文章目录
-
- 一、LRU算法:基础与核心思想
-
- [1.1 什么是LRU?](#1.1 什么是LRU?)
- 二、LRU的数据结构实现
-
- [2.1 为什么?](#2.1 为什么?)
- [2.2 核心数据结构:哈希表 + 双向链表](#2.2 核心数据结构:哈希表 + 双向链表)
- [2.3 示例(C++)](#2.3 示例(C++))
- [2.4 主函数](#2.4 主函数)
- [2.5 手动模拟执行过程](#2.5 手动模拟执行过程)
- [2.6 完整测试程序](#2.6 完整测试程序)
- 三、LRU的应用场景
-
- [3.1 操作系统:页面置换算法](#3.1 操作系统:页面置换算法)
- [3.2 数据库系统:缓冲池管理](#3.2 数据库系统:缓冲池管理)
- [3.3 Web浏览器:资源缓存](#3.3 Web浏览器:资源缓存)
- [3.4 分布式缓存:Redis](#3.4 分布式缓存:Redis)
- [3.5 应用层缓存:C++实现](#3.5 应用层缓存:C++实现)
- 四、LRU的局限性
-
- [4.1 缓存污染问题](#4.1 缓存污染问题)
- [4.2 循环访问模式](#4.2 循环访问模式)
- [4.3 时间局部性假设失效](#4.3 时间局部性假设失效)
- 五、LRU的扩展与改进
-
- [5.1 LRU-K算法(C++实现)](#5.1 LRU-K算法(C++实现))
- [5.2 2Q算法(Two Queues)](#5.2 2Q算法(Two Queues))
- 六、优化进阶:并发安全的LRU缓存
-
- [6.1 线程安全的LRU缓存](#6.1 线程安全的LRU缓存)
- [6.2 性能测试](#6.2 性能测试)
- 七、监控与统计功能
-
- [7.1 带统计功能的LRU缓存](#7.1 带统计功能的LRU缓存)
- [7.2 实际使用](#7.2 实际使用)
- 八、总结
-
- [8.1 LRU的核心价值](#8.1 LRU的核心价值)
- [8.2 实现要点](#8.2 实现要点)
- [8.3 选择合适的变体](#8.3 选择合适的变体)
- [8.4 建议](#8.4 建议)
一、LRU算法:基础与核心思想
1.1 什么是LRU?
LRU,全称Least Recently Used(最近最少使用),是一种缓存淘汰策略。它的核心思想基于一个朴素的观察:
最近被访问过的数据,未来被再次访问的概率更高;而长时间未被访问的数据,未来被访问的概率更低。
这符合计算机科学中的时间局部性原理(Temporal Locality)。
二、LRU的数据结构实现
2.1 为什么?
要实现高效的LRU缓存,我们需要满足以下要求:
- O(1)时间复杂度的查找操作
- O(1)时间复杂度的插入和删除操作
- 能够快速定位"最近最少使用"的元素
2.2 核心数据结构:哈希表 + 双向链表
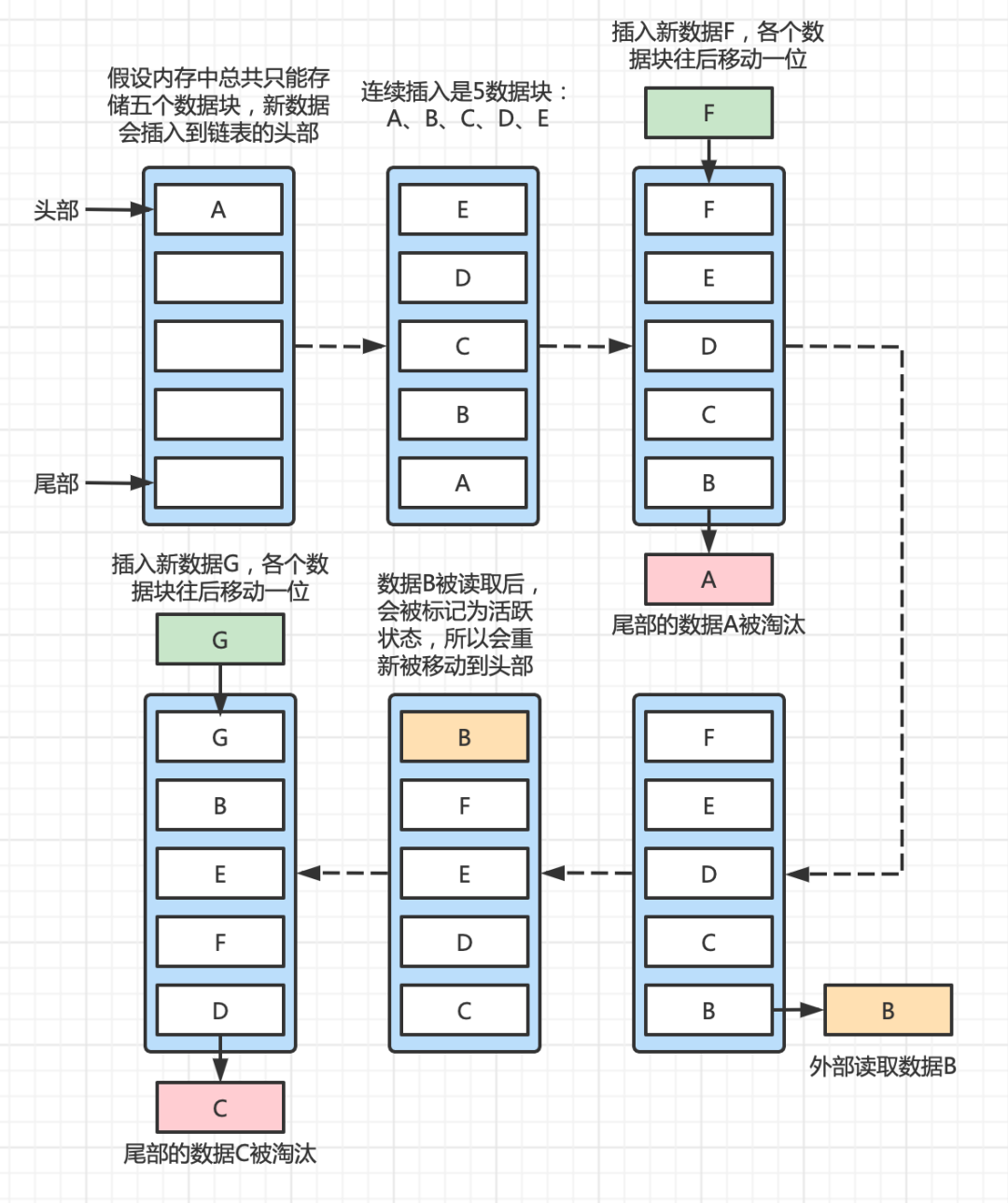
为什么选择这种组合?
| 操作 | 哈希表的作用 | 双向链表的作用 |
|---|---|---|
| 查找 | O(1)快速定位节点 | - |
| 更新顺序 | - | O(1)移动节点到头部 |
| 淘汰 | O(1)删除映射 | O(1)删除尾部节点 |
2.3 示例(C++)
cpp
#include <iostream>
#include <unordered_map>
#include <list>
#include <utility>
template<typename K, typename V>
class LRUCache {
private:
// 定义缓存节点类型
using Node = std::pair<K, V>;
using ListIterator = typename std::list<Node>::iterator;
size_t capacity_; // 缓存容量
std::list<Node> cache_list_; // 双向链表,头部为最近使用
std::unordered_map<K, ListIterator> cache_map_; // 哈希表映射
public:
explicit LRUCache(size_t capacity) : capacity_(capacity) {}
// 获取缓存值,时间复杂度O(1)
V get(const K& key) {
auto it = cache_map_.find(key);
if (it == cache_map_.end()) {
throw std::out_of_range("Key not found in cache");
}
// 将访问的节点移动到链表头部(最近使用)
cache_list_.splice(cache_list_.begin(), cache_list_, it->second);
return it->second->second;
}
// 插入或更新缓存,时间复杂度O(1)
void put(const K& key, const V& value) {
auto it = cache_map_.find(key);
if (it != cache_map_.end()) {
// 更新已有数据
it->second->second = value;
// 移动到链表头部
cache_list_.splice(cache_list_.begin(), cache_list_, it->second);
} else {
// 插入新数据
if (cache_list_.size() >= capacity_) {
// 容量超限,淘汰尾部节点(最少使用)
auto last = cache_list_.back();
cache_map_.erase(last.first);
cache_list_.pop_back();
}
// 插入到链表头部
cache_list_.emplace_front(key, value);
cache_map_[key] = cache_list_.begin();
}
}
// 检查键是否存在
bool contains(const K& key) const {
return cache_map_.find(key) != cache_map_.end();
}
// 获取缓存大小
size_t size() const {
return cache_list_.size();
}
// 清空缓存
void clear() {
cache_list_.clear();
cache_map_.clear();
}
// 打印缓存状态(用于调试)
void printCache() const {
std::cout << "LRU Cache (capacity: " << capacity_
<< ", size: " << cache_list_.size() << "):" << std::endl;
std::cout << "From MRU to LRU: ";
for (const auto& node : cache_list_) {
std::cout << "[" << node.first << "=" << node.second << "] ";
}
std::cout << std::endl;
}
};2.4 主函数
cpp
#include <iostream>
#include <string>
int main() {
// 创建容量为3的LRU缓存
LRUCache<int, std::string> cache(3);
std::cout << "=== LRU Cache 演示 ===" << std::endl;
std::cout << std::endl;
// 操作1: 插入数据
std::cout << "1. put(1, \"A\")" << std::endl;
cache.put(1, "A");
cache.printCache();
std::cout << std::endl;
// 操作2: 插入数据
std::cout << "2. put(2, \"B\")" << std::endl;
cache.put(2, "B");
cache.printCache();
std::cout << std::endl;
// 操作3: 插入数据
std::cout << "3. put(3, \"C\")" << std::endl;
cache.put(3, "C");
cache.printCache();
std::cout << std::endl;
// 操作4: 访问数据(触发移动)
std::cout << "4. get(1) -> " << cache.get(1) << std::endl;
cache.printCache();
std::cout << std::endl;
// 操作5: 插入新数据(触发淘汰)
std::cout << "5. put(4, \"D\")" << std::endl;
cache.put(4, "D");
cache.printCache();
std::cout << std::endl;
// 操作6: 尝试访问已淘汰的数据
std::cout << "6. get(2)" << std::endl;
try {
std::cout << " Result: " << cache.get(2) << std::endl;
} catch (const std::out_of_range& e) {
std::cout << " Error: " << e.what() << std::endl;
}
std::cout << std::endl;
// 操作7: 插入新数据
std::cout << "7. put(5, \"E\")" << std::endl;
cache.put(5, "E");
cache.printCache();
std::cout << std::endl;
// 检查缓存状态
std::cout << "=== 缓存状态检查 ===" << std::endl;
std::cout << "缓存大小: " << cache.size() << std::endl;
std::cout << "包含键3: " << (cache.contains(3) ? "是" : "否") << std::endl;
std::cout << "包含键2: " << (cache.contains(2) ? "是" : "否") << std::endl;
return 0;
}2.5 手动模拟执行过程
假设我们创建一个容量为3的LRU缓存:
cpp
LRUCache<int, int> cache(3);操作序列:
put(1, 10)→ 缓存:[1]put(2, 20)→ 缓存:[2, 1](2是最近使用的)put(3, 30)→ 缓存:[3, 2, 1]get(1)→ 命中!缓存:[1, 3, 2](1被移动到头部)put(4, 40)→ 容量满,淘汰2 → 缓存:[4, 1, 3]get(2)→ 未命中,抛出异常put(5, 50)→ 淘汰3 → 缓存:[5, 4, 1]
py
时间线可视化:
t0: [] (初始空缓存)
t1: [1] (插入1)
t2: [2, 1] (插入2,1移到后面)
t3: [3, 2, 1] (插入3)
t4: [1, 3, 2] (访问1,1移到头部)
t5: [4, 1, 3] (插入4,淘汰2)
t6: [4, 1, 3] (访问2,未命中)
t7: [5, 4, 1] (插入5,淘汰3)
2.6 完整测试程序
cpp
#include <iostream>
#include <cassert>
void testLRUCache() {
LRUCache<int, int> cache(2);
// 测试1: 基本插入
cache.put(1, 1);
cache.put(2, 2);
assert(cache.get(1) == 1); // 访问1,移动到头部
// 测试2: 淘汰机制
cache.put(3, 3); // 应该淘汰2
try {
cache.get(2); // 2应该不存在
assert(false); // 不应该到达这里
} catch (const std::out_of_range&) {
// 预期的异常
}
// 测试3: 更新值
cache.put(1, 10);
assert(cache.get(1) == 10);
// 测试4: 再次淘汰
cache.put(4, 4); // 应该淘汰3
try {
cache.get(3);
assert(false);
} catch (const std::out_of_range&) {
// 预期的异常
}
assert(cache.get(1) == 10);
assert(cache.get(4) == 4);
std::cout << "所有测试通过!" << std::endl;
}
int main() {
testLRUCache();
return 0;
}三、LRU的应用场景
3.1 操作系统:页面置换算法
在虚拟内存管理中,当物理内存不足时,操作系统需要将某些页面换出到磁盘。LRU是一种常用的页面置换算法。
Linux Page Cache:
bash
# 查看系统缓存统计
$ cat /proc/meminfo | grep -i cache
Cached: 123456 kB3.2 数据库系统:缓冲池管理
MySQL InnoDB缓冲池使用LRU的变体来管理数据页缓存:
sql
-- 查看缓冲池状态
SHOW ENGINE INNODB STATUS;3.3 Web浏览器:资源缓存
浏览器使用LRU策略缓存CSS、JavaScript、图片等静态资源,提升页面加载速度。
3.4 分布式缓存:Redis
Redis支持多种淘汰策略,LRU是其中最常用的一种:
redis
# 配置Redis使用LRU淘汰策略
CONFIG SET maxmemory-policy allkeys-lru3.5 应用层缓存:C++实现
cpp
#include <iostream>
#include <string>
#include <functional>
// 使用LRUCache实现函数结果缓存
template<typename ReturnType, typename... Args>
class FunctionCache {
private:
LRUCache<std::string, ReturnType> cache_;
std::function<ReturnType(Args...)> func_;
// 将参数转换为唯一键
template<typename... Ts>
std::string makeKey(Ts&&... args) {
std::ostringstream oss;
((oss << args << "|"), ...);
return oss.str();
}
public:
FunctionCache(size_t capacity, std::function<ReturnType(Args...)> func)
: cache_(capacity), func_(func) {}
ReturnType operator()(Args... args) {
std::string key = makeKey(args...);
if (cache_.contains(key)) {
std::cout << "Cache hit for key: " << key << std::endl;
return cache_.get(key);
}
std::cout << "Cache miss for key: " << key << std::endl;
ReturnType result = func_(args...);
cache_.put(key, result);
return result;
}
};
// 示例:缓存斐波那契数列计算
int fibonacci(int n) {
if (n < 2) return n;
return fibonacci(n - 1) + fibonacci(n - 2);
}
int main() {
// 创建缓存版本的斐波那契函数
FunctionCache<int, int> cachedFib(100, fibonacci);
std::cout << "第一次计算: " << cachedFib(10) << std::endl; // 缓存未命中
std::cout << "第二次计算: " << cachedFib(10) << std::endl; // 缓存命中
std::cout << "第三次计算: " << cachedFib(15) << std::endl; // 部分命中
return 0;
}四、LRU的局限性
4.1 缓存污染问题
场景: 批量数据扫描(如全表扫描)
cpp
// 模拟全表扫描导致的缓存污染
void tableScan(LRUCache<int, std::string>& cache, int tableSize) {
for (int i = 0; i < tableSize; ++i) {
// 大量一次性访问的数据
cache.put(i, "data_" + std::to_string(i));
}
}问题: 这些一次性访问的数据会"污染"缓存,挤掉真正的热点数据。
4.2 循环访问模式
如果访问模式是循环的(A→B→C→A→B→C...),且循环周期大于缓存容量,LRU的表现会很差。
cpp
void testCircularAccess() {
LRUCache<char, int> cache(2);
// 循环访问模式
std::string pattern = "ABCABCABC";
for (char c : pattern) {
try {
cache.get(c);
std::cout << "Hit: " << c << std::endl;
} catch (...) {
std::cout << "Miss: " << c << std::endl;
cache.put(c, 1);
}
}
// 结果:命中率极低,因为缓存容量小于循环周期
}4.3 时间局部性假设失效
某些应用场景下,"最近使用"并不意味着"未来会使用"。
五、LRU的扩展与改进
5.1 LRU-K算法(C++实现)
核心思想: 不仅记录最近使用时间,还记录历史访问次数。只有当数据被访问K次后,才将其加入主缓存。
cpp
#include <queue>
#include <set>
template<typename K, typename V>
class LRU_K_Cache {
private:
struct HistoryEntry {
K key;
int access_count;
HistoryEntry(K k, int c = 1) : key(k), access_count(c) {}
bool operator<(const HistoryEntry& other) const {
return access_count < other.access_count;
}
};
size_t capacity_;
size_t k_;
LRUCache<K, V> main_cache_; // 主缓存(LRU)
std::unordered_map<K, int> access_counter_; // 访问计数器
std::queue<K> history_queue_; // 历史队列
public:
LRU_K_Cache(size_t capacity, size_t k = 2)
: capacity_(capacity), k_(k), main_cache_(capacity) {}
V get(const K& key) {
if (main_cache_.contains(key)) {
return main_cache_.get(key);
}
// 更新访问计数
access_counter_[key]++;
// 如果达到K次访问,加入主缓存
if (access_counter_[key] >= k_) {
// 需要从其他地方获取value,这里简化处理
// 实际应用中应该有数据源
V value = retrieveValue(key);
main_cache_.put(key, value);
access_counter_.erase(key); // 重置计数
}
throw std::out_of_range("Key not in cache");
}
void put(const K& key, const V& value) {
if (access_counter_[key] >= k_) {
main_cache_.put(key, value);
access_counter_.erase(key);
} else {
access_counter_[key]++;
}
}
private:
// 模拟从数据源获取值
V retrieveValue(const K& key) {
// 实际实现应该从数据库、文件等获取
return V();
}
};5.2 2Q算法(Two Queues)
2Q是LRU-2的一个具体实现,维护两个队列:
cpp
template<typename K, typename V>
class TwoQueueCache {
private:
// A1: FIFO队列,存储新数据
std::queue<K> a1_queue_;
std::unordered_map<K, V> a1_map_;
size_t a1_capacity_;
// Am: LRU队列,存储热数据
LRUCache<K, V> am_cache_;
public:
TwoQueueCache(size_t total_capacity)
: a1_capacity_(total_capacity / 3), // A1占1/3
am_cache_(total_capacity * 2 / 3) {} // Am占2/3
V get(const K& key) {
// 先在Am中查找
if (am_cache_.contains(key)) {
return am_cache_.get(key);
}
// 再在A1中查找
auto it = a1_map_.find(key);
if (it != a1_map_.end()) {
// 从A1移到Am
V value = it->second;
a1_map_.erase(it);
// 从队列中移除(简化处理)
auto q_it = std::find(a1_queue_.begin(), a1_queue_.end(), key);
if (q_it != a1_queue_.end()) {
a1_queue_.erase(q_it);
}
am_cache_.put(key, value);
return value;
}
throw std::out_of_range("Key not found");
}
void put(const K& key, const V& value) {
// 如果在Am中,直接更新
if (am_cache_.contains(key)) {
am_cache_.put(key, value);
return;
}
// 如果在A1中,更新值
if (a1_map_.find(key) != a1_map_.end()) {
a1_map_[key] = value;
return;
}
// 新数据,加入A1
if (a1_map_.size() >= a1_capacity_) {
// A1满了,淘汰队首
K old_key = a1_queue_.front();
a1_queue_.pop();
a1_map_.erase(old_key);
}
a1_queue_.push(key);
a1_map_[key] = value;
}
};六、优化进阶:并发安全的LRU缓存
6.1 线程安全的LRU缓存
cpp
#include <mutex>
#include <shared_mutex>
template<typename K, typename V>
class ThreadSafeLRUCache {
private:
LRUCache<K, V> cache_;
mutable std::shared_mutex mutex_; // C++17共享互斥锁
public:
explicit ThreadSafeLRUCache(size_t capacity) : cache_(capacity) {}
// 读操作使用共享锁
V get(const K& key) {
std::shared_lock<std::shared_mutex> lock(mutex_);
return cache_.get(key);
}
// 写操作使用独占锁
void put(const K& key, const V& value) {
std::unique_lock<std::shared_mutex> lock(mutex_);
cache_.put(key, value);
}
bool contains(const K& key) const {
std::shared_lock<std::shared_mutex> lock(mutex_);
return cache_.contains(key);
}
size_t size() const {
std::shared_lock<std::shared_mutex> lock(mutex_);
return cache_.size();
}
};6.2 性能测试
cpp
#include <thread>
#include <vector>
#include <chrono>
void performanceTest() {
ThreadSafeLRUCache<int, std::string> cache(10000);
auto start = std::chrono::high_resolution_clock::now();
// 创建多个线程并发访问
std::vector<std::thread> threads;
for (int i = 0; i < 10; ++i) {
threads.emplace_back([&cache, i]() {
for (int j = 0; j < 10000; ++j) {
int key = (i * 10000 + j) % 5000; // 50%命中率
if (j % 2 == 0) {
cache.put(key, "value_" + std::to_string(key));
} else {
try {
cache.get(key);
} catch (...) {
// 忽略异常
}
}
}
});
}
for (auto& t : threads) {
t.join();
}
auto end = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end - start);
std::cout << "并发测试完成,总操作数: " << 10 * 10000 << std::endl;
std::cout << "耗时: " << duration.count() << " ms" << std::endl;
std::cout << "吞吐量: " << (10 * 10000 * 1000.0 / duration.count())
<< " ops/sec" << std::endl;
}七、监控与统计功能
7.1 带统计功能的LRU缓存
cpp
template<typename K, typename V>
class MonitoredLRUCache {
private:
LRUCache<K, V> cache_;
mutable std::mutex stats_mutex_;
struct Statistics {
size_t hits = 0;
size_t misses = 0;
size_t puts = 0;
size_t evictions = 0;
std::chrono::steady_clock::time_point start_time;
Statistics() : start_time(std::chrono::steady_clock::now()) {}
double hitRate() const {
size_t total = hits + misses;
return total > 0 ? (double)hits / total : 0.0;
}
double uptimeSeconds() const {
auto now = std::chrono::steady_clock::now();
return std::chrono::duration<double>(now - start_time).count();
}
} stats_;
public:
explicit MonitoredLRUCache(size_t capacity) : cache_(capacity) {}
V get(const K& key) {
try {
V value = cache_.get(key);
{
std::lock_guard<std::mutex> lock(stats_mutex_);
stats_.hits++;
}
return value;
} catch (const std::out_of_range&) {
{
std::lock_guard<std::mutex> lock(stats_mutex_);
stats_.misses++;
}
throw;
}
}
void put(const K& key, const V& value) {
bool will_evict = cache_.size() >= cache_.capacity() && !cache_.contains(key);
cache_.put(key, value);
{
std::lock_guard<std::mutex> lock(stats_mutex_);
stats_.puts++;
if (will_evict) {
stats_.evictions++;
}
}
}
Statistics getStats() const {
std::lock_guard<std::mutex> lock(stats_mutex_);
return stats_;
}
void printStats() const {
Statistics stats = getStats();
std::cout << "=== LRU Cache Statistics ===" << std::endl;
std::cout << "Uptime: " << stats.uptimeSeconds() << " seconds" << std::endl;
std::cout << "Total operations: " << (stats.hits + stats.misses + stats.puts) << std::endl;
std::cout << "Hits: " << stats.hits << std::endl;
std::cout << "Misses: " << stats.misses << std::endl;
std::cout << "Puts: " << stats.puts << std::endl;
std::cout << "Evictions: " << stats.evictions << std::endl;
std::cout << "Hit rate: " << (stats.hitRate() * 100) << "%" << std::endl;
std::cout << "============================" << std::endl;
}
};7.2 实际使用
cpp
void demonstrateMonitoring() {
MonitoredLRUCache<int, std::string> cache(5);
// 模拟访问模式
for (int i = 0; i < 20; ++i) {
cache.put(i % 8, "value_" + std::to_string(i % 8));
if (i % 3 == 0) {
try {
cache.get(i % 5);
} catch (...) {}
}
}
cache.printStats();
}八、总结
8.1 LRU的核心价值
- 简单高效: 实现简单,性能优异
- 符合直觉: 基于时间局部性原理
- 广泛应用: 从操作系统到应用层都有应用
- C++优势: 零开销抽象,适合系统级开发
8.2 实现要点
| 特性 | 实现技巧 | 优势 |
|---|---|---|
| 性能 | 使用std::list + std::unordered_map |
O(1)复杂度 |
| 内存 | 使用emplace避免拷贝 |
零拷贝插入 |
| 泛型 | 模板编程 | 类型安全,代码复用 |
| 并发 | std::shared_mutex |
读多写少场景优化 |
8.3 选择合适的变体
| 场景 | 推荐算法 | 原因 |
|---|---|---|
| 通用缓存 | 标准LRU | 简单高效 |
| 数据库系统 | LIRS或InnoDB LRU | 防止扫描污染 |
| 批量处理 | LRU-K (K=2) | 过滤一次性访问 |
| 高并发系统 | 2Q | 平衡性能和命中率 |
| 分布式系统 | 带监控的LRU | 可观测性 |
8.4 建议
-
容量规划: 根据工作集大小和访问模式合理设置缓存容量
-
监控指标: 持续监控命中率,及时调整策略
-
避免过度优化: 在大多数场景下,标准LRU已经足够好
-
考虑业务特性: 根据具体业务选择或定制淘汰策略
-
C++最佳实践:
- 使用移动语义减少拷贝
- 考虑使用智能指针管理资源
- 注意异常安全性
- 使用
constexpr优化编译期计算
-
生产环境建议添加的功能:
python
// 1. TTL(Time To Live)支持
// 2. LRU链表的惰性清理
// 3. 批量操作接口
// 4. 序列化/反序列化
// 5. 完善的异常处理
// 6. 性能分析工具集成
// 7. 配置热更新
// 8. 分布式一致性支持