前言
在日常软件测试学习与项目实操中,Web UI 自动化测试是功能测试进阶的核心内容。传统手写自动化脚本存在重复代码多、用例设计繁琐、元素定位易报错、用例依赖难处理、报告搭建复杂 等痛点。本次实战依托 Trae AI 全程辅助开发,完整完成:多页面测试用例设计、Selenium+Pytest 自动化脚本生成、元素定位修复、参数化优化、用例依赖处理、全局 fixture 结构重构、标准化项目框架搭建、Allure 可视化测试报告输出全流程。
一、项目整体介绍
1. 测试对象
博客系统,包含四大核心页面:
-
登录页面:系统入口,校验账号密码、导航跳转、页面元素展示
-
博客列表页:登录后首页,展示个人信息、导航栏、博客条目、全文跳转
-
博客详情页:展示单篇博客完整内容,携带 blogId 路径参数
-
博客编辑页:实现博客新增、编辑发布功能
- 核心技术栈
-
编程语言:Python
-
自动化工具:Selenium
-
测试框架:Pytest
-
数据驱动:YAML
-
执行顺序:pytest-order
-
日志管理:分级日志、按天分割
-
测试报告:Pytest 简易报告 + Allure 可视化报告
-
整体实操流程
-
单页面独立设计 UI 测试用例(登录→列表→详情→编辑)
-
依据用例 + 页面 HTML 源码,AI 生成自动化测试脚本
-
解决元素找不到、登录态失效、用例执行失败等问题
-
参数化优化、用例依赖优化、全局代码结构重构
-
搭建标准化分层项目目录结构
-
批量生成全页面自动化脚本
-
测试报告生成
二、登录页面自动化实现
2.1 登录页测试用例生成
给到 Trae AI 的提示词:
@【截图】博客系统登录页面
根据图片提供的登陆界面设计UI自动化测试用例,页面包含标题、导航栏和登陆表单模块要求:
1)用例包含登陆功能(正常、异常)、导航栏的跳转、标题的验证
2)按照优先级设计用例数量在10以内
3)输出格式:用例名称、操作步骤,预期结果。内容具体,避免模糊的描述方式
4)将输出内容保存至"登录页面测试用例.md"文件中
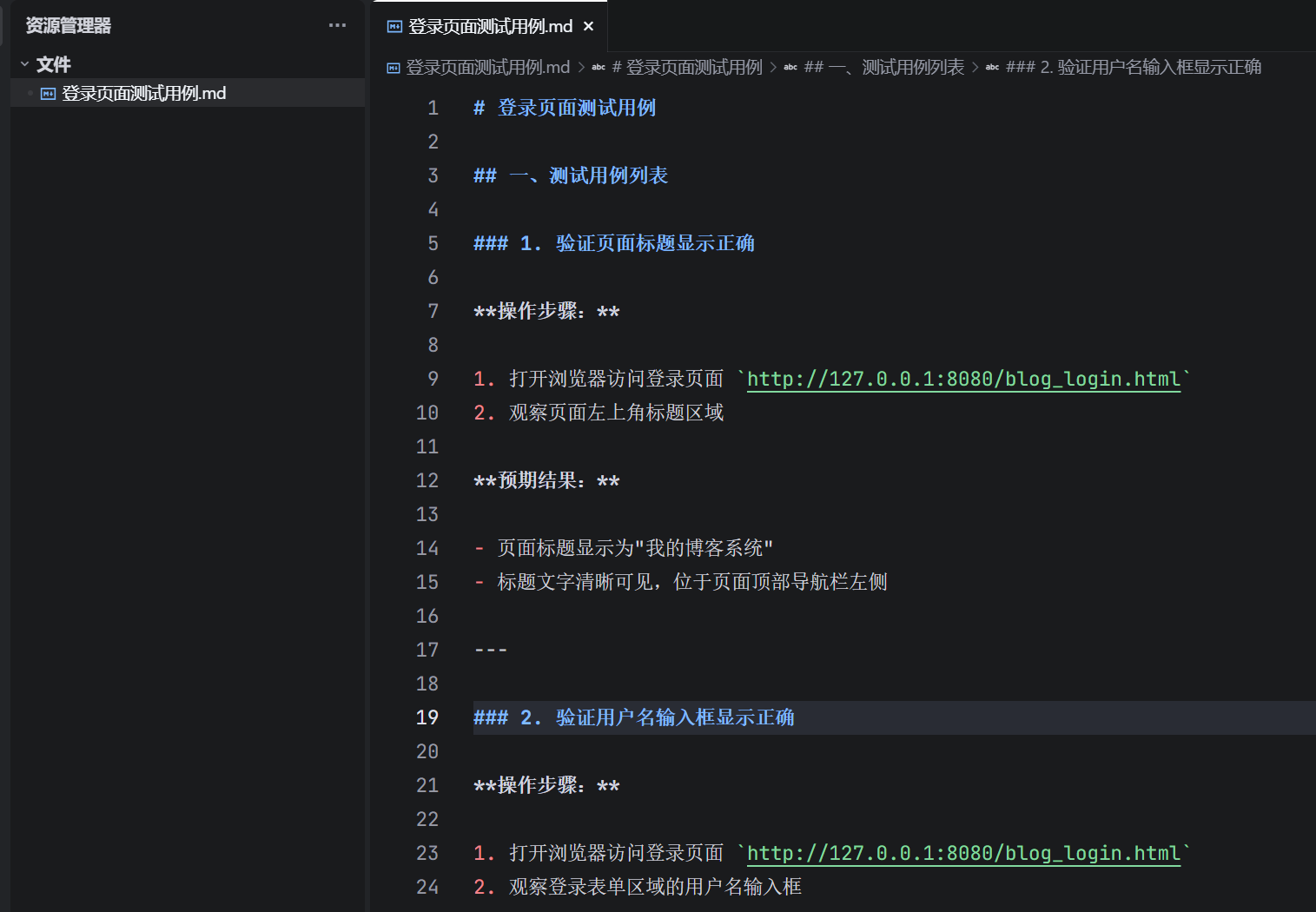
AI 根据页面模块,自动区分高优先级核心用例与次要展示用例,覆盖正常登录、错误账号、错误密码、空输入、页面标题校验、导航跳转等场景,用例格式规范、步骤可落地,AI生成测试用例后还需人工进行校验。
部分结果展示:
2.2 登录页自动化测试脚本生成
拿到标准化用例文档后,基于用例批量生成可执行代码。
给到 Trae AI 的提示词:
@登录页面测试用例.md
读取登录页面测试用例.md文档内容并生成测试脚本,要求:
1)使用Python+selenium实现自动化脚本编写
2)用例遵循pytest框架运行规则
3)测试方法命名要合理
4)每个测试用例都要对结果进行断言
5)不使用复杂设计模式
6)完全遵循以上要求,不要做额外拓展
AI 自动完成:
-
导入 selenium 依赖、浏览器驱动配置
-
每条用例对应独立测试方法
-
方法命名规范(test_xxx 格式)
-
关键节点添加断言,保障用例有效性
-
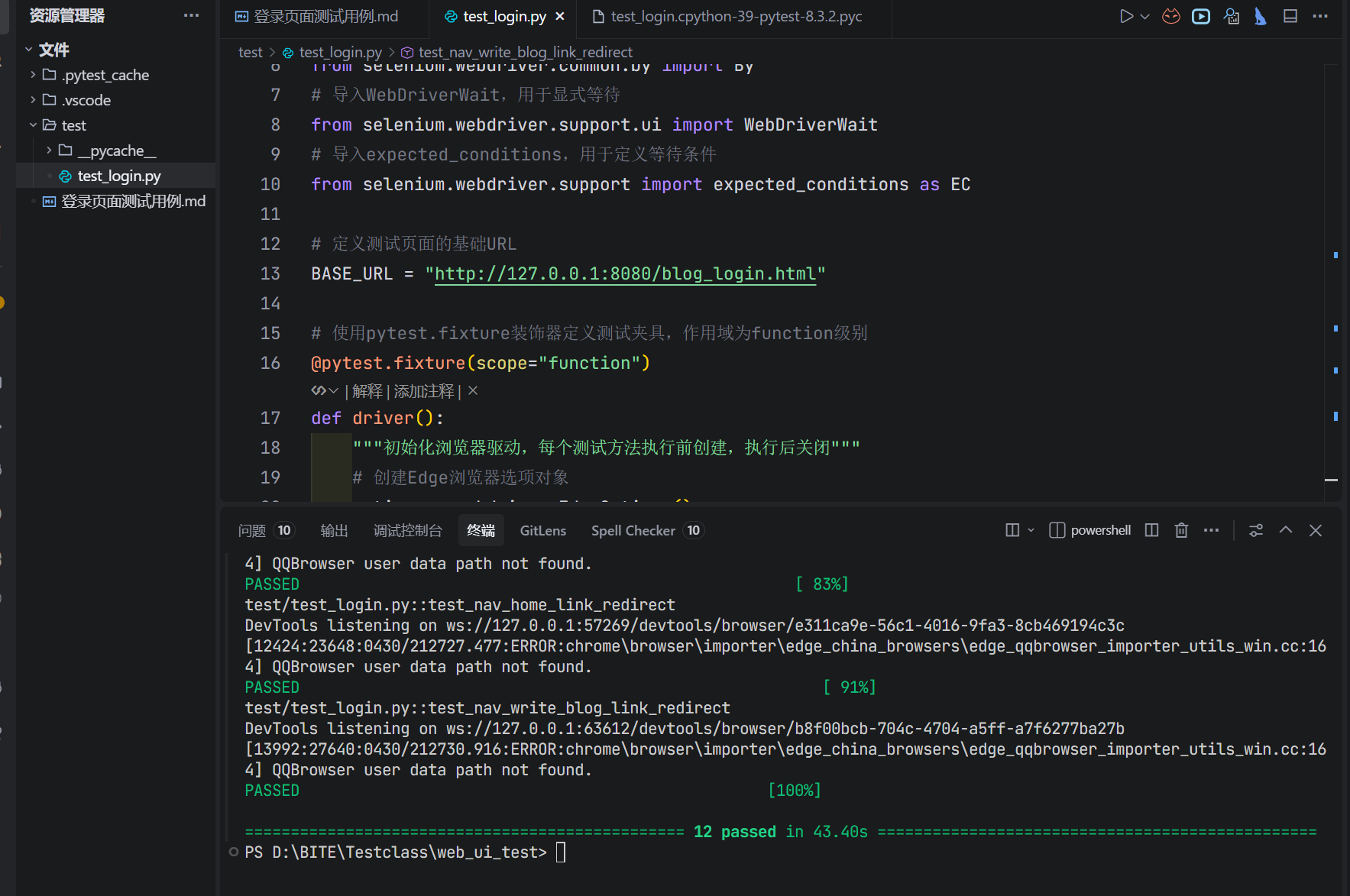
输出完整代码 + 脚本运行结果预览
(AI给出的代码并不是百分百能运行通过,还需人工介入检查代码报错原因,再进一步指导AI修改报错直至代码能够完全运行通过)
部分结果展示:
2.3 元素定位报错修复
问题现象: 脚本初次运行抛出:NoSuchElementException 元素找不到异常。原因:AI 初始生成的定位方式(id、name、简单 xpath)和本地实际页面 HTML 源码不匹配。
如果出现元素定位相关的报错"NoSuchElementException"提供页面对应的html源数据给AI,让AI自动获取元素的定位方式。
给到 Trae AI 提示词:
@test_login_page.py @blog_login.html
根据页面源码blog_login.html文件,修改代码中获取对应元素的方式,避免出现页面元素查找不到的错误。
AI 读取本地 blog_login.html 源码,分析元素真实属性,批量替换 XPath、CSS 定位表达式,精准匹配页面真实节点,彻底解决元素找不到问题。
三、参数化优化,精简冗余用例
初期脚本中,多个异常登录用例(错误账号、错误密码、空账号、空密码)逻辑高度重复,代码冗余严重的情况,我们可以根据这种情况让AI再做进一步的优化。
给到 Trae AI 的提示词:
分析脚本,利用pytest中的参数化操作来减少用例数量
要求:
1)可以合并的用例放在同⼀个用例中
2)不可以合并的用例不做处理,避免强行处理降低代码可读性
AI 优化效果:
-
引入
@pytest.mark.parametrize装饰器 -
将多组异常账号密码数据整合为一组参数化用例
-
保留独立不可合并用例(标题验证、导航跳转)
-
大幅精简代码行数,降低后期维护成本
四、博客列表页用例与脚本开发
4.1 列表页测试用例设计
列表页核心模块:个人信息面板、顶部导航栏、博客列表模块、查看全文按钮。
给到 Trae AI 的提示词:
根据图片提供的列表界面设计UI自动化测试用例,页面包含个人信息(头像、GitHub地址、文章、分类)、导航栏(主页、写博客、注销)和博客列表(至少包含⼀条博客,每条博客包含标题、发布时间、博客内容、查看全文按钮)要求:
1)用例包含博客列表信息、个人信息的验证
2)按照优先级设计用例数量在10以内
3)输出格式:用例名称、操作步骤,预期结果。内容具体,避免模糊的描述方式
4)将输出内容保存至"列表页面测试用例.md"文件中
生成用例覆盖:个人信息展示校验、导航栏功能、博客列表数据展示、查看全文跳转、注销功能校验等。
4.2 列表页自动化脚本生成
给到 Trae AI 的提示词:
@列表页面测试用例.md @blog_list.html
读取列表页面测试用例.md内容和页面源码blog_list.html文件,生成列表页测试脚本,要求:
1)使用Python+selenium实现自动化脚本编写
2)用例遵循pytest框架运行规则
3)测试方法命名要合理
4)每个测试用例都要对结果进行断言
5)不使用复杂设计模式
6)完全遵循以上要求,不要做额外拓展
4.3 用例依赖导致全部用例失败
直接单独运行列表页脚本,所有用例 100% 失败:
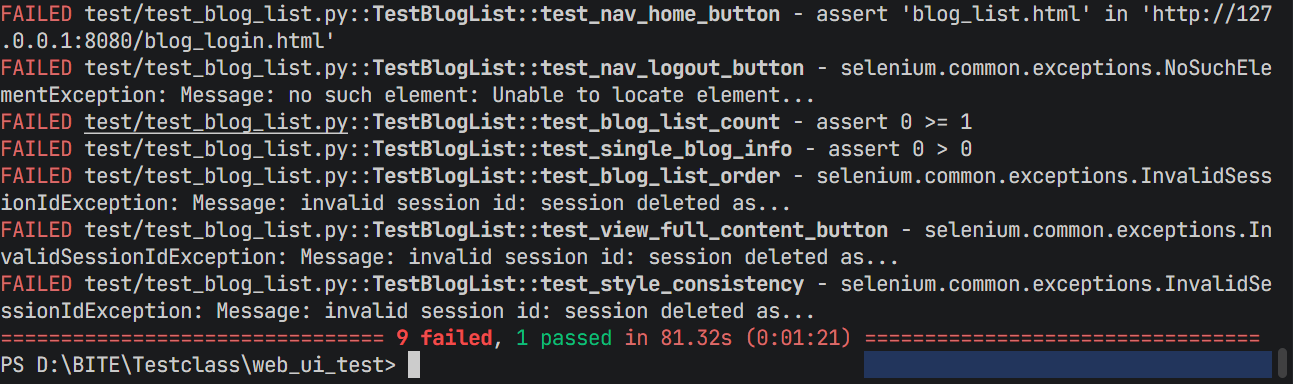
至此我们就发现了,若只执行列表页的测试用例,所有测试用例将执行失败,是因为若想成功访问列表页面,需要先执行登陆操作。因此,无法直接执行列表页测试用例,需要先执行登录页测试用例。
核心原因:
-
博客列表页必须携带登录态才可访问;
-
未登录状态直接访问列表页 URL,系统自动强制重定向到登录页面;
-
初始代码中,每条测试用例都会独立创建浏览器、关闭浏览器,登录态无法保存,会话丢失。
这也是 UI 自动化中页面级用例依赖的经典实操问题。
五、用例依赖专项优化
针对上面出现的用例依赖有关的报错,有以下两种解决方案。
5.1 方案一:pytest-order 指定执行顺序
为保证「先执行登录、再执行列表页」,使用 pytest-order 插件控制类执行顺序,通过pytest-order工具,可以指定方法或类的执行顺序。
给到 Trae AI 的提示词:
使用pytest-order插件指定类的执行顺序,顺序依次为:TestLoginPage、TestListPage
二次运行结果:
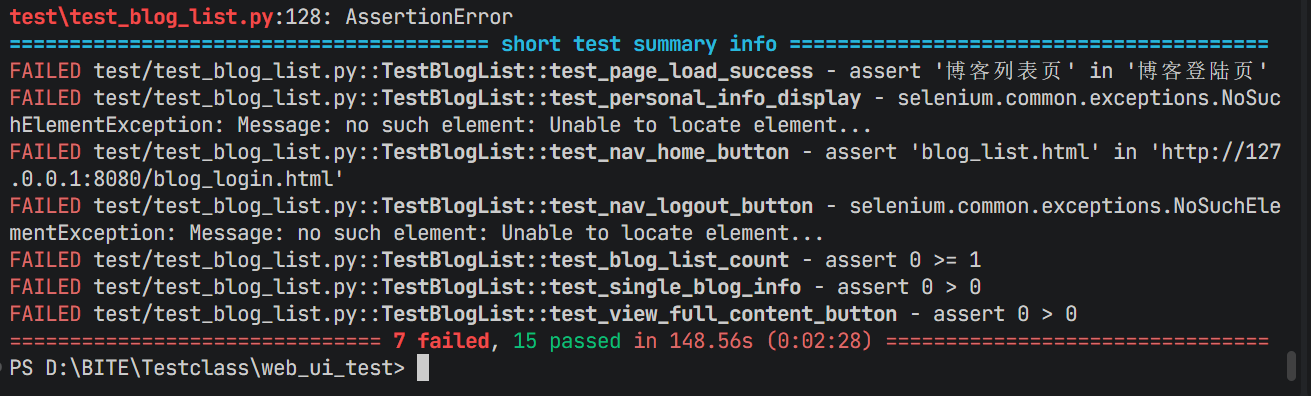
AI 自动为测试类添加顺序装饰器:
-
登录测试类:优先执行
-
列表页测试类:延后执行解决了执行顺序错乱问题,但依旧无法解决浏览器重复创建、登录态丢失的核心痛点。
5.2 方案二:conftest 全局 fixture 结构重构
问题总结
-
每条用例重复启动 / 关闭浏览器,执行效率极低;
-
浏览器会话不共享,登录 Cookie 丢失,二级页面强制跳转登录页;
-
代码高度冗余,浏览器初始化代码重复编写。
使用pytest中的conftest.py操作将类中定义的fixture标记方法管理起来,并重新修改作用域。
给到 Trae AI 的提示词:
背景:登录成功后才能访问列表页,否则会自动跳转至登录页,导致列表页测试用例全部执行失败
重新优化代码设计,要求:
1)提取测试文件中的启动和关闭浏览器操作,封装为fixture标记的方法,使得所有用例执行前启动⼀次浏览器,执行结束后关闭⼀次浏览器
2)执行列表页每个测试用例之前需要保证已经存在登录态
3)不改变每个测试用例的逻辑
4)不要做过多拓展
优化效果
-
新增全局
conftest.py配置文件; -
封装
scope="session"级别 fixture,全局唯一浏览器实例; -
整个测试套件只打开一次浏览器、最后统一关闭;
-
登录成功后会话全局保留,列表、详情、编辑页直接复用登录态;
-
原有每条用例业务逻辑完全不变,低侵入式优化。
六、全页面全覆盖自动化落地
6.1 详情页 + 编辑页测试用例设计
整合项目所有页面 HTML 源码,批量补齐剩余页面用例
给到 Trae AI 的提示词:
需求分析与用例设计
提示词:
@blog_edit.html
@blog_login.html
@blog_list.html
@blog_detail.html
根据附件提供的html文件,设计各个页面的UI自动化测试用例,为后续的编写UI自动化测试脚本做准备,要求:
1)包含功能和界⾯等方面来设计
2)按照优先级,每个页面设计用例数量在10以内
3)输出格式:按照博客系统测试用例模板.md格式输出,内容具体,避免模糊的描述方式
4)将生成的测试用例分别保存至"详情页面测试用例.md"、"编辑页面测试用例.md"中
6.2 标准化项目框架搭建
为项目搭建企业级分层目录,适配后续扩展、数据驱动、日志、报告一体化需求
给到 Trae AI 的提示词:
@博客系统页面测试用例.md
根据附件内容,帮我设计⼀套UI自动化目录结构。
技术栈要求:
编程语言:Python
测试框架:pytest
自动化测试:selenium
数据驱动:YAML
报告:Allure
logging日志记录:日志分级输出,按天分割
合理使用异常,避免使用复杂的设计模式
输出:只输出目录结构即可
AI 输出分层结构:配置层、数据层、页面元素层、测试用例层、日志层、报告层、静态资源层,结构清晰,人工检查合格之后可直接用于正式项目。
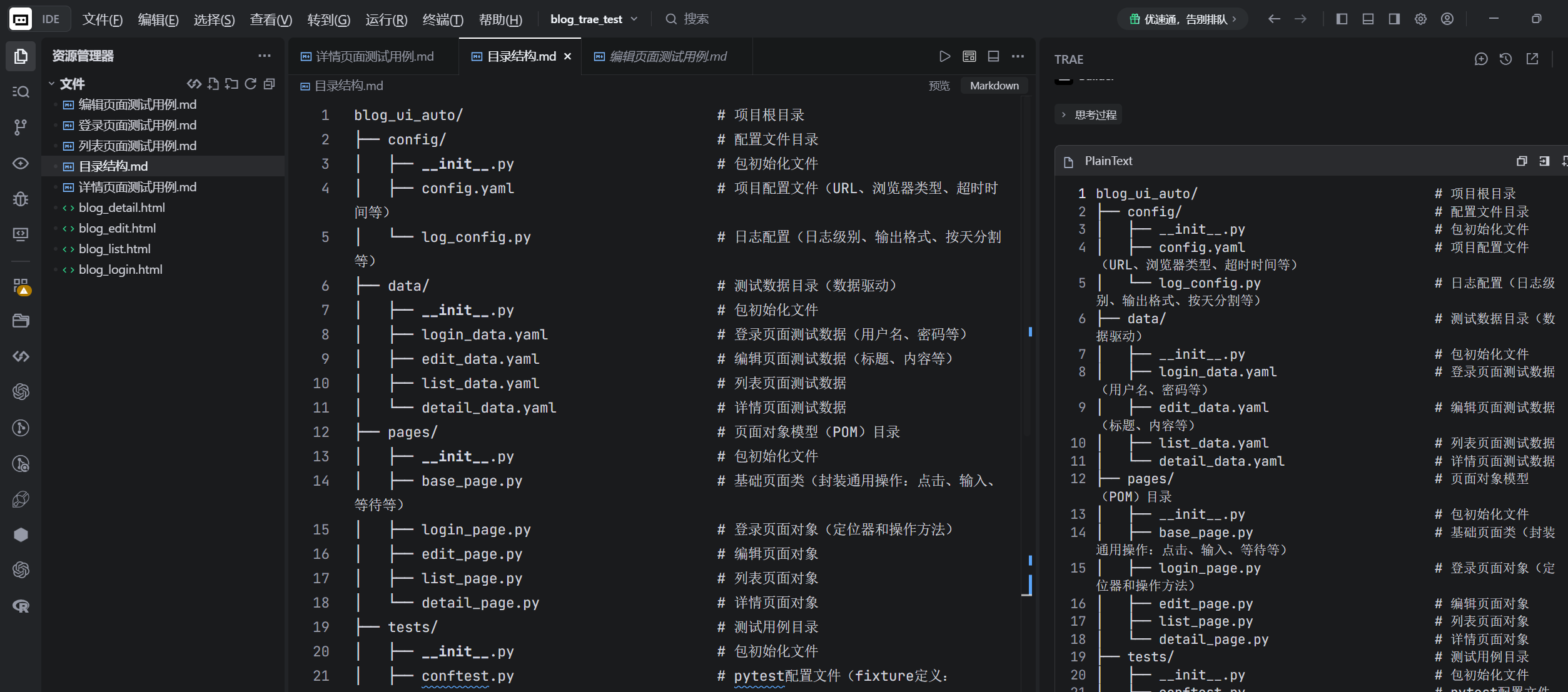
6.3 全项目自动化脚本批量生成
给到 Trae AI 的提示词:
@博客系统项目结构.md
@博客系统页面测试用例.md
@blog_detail.html
@blog_edit.html
@blog_list.html
@blog_login.html
结合附件中博客系统相关文件,严格按照各文件内容要求,在当前项目下生成web ui自动化测试,要求如下:
1.严格按照目录结构创建项目结构
2.完全按照测试用例来编写测试脚本
3.完全按照提供的html页面源码进行元素定位
4.测试文件执行顺序为:test_login.py、test_list.py、test_detail.py、test_edit.py
5.列表页、编辑页、详情页需要有登录状态才能访问
6.详情页url中带有参数blogId、可以通过列表页点击"查看全文"按钮进入详情页,此时url上的blogId值是有效的
7.浏览器的打开和关闭只执行一次
由于本次提示词内容较多,AI需要完成大量的工作。可能会存在用例生成不完整。
针对 AI 初次生成代码不全的问题,追加补充提示词:
代码块存在部分页面对应的测试脚本未实现完全,请继续生成
最终实现四大页面完整自动化脚本全覆盖。
七、测试报告生成与问题排错
自动化执行完成后,需要可视化报告展示执行结果,本次使用两种主流方案。
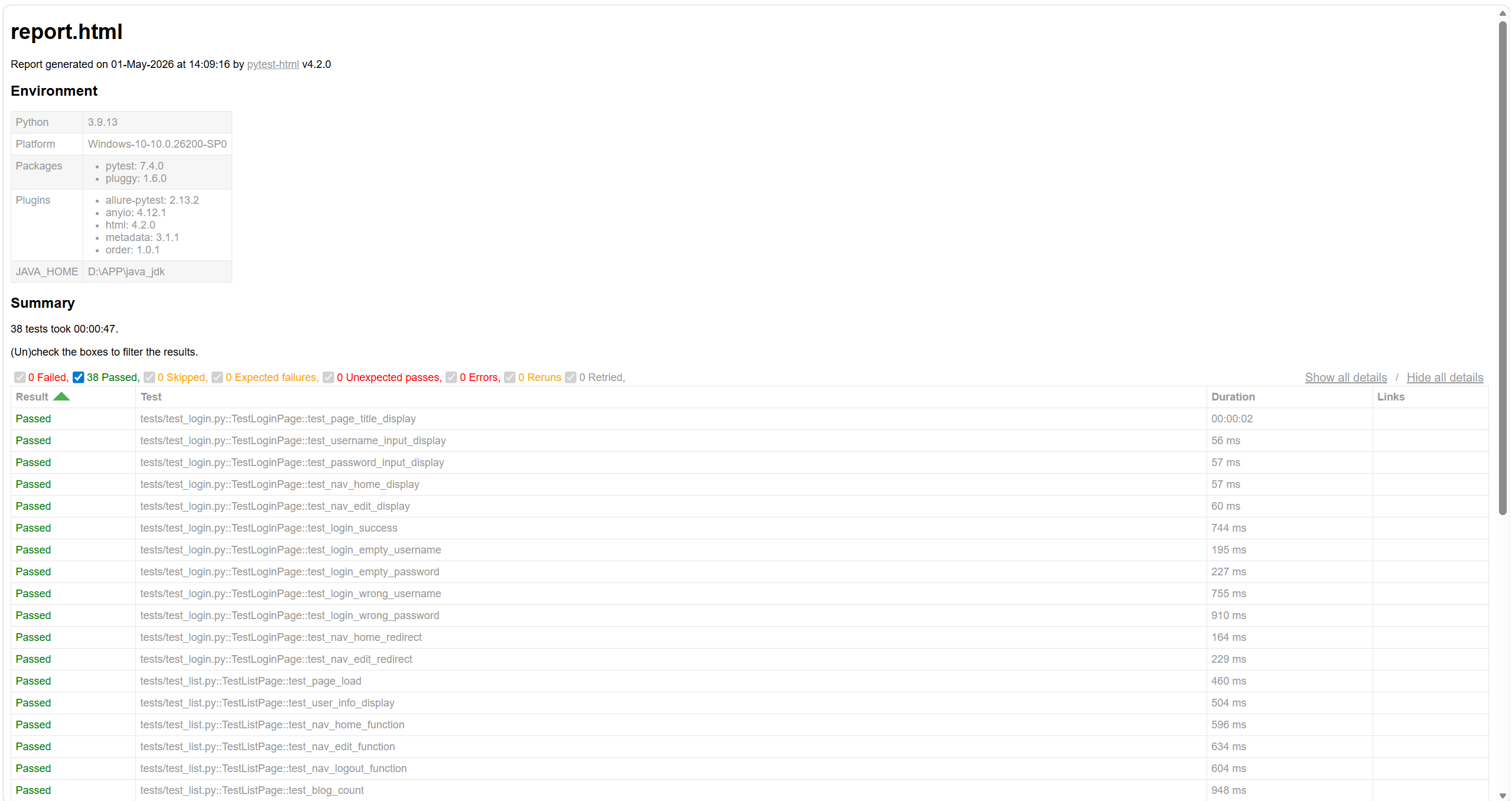
7.1 Pytest 简易 HTML 报告
轻量化、无需额外依赖,适合快速查看结果。再终端执行命令:
pytest --html=reports/report.html优点:部署简单、开箱即用;缺点:样式简陋、数据维度少。
7.2 Allure 高端可视化报告
行业主流方案,支持用例分级、失败截图、执行时长、趋势分析等。
-
先生成原始报告数据
-
本地拉起服务在线查看
-
导出静态离线报告
对应实操命令:
# 生成原始结果数据
pytest --alluredir=reports/allure-results
# 启动本地服务,在线查看报告(推荐)
allure serve .\reports\allure-results\
# 生成离线静态报告
allure generate .\reports\allure-results\ -o .\reports\allure-report\7.2.1 经典报错:Allure 报告本地打开空白
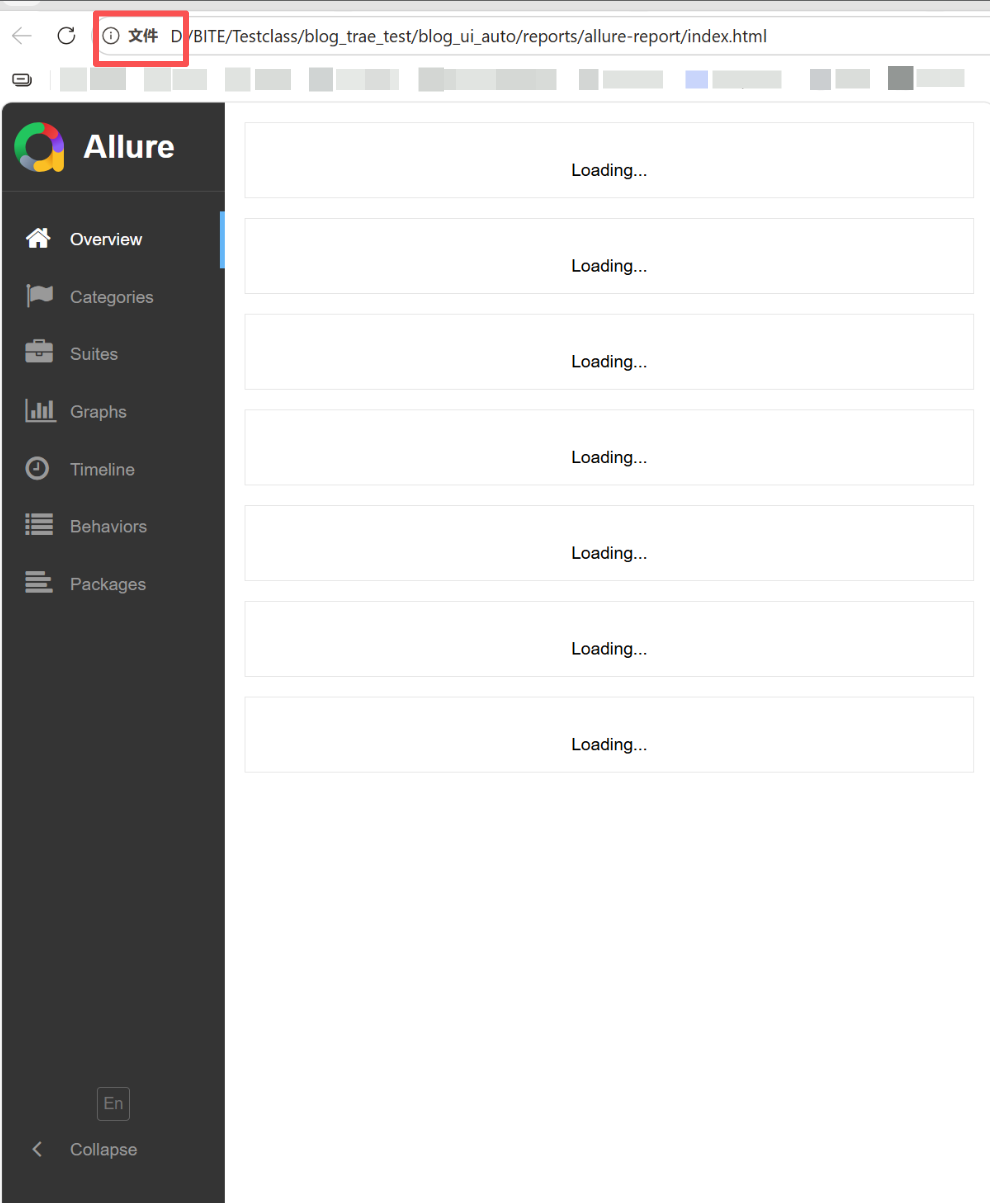
直接双击本地 html 文件打开报告,样式丢失、图表空白、资源加载失败
报错原因: 浏览器安全策略限制:file 本地文件协议,禁止跨域加载 CSS、JS 静态资源,导致报告渲染异常。
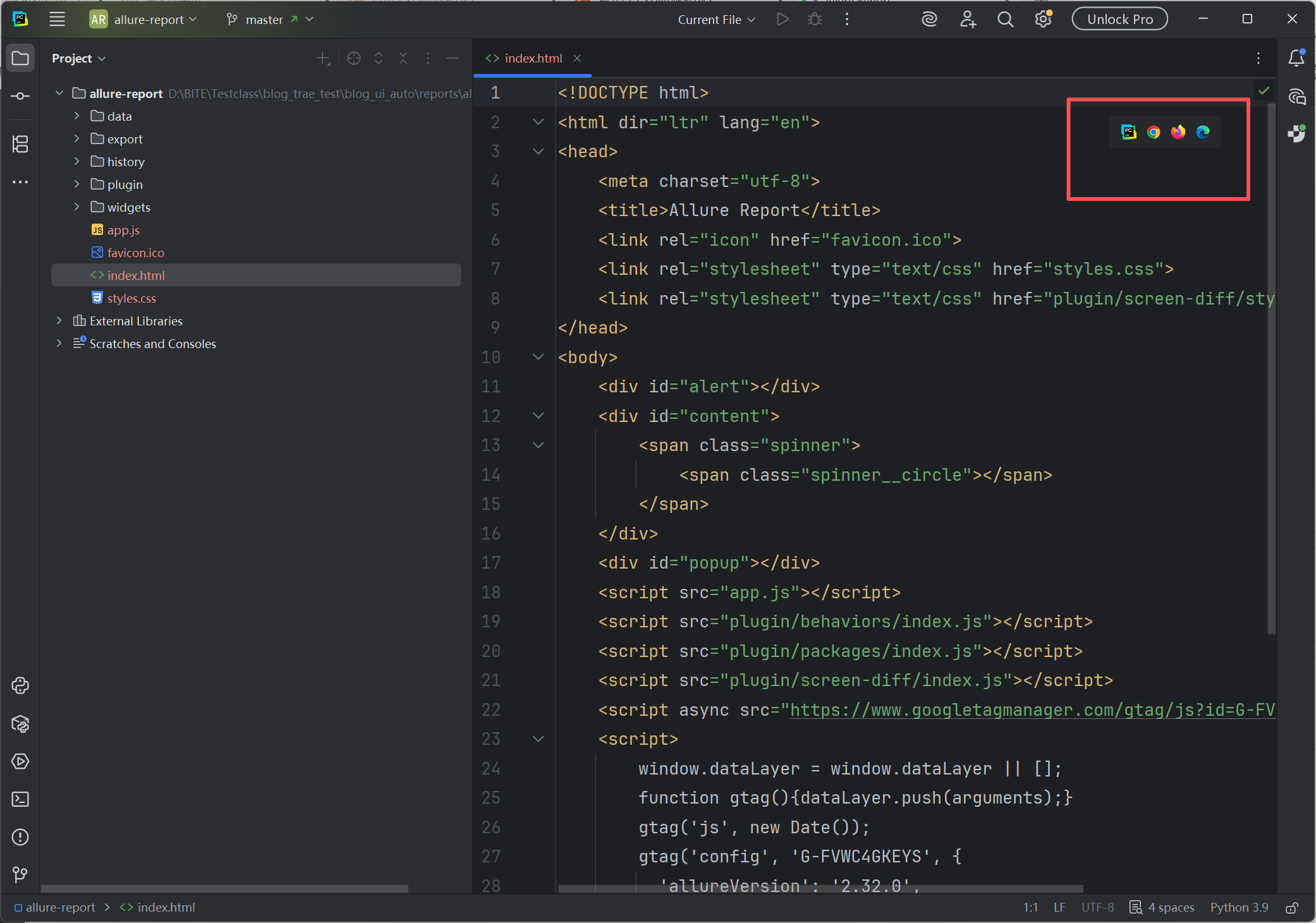
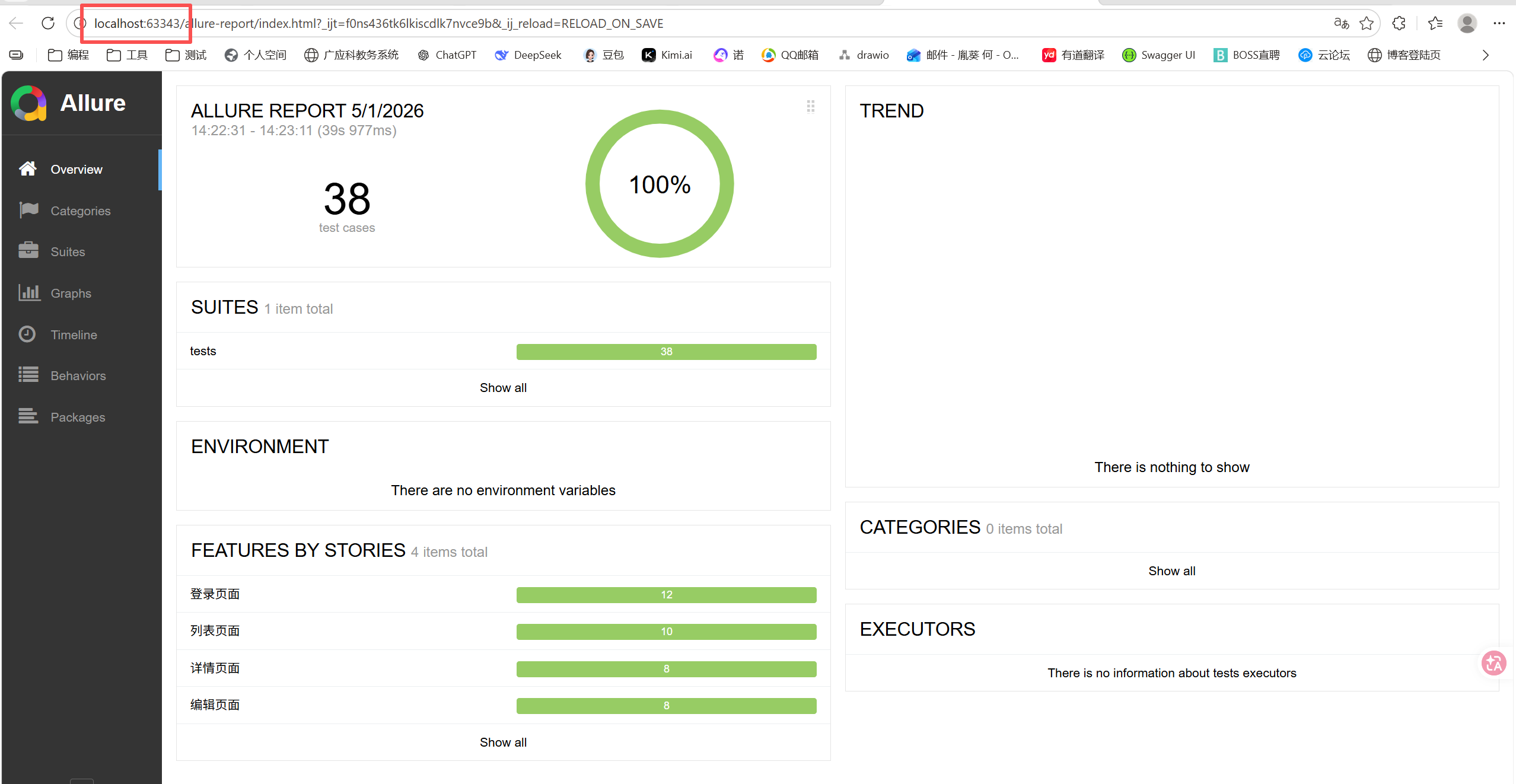
**解决方案:**将生成的测试报告文件夹用 PyCharm 打开,再将生成的html测试报告在 PyChatm 中使用服务器打开,63343是allure测试报告的默认端口号。
八、总结
-
AI 提示词标准化至关重要本次所有用例、脚本、优化代码、框架结构,全部依靠精准提示词生成,清晰的要求、格式限制、文件关联,是 AI 产出高质量代码的核心。
-
UI 自动化核心难点攻克了解了 Web 自动化高频问题:元素定位失效、页面跳转拦截、登录态共享、用例执行顺序、跨用例依赖问题。
-
框架思维升级从单文件零散脚本,升级为「配置 + 数据 + 用例 + 日志 + 报告」一体化分层项目,告别杂乱代码,适配后续迭代维护。
-
效率大幅提升Trae AI 替代重复编码、用例编写、元素修改、报告配置等机械工作,测试人员可专注逻辑设计、问题分析、缺陷验证核心工作。