很多人理解 AI 编程,还停留在"代码补全"这一层。
但 OpenAI 这篇关于 Codex 的实践文章,讨论的已经不是"模型能不能多写几行代码",而是另一个更关键的问题:
当代码生成能力不再稀缺之后,软件工程真正的核心约束,会转移到哪里?
OpenAI 给出的答案很明确:约束不会消失,只会从"人手写代码"转移为"为智能体设计环境、规则和反馈回路"。
在这项内部实验里,OpenAI 团队从空仓库起步,在大约 5 个月内,用 Codex 生成了约 100 万行代码,累计打开并合并约 1,500 个 Pull Request,核心团队最初只有 3 名工程师,后续扩展到 7 人。更关键的是,这并不是玩具项目,而是一个经历了交付、部署、故障和修复、并被真实用户使用的产品。按照文章披露的口径,整体交付速度大约是纯手工编码的 1/10 成本。
这组数字当然足够吸引眼球,但对工程团队更有价值的,不是"100 万行代码"本身,而是它背后那套可以迁移的方法论。
一、工程师最重要的工作,已经不是"写代码"
在智能体优先的开发模式里,工程师不再主要靠亲手实现功能创造价值,而是通过定义目标、拆解任务、补齐上下文、设计工具链和构建反馈机制来放大智能体的产出。
这意味着,当任务推进不顺利时,最有效的应对方式不再是继续追加提示词,而是反过来追问三个问题:
- 智能体缺少什么上下文
- 智能体缺少什么工具
- 哪些约束还停留在口头层面,尚未被机器化
这其实是在重写工程师的能力模型。过去,强工程师的优势可能体现在局部编码速度和复杂实现能力;现在,越来越体现在系统杠杆、约束设计和反馈闭环的构建能力。
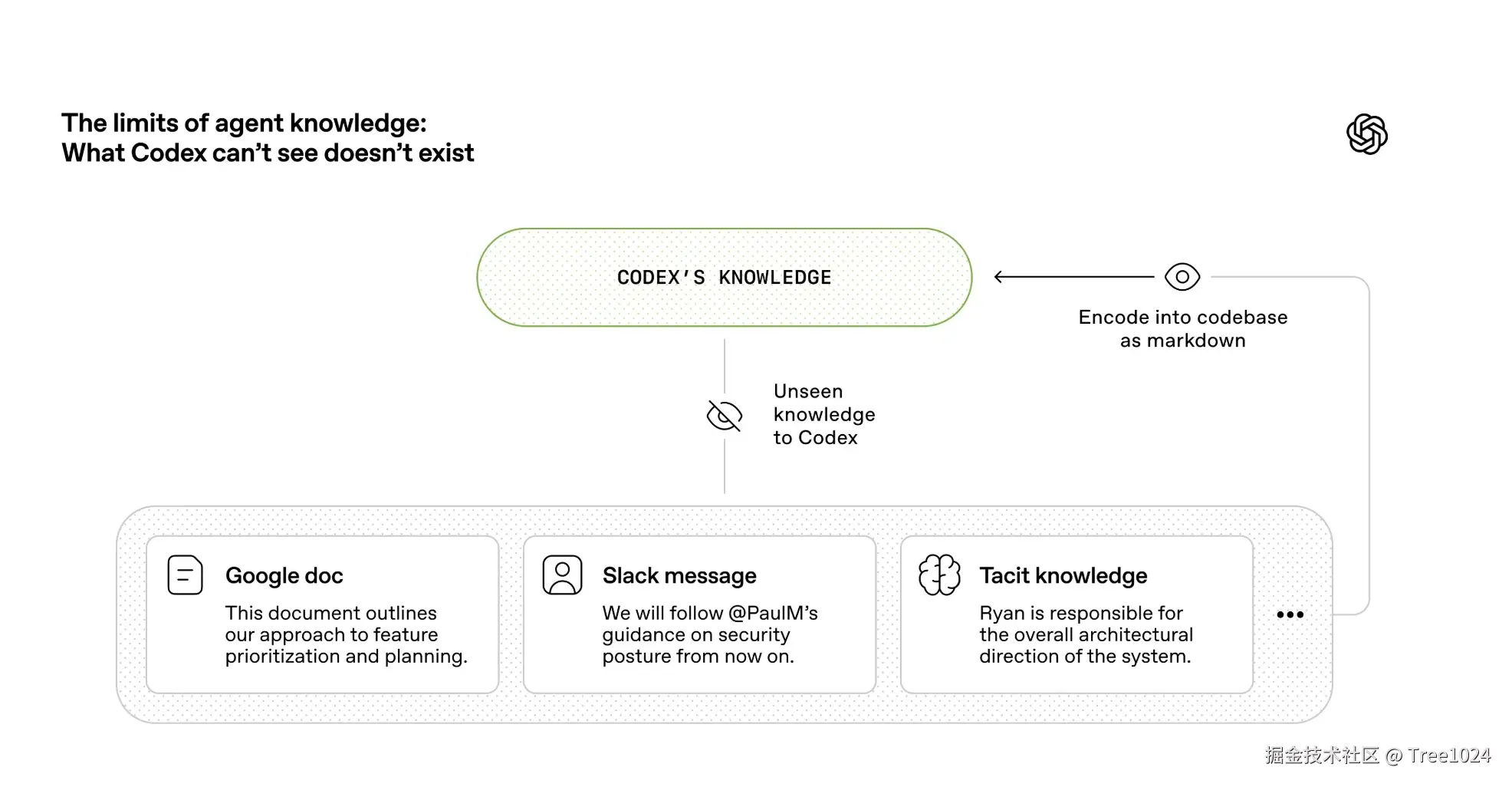
二、对智能体来说,看不见的知识就等于不存在
OpenAI 在文中反复强调的一点是:不要给智能体一本冗长手册,而要给它一张地图。
他们曾尝试用一个很大的 AGENTS.md 承载所有规则,结果并不好。原因也很直接:
- 上下文窗口是稀缺资源,超大说明书会挤占真正重要的任务和代码信息
- 当所有规则都被标成"重要",模型会失去优先级判断
- 这类巨型文档很快就会过时,而且难以验证其是否仍然正确
因此,他们把 AGENTS.md 收缩成一个简洁入口,只承担导航作用;真正的设计原则、产品规格、架构分层、执行计划、技术债、质量规则等内容,全部进入结构化、可版本化、可检查的仓库文件中。
这个原则非常值得国内团队借鉴:对智能体来说,运行时看不到的知识,就等同于不存在。
那些散落在 Slack、飞书、Notion、Google Docs 和口头共识里的信息,如果没有回写到仓库,就无法稳定参与执行。
三、真正拉开差距的,不是生成代码,而是理解运行中的系统
代码生成速度一旦上来,瓶颈很快就不再是编码本身,而是验证、回归和 QA。
OpenAI 的做法不是继续把验证压力压给人,而是让 Codex 直接具备读取运行态的能力。他们做了三件非常关键的事情:
- 基于
git worktree为每次变更启动独立实例 - 接入 Chrome DevTools 协议,让 Codex 可以读取 DOM、截图、导航和复现 UI 行为
- 暴露日志、指标、追踪,让 Codex 可以直接查询
LogQL、PromQL等运行信号
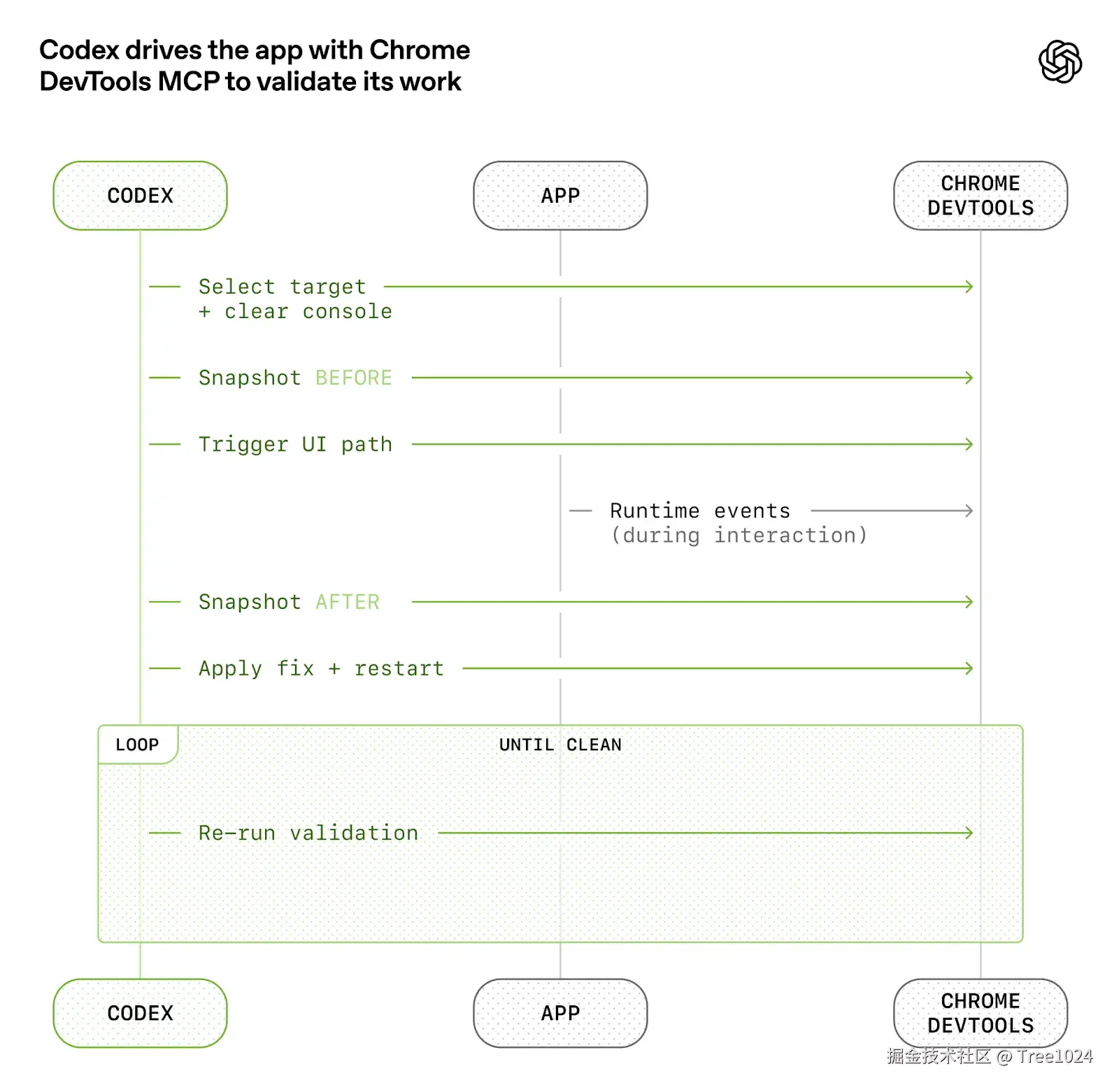
Codex 通过 Chrome DevTools 驱动应用并验证结果
这一步的意义非常大。没有运行态可见性,智能体只能"猜";有了运行态可见性,智能体才有可能完成真正的闭环:
复现问题 -> 修改代码 -> 验证修复 -> 提交 PR -> 响应反馈 -> 再次验证
这也是为什么很多团队虽然已经在用代码助手,但依然没有获得数量级提效。问题往往不在模型,而在工程系统没有对智能体开放足够多的可观察面。
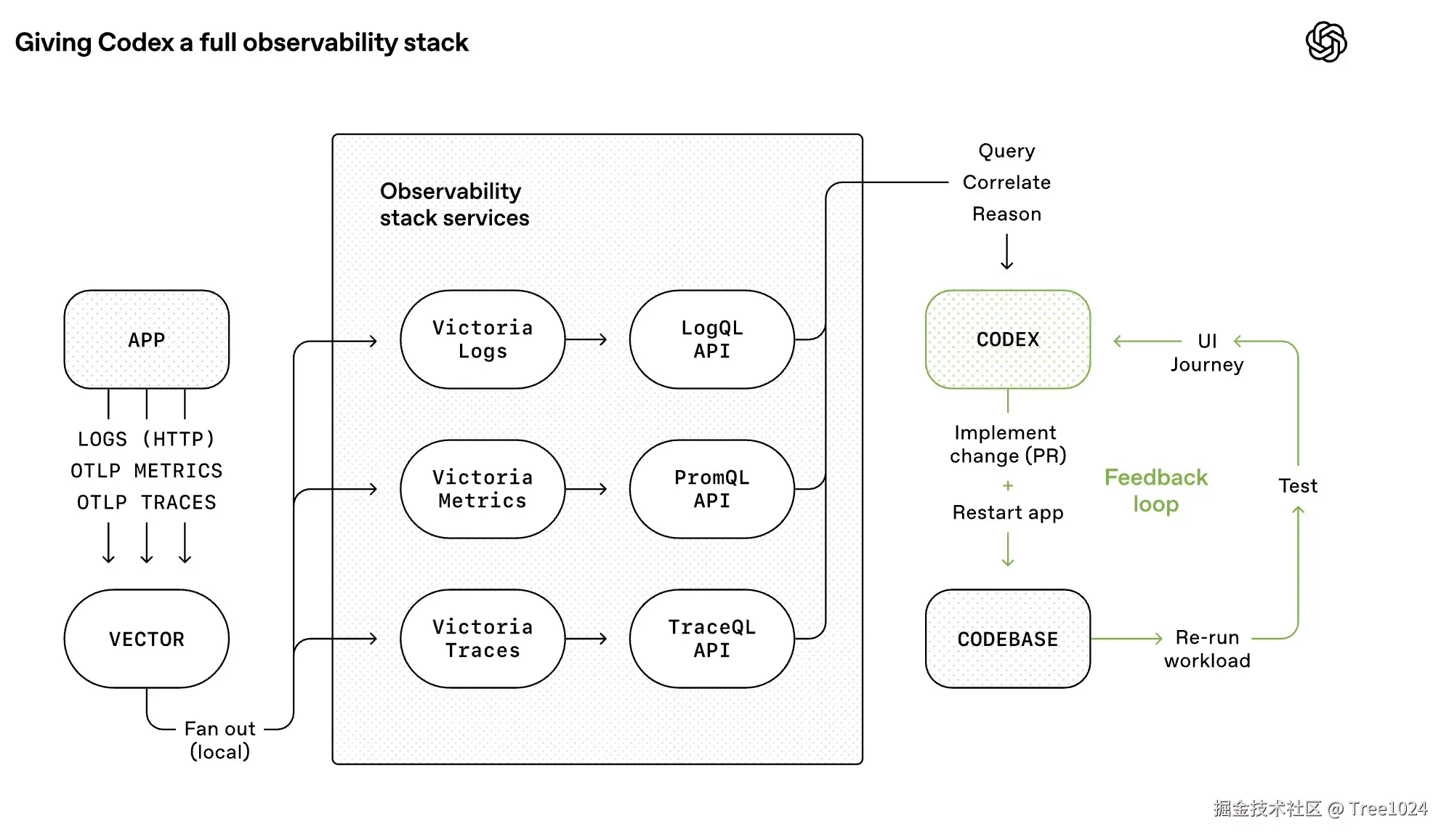
把日志、指标和追踪完整暴露给智能体
四、治理 AI 代码库,靠的不是口头规范,而是可执行约束
文中另一个非常关键的结论是:文档只能解释规则,真正保证一致性的,必须是机器强制执行的约束。
OpenAI 的做法不是微观规定每一段代码应该怎么写,而是把真正重要的不变量编码进系统,包括但不限于:
- 架构分层和依赖方向
- 横切能力的合法入口
- 命名约定和类型边界
- 结构化日志规则
- 文件大小与平台可靠性约束
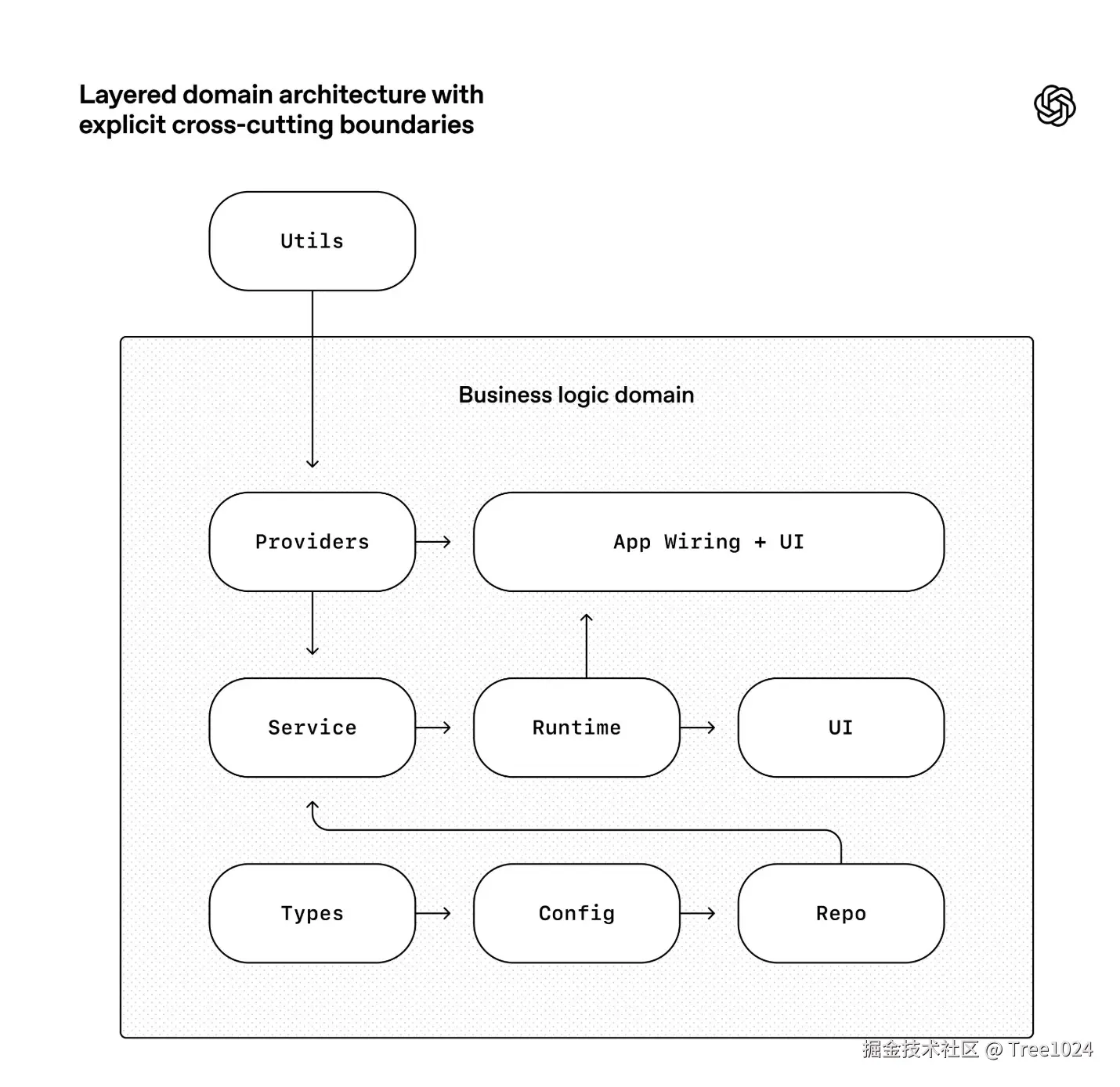
严格分层与显式边界,让智能体在可控结构内生成代码
这些规则通过自定义 linter、结构测试和 CI 作业持续执行。对于智能体来说,这种治理方式远比"最佳实践"更有效,因为它提供的是明确、稳定、可验证的搜索空间。
换句话说,在智能体优先的世界里,真正有价值的不是"代码风格建议",而是"机器可执行的工程法则"。
五、高吞吐量下,PR 与合并策略必须重写
当一个团队每天面对的不是少量人工 PR,而是持续涌入的大量智能体变更时,传统审查流程会迅速成为瓶颈。
OpenAI 在实践中选择了更短的 PR 生命周期,并尽量减少阻塞式门禁。原因并不复杂:在高吞吐环境里,很多问题的修复成本已经低于等待成本。某些偶发失败,与其长期阻塞主线,不如在后续自动重跑和补丁修复中解决。
这并不意味着降低质量标准,而是意味着质量控制的位置发生了变化:
- 从"人肉 review 兜底"转向"系统自动校验优先"
- 从"合并前尽量做完所有判断"转向"让反馈回路足够快"
- 从"谨慎地少改"转向"高频小步、快速纠偏"
这套逻辑只有在自动化验证、结构约束和可观察性足够强时才成立,但一旦条件具备,它会显著改变团队的节奏。
六、AI 不会自动消灭技术债,它只会放大技术债
OpenAI 文章里一个很真实的细节是:早期他们每周要拿出大约 20% 的时间清理所谓的"AI 残渣"。
这很合理。智能体会复用代码库里已经存在的模式,而它并不会天然区分哪些模式是优秀实践,哪些只是历史遗留。只要仓库中存在坏味道,模型就会放大它。
他们后来的治理方式,是把"黄金原则"直接写成规则,再通过后台 Codex 任务持续扫描偏差、更新质量评分并提交小型重构 PR。技术债治理从一次性的人肉清扫,转变为持续性的"垃圾回收"机制。
这点对所有希望大规模引入 AI 编码的团队都很重要:AI 不会让代码库自动变整洁,只有把品味、约束和清理策略编码进系统,整洁性才会自动延续。
七、这篇文章真正揭示的,是软件工程重心的整体上移
如果把这篇文章压缩成一句话,我认为可以这么概括:
未来的软件工程竞争力,不再主要取决于团队能否更快地手写代码,而取决于团队能否为智能体构建一个可理解、可验证、可纠偏、可持续演进的工程系统。
这意味着,工程师的价值并没有下降,而是在上移:
- 从实现者转向系统设计者
- 从编码者转向约束定义者
- 从问题修补者转向反馈回路构建者
- 从知识消费者转向仓库知识体系维护者
对于已经在尝试 AI 协作开发的团队,最值得优先投资的通常不是"再换一个更强模型",而是以下四类基础设施:
- 把设计、计划、验收标准、技术债和架构约束沉淀进仓库
- 让 UI、日志、指标、追踪对智能体可读
- 用 lint、测试、脚本和 CI 把规范编译成机器规则
- 建立持续的小步清理机制,而不是等代码库失控后再大扫除
结语
OpenAI 这篇文章最有价值的地方,在于它把"AI 写代码"从演示层面推进到了工程系统层面。它讨论的不是一个模型能不能补全函数,而是一个团队如何围绕智能体重写开发环境、知识组织方式和质量控制机制。
在智能体优先的世界里,软件工程不会消失,但它的重心会从"产出代码"转向"设计控制系统"。谁先完成这次迁移,谁就更有机会获得数量级上的研发杠杆。
一句话总结:在智能体优先的时代,代码不再是最稀缺的资产,真正稀缺的是把智能体组织成生产力的工程系统。
原文信息
- 标题:工程技术:在智能体优先的世界中利用 Codex
- 作者:Ryan Lopopolo
- 发布时间:2026 年 2 月 11 日
- OpenAI 官方原文:openai.com/zh-Hans-CN/...