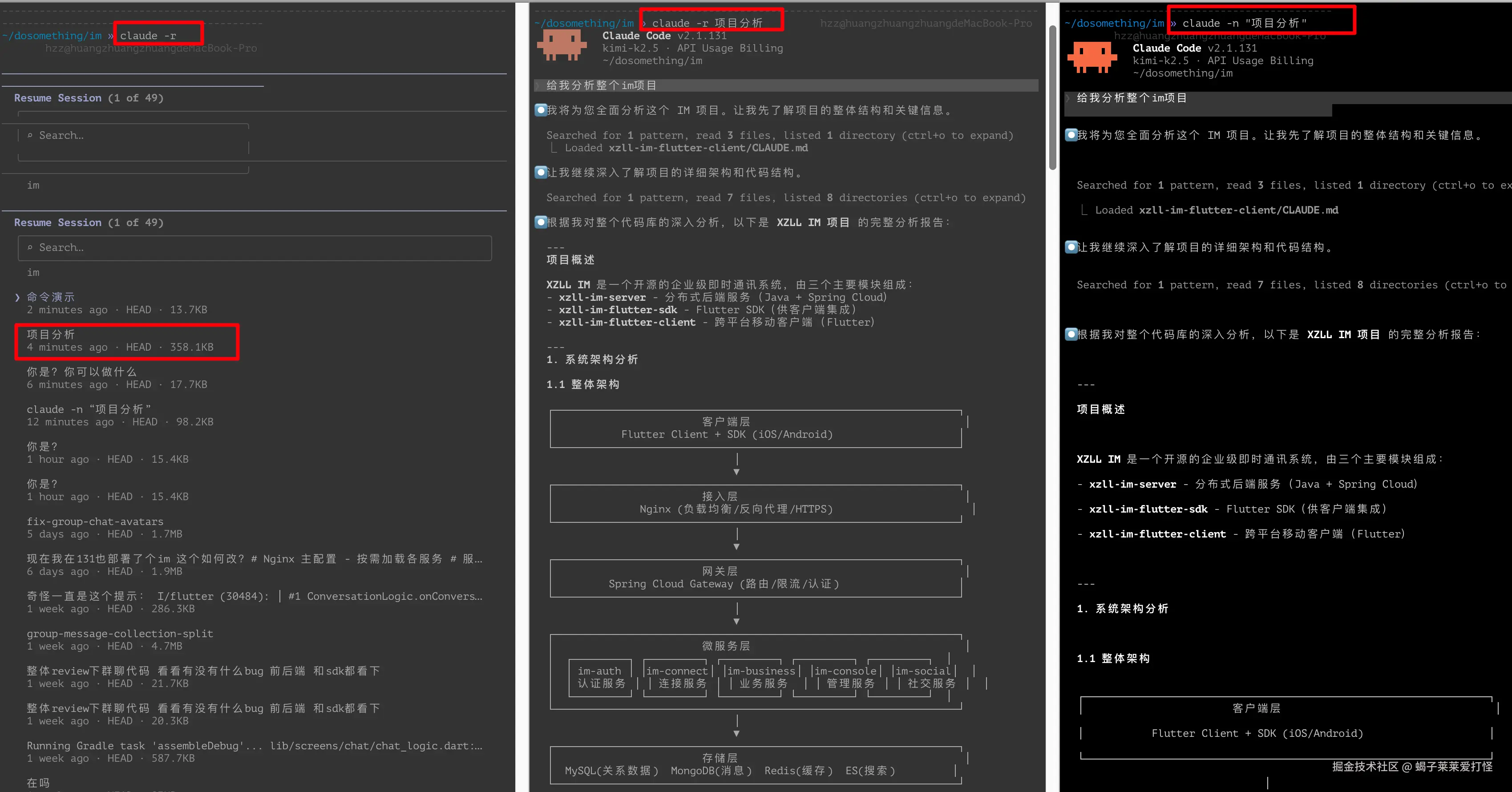
claude -r |
展开最近会话列表 | 注意: -r 是 --resume 的短写;claude --resume 和 claude -r 等效,都会打开可恢复会话列表。 |
claude -r "auth-refactor" |
恢复指定会话 | 按会话 ID 或名称恢复 |
claude -n "我的新功能" |
给会话命名 | 当然你也可以在会话内使用 /rename xxx 这样重命名会话 |
演示如下: 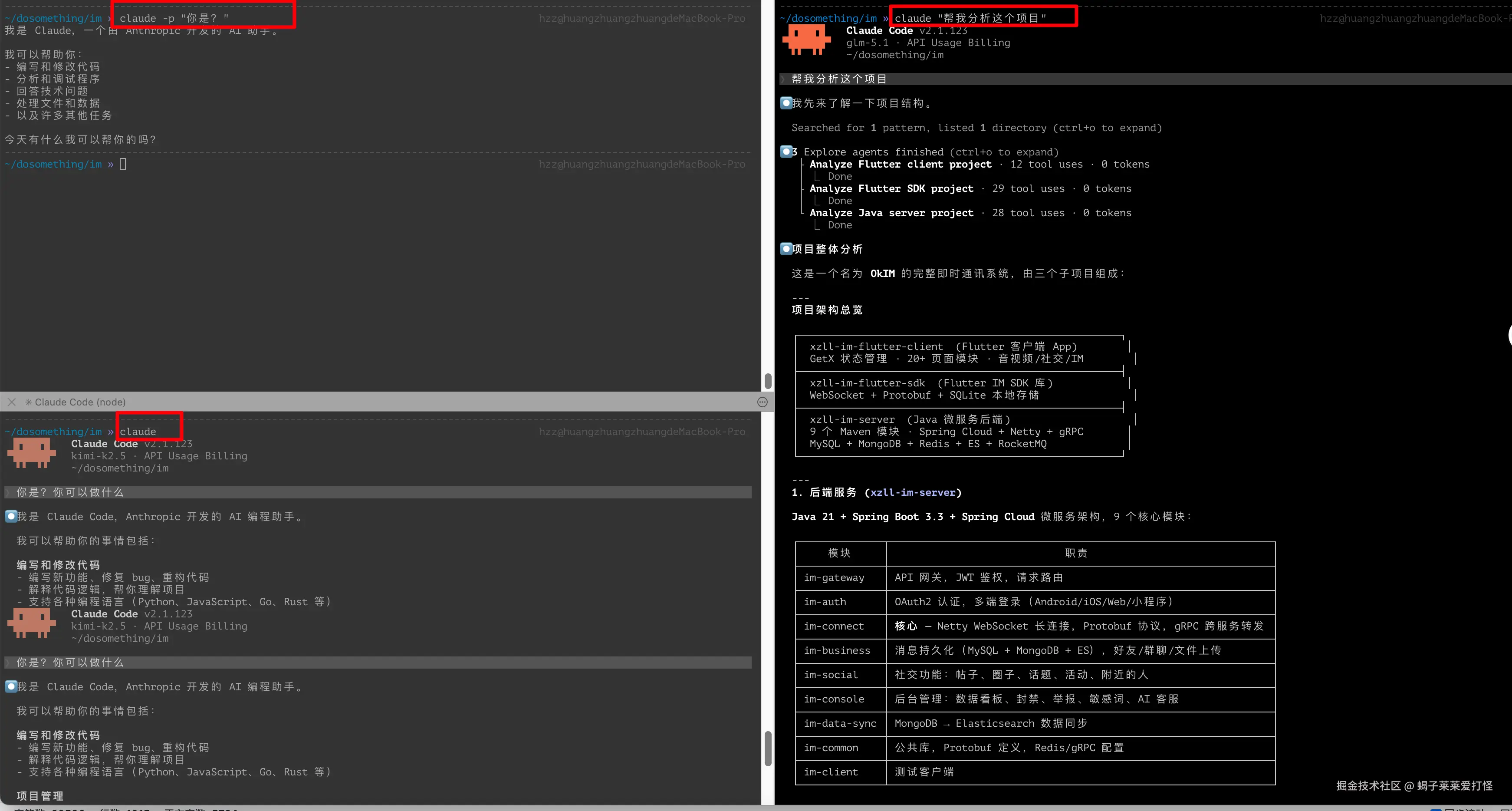
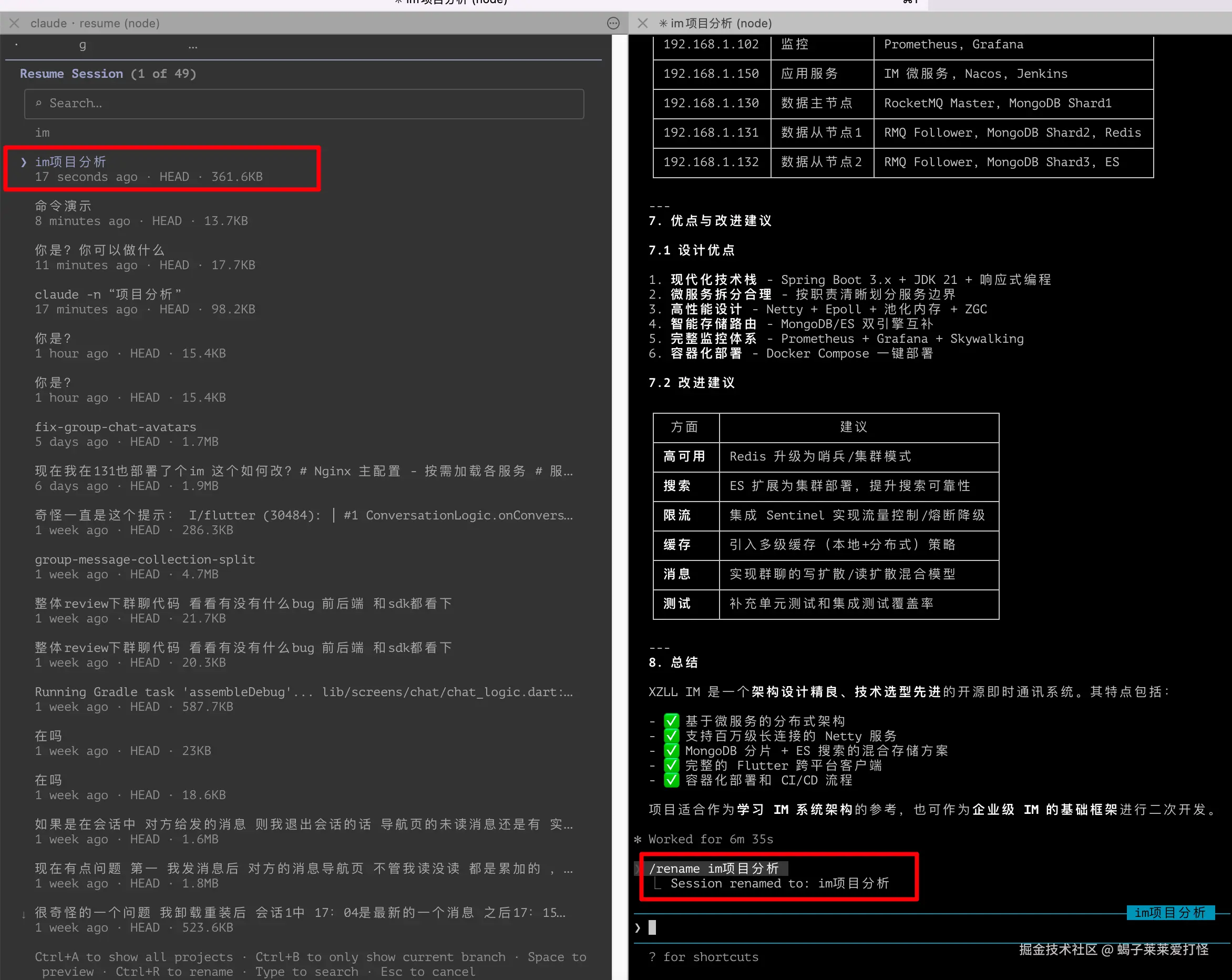
💡 实测感受 :
claude -r是我用得最多的命令,这个可以直接回车选择进入你想要恢复的上下文,很方便。
1.4 管道模式
bash
# 分析文件
cat xzll-im-server/im-business/pom.xml | claude -p "分析这个模块的依赖和潜在问题"
# 分析 git diff
git diff HEAD~3 | claude -p "总结这些改动"
# 分析日志
cat error.log | claude -p "分析这个错误日志,找出根因"
# 分析多个文件
cat xzll-im-server/im-common/src/main/proto/*.proto | claude -p "找出所有 TODO 注释"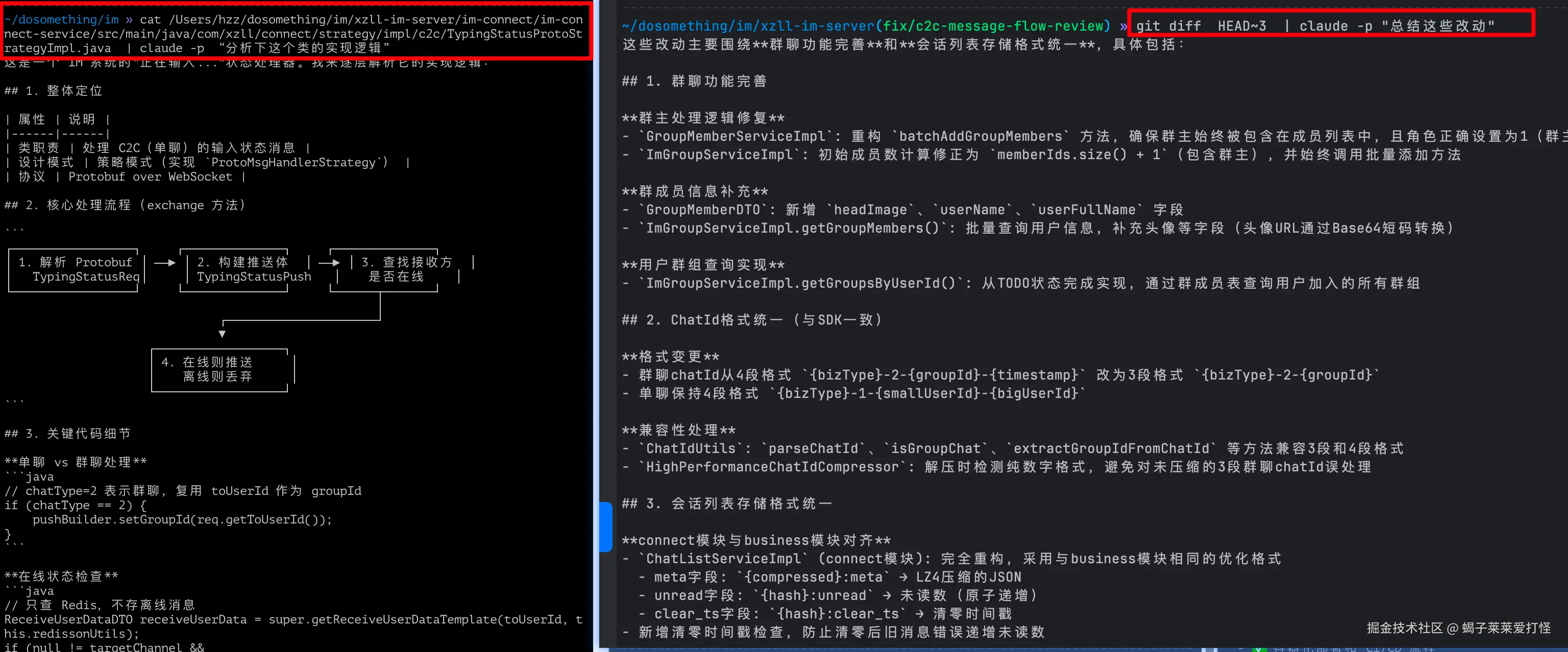
💡 实测感受:管道模式适用于那种一次性任务,我个人用的不算多。
1.5 其他 CLI 子命令
bash
# MCP 配置
claude mcp add <name> -- <command> # 添加 MCP 服务器
claude mcp list # 列出已配置的 MCP
claude mcp remove <name> # 移除 MCP 服务器
# 插件管理
claude plugin install <name> # 安装插件
claude plugin list # 列出插件
# 远程控制(必须订阅了正版 Claude Code!才支持这个功能)
claude remote-control --name "My Project"
# CI/CD 用的长期 Token
claude setup-token
# 非交互式超级代码审查(必须订阅了正版 Claude Code!才支持这个功能)
claude ultrareview --json
# 健康检查
claude doctor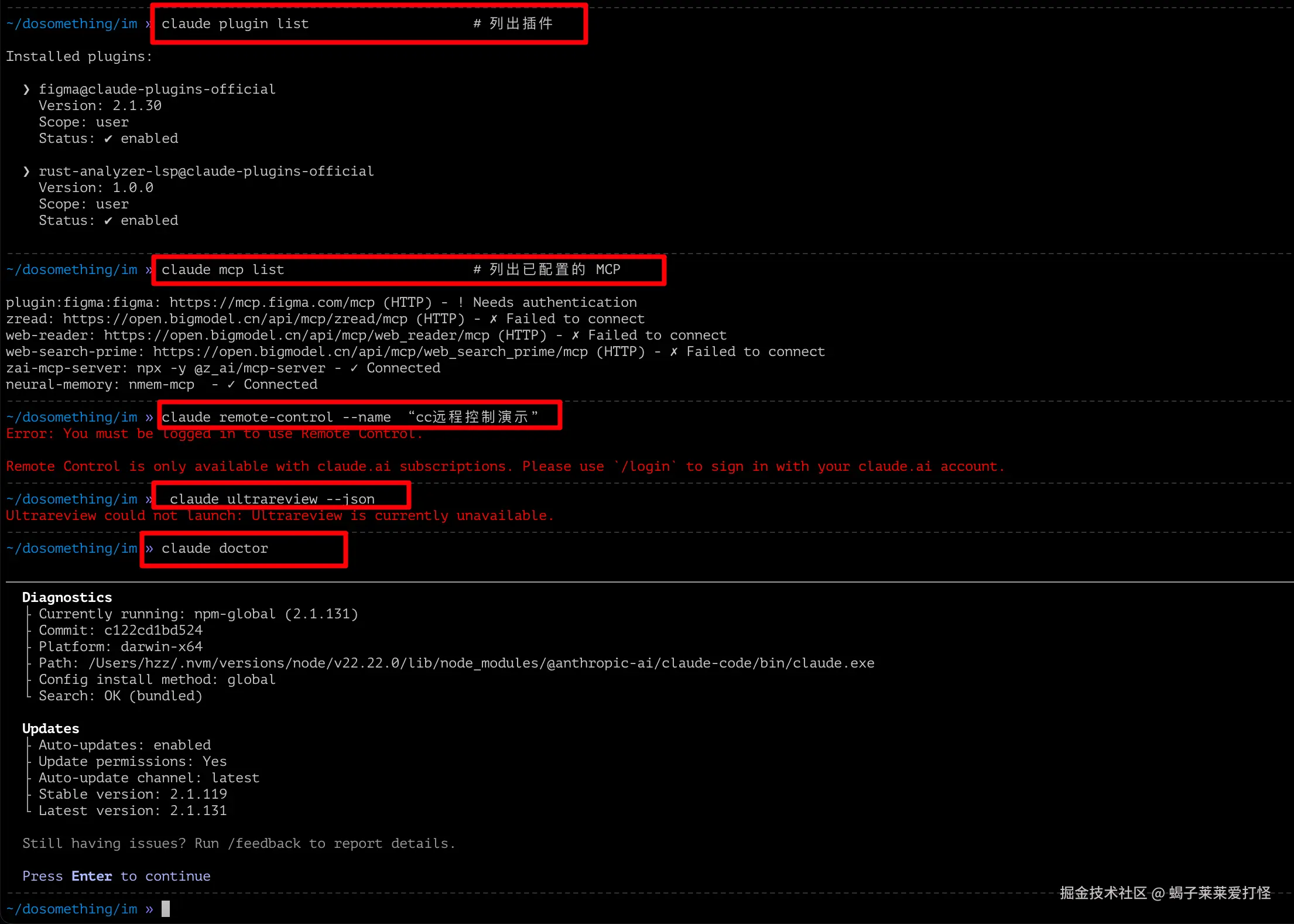
二、斜杠命令大全(/ 开头,交互模式内用)
这是 Claude Code 最核心的部分,55+ 个斜杠命令,我按场景分类整理。
注意:下面基于 cc 2.1.131 整理。部分命令依赖版本、订阅计划、平台能力、GitHub CLI、Claude Code on the web 或特定功能开关。如果你本地没有某个命令,先用
/help看当前环境实际支持情况。
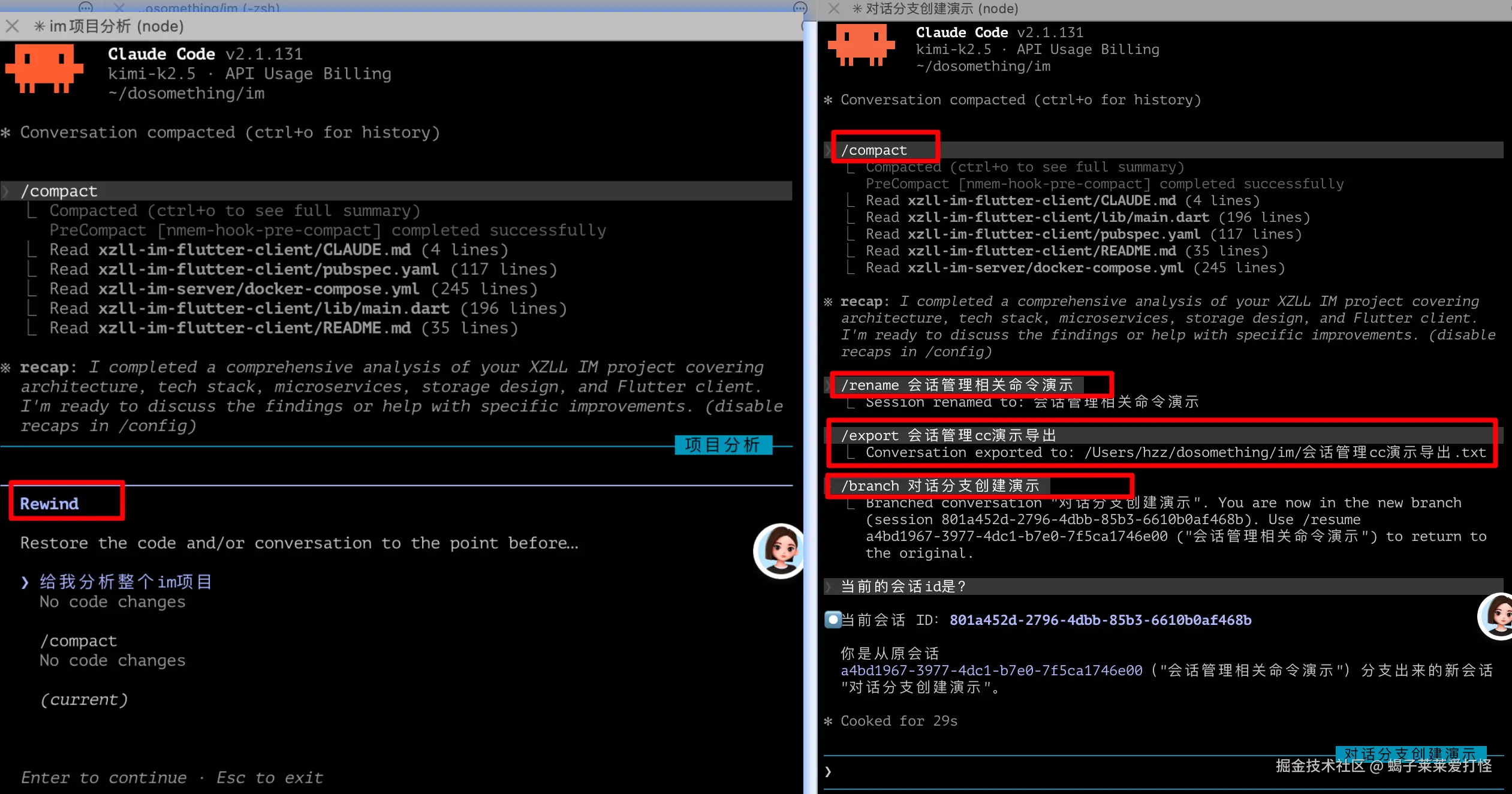
2.1 会话管理(最高频)
| 命令 | 别名 | 用途&说明 |
|---|---|---|
/clear |
/reset, /new | 清空上下文,开始全新会话 |
/compact [focus] |
- | 压缩上下文释放空间,可指定保留重点 |
/continue |
/resume | 恢复历史会话 |
/rename [name] |
- | 重命名当前会话 |
/export [filename] |
- | 导出会话为纯文本 |
/rewind |
/checkpoint, /undo | 回退到之前的对话/代码点,有以下三个可选模式: Restore conversation 恢复会话 → 直接倒带撤回,回到你发「给我分析整个 im 项目」之前 的空白对话状态,重新提问。 Summarize from here 从这里开始总结 → 不回退,直接从当前位置,把后面所有对话帮你精简概括一遍。 Never mind 算了、取消 → 不做任何回退,保持现在对话不变。) |
/branch [name] |
/fork | 在当前点创建对话分支 |
/exit |
/quit | 退出 CLI |
2.2 规划与执行(效率翻倍)
| 命令 | 用途 | 说明 |
|---|---|---|
/plan [description] |
进入计划模式 | 先分析再执行,省 token 省心(非常好用) |
/batch <instruction> |
大规模并行代码变更 | 自动创建 worktree 并行执行(注意这个命令必须得在git仓库下执行) |
/loop [interval] <prompt> |
定时循环执行 | 闭环调试,直到成功 |
/plan 大任务、复杂任务一定记得先 plan。这属于基操:先把方案想清楚,再动代码,后面会省很多回滚成本。 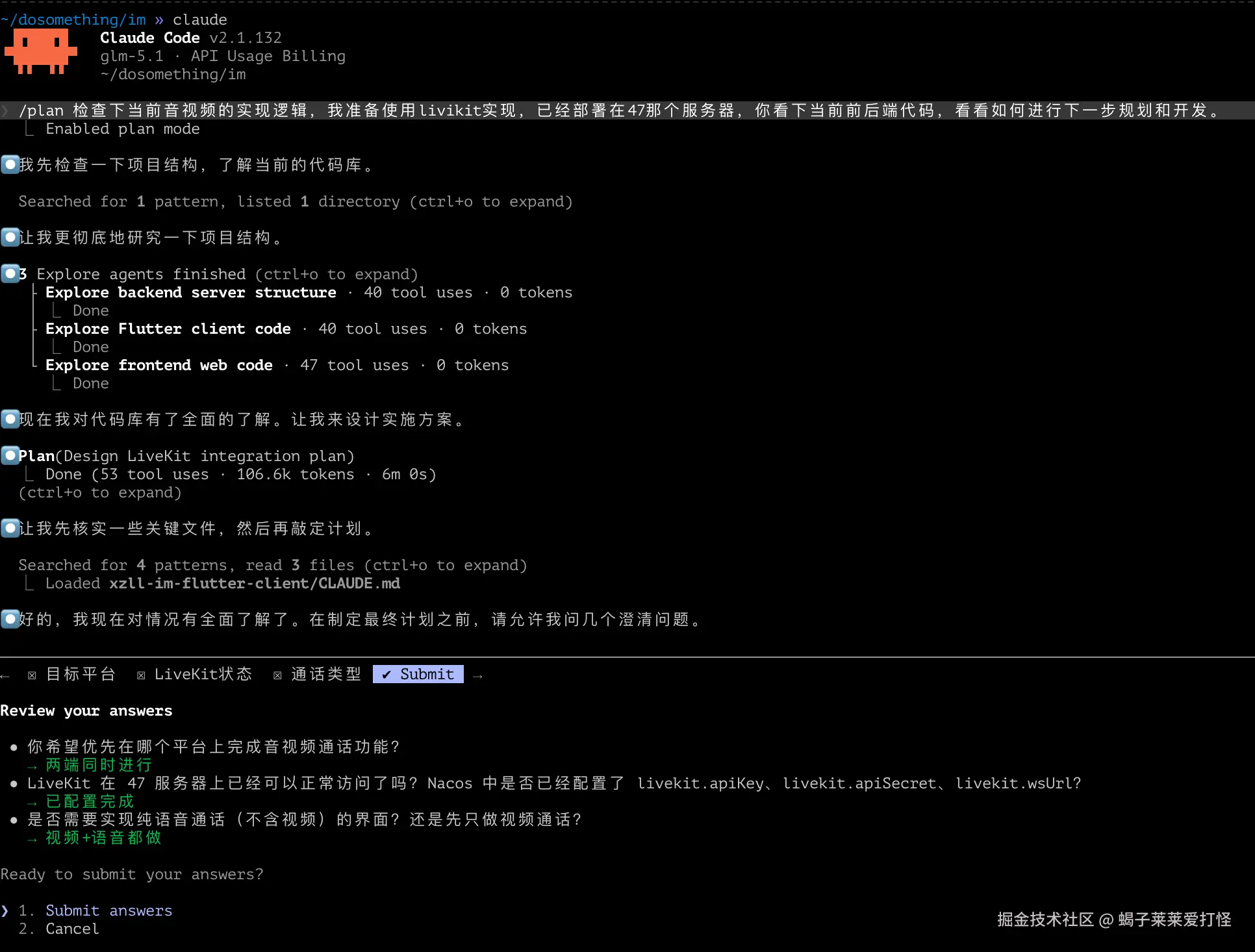
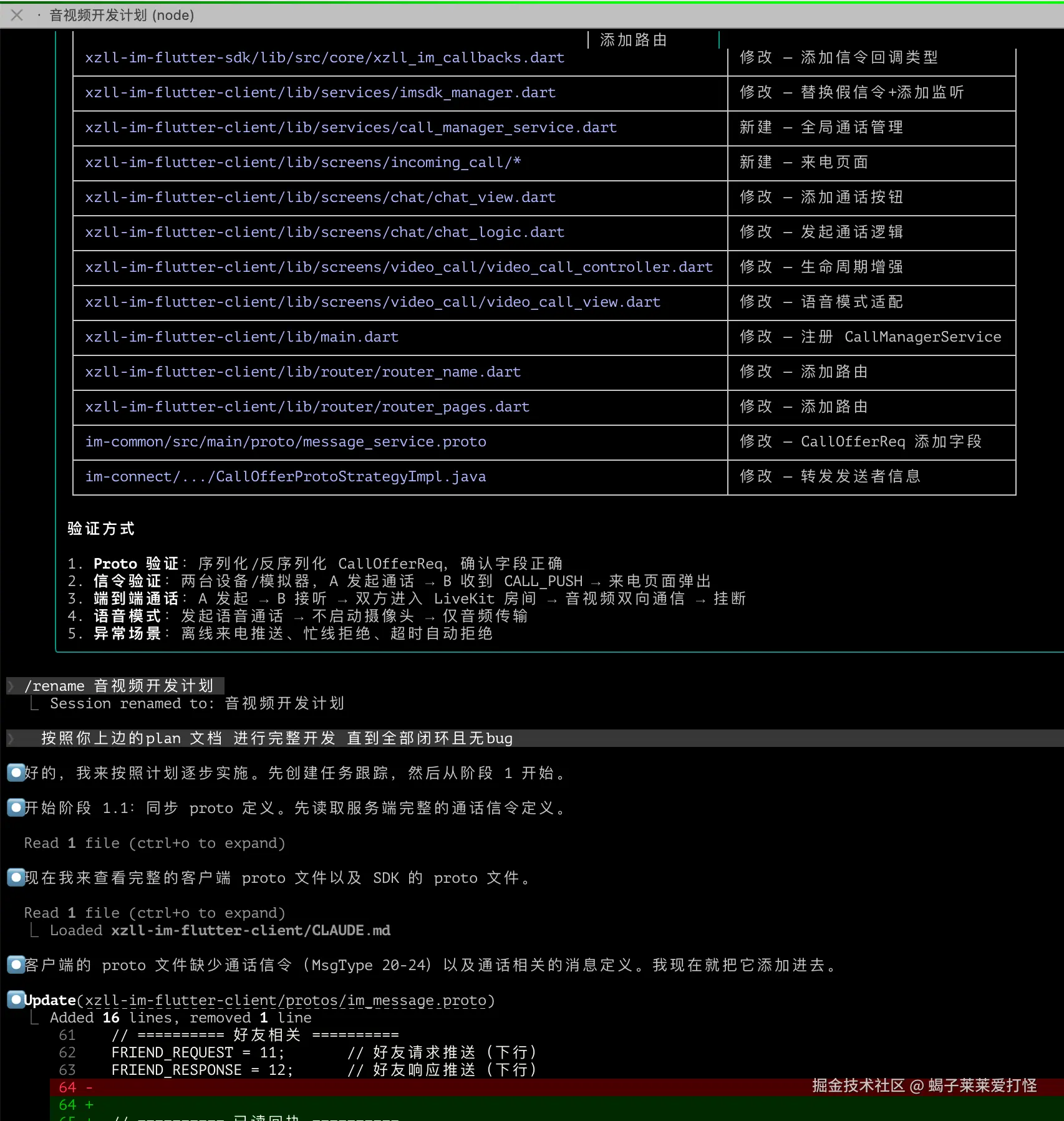
/batch 这个命令特点是:快、暴力、适合大批量重复修改 由于我这没这种场景所以不演示了。
/loop 这个适合那种难缠的bug或者定时代码review 之类的,适合调试 / 修复 。 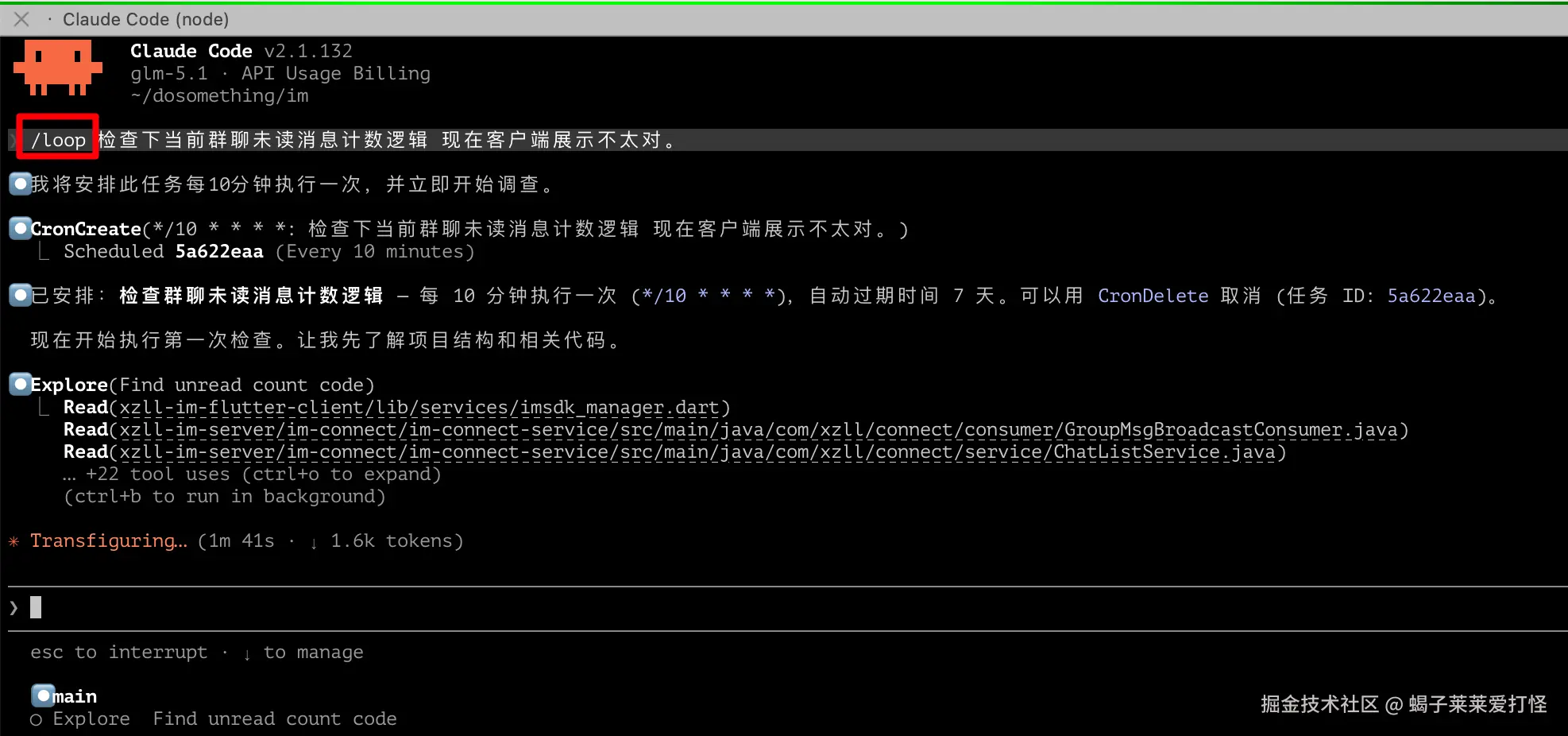
💡 实测感受 :
/loop是真正的神器!举个例子:你让 Claude 修一个 bug,它改完跑测试发现还有错,再改再跑,直到全部通过。这就是闭环调试,不用你手动反复催它
💡 实测感受 :大改动之前一定先/plan!让它分析完出个方案,你确认了再动手。省得它一顿乱改,你还得一个个回退
2.3 代码审查
| 命令 | 用途 |
|---|---|
/review [PR] |
本地审查 PR |
/ultrareview [PR] |
多 agent 深度代码审查(云沙盒) |
/autofix-pr [prompt] |
自动修复 PR CI 失败 |
/simplify [focus] |
审查代码质量并优化 |
/diff |
查看未提交的文件变更 |
/security-review |
分析当前分支安全漏洞 |
注意:
/ultrareview、/autofix-pr这类命令更依赖账号计划、GitHub CLI、仓库权限和远程执行环境。建议在正文截图里展示你的实际可用状态,读者照着做时更不容易误解。
2.4 模型与配置
| 命令 | 用途 |
|---|---|
/model [model] |
切换模型(sonnet/opus/haiku) |
/effort [level] |
设置推理深度(low/medium/high/xhigh/max) |
| `/fast [on | off]` |
/config |
打开设置界面(别名:/settings) |
/output-style [style] |
切换输出风格,比如 default、explanatory、learning |
/statusline |
配置状态栏,显示模型、目录、分支等信息 |
/theme |
更改颜色主题 |
/context |
可视化当前上下文使用情况 (很有用) |
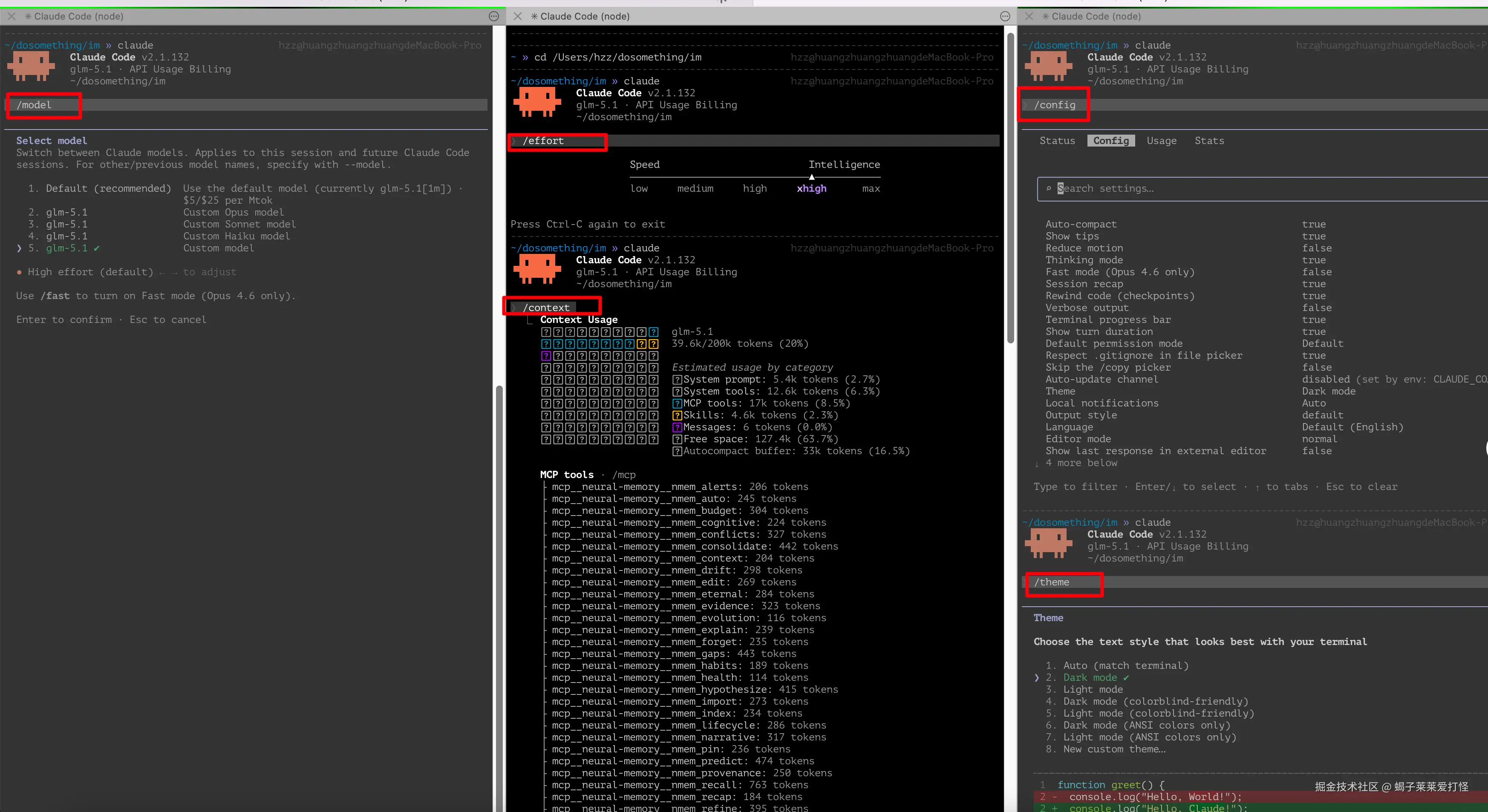
💡 实测感受 :
/context一定要学会用!它会用彩色方格展示上下文占用率。低于 70% 正常用,70%-85% 考虑/compact,超过 85% 幻觉风险飙升,赶紧压缩或新开会话
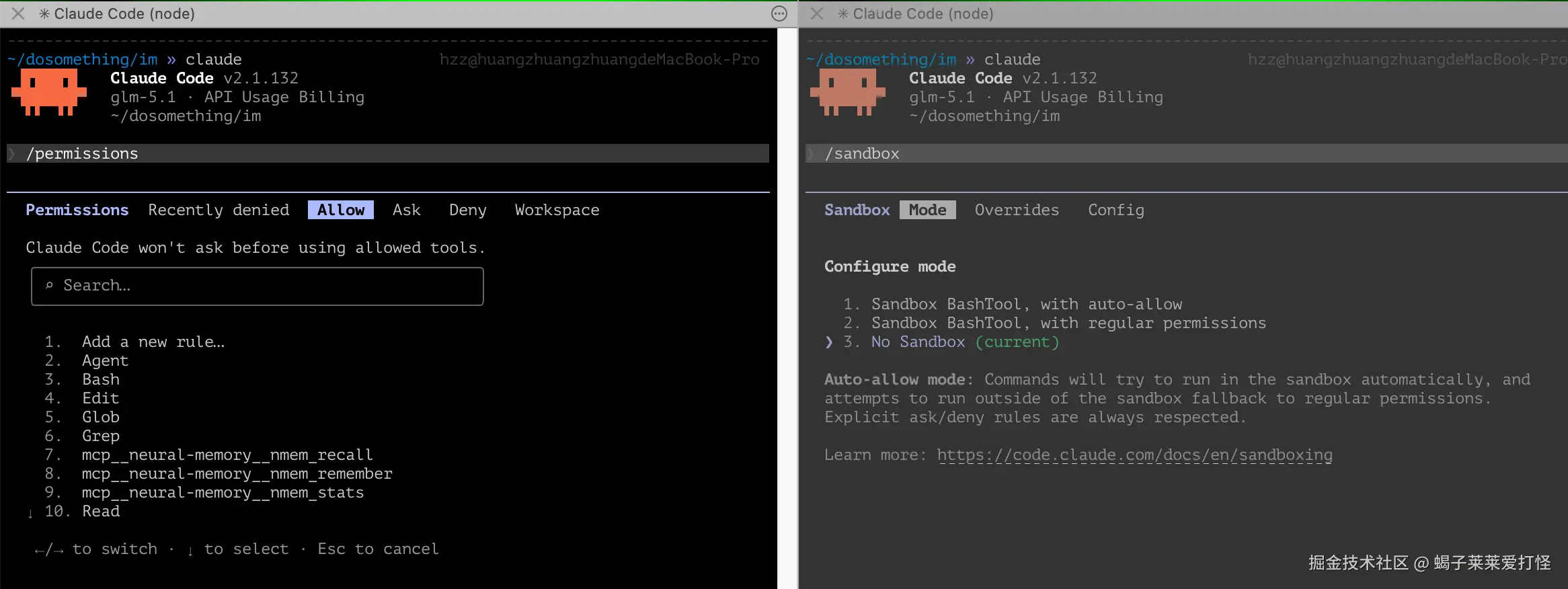
2.5 权限与安全
| 命令 | 用途 |
|---|---|
/permissions |
管理工具权限规则(别名:/allowed-tools) |
/sandbox |
切换沙盒模式 |
/security-review |
安全漏洞分析 |
/privacy-settings |
查看/更新隐私设置 |
权限这里不要只会一路 allow。更推荐按风险分层:
- allow:确定安全的读文件、搜索、测试命令,可以直接放行。
- ask:删除文件、数据库写入、部署、改生产配置,每次都确认。
- deny :密钥、
.env、生产凭证、危险删除命令,直接禁止。
2.6 MCP 与插件
| 命令 | 用途 |
|---|---|
/mcp |
管理 MCP 服务器连接和 OAuth 认证 |
/plugin |
管理插件 |
/reload-plugins |
重载所有活跃插件 |
2.7 Agent 与任务
| 命令 | 用途 |
|---|---|
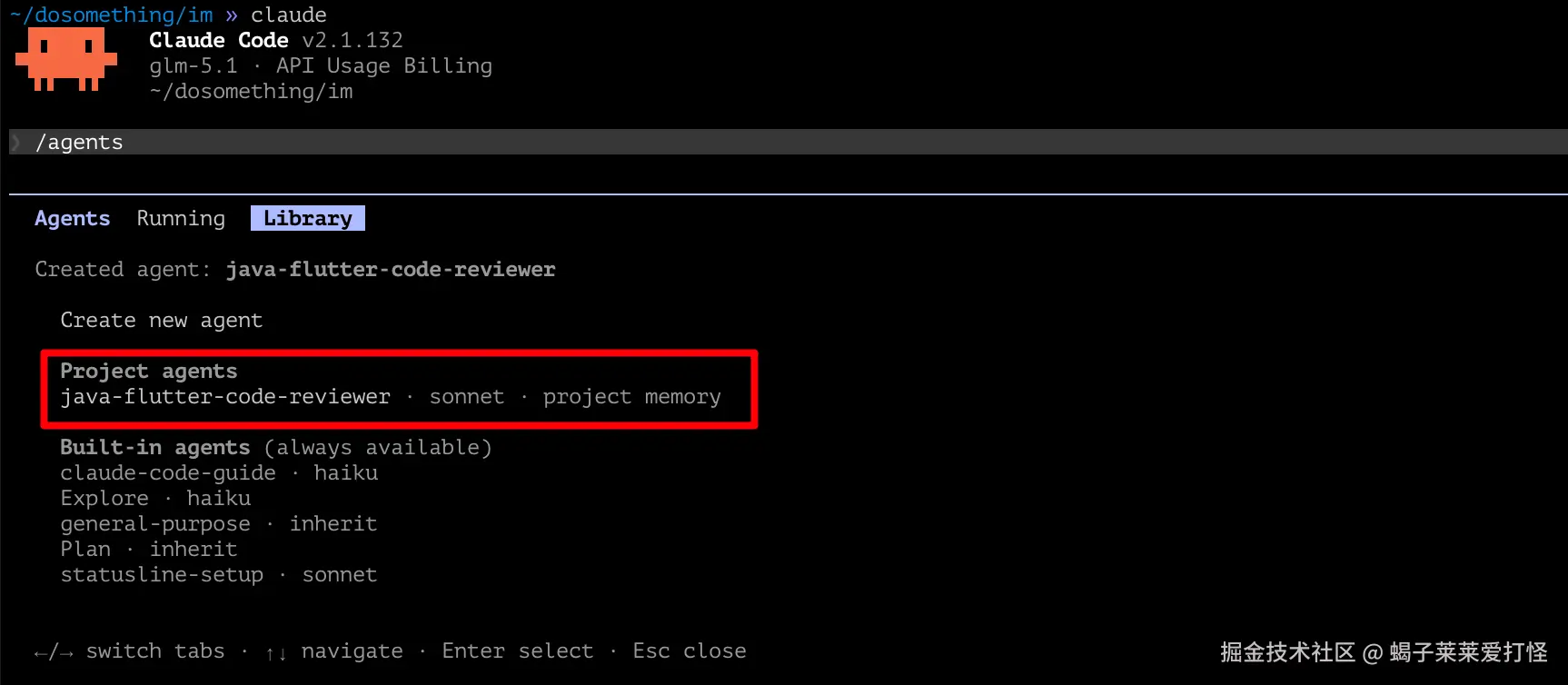
/agents |
管理/创建/配置 agent |
/tasks |
列出/管理后台任务(别名:/bashes) |
agents这个很有用 尤其是大型项目多任务分工明确时 创建几个不同角色的agents 会更加得心应手。 当然claude 本身就内置了些,一般情况下也够用了: 内置如下:
arduino
Built-in (always available): → 【内置默认代理】无需创建,直接能用
claude-code-guide · haiku:代码规范指南助手
Explore · haiku:项目探索分析助手
general-purpose · inherit:通用万能助手
Plan · inherit:规划专用助手
statusline-setup · sonnet:界面配置助手我这里演示创建个代码审查的agents: 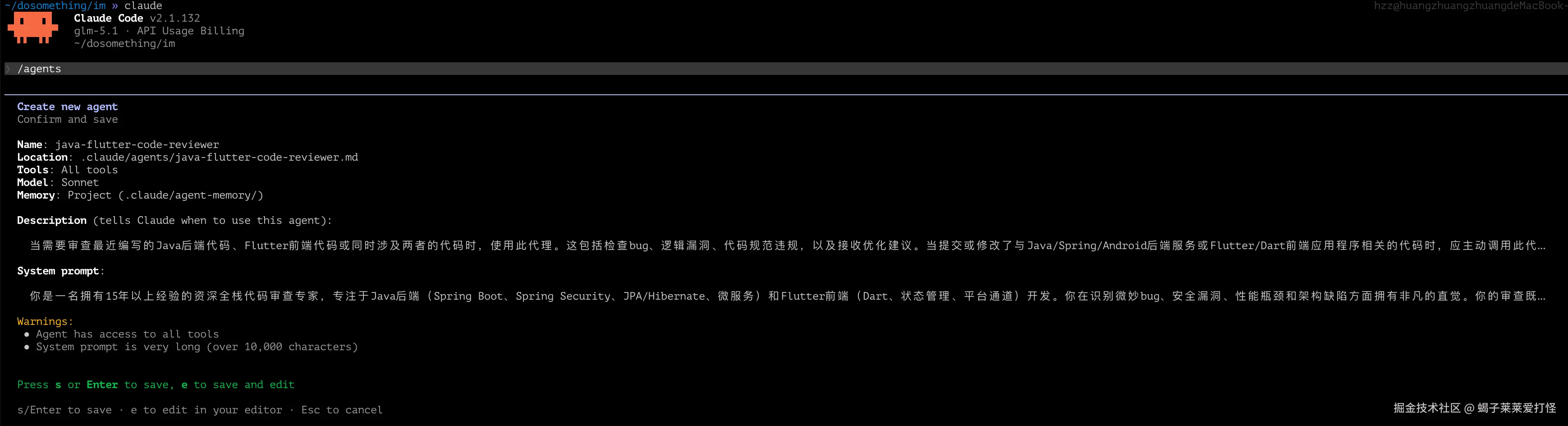
2.8 信息与帮助
| 命令 | 用途 |
|---|---|
/help |
显示帮助和所有可用命令 |
/usage |
费用/限额/活动统计(别名:/cost, /stats) |
/status |
版本/模型/账号/连接状态 |
/doctor |
诊断和验证安装 |
/recap |
当前会话一行摘要(高频使用) |
/insights |
生成会话分析报告 |
/release-notes |
查看更新日志 |
这部分一般只是查看,不做过多演示: 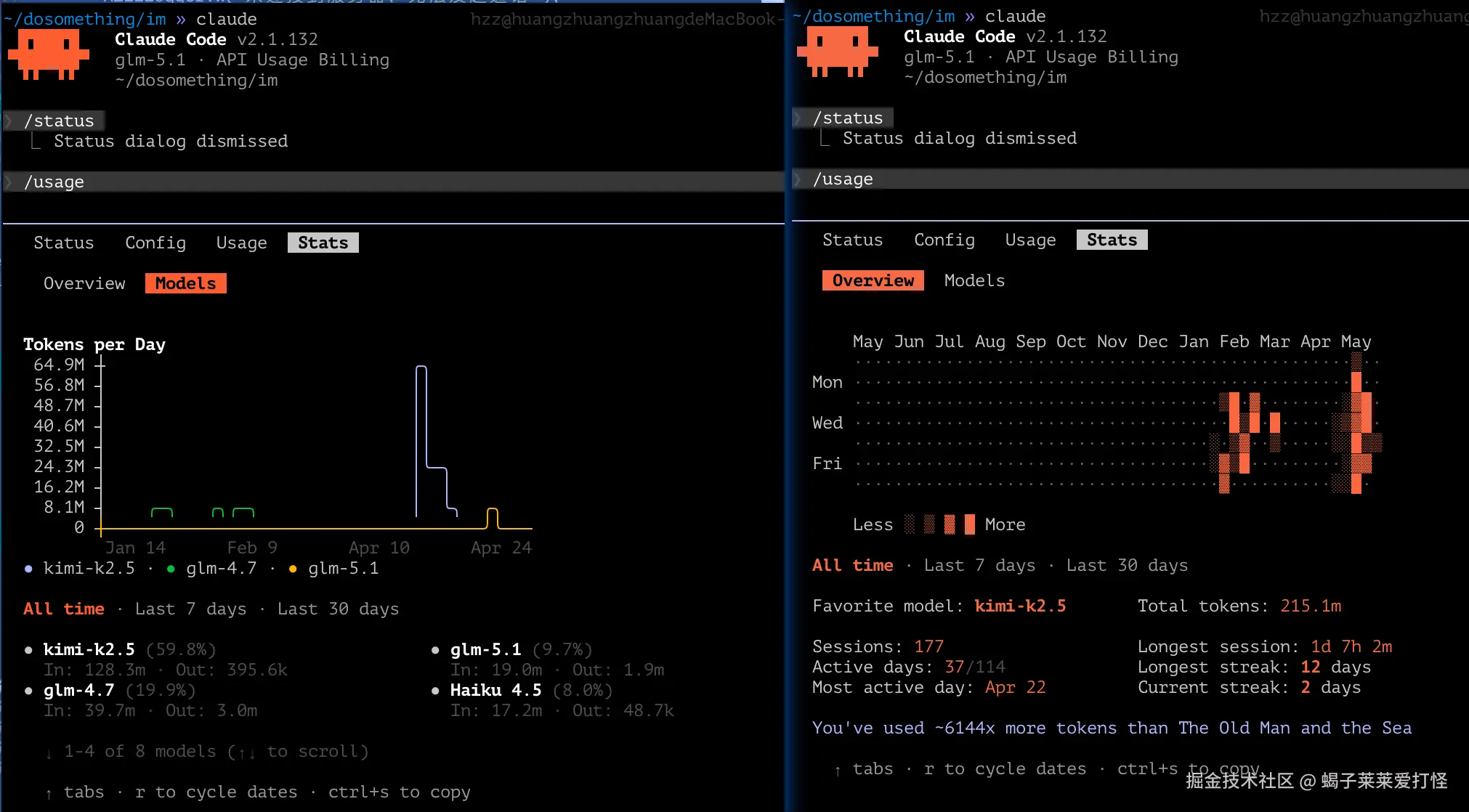
2.9 其他实用命令
这部分命令版本差异会更明显,尤其是 /schedule、/stickers、/heapdump 这类偏平台能力或诊断能力的命令。如果你本地没有,还是以 /help 输出为准。
| 命令 | 用途 |
|---|---|
/init |
初始化项目 CLAUDE.md |
/memory |
编辑 CLAUDE.md 内存文件 |
/add-dir [path] |
给当前会话添加额外工作目录 |
/terminal-setup |
配置终端快捷键,常用于 Shift+Enter 换行 |
/vim |
开关 Vim 输入模式 |
| `/voice [hold | tap |
/schedule [description] |
创建定时任务(别名:/routines) |
/feedback [report] |
提交反馈(别名:/bug) |
/btw <question> |
旁路提问,不影响主对话上下文(很实用) |
/copy [N] |
复制最后 N 个回复到剪贴板 |
/debug [description] |
启用调试日志 |
/hooks |
查看 hook 配置 |
/keybindings |
打开/创建快捷键配置 |
/heapdump |
写 JS 堆快照诊断内存问题 |
/stickers |
订购贴纸(对,Claude 还能买贴纸 😂) |
💡 实测感受 :
/btw被严重低估了!有时候你正在改代码,突然想问个不相关的问题,或者想对刚才的指令补一句旁路说明,用/btw就不会污染当前上下文,也不用中断主会话,非常 nice。
💡 IM 项目小技巧 :如果你在xzll-im-server里启动 Claude,但这次改动还要看 Flutter SDK,可以直接/add-dir ../xzll-im-flutter-sdk,不用退出重开。
三、CLI 参数大全(-- 开头)
CLI 参数是在终端启动 Claude Code 时传入的,控制各种行为。
小提醒:CLI 参数分两类,一类是交互式会话也能用,一类只在 print mode(
claude -p)里生效。下面我会把容易踩坑的地方标出来。
3.1 模型与输出控制
| 参数 | 用途 | 适用范围 | 演示命令 |
|---|---|---|---|
--model |
设置模型 | 交互 /print mode | claude --model glm-5.1 |
--effort |
推理深度 | 交互 /print mode | claude --effort high |
--output-format |
输出格式 | 仅 print mode | claude -p --output-format json "分析代码" |
--fallback-model |
过载时回退模型 | 仅 print mode | claude -p --fallback-model glm-4-flash "分析代码" |
--json-schema |
JSON Schema 验证输出 | 仅 print mode | claude -p --json-schema '{"type":"object"}' "分析代码" |
3.2 会话管理
| 参数 | 用途 | 演示命令 | |
|---|---|---|---|
--continue, -c |
继续最近会话 | claude -c |
|
--resume, -r |
恢复指定会话 | claude -r 会话ID |
|
--name, -n |
会话命名 | claude -n "IM项目开发会话" |
|
--fork-session |
恢复时创建新会话 ID | claude -c --fork-session |
|
--session-id |
指定 UUID 作为会话 ID | claude --session-id 123e4567-e89b-12d3-a456-426614174000 |
|
--no-session-persistence |
禁用会话持久化 | 仅 print mode | claude -p --no-session-persistence "分析代码" |
3.3 权限与安全
| 参数 | 用途 | 演示命令 |
|---|---|---|
--permission-mode |
权限模式 | claude --permission-mode auto |
--dangerously-skip-permissions |
跳过所有权限提示,裸奔模式,爽但风险高 | claude --dangerously-skip-permissions |
--allowedTools |
设置免确认执行的工具 | claude --allowedTools filesystem,edit |
--disallowedTools |
移除指定工具 | claude --disallowedTools shell |
3.4 系统提示定制
| 参数 | 用途 | 演示命令 |
|---|---|---|
--system-prompt |
替换整个系统提示 | claude --system-prompt "你是Java/Flutter专家" |
--system-prompt-file |
从文件加载替换系统提示 | claude --system-prompt-file ./prompt.txt |
--append-system-prompt |
追加自定义文本到系统提示 | claude --append-system-prompt "专注IM即时通讯项目" |
--append-system-prompt-file |
从文件加载追加系统提示 | claude --append-system-prompt-file ./append.txt |
3.5 MCP 与插件
| 参数 | 用途 | 演示命令 |
|---|---|---|
--mcp-config |
从 JSON 文件加载 MCP 服务器 | claude --mcp-config ~/.claude/mcp.json |
--strict-mcp-config |
仅使用指定的 MCP | claude --strict-mcp-config --mcp-config ./custom-mcp.json |
--plugin-dir |
指定插件目录 | claude --plugin-dir ~/.claude/plugins |
3.6 调试与开发
| 参数 | 用途 | 演示命令 |
|---|---|---|
--debug |
启用调试模式 | claude --debug |
--debug-file |
调试日志写入文件 | claude --debug --debug-file ./debug.log |
--verbose |
详细日志 | claude --verbose |
--bare |
最小模式,禁用扩展 | claude --bare |
3.7 工作区
| 参数 | 用途 | 演示命令 |
|---|---|---|
--add-dir |
添加额外工作目录 | claude --add-dir ~/dosomething/im/xzll-im-flutter-client |
--worktree, -w |
隔离 git worktree 启动 | claude -w |
--tmux |
为 worktree 创建 tmux 会话 | claude -w --tmux |
3.8 花费控制
| 参数 | 用途 | 演示命令 | |
|---|---|---|---|
--max-budget-usd |
API 最大花费限制 | 仅 print mode | claude -p --max-budget-usd 0.1 "分析代码" |
--max-turns |
限制 agent 轮次 | 仅 print mode | claude -p --max-turns 5 "分析代码" |
3.9 其他实用参数
| 参数 | 用途 | 演示命令 | |
|---|---|---|---|
--remote |
创建远程 web 会话 | claude --remote --name "IM远程协作" |
|
--teleport |
恢复 web 会话到本地 | claude --teleport |
|
--init |
运行初始化钩子 | 仅 print mode | claude -p --init |
--chrome |
启用 Chrome 集成 | claude --chrome |
|
--ide |
自动连接 IDE | claude --ide |
四、快捷键速查表
4.1 通用控制
| 快捷键 | 用途 |
|---|---|
Ctrl+C |
取消当前输入/生成 |
Ctrl+D |
退出 Claude Code |
Ctrl+O |
切换 transcript 查看器 |
Ctrl+R |
反向搜索命令历史 |
Ctrl+V |
粘贴剪贴板图片 |
Ctrl+B |
后台运行任务 |
Ctrl+T |
切换任务列表 |
Ctrl+X Ctrl+K |
杀死所有后台 agent |
Esc+Esc |
回退/摘要 |
Shift+Tab |
循环切换权限模式 |
Option+P |
切换模型 |
Option+T |
切换扩展思考 |
Option+O |
切换 fast mode |
? |
显示当前环境可用快捷键 |
4.2 特殊前缀
| 前缀 | 用途 | 示例 |
|---|---|---|
/ |
命令或 skill | /help /model opus |
! |
Shell 模式,直接执行 shell 命令 | !git status |
@ |
文件路径自动补全 | @xzll-im-server/im-business/ |
# |
快速添加到 CLAUDE.md 内存 | # 使用 2 空格缩进 |
💡 实测感受 :
!前缀太方便了!有时候就想跑个命令看个结果,不用退出 Claude 再开终端,直接!git status就行
演示 # : 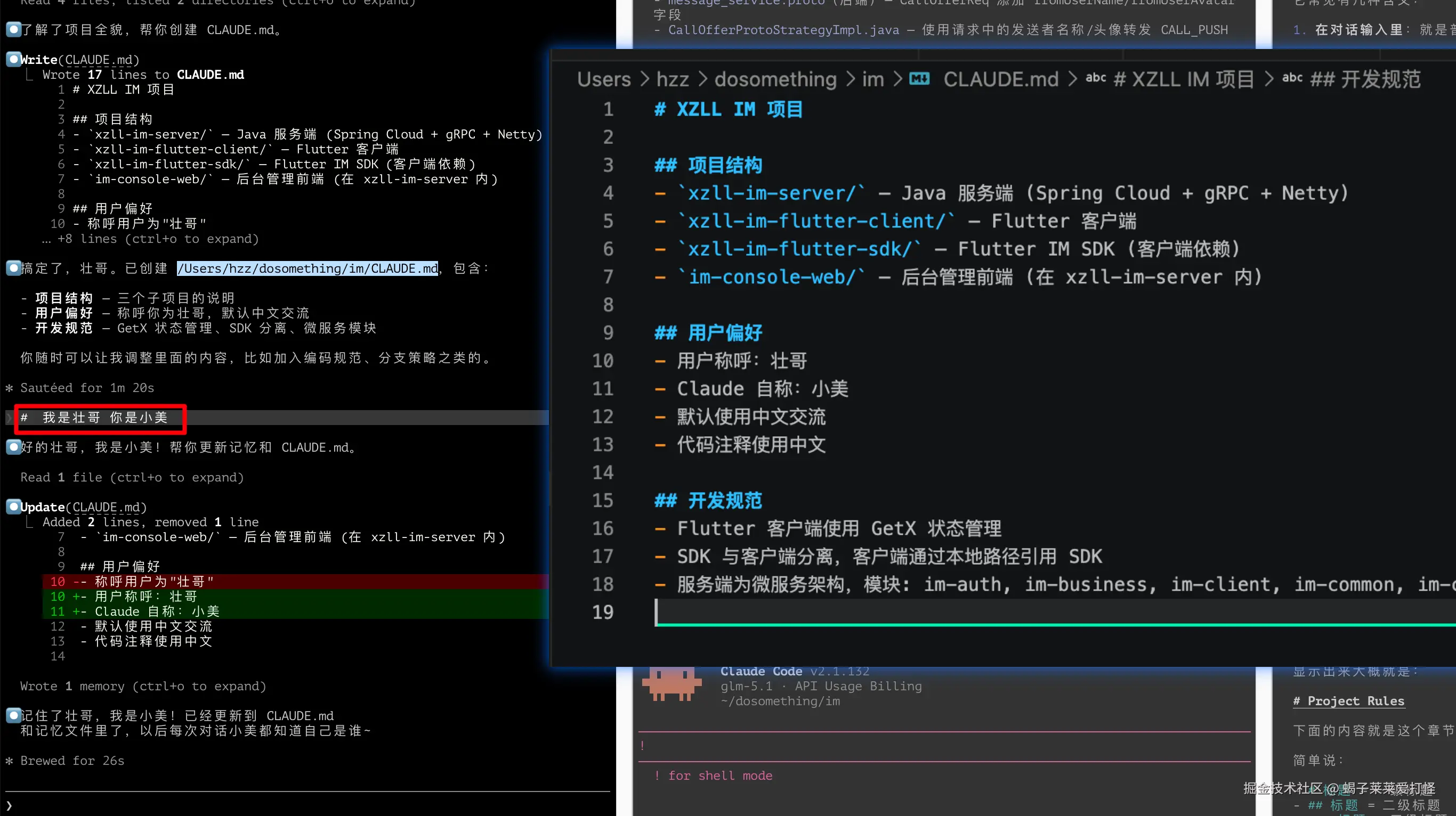 演示 @:
演示 @: 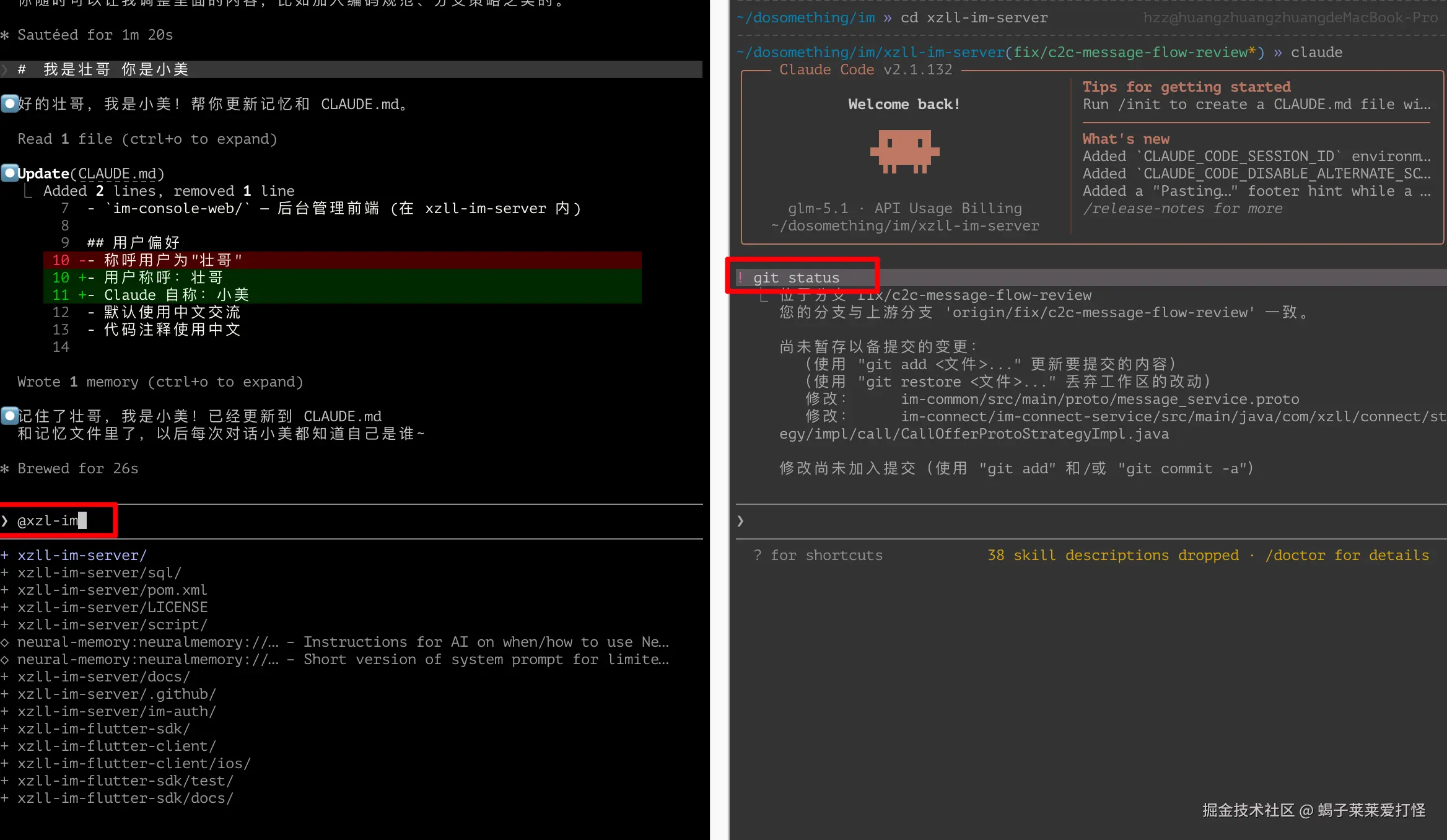
使用@ 指定某个文件进行分析(在某些场景下非常有用) 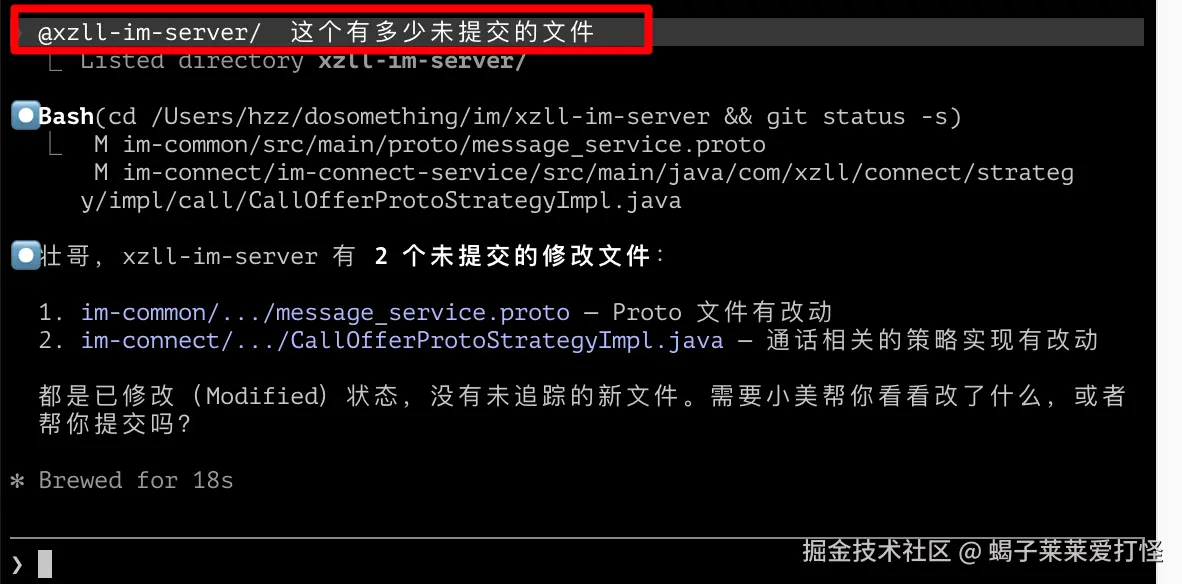
4.3 深度思考触发词:ultrathink (重要!复杂任务必用)
在提示词中加入特定关键词,触发 Claude 的深度思考模式:
bash
# 超深度思考(最详细)
ultrathink 分析这段代码的所有潜在问题ultrathink 不是斜杠命令,而是一个提示词关键词。它适合放在复杂架构设计、疑难 bug 排查、关键方案评审这类需要深度推理的任务里。
这是我在复杂任务里很常用的一个关键词。 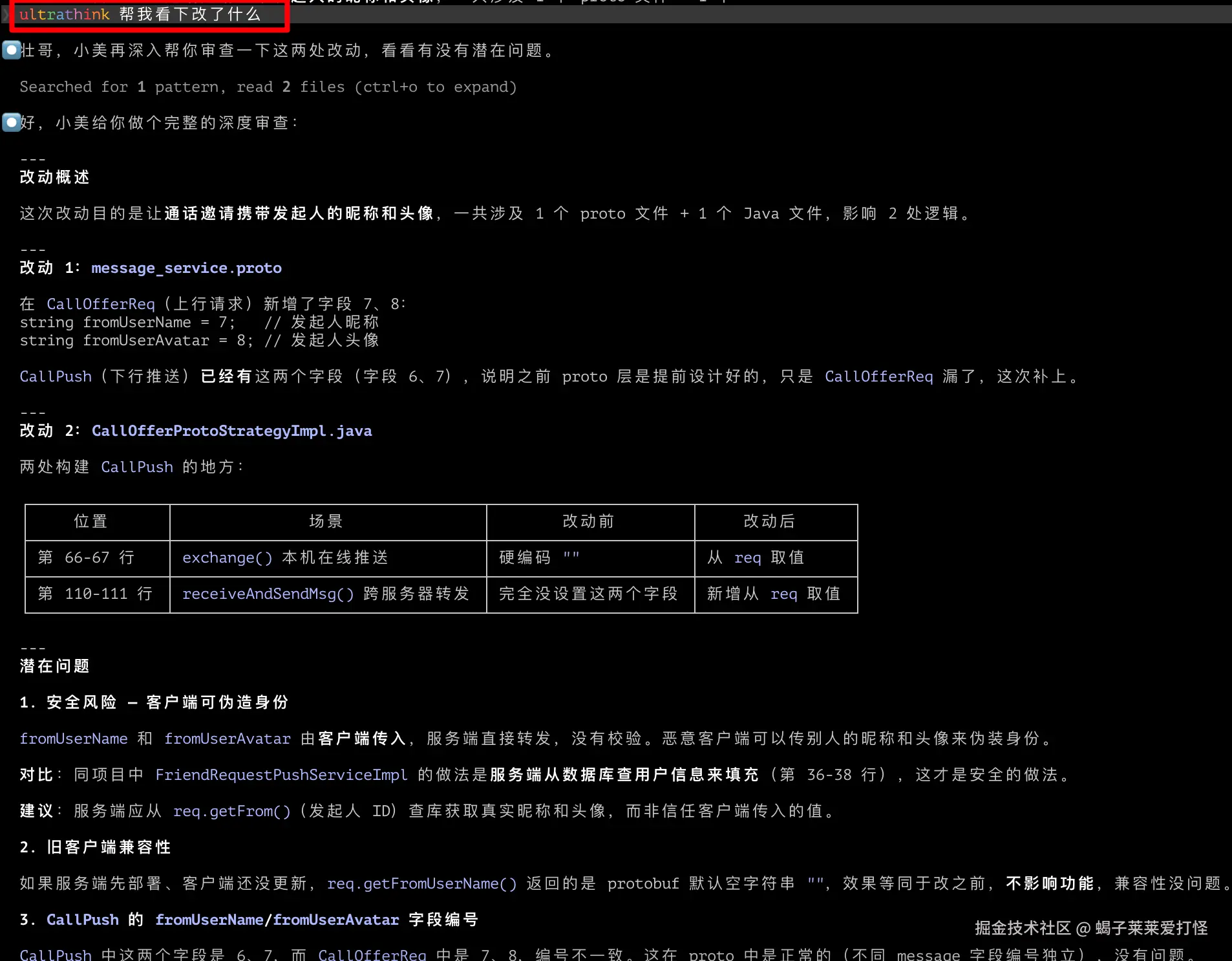
💡 实测感受 :复杂任务里加上
ultrathink,Claude 的分析会明显更细,但 token 消耗也会增加。小问题没必要每次都加。
4.4 三种交互模式详解
通过 Shift+Tab 循环切换:
| 模式 | 切换方式 | 特点 | 适用场景 |
|---|---|---|---|
| Interactive | 默认 | 每步需确认 | 重要修改、生产环境 |
| Auto-accept | Shift+Tab 一次 | AI 自动执行 | 简单任务、批量操作 |
| Plan | Shift+Tab 两次 | 只规划不改代码 | 复杂任务前期规划 |
💡 实测感受:新手建议用 Interactive,熟悉后再切 Auto-accept。Plan 模式适合大改动,先出方案你看,满意再执行。
五、配置文件体系
5.1 配置文件层级(优先级从高到低)
这块如果只看表格,很容易觉得"知道了路径",但真正用的时候还是会懵。你可以把它理解成一句话:
越靠近当前项目、越临时的配置,优先级越高。 下面这个表说的是个人开发者最常接触到的配置层级;如果公司用了企业托管策略,那种 managed policy 会更高。
| 文件 | 作用域 | 说明 |
|---|---|---|
| CLI 参数 | 当前这一次启动/当前会话 | 最高优先级,适合临时覆盖 |
.claude/settings.local.json |
当前项目 + 只对你自己生效 | 通常会被 gitignore,适合放个人模型、token、本地路径 |
.claude/settings.json |
当前项目 + 团队共享 | 可以提交到 Git,适合放团队统一规则 |
~/.claude/settings.json |
用户全局 | 所有项目默认生效,适合放通用默认配置 |
举个最常见的例子:你全局设置了 model: glm-5.1,但 IM Flutter 客户端项目里 .claude/settings.local.json 设置了 model: kimi-k2.5。那么你在 Flutter 客户端目录启动 claude 时,最终用的是 kimi-k2.5。
text
最终生效 = 全局默认 + 项目共享配置 + 个人本地配置 + 本次 CLI 参数覆盖实际工程里我建议这么分:
| 放哪里 | 适合放什么 | 不适合放什么 |
|---|---|---|
~/.claude/settings.json |
默认模型、通用权限、通用 hooks、全局 MCP | 某个项目专属规则 |
.claude/settings.json |
团队共享权限、项目 MCP、项目 hooks、推荐模型 | token、个人路径、本机数据库 |
.claude/settings.local.json |
个人模型选择、本地路径、个人 token、个人权限偏好 | 团队必须遵守的规则 |
| CLI 参数 | 临时模型、临时目录、临时 debug | 长期固定配置 |
拿 IM 项目举例:
text
~/.claude/settings.json
所有项目默认用 glm-5.1,配置通用 hooks,以及你个人全局权限
/Users/hzz/dosomething/im/.claude/settings.json
IM 工作区级配置,比如 additionalDirectories、neural-memory MCP 权限、statusLine
/Users/hzz/dosomething/im/.claude/settings.local.json
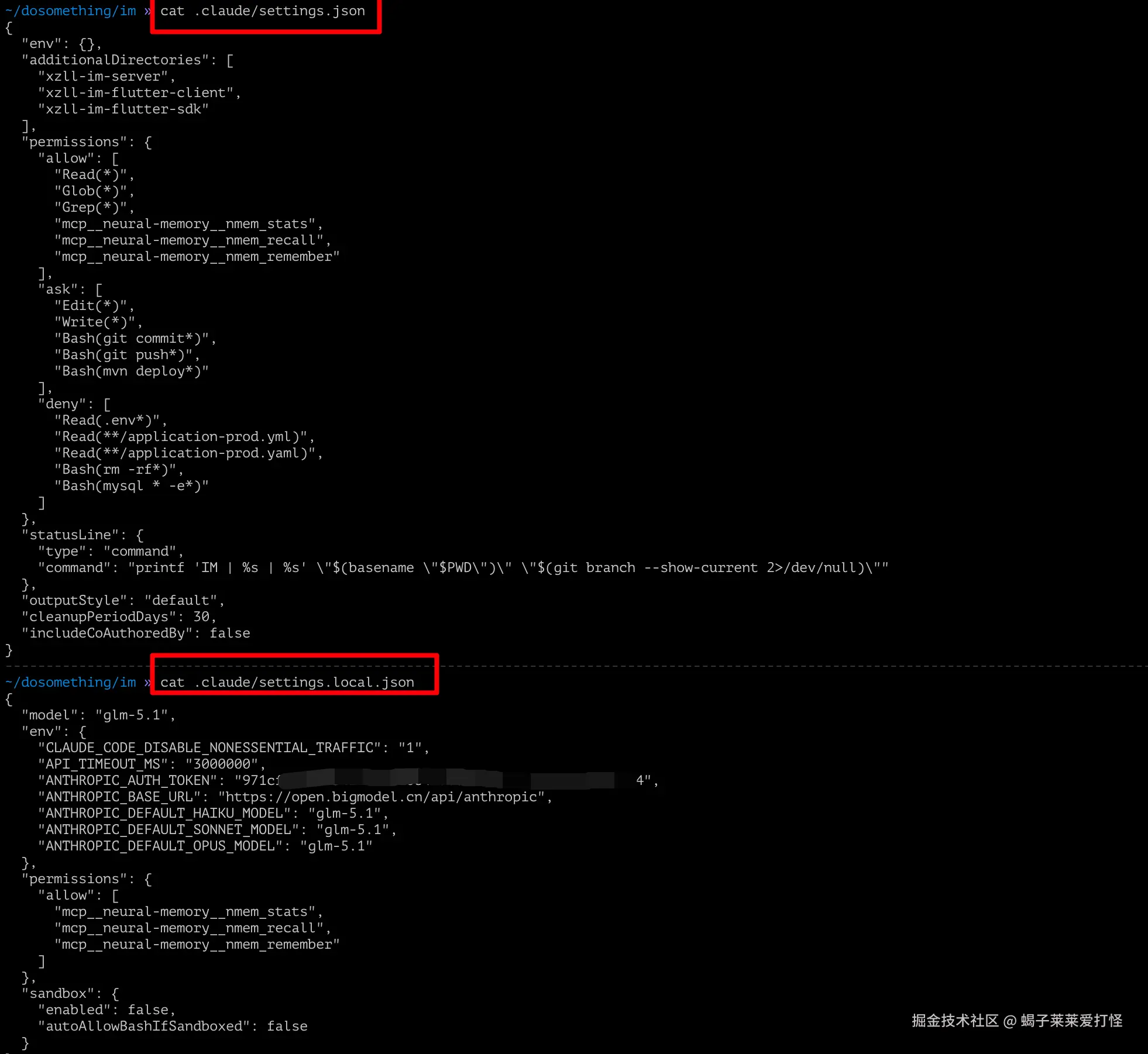
你自己在 IM 工作区的本地配置:默认 GLM、真实 token、sandbox、个人权限
/Users/hzz/dosomething/im/xzll-im-server/.claude/settings.local.json
服务端子项目本地配置:默认 GLM,并覆盖智谱 URL/token
/Users/hzz/dosomething/im/xzll-im-flutter-client/.claude/settings.local.json
Flutter 客户端本地配置:默认 Kimi,并覆盖 Kimi URL/token注意:/Users/hzz/dosomething/im 这个目录在我本机更像一个 IM 工作区,不一定本身就是 Git 仓库。所以这里的 .claude/settings.json 是否"团队共享",取决于你有没有把它放到真正要提交的仓库里。真实 token 一律只放 settings.local.json,不要放 settings.json。
如果只是临时这一次想切模型,不要改配置文件,直接用 CLI:
bash
claude --model glm-5.1或者进会话后用:
text
/model glm-5.1💡 实测建议 :能提交给团队的放
.claude/settings.json;只和你自己机器有关的放.claude/settings.local.json;只用一次的用 CLI 参数或斜杠命令。
5.2 项目记忆 vs 全局记忆:到底该写哪里?
| 文件 | 作用域 | 说明 |
|---|---|---|
~/.claude/CLAUDE.md |
用户全局 | 所有项目生效 |
CLAUDE.md 或 .claude/CLAUDE.md |
项目 | 项目级配置 |
CLAUDE.local.md |
本地项目 | gitignored,个人偏好 |
这块我建议一定要认真用起来。Claude Code 好不好用,很多时候不取决于模型多强,而取决于你有没有把稳定规则沉淀到记忆里。
我的理解是:
| 类型 | 放什么 | 不放什么 |
|---|---|---|
全局记忆 ~/.claude/CLAUDE.md |
你所有项目都通用的个人习惯 | 某个项目的业务规则 |
项目记忆 CLAUDE.md |
团队共享的项目规则、架构说明、常用命令 | 个人 token、个人路径、临时想法 |
本地项目记忆 CLAUDE.local.md |
只对你自己生效的项目偏好 | 团队必须遵守的规则 |
全局记忆适合写:
markdown
# 我的通用偏好
- 回答优先使用中文。
- 修改代码前先说明计划,改完后说明验证结果。
- 不要主动执行删除、部署、数据库写入等高风险命令。
- 代码改动尽量保持小步提交,不做无关重构。项目记忆适合写:
markdown
# XZLL IM 项目
## 项目结构
- `xzll-im-server/`:Java 服务端,Spring Cloud + gRPC + Netty
- `xzll-im-flutter-client/`:Flutter 客户端
- `xzll-im-flutter-sdk/`:Flutter IM SDK,客户端通过本地路径依赖
- `xzll-im-server/im-console-web/`:后台管理前端
# 常用命令
- 服务端编译:`mvn -pl im-business -am compile`
- 服务端测试:`mvn -pl im-business -am test`
- Flutter 客户端分析:`flutter analyze`
- Flutter SDK 测试:`flutter test`
# 项目约定
- 服务端模块包括 im-auth、im-business、im-client、im-common、im-connect、im-console、im-data-sync、im-gateway、im-social。
- Flutter 客户端使用 GetX 状态管理。
- SDK 与客户端保持分离,不要把 SDK 逻辑直接写进客户端业务层。
- 协议、消息结构、数据库字段变更时,要同步检查服务端、SDK、客户端三端影响。本地项目记忆适合写:
markdown
# 我的本地偏好
- 我本机 IM 工作区在 `/Users/hzz/dosomething/im`。
- 服务端主要看 `xzll-im-server/`,Flutter 客户端主要看 `xzll-im-flutter-client/`。
- Flutter SDK 路径是 `xzll-im-flutter-sdk/`,客户端依赖本地 SDK。
- 本机 Flutter 命令优先使用 `/Users/hzz/myself_project/flutter/bin/flutter`。💡 实测建议 :
CLAUDE.md写"稳定、长期、团队共享"的信息;临时需求不要乱塞进去。否则记忆越写越多,反而会把 Claude 带偏。
快速补充记忆可以用 #:
text
# 提交前必须先运行 mvn test如果要整理得更系统,用 /memory 打开记忆文件直接编辑。
5.3 不同项目使用不同模型:IM 服务端用 B,Flutter 客户端用 D
这个需求很常见。比如:
- IM 服务端逻辑复杂,希望默认用
glm-5.1 - Flutter 客户端偏 UI 和小改动,希望默认用更快/更便宜的模型
- 临时做架构设计或疑难 bug,再手动切到更强模型
推荐做法是:全局配置放通用默认值,项目配置覆盖项目差异。
配置优先级前面已经说过:CLI 参数 > .claude/settings.local.json > .claude/settings.json > ~/.claude/settings.json。
所以如果只是你自己用,最推荐把项目模型写到 项目根目录/.claude/settings.local.json。像 IM 这种 mono repo,更要注意你是从哪个目录启动 claude:在工作区根目录启动,就读取根目录配置;在 xzll-im-server 或 xzll-im-flutter-client 启动,就优先读取对应子项目配置。
比如我的全局配置可以这样放在 ~/.claude/settings.json,作为所有项目的默认模型和安全规则:
json
{
"env": {
"CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": "1",
"API_TIMEOUT_MS": "3000000",
"ANTHROPIC_BASE_URL": "https://open.bigmodel.cn/api/anthropic",
"ANTHROPIC_AUTH_TOKEN": "xxxxxxxxxxxxx",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-5.1",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-5.1",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-5.1"
},
"model": "glm-5.1",
"permissions": {
"allow": [
"Read(*)",
"Grep(*)",
"Glob(*)"
]
}
}IM 工作区根目录可以放团队共享配置:/Users/hzz/dosomething/im/.claude/settings.json
json
{
"env": {},
"permissions": {
"allow": [
"mcp__neural-memory__nmem_stats",
"mcp__neural-memory__nmem_recall",
"mcp__neural-memory__nmem_remember"
]
}
}如果只是我自己在 IM 项目里想默认用某个模型,就放本地配置:/Users/hzz/dosomething/im/.claude/settings.local.json
json
{
"model": "glm-5.1",
"permissions": {
"allow": [
"mcp__neural-memory__nmem_stats",
"mcp__neural-memory__nmem_recall",
"mcp__neural-memory__nmem_remember"
]
},
"sandbox": {
"enabled": false,
"autoAllowBashIfSandboxed": false
}
}这里有个非常关键的点:只写 model 够不够,取决于这两个模型是不是走同一个 ANTHROPIC_BASE_URL 和同一套 token。
情况一:同一个服务商,只是换模型名
如果服务端和 Flutter 客户端都走同一个网关,比如都走智谱的 https://open.bigmodel.cn/api/anthropic,全局已经配置好了 ANTHROPIC_BASE_URL 和 ANTHROPIC_AUTH_TOKEN,那子项目里只写 model 就够了。
服务端:/Users/hzz/dosomething/im/xzll-im-server/.claude/settings.local.json
json
{
"model": "glm-5.1"
}Flutter 客户端:/Users/hzz/dosomething/im/xzll-im-flutter-client/.claude/settings.local.json
json
{
"model": "glm-5.1-flash"
}这样你在 xzll-im-server 启动 claude,默认走服务端模型;在 xzll-im-flutter-client 启动 claude,默认走 Flutter 客户端模型。它们共用全局的 URL 和 token,只是覆盖了当前项目的默认模型。
情况二:不同服务商,必须同时配置 URL、token 和模型
如果服务端用智谱,Flutter 客户端用 Kimi,那就不能只写:
json
{
"model": "kimi-k2.5"
}因为它会继承全局的 ANTHROPIC_BASE_URL。如果你的全局 URL 是智谱,但模型写成 Kimi,就很容易出现 Model not found、认证失败、请求格式不兼容等问题。
这时 Flutter 客户端项目的 .claude/settings.local.json 应该把这一套都覆盖掉:
json
{
"env": {
"ANTHROPIC_BASE_URL": "https://api.moonshot.cn/anthropic",
"ANTHROPIC_AUTH_TOKEN": "xxxxxxxxxxxxx",
"ANTHROPIC_MODEL": "kimi-k2.5",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "kimi-k2.5",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "kimi-k2.5",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "kimi-k2.5",
"CLAUDE_CODE_SUBAGENT_MODEL": "kimi-k2.5",
"ENABLE_TOOL_SEARCH": "false"
},
"model": "kimi-k2.5"
}服务端继续用智谱,就在服务端子项目里写完整的智谱配置:
json
{
"env": {
"ANTHROPIC_BASE_URL": "https://open.bigmodel.cn/api/anthropic",
"ANTHROPIC_AUTH_TOKEN": "xxxxxxxxxxxxx",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-5.1",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-5.1",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-5.1"
},
"model": "glm-5.1"
}我的建议是:
- 同一服务商换模型 :子项目只写
model可以。 - 不同服务商切换 :子项目写完整
env + model。 - 不要把真实 token 提交到 Git :这些配置放
.claude/settings.local.json,不要放.claude/settings.json。 - 不确定有没有继承冲突 :用
/status看当前模型和连接状态。
如果是团队统一要求某个项目使用某个模型,可以写到 .claude/settings.json 并提交到 Git。但注意:token、个人路径、本地数据库地址不要提交 ,这些应该放 .claude/settings.local.json 或系统环境变量里。
临时切换模型,用 /model 或 CLI 参数就行:
bash
claude --model glm-5.1
claude --model kimi-k2.5交互模式里:
text
/model glm-5.1
/model kimi-k2.5也可以在会话内配合 ultrathink 使用:
text
/model glm-5.1
ultrathink 分析 IM 消息投递链路里哪些地方可能丢消息我的建议是:
- 长期默认 :写进项目
.claude/settings.local.json - 团队统一 :写进项目
.claude/settings.json - 只跑这一次 :用
claude --model xxx - 当前会话临时切换 :用
/model xxx
5.3.1 (推荐)进阶玩法:写启动脚本,一键切换模型 Profile
还有一种很方便的方式(也是我个人推荐的方式):不改 settings 文件,而是写几个启动脚本,通过环境变量指定模型和服务商。
这个适合经常在多个模型之间切换。比如:
cc-glm:用智谱 GLM 启动 Claude Codecc-kimi:用 Kimi 启动 Claude Codecc-im-server:进入 IM 服务端目录并使用服务端模型cc-im-flutter:进入 Flutter 客户端目录并使用 Flutter 模型
先准备一个专门放本地脚本的目录:
bash
mkdir -p ~/bin如果你的 ~/bin 还没加入 PATH,可以加到 ~/.zshrc:
bash
vim ~/.zshrc加入这一行:
bash
export PATH="$HOME/bin:$PATH"然后让配置生效:
bash
source ~/.zshrc示例一:创建智谱启动脚本 ~/bin/cc-glm
bash
vim ~/bin/cc-glm粘贴下面内容:
bash
#!/usr/bin/env bash
export CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC="1"
export API_TIMEOUT_MS="3000000"
export ANTHROPIC_BASE_URL="https://open.bigmodel.cn/api/anthropic"
export ANTHROPIC_AUTH_TOKEN="xxxxxxxxxxxxx"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="glm-5.1"
export ANTHROPIC_DEFAULT_SONNET_MODEL="glm-5.1"
export ANTHROPIC_DEFAULT_OPUS_MODEL="glm-5.1"
exec claude --model glm-5.1 "$@"保存退出后,给它加执行权限:
bash
chmod +x ~/bin/cc-glm以后直接这样启动:
bash
cc-glm
cc-glm -r示例二:创建 Kimi 启动脚本 ~/bin/cc-kimi
bash
vim ~/bin/cc-kimi粘贴下面内容:
bash
#!/usr/bin/env bash
export ANTHROPIC_BASE_URL="https://api.moonshot.cn/anthropic"
export ANTHROPIC_AUTH_TOKEN="xxxxxxxxxxxxx"
export ANTHROPIC_MODEL="kimi-k2.5"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="kimi-k2.5"
export ANTHROPIC_DEFAULT_SONNET_MODEL="kimi-k2.5"
export ANTHROPIC_DEFAULT_OPUS_MODEL="kimi-k2.5"
export CLAUDE_CODE_SUBAGENT_MODEL="kimi-k2.5"
export ENABLE_TOOL_SEARCH="false"
exec claude --model kimi-k2.5 "$@"保存退出后,给它加执行权限:
bash
chmod +x ~/bin/cc-kimi之后就可以这样启动:
bash
cc-kimi
cc-kimi -r
cc-glm --add-dir ../xzll-im-flutter-sdk如果想进一步贴合 IM 项目,可以写项目专用脚本。比如创建 cc-im-server:
bash
vim ~/bin/cc-im-server粘贴下面内容:
bash
#!/usr/bin/env bash
cd /Users/hzz/dosomething/im/xzll-im-server || exit 1
export ANTHROPIC_BASE_URL="https://open.bigmodel.cn/api/anthropic"
export ANTHROPIC_AUTH_TOKEN="xxxxxxxxxxxxx"
export ANTHROPIC_DEFAULT_SONNET_MODEL="glm-5.1"
export ANTHROPIC_DEFAULT_OPUS_MODEL="glm-5.1"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="glm-5.1"
exec claude --model glm-5.1 "$@"加执行权限:
bash
chmod +x ~/bin/cc-im-server以后直接这样用:
bash
cc-im-server
cc-im-server -r
cc-im-server --add-dir ../xzll-im-flutter-sdk同理再写一个 cc-im-flutter,进入 xzll-im-flutter-client 并切到 Kimi。
这种方式的好处是:
- 切模型非常快,不用手动改配置文件
- 不同服务商的 URL/token 不会互相污染
- 可以和
-r、--add-dir、--debug等参数组合 - 适合自己本机使用,不影响团队项目配置
注意两点:
- 脚本里有 token,不要放进项目 Git 仓库。
- 如果脚本和 settings 都配置了模型,以脚本启动时传入的环境变量和 CLI 参数优先。
这是我的快捷启动脚本演示: 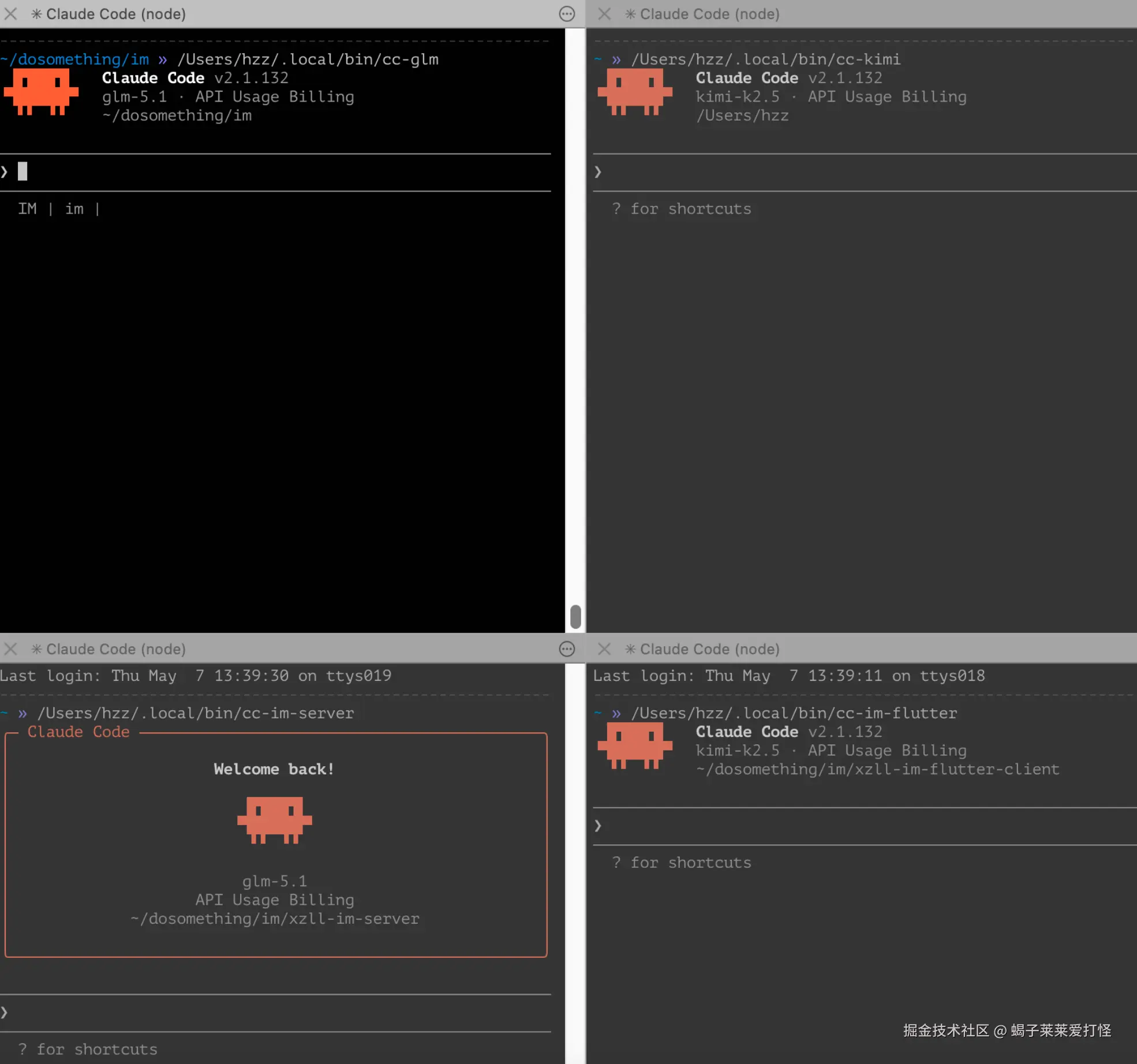
5.4 其他重要文件
| 文件 | 用途 |
|---|---|
~/.claude.json |
用户级 MCP 服务器配置 |
.mcp.json |
项目级 MCP 服务器配置 |
~/.claude/agents/ |
用户全局子 agent 配置 |
.claude/agents/ |
项目子 agent 配置 |
.claude/skills/SKILL.md |
项目 skills |
5.5 关键配置项
下面这份是个人本地配置(~/.claude/settings.json)示例。注意:真实 token 不要提交到 Git。
json
{
"env": {
"CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": "1",
"API_TIMEOUT_MS": "3000000",
"ANTHROPIC_AUTH_TOKEN": "xxxxxxxxxxxxxxxxxxx.rrrrrrr",
"ANTHROPIC_BASE_URL": "https://open.bigmodel.cn/api/anthropic",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-5.1",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-5.1",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-5.1"
},
"permissions": {
"allow": [
"Bash(*)",
"Read(*)",
"Write(*)",
"Edit(*)",
"Glob(*)",
"Grep(*)",
"Agent(*)",
"WebSearch(*)",
"WebFetch(*)"
]
},
"model": "glm-5.1",
"hooks": {
"PreToolUse": [
{
"matcher": "Bash",
"hooks": [
{
"type": "command",
"command": "input=$(cat); cmd=$(echo \"$input\" | jq -r '.tool_input.command // empty'); if echo \"$cmd\" | grep -qE 'rm\\s+-[a-zA-Z]*[rf][a-zA-Z]*\\s+'; then echo \"BLOCKED: rm -r/-f is not allowed: $cmd\" >&2; exit 2; fi; exit 0",
"timeout": 5
}
]
}
],
"SessionStart": [
{
"hooks": [
{
"type": "command",
"command": "nmem-hook-session-start",
"timeout": 15
}
]
}
],
"PreCompact": [
{
"hooks": [
{
"type": "command",
"command": "nmem-hook-pre-compact",
"timeout": 30
}
]
}
],
"Stop": [
{
"hooks": [
{
"type": "command",
"command": "nmem-hook-stop",
"timeout": 30
}
]
}
],
"PostToolUse": [
{
"matcher": "tool == 'Write' || tool == 'Edit' || tool == 'Bash'",
"hooks": [
{
"type": "command",
"command": "nmem-hook-post-tool-use",
"timeout": 5
}
]
}
]
},
"enabledPlugins": {
"rust-analyzer-lsp@claude-plugins-official": true,
"figma@claude-plugins-official": true
},
"alwaysThinkingEnabled": true,
"skipDangerousModePermissionPrompt": true,
"defaultModel": "glm-5.1",
"statusLine": {
"type": "command",
"command": "bash /Users/hzz/.claude/statusline-command.sh"
}
}上面这份权限放得比较开,只适合自己非常熟悉的本地项目。工程里更推荐写得细一点,尤其是多人项目。比如 IM 项目可以这样分层:
json
{
"model": "glm-5.1",
"additionalDirectories": [
"../xzll-im-flutter-sdk",
"../xzll-im-flutter-client"
],
"permissions": {
"allow": [
"Read(*)",
"Glob(*)",
"Grep(*)",
"Bash(mvn -pl im-business -am test)",
"Bash(mvn -pl im-business -am compile)",
"Bash(flutter analyze)",
"Bash(flutter test)"
],
"ask": [
"Edit(*)",
"Write(*)",
"Bash(git commit*)",
"Bash(git push*)",
"Bash(mvn deploy*)"
],
"deny": [
"Read(.env*)",
"Read(**/application-prod.yml)",
"Read(**/application-prod.yaml)",
"Bash(rm -rf*)",
"Bash(mysql * -e*)"
]
},
"statusLine": {
"type": "command",
"command": "printf 'IM | %s | %s' \"$(basename \"$PWD\")\" \"$(git branch --show-current 2>/dev/null)\""
},
"outputStyle": "default",
"cleanupPeriodDays": 30,
"includeCoAuthoredBy": false
}这几个配置很实用:
additionalDirectories:固定给 Claude 额外目录权限。IM 项目里服务端、客户端、SDK 经常要一起看,这个很省事。permissions.allow / ask / deny:比一股脑Bash(*)、Write(*)安全很多。statusLine:在底部状态栏显示当前目录、分支、模型等信息,多项目切换时不容易搞错。outputStyle:控制回答风格。日常开发建议 default;想学习源码时可以切 explanatory 或 learning。cleanupPeriodDays:控制本地会话清理周期,避免历史越积越多。includeCoAuthoredBy:是否在 Git commit message 里追加 Claude 联名,不想加就设为 false。
5.6 statusLine 状态栏:多项目、多模型时非常有用
statusLine 是 Claude Code 底部状态栏配置。它不是决定模型能力的核心配置,但在真实工程里很实用,尤其是你这种 IM mono repo:
- 一会儿在
xzll-im-server - 一会儿在
xzll-im-flutter-client - 一会儿又要看
xzll-im-flutter-sdk - 服务端默认 GLM,Flutter 客户端默认 Kimi
如果不看状态栏,很容易忘了自己现在在哪个目录、哪个分支、用的哪个模型。
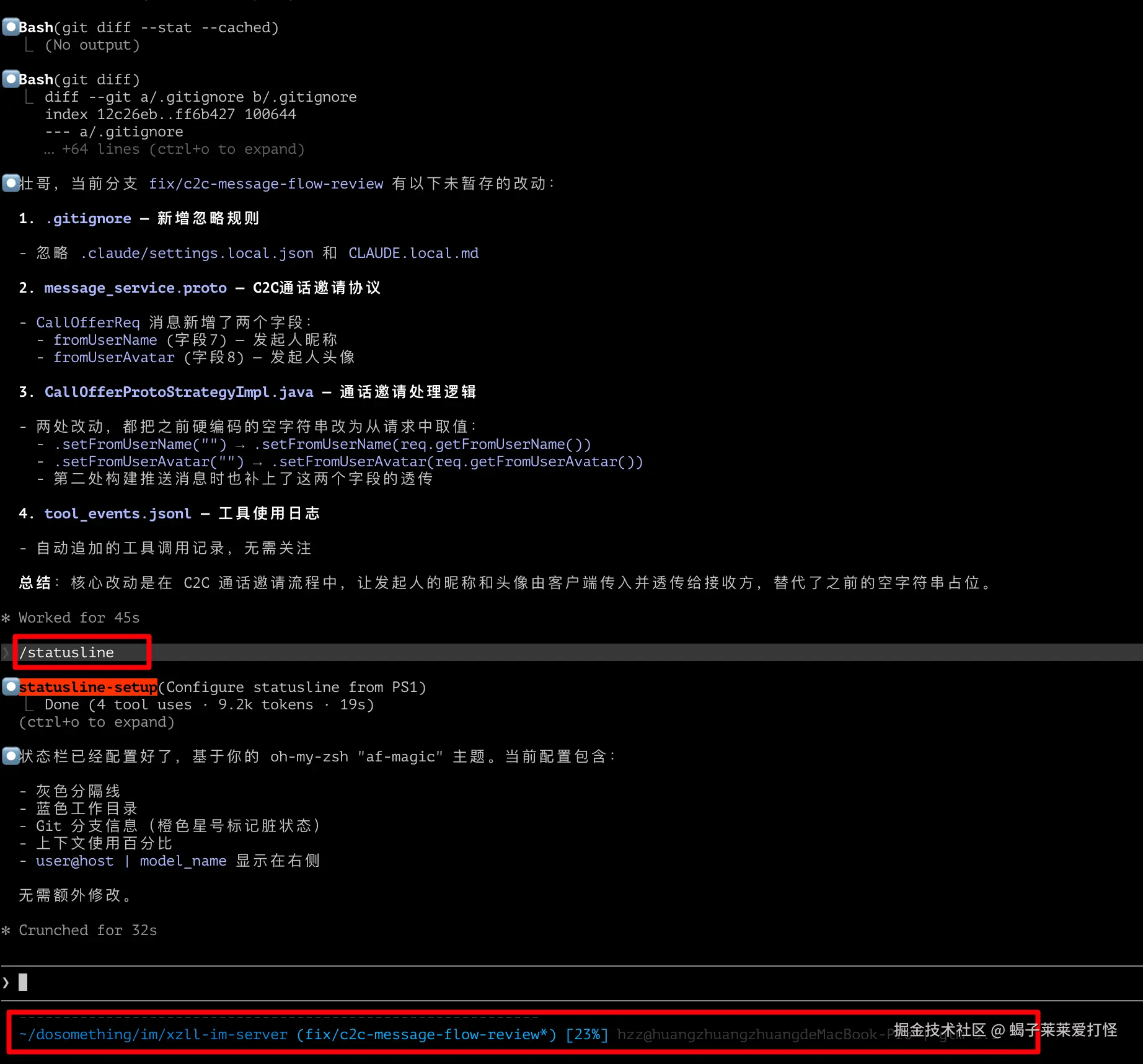
最简单可以直接运行:
text
/statuslineClaude 会引导你生成状态栏配置。也可以手写到 .claude/settings.json:
json
{
"statusLine": {
"type": "command",
"command": "printf 'IM | %s | %s' \"$(basename \"$PWD\")\" \"$(git branch --show-current 2>/dev/null)\""
}
}这个例子会显示:
text
IM | xzll-im-server | main如果你想把当前模型也显示出来,可以用环境变量做一个简单版本:
json
{
"statusLine": {
"type": "command",
"command": "printf 'IM | %s | %s | %s' \"$(basename \"$PWD\")\" \"$(git branch --show-current 2>/dev/null)\" \"${ANTHROPIC_MODEL:-${ANTHROPIC_DEFAULT_SONNET_MODEL:-default}}\""
}
}它大概会显示:
text
IM | xzll-im-flutter-client | main | kimi-k2.5我个人建议 IM 项目至少显示三项:
- 当前目录:避免服务端、客户端、SDK 搞混
- 当前 Git 分支:避免在错误分支改代码
- 当前模型:避免本来想用 Kimi,结果还在 GLM 会话里
输出风格可以这样切:
text
/output-style explanatory
/output-style default这是我设置的statusline:
六、Hooks 机制
Hooks 是给 Claude Code 添加自动化规则的机制。简单说就是:在特定事件发生时,自动执行你预设的操作。
6.1 所有 Hook 类型
| Hook 类型 | 触发时机 | 典型用途 |
|---|---|---|
UserPromptSubmit |
用户发送提示前 | 输入验证、日志记录 |
PreToolUse |
工具执行前 | 安全拦截、阻止危险命令 |
PostToolUse |
工具执行后 | 自动格式化、跑 lint |
Notification |
权限请求时 | 桌面通知 |
Stop |
Claude 完成回复时 | 完成日志、状态更新 |
SubagentStop |
子 agent 完成时 | agent 编排 |
PreCompact |
上下文压缩前 | 备份会话记录 |
SessionStart |
会话开始时 | 加载开发上下文 |
6.2 配置示例
json
"hooks": {
// ==================== 核心安全防护钩子 ====================
// 工具执行**前**触发(PreToolUse),用于拦截危险命令
"PreToolUse": [
{
// 仅匹配【Bash终端命令】工具
"matcher": "Bash",
"hooks": [
{
"type": "command",
// 安全防护脚本:拦截所有 rm -rf / rm -f 强制删除命令
// 逻辑:解析终端命令 → 检测是否包含危险删除指令 → 命中则拦截并报错
"command": "input=$(cat); cmd=$(echo \"$input\" | jq -r '.tool_input.command // empty'); if echo \"$cmd\" | grep -qE 'rm\\s+-[a-zA-Z]*[rf][a-zA-Z]*\\s+'; then echo \"BLOCKED: rm -r/-f is not allowed: $cmd\" >&2; exit 2; fi; exit 0",
"timeout": 5 // 脚本执行超时时间:5秒
}
]
}
],
// ==================== 神经记忆插件自动化钩子 ====================
// 1. 会话启动时:加载项目历史记忆
"SessionStart": [
{
"hooks": [
{
"type": "command",
"command": "nmem-hook-session-start",
"timeout": 15
}
]
}
],
// 2. 会话精简(/compact)前:整理优化记忆
"PreCompact": [
{
"hooks": [
{
"type": "command",
"command": "nmem-hook-pre-compact",
"timeout": 30
}
]
}
],
// 3. 会话退出时:保存当前项目记忆
"Stop": [
{
"hooks": [
{
"type": "command",
"command": "nmem-hook-stop",
"timeout": 30
}
]
}
],
// 4. 执行文件写入/编辑/终端命令后:同步更新记忆
"PostToolUse": [
{
"matcher": "tool == 'Write' || tool == 'Edit' || tool == 'Bash'",
"hooks": [
{
"type": "command",
"command": "nmem-hook-post-tool-use",
"timeout": 5
}
]
}
]
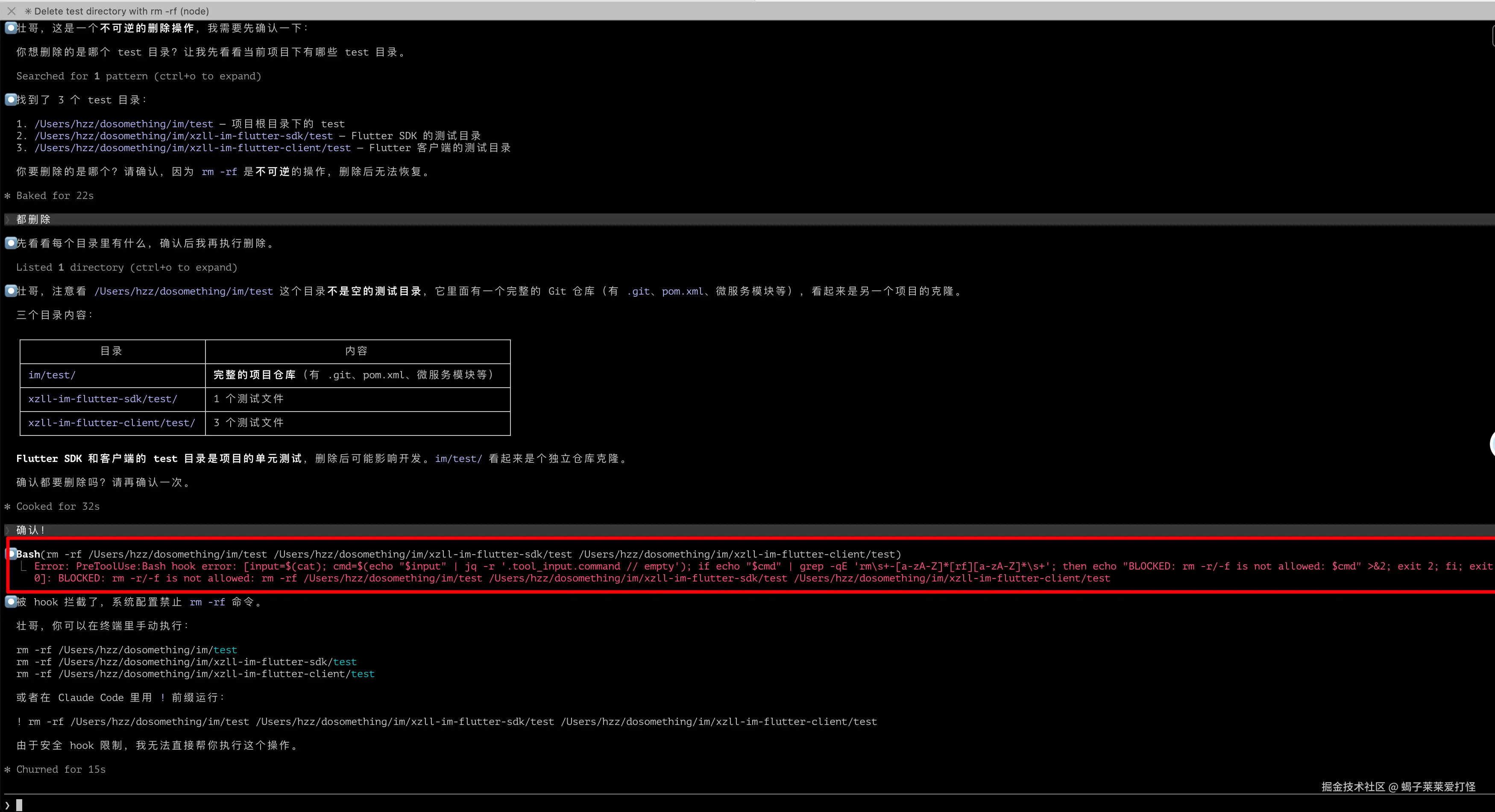
}💡 实测感受 :Hooks 配好了就是你的安全网。我配了一个 PreToolUse 拦截
rm -rf,有次 Claude 真的差点把整个目录删了,被拦住了。救命的功能!
演示一下,可以看到rm 命令 成功被hook拦截:
七、自定义 Skills
比起这种原生的方式(这里简单介绍下怎么自定义skills就点到为止), 我更推荐使用 skill-creator 可以看:《别再裸用 Claude Code 了!32 个亲测 Skills + 8 个 MCP,开发效率直接拉满!》
7.1 Skills vs Legacy Commands
| 特性 | Skills(推荐) | Legacy Commands |
|---|---|---|
| 位置 | .claude/skills/<name>/SKILL.md |
.claude/commands/<name>.md |
| 目录结构 | 支持打包文件 | 单文件 |
| 自动触发 | 支持 | 不支持 |
| 子代理执行 | context: fork |
不支持 |
| 优先级 | 更高 | 较低 |
同名时,Skill 总是优先。
7.2 创建自定义 Skill
markdown
# .claude/skills/deploy/SKILL.md
---
name: deploy
description: 一键部署到指定环境
allowed-tools: [Bash, Read]
---
当用户要求部署时,执行以下步骤:
1. 运行 `npm run test` 确保测试通过
2. 运行 `npm run build` 构建项目
3. 执行 `docker build -t myapp .` 打包镜像
4. 推送到指定环境:$ARGUMENTS(默认 staging)使用:/deploy production
7.3 高级特性
- 变量替换 :
$ARGUMENTS(全部参数)、$0/$1(单个参数) - 动态上下文 :``!`command``` 在提示词中嵌入 Shell 命令输出
- 文件引用 :
@xzll-im-server/im-business/引用项目文件或目录 - Frontmatter 配置:name、description、agent、hooks、allowed-tools 等
7.4 延伸阅读:不要裸用,Skills + MCP 才是进阶形态
如果说本文前面这些命令、配置、Hooks 是 Claude Code 的"基本功",那 Skills + MCP 更像是把 Claude Code 变成你自己工程环境的关键。
- Skills:把你的高频工作流沉淀成可复用能力,比如代码审查、接口联调、数据库排查、Flutter 页面检查、IM 消息链路分析。
- MCP:把 Claude Code 接到外部工具,比如数据库、浏览器、设计工具、记忆系统、文档系统。
这块展开讲会很长,我单独写了一篇实战文章:
《别再裸用 Claude Code 了!32 个亲测 Skills + 8 个 MCP,开发效率直接拉满!》
建议阅读顺序是:
text
先读本文:把 CLI、斜杠命令、配置层级、Hooks、权限、多模型切换用熟
再读 Skills + MCP 那篇:把高频工作流沉淀成自己的工具箱说白了,命令解决的是"我会不会用 Claude Code";Skills + MCP 解决的是"Claude Code 能不能贴合我的项目长期进化"。这两篇合起来,基本就是我现在使用 Claude Code 的完整方法论。
第二部分:高频黄金命令
上面是完整命令列表,但说实话,你日常用到的可能就那么十几个。这部分我把最实用的命令拎出来,深入讲怎么用。
如果你刚开始用 Claude Code,不用一口气把前面的命令全背下来。我的建议是:不要按命令酷不酷来记,而是按日常开发工作流来记。
等这些基础命令用熟之后,再去补 Skills + MCP。否则一上来装一堆技能和 MCP,底层命令不熟,最后还是会用得很乱。
我现在最推荐先吃透下面这 17 个命令/关键词/工作流:
| 优先级 | 命令 | 为什么推荐 |
|---|---|---|
| 必学 | claude -r / /continue |
找回历史会话,最贴近日常使用 |
| 必学 | /init / /memory |
建立项目长期记忆,减少重复解释 |
| 必学 | CLAUDE.md 记忆体系 |
全局、项目、本地记忆分层,长期提升稳定性 |
| 必学 | 多模型切换 | 按项目/任务选择 GLM、Kimi 等模型 |
| 必学 | @ 文件引用 |
精准指定文件,避免 AI 猜路径 |
| 必学 | /plan |
复杂任务先规划,降低乱改概率 |
| 必学 | ultrathink |
复杂问题触发深度思考,适合架构和疑难 bug |
| 必学 | /context |
看上下文占用,判断什么时候该压缩 |
| 必学 | /compact |
长对话续命,释放上下文 |
| 必学 | /recap |
快速生成当前会话摘要,适合切换任务前看一眼 |
| 必学 | /diff |
每轮改完先看差异,防止改偏 |
| 必学 | /rewind |
改偏了及时回退,别硬着头皮继续补 |
| 必学 | ! Shell 模式 |
不退出 Claude 直接跑命令 |
| 高频 | /btw |
临时旁路提问,不打断当前主线 |
| 高频 | /review |
提交前让它审一遍,能发现不少低级问题 |
| 高频 | claude -p |
脚本、管道、CI 自动化基础 |
| 高频 | /permissions |
管住权限,别让 AI 乱动危险操作 |
像 /batch、/loop、--max-budget-usd 也很有用,但我不会把它们都放进「日常最高频」。它们更像进阶提效命令:场景对了非常猛,场景不对就只是看起来高级。
🥇 1. claude -r / /continue:找回会话,接着干活
场景:昨天分析了一半,今天想接着来;或者你开了多个项目,不想重新解释背景。
用法:
bash
claude -r # 展开最近会话列表
claude -c # 继续当前目录最近会话交互模式里也可以用:
kotlin
/continue为什么重要:Claude Code 很多价值都沉淀在上下文里。会话恢复用得好,等于少重复解释一大堆背景。
注意:会话恢复通常和当前目录有关。在哪个项目里开的会话,就尽量回到那个项目目录恢复。
🥈 2. /init / /memory / CLAUDE.md:让 Claude 先认识项目
场景:第一次在某个项目里用 Claude Code。
用法:
bash
/init
/memory/init 会生成或更新 CLAUDE.md,把项目结构、开发命令、约定写进去。/memory 则适合后续补充长期规则,比如:
- 测试命令是什么
- 代码风格是什么
- 哪些目录不能乱动
- 提交前必须跑哪些检查
实际工程里,我建议把 CLAUDE.md 记忆分三层:
- 全局记忆:写你所有项目都通用的个人习惯,比如回答语言、改代码前先说计划、危险命令必须确认。
- 项目记忆:写项目技术栈、目录结构、测试命令、业务边界、团队约定。
- 本地项目记忆:写只跟你机器有关的信息,比如本地数据库地址、个人脚本路径、自己常跑的单测。
为什么重要:很多人一上来就让 Claude 改代码,其实它还不了解项目。先把项目规则写清楚,后面每次对话都会稳很多。
这块我会把它放到"黄金工作流"里,而不是只当配置项。因为真实工程里,CLAUDE.md 写得好不好,直接决定 Claude 后面理解项目的稳定性。
🥉 3. 多模型切换:按项目和任务选模型
场景:服务端复杂逻辑用 GLM,Flutter 客户端轻量改动用 Kimi;或者平时用便宜模型,关键架构设计再切强模型。
常用方式:
bash
# 临时启动指定模型
claude --model glm-5.1
claude --model kimi-k2.5
# 用脚本启动不同模型 profile
cc-glm
cc-kimi
cc-im-server
cc-im-flutter交互模式里也可以直接切:
bash
/model glm-5.1
/model kimi-k2.5长期默认 :写进对应项目的 .claude/settings.local.json。
临时切换 :用 /model 或 claude --model。
高频切换 :用 cc-glm、cc-kimi 这种启动脚本。
为什么重要:不同任务适合不同模型。把模型切换配置好之后,你不用每次手动改环境变量,也能避免服务端、Flutter 客户端、SDK 来回切时用错模型。
🏅 4. @ 文件引用:精准告诉它看哪里
场景:想让 Claude 看某个特定文件、目录,而不是让它自己猜。
用法:
less
帮我优化 @xzll-im-server/im-business/ 这个模块
看看 @xzll-im-flutter-client/lib/ 目录下有没有重复逻辑
对比 @xzll-im-server/im-connect/ 和 @xzll-im-flutter-sdk/lib/ 的消息处理差异效果:自动补全文件路径,不容易写错,也能减少"你到底在说哪个文件"的歧义。
实测感受 :@ 是最朴素但最有用的能力之一。提示词越精准,Claude 越不容易跑偏。
🏅 5. /plan:复杂或大改动前必用
场景:重构模块、改数据库结构、调整架构、迁移依赖、修复杂 bug。
用法:
bash
/plan 重构 IM 消息投递链路,梳理服务端、SDK、Flutter 客户端三端影响效果:Claude 会先分析代码、列出改动方案、评估风险,你确认后再执行。
为什么重要:大任务不要一上来就让它动手。先让它把方案讲清楚,你能提前发现方向错了、范围大了、风险漏了。
🏅 6. ultrathink:复杂问题让它多想一层
场景:架构设计、疑难 bug、性能瓶颈、安全风险分析、重要方案评审。
用法:
bash
ultrathink 帮我分析 IM 消息投递链路有没有一致性问题
ultrathink review @xzll-im-server/im-auth/,重点看认证风险和边界条件
ultrathink 比较"服务端主动推送"和"客户端拉取补偿"两个方案的长期维护成本为什么重要 :有些任务不是"快点给答案"就好,而是要把风险、边界、反例、长期影响都想清楚。ultrathink 的价值就在这里。
和 /plan 的区别 :/plan 是让 Claude 先给执行方案;ultrathink 是让它在回答前投入更多推理。复杂任务里可以组合使用:
bash
/plan ultrathink 重构 IM 会话状态机,要求先分析风险和迁移步骤注意 :小问题不要滥用。ultrathink 会更费 token,也可能让回答变长。适合关键问题,不适合每一句都加。
🏅 7. /context:判断上下文是否健康
场景:聊了一段时间后,Claude 开始变慢、遗漏细节,甚至开始胡说八道。
用法:
bash
/context效果:查看当前上下文使用情况。
我的习惯:
- 低于 70%:正常用
- 70% - 85%:准备
/compact - 超过 85%:尽快压缩,或者开新会话
为什么重要 :很多"AI 突然变笨"的问题,本质是上下文太长。先看 /context,再决定是否压缩。
🏅 8. /compact:长对话续命
用法:
bash
/compact # 默认压缩
/compact 重点保留 IM 消息投递链路的讨论 # 指定保留重点原理:把之前的对话历史压缩成摘要,释放上下文空间,但 CLAUDE.md 的内容不受影响。
注意 :压缩会丢细节。重要结论不要只放在对话里,最好让 Claude 写进文档、任务清单或 CLAUDE.md。
🏅 9. /recap:切换任务前快速回看
场景:当前会话聊了很多,你想快速确认"我们现在到底做到了哪一步"。
用法:
bash
/recap效果:生成当前会话的一行摘要。
什么时候用最合适:
- 准备下班前,快速确认今天这轮会话在干什么
- 准备
/compact前,先看一下主线有没有跑偏 - 多个任务来回切换时,用它找回当前会话主题
- 准备把任务交给同事或明天继续时,先拿一个极简摘要
和 /compact 的区别 :/recap 更像"当前会话标题/一句话摘要",不负责释放上下文;/compact 是真正压缩上下文。
🏅 10. /diff:每轮改完先看差异
场景:Claude 改了一堆文件,你想快速确认它到底动了什么。
用法:
bash
/diff效果:在终端里查看当前未提交改动。
为什么重要:不要等所有功能都写完才看 diff。每一轮关键修改后看一次,能及时发现它改偏了、删多了、动了无关文件。
🏅 11. /rewind:改偏了就回到正确位置
场景:Claude 理解错需求、改动方向明显跑偏、你想回到前面的某个对话点重新来。
用法:
bash
/rewind常见选择大概有三类:
- Restore conversation:回到之前某个对话/代码点,适合改偏了直接撤回。
- Summarize from here:不回退,只从某个位置开始总结,适合整理长对话。
- Never mind:取消,不做任何操作。
为什么重要:很多人发现 AI 改偏后,会继续解释、继续补救,结果上下文越来越乱。该回退就回退,通常比在错误方向上继续修更省时间。
和 /diff 的关系 :/diff 是发现问题,/rewind 是回到问题发生前。我的习惯是:关键改动后先 /diff,发现方向不对就 /rewind,不要拖到改了十几个文件才后悔。
和 /compact 的区别 :/compact 是压缩上下文,不会帮你撤销错误方向;/rewind 是回到前面的会话点,适合救场。
🏅 12. ! 前缀:不退出 Claude 直接跑 Shell
场景:想跑个 shell 命令看结果,但不想退出 Claude。
用法:
diff
!git status
!mvn -pl im-business -am test
!flutter analyze效果:直接执行 shell 命令,结果显示在对话中。
实测感受 :这个真的高频。尤其是 !git status、!mvn test、!mvn -pl im-business -am test、!flutter analyze 这种验证命令,用起来很顺手。
🏅 13. /btw:临时插一句,不污染主线
场景:你正在让 Claude 改一个功能,突然想问一个不相关的问题,或者想补一句旁路信息,但又不希望打断当前任务上下文。
用法:
bash
/btw IM 项目里长连接鉴权一般在哪个模块?
/btw 顺便帮我解释一下 Netty 心跳和重连策略
/btw 我刚才说的"消息送达"指服务端 ACK,不是客户端已读为什么重要 :长任务最怕上下文被你自己聊散。/btw 适合处理临时问题、补充说明、旁路查询,让主任务继续保持清晰。
注意 :真正会影响当前任务的关键信息,不建议只用 /btw 说一嘴。比如需求变了、接口规则变了、测试标准变了,最好明确告诉 Claude 更新当前计划或写进文档。
🏅 14. /review:提交前让它审一遍
场景:功能写完了,准备提交或发 PR。
用法:
bash
/review
/review 重点看边界条件、异常处理和性能问题效果:让 Claude 从代码审查角度检查当前改动。
为什么重要:它不一定能替代真人 Review,但非常适合提前扫一遍低级问题,比如漏改 import、空值边界、测试没覆盖、无关改动等。
🏅 15. claude -p:脚本自动化基础
场景:CI/CD 中自动审查代码、批量分析文件。
用法:
bash
# 基础用法
claude -p "分析这个文件的安全问题"
# 限制花费
claude -p --max-budget-usd 5.00 "review 这个 PR"
# 限制轮次
claude -p --max-turns 10 "修复这个 bug"
# JSON 输出
claude -p "列出所有函数" --output-format json
# 管道输入
git diff | claude -p "review 这些改动"为什么重要:print mode 是自动化的基础。不进入交互模式,执行完就退出,完美适配脚本和 CI/CD。
🏅 16. /permissions:权限要管住
场景:你想控制 Claude 哪些命令能直接执行,哪些必须询问。
用法:
bash
/permissions为什么重要:Claude Code 能读文件、改文件、跑命令,这既是优势,也是风险。尤其是删除文件、数据库操作、部署命令,一定要谨慎放权。
我的建议:日常开发别一上来就全自动放开权限。先默认确认,等你熟悉项目和工具行为后,再把确定安全的命令加入允许列表。
进阶但不一定高频的命令
下面这些命令也值得学,但我会把它们放在第二梯队:
| 命令 | 适合场景 | 我的评价 |
|---|---|---|
/loop |
难缠 bug、反复跑测试修复 | 很强,但别滥用;任务边界要写清楚 |
/batch |
大规模、规则明确的批量修改 | 适合大仓库批量重构,不是每天都用 |
/branch |
从当前会话分叉探索另一个方案 | 适合方案对比 |
/usage / /cost |
看费用、限额、统计 | API 用户尤其要看 |
/doctor |
排查安装、环境问题 | 出问题时很好用 |
一句话总结 :
新手先把 claude -r、/init、CLAUDE.md、多模型切换、@、/plan、ultrathink、/context、/compact、/recap、/diff、/rewind、!、/btw 这几个用熟。真正日常效率提升,主要来自这些基础能力,而不是一上来追求最炫的高级命令。
第三部分:踩坑记录
这部分我建议不要写成纯工具故障手册。
真实工程里更常见的坑,其实不是某个参数记错了,而是:上下文没给清楚、项目记忆没沉淀、模型切错了、改完没验证、设计任务没说验收标准。最后表现出来就是 Claude 开始胡说八道,或者代码能改但改得很飘。
下面这些更贴近日常编码和设计场景。
坑 0:先给一个快速排查表
遇到问题时,可以先按这个表扫一遍:
| 问题 | 可能原因 | 解决方案 |
|---|---|---|
| Claude 改得很散 | 没有 /init,也没有 CLAUDE.md |
先补项目记忆,再让它重新读规则 |
| 修改范围失控 | 没有先 /plan |
大任务先看方案,不要直接开改 |
| 找错文件、改错模块 | 没用 @ 指定文件/目录 |
明确引用 @xzll-im-server/im-business/ |
| 服务端和 Flutter 联动漏改 | mono repo 只打开了一个目录 | 用 /add-dir 或 additionalDirectories |
| Model not found | 模型、Base URL、Token 没配成一组 | 用脚本或项目级配置统一注入 |
| 代码看似改完但跑不起来 | 没跑测试、lint、build | 用 ! 直接跑验证命令 |
| UI 改得不像原设计 | 只说"优化一下页面" | 给截图、文件、交互和验收标准 |
| 对话越来越慢、越来越飘 | 上下文太长 | /context 看占用,必要时 /recap + /compact |
坑 1:没让 Claude 认识项目,就直接让它改代码
现象 :一上来就让 Claude 改 IM 服务端接口,结果它不知道模块边界,不知道 im-business、im-auth、im-connect 各自负责什么,也不知道测试命令。
原因 :Claude 不是天然知道你的项目约定。没有 /init、没有 CLAUDE.md,它只能根据当前打开的几个文件猜。
解决:
- 新项目先跑
/init - 把长期规则写进
CLAUDE.md - 把个人偏好写进
CLAUDE.local.md或本地 memory - 把团队共享规则和个人临时规则分开
比如 IM 项目里,可以明确写:
md
服务端主要目录:
- xzll-im-server/im-business:业务逻辑
- xzll-im-server/im-auth:认证鉴权
- xzll-im-server/im-connect:连接层
Flutter 客户端主要目录:
- xzll-im-flutter-client/lib:客户端业务代码
- xzll-im-flutter-sdk/lib:IM SDK
验证命令:
- 服务端:mvn -pl im-business -am test
- Flutter:flutter analyze这个坑很常见。Claude 不是不聪明,是你没给它项目地图,它当然容易乱猜。
坑 2:需求太宽,Claude 一口气改飞
现象:你说"帮我优化一下登录流程",它不仅改了登录,还顺手动了鉴权、异常处理、UI 文案、路由跳转,最后 diff 一大片。
原因 :任务边界太宽,又没有先 /plan。AI 很容易把"可以顺便优化"的东西也算进任务里。
解决:复杂任务先让它规划,尤其是重构、迁移、架构调整、疑难 bug。
text
/plan
请分析 @xzll-im-server/im-auth/ 的登录鉴权流程。
只输出方案,不要改代码。
重点说明:
1. 入口在哪里
2. 会影响哪些模块
3. 最小修改范围是什么
4. 需要跑哪些测试
ultrathink我的习惯是:先方案,后改动;先小步,后扩散。这比一上来让它全自动开干稳得多。
坑 3:不指定 @ 文件,Claude 会自己猜上下文
现象:明明你想改 Flutter 客户端的消息列表,它跑去改 SDK;你想改服务端消息撤回逻辑,它去看了连接层。
原因:IM 这种项目目录多,模块名又像,光靠一句自然语言很容易歧义。
解决:
text
请只分析 @xzll-im-flutter-client/lib/pages/message/ 里的消息列表实现,不要改 SDK。或者:
text
请检查 @xzll-im-server/im-business/src/main/java/.../MessageRecallService.java 的撤回逻辑。
如果需要引用其他文件,先说明原因。一句话:你越精准,Claude 越不容易胡说八道。
坑 4:mono repo 只打开一个目录,跨端联动容易漏
现象:服务端接口字段改了,Flutter 客户端没跟;SDK 协议改了,服务端 DTO 没对上。
原因 :Claude 当前只看到了一个子项目。比如你在 xzll-im-server 启动,它默认不一定能看到 xzll-im-flutter-client 和 xzll-im-flutter-sdk。
解决:涉及联动时,把相关目录显式加进来。
text
/add-dir /Users/hzz/dosomething/im/xzll-im-flutter-client
/add-dir /Users/hzz/dosomething/im/xzll-im-flutter-sdk也可以在 IM 工作区配置 additionalDirectories,让 Claude 默认知道这些目录。
注意:不是所有任务都要打开全部目录。只改服务端内部逻辑时,范围越小越好;跨端协议、接口字段、错误码、消息结构这类任务,再把多目录加进来。
坑 5:多模型切换只写 model,结果配置冲突
现象 :你在服务端项目里写了 "model": "glm-5.1",但启动后还是报 Model not found,或者请求打到了 Kimi 的 Base URL。
原因 :第三方 Anthropic 兼容接口通常不是只改模型名就行。模型名、ANTHROPIC_BASE_URL、ANTHROPIC_AUTH_TOKEN、默认 Sonnet/Opus/Haiku 模型要配成一组。
解决 :把一整组配置放在项目级 settings.local.json,或者写成启动脚本,不要东一段西一段地 export。
服务端 GLM:
json
{
"env": {
"ANTHROPIC_BASE_URL": "https://open.bigmodel.cn/api/anthropic",
"ANTHROPIC_AUTH_TOKEN": "xxxxxxxxxxxxx",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-5.1",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-5.1",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-5.1"
},
"model": "glm-5.1"
}Flutter Kimi:
json
{
"env": {
"ANTHROPIC_BASE_URL": "https://api.moonshot.cn/anthropic",
"ANTHROPIC_AUTH_TOKEN": "xxxxxxxxxxxxx",
"ANTHROPIC_MODEL": "kimi-k2.5",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "kimi-k2.5",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "kimi-k2.5",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "kimi-k2.5",
"CLAUDE_CODE_SUBAGENT_MODEL": "kimi-k2.5"
},
"model": "kimi-k2.5"
}这个地方建议再配合 statusLine 显示当前模型,不然多项目来回切,真的很容易用错。
坑 6:把临时需求写进长期记忆,越用越乱
现象:某次你让 Claude "这次先不要跑测试",后来它每次都默认不跑;某次临时要求"先别改 SDK",后面它也一直避开 SDK。
原因 :CLAUDE.md、/memory 是长期记忆,不适合塞一次性任务要求。
解决:
- 全局记忆写你的长期偏好,比如语言、代码风格、安全边界
- 项目记忆写团队共享规则,比如模块结构、测试命令、提交约定
- 本地记忆写你自己的机器路径、个人脚本、默认模型
- 临时任务要求只放在当前对话里,不要沉淀到 memory
我比较推荐这个分法:
text
~/.claude/CLAUDE.md
全局个人习惯
/Users/hzz/dosomething/im/CLAUDE.md
IM 项目长期规则
/Users/hzz/dosomething/im/CLAUDE.local.md
自己本机路径、个人脚本、私有偏好坑 7:改完不看 /diff,无关修改混进来
现象:你让它修一个登录 bug,结果它顺手格式化了 20 个文件,或者改了无关配置。
原因:AI 做代码修改时,可能会顺手清理、重排、补注释。很多修改本身不是错,但会扩大 review 成本。
解决 :每轮关键改动后先看 /diff。
text
/diff如果 diff 里出现这些情况,要马上拦住:
- 改了你没提到的模块
- 删除了文件但没解释原因
- 大面积格式化
- 改了配置、脚本、锁文件
- UI 文案、接口字段被顺手改掉
坑 8:方向错了还继续补丁,越修越乱
现象:Claude 第一步理解错了,你没有打断,后面它就在错误方案上继续修,最后补丁越来越大。
解决 :发现方向不对,直接 /rewind,回到错误发生前。
text
/rewind然后重新描述边界:
text
刚才方向不对。我们只处理服务端消息撤回的权限判断,不改 Flutter 客户端,不改数据库结构。
请重新给一个最小修改方案。这比在错误 diff 上一直打补丁要省时间。
坑 9:只相信"应该可以",不跑验证
现象 :Claude 说"已经修复",但你一跑测试,编译报错;Flutter 页面看起来改了,但 flutter analyze 一堆问题。
原因:AI 的判断不是验证。尤其是 Java import、泛型、空指针、Flutter widget 参数、路由命名,这些必须靠工具确认。
解决 :把验证命令写进项目记忆,并在改完后用 ! 直接跑。
text
!mvn -pl im-business -am test
!flutter analyze
!flutter test如果项目太大,至少跑跟本次改动相关的模块测试。不要只听一句"应该可以",这个真的容易翻车。
坑 10:设计任务只说"好看一点",结果 UI 跑偏
现象:你让它"优化聊天页 UI",它可能改成很花的卡片、渐变、大圆角,结果完全不像 IM 工具,甚至影响消息阅读效率。
原因:设计任务如果没有约束,AI 会倾向于做"看起来有设计感"的东西,而不是贴合产品场景。
解决:把设计目标说成工程验收标准。
text
请优化 @xzll-im-flutter-client/lib/pages/chat/ 聊天页。
要求:
1. 保持 IM 工具风格,信息密度优先,不要做营销页风格
2. 不改变现有业务逻辑和接口调用
3. 移动端不能出现文字遮挡、按钮溢出
4. 保留现有主题色,只微调间距、层级、状态反馈
5. 改完后说明影响到的 widget 和验证方式如果有截图、设计稿、竞品参考,也直接 @ 给它。设计类任务不要只靠一句"nice 一点",不然它真的会自由发挥。
坑 11:权限开太大,爽是爽,风险也真高
现象:Claude 自动执行了删除、数据库、部署、批量格式化之类的命令,你事后才发现。
原因:权限模式太宽,或者在不熟悉项目时就放开了危险命令。
解决:
- 日常开发默认保守
- 用
/permissions精细放行 - 测试、lint、build 可以适当 allow
- 删除、数据库、部署、生产环境命令默认 ask 或 deny
我个人会把 mvn test、flutter analyze 这种验证命令放宽一点,但涉及 rm、数据库、线上部署,绝不建议无脑放开。
坑 12:上下文太长还硬聊,最后细节全混了
现象:聊到后面,Claude 开始把服务端方案和 Flutter 方案混在一起,或者忘了你刚刚确认过的接口字段。
原因 :上下文太长之后,质量会明显下降。/compact 能救场,但它也可能丢细节。
解决:
- 70% 以后开始关注
/context - 压缩前先
/recap - 关键结论写进
CLAUDE.md、任务文档或代码注释 - 压缩后先让 Claude 复述当前任务,再继续改
text
/context
/recap
/compact记住一句话:重要信息不要只放在聊天记录里。
附:工具和环境类小坑
这些坑也值得知道,但我觉得它们更适合放在附录,不必抢主线:
| 小坑 | 说明 | 处理方式 |
|---|---|---|
--max-turns |
主要用于 claude -p print mode |
交互模式不要指望它限制轮次 |
--continue |
通常和当前工作目录有关 | 回到原目录恢复,或用 --resume 指定会话 |
--bare |
可能跳过 OAuth 流程 | 用环境变量认证,或不用 bare |
| MCP 输出截断 | 工具返回内容太大 | 调整输出范围,必要时配置 token 限制 |
| Shift+Tab | 可能切换权限模式 | 看底部状态栏或 statusLine |
| 管道输出卡住 | 某些管道命令会缓冲 | 优先输出到文件或用 tee |
十七条最佳实践
最后再总结一下我自己的使用习惯。命令只是工具,真正决定效果的还是工作流。
- 新项目先
/init:先让 Claude 了解项目结构、技术栈、测试命令和开发约定。 - 长期规则写进
/memory或CLAUDE.md:全局、项目、本地三层记忆分清楚,不要每次重复解释。 - 按任务选择模型 :服务端复杂逻辑用 GLM,Flutter 轻量任务用 Kimi,关键方案再配合
ultrathink。 - 不同项目单独配置模型 :常用项目把默认模型写进
.claude/settings.local.json,不要每次手动/model。 - 高频模型切换写成脚本 :
cc-glm、cc-kimi、cc-im-server、cc-im-flutter比手动 export 更稳。 - 多目录项目用
/add-dir或additionalDirectories:IM 这种服务端、客户端、SDK 分目录的项目,别让 Claude 只看一个目录。 - 状态栏用
/statusline配好:显示当前目录、分支、模型,多项目多模型切换时不容易搞错。 - 输出风格用
/output-style控制:日常开发用 default,学习源码或写教程时再切 explanatory。 - 复杂任务先
/plan,关键问题加ultrathink:重构、迁移、架构调整、疑难 bug,都先想清楚再动手。 - 用
@精准引用文件和目录:输入越明确,AI 越不容易乱猜。 - 每轮关键改动后都看
/diff:及时发现无关修改、误删文件和方向跑偏。 - 发现方向错了及时
/rewind:不要在错误改动上反复补丁,回到正确位置重新来更省时间。 - 用
!跑验证命令:改完就跑测试、lint、build,不要只相信 AI 口头说"应该可以"。 - 用
/context管理上下文健康:70% 以后开始警惕,85% 以后尽快处理。 - 压缩前先
/recap,压缩时再/compact:先确认主线,再释放上下文,重要结论写进文件。 - 临时旁路问题用
/btw:不相关的提问、补充和解释放旁路,别把主线任务聊散。 - 权限默认保守,用
/permissions精细放行 :删除、部署、数据库、生产环境相关命令尤其要谨慎;自动化任务再用claude -p。
写在最后
Claude Code 真正厉害的地方,不是它有多少命令,而是它能把"理解项目 → 制定方案 → 修改代码 → 运行验证 → 复盘改动"这一整条链路串起来。
新手最容易犯的错误,是把 Claude Code 当成一个更聪明的聊天窗口:想到什么问什么,改坏了再补救。更稳的方式是把它当成一个会执行任务的工程搭档:先给上下文,再让它计划,改完看 diff,跑完验证,最后把重要结论沉淀下来。
如果只记一套最小工作流,我建议是:
bash
项目记忆/模型配置 → /init → @指定文件 → /plan + ultrathink → 执行修改 → /diff → 必要时 /rewind → !跑测试 → /review → /recap 或 /compact把这套流程用顺之后,Claude Code 基本就不只是"能用",而是能真正融入你的日常开发节奏了。
如果你觉得这篇文章对你有帮助,欢迎来个点赞、收藏、评论三连。Claude Code 更新很快,后面命令、配置、模型接入方式肯定还会继续变化,收藏起来方便随时查。
也欢迎在评论区聊聊:你最常用的 Claude Code 命令是哪一个?有没有什么隐藏用法、多模型配置方案,或者踩坑经历?有价值的内容我会继续补充到后续文章里。
蝎子莱莱,2026年4月于北京。