作者:来自 Elastic Jonas Kunz
随时查询任意百分位数。Elasticsearch 原生存储 OTel 指数直方图(exponential histogram),并允许你在 ES|QL 中分析分布数据,无需固定 bucket,也无需有损转换。
亲自体验 Elasticsearch:深入探索 Elasticsearch Labs 仓库中的示例 notebooks,开始免费的云试用,或立即在你的本地机器上试用 Elastic。
Elasticsearch 在 ES|QL 中新增了对 OpenTelemetry 指数直方图(exponential histogram)的原生支持。与固定 bucket 的直方图不同,指数直方图会根据你的数据动态自适应 ------ 让你能够在查询时获得准确的百分位数估算(中位数、p99,或任何你想要的百分位数),并提供有保证的误差边界。不再需要预先定义 bucket,也不再需要有损转换。
你只需将 OTel 指标发送到 Elasticsearch 的 OTLP/HTTP endpoint,它们就会以新的 [exponential_histogram](https://www.elastic.co/docs/reference/elasticsearch/mapping-reference/exponential-histogram "exponential_histogram") 类型存储,并可立即查询。已经有以经典 histogram 类型存储的历史数据?只需在 ES|QL 查询中使用简单的 ::exponential_histogram 类型转换,即可透明完成迁移。已经在使用 downsampling?现在两种 histogram 字段类型都已获得完整支持。
Histogram 指标
在处理指标(例如 OpenTelemetry 或 Prometheus 中的指标)时,counter 和 gauge 是最常见的指标类型。Gauge 用于监控会上升或下降的值(例如 CPU 利用率)。Counter 则用于 "计数",例如统计你的服务处理的 HTTP 请求总数。Counter 通常只会不断增加,只有少数情况下会重置,例如服务器重启时。
对于 counter,你还可以额外收集一个用于统计 HTTP 响应时间总和的 counter,通过将该总和除以请求总数,就能得到平均响应时间。然而,平均响应时间对于理解采集到的数据和系统行为的洞察非常有限。真正有价值的分析来自于对指标分布的研究,例如计算中位数和百分位数。而这正是 counter 的不足之处。
过去,人们通常会采用一些变通方案。例如,经典的 Prometheus 风格直方图会尝试通过一组 counter 来捕获数据分布。方法是定义固定 bucket(例如一个 bucket 表示响应时间位于 [0s, 1s),另一个表示 [1s, 4s),以此类推),并为每个 bucket 关联一个 counter。这样我们至少可以粗略估算百分位数。然而,这种方法的核心问题在于:我们必须提前知道数据的分布情况,才能合理地定义这些 bucket。
为了解决这个问题,OpenTelemetry 社区提出了更好的方案:指数直方图(exponential histogram)。指数直方图和经典的 Prometheus 风格直方图一样,也会将采集到的值分配到 bucket 中。关键区别在于,这些 bucket 会根据采集到的数据动态变化。"指数(exponential)" 这一名称来源于 bucket 大小按指数增长的特性:对于较小的值,我们使用较小的 bucket;对于较大的值,则使用更宽的 bucket。你可以在 OpenTelemetry 关于指数直方图的介绍中找到一篇非常优秀的入门文章。
需要注意的是,除了经典直方图之外,Prometheus 还新增了 native histogram,它与 OTel 指数直方图是直接对应的。Native histogram 也拥有自己的 PromQL 语法。我们正在积极为 Elasticsearch 的 PromQL 实现增加对该语法的支持,以便你能够直接使用 PromQL 查询指数直方图。
Demo 环境搭建
让我们先采集一些 histogram 指标,演示如何使用 ES|QL 在 Elasticsearch 中存储和分析这些指标。
我们将重点关注一个 Java JVM 指标:垃圾回收持续时间(garbage collection durations)。OpenTelemetry 定义了 [jvm.gc.duration](https://opentelemetry.io/docs/specs/semconv/runtime/jvm-metrics/#metric-jvmgcduration "jvm.gc.duration") 指标,它是一种 histogram 类型的指标。OpenTelemetry Java agent 原生支持采集该指标。
我们会启动一个运行 Renaissance benchmark 的 JVM,对其施加压力测试。随后,我们会在该 JVM 上挂载原生的 OpenTelemetry Java agent,并让它将指标直接发送到 Elasticsearch。
你可以在这里找到可直接运行的 Docker Compose 文件。你只需要在 docker-compose.yml 中填入你的 Elasticsearch OTLP/HTTP endpoint 和 API key:
arduino
`
1. OTEL_EXPORTER_OTLP_ENDPOINT: https://<elasticsearch url>/_otlp
2. OTEL_EXPORTER_OTLP_HEADERS: "Authorization=ApiKey <base64 API key>"
`AI写代码请注意,你并不一定非要使用这个 demo 环境。我们甚至鼓励你直接在自己的应用程序上进行尝试。下面是该 demo 已经包含的其他重要 OpenTelemetry agent 配置;如果你使用自己的应用,也建议一并启用这些配置:
yaml
`
1. OTEL_EXPORTER_OTLP_METRICS_TEMPORALITY_PREFERENCE: delta
2. OTEL_EXPORTER_OTLP_METRICS_DEFAULT_HISTOGRAM_AGGREGATION: BASE2_EXPONENTIAL_BUCKET_HISTOGRAM
3. OTEL_INSTRUMENTATION_RUNTIME_TELEMETRY_ENABLED: "true"
`AI写代码让我们逐项来看:
-
Temporality preference(时间性偏好):OpenTelemetry 同时支持 cumulative(累积)和 delta(增量)两种 histogram 模式。Cumulative 表示 histogram 只会在应用重启后清空;而 delta 会在每次导出后清空。在撰写本文时,Elasticsearch 仅支持 histogram 的 delta temporality。我们也正在积极推进对 cumulative histogram 的支持。
-
Default Histogram Aggregation(默认直方图聚合):默认情况下,OpenTelemetry 会以 Prometheus 风格的固定 bucket 格式导出 histogram。由于我们希望获得指数直方图带来的优势,因此需要告诉 agent 改用 exponential histogram。
-
Runtime Telemetry enabled (启用运行时遥测):该配置会让 agent 实际采集详细的 JVM 指标,其中就包括
jvm.gc.duration。
现在一切准备就绪!我们会让应用程序在后台持续运行,然后切换到 Kibana 来分析 GC 指标。
使用 ES|QL 查询
现在打开 Kibana 并进入 "Discover"。在那里切换到 ES|QL 模式,然后开始查询已采集的数据:
scss
`TS metrics-* | STATS COUNT(jvm.gc.duration)`AI写代码作为响应,我们现在可以看到下方展示的指标面板。如果你没有看到任何数据,请务必检查 Kibana 的时间范围过滤器(time range filter)是否设置正确。
 ES|QL 指标面板,显示 jvm.gc.duration 样本的总数量。
ES|QL 指标面板,显示 jvm.gc.duration 样本的总数量。
这个数字表示在所选时间范围内,测试应用中发生的垃圾回收操作总次数。
同样地,我们也可以查询这些垃圾回收操作所花费的总时间:
scss
`TS metrics-* | STATS SUM(jvm.gc.duration)`AI写代码 ES|QL 指标面板显示在所选时间范围内 jvm.gc.duration 值的总和(sum)。
ES|QL 指标面板显示在所选时间范围内 jvm.gc.duration 值的总和(sum)。
所以我们大约有 27 万次垃圾回收(GC),总共耗时 713 秒。
有了这两个数字,其实我们已经可以用小学数学水平轻松算出平均值:用总耗时除以 GC 次数即可。
如果你不想手算,ES|QL 也可以直接帮你完成这个计算:
 ES|QL 指标面板显示 jvm.gc.duration 的平均值(average)
ES|QL 指标面板显示 jvm.gc.duration 的平均值(average)
现在我们知道,每次垃圾回收(GC)的平均耗时大约是 3 毫秒。
不过 Java 专家可能会注意到,实际运行中会发生不同类型的垃圾回收,而这些类型的暂停时间可能差异很大。幸运的是,OpenTelemetry 指标携带了 attributes(属性),这使我们可以按维度对数据进行切分分析:
scss
`TS metrics-* | STATS AVG(jvm.gc.duration) BY jvm.gc.action`AI写代码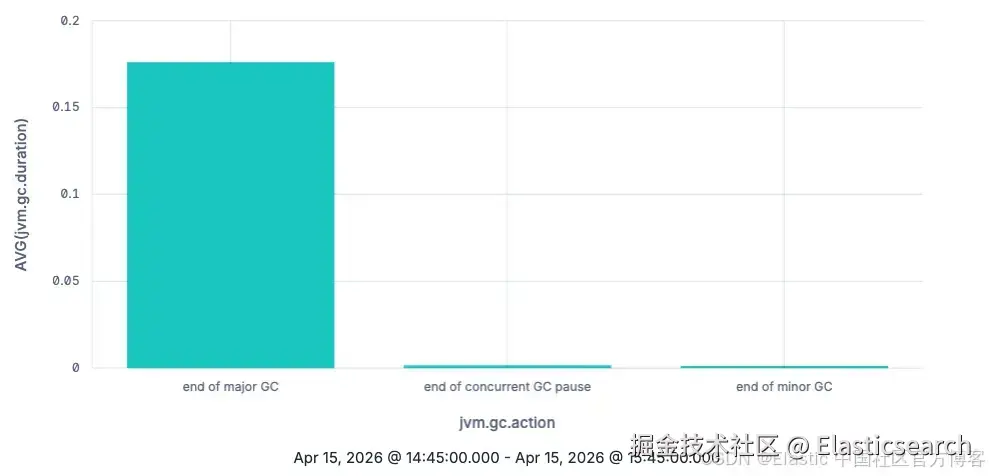 ES|QL 柱状图展示按 jvm.gc.action 分组的 jvm.gc.duration 平均值
ES|QL 柱状图展示按 jvm.gc.action 分组的 jvm.gc.duration 平均值
正如预期,major GC(大回收)每次的耗时明显高于 minor GC,至少在平均值层面是这样的。
但到目前为止,我们做的分析其实都还停留在 counter 的能力范围内 ------ 也就是 "总量 + 平均值"。真正的区别现在才开始出现:我们可以使用 histogram 来理解 GC latency 的真实分布情况。
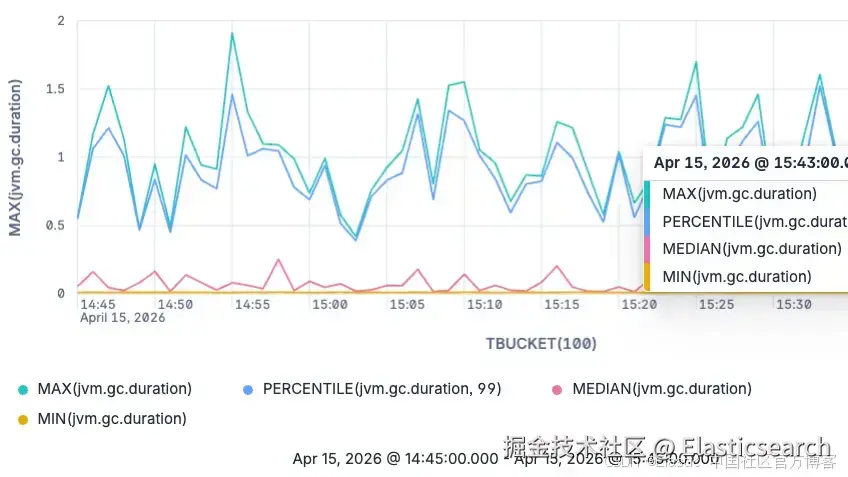
接下来,我们会把时间维度纳入分析(通过 TBUCKET 分组),并专注于 major garbage collections:
ES|QL 柱状图展示在 TBUCKET 时间分桶下,jvm.gc.duration(major GC)分布的变化情况。
scss
`
1. TS metrics-*
2. | WHERE jvm.gc.action == "end of major GC"
3. | STATS MAX(jvm.gc.duration),
4. PERCENTILE(jvm.gc.duration, 99),
5. MEDIAN(jvm.gc.duration),
6. MIN(jvm.gc.duration)
7. BY TBUCKET(100)
`AI写代码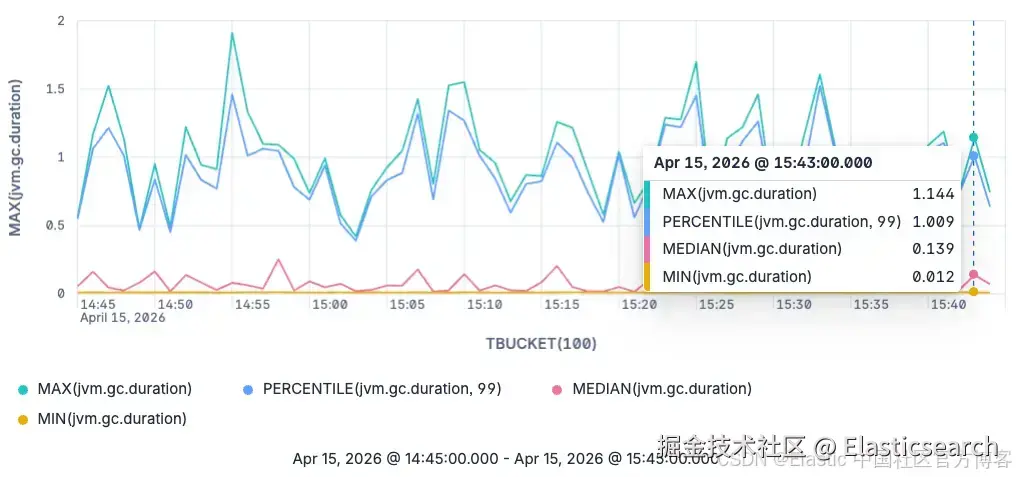 ES|QL major garbage collections 的 jvm.gc.duration 的 min、median、p99 和 max 折线图
ES|QL major garbage collections 的 jvm.gc.duration 的 min、median、p99 和 max 折线图
现在这个图展示了 major garbage collections 的最小值、最大值、中位数以及 99 分位数。
需要注意的是,我们并不局限于只查询中位数和 99 分位数。你可以查询任意想看的百分位数,因为这些值是在查询时基于原始 exponential histograms 动态估算出来的。
向后兼容说明
到目前为止,我们已经看到了 Elasticsearch 和 ES|QL 中这个"新玩具":exponential histograms。
但由于它是在 9.4 版本刚刚达到正式可用,那么历史数据怎么办?
在 exponential histograms 出现之前,Elasticsearch 已经可以使用 histogram field type 存储 OpenTelemetry 的 histogram 数据。当时的做法是将其转换为 histogram field type 支持的另一种数据结构:T-Digest。
T-Digest 对极端百分位数(例如 99 分位)有较好的精度,但代价是中间分布(例如 median)的精度会下降。相比之下,exponential histograms 为每一个百分位数提供了相对误差的上界保证。由于任何转换都会引入误差,我们现在很高兴拥有原生的 exponential histogram 支持,从而可以端到端采集和分析指标,而不需要不必要的转换。
那么问题来了:如果你已经有历史数据,并且仍然想查询它,该怎么办?
得益于 ES|QL 的 union types,这个问题其实很简单:你只需要在查询中的 histogram 指标后面加上 ::exponential_histogram 后缀即可:
scss
`TS metrics-* | STATS AVG(jvm.gc.duration::exponential_histogram)`AI写代码当这个查询遇到 histogram 字段时,它会尝试将其转换为 exponential histograms。当操作的是 exponential_histogram 字段时,::exponential_histogram 强制转换不会产生任何影响。注意,这也适用于混合数据集:如果你的底层索引同时使用了两种类型,查询会自动正确处理。
因此,如果你在构建预期运行在 pre-9.4 版本数据上的查询或 dashboard,我们建议你直接添加:::exponential_histogram 转换。
总结
Elasticsearch 对 OpenTelemetry exponential histograms 的原生支持,为你在 ES|QL 中提供了更高的指标保真度和更灵活的分析能力。在这篇博客中,我们展示了如何使用 ES|QL 通过各种聚合轻松摄取和分析 histogram 指标,以及 exponential histograms 带来的影响。
Exponential histograms 从 Elasticsearch basic 9.4.0 版本开始正式可用。它们将在 Elastic Cloud Serverless 中于 9.4.0 发布后的几周内可用,届时 mOTLP(托管可观测性 OTLP ingestion)将切换为使用 Elasticsearch OTLP endpoint。当这一切发生时,我们会更新这篇博客,并在 Elastic Cloud Serverless release notes 中添加说明。
常见问题
如何在 Elasticsearch 中查询 OpenTelemetry histogram 指标?
Elasticsearch 9.4 原生存储 OpenTelemetry exponential histograms,并支持在 ES|QL 中查询它们。你可以直接在 histogram 字段上使用 AVG、SUM、COUNT、PERCENTILE、MEDIAN、MIN 和 MAX 等标准聚合函数。只需将 OTel metrics 发送到 Elasticsearch OTLP/HTTP endpoint,并在 Kibana Discover 中使用 ES|QL 查询即可。
exponential histograms 和经典 Prometheus 风格 histograms 有什么区别?
经典 Prometheus 风格 histogram 需要你预先定义固定 bucket,这意味着你必须提前知道数据分布。Exponential histograms 会根据采集到的值动态调整 bucket 边界,从而在不需要任何预定义配置的情况下提供准确的百分位数估计。这使它们在真实世界中分布不断变化的工作负载中更加灵活。
为什么 exponential histograms 比 T-Digest 更适合指标存储?
在 9.4 之前,Elasticsearch 会将 OTel histograms 转换为 T-Digest 进行存储。T-Digest 对极端百分位数(如 p99)有较好精度,但在中间分位数(如 median)上精度较低。Exponential histograms 对每个百分位数都提供相对误差的上界保证,并且原生存储消除了有损转换步骤。另外 T-Digest 不支持 cumulative temporality。
升级到 Elasticsearch 9.4 后还能查询历史 histogram 数据吗?
可以。如果你有旧版本存储在经典 histogram field type 中的数据,可以通过在 ES|QL 查询中添加 ::exponential_histogram cast 来与新的 exponential_histogram 数据一起查询。ES|QL union types 会透明处理转换,即使跨多个混合索引也是如此。
如何将 OpenTelemetry exponential histograms 发送到 Elasticsearch?
配置你的 OpenTelemetry SDK 或 agent 使用 delta temporality(OTEL_EXPORTER_OTLP_METRICS_TEMPORALITY_PREFERENCE: delta)以及 exponential bucket histograms(OTEL_EXPORTER_OTLP_METRICS_DEFAULT_HISTOGRAM_AGGREGATION: BASE2_EXPONENTIAL_BUCKET_HISTOGRAM)。将 OTLP exporter 指向 Elasticsearch OTLP/HTTP endpoint,histograms 就会被原生存储------无需中间 collector 或转换。
Elasticsearch 是否支持 histogram metrics 的 downsampling?
支持。从 Elasticsearch 9.4 开始,exponential_histogram 和经典 histogram field type 都支持 time series data stream downsampling。这可以让你以更低存储成本保留长期 histogram 数据,同时仍然能够查询百分位数。
Elasticsearch 的 histogram 支持与其他可观测性平台相比如何?
大多数可观测性平台要么依赖固定 bucket histograms(损失精度),要么在 ingest 阶段将分布转换为 sketches(损失原始数据)。Elasticsearch 9.4 原生存储 OTel exponential histograms,并允许你在查询时使用 ES|QL 计算任意百分位数,而无需预定义 bucket 或在中间转换中丢失数据。