****论文题目:****TACKLING TIME-SERIES FORECASTING GENERALIZATION VIA MITIGATING CONCEPT DRIFT(通过减少概念漂移解决时间序列预测泛化问题)
会议:ICLR2026
****摘要:****时间序列预测在现实世界中有着广泛的应用。由于时间序列数据的动态性,对于时间序列预测模型来说,处理随时间变化的潜在分布变化是很重要的。在本文中,我们初步确定了两种类型的时间序列分布漂移:概念漂移和时间漂移。我们认识到,虽然现有的研究主要集中在解决时间序列预测中的时间漂移问题,但设计合适的时间序列预测的概念漂移方法受到的关注相对较少。由于需要解决潜在的概念漂移,而传统的通过不变学习的概念漂移方法在时间序列预测中面临一定的挑战,我们提出了一种软注意机制,从回顾和水平时间序列中发现不变模式。此外,我们强调了缓解时间变化作为解决概念漂移的初步措施的重要性。在这种情况下,我们介绍了shift,这是一个方法不可知的框架,旨在首先处理时间转移,然后在统一的方法中处理概念漂移。大量的实验证明了shift在跨多个数据集持续提高不可知论模型的预测精度方面的有效性,并且优于现有的概念漂移、时间漂移和组合基线。
ShifTS:让时间序列预测模型真正学会应对"变化的世界"
一、为什么时间序列预测这么难?
时间序列预测在现实中无处不在------经济学家用它预测汇率走势,流行病学家用它预测流感患者数量,交通管理者用它调度城市资源。过去十年,深度学习模型(Informer、PatchTST、iTransformer等)在这一领域取得了令人瞩目的进展。
然而,这些模型大多建立在一个理想化假设之上:训练集和测试集的数据分布相同(IID假设)。
现实中,时间序列数据是动态变化的,这个假设几乎从不成立。
二、问题的根源:两种"分布偏移"
这篇论文最重要的贡献之一,是清晰地将时间序列中的分布偏移区分为两种完全不同的类型,并指出此前学界在这两者的处理上存在严重不对等。
2.1 时间偏移(Temporal Shift)
定义: 时间序列自身的边缘统计特性随时间变化,包括均值、方差、自相关结构等,而X与Y之间的条件关系不变。
直观来说,就是一段时间内气温的"平均水平"和"波动幅度"发生了变化,但气温与用电量之间的规律本身没有变。
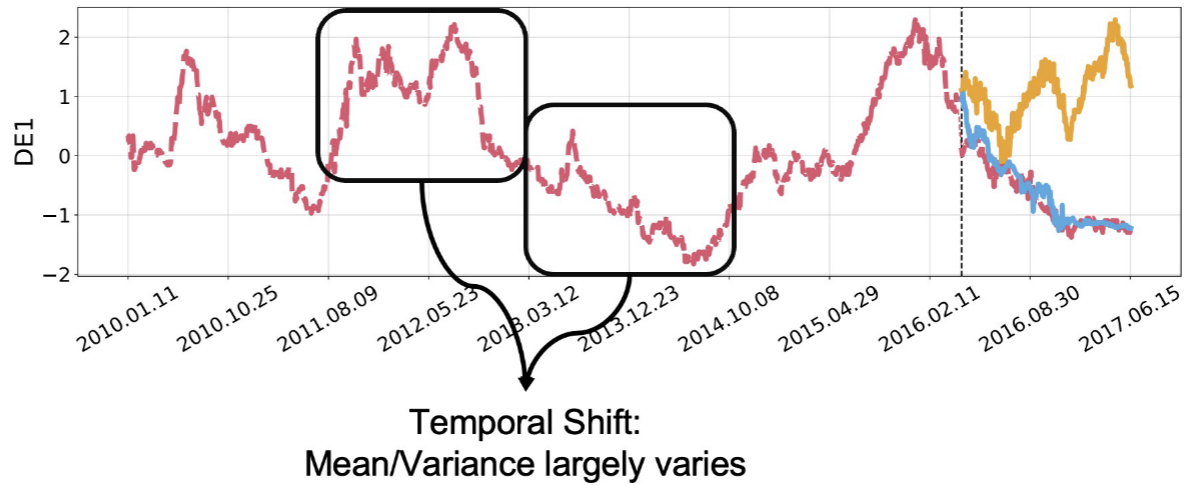
📊 【配图:Figure 4 - 时间偏移示意图】
图中展示了一条时间序列在lookback窗口和horizon窗口之间均值与方差发生明显漂移的情况。
现状: 学界已有较为成熟的解决方案,如 RevIN(可逆实例归一化)、N-S Transformer、SAN 等,核心思路都是"进模型前归一化,出模型后反归一化"。
2.2 概念漂移(Concept Drift)
定义: 外生变量X与目标变量Y之间的条件分布随时间发生变化,即 P(Y^H | X^L) 不稳定,而边缘分布本身不变。
直观来说,就是某个外部因素与预测目标之间的"相关方向"发生了反转------比如某个气象指标在冬天与流感患者数正相关,但在夏天却与之负相关。
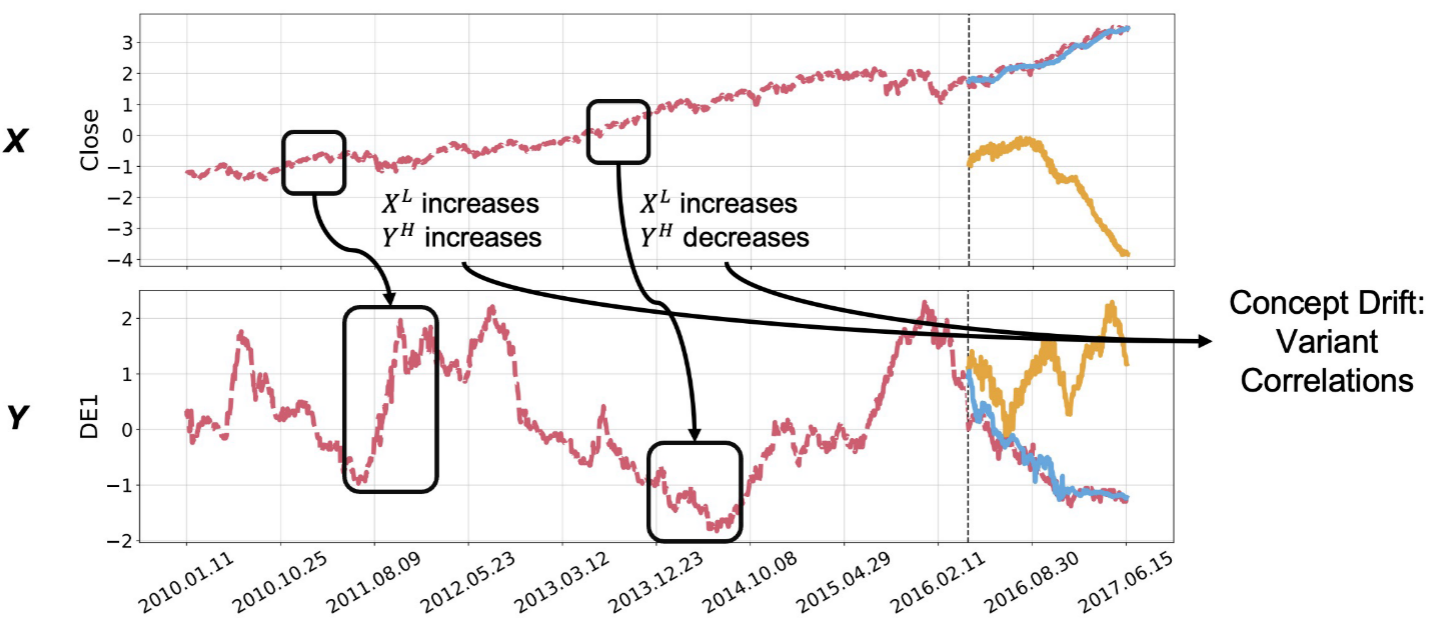
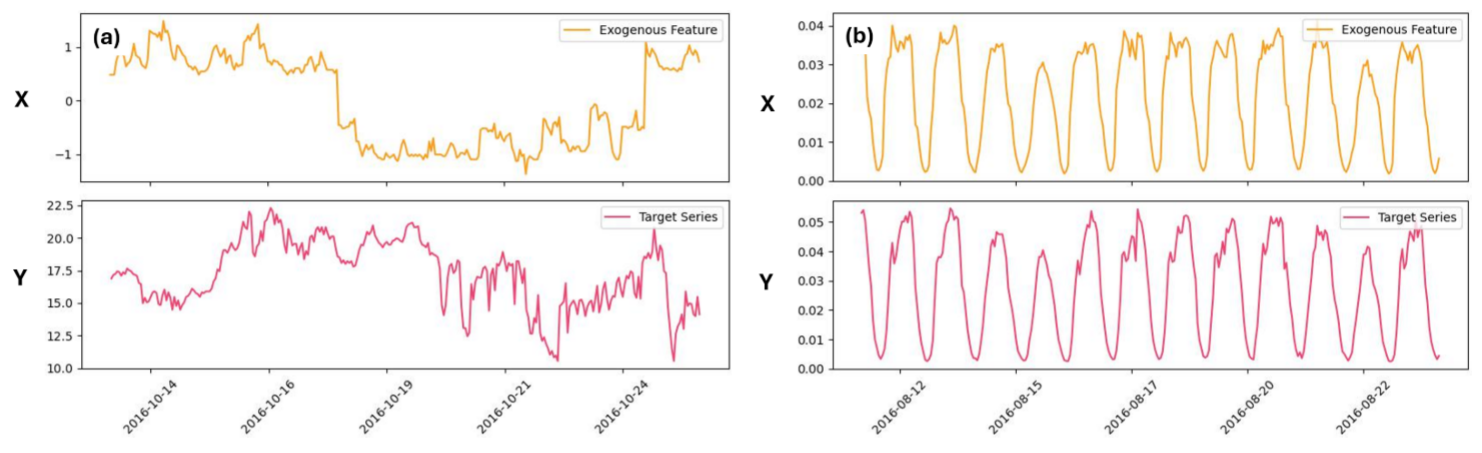
📊 【配图:Figure 5 - 概念漂移示意图】
图中上方是外生特征X,下方是目标序列Y。可以看到在早期时间段X升高则Y升高,而在后期时间段X升高则Y降低,相关关系发生了根本性反转。
现状:严重被忽视。 通用机器学习中的不变学习方法(IRM、GroupDRO、VREx等)虽然能处理概念漂移,但它们需要环境标签 (environment labels),而时间序列数据天然不具备这种标签。极少数专门针对时序的概念漂移方法,又只能用于在线学习场景(需要在每个时间步迭代重训练),根本不适用于标准的时间序列预测任务。
这就是本文要填补的空白。
三、核心洞见:为什么Lookback窗口不够用?
传统时序预测的输入结构如下:用历史lookback窗口的外生特征 X^L 和历史目标 Y^L 来预测未来的 Y^H。
问题在于,X^L 的信息往往不足以建立稳定的条件分布。考虑流感预测的例子:一次冬季流感爆发,可能由极端严寒触发,也可能由夏季热浪的后续效应引发。如果只看lookback窗口,这种跨时间的因果关系就被切断了。
真正能够稳定预测 Y^H 的,是 X^H(horizon窗口中的外生特征)与 X^L 联合提供的完整因果信息。然而,X^H 在测试时是未知的,不能直接使用------这正是方法设计的挑战所在。
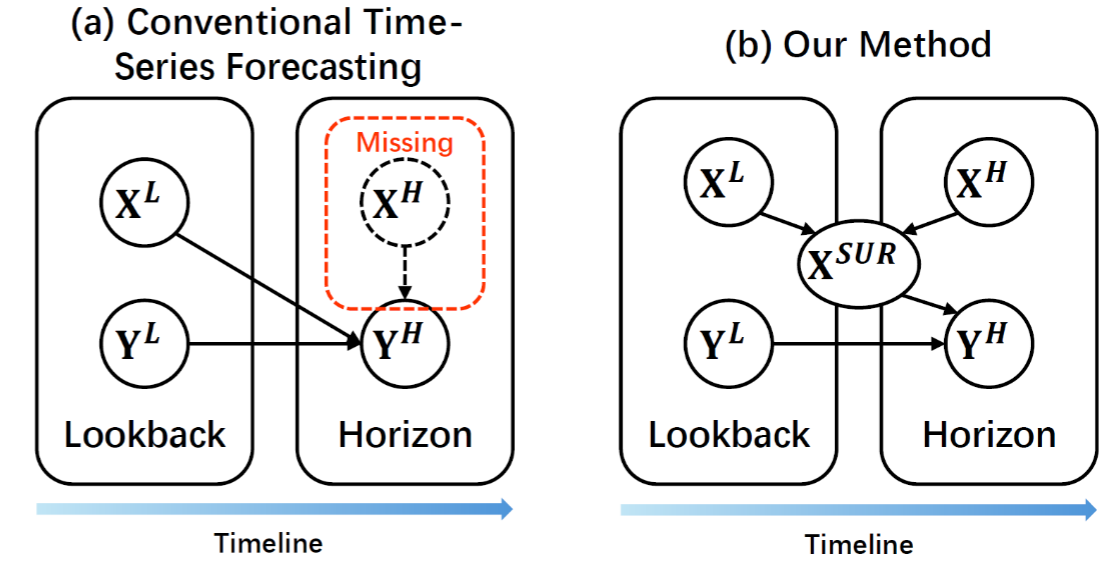
📊 【配图:Figure 1 - 传统方法与本文方法对比示意图】
(a) 传统方法:仅用 X^L 和 Y^L 预测 Y^H,horizon窗口中的 X^H 信息被完全忽略。
(b) 本文方法:从 X\^L, X\^H 中识别不变模式,构建代理特征 X^SUR 来辅助预测。
四、方法:ShifTS框架
ShifTS由两个核心组件构成:SAM(软注意力掩码机制) 用于应对概念漂移,RevIN 用于应对时间偏移,两者组合在统一框架中按序执行。
4.1 SAM:软注意力掩码机制(应对概念漂移)
SAM的目标是从完整的外生特征序列 X\^L, X\^H 中,识别那些与目标 Y^H 之间具有跨时间稳定相关性的"不变模式",并将它们聚合为代理特征 X^SUR。
具体步骤:
Step 1 - 切片提取局部模式
将 X\^L, X\^H(长度 L+H)用大小为 H 的滑动窗口切片,共得到 L+1 个局部子序列,每个子序列代表某一时间步的局部模式候选。
Step 2 - 软注意力加权筛选
用可学习的软注意力矩阵 M 对每个局部模式进行加权,经过三步操作:
- Softmax:计算每个模式对目标贡献的相对权重
- 稀疏化:过滤掉低权重的模式,保留真正稳定的"高权重"模式
- 归一化:确保权重之和规范化
权重高的模式,意味着它在所有时间步上都一致地贡献于目标预测,这正是"不变模式"的定义。
Step 3 - 构建代理特征与损失计算
将筛选出的不变模式加权求和,得到代理特征:
由于 X^H 在测试时不可用,SAM 在训练时学习估计 X̂^SUR,代理损失为:
4.2 为什么必须先处理时间偏移?
论文的一个关键理论洞见:时间偏移的解决是概念漂移处理的前提条件。
原因很直接:SAM 的目标是学习一个稳定的条件分布 P(Y^H | X^SUR)。但如果边缘分布 P(Y^H) 或 P(X^SUR) 本身就因时间偏移而不断变化,SAM 就无法辨别"条件关系不稳定"到底是真正的概念漂移,还是只是边缘分布变化带来的假象。
因此,必须先通过归一化稳定边缘分布,再让 SAM 在干净的条件分布空间中识别不变模式。
4.3 ShifTS完整工作流
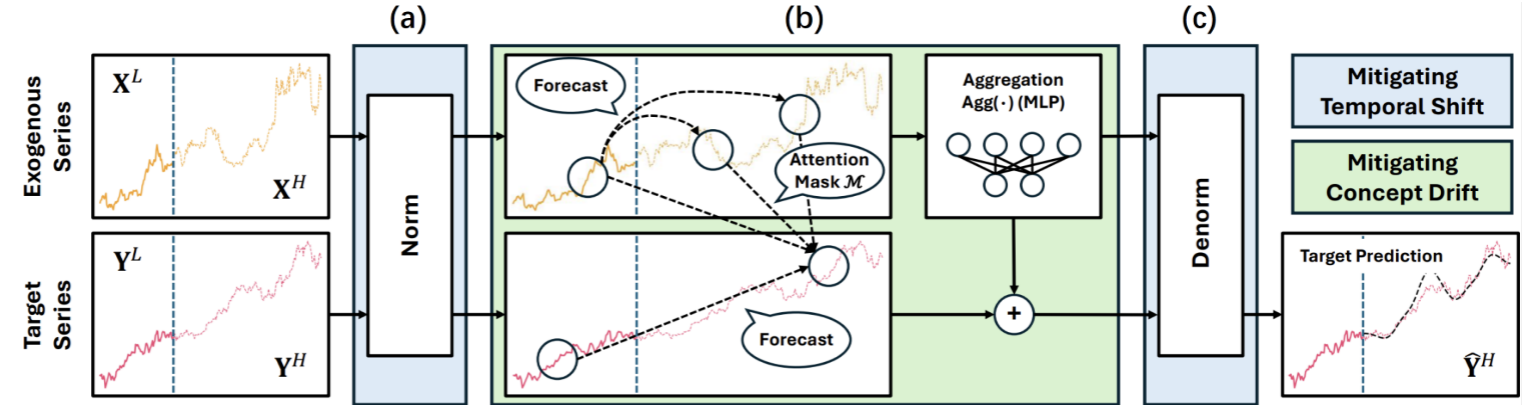
📊 【配图:Figure 2 - ShifTS框架整体图】
图中展示了ShifTS的三个核心模块:(a) 归一化(Norm),(b) 两阶段预测过程(SAM识别不变模式 + 聚合MLP预测目标),(c) 反归一化(Denorm)。
训练阶段(4步):
| 步骤 | 操作 | 目的 |
|---|---|---|
| 1 | 归一化输入 X\^L, Y\^L | 消除时间偏移 |
| 2 | 基础模型预测 X̂\^SUR, Ŷ\^H | 一阶段预测代理特征和目标 |
| 3 | 聚合MLP:Ŷ^H += Agg(X̂^SUR) | 利用不变模式修正预测 |
| 4 | 反归一化输出 | 恢复真实尺度 |
总损失:
测试阶段: 仅使用 X^L 和 Y^L,无需访问 X^H------SAM 通过学习到的注意力矩阵直接估计 X̂^SUR。
五、实验:全面验证ShifTS的有效性
5.1 实验设置
数据集: 6个真实世界数据集
- ILI:美国每周流感样患者数(8个变量)
- Exchange:8种货币每日汇率
- ETTh1/ETTh2:中国两地电力变压器温度(小时级,7个变量)
- ETTm1/ETTm2:同上,分钟级
为什么不用Traffic和Weather? 这些数据集具有强周期性,近似平稳,分布偏移问题不显著,不适合作为评测对象。
📊 【配图:Figure 6 - ETT与Traffic数据集分布偏移对比】
ETT数据集(左)存在明显的时间偏移(方差随时间变化)和概念漂移(X与Y相关性不稳定);Traffic数据集(右)近似周期性,偏移程度较低。
基础预测模型: 6个(均作为ShifTS的backbone)
- 较旧模型:Informer (AAAI'21)、Pyraformer (ICLR'21)
- 现代模型:Crossformer (ICLR'23)、PatchTST (ICLR'23)、TimeMixer (ICLR'24)
- SOTA:iTransformer (ICLR'24)
分布偏移基线:
- 概念漂移方法:GroupDRO、IRM、VREx、EIIL
- 时间偏移方法:RevIN、N-S Trans.、SAN
- 组合方法:IRM+RevIN、EIIL+RevIN、FOIL
5.2 主实验:ShifTS对各类模型的一致性提升
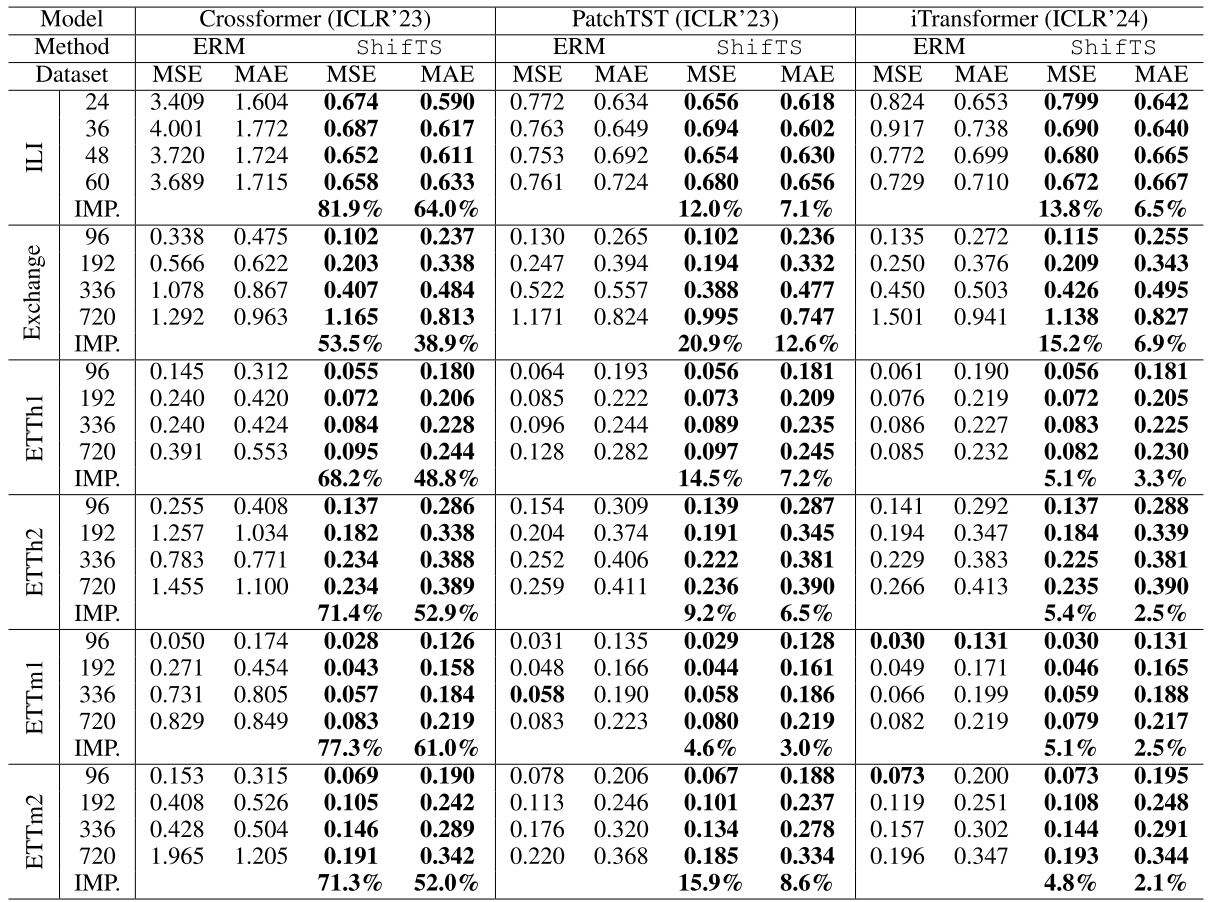
📊 【配Table 1 - ShifTS vs ERM(Crossformer、PatchTST、iTransformer)】
展示了在6个数据集、4种预测horizon下,加入ShifTS前后的MSE和MAE对比,以及平均提升幅度IMP.。
几个关键数据点:
对较旧/较弱模型,提升极为显著:
- Crossformer 在 ILI 数据集:MSE 平均下降 81.9% ,MAE 下降 64.0%
- Crossformer 在 ETTh1 数据集:MSE 平均下降 68.2%
对SOTA模型,依然有实质提升:
- iTransformer 在 ILI 数据集:MSE 平均下降 13.8%
- iTransformer 在 Exchange 数据集:MSE 平均下降 15.2%
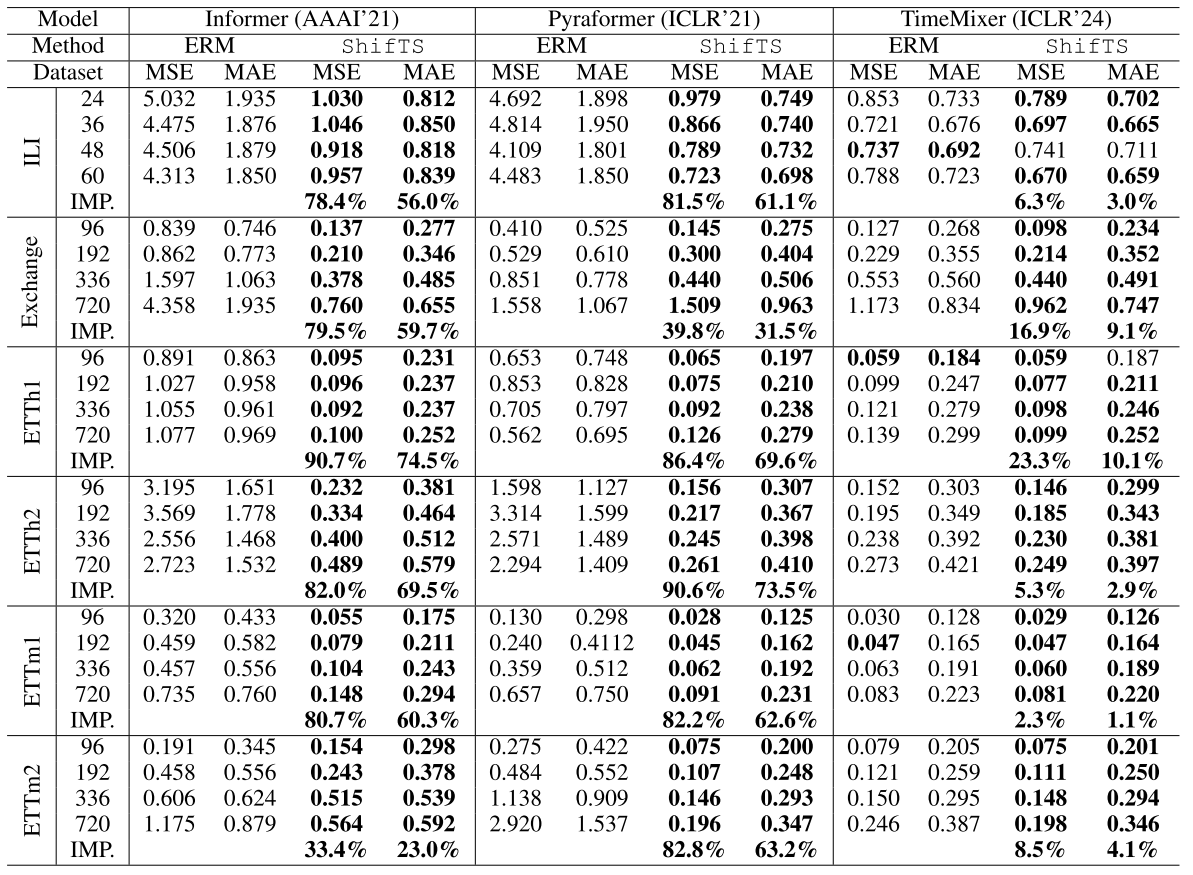
📊 【配Table 4 - ShifTS vs ERM(Informer、Pyraformer、TimeMixer)】
Informer 在 ETTh1 数据集 MSE 下降高达 90.7%,Pyraformer 在 ETTh2 数据集 MSE 下降 90.6%,进一步验证ShifTS对老模型的显著增益。
5.3 与分布偏移基线的比较
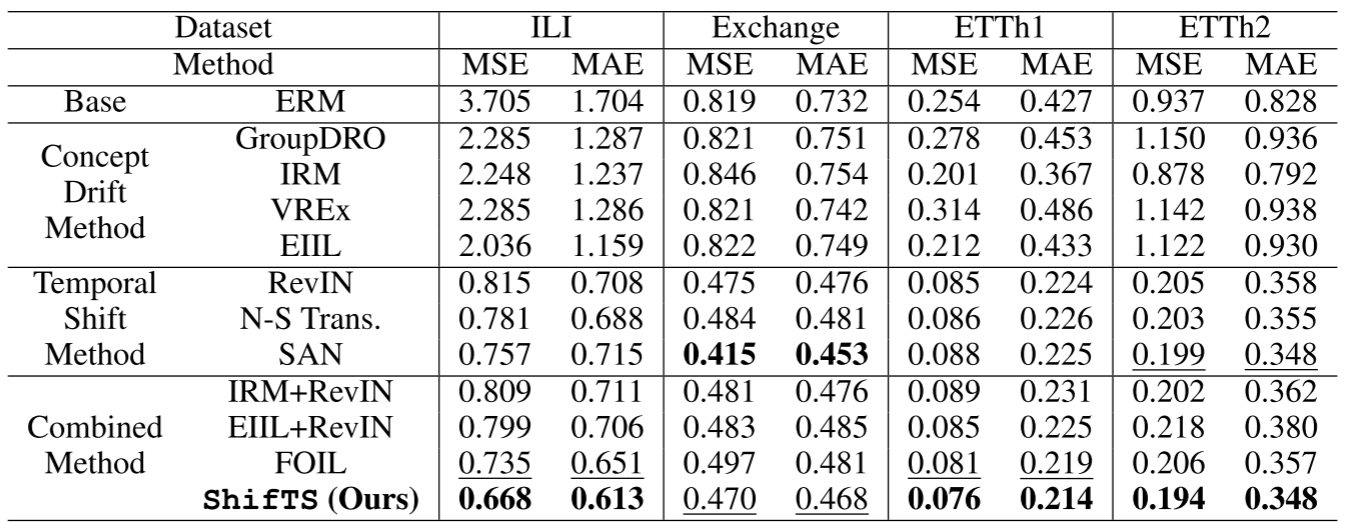
📊 【配Table 2 - ShifTS vs 各类分布偏移方法(Crossformer backbone)】
以Crossformer为基础模型,在ILI、Exchange、ETTh1、ETTh2四个数据集上对比所有基线。
核心发现:
-
纯概念漂移方法(IRM、GroupDRO等)效果有限甚至更差:在ETTh1和ETTh2上,GroupDRO的MSE反而比ERM基线更高(0.278 vs 0.254)。这证明了通用不变学习方法不适合时序场景。
-
时间偏移方法明显优于概念漂移方法,但ShifTS进一步超越了最好的时间偏移方法(SAN):例如在ILI数据集,ShifTS的MSE为0.668,优于SAN的0.757。
-
ShifTS在8项评估中6项排名第一,2项排名第二,全面领先所有组合方法(包括FOIL------当前专门针对时序分布偏移的SOTA)。
-
ShifTS可与更强的时间偏移方法组合,进一步提升性能:
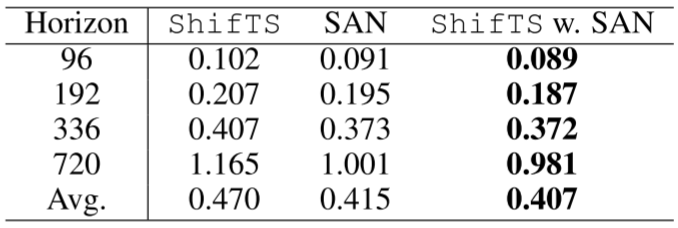
📊 【配Table 3 - ShifTS vs SAN vs ShifTS+SAN(Exchange数据集)】
在Exchange数据集上,ShifTS单独平均MSE为0.470,SAN单独为0.415,而ShifTS+SAN组合达到0.407,优于两者各自独立使用。
5.4 消融实验:每个模块都不可或缺
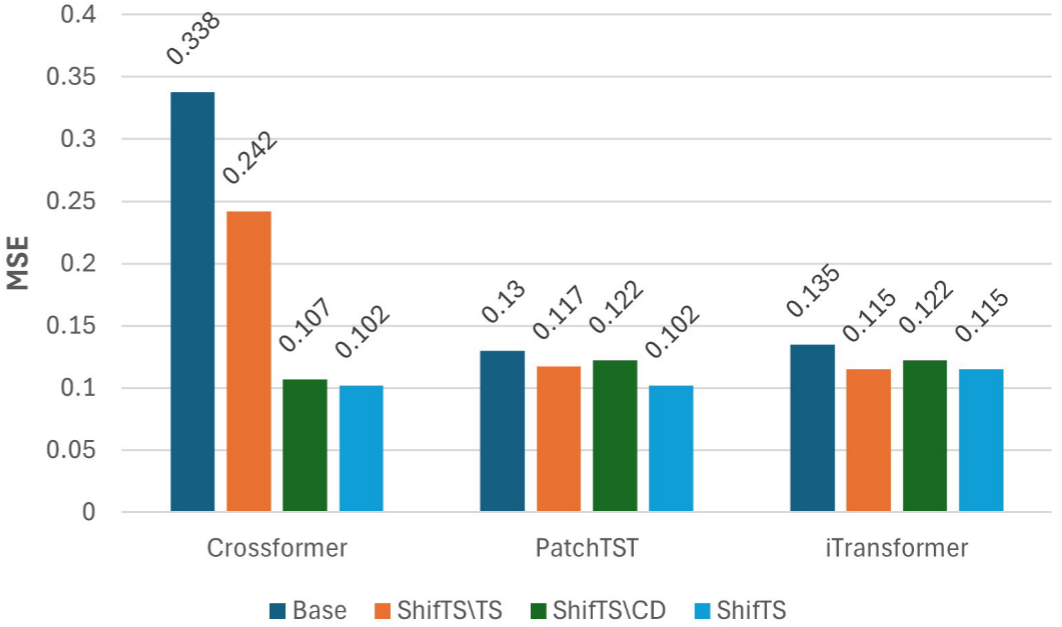
📊 【配图:Figure 3(b) - 消融实验柱状图】
对比Base / ShifTS\TS(去掉时间偏移处理)/ ShifTS\CD(去掉概念漂移处理)/ ShifTS(完整),在Exchange数据集、horizon=96下,三种backbone模型上的MSE。
以Crossformer为例,完整的ShifTS(MSE=0.102)显著优于:
- Base(MSE=0.338,无任何处理)
- ShifTS\TS(MSE=0.137,仅处理概念漂移)
- ShifTS\CD(MSE=0.133,仅处理时间偏移)
两个重要观察:
-
对本身已包含归一化处理的模型 (如PatchTST、iTransformer),追加SAM(概念漂移处理)的增益更显著;而追加RevIN的时间偏移处理增益相对较小------因为模型本身已部分处理了时间偏移。
-
对无任何归一化的模型 (如Crossformer),先处理时间偏移的增益更显著。这与论文核心论断完全吻合:时间偏移是概念漂移的前提。
5.5 ShifTS何时最有效?
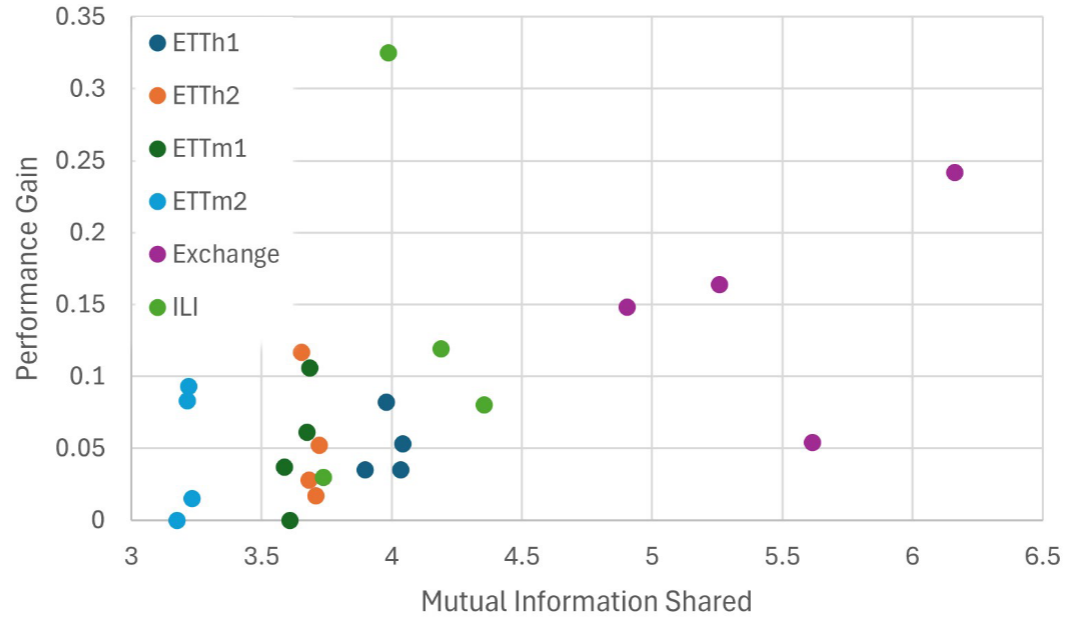
📊 【配图:Figure 3(a) - 互信息 vs 性能增益散点图】
横轴为外生特征horizon窗口 X^H 与目标 Y^H 之间的最大平均互信息 I(X^H; Y^H),纵轴为ShifTS带来的性能增益。
论文通过计算 I(X^H; Y^H)(horizon外生特征与目标之间的互信息)来量化"horizon信息的价值",发现:
- 互信息越大,ShifTS的性能增益越显著(p = 0.012,统计显著的正相关)
- ILI 和 Exchange 数据集的互信息更高,ShifTS增益最大;ETT系列互信息较低,增益相对较小
实践意义: 在使用ShifTS之前,可以先计算 I(X^H; Y^H) 来预判其效果上限,具有较强的实用指导价值。
六、局限性与未来方向
论文对自身局限性有清晰的认知:
-
缺乏理论保证:目前没有定量分析表明,处理概念漂移/时间偏移能将误差界缩紧多少。这是未来理论研究的方向。
-
SAM不是唯一解:论文定义了时序预测中的概念漂移问题,但SAM只是一种解法。其他架构或思路(如基于因果推断的方法)同样值得探索。
-
RevIN的局限:论文选择RevIN作为时间偏移处理模块,主要因其简洁有效,但更先进的方法(如SAN)作为替换可以带来额外增益------不过这超出了本文的研究范围。
七、总结
ShifTS这篇论文的价值,在于它清晰地拆解了一个被混淆的问题:时序预测中的"分布偏移"并非铁板一块,时间偏移和概念漂移是本质不同的两类问题,需要不同的工具来应对,且有明确的处理顺序(时间偏移优先)。
| 维度 | 贡献 |
|---|---|
| 问题定义 | 明确区分时序预测中的时间偏移与概念漂移 |
| 方法创新 | SAM:无需环境标签,利用horizon窗口不变模式应对概念漂移 |
| 框架设计 | ShifTS:model-agnostic,两类偏移统一处理,顺序明确 |
| 实验结论 | 在6个数据集、6个模型上一致性提升;8项对比中6项SOTA |
| 可解释性 | 互信息量化ShifTS适用性,有实践指导价值 |
对于任何在真实世界数据上部署时序预测模型的从业者,ShifTS提供了一个轻量、即插即用的增强框架,值得在实际项目中尝试。