引言
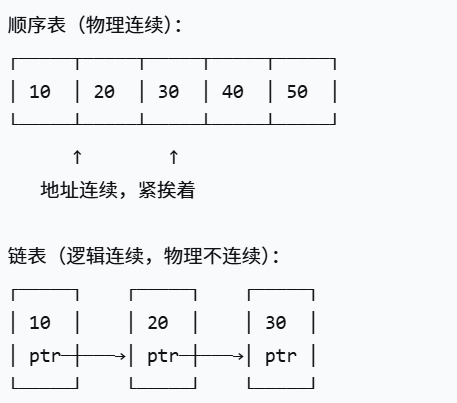
在数据结构的学习中,我们首先学习了顺序表(数组)。顺序表虽然访问速度快,但插入和删除操作需要移动大量元素,效率较低。此外,顺序表的大小固定,扩容需要重新分配内存并拷贝数据。
链表 解决了这些问题。链表中的元素在内存中不连续存储,通过指针连接形成逻辑上的线性结构。
今天,我们将从零开始实现一个完整的带头结点的单向链表,涵盖初始化、插入、删除、遍历等核心操作。
第一部分:链表的基本概念
一、什么是链表?
链表是一种物理存储单元上非连续、非顺序的线性结构。数据元素之间的逻辑关系通过指针链接实现。
链表的分类:
| 分类标准 | 类型 | 说明 |
|---|---|---|
| 方向 | 单向链表 | 每个节点只有一个指向后继的指针 |
| 双向链表 | 每个节点有前驱和后继两个指针 | |
| 是否循环 | 非循环链表 | 尾节点指针指向NULL |
| 循环链表 | 尾节点指针指向头节点 | |
| 是否有头结点 | 带头结点 | 头结点不存储数据,简化操作 |
| 不带头结点 | 第一个节点就存储数据 |
本文实现的是带头结点的单向非循环链表。
二、带头结点的优势
| 特点 | 不带头结点 | 带头结点 |
|---|---|---|
| 空表判断 | head == NULL |
head->next == NULL |
| 头插操作 | 需要修改头指针 | 操作统一,不修改头指针 |
| 删除头节点 | 需要修改头指针 | 操作统一 |
| 代码复杂度 | 较高 | 较低 |
第二部分:数据结构设计
一、节点结构体
cpp
typedef int ElemType; // 链表存储的数据类型
// 节点结构体
typedef struct ListNode {
ElemType data; // 数据域:存储实际数据
struct ListNode* next; // 指针域:指向下一个节点
} ListNode;节点结构体大小:
cpp
┌─────────────────────────────────────────────┐
│ ListNode 节点 │
├─────────────────────────────────────────────┤
│ data (4字节) │ next (8字节,64位系统) │
└─────────────────────────────────────────────┘
总大小:12字节(可能内存对齐后为16字节)二、链表管理结构体
cpp
// 链表管理结构体
struct LinkList {
ListNode* head; // 指向头结点(不存储数据)
size_t cursize; // 当前链表中的元素个数
};设计意图:
-
head:始终指向头结点,头结点的next指向第一个实际存储数据的节点 -
cursize:记录链表长度,避免每次遍历计算
第三部分:链表的基本操作
一、初始化
原理 :创建头结点,让head指向它,头结点的next指向NULL。
cpp
void InitLinkList(struct LinkList* ps) {
assert(ps != NULL);
// 分配头结点内存
ListNode* p = (ListNode*)malloc(sizeof(ListNode));
if (p == NULL) return;
p->data = 0; // 头结点数据域无用,可任意赋值
p->next = NULL; // 初始时没有实际节点
ps->head = p;
ps->cursize = 0;
}初始化后的内存布局:

二、创建新节点(辅助函数)
cpp
ListNode* BuyNode(ElemType val) {
ListNode* p = (ListNode*)malloc(sizeof(ListNode));
if (p == NULL) return p;
p->data = val;
p->next = NULL;
return p;
}三、遍历与打印
cpp
void PrintLinkList(struct LinkList* ps) {
assert(ps != NULL);
// 从第一个实际节点开始遍历(跳过带头结点)
for (ListNode* p = ps->head->next; p != NULL; p = p->next) {
printf("%d ", p->data);
}
printf("\n");
}第四部分:插入操作
一、尾插(在尾部插入)
原理:遍历到尾节点,将新节点链接到尾部。
cpp
// 时间复杂度:O(n)
bool InsertBack(struct LinkList* ps, ElemType val) {
assert(ps != NULL);
ListNode* p = BuyNode(val);
if (p == NULL) return false;
// 找到尾节点
ListNode* q = ps->head;
while (q->next != NULL) {
q = q->next;
}
// 链接新节点
p->next = q->next; // 等价于 p->next = NULL
q->next = p;
ps->cursize++;
return true;
}示意图:
cpp
插入前 : head → ┌───┐ ┌───┐ ┌───┐
│10 │→ │20 │→ │30 │→ NULL
└───┘ └───┘ └───┘
插入val=40后:
┌───┐ ┌───┐ ┌───┐ ┌───┐
│10 │→ │20 │→ │30 │→ │40 │→ NULL
└───┘ └───┘ └───┘ └───┘二、头插(在头部插入)
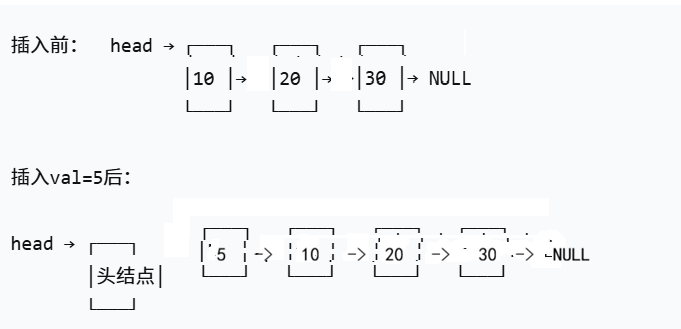
原理 :新节点的next指向原来的第一个节点,头结点指向新节点。
cpp
// 时间复杂度:O(1)
bool InsertFront(struct LinkList* ps, ElemType val) {
assert(ps != NULL);
ListNode* p = BuyNode(val);
if (p == NULL) return false;
p->next = ps->head->next; // 新节点指向原第一个节点
ps->head->next = p; // 头结点指向新节点
ps->cursize++;
return true;
}示意图:
三、按位置插入
原理 :找到第pos-1个节点,在其后插入新节点。
cpp
// 时间复杂度:O(n)
bool InsertPos(struct LinkList* ps, ElemType val, int pos) {
assert(ps != NULL);
// 位置有效性检查:1 ≤ pos ≤ cursize+1
if (pos < 1 || pos > ps->cursize + 1) return false;
ListNode* p = BuyNode(val);
if (p == NULL) return false;
// 找到第 pos-1 个节点
ListNode* q = ps->head;
for (int i = 0; i < pos - 1; i++) {
q = q->next;
}
// 插入新节点
p->next = q->next;
q->next = p;
ps->cursize++;
return true;
}第五部分:删除操作
一、尾删(删除尾部节点)
原理 :找到倒数第二个节点,将其next设为NULL,释放尾节点。
cpp
// 时间复杂度:O(n)
bool PopBack(struct LinkList* ps) {
assert(ps != NULL);
if (ps->cursize == 0) return false; // 空链表
// 找到倒数第二个节点
ListNode* q = ps->head;
while (q->next->next != NULL) {
q = q->next;
}
// 释放尾节点
ListNode* p = q->next;
q->next = p->next; // 即 q->next = NULL
free(p);
p = NULL;
ps->cursize--;
return true;
}二、头删(删除头部节点)
原理:头结点绕过第一个节点,指向第二个节点,释放第一个节点。
cpp
// 时间复杂度:O(1)
bool PopFront(struct LinkList* ps) {
assert(ps != NULL);
if (ps->cursize == 0) return false;
ListNode* p = ps->head->next; // 要删除的节点
ps->head->next = p->next; // 头结点指向第二个节点
free(p);
p = NULL;
ps->cursize--;
return true;
}三、按位置删除
cpp
// 时间复杂度:O(n)
bool PopPos(struct LinkList* ps, int pos) {
assert(ps != NULL);
if (ps->cursize == 0) return false;
if (pos < 1 || pos > ps->cursize) return false;
// 找到第 pos-1 个节点
ListNode* q = ps->head;
for (int i = 0; i < pos - 1; i++) {
q = q->next;
}
// 删除第 pos 个节点
ListNode* p = q->next;
q->next = p->next;
free(p);
p = NULL;
ps->cursize--;
return true;
}第六部分:完整测试代码
cpp
#include "List.h"
#include <stdio.h>
int main() {
struct LinkList list;
// 1. 初始化
InitLinkList(&list);
printf("初始化后,元素个数:%zu\n", list.cursize);
// 2. 头插
InsertFront(&list, 10);
InsertFront(&list, 20);
InsertFront(&list, 30);
printf("头插后:");
PrintLinkList(&list); // 30 20 10
// 3. 尾插
InsertBack(&list, 40);
InsertBack(&list, 50);
printf("尾插后:");
PrintLinkList(&list); // 30 20 10 40 50
// 4. 按位置插入
InsertPos(&list, 100, 3); // 在第3个位置插入100
printf("位置插入后:");
PrintLinkList(&list); // 30 20 100 10 40 50
// 5. 头删
PopFront(&list);
printf("头删后:");
PrintLinkList(&list); // 20 100 10 40 50
// 6. 尾删
PopBack(&list);
printf("尾删后:");
PrintLinkList(&list); // 20 100 10 40
// 7. 按位置删除
PopPos(&list, 2);
printf("删除位置2后:");
PrintLinkList(&list); // 20 10 40
return 0;
}第七部分:顺序表 vs 链表
| 操作 | 顺序表 | 链表 | 说明 |
|---|---|---|---|
| 按下标访问 | O(1) | O(n) | 链表需要遍历 |
| 头部插入 | O(n) | O(1) | 链表只需改指针 |
| 头部删除 | O(n) | O(1) | 链表只需改指针 |
| 尾部插入 | O(1)(扩容时O(n)) | O(n) | 链表需遍历到尾 |
| 中间插入 | O(n) | O(n) | 都需要定位 |
| 内存占用 | 较少 | 较多 | 链表有指针开销 |
| 缓存友好 | 好 | 差 | 顺序表内存连续 |
选择建议:
-
频繁按下标访问 → 顺序表
-
频繁头插/头删 → 链表
-
频繁尾插 → 顺序表(或维护尾指针的链表)
-
大小频繁变化 → 链表
第八部分:常见错误与注意事项
一、指针操作错误
cpp
// ❌ 错误:p未初始化就修改next
ListNode* p;
p->next = NULL;
// ✅ 正确:先分配内存
ListNode* p = (ListNode*)malloc(sizeof(ListNode));
p->next = NULL;二、内存泄漏
cpp
// ❌ 错误:删除节点后未释放内存
q->next = p->next;
// p 的内存泄漏了
// ✅ 正确:释放内存
q->next = p->next;
free(p);
p = NULL;三、空指针解引用
cpp
// ❌ 错误:未检查链表是否为空
bool PopFront(struct LinkList* ps) {
ListNode* p = ps->head->next;
ps->head->next = p->next; // 如果p是NULL,这里崩溃
free(p);
return true;
}
// ✅ 正确:检查空链表
bool PopFront(struct LinkList* ps) {
if (ps->cursize == 0) return false;
// ... 正常删除逻辑
}总结
一、链表操作复杂度总结
| 操作 | 时间复杂度 | 代码关键点 |
|---|---|---|
| 初始化 | O(1) | 创建头结点 |
| 尾插 | O(n) | 遍历到尾节点 |
| 头插 | O(1) | 新节点指向原第一个节点 |
| 中间插入 | O(n) | 定位到前驱节点 |
| 尾删 | O(n) | 找到倒数第二个节点 |
| 头删 | O(1) | 头结点指向第二个节点 |
| 中间删除 | O(n) | 定位到前驱节点 |
| 遍历 | O(n) | 从头结点下一个开始 |
二、带头结点的优势
| 场景 | 不带头结点 | 带头结点 |
|---|---|---|
| 空表判断 | head == NULL |
head->next == NULL |
| 头插操作 | 需要修改头指针 | 操作统一 |
| 删除头节点 | 需要修改头指针 | 操作统一 |
三、核心函数速查
| 函数 | 功能 | 关键操作 |
|---|---|---|
InitLinkList |
初始化 | 创建头结点 |
BuyNode |
创建节点 | malloc + 赋值 |
InsertBack |
尾插 | 遍历到尾 + 链接 |
InsertFront |
头插 | 头结点后插入 |
InsertPos |
位置插入 | 找前驱 + 链接 |
PopBack |
尾删 | 找倒数第二个 + 释放 |
PopFront |
头删 | 头结点绕过第一个 |
PopPos |
位置删除 | 找前驱 + 释放 |
链表是数据结构中非常重要的基础结构。本文实现了带头结点的单向链表,涵盖以下知识点:
-
节点结构:包含数据域和指针域
-
头结点:简化插入删除操作
-
插入操作:头插、尾插、按位置插入
-
删除操作:头删、尾删、按位置删除
-
内存管理:malloc分配、free释放
-
复杂度分析:理解各操作的时间复杂度
学习建议:
-
画图理解指针操作,不要只靠想象
-
注意边界条件(空链表、单节点链表)
-
插入和删除时确保指针指向正确
-
释放内存后将指针置NULL防止野指针