Spark任务调度的核心逻辑,在于利用有向无环图(DAG)来优化并行计算。整个流程始于用户代码构建的RDD依赖图,DAGScheduler会依据宽依赖(Shuffle)将图切分为多个Stage,窄依赖则被合并以实现流水线计算。随后,TaskScheduler将这些Stage转化为具体的任务集,并分发给Worker节点的Executor执行。这种"逻辑划分"与"物理执行"解耦的机制,通过隔离昂贵的Shuffle操作,极大地提升了分布式计算的效率与容错能力。
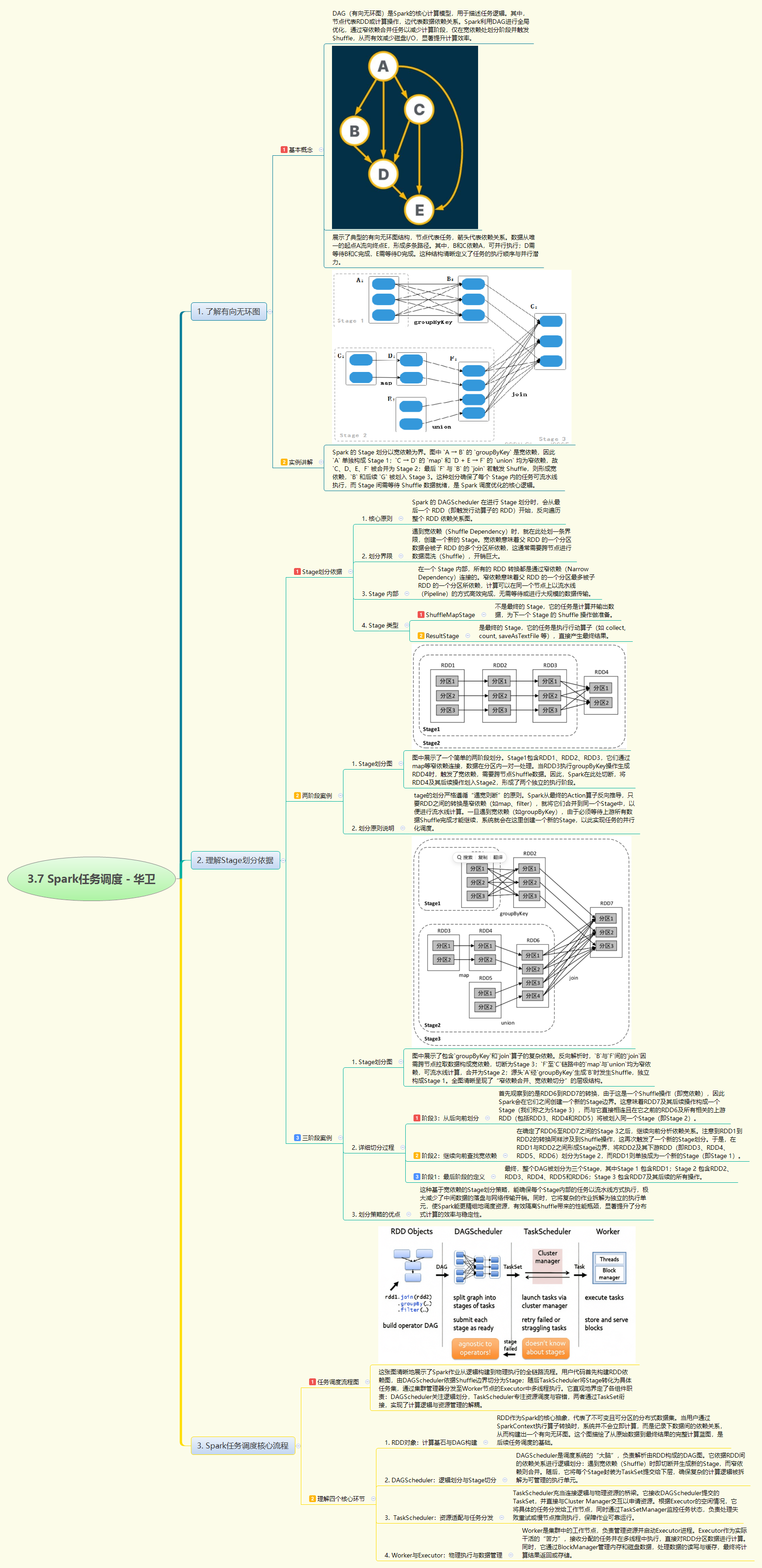
Spark任务调度的核心逻辑,在于利用有向无环图(DAG)来优化并行计算。整个流程始于用户代码构建的RDD依赖图,DAGScheduler会依据宽依赖(Shuffle)将图切分为多个Stage,窄依赖则被合并以实现流水线计算。随后,TaskScheduler将这些Stage转化为具体的任务集,并分发给Worker节点的Executor执行。这种"逻辑划分"与"物理执行"解耦的机制,通过隔离昂贵的Shuffle操作,极大地提升了分布式计算的效率与容错能力。