在海量业务数据场景中(如电商订单统计、日志数据分析、用户行为监控),快速完成求和、平均值、最大值、最小值、去重计数、百分位 等数值统计是核心需求。Elasticsearch(简称 ES)提供的指标聚合(Metrics Aggregations) 功能,无需复杂的 SQL 计算,就能对海量数据实现毫秒级数值统计,是大数据实时分析的核心能力。
本文将全面讲解 ES 指标聚合的核心概念、常用语法、实战场景与最佳实践,帮助你快速掌握 ES 数值统计的核心用法,适配生产环境的实时数据统计需求。
metric指标聚合
为了便于大家得理解和查看,为大家展示了一下我得示例得数据,大家可以直接copy一下:
# 创建订单索引(设置字段类型,保证数值聚合正常执行)
PUT order_index
{
"settings": {
"number_of_replicas": 0
},
"mappings": {
"properties": {
"order_id": { "type": "keyword" },
"price": { "type": "double" }, // 数值型,支持聚合计算
"pay_num": { "type": "integer" },
"order_time": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss" },
"category": { "type": "keyword" }
}
}
}
# 批量插入测试数据
POST order_index/_bulk?refresh=true
{"index":{"_id":1}}
{"order_id":"ORDER_001","price":99.8,"pay_num":1,"order_time":"2025-01-01 10:00:00","category":"数码"}
{"index":{"_id":2}}
{"order_id":"ORDER_002","price":199.5,"pay_num":2,"order_time":"2025-01-01 11:00:00","category":"服饰"}
{"index":{"_id":3}}
{"order_id":"ORDER_003","price":299.0,"pay_num":1,"order_time":"2025-01-01 14:00:00","category":"数码"}
{"index":{"_id":4}}
{"order_id":"ORDER_004","price":88.6,"pay_num":1,"order_time":"2025-01-02 09:00:00","category":"食品"}案例展示
#获取价格中的stats
GET order_index/_search
{
"_source":false,
"aggs": {
"test_type": {
"stats": {
"field": "price"
}
}
}
}指标聚合函数
一、基础数值统计聚合(最常用)
核心:对数值字段做简单统计,你提到的
sum/max/min/avg都在这一类
表格
| 聚合函数 | 中文名称 | 核心作用 | 适用场景 |
|---|---|---|---|
| sum | 求和聚合 | 计算字段所有值的总和 | 统计订单总金额、访问总次数、流量总量 |
| max | 最大值聚合 | 获取字段的最大值 | 查找最高温度、最大订单金额、最长响应时间 |
| min | 最小值聚合 | 获取字段的最小值 | 查找最低价格、最小库存、最短耗时 |
| avg | 平均值聚合 | 计算字段所有值的平均值 | 统计平均响应时间、平均客单价、平均评分 |
| value_count | 计数聚合 | 统计字段非空值的数量 | 统计有效数据条数、参与评分的用户数 |
二、高级数值统计聚合
核心:进阶统计,补充基础统计的不足,生产高频使用
表格
| 聚合函数 | 中文名称 | 核心作用 | 适用场景 |
|---|---|---|---|
| stats | 通用统计聚合 | 一次性返回 sum/max/min/avg/value_count | 需要同时获取多个基础统计值时 |
| extended_stats | 扩展统计聚合 | 在 stats 基础上,增加方差、标准差、平方和等 | 数据分析、异常检测、数据分布统计 |
| cardinality | 基数聚合 | 统计字段去重后的值数量 | 统计独立 IP 数、独立用户数、独立商品数 |
三、百分位 / 分位数聚合(数据分析专用)
核心:用于数据分布、性能监控、阈值分析
| 聚合函数 | 中文名称 | 核心作用 | 适用场景 |
|---|---|---|---|
| percentiles | 百分位聚合 | 计算指定百分位的值(如 P50/P90/P99) | 接口响应耗时分析(P99 耗时)、数据分布 |
| percentile_ranks | 百分位排名聚合 | 计算某个值在数据中的百分位排名 | 判断某个数值处于整体数据的什么水平 |
percentiles 案例讲解:
GET page_study_index/_search
{
"size":0,
"aggs": {
"agg_type_price": {
"percentiles": {
"field": "number",
"percents": [
0,
1,
5,
25,
50,
75,
95,
99,
100
]
}
}
}
}结果演示:
"aggregations" : {
"agg_type_price" : {
"values" : {
"0.0" : 10,
"1.0" : 15,
"5.0" : 20,
"25.0" : 50,
"50.0" : 100,
"75.0" : 150,
"95.0" : 200,
"99.0" : 220,
"100.0": 250
}
}
}这个结果可以这样理解:
"0.0" : 10: 表示number字段的最小值是 10。"50.0" : 100: 表示有 50% 的数据,其number字段的值小于或等于 100。这也就是我们常说的中位数。"95.0" : 200: 表示有 95% 的数据,其number字段的值小于或等于 200。"100.0": 250: 表示number字段的最大值是 250。
TDigest 的compression参数:
GET page_study_index/_search
{
"size":0,
"aggs": {
"agg_type_price": {
"percentiles": {
"field": "number",
"percents": [
50,
75,
95,
99,
100
],
"tdigest":{
"compression":1000000
}
}
}
}
}Digest 算法之所以能处理海量数据而不撑爆内存,是因为它不把每一个原始数据都存下来,而是把数据"压缩"成一个个小团体。
compression 参数直接决定了 TDigest 算法最多可以保留多少个"质心"。
- 公式(估算) :最大质心数量 ≈
20 * compression。 - 直观理解 :
compression值越大 ➔ 允许保留的质心越多 ➔ 数据压缩得越少 ➔ 精度越高 ,但内存占用越大。compression值越小 ➔ 允许保留的质心越少 ➔ 数据被强行合并 ➔ 精度越低 ,但内存占用越小。
四、地理指标聚合(地理数据专用)
核心:针对经纬度地理坐标字段
| 聚合函数 | 中文名称 | 核心作用 | 适用场景 |
|---|---|---|---|
| geo_centroid | 地理质心聚合 | 计算一组地理坐标的中心点 | 统计用户分布中心、门店覆盖中心 |
| geo_bounds | 地理边界聚合 | 计算坐标的最小 / 最大经纬度边界 | 绘制地理区域范围、地图展示边界 |
五、脚本 / 自定义值聚合
核心:基于脚本动态计算值,灵活适配复杂场景
| 聚合函数 | 中文名称 | 核心作用 | 适用场景 |
|---|---|---|---|
| scripted_metric | 脚本指标聚合 | 自定义脚本实现复杂聚合 |
直接在函数中使用脚本:
GET page_study_index/_search
{
"aggs": {
"trest": {
"avg": {
"script": {
"source": """
//使用脚本将下面的number数据放大10倍
doc['number'].value*10
"""
}
}
}
}
}六、string_stats
是 Elasticsearch 中专门用于对字符串类型字段进行统计分析的聚合方式。
string_stats 是 Elasticsearch 中专门用于对字符串类型字段进行统计分析的聚合方式。
与 percentiles 或 stats 等用于数值计算的聚合不同,string_stats 关注的是字符串本身的特征,比如长度和内容的多样性。
📊 它能提供哪些统计指标?
对一个字段使用 string_stats 后,你会得到以下几个核心指标:
count: 包含非空字符串的文档数量。min_length: 所有字符串中的最短长度。max_length: 所有字符串中的最长长度。avg_length: 所有字符串的平均长度。entropy: 信息熵。这是一个衡量字符串内容复杂度的指标,可以量化数据的多样性、相似性或随机性。熵值越高,说明字符串包含的字符种类越丰富,分布越均匀。
七:top_hits子聚合:
top_hits 和普通的查询不一样,它不是一个独立的聚合,而是一个指标聚合 。这意味着它必须依附于一个桶聚合 (比如 terms、range 等)才能工作。
这个在之后的桶聚合中还会讲解,但是因为他是属于指标聚合的,所以大家还是要理解他
下面的例子是,先使用桶聚合按着星期几进行分桶,之后返会每个桶中最相关的数据
GET kibana_sample_data_ecommerce/_search
{
"size":0,
"aggs": {
"test": {
"terms": {
"field": "day_of_week"
},
"aggs":{
"top_Test":{
"top_hits": {
"size": 1
}
}
}
}
}
}指数聚合常见属性:
missing 参数 核心说明
| 参数 | 取值示例 | 含义 |
|---|---|---|
| missing | 数值 / 字符串 | 文档无该字段、字段为 null时,用设定的值替代,参与聚合计算;不设置则直接忽略该文档 |
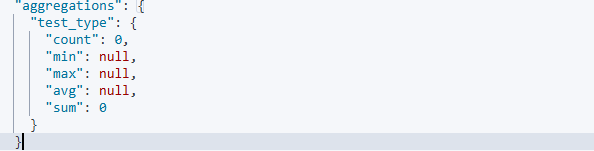
使用参数效果展示:

没使用函数效果展示:
format临时解决数据精度问题:
在实际开发中我们可能只是需要在小数点之后保留两位小数,这是我们在进行数据统计的时候可以使用format进行一下格式化,保证保留两位小数。
GET kibana_sample_data_ecommerce/_search
{
"size":0,
"_source":true,
"query": {
"bool": {
"must": [
{
"match": {
"day_of_week": "Monday"
}
}
]
}
},
"aggs": {
"min_price_agg": {
"stats": {
"field": "products.min_price",
"missing": 0,
"format": "#.00"
}
}
}
}但是上面的方式只是解决这个问题的临时方案,最好的方案还是在创建mapping是指定的数据类型:
"mappings": {
"properties": {
"products.min_price": {
"type": "scaled_float",
"scaling_factor": 100
}
}
}实际上我们的数据是11.11,但是es会存成1111,这就解决了精度问题,但是我们在使用json进行展示的时候还是可能出现尾巴的问题,但是这个时候你加上 "format": "#.00"就可以解决问题了。