一、为什么普通的IP查询已经不够用了?
某跨境电商平台的风控团队发现一个异常模式:大量来自"广东省深圳市"的订单,收件地址却集中在东南亚某国。进一步排查发现,这些订单的IP地址虽然显示为深圳,但实际来源于一个部署在深圳数据中心的代理服务器,真正的买家远在数千公里之外。普通的城市级IP查询在这里完全失效。
在广告投放领域,某教育类App的运营团队发现,大量"北京"用户的点击转化率极低。使用高精度IP定位后发现,超过60%的"北京"流量实际来自数据中心和代理节点,真实北京用户占比不足30%------相当于每月数十万元的广告预算打了水漂。
这些案例揭示了一个核心问题:在反欺诈、精准营销、内容合规等场景中,城市级的IP定位精度已经远远不够 。IP地理位置精准查询------能够提供区县级乃至街道级定位的服务,正成为企业数字基础设施的关键组件。

二、IP地理位置定位的技术原理
传统IP定位的三层架构
普通IP地理位置查询主要依赖IP地址库匹配,其技术架构分为三个层次:
| 层级 | 数据来源 | 精度 | 更新频率 | 典型应用 |
|---|---|---|---|---|
| L1 基础库 | WHOIS注册信息、RIR分配记录 | 国家/省级 | 月更/年更 | 基础统计 |
| L2 运营数据库 | ISP互联协议、路由公告 | 城市级 | 周更 | 内容分发 |
| L3 精准库 | 多源数据融合、机器学习校正 | 区县/街道级 | 日更 | 反欺诈、精准营销 |
前插行后插行
L1基础库依赖的是互联网号码分配机构(IANA)和各地区互联网注册机构(RIR,如APNIC、ARIN)的公开分配记录。这些数据只能精确到国家或省级,因为IP地址在分配时仅记录了接收机构的国家信息。
L2运营数据库通过BGP路由公告、ISP互联协议等网络层面的数据,将IP地址映射到具体的城市和运营商。这个级别的数据来自各大ISP(如中国电信、中国联通)的实际网络部署,覆盖大部分固定宽带IP。
L3精准库是当前高精度IP定位的核心。它不再单纯依赖网络层面的数据,而是通过机器学习、地理信息系统交叉验证、用户行为分析等多源数据融合,将IP定位精度提升到区县甚至街道级别。
从城市级到街道级:精度的跃升是如何实现的?
普通IP查询的精度通常停留在城市级别(误差10-50公里),而IP精准定位服务可以将精度提升到区县级(误差2-5公里),部分场景甚至可达到街道级(误差2公里以内)。这一质的飞跃依赖于以下几种关键技术:
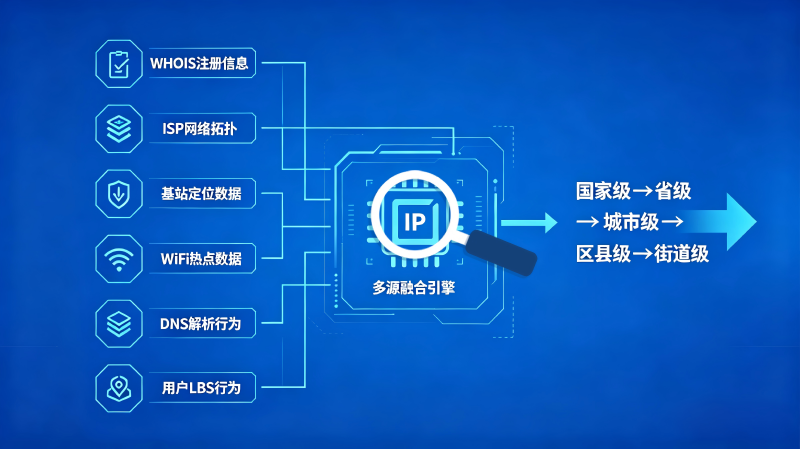
1. 多源数据融合技术
高精度IP定位不再是简单的"查表",而是通过融合多种数据源进行交叉验证:
2. 基站与WiFi辅助定位
对于移动网络IP,运营商的基站数据可以提供高精度位置信息。中国三大运营商拥有超过800万个基站,每个基站的经纬度坐标是已知的。当用户通过移动网络访问时,虽然外部看到的是运营商网关IP(通常定位在省会级别),但高精度定位服务可以通过与运营商合作,获取基站级别的精确位置。
WiFi热点定位的原理类似:当设备连接WiFi时,通过周围WiFi热点的信号强度和已知坐标,可以将定位精度提升到街道甚至建筑级别。
3. 机器学习校正模型
传统的IP地址库往往存在"一刀切"的问题------将一个/24网段(256个IP)的所有地址都标注为同一个位置。实际上,同一网段内的IP可能分布在城市的不同区域。机器学习模型可以通过分析历史数据中的位置分布模式,将大范围的网段校准到更精确的子区域:
-
特征工程:提取ASN特征、延迟特征、路由路径特征、时间序列特征
-
模型训练:以已知的高精度位置数据(如GPS、LBS数据)为标注,训练回归模型
-
预测校准:模型对未知IP自动输出更精细的位置估计
三、高精度IP定位查询能返回什么?
相比城市级IP查询的寥寥几个字段,高精度IP定位查询可返回20余个维度的数据:
| 数据维度 | 示例值 | 精度层次 | 应用价值 |
|---|---|---|---|
| ip | 14.150.197.228 | IPv4 | 查询对象 |
| country | 中国 | 国家级 | 基础筛选 |
| country_code | CN | 国家级 | 国际标准 |
| province | 广东省 | 省级 | 区域业务 |
| city | 东莞市 | 城市级 | 内容分发 |
| district | 东城区 | 区县级★ | 精准营销 |
| street | 李横路 | 街道级★★ | 反欺诈判断 |
| longitude | 113.9239 | 高精度坐标 | 地图可视化 |
| latitude | 23.1013 | 高精度坐标 | 距离计算 |
| radius | 2.00km | 定位误差半径 | 精度评估 |
| isp | 中国电信 | 运营商 | 网络分析 |
| asn | AS4134 | 自治域 | 溯源分析 |
| usage_type | 移动网络 | 网络类型 | 风险识别 |
| proxy | 否 | 是否代理 | 代理检测 |
关键解读 :在反欺诈场景中,district(区县)和usage_type(网络类型)是最有价值的两个字段。如果用户声称在"福田区"办公,但IP定位显示在"宝安区"且usage_type为"数据中心",则极大概率是虚假身份。
四、高精度IP定位查询的应用场景
场景一:金融反欺诈
银行和金融机构是高精度IP定位的最大应用方之一:
-
贷前审核:判断申请人IP与填写的居住城市是否匹配。如申请人填写"杭州"但IP定位为某边远省份的二三线城市,触发人工复核
-
交易风控:对大额转账时,如果IP定位在境外或被标记为代理IP,实时拦截或进行多重身份验证
-
额度管理:根据IP定位的城市消费水平,动态调整新用户的初始额度
某国有银行在信用卡线上申请环节接入高精度IP定位后,首月拦截可疑申请超过3万笔,虚假申请识别率提升42%。
场景二:电商防薅羊毛
在秒杀、促销场景中,IP精准定位可以有效识别批量刷单行为:
-
当检测到同一区县IP段内短时间内大量参与活动时,触发人机验证
-
结合IP和收件地址的地理距离:距离超过阈值自动拦截
-
对
usage_type为"数据中心"的IP限制参与优惠活动
场景三:广告投放反欺诈
数字广告领域,每年因虚假流量造成的损失高达数百亿美元:
-
识别来自数据中心、代理服务器的虚假曝光和点击
-
验证广告投放的地域精准度------如果广告定向"上海市"但高精度定位显示大部分流量来自国内其他城市甚至境外代理,立即暂停投放
-
过滤无效流量,提升广告投放的ROI
场景四:内容合规与本地化
-
内容分发:视频、游戏平台根据用户IP定位到区县级别,推送本地化内容(方言版本、地域特色内容)
-
合规屏蔽:根据法规要求,精确屏蔽特定区域的访问权限(如某省份的特定内容限制)
-
O2O精准推荐:本地生活平台根据用户IP街道级定位,推荐最近的门店和服务

五、API集成实战:Python调用高精度IP定位
以下代码展示如何集成高精度IP定位查询API(使用IP数据云的接口作为示例),并基于返回结果构建风控决策引擎:
import requests
import hashlib
import time
from dataclasses import dataclass, field
from typing import Optional, List
@dataclass
class IPGeoResult:
"""高精度IP定位返回结果"""
ip: str
province: str
city: str
district: str
longitude: float
latitude: float
radius: float # 定位误差半径(km)
isp: str
asn: str
usage_type: str # 网络类型: 住宅宽带/数据中心/移动网络
risk_score: int # 0-100
accuracy: str # 定位精度: 城市级/区县级/街道级
def is_datacenter(self) -> bool:
return self.usage_type == "数据中心"
def location_str(self) -> str:
return f"{self.province}{self.city}{self.district}"
class HighPrecisionIPLocator:
"""高精度IP定位查询客户端"""
# 精度等级映射
ACCURACY_RANK = {
"国家级": 0,
"省级": 1,
"城市级": 2,
"区县级": 3,
"街道级": 4
}
def __init__(self, api_key: str, base_url: str = "https://api.ipdatacloud.com"):
self.api_key = api_key
self.base_url = base_url.rstrip('/')
self._cache: dict[str, tuple[IPGeoResult, float]] = {} # {ip: (result, timestamp)}
self._cache_ttl = 3600 # 1小时
def locate(self, ip: str, bypass_cache: bool = False) -> Optional[IPGeoResult]:
"""
高精度IP地理位置查询
Args:
ip: 目标IP地址
bypass_cache: 是否跳过缓存
Returns:
IPGeoResult或None
"""
# 检查缓存
if not bypass_cache:
cached = self._cache.get(ip)
if cached:
result, ts = cached
if time.time() - ts < self._cache_ttl:
return result
# 内网IP快速返回
if self._is_private_ip(ip):
return None
url = f"{self.base_url}/v2/ip_query"
params = {
"ip": ip,
"key": self.api_key,
"fields": "province,city,district,longitude,latitude,radius,"
"isp,asn,usage_type,risk_score,accuracy"
}
try:
resp = requests.get(url, params=params, timeout=0.8)
data = resp.json()
if data.get("code") != 200:
return None
d = data.get("data", {})
result = IPGeoResult(
ip=d.get("ip", ip),
province=d.get("province", ""),
city=d.get("city", ""),
district=d.get("district", ""),
longitude=float(d.get("longitude", 0)),
latitude=float(d.get("latitude", 0)),
radius=float(d.get("radius", 999)),
isp=d.get("isp", ""),
asn=d.get("asn", ""),
usage_type=d.get("usage_type", ""),
risk_score=int(d.get("risk_score", 0)),
accuracy=d.get("accuracy", "城市级")
)
# 写入缓存
self._cache[ip] = (result, time.time())
return result
except Exception as e:
print(f"定位失败 [{ip}]: {e}")
return None
def accuracy_meets(self, result: IPGeoResult, minimum: str) -> bool:
"""判断定位精度是否达到最低要求"""
return self.ACCURACY_RANK.get(result.accuracy, 0) >= self.ACCURACY_RANK.get(minimum, 0)
@staticmethod
def _is_private_ip(ip: str) -> bool:
private_prefixes = (
'10.', '172.16.', '172.17.', '172.18.', '172.19.',
'172.20.', '172.21.', '172.22.', '172.23.',
'172.24.', '172.25.', '172.26.', '172.27.',
'172.28.', '172.29.', '172.30.', '172.31.',
'192.168.', '127.', '::1', 'fc00:', 'fe80:'
)
return any(ip.startswith(p) for p in private_prefixes)
# ===== 风控决策引擎示例 =====
class FraudDecisionEngine:
"""基于高精度IP定位的风控决策引擎"""
def __init__(self, locator: HighPrecisionIPLocator):
self.locator = locator
# 可配置的风险规则
self.rules = [
self._rule_datacenter,
self._rule_proxy_detected,
self._rule_location_mismatch,
self._rule_geo_jump,
]
def assess(self, ip: str, claimed_location: str = "",
user_history: list = None) -> dict:
"""综合风险评估"""
geo = self.locator.locate(ip)
if geo is None:
return {"decision": "allow", "reason": "no_geo_data", "score": 0}
score = 0
reasons = []
# 规则1: 数据中心IP
if self._rule_datacenter(geo):
score += 50
reasons.append("datacenter_ip")
# 规则2: 高风评分
if geo.risk_score >= 80:
score += 30
reasons.append(f"high_risk_score_{geo.risk_score}")
# 规则3: 地理位置不匹配
if claimed_location and self._rule_location_mismatch(geo, claimed_location):
score += 20
reasons.append("location_mismatch")
# 规则4: 地理跳跃
if user_history:
if self._rule_geo_jump(geo, user_history):
score += 25
reasons.append("geo_jump")
# 决策输出
if score >= 70:
decision = "block"
elif score >= 40:
decision = "verify"
else:
decision = "allow"
return {
"decision": decision,
"score": score,
"reasons": reasons,
"geo": {
"location": geo.location_str(),
"accuracy": geo.accuracy,
"usage_type": geo.usage_type,
"risk_score": geo.risk_score
}
}
@staticmethod
def _rule_datacenter(geo: IPGeoResult) -> bool:
return geo.is_datacenter()
@staticmethod
def _rule_location_mismatch(geo: IPGeoResult, claimed: str) -> bool:
"""判断IP位置与声称的不匹配"""
claimed_set = set(claimed.replace('市', '').replace('区', ''))
actual_set = set((geo.province + geo.city + geo.district)
.replace('市', '').replace('区', ''))
return not claimed_set.issubset(actual_set)
@staticmethod
def _rule_geo_jump(geo: IPGeoResult, history: list) -> bool:
"""判断短时间内地理跳跃"""
if len(history) < 2:
return False
prev = history[-1]
# 简易距离判断:不同省份即触发
if prev.get("province") != geo.province:
return True
return False
# ===== 使用示例 =====
if __name__ == "__main__":
# 1. 初始化定位客户端
locator = HighPrecisionIPLocator(api_key="your_api_key_here")
# 2. 高精度IP定位查询
result = locator.locate("203.0.113.45")
if result:
print(f"IP: {result.ip}")
print(f"位置: {result.location_str()}")
print(f"精度: {result.accuracy} (误差 ~{result.radius}km)")
print(f"网络类型: {result.usage_type}")
print(f"风险评分: {result.risk_score}")
# 精度判断
if locator.accuracy_meets(result, "区县级"):
print("✓ 满足区县级精度要求")
else:
print("✗ 精度不足,建议升级服务")
# 3. 风控决策引擎
engine = FraudDecisionEngine(locator)
# 模拟场景:用户声称位于深圳市福田区
verdict = engine.assess(
ip="203.0.113.45",
claimed_location="深圳市福田区"
)
print(f"\n风控决策: {verdict['decision']}")
print(f"风险评分: {verdict['score']}")
print(f"触发规则: {verdict['reasons']}")六、IP精准定位服务对比
| 服务商 | 最高精度 | 查询方式 | 免费额度 | IPv6支持 | 特色能力 |
|---|---|---|---|---|---|
| IP数据云 | 街道级 | API/离线库 | 免费试用 | ✓ | 风险评分+代理检测+威胁标签 |
| IPnews | 城市级 | 离线库/API | 10000次免费查询 | ✓ | IP画像多维度数据 |
| OpenGPS | 街道级 | Web查询 | 免费查询 | 部分 | 多数据源融合,警用级精度 |
选型核心指标
选择IP精准定位服务时,建议按以下权重进行评估:
-
定位精度 (权重35%):是否满足业务最低精度要求(如"至少区县级")
-
API响应速度 (权重25%):风控场景要求毫秒级响应(P99 < 50ms)
-
数据更新频率 (权重20%):日更是最低要求,实时更新更佳
-
覆盖率 (权重10%):IPv4和IPv6的全球/全国覆盖率
-
附加能力 (权重10%):风险评分、代理检测、威胁标签等
七、高精度IP定位的局限与误区
误区一:"高精度意味着100%准确"
所有IP定位本质上都是概率推断,不存在100%准确的IP定位服务。街道级定位的准确性通常在85%-95%之间,区县级在90%-98%之间。特别是对于以下场景,精度会显著下降:
-
移动网络IP:手机用户通过运营商NAT网关出口,外部只能看到省级汇聚点的IP
-
VPN与代理IP:实际物理位置被VPN服务器位置替代
误区二:"IP定位越精细越好"
定位精度与覆盖范围是矛盾的。街道级定位通常只覆盖一线城市的固定宽带IP,而在三四线城市或移动网络中可能退化到城市级。根据业务需求选择合适的精度等级,比盲目追求最高精度更务实。
误区三:"买了高精度IP库就一劳永逸"
IP地址是动态分配的------家庭宽带的IP可能每天更换,数据中心IP可能每小时更换。高精度IP定位查询必须依赖持续更新的数据库,静态库在3个月后准确率可能下降30%-50%。
总结
IP地理位置精准查询正在从"锦上添花"变成企业的"刚需基础设施"。从城市级到区县级再到街道级的精度提升,不仅仅是数据的进步,更是反欺诈、精准营销、内容分发等场景能力的质变。
对于技术团队而言,选择高精度IP定位服务时需权衡精度、速度、成本三大维度,并建立自己的缓存、降级和风控决策体系。IP定位从来不是孤立的------与设备指纹、行为分析、多头数据形成多维度联防体系,才是数字时代企业风控的正确姿势。