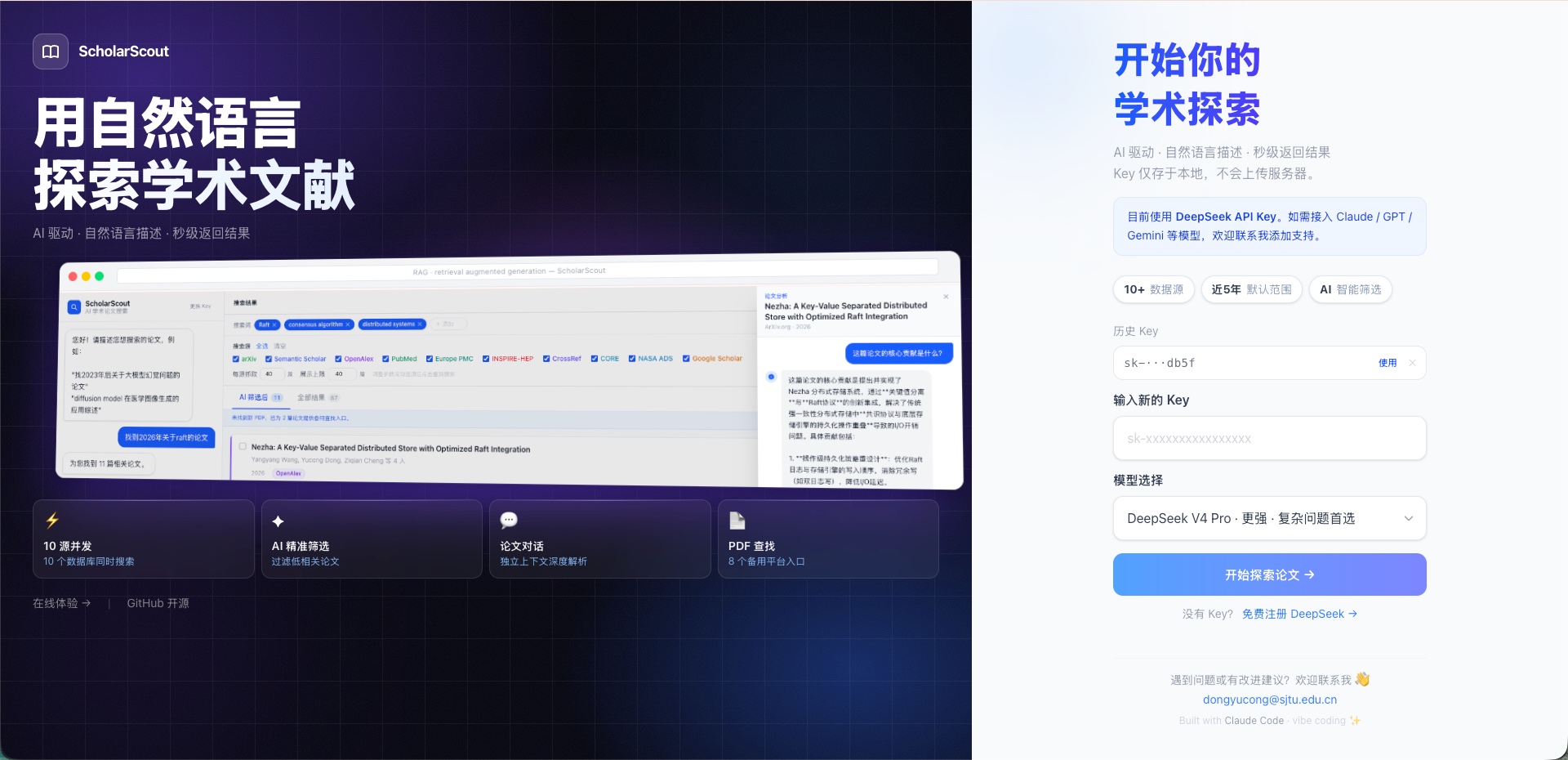
我用 Claude Code 做了一个学术论文搜索工具
非计算机背景也能用,支持中文自然语言描述、AI 筛选、论文独立对话、批量下载 PDF。
起因
做科研的时候,找论文这件事一直让我觉得麻烦。Google Scholar 需要想好关键词,结果还要一篇篇手动判断相不相关,PDF 找不到还得去各个平台碰运气。
于是就想做一个工具,让这件事变简单一点------直接用中文说"我要找什么",剩下的交给程序。
最近花了一些时间,用 Claude Code(Sonnet 4.6) vibe coding 出来了,取名 ScholarScout,部署在自己的云服务器上,现在开放试用。
核心功能
1. 自然语言搜索
不需要想英文关键词。直接输入中文描述,比如:
"找 2023 年后关于大模型幻觉问题的论文"
"diffusion model 在医学图像生成的综述"
后端调用 DeepSeek 自动提取英文学术关键词,展示给你确认,点确认之后再开始搜索。
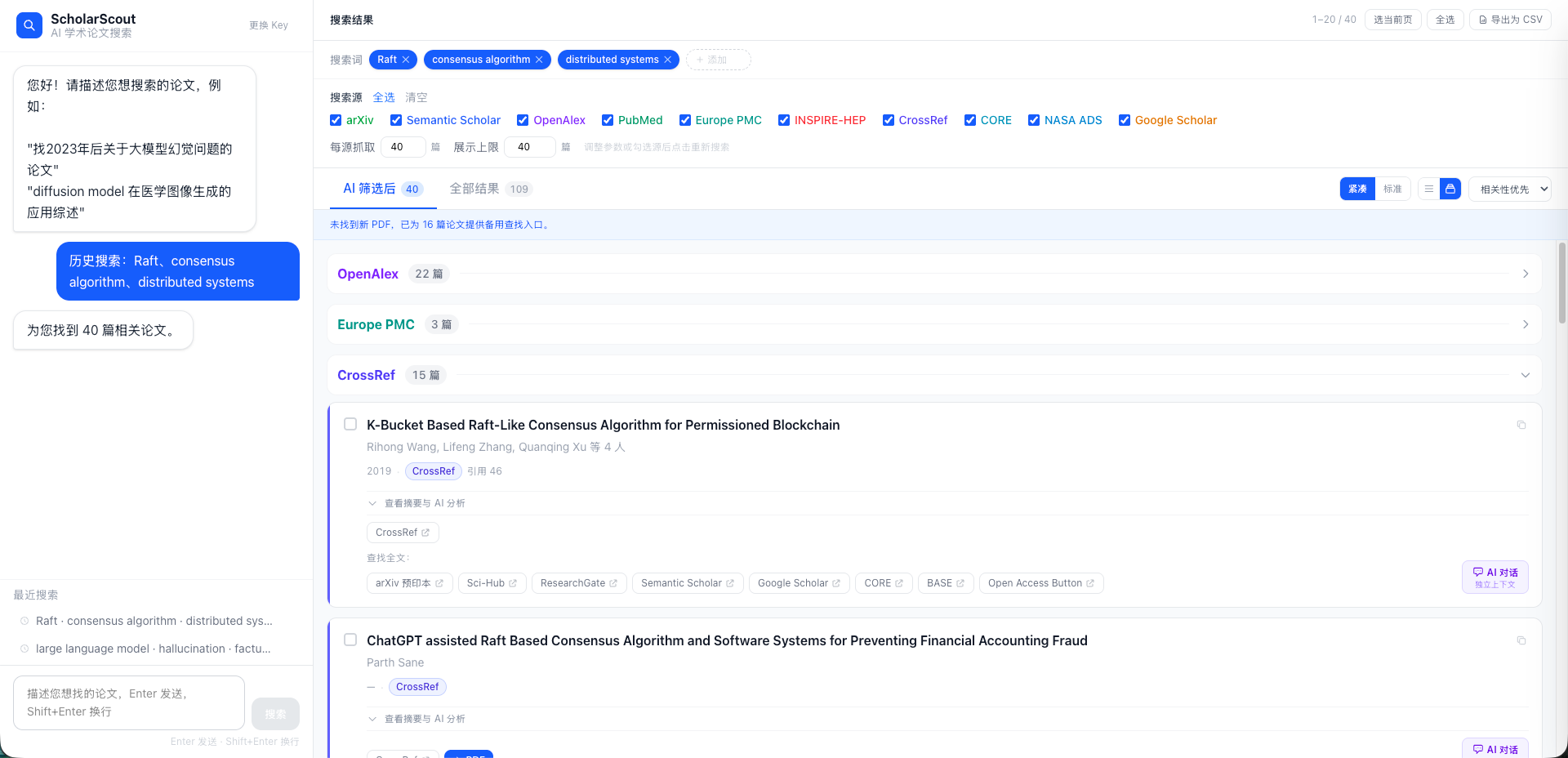
2. 10 个数据库并发搜索
同时搜索以下数据源,结果自动去重合并:
| 数据源 | 特点 |
|---|---|
| arXiv | 预印本,CS/物理/数学 |
| Semantic Scholar | AI 领域最强,有引用图谱 |
| PubMed | 生物医学权威库 |
| OpenAlex | 覆盖面最广的开放数据库 |
| CrossRef | DOI 元数据最全 |
| CORE | 开放获取论文聚合 |
| Europe PMC | 欧洲生命科学 |
| INSPIRE-HEP | 高能物理专属 |
| NASA ADS | 天文航空专属 |
| Google Scholar | 覆盖最广,兜底 |
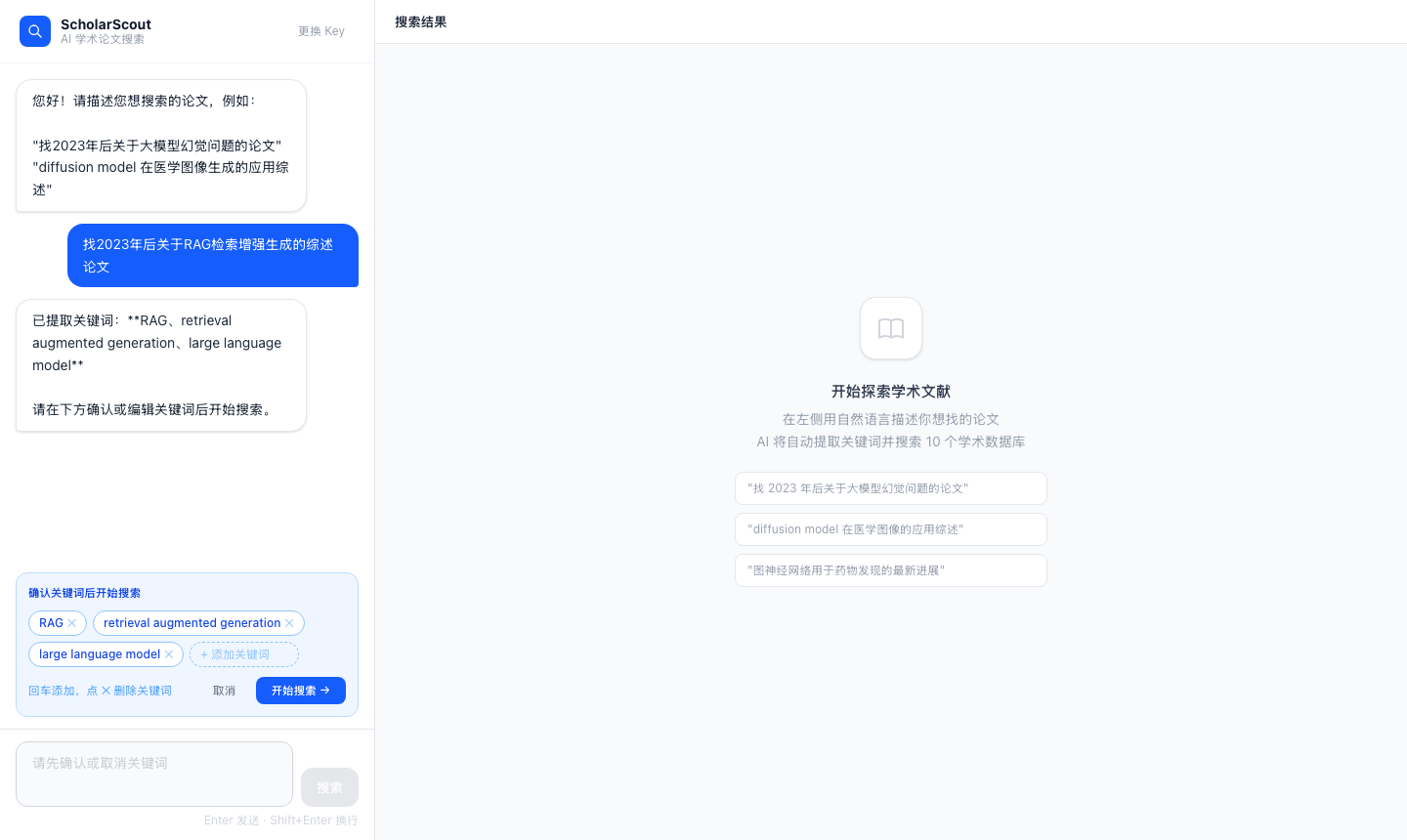
3. AI 相关性筛选
搜到的论文先经过 DeepSeek 过滤一遍,低相关的打上标记单独展示,高相关的排在前面。支持 Tab 切换查看"AI 筛选后"和"全部结果"。
4. 每篇论文独立 AI 对话
这个是我个人最喜欢的功能。每篇论文右侧有一个按钮,点开会滑出一个对话抽屉,可以直接问:
- "这篇论文的核心方法是什么?"
- "和 XXX 方法相比有什么优势?"
- "这个方法有什么局限性?"
每篇论文的对话历史独立保存,互不干扰。
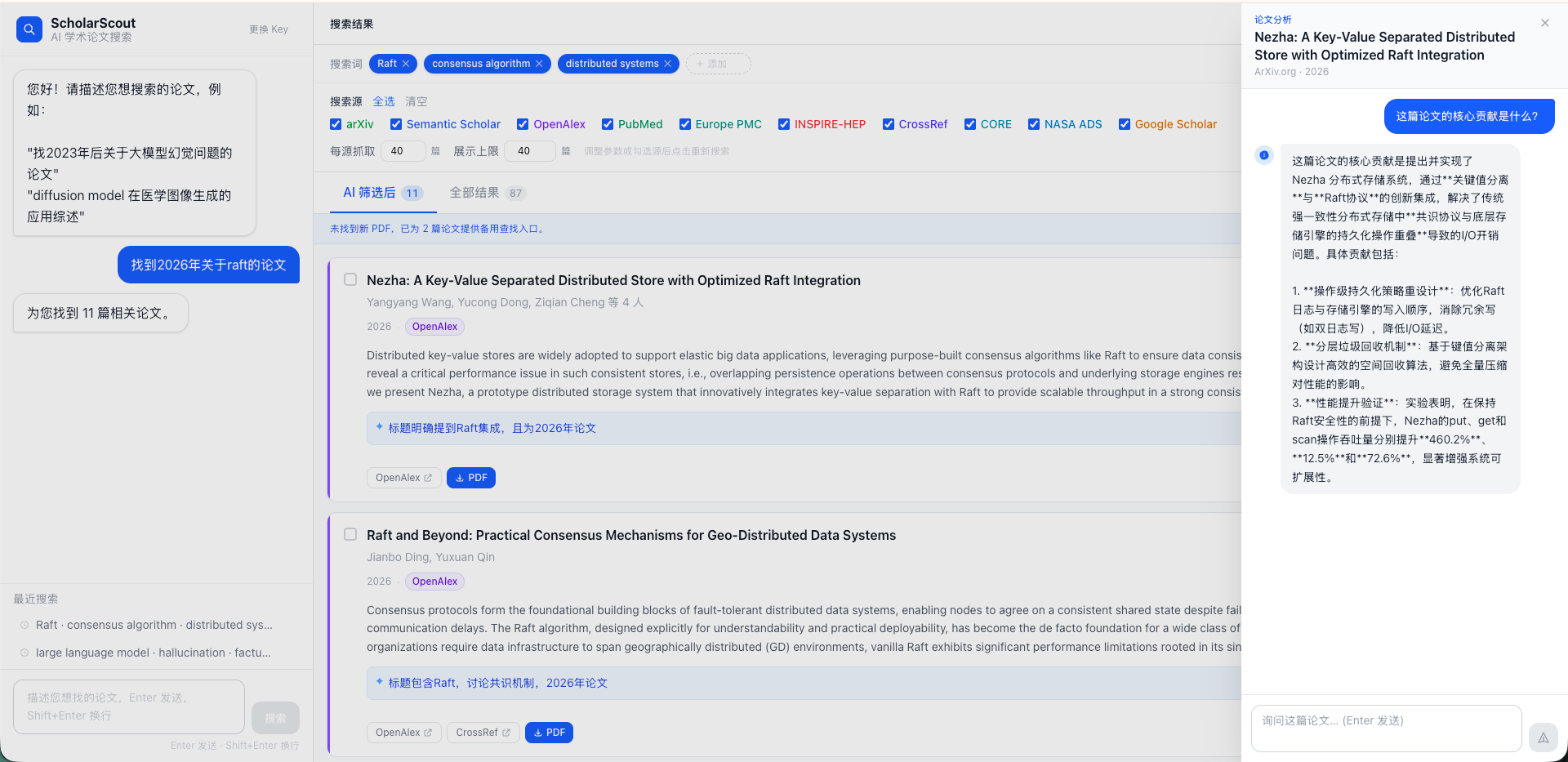
5. 批量下载 PDF + 备用查找
选中感兴趣的论文,一键打包下载 PDF。
对于找不到 PDF 的论文,系统会:
- 调用 Kimi 联网搜索尝试找开放获取版本
- 找不到则自动生成 8 个平台的跳转链接(Google Scholar、Sci-Hub、Unpaywall、Semantic Scholar 等),点击直达
技术实现
整体架构
前端 React + Vite + TypeScript + Tailwind CSS
后端 Python 3.11 + FastAPI
通信 SSE(Server-Sent Events)流式推送
LLM DeepSeek API(用户自备 Key)
Kimi API(服务端,PDF 深度查找)
部署 Nginx + systemd,个人 4C4G 云服务器
统计 Umami 自托管为什么用 SSE 流式推送
搜索过程涉及 10 个数据源并发 + LLM 调用,总耗时可能 10-20 秒。如果等全部结果再返回,用户体验很差。
SSE 可以让后端实时推送每个阶段的进度:
search_start → 告知前端将搜索哪些源
source_done → 每个数据源完成时推送(源名称 + 篇数)
progress → 文字进度提示
done → 全部结果
pdf_update → PDF 深度查找结果(异步补充,不阻塞结果展示)前端会实时展示每个数据源的完成状态(Perplexity 风格的进度网格)。
搜索去重合并
10 个数据源搜出来的论文会有大量重复。去重策略:
- DOI 精确匹配(最可靠)
- 标题规范化后模糊匹配(去除标点、统一小写、计算编辑距离)
- 合并时保留各来源最优字段(优先选有摘要、有 PDF 的版本)
Key 的安全设计
用户的 DeepSeek API Key 只存在浏览器的 localStorage,不会发送到我的服务器(除了每次搜索请求里作为参数直接转发给 DeepSeek,不落库不记录)。
后端做了基础安全加固:
- Nginx 限速(搜索接口 5次/分钟,防滥用)
- 下载接口域名白名单(SSRF 防护)
- 请求体大小限制(Pydantic 字段约束)
- 错误信息脱敏(内部异常不暴露给前端)
前端状态管理
没有用 Redux 这类重型方案,全程 React hooks 自定义:
useSearch--- 两阶段搜索(parse → search)+ SSE 事件处理useModel--- 模型选择,localStorage 持久化usePaperChat--- 每篇论文独立对话历史 + 流式输出useSettings--- 搜索参数(数据源多选、条数限制等)useSearchHistory--- 搜索历史,localStorage 持久化
部署
跑在腾讯云轻量服务器(4C4G,Ubuntu)上,用 systemd 管理后端进程,Nginx 做反向代理和静态文件服务,Umami 统计用 Docker Compose 部署。
用 Claude Code 开发的体验
整个项目基本上是用 Claude Code(claude-sonnet-4-6)vibe coding 出来的,自己主要负责提需求、看效果、给反馈,具体的代码实现大部分交给 Claude。
这种开发方式对我来说很顺------不需要记住所有 API 文档,想加什么功能直接描述,Claude 会把涉及的文件都改好,有时候还会主动指出潜在的问题。
当然也踩了不少坑,比如 DeepSeek 的 models.list() 返回格式和 openai SDK 预期不一致、Umami v2 Docker 镜像不支持 BASE_PATH 环境变量、nginx subpath 代理的 trailing slash 问题......这些都是真实踩过的坑。
局限性(诚实说一下)
- 服务器是个人小机器,并发能力有限,访问人多了可能会慢
- 中文论文支持很差(基本不支持),10 个数据源基本都是英文为主
- 部分数据源(Google Scholar)有反爬限制,偶尔会搜不到
- PDF 找不到的情况仍然存在,尤其是较新的付费期刊
试用
需要一个 DeepSeek API Key(免费注册:https://platform.deepseek.com),Key 仅存本地。
有问题、建议、或者想聊聊的,联系邮箱在网站底部。
只是自己做着玩的工具,能帮到人就很开心 😃
Built with Claude Code · 开源:https://github.com/Dshuishui/ScholarScout