学习目标:
1.理解信息熵的意义
2.理解信息增益的作用
3.知道ID3树的构建流程
(ID3决策树是通过信息增益来进行划分的,信息增益:信息增益 = 熵 - 条件熵,熵?条件熵?ID3树的构建是根据信息增益来构建的,信息增益越大,越优先参考;)
1. 信息熵

(随机变量的不确定度即这些随机变量是有序的还是无序的 即 熵代表数据的混乱程度 :数据越乱熵越大、数据越规整熵越小 ;熵越大,数据的不确定性度越高,信息就越多熵越小,数据的不确定性越低。
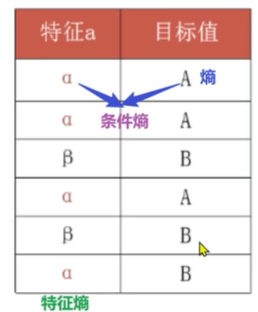
熵计算公式:(信息)熵 = ∑ - 分类占比 * log2(分类占比) :(信息)熵 等于 分类占比 乘以 log以2为底、分类占比的对数,在取负数,再加西格玛∑做求和 表示把每个分类的占比都乘以 log2(分类占比),有几个分类就乘以几次,最终∑ 做求和 。对于数据α 来讲:熵表示其混乱程度,有几个分类要算几次:有8个数据即8个分类:首先对于 A: -1/8 * log2(1/8) =3/8 A占比1/8 乘以 以2为底 1/8的对数:log2(1/8)计算:log2(8的-1次方),将-1前置,则log2(8)=3、3*(-1)=-3、-3*(-1/8)=3/8、对于B、C、...H
:都是一样的即 ∑ 相加8次即乘以8,最终结果为:3。对于数据β :对于A:-1/2 * log2(1/2) =1/2、对于B:-1/4 * log2(1/4) =1/2、对于C、D: -1/8 * log2(1/8) =3/8,所以最终结果为:1/2 + 1/2 +3/8 +3/8 =7/4
计算方法:-∑i=0~n:表示 负的累加和,P(xi)表示 数据中类别出现的概率即 分类占比)
2. 信息增益
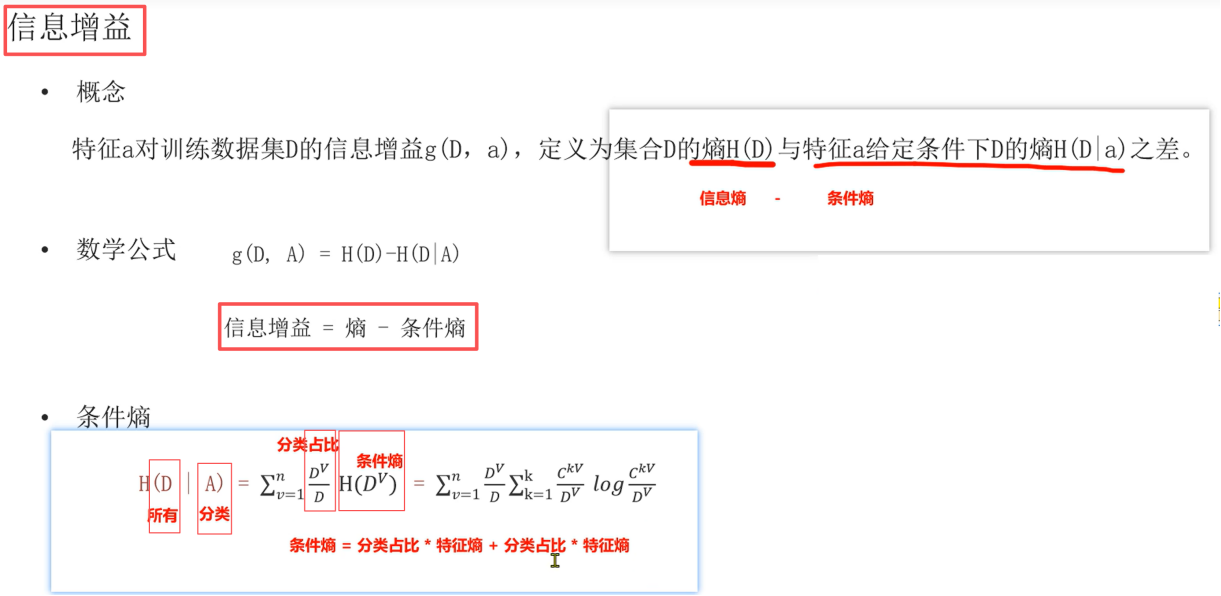
(集合D的熵H(D) 即 信息熵,特征a给定条件下D的熵H(Da) 即 条件熵,信息增益=信息熵-条件熵;信息熵即为熵,所有的熵;
条件熵的计算:D代表所有,A代表某个分类,Dv/D 即为分类占比,H(Dv)即为条件熵;条件熵=A分类占比*A的条件熵+ B分类占比*B的条件熵)
3. ID3决策树
ID3树核心思想:优先参考信息增益大的特征列充当上层节点;
ID3树的不足:偏向于选择种类多的特征作为分裂依据;
3.1 ID3决策树构建流程
1️⃣ 计算每个特征的信息增益;
2️⃣使用信息增益最大的特征将数据集 拆分为子集;
3️⃣ 使用该特征(信息增益最大的特征)作为决策树的一个
节点;
4️⃣ 使用剩余特征对子集重复上述(1,2,3)过程;
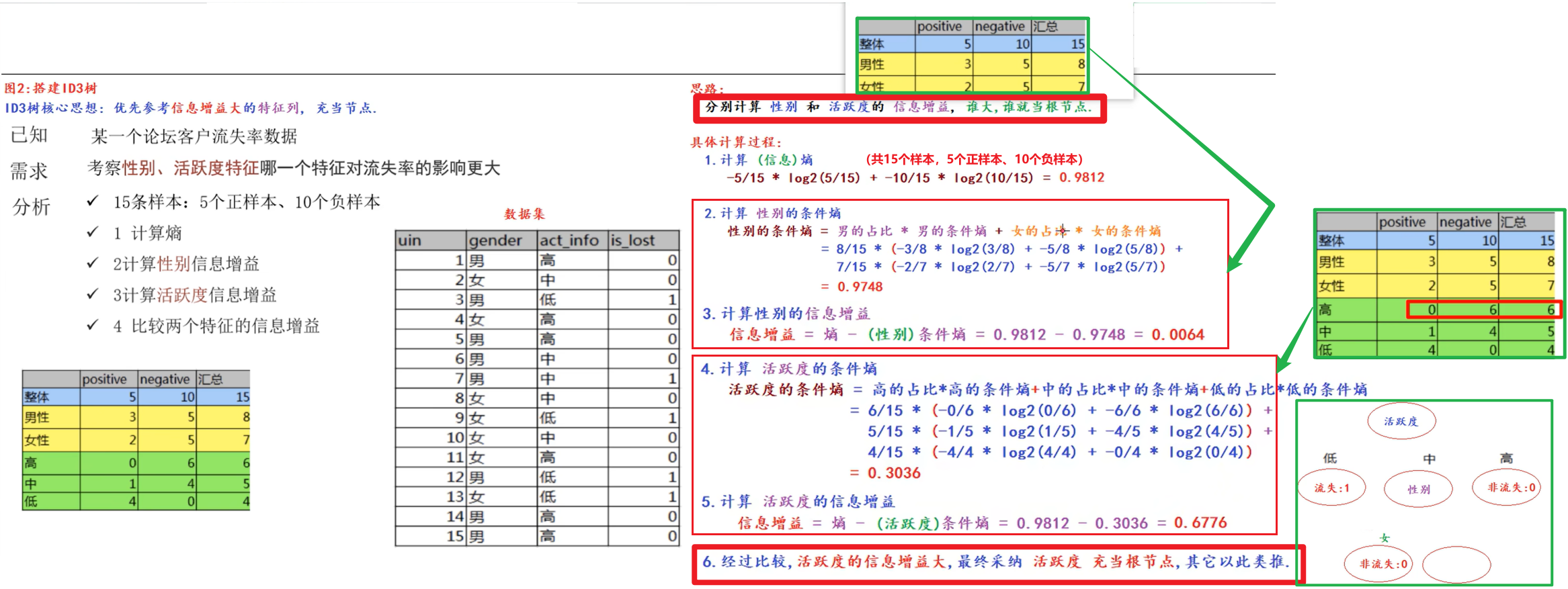
(ID3树核心思想:优先参考信息增益大的特征列充当上层节点。
思路:分别计算 性别 和 活跃度的 信息增益,谁大,谁就当根节点;
具体计算过程:
①计算信息熵(各类别的占比):一共15个样本,5个正、10个负;
②计算性别的条件熵、信息增益;
③计算活跃度的条件熵、信息增益;
④比较大小,确定根节点。)
4. 总结:
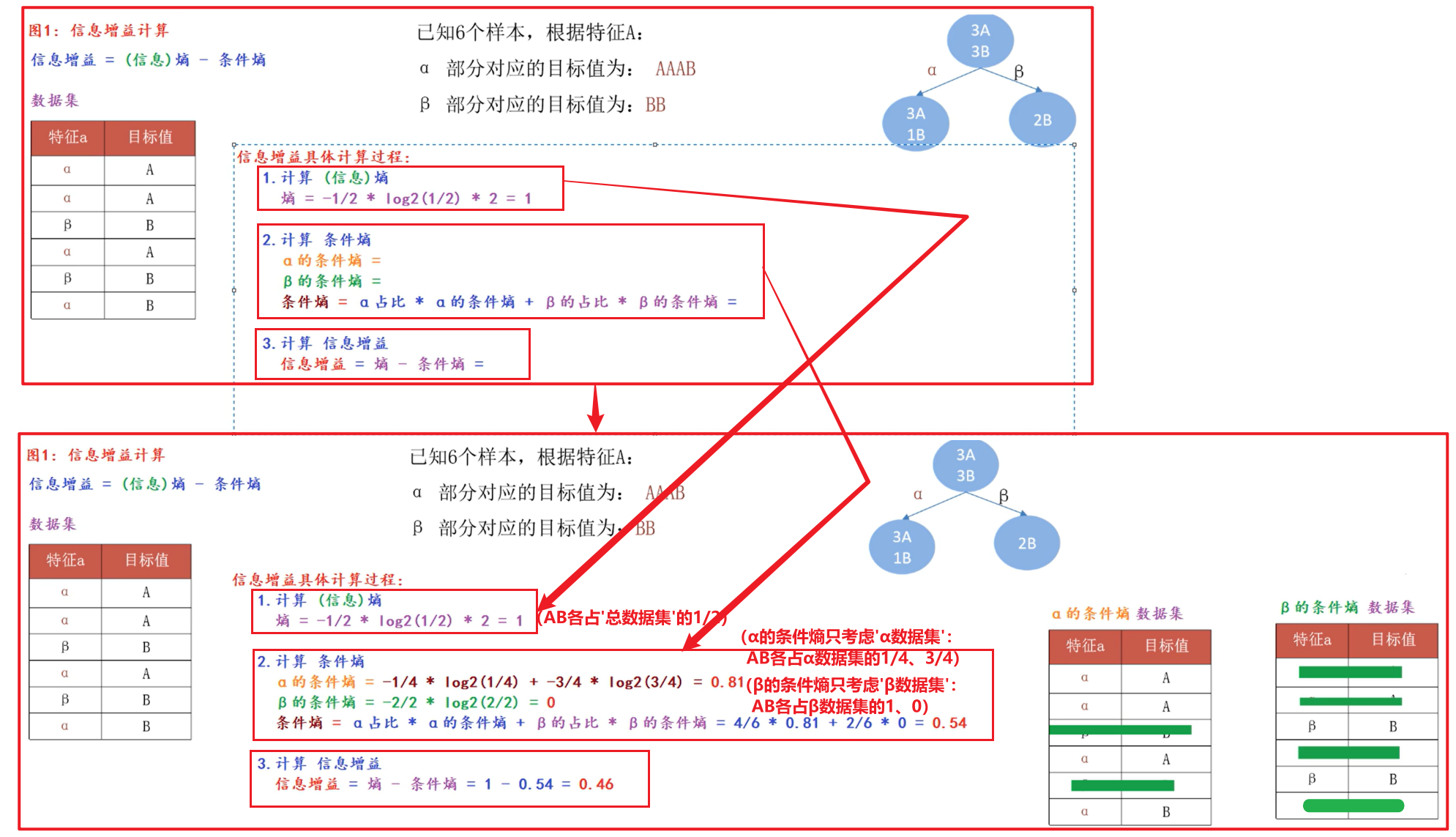
 (对于ID3树:采用信息增益来划分,信息增益越大,越优先充当根节点;但它会存在一个问题:假设有好几列特征,对于信息增益的计算:哪一列的数据值越多即分类越多则增益越大,即分类越多越容易充当根节点,这样不太好;因此C4.5给定了一个惩罚系数,
(对于ID3树:采用信息增益来划分,信息增益越大,越优先充当根节点;但它会存在一个问题:假设有好几列特征,对于信息增益的计算:哪一列的数据值越多即分类越多则增益越大,即分类越多越容易充当根节点,这样不太好;因此C4.5给定了一个惩罚系数,惩罚系数 = 信息增益率 = 信息增益 * (1/特征熵) = 信息增益 * 特征熵的倒数 = 信息增益 / 特征熵 :特征熵越大,惩罚系数越小;
1️⃣(信息) 熵 :表示数据的混乱程度;(如图)拿着 目标值 计算出的就是 熵 ,AB各占总数的3/6:熵 = -1/2 * log2(1/2) * 2 = 1;
2️⃣ 条件熵 :(α的占比 * α的条件熵) + (β的占比 * β的条件熵)
① α的占比=4/6、α的条件熵 = -3/4 * log2(3/4) + -1/4 * log2(1/4);
② β的占比=2/6 、β的条件熵 = -1 * log2(1) ;
③ 条件熵 = (α的占比 * α的条件熵) + (β的占比 * β的条件熵);
即条件熵 只考虑当前类别的数据集,不考虑其他类别的数据集;
基于 特征(当前类别的数据集的占比) 和 熵(当前类别的条件熵) 一起计算的叫做条件熵(即拿着 特征α和目标值计算出来的就是 条件熵 );
信息增益 = 熵 - 条件熵 ;
3️⃣ 特征熵 :
不需要 目标值列,只需要 特征α列,即拿着 特征α 算出来的就是 特征熵;)
5. C4.5树
学习目标:
1.理解信息增益率的意义;
2.知道C4.5树的构建方法;
(C4.5决策树是基于ID3决策树做的一种优化。C4.5存在的原因?:因为ID3是采用信息增益来做划分,即数据越混乱,信息增益就越大,即某一列数据划分种类越多熵越大,越优先被选择,这样容易造成过拟合,因此使用C4.5这种解决方案,不再用信息增益,而是使用信息增益率;)
5.1 信息增益率
1️⃣ 信息增益率:
信息增益率= 信息增益/ 特征熵
相当于对信息增益进行修正,增加一个惩罚系数;
2️⃣ 信息增益率的作用:
信息增益偏向于选择种类多的特征作为分裂依据;缓解ID3树中存在的不足(其不足是:优先选择分类多的那一列)
 (
(信息增益率=信息增益 / 特征熵 即 信息增益率=信息增益 * 1/特征熵,惩罚系数=特征熵的倒数,特征熵越大,其倒数(1/特征熵) 越小;
信息增益率的本质:是特征的信息增益 除以 特征的内在信息,内在信息即特征熵;相当于对信息增益进行修正,增加一个惩罚系数,特征熵越大、惩罚系数就越小;特征取值个数越多、信息增益越大,惩罚系数就越小,特征熵就越大;
ID3是根据特征列的特征越多越优先划分、C4.5特征越少越优先划分,根据少划分会比多的划分更合适,因为子节点更少;)