写给机器学习入门者的保姆级教程,从概念到代码,一文讲透线性回归
一、引言:为什么要从线性回归开始?
如果你是机器学习的初学者,线性回归绝对是你应该学习的第一个算法。为什么这么说呢?
*它是机器学习的Hello World------ 就像学习编程时写的第一个程序一样,线性回归蕴含了机器学习最核心的思想:从数据中学习规律,并用这个规律进行预测。
它是所有高级算法的基石------ 无论是逻辑回归、SVM,还是深度学习,其核心思想都与线性回归一脉相承。理解了线性回归,你就掌握了机器学习的通用语言。
它在工业界应用极其广泛------ 从房价预测、销售预测到风险评估,线性回归因为简单、可解释性强,至今仍是很多实际问题的首选方案。
💡 小贴士:不要因为线性回归简单就轻视它。很多人学了一堆复杂算法,遇到实际问题时,才发现线性回归往往是最好用的那个!
二、核心概念:打好基础
2.1 什么是线性回归?
想象一下:你有一组房屋面积和房价的数据,想通过面积来预测房价。线性回归做的事情就是:找到一条直线,让这条直线尽可能穿过所有的数据点。
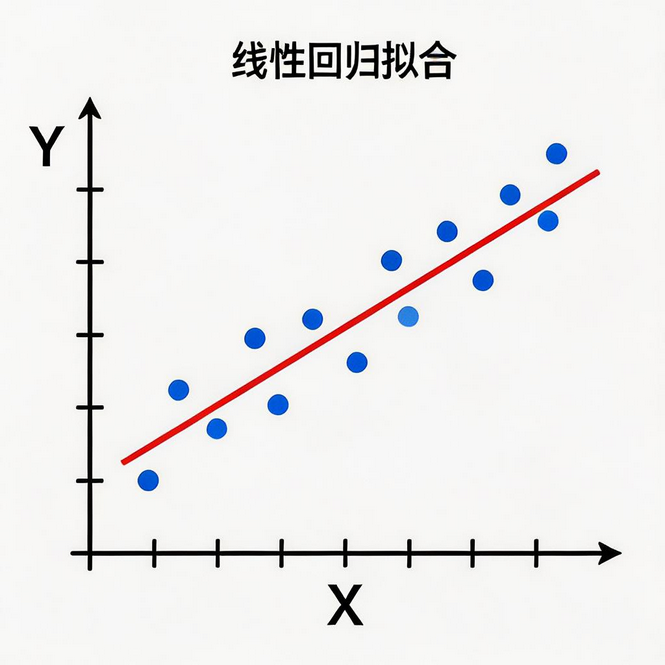
通俗地说:
-
我们假设 y(房价) 和 x(面积) 之间存在线性关系
-
目标是找到一条最合适的直线来描述这种关系
-
有了这条直线,给定新的 x(面积),我们就能预测对应的 y(房价)
💡 通俗理解:线性回归就像在散点中画直线,只不过这条直线不是凭感觉画的,而是用数学方法算出来的最优 直线。
2.2 偏置(Bias)与权重(Weight)
一条直线可以用公式表示:y = wx + b
这两个参数是什么意思呢?看下图就明白了:
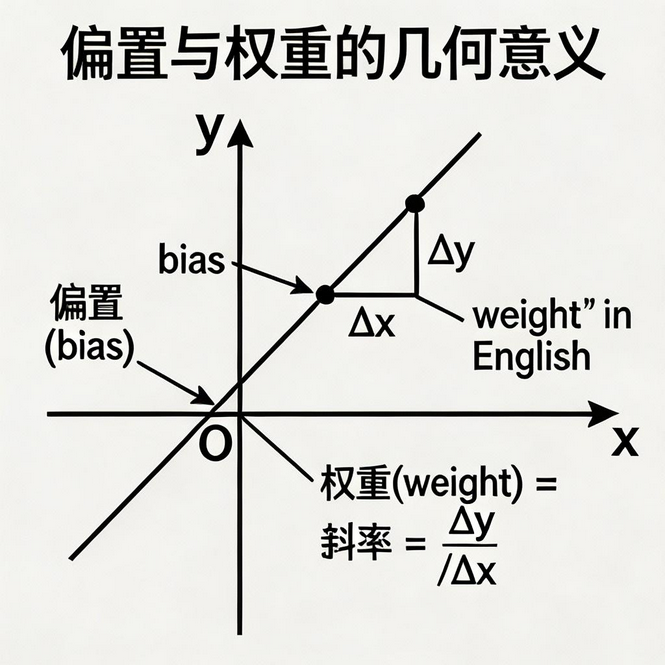
-
权重(w) :就是直线的斜率,表示 x 每增加 1 个单位,y 会增加多少。
- 比如 w=0.8,意味着面积每增加 1 平米,房价增加 0.8 万
-
偏置(b) :就是直线的截距,表示当 x=0 时,y 的取值。
- 比如 b=5,意味着即使房子面积为 0(理论上),也要 5 万(可能是地皮钱?)
💡 小贴士:可以把 w 理解为影响程度,b 理解为基准值。w 越大,x 对 y 的影响越大;b 是所有 x 都为 0 时的基础输出。
2.3 模型参数 vs 超参数
这是初学者最容易混淆的两个概念,我们用一张图和一张表讲清楚:

| 对比维度 | 模型参数(Parameters) | 超参数(Hyperparameters) |
|---|---|---|
| 是什么 | w(权重)、b(偏置) | 学习率、迭代次数、批量大小 |
| 怎么来 | 从训练数据中自动学习获得 | 训练前人为手动设定 |
| 训练中 | 不断动态更新优化 | 保持固定不变 |
| 数量 | 通常很少(线性回归只有 2 个) | 可能很多,需要调参 |
| 目标 | 让模型拟合数据 | 让模型更好地学习 |
💡 生活化类比:
模型参数 = 厨师做菜时盐、糖的用量(根据食材和口味调整)
超参数 = 厨师做菜的时间、火候大小(做菜前就定好的策略)
三、公式原理:数学其实很简单
3.1 一元线性回归公式推导
一元线性回归就是只有一个特征 x 的情况,公式:
y=wx+by = wx + by=wx+b
怎么找到最优的 w 和 b 呢? 思路很简单:
-
定义一个误差衡量标准 ------ 预测值和真实值差多少
-
找到让这个误差最小的 w 和 b
用最小二乘法可以直接推导出解析解:
w=∑i=1n(xi−xˉ)(yi−yˉ)∑i=1n(xi−xˉ)2w = \frac{\sum_{i=1}^n (x_i - \bar{x})(y_i - \bar{y})}{\sum_{i=1}^n (x_i - \bar{x})^2}w=∑i=1n(xi−xˉ)2∑i=1n(xi−xˉ)(yi−yˉ)
b=yˉ−wxˉb = \bar{y} - w\bar{x}b=yˉ−wxˉ
其中xˉ\bar{x}xˉ和yˉ\bar{y}yˉ分别是 x 和 y 的平均值。
💡 通俗理解:你不需要记住这个公式!因为实际工作中我们都是用代码计算的。理解找误差最小的参数这个思想就够了。
3.2 多元线性回归公式
当有多个特征时(比如预测房价不仅考虑面积,还要考虑房间数、楼层、地段),就变成了多元线性回归:
y=w1x1+w2x2+...+wnxn+by = w_1x_1 + w_2x_2 + ... + w_nx_n + by=w1x1+w2x2+...+wnxn+b
写成矩阵形式更简洁:
Y=WTX+bY = W^TX + bY=WTX+b
每个特征xix_ixi都有对应的权重wiw_iwi,表示这个特征对预测结果的贡献程度
3.3 损失函数(Loss Function)详解
损失函数是机器学习的核心概念!它是用来衡量模型预测得有多差的函数。
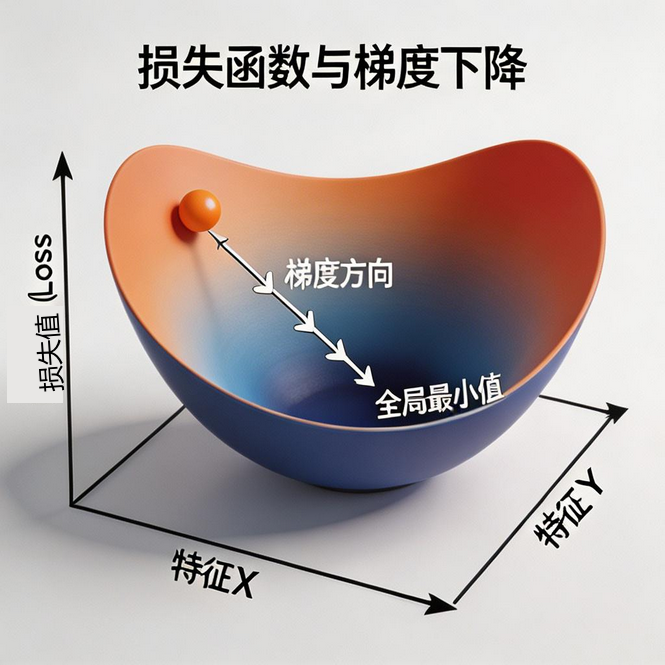
线性回归最常用的损失函数是均方误差(MSE):
J(w,b)=1m∑i=1m(h(xi)−yi)2J(w,b) = \frac{1}{m}\sum_{i=1}^m (h(x_i) - y_i)^2J(w,b)=m1∑i=1m(h(xi)−yi)2
其中:
-
h(xi)h(x_i)h(xi)是模型的预测值
-
yiy_iyi是真实值
-
m 是样本数量
💡 通俗理解:
损失函数 = 模型的考试分数
分数越高(损失越大),模型越差
我们的目标:通过调整 w 和 b,让这个考试分数尽可能低(损失最小)
四、优化方法:梯度下降
找到了衡量模型好坏的损失函数,接下来就是怎么找到让损失最小的参数。这就是梯度下降的工作。
4.1 梯度下降的核心思想
梯度下降的原理超级简单,看下图就懂了:
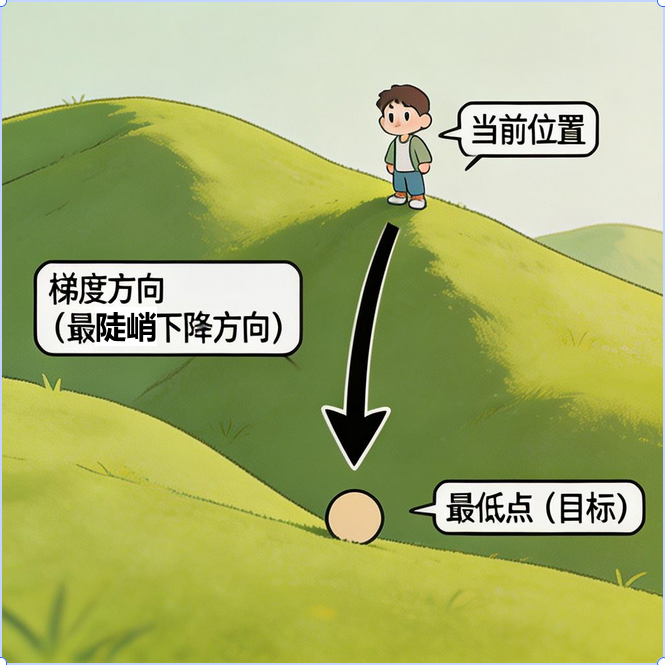
想象你站在山坡上,想要最快到达山谷最低点:
-
找到当前位置最陡峭的下坡方向(梯度的反方向)
-
朝着这个方向走一小步
-
到达新位置后,重复步骤 1-2,直到到达最低点
用数学公式表示参数更新:
θi+1=θi−α∂∂θi∂J(θ)θ_{i+1}= θ_{i}- \alpha \frac{\partial}{\partial θ_{i}}\partial J(θ)θi+1=θi−α∂θi∂∂J(θ)
- α: 学习率(步长) 不能太大, 也不能太小. 机器学习中:0.001 ~ 0.01
- 梯度是上升最快的方向, 我们需要是下降最快的方向, 所以需要加负号
可以记作:新参数=旧参数-学习率×梯度
💡 小贴士:
学习率太大:步子迈太大,可能跨过最低点,甚至越走越高
学习率太小:步子太小,走得太慢,需要很久才能到达
选择合适的学习率是调参的第一步!
4.2 三种梯度下降方法详解
梯度下降有三种主要变体,区别在于每次更新参数时使用多少数据:
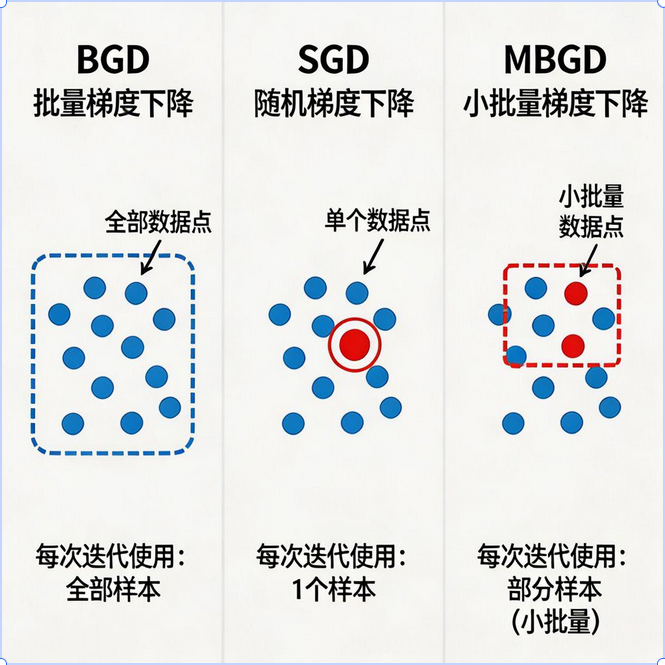
批量梯度下降(BGD - Batch Gradient Descent)
-
做法 :每次更新使用全部m 个样本
-
优点:收敛稳定,能找到全局最优
-
缺点:数据量大时非常慢,每次迭代要遍历所有数据
随机梯度下降(SGD - Stochastic Gradient Descent)
-
做法 :每次更新只使用1 个样本
-
优点:速度极快,适合大数据
-
缺点:收敛不稳定,波动大,容易陷入局部最优
小批量梯度下降(MBGD - Mini-Batch Gradient Descent)
-
做法 :每次更新使用一小批样本(如 32、64、128 个)
-
优点:兼顾速度和稳定性,是深度学习的标准做法
-
缺点:需要选择合适的批量大小(batch size)
4.3 三种梯度下降对比表
| 对比维度 | BGD 批量梯度下降 | SGD 随机梯度下降 | MBGD 小批量梯度下降 |
|---|---|---|---|
| 每次使用数据量 | 全部样本 | 1 个样本 | 一小批样本(32-128) |
| 收敛速度 | 慢 | 快 | 中等偏快 |
| 收敛稳定性 | 稳定,平滑下降 | 波动大,不稳定 | 相对稳定 |
| 内存需求 | 大(需存全部数据) | 小(只需 1 个样本) | 中等 |
| 能否跳出局部最优 | 不能 | 有机会跳出 | 有一定机会 |
| 适合场景 | 小数据集 | 超大数据集、在线学习 | 绝大多数场景 |
| 工业界使用频率 | ★☆☆☆☆ | ★★★☆☆ | ★★★★★ |
💡 生活化类比:
BGD = 考完所有题目再检查一遍,然后修改答案
SGD = 每做一道题就检查并修改答案
MBGD = 每做10 道题就检查修改一次
五、评估指标:模型好不好,怎么衡量?
训练完模型,怎么知道它好不好?这就需要评估指标。
5.1 MAE(平均绝对误差)
MAE=1m∑i=1m∣h(xi)−yi∣MAE = \frac{1}{m}\sum_{i=1}^m |h(x_i) - y_i|MAE=m1∑i=1m∣h(xi)−yi∣
-
含义 :预测值和真实值之间绝对误差的平均值
-
特点:对异常值不敏感,误差单位和原数据一致
5.2 MSE(均方误差)
MSE=1m∑i=1m(h(xi)−yi)2MSE = \frac{1}{m}\sum_{i=1}^m (h(x_i) - y_i)^2MSE=m1∑i=1m(h(xi)−yi)2
-
含义 :预测值和真实值之间误差平方的平均值
-
特点:对大误差惩罚更重(因为平方了),是最常用的损失函数
5.3 RMSE(均方根误差)
RMSE=1m∑i=1m(h(xi)−yi)2RMSE = \sqrt{\frac{1}{m}\sum_{i=1}^m (h(x_i) - y_i)^2}RMSE=m1∑i=1m(h(xi)−yi)2
-
含义:MSE 开平方
-
特点:单位和原数据一致,更容易解释
5.4 R²(决定系数)
R2=1−∑i=1m(h(xi)−yi)2∑i=1m(yˉ−yi)2R^2 = 1 - \frac{\sum_{i=1}^m (h(x_i) - y_i)^2}{\sum_{i=1}^m (\bar{y} - y_i)^2}R2=1−∑i=1m(yˉ−yi)2∑i=1m(h(xi)−yi)2
-
含义:模型能解释的数据变异比例
-
取值范围:0~1,越接近 1 说明模型越好
-
特点:不受数据量纲影响,是最通用的评估指标
💡 通俗理解:R²=0.8 意味着你的模型解释了数据中的变化规律,剩下 20% 是随机噪声或其他未考虑的因素。
5.5 MAE、MSE、RMSE 几何意义与对比
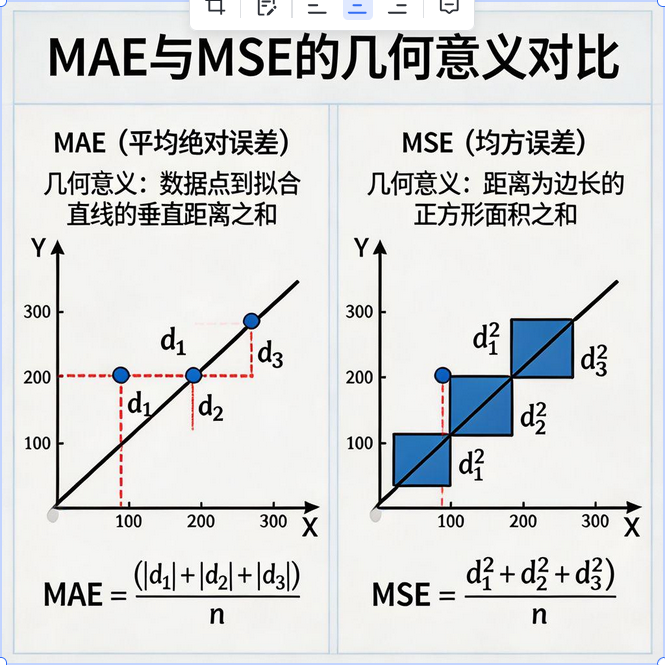
| 对比维度 | MAE 平均绝对误差 | MSE 均方误差 | RMSE 均方根误差 |
|---|---|---|---|
| 异常值敏感度 | 不敏感 | 非常敏感 | 敏感 |
| 是否可导 | 0 点不可导 | 处处可导 | 处处可导 |
| 单位一致性 | 是 | 否(平方单位) | 是 |
| 作为损失函数 | 较少使用 | 最常用 | 较少直接使用 |
| 解释难度 | 容易 | 较难 | 容易 |
| 数学性质 | L1 损失 | L2 损失 | L2 损失开方 |
💡 选择建议:
如果数据有很多异常值 → 用 MAE
否则 → 优先用 MSE(因为可导,方便优化)
给业务方解释时 → 用 RMSE(单位一致,好理解)
六、实战案例:Python 实现线性回归
理论讲了这么多,我们来动手写代码!
6.1 数据集介绍
我们使用经典的波士顿房价数据集(简化版),目标是根据房屋的平均房间数(RM)预测房价(MEDV)。
6.2 完整代码实现
6.2.1 导包
python
from sklearn.datasets import load_boston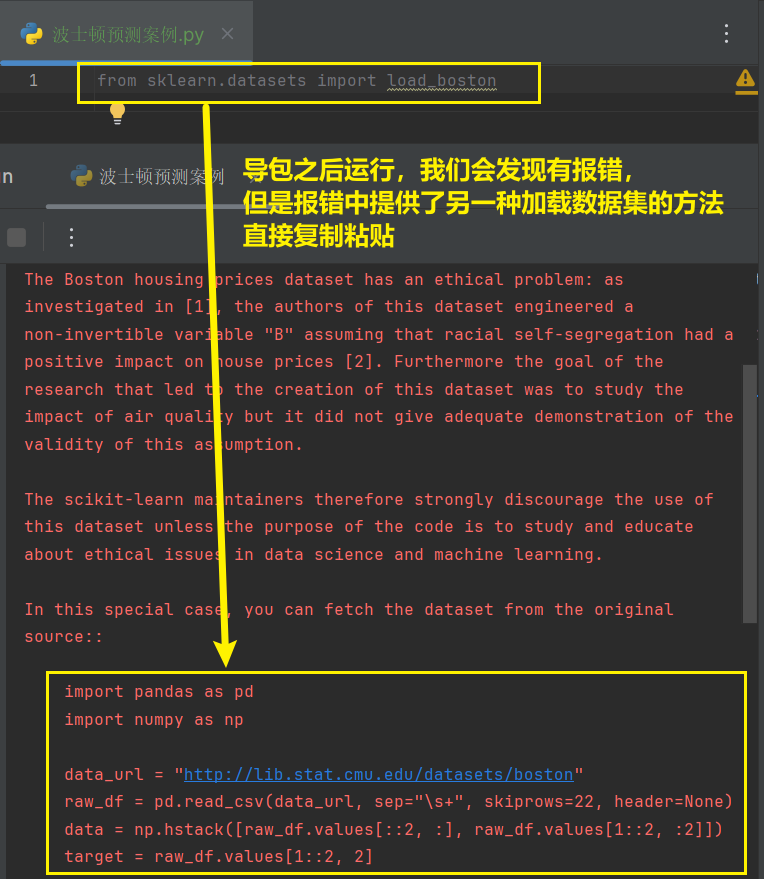
python
# 导包
import pandas as pd
import numpy as np
# 1. 加载数据集
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
print('特征:', data)
print('标签:', target)6.2.2 完整代码
python
# 导包
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import SGDRegressor
from sklearn.metrics import mean_absolute_error, mean_squared_error
# 1. 加载数据集
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
# 2. 数据预处理
X_train, X_test, y_train, y_test = train_test_split(
data, target, test_size=0.2, random_state=22
)
# 3. 特征标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 4. 模型定义(修复:固定随机种子 + 更稳定的学习率)
model = SGDRegressor(
learning_rate='adaptive', # 比 constant 稳定得多
eta0=0.01,
max_iter=1000,
fit_intercept=True,
random_state=22 # 固定随机种子,结果可复现
)
# 5. 训练
model.fit(X_train_scaled, y_train)
# 6. 预测与评估
y_predict = model.predict(X_test_scaled)
print("平均绝对误差(MAE):", mean_absolute_error(y_test, y_predict))
print("均方误差(MSE):", mean_squared_error(y_test, y_predict))
print("均方根误差(RMSE):", np.sqrt(mean_squared_error(y_test, y_predict))) # 兼容所有版本
print("模型 R² 得分:", model.score(X_test_scaled, y_test))
# 7. 查看线性模型参数
print("\n模型权重:", model.coef_)
print("模型偏置:", model.intercept_)6.3 代码运行结果解读
运行上面的代码,你会看到类似这样的输出:
Plain
平均绝对误差(MAE): 3.427011018302896
均方误差(MSE): 20.771560976635854
均方根误差(RMSE): 4.557582799756451
模型 R² 得分: 0.7657367125931608
模型权重: [-0.72174268 1.11428434 -0.16749907 0.85837 -2.04398397 2.73363592
-0.1398481 -3.34552084 2.5318206 -1.62193834 -1.68645247 0.91303225
-3.78898053]
模型偏置: [22.57301691]七、总结与扩展学习建议
7.1 核心知识点回顾
让我们用一张思维导图回顾一下线性回归的全貌:
-
核心思想:用直线拟合数据,做预测
-
模型参数:w(权重 / 斜率)、b(偏置 / 截距)
-
优化目标:最小化损失函数(MSE)
-
优化方法:梯度下降(BGD/SGD/MBGD)
-
评估指标:MAE、MSE、RMSE、R²
7.2 常见面试题总结
-
Q:线性回归有哪些假设?
A:线性关系、误差正态分布、同方差性、无多重共线性、误差独立
-
Q:为什么 MSE 对异常值敏感?
A:因为平方操作会放大误差,一个远离群点的样本会主导损失值
-
Q:什么时候用梯度下降而不是最小二乘法?
A:数据量大时(最小二乘法需要矩阵求逆,O (n³) 复杂度)
7.3 下一步学习建议
如果你已经掌握了线性回归,建议按以下路径继续学习:
-
立即进阶:逻辑回归(分类问题的基础)
-
深入理解:正则化(L1/L2)解决过拟合问题
-
工程实践:特征工程、交叉验证、调参技巧
-
高级算法:决策树、随机森林、SVM
📚 推荐学习资源:
Andrew Ng 机器学习课程(经典中的经典)
《统计学习方法》李航(理论扎实)
Scikit-learn 官方文档(动手实践)
写在最后
线性回归虽然简单,但它蕴含了机器学习最核心的思想:定义目标 → 优化目标 → 评估效果。这个范式适用于几乎所有的机器学习算法。
记住:简单的算法不一定差,复杂的算法不一定好。在实际工作中,先从简单的模型开始,往往是最明智的选择。
祝你在机器学习的道路上越走越远!🚀
如果这篇教程对你有帮助,欢迎分享给更多正在学习机器学习的朋友!