1.环境变量
1-1 环境变量的基本概念
1. 什么是环境变量
环境变量是操作系统层面维护的一组键值对(KEY=VALUE),它们构成了程序运行时的环境上下文,影响着操作系统、Shell 会话以及运行在其中的进程的行为。
2. 命令行参数
在 C/C++ 程序中,main 函数可以接收参数。它的标准形式有两个参数:
-
int argc:命令行参数的个数。 -
char* argv[]:命令行参数数组,每个元素指向一个参数字符串。
用以下代码可以打印所有参数:
cpp
#include <stdio.h>
//main函数也有参数
int main(int argc,char* argv[])
{
for(int i=0;i<argc;i++)
printf("argv[%d]:%s\n",i,argv[i]);
return 0;
}运行结果:
bash
xqq@ubuntu-server:~/linux/moduleVI$ ./code.exe
argv[0]:./code.exe
xqq@ubuntu-server:~/linux/moduleVI$ ./code.exe a
argv[0]:./code.exe
argv[1]:a
xqq@ubuntu-server:~/linux/moduleVI$ ./code.exe a b
argv[0]:./code.exe
argv[1]:a
argv[2]:b
xqq@ubuntu-server:~/linux/moduleVI$ ./code.exe a b c
argv[0]:./code.exe
argv[1]:a
argv[2]:b
argv[3]:c可以观察到:Shell 按空格将整行命令拆分成多个字符串,依次存入 argv 数组。argc 记录有效元素个数,标准规定 argv[argc]即最后一个元素 为空指针 NULL。
命令行参数的实际意义在于:让同一个程序通过不同选项实现不同功能。下面是一个示例:
bash
xqq@ubuntu-server:~/linux/moduleVI$ cat code.c
#include <stdio.h>
#include<string.h>
//main函数也有参数
int main(int argc,char* argv[])
{
if(argc!=2)
{
printf("Usage: %s [-a|-b|-c]\n",argv[0]);
return 1;
}
const char*arg=argv[1];
if(strcmp(arg,"-a")==0)
printf("这是功能a\n");
else if(strcmp(arg,"-b")==0)
printf("这是功能b\n");
else if(strcmp(arg,"-c")==0)
printf("这是功能c\n");
else
printf("Usage: %s [-a|-b|-c]\n",argv[0]);
return 0;
}
xqq@ubuntu-server:~/linux/moduleVI$ ./code.exe
Usage: ./code.exe [-a|-b|-c] #提示用法
xqq@ubuntu-server:~/linux/moduleVI$ ./code.exe -a
这是功能a
xqq@ubuntu-server:~/linux/moduleVI$ ./code.exe -b
这是功能b
xqq@ubuntu-server:~/linux/moduleVI$ ./code.exe -c
这是功能c我们日常使用的 ls、grep 等命令,本质上也是 C 语言编写的可执行程序,它们支持各种选项的原理与上述代码相同。整个流程概括为:Shell 获取命令行输入 → 拆分构建 argv 表 → 传递给程序。
3. PATH 环境变量
我们自己编写的程序需要带路径才能执行(如 ./code.exe),而系统命令(如 ls)却可以直接输入。原因不在于程序本身有区别(都是可执行的二进制文件),而在于系统命令的所在目录被记录在了 PATH 环境变量中。
查看 ls 的实际位置:
bash
xqq@ubuntu-server:~/linux/moduleVI$ which ls
/usr/bin/ls
xqq@ubuntu-server:~/linux/moduleVI$ ls -a
. .. code.c code.exe Makefile
xqq@ubuntu-server:~/linux/moduleVI$ code.exe -a
code.exe: command not found如果我们将code.exe 拷贝到usr/bin目录下,我们也可以像系统命令一样不带路径
bash
xqq@ubuntu-server:~/linux/moduleVI$ ls -dl /usr/bin/
drwxr-xr-x 2 root root 49152 May 2 06:09 /usr/bin/#xqq是other,没有写权限
xqq@ubuntu-server:~/linux/moduleVI$ sudo cp code.exe /usr/bin/
[sudo] password for xqq:
xqq@ubuntu-server:~/linux/moduleVI$ code.exe -a
这是功能a
xqq@ubuntu-server:~/linux/moduleVI$ code.exe -b
这是功能b
xqq@ubuntu-server:~/linux/moduleVI$ sudo rm /usr/bin/code.exe
xqq@ubuntu-server:~/linux/moduleVI$ code.exe -a
-bash: /usr/bin/code.exe: No such file or directory但注意:不推荐我们直接将我们自己写的程序拷贝到/usr/bin/目录下,可能会有各种问题,会污染系统指令池,带来安全隐患。更安全的做法是将自定义目录追加到 PATH 中。
PATH 环境变量详解
- 基本定义
PATH 是一个由目录绝对路径 组成的列表,用冒号 : 分隔。它告诉 Shell:当你输入一个命令时,应该去哪些地方找对应的可执行程序(会按照 PATH 中的顺序逐个目录搜索可执行文件)。
- 工作原理:命令查找流程
当你在终端敲下 code.exe -a 并回车,Shell 的处理顺序是这样的: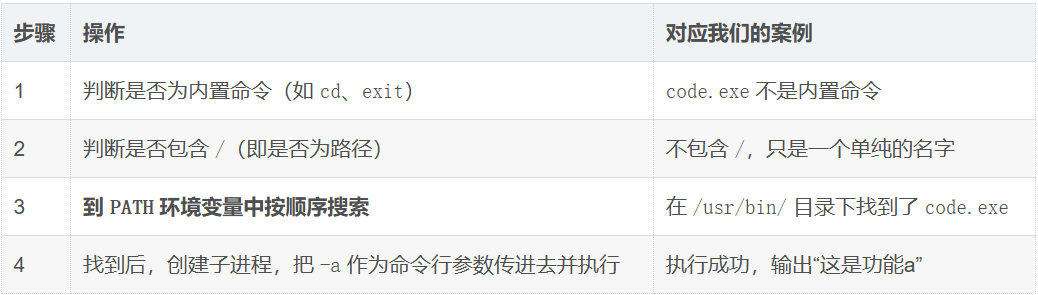
之前能直接运行 code.exe,正是因为 PATH 里包含了 /usr/bin。
也就是说如果我们将我们当前工作目录的绝对路径添加到PATH里,也可以完成像之前一样的效果
3.添加自定义路径到 PATH
bash
xqq@ubuntu-server:~/linux/moduleVI$ pwd
/home/xqq/linux/moduleVI #直接覆盖原路径,虽然能达到效果但无法执行系统命令
xqq@ubuntu-server:~/linux/moduleVI$ PATH=/home/xqq/linux/moduleVI
xqq@ubuntu-server:~/linux/moduleVI$ echo $PATH
/home/xqq/linux/moduleVI #可以重新登陆xshell系统会重新加载PATH,也可以直接将原本路径赋值回去前提你要知道
#正确添加方式
xqq@ubuntu-server:~/linux/moduleVI$ PATH=$PATH:/home/xqq/linux/moduleVI
xqq@ubuntu-server:~/linux/moduleVI$ echo $PATH #当然这样也是临时的,也就是重新登陆xshell就无效了
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin:/home/xqq/linux/moduleVI
#^新加的路径查看环境变量
env命令可查看当前 Shell 的所有环境变量,输出格式统一为KEY=VALUE:
bash
#名称=内容
xqq@ubuntu-server:~/linux/moduleVI$ env
SHELL=/bin/bash
PWD=/home/xqq/linux/moduleVI
LOGNAME=xqq
XDG_SESSION_TYPE=tty
MOTD_SHOWN=pam
HOME=/home/xqq
LANG=en_US.UTF-8
...- 查看单个变量用
echo $变量名(注意加$):
bash
xqq@ubuntu-server:~/linux/moduleVI$ echo PATH#错误写法:将PATH当字符串打印
PATH
xqq@ubuntu-server:~/linux/moduleVI$ echo $PATH#加$
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin1-2 常⻅环境变量
基础变量 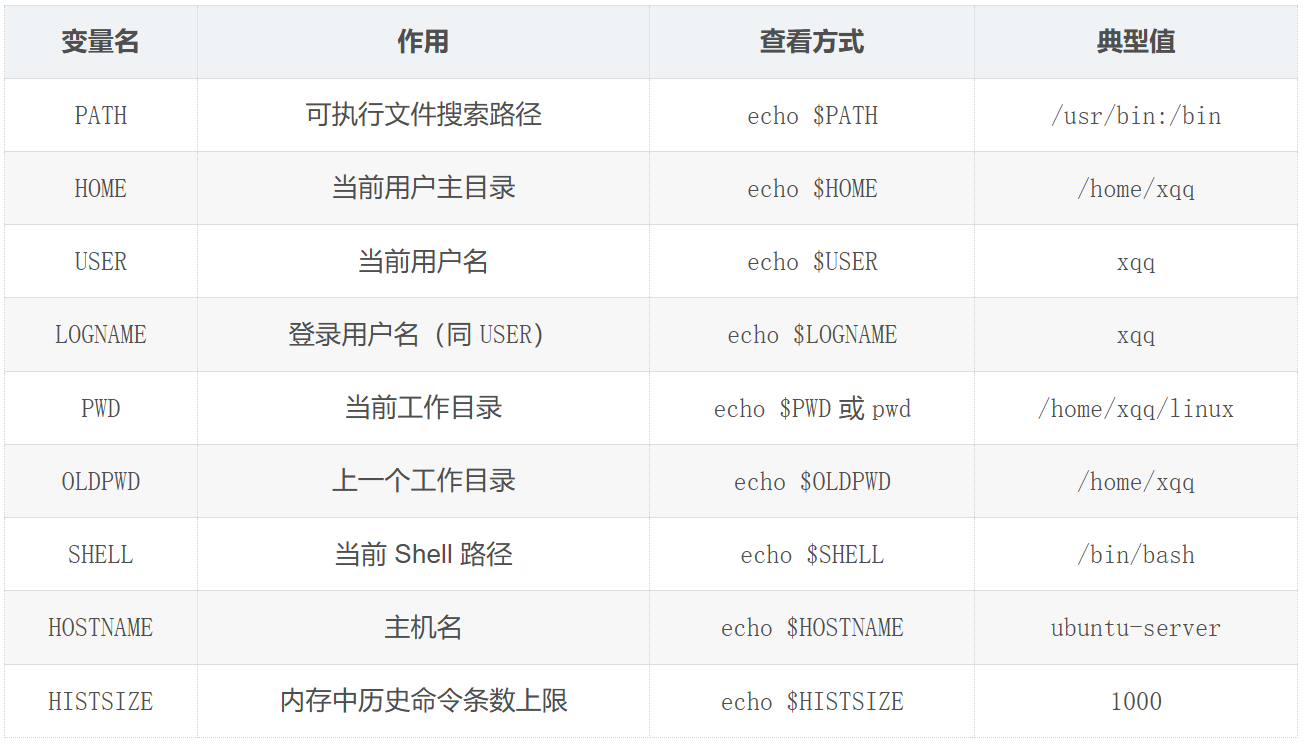
编译与链接相关 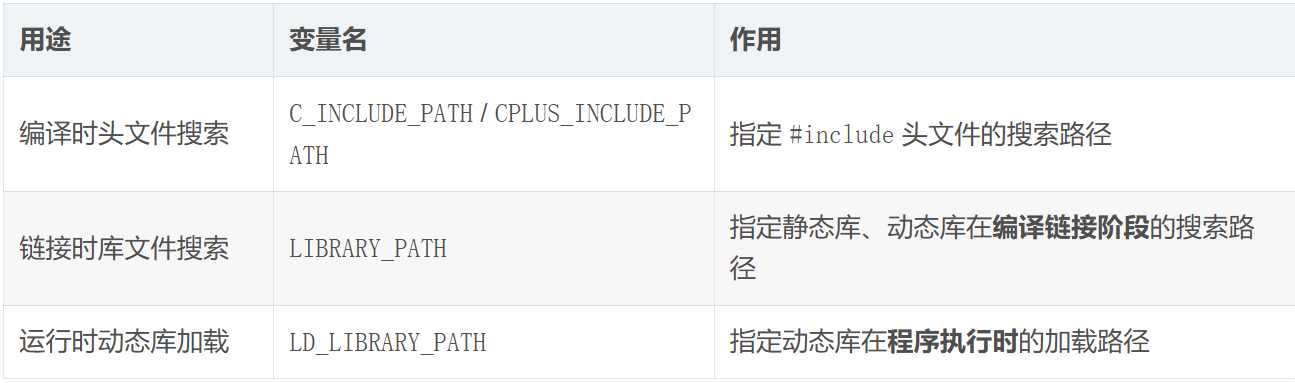
关键区别 :编译链接成功是因为编译器和链接器参考了 LIBRARY_PATH;程序能运行,则是动态链接器参考了 LD_LIBRARY_PATH。
特殊用途与全局特性
- 特殊用途
环境变量是向程序传递配置信息的标准方式,避免了硬编码,让程序更加灵活。例如,不同用户可以用相同的程序,仅通过各自的 LANG 或 HOME 变量呈现个性化行为。
- 全局特性
环境变量在系统中通常具有全局性,这体现在两个层面:
-
对子进程的继承性:这是环境变量全局特性的核心。当一个父进程(如Shell)创建一个子进程(如你运行的程序)时,子进程会继承父进程的环境变量副本。这确保了同一Shell会话中启动的所有程序共享一套基本环境。
-
系统级与用户级结合 :系统级配置与用户级配置的结合 :系统启动时,环境变量通过一系列文件进行全局配置,所有用户的Shell都会加载。例如Linux中的
/etc/environment、/etc/profile,然后再叠加用户个人目录下的~/.bashrc等文件,最终构成当前用户看到的完整环境。
需要注意:子进程对环境变量的修改不会反向影响父进程,保证了环境影响的单向性和隔离性。
1-3 获得环境变量方法
命令方式
| 命令 | 作用 |
|---|---|
env |
查看全部环境变量 |
echo $变量名 |
查看某个变量(最常用) |
printenv |
查看全部或指定变量(不加 $) |
export VAR=value |
设置环境变量 |
unset VAR |
删除环境变量 |
通过代码方式
方式一:main 函数第三参数
之前我们说main函数可以有三个参数,我们知道了两个,最后一个是什么呢--char* env\[\]也就是说还有环境变量字符串数组,看一下下面一段代码:
cpp
#include <stdio.h>
#include <string.h>
int main(int argc,char* argv[],char* env[])
{
(void)argc;
(void)argv;
//方式一:通过main函数的env参数获取
//env结尾是0(null)也就是env[i]为假跳出循环
for(int i=0;env[i];i++)
{
printf("env[%d]->: %s\n",i,env[i]);
}
return 0;
}运行结果:
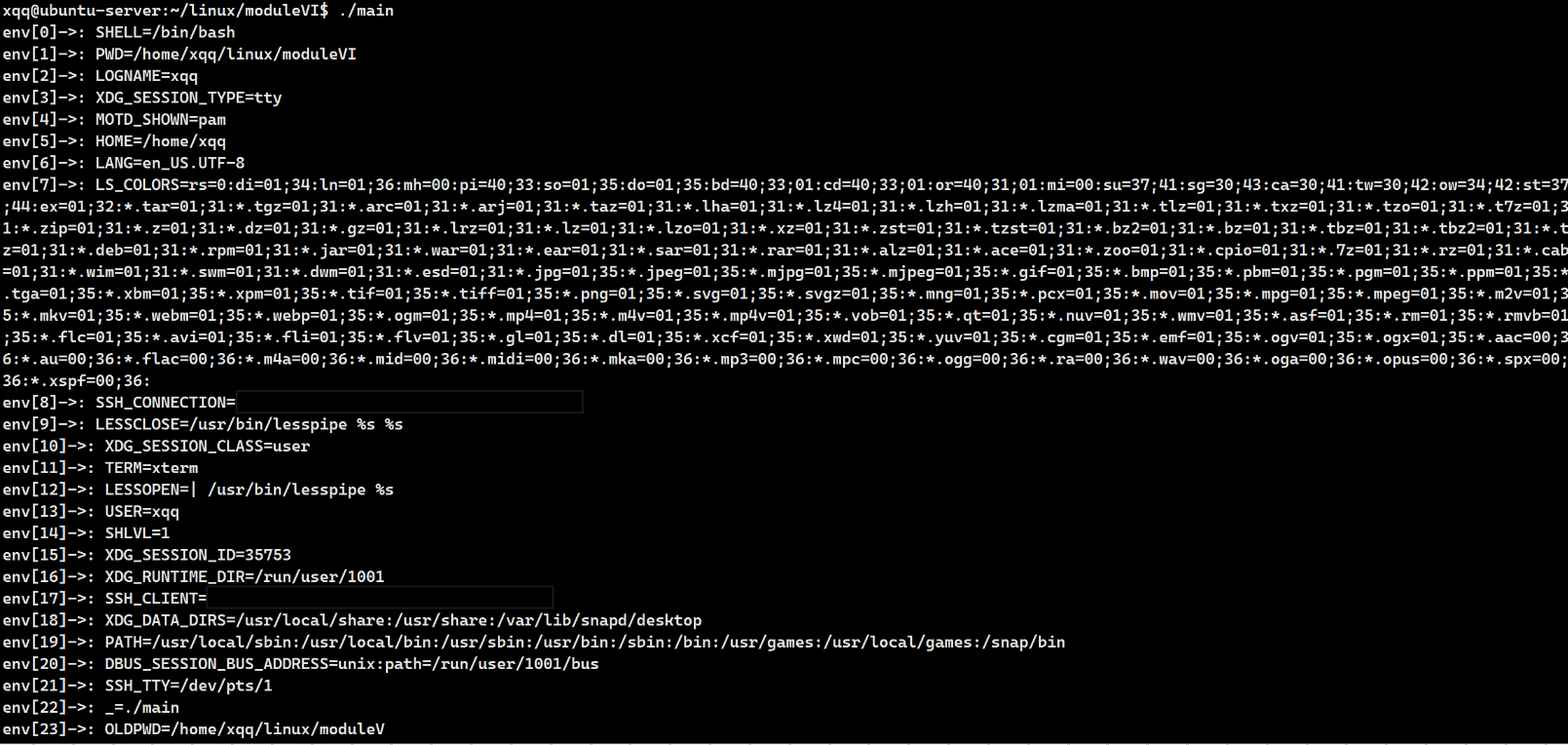
总结:main 函数的第三个参数 char* env[] 接收整个环境变量表:
方式二:getenv() 函数

示例代码:获取单个环境变量
cpp
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
int main(int argc,char* argv[],char* env[])
{
(void)argc;
(void)argv;
(void)env;
//方式二:通过系统调用获取
char* value =getenv("PATH");
if(value==NULL)
printf("获取失败");
else
printf("PATH->%s\n",value);
return 0;
}运行结果
bash
xqq@ubuntu-server:~/linux/moduleVI$ ./main
PATH->/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin实战示例:基于环境变量的用户验证
cpp
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
int main(int argc,char* argv[],char* env[])
{
(void)argc;
(void)argv;
(void)env;
//身份认证
const char* usr=getenv("USER");
if(usr==NULL) return 1;
if(strcmp("xqq",usr)==0)//给特定用户运行
{
printf("身份验证通过,正常运行\n");
}
else
printf("你没有权限\n");
return 0;
}运行结果:
bash
xqq@ubuntu-server:~/linux/moduleVI$ whoami
xqq
xqq@ubuntu-server:~/linux/moduleVI$ ./main
身份验证通过,正常运行这也体现了继承环境变量的意义----子进程可以根据环境变量进行个性化操作
方式三:全局变量 environ

environ 是一个全局变量 ,类型为 char **,指向当前进程的完整环境变量表(以 NULL 结尾的字符串数组)。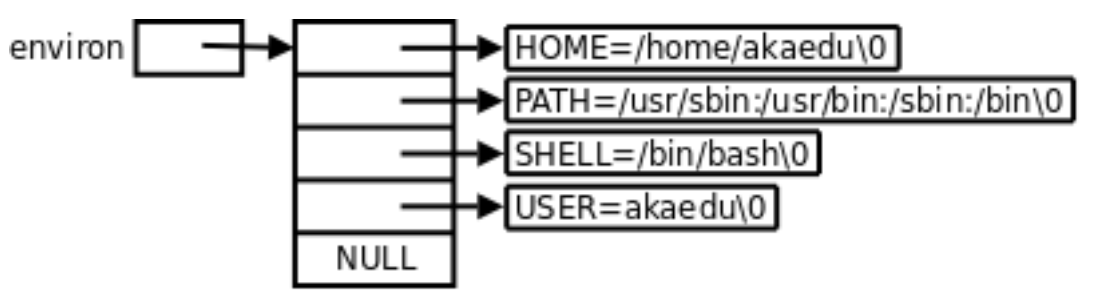
示例代码:使用前需声明
cpp
#include <stdio.h>
#include <unistd.h>
extern char** environ;
int main()
{
//方式四:全局变量方式,使用前前extern
for(int i=0;environ[i];i++)
{
printf("environ[%d]->: %s\n",i,environ[i]);
}
return 0;
}运行结果同方式一
1.4理解环境变量的特性
环境变量存储与继承的本质
从存储的角度看,环境变量的最终载体是 Bash 进程内部维护的一张环境变量表 。这张表本质上是一个字符指针数组(environ),数组中每个指针指向一个 KEY=VALUE 格式的字符串,以 NULL 结尾。我们通过 env 命令看到的所有输出,正是对这张表的遍历打印。
环境变量的核心特性是全局性 ,这种全局性通过父子进程间的继承实现。Bash 本身维护着两张关键的表:
当在命令行中输入指令时,Bash 的处理流程如下:
-
Bash 获取命令行输入,解析并构建命令行参数表 (
argv)和环境变量表。 -
Bash 将命令名与
PATH结合,在PATH指定的各路径中依次查找该命令。 -
若找到,Bash 通过
fork()创建子进程,再调用execve()将这两张表完整复制到子进程的地址空间。 -
若找不到,提示
command not found。
main 函数的三个参数------argc、argv 和 env------正是子进程接收这两张表的入口:
cpp
int main(int argc, char *argv[], char *env[])
// ↑ ↑ ↑
// 表1大小 表1本体 表2本体一个普通程序的 main 函数,拿到的命令行参数是 Bash 现拼的,环境变量表是 Bash 从自己内存里完整复制过来的。也因此,子进程对环境变量的任何修改都只影响自己的那张副本,不会反向影响父进程,这保证了环境影响的单向性和隔离性。
后续我将继续更新博客,模拟实现一个简易的 Bash,届时对这套流程会有更深刻地理解。
环境变量从哪来?
搞清楚"怎么存"和"怎么传"之后,下一个问题就是:这张表最初是怎么被填满的?
一、从源头看:来自操作系统内核的"祖传"环境
内核在启动第一个用户态进程(如 init/systemd)时,会为它设定一小份初始环境变量。此后,每个进程通过 fork() 创建子进程时都会继承父进程的环境表,这份环境就这样一代代传递到我们面前的 Shell。
二、从直接来源看:来自配置文件的逐条加载
我们日常用到的绝大多数环境变量(如 PATH、HOME、USER),都是在 Bash 启动时从配置文件中逐条加载的。Bash 依次读取 /etc/profile、~/.bashrc 等文件,执行其中的 export 语句,将变量写入自己的环境表。
因此,要永久修改环境变量,必须修改配置文件 。在终端用 export 直接修改仅对当前会话有效,关闭终端即丢失。
1.5补充概念
1.命令行定义本地变量
命令行定义本地变量,指的是在当前 Shell 进程中创建变量,它有别于环境变量,不会被子进程继承,只能在bash内部使用
一、如何定义本地变量
在 Shell 里,仅用 = 赋值,不加 export,就可以定义一个本地变量:
bash
# 定义本地变量(注意等号两边不能有空格)
xqq@ubuntu-server:~/linux/moduleVI$ myvar="hello"
xqq@ubuntu-server:~/linux/moduleVI$ mynum=100
xqq@ubuntu-server:~/linux/moduleVI$ mypath="/home/xqq/my_tools"二、本地变量 vs 环境变量
bash会记录两套变量:1.环境变量 2.本地变量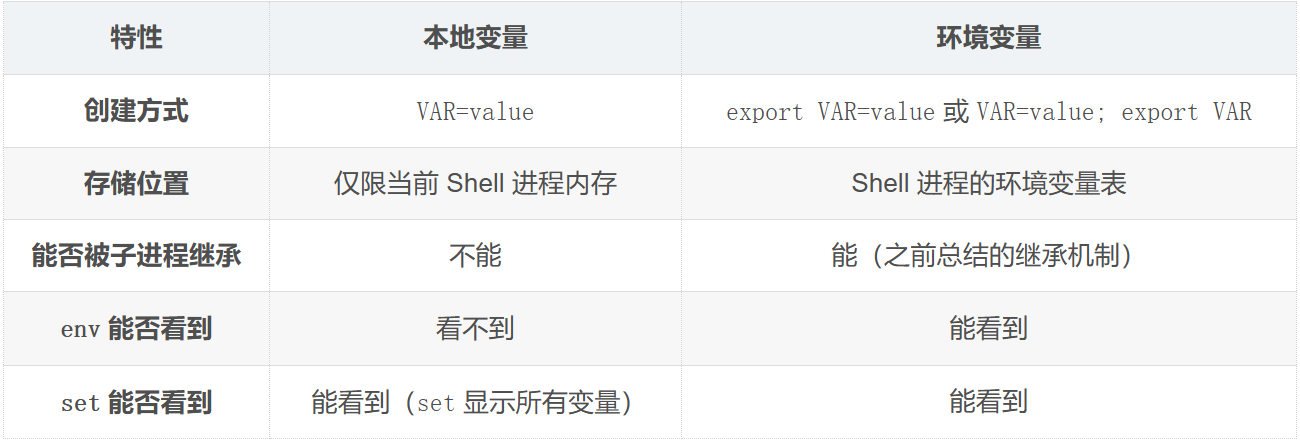
三、本地变量有以下操作:
用 export 将其提升为环境变量
cpp
xqq@ubuntu-server:~/linux/moduleVI$ export i=0 #直接定义环境变量
xqq@ubuntu-server:~/linux/moduleVI$ s=1
xqq@ubuntu-server:~/linux/moduleVI$ export s #先定义本地变量,再用export提升为环境变量export 的作用,就是把一个变量从"本地变量区"复制(或移动)到"环境变量表"中,这样它就能进入进程间继承的通道了。
用 unset 删除变量
bash
xqq@ubuntu-server:~/linux/moduleVI$ unset i
xqq@ubuntu-server:~/linux/moduleVI$ unset s2.内建命令
我们知道环境变量再bash里面,bash的子进程可以继承它,可是export是命令,也就是bash的子进程,所以子进程在导环境变量是导到父进程bash的环境变量里面,那么子进程是怎么将数据交给父进程的呢,其实export是一种内建命令,这种命令不需要创建子进程,而是由bash亲自执行,调用函数或者系统命令完成
验证命令类型:
bash
xqq@ubuntu-server:~/linux/moduleVI$ type cd
cd is a shell builtin#内建命令
xqq@ubuntu-server:~/linux/moduleVI$ type chmod
chmod is /usr/bin/chmod#外部命令有些命令同时存在内建版和外部版 (如 echo、pwd),Bash 默认优先用内建版,因为更快,这也是内建命令能够修改当前 Shell 状态(如 cd 切换目录、export 修改环境表)的根本原因
2.程序地址空间
在我之前一篇博客C++内存管理详解-CSDN博客,讲解了我们的C/C++程序内存布局通常被操作系统从低地址 到高地址 划分为以下几个经典区域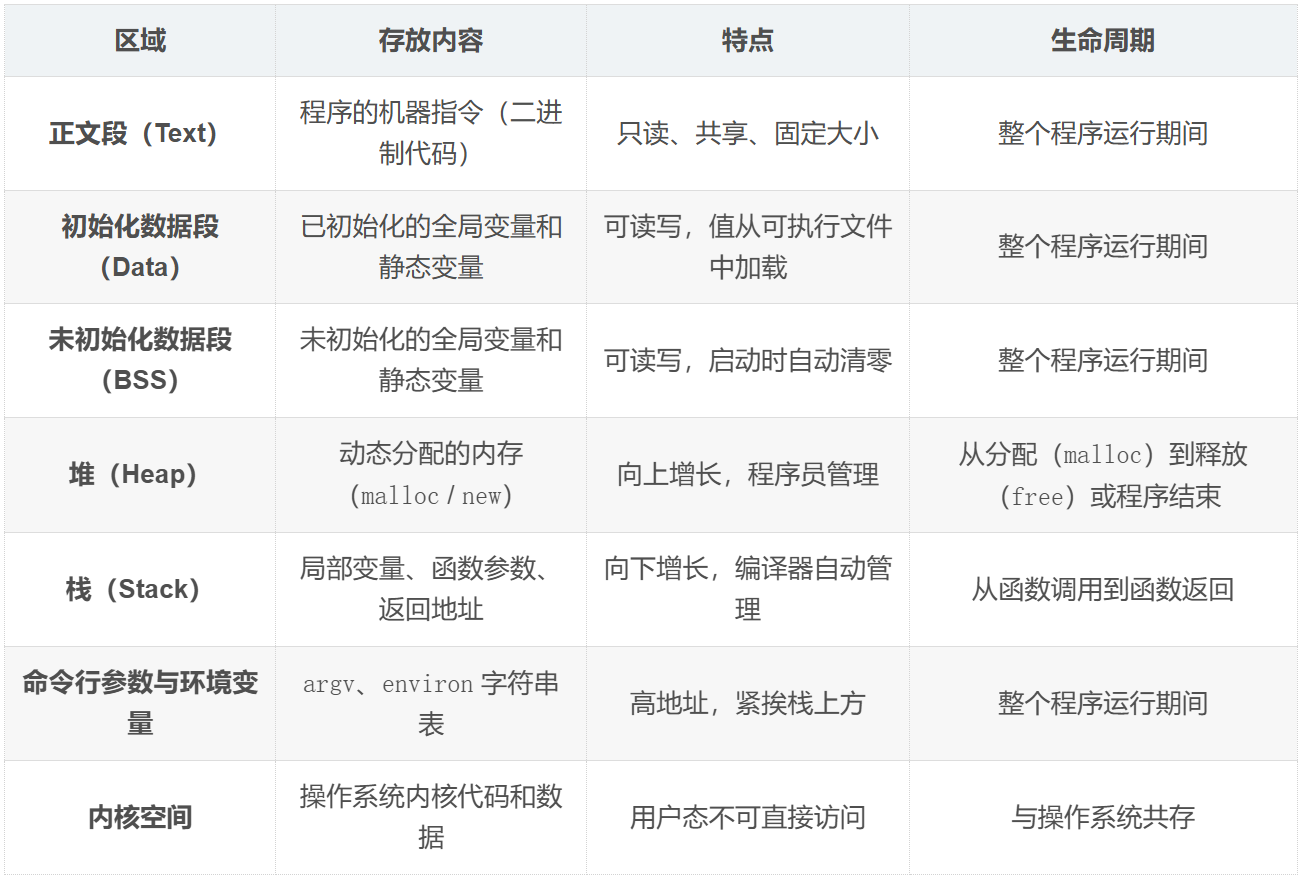
示例代码
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_unval;
int g_val = 100;
int main(int argc, char *argv[], char *env[])
{
const char *str = "helloworld";
printf("code addr: %p\n", main);
printf("init global addr: %p\n", &g_val);
printf("uninit global addr: %p\n", &g_unval);
static int test = 10;
char *heap_mem = (char*)malloc(10);
char *heap_mem1 = (char*)malloc(10);
char *heap_mem2 = (char*)malloc(10);
char *heap_mem3 = (char*)malloc(10);
printf("heap addr: %p\n", heap_mem);
printf("heap addr: %p\n", heap_mem1);
printf("heap addr: %p\n", heap_mem2);
printf("heap addr: %p\n", heap_mem3);
printf("test static addr: %p\n", &test);
printf("stack addr: %p\n", &heap_mem);
printf("stack addr: %p\n", &heap_mem1);
printf("stack addr: %p\n", &heap_mem2);
printf("stack addr: %p\n", &heap_mem3);
printf("read only string addr: %p\n", str);
for(int i = 0 ;i < argc; i++)
{
printf("argv[%d]: %p\n", i, argv[i]);
}
for(int i = 0; env[i]; i++)
{
printf("env[%d]: %p\n", i, env[i]);
}
return 0;
}运行结果:

**一个重要的认知转折:**虚拟地址与物理地址
在 C/C++ 程序中,我们用 printf("%p", &var) 打印出来的地址,全部都是虚拟地址(也称线性地址),不是物理地址。物理地址对用户程序是不可见的。
两者的核心区别: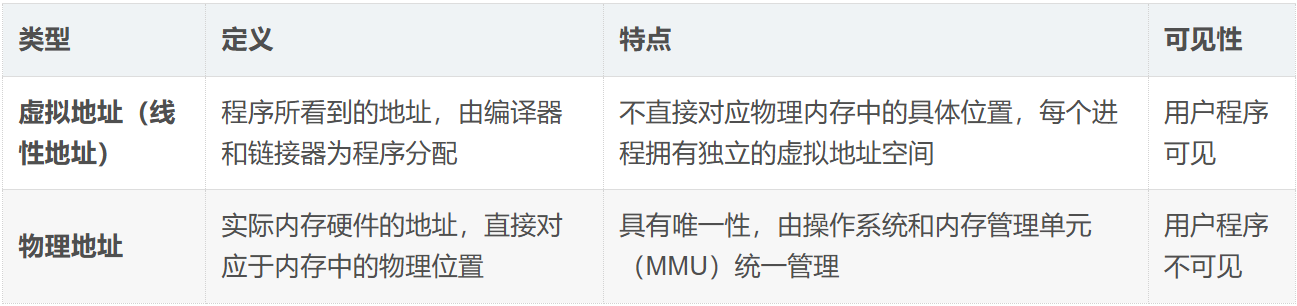
操作系统通过 MMU 将虚拟地址映射到物理地址,使得每个进程都以为自己独占一整块内存,而实际上物理内存由所有进程共享。
进程地址空间 vs 系统内存分布
我们常说的"内存布局图",严格来说指的是进程地址空间分布图 ,它和系统内存分布图 是两回事:
我们之前打印各变量地址、观察堆和栈的增长方向,都是在分析当前这个进程的地址空间,而不是整个系统的物理内存分布。
为什么理解这一点很重要
当使用 fork() 创建子进程时,父子进程拥有各自独立的虚拟地址空间 (写时拷贝机制)。子进程对某个变量值的修改,只影响自己的虚拟地址空间,不会影响父进程。但父子进程中同一个变量的虚拟地址看起来是相同的,这正是因为每个进程都使用自己的页表映射到不同的物理页面。
fork 实证:同一虚拟地址,不同物理内存
结合下文的 fork 实验,这个结论会进一步得到实证。
示例代码与运行结果:
bash
xqq@ubuntu-server:~/linux/moduleVI$ cat test_virtual_address.c
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int count=0;
int main()
{
pid_t id=fork();
if(id==0)
{
while(1)
{
printf("child,pid:%d,ppid:%d,count=%d,&count=%p\n",getpid(),getppid(),count,&count);
count++;
sleep(1);
}
}
else
{
while(1)
{
printf("parent,pid:%d,ppid:%d,count=%d,&count=%p\n",getpid(),getppid(),count,&count);
sleep(1);
}
}
return 0;
}
xqq@ubuntu-server:~/linux/moduleVI$ ./testPVAS
parent,pid:936979,ppid:935902,count=0,&count=0x55c6b35b9014
child,pid:936980,ppid:936979,count=0,&count=0x55c6b35b9014
parent,pid:936979,ppid:935902,count=0,&count=0x55c6b35b9014
child,pid:936980,ppid:936979,count=1,&count=0x55c6b35b9014
parent,pid:936979,ppid:935902,count=0,&count=0x55c6b35b9014
child,pid:936980,ppid:936979,count=2,&count=0x55c6b35b9014
^C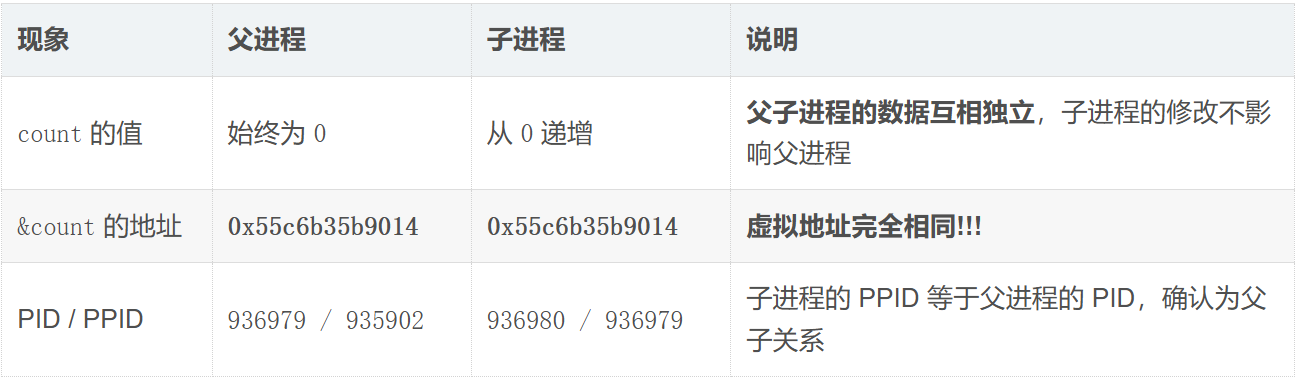
地址相同锤实了这个地址一定不是内存地址
3.进程虚拟地址空间
3.1 基本概念
- 一个进程,一个虚拟地址空间
每当一个程序被加载运行时,操作系统就会为其创建一个进程 。在内核中,这个进程由一个 task_struct 结构体来描述。task_struct 中有一个指针 mm,指向一个 mm_struct 结构体对象--这个结构体对象就是进程虚拟地址空间本身
每个进程都有自己独立的虚拟地址空间 。这意味着进程 A 看到的地址 0x12345678 和进程 B 看到的同一个地址,通过各自的页表会映射到完全不同的物理内存位置。这种隔离性是操作系统实现多任务并发运行且互不干扰的基石。
- 最小寻址单位:1 字节
虚拟地址空间以**字节(Byte)**为最小单位进行编址。每个地址指向一个字节的存储空间。
这意味着一个 int 类型变量(通常占 4 字节)在内存中会占据 4 个连续的地址。当我们用 & 取一个 int 变量的地址时,得到的是这 4 个地址中最小的那个(起始地址) 。CPU 在读取这个 int 时,会根据类型信息知道要从起始地址连续读取 4 个字节,并按补码规则解析成整数值。
这正是 C 语言指针类型存在的底层意义------int* 和 char* 存储的都是虚拟地址值,但解引用时前者读 4 字节,后者读 1 字节。
- 一切皆虚地址
程序中所有的"地址",无一例外都是虚拟地址:
-
代码本身 :
main函数的入口地址。 -
全局变量/静态变量:Data 段或 BSS 段内的地址。
-
堆空间 :
malloc/new返回的指针值。 -
栈变量:局部变量、函数参数的地址。
-
命令行参数 :
argv数组中各字符串的地址。 -
环境变量 :
envp/environ中各字符串的地址。
这些虚拟地址不直接对应物理内存 。最终必须通过页表翻译成物理地址,才能真正访问到硬件内存中的数据。
3.2 虚拟地址空间范围
32 位机器
-
地址总线宽度:32 位。
-
可表示的地址总数 :
2^32 = 4,294,967,296个。 -
地址范围 :
0x00000000~0xFFFFFFFF。 -
理论最大虚拟地址空间 :4 GB。
在典型的 32 位 Linux 系统中,这 4GB 被分为两部分:
后续内容主要基于 32 位机器展开,便于画图和理解。
64 位机器
-
地址总线宽度:64 位(实际使用 48 位)。
-
可表示的地址总数 :
2^64,理论最大空间 16 EB。 -
实际使用 :只用 48 位寻址,空间为
2^48 = 256 TB,平分给用户空间和内核空间各 128 TB。
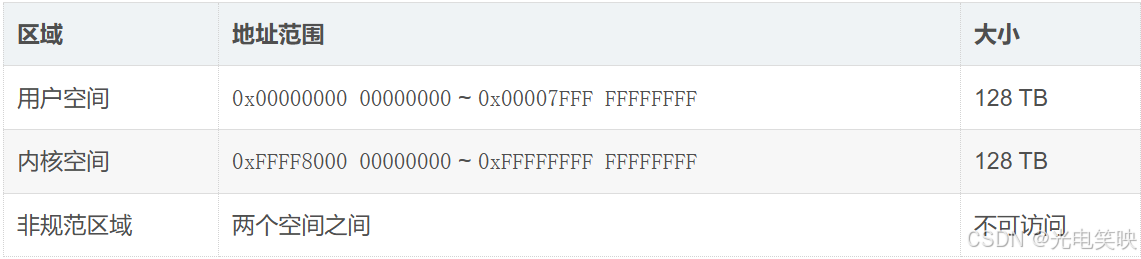
64 位下用户空间地址的典型特征:
-
0x55...或0x56...开头:代码段、数据段、堆。 -
0x7f...开头:栈、共享库、mmap映射区。 -
0xFF...开头:内核空间(用户态不可见)。
3.3区域划分
进程虚拟地址空间不是铁板一块,而是一张被精确切割的"地图"。操作系统通过 mm_struct 中记录的边界值,将整个地址空间划分为若干个功能独立的区域。每个区域在地址空间中占据一段连续的虚拟地址范围,有各自的增长方向和访问权限。
从内核数据结构的视角来看,这些区域在运行时由一个个 VMA (struct vm_area_struct)来代表,而 mm_struct 中的边界字段则定义了进程启动时必须拥有的最基础的几个区域的起止位置。
mm_struct 中的边界字段:
cpp
struct mm_struct {
/*...*/
struct vm_area_struct *mmap; /* 指向虚拟区间(VMA)链表 */
struct rb_root mm_rb; /* red_black树 */
unsigned long task_size; /*具有该结构体的进程的虚拟地址空间的⼤⼩*/
/*...*/
unsigned long start_code, end_code; // 代码段
unsigned long start_data, end_data; // 数据段
unsigned long start_brk, brk; // 堆区
unsigned long start_stack; // 栈区
unsigned long arg_start, arg_end; // 命令行参数
unsigned long env_start, env_end; // 环境变量
};3.4 页表与 MMU
3.4.1 页表概念
页表 是存储虚拟地址到物理地址映射关系的核心数据结构 。每个进程都有一套独立的页表 ,由操作系统在创建进程时分配,进程切换时随之切换。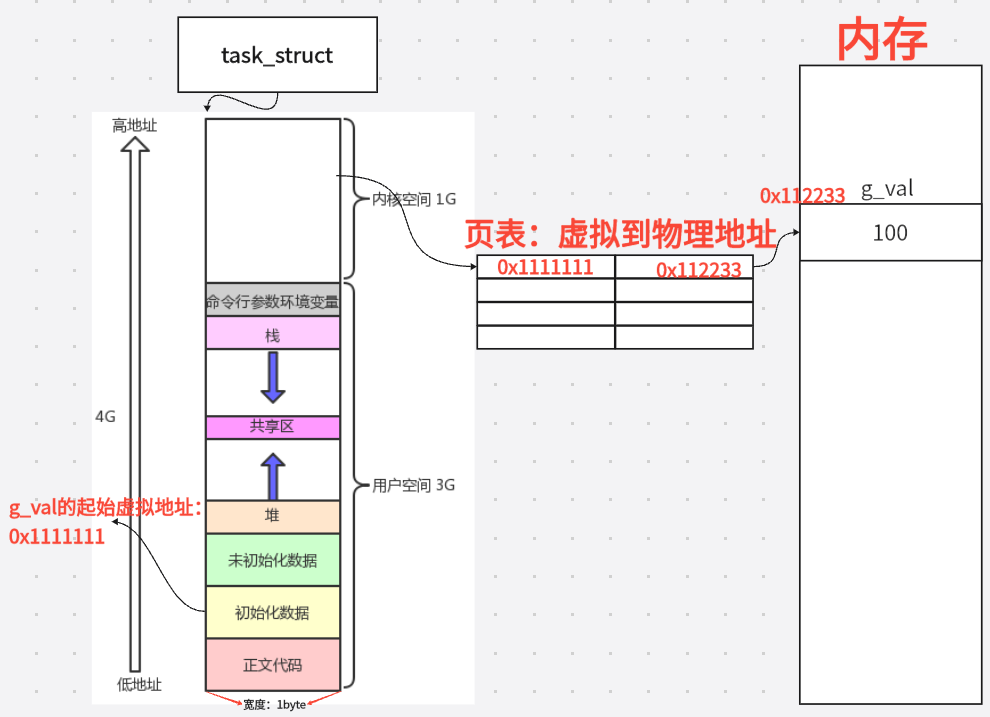
3.4.2 MMU 与 CR3 寄存器
MMU (Memory Management Unit,内存管理单元)是 CPU 内部的硬件组件,负责在每次内存访问时自动完成地址翻译。MMU 通过 CR3 寄存器找到当前进程的页表基地址,然后逐级查表,将虚拟地址转换为物理地址。
核心结论 :进程地址空间本身不具备保存代码和数据的能力,它只是一个"虚拟的承诺"。真正的存储能力来自 页表 + MMU + 物理内存三者的协作。
关键点:
-
同一个虚拟地址(如
0x12345678)在不同进程中,通过各自独立的页表,可以映射到完全不同的物理页面。 -
页表不仅记录映射关系,还记录每个页面的访问权限(可读 r、可写 w、可执行 x)。
3.5 fork 与写时拷贝
3.5.1 实验代码
回到我们之前的fork 实验运行结果如下
bash
xqq@ubuntu-server:~/linux/moduleVI$ ./testPVAS
parent,pid:936979,ppid:935902,count=0,&count=0x55c6b35b9014
child,pid:936980,ppid:936979,count=0,&count=0x55c6b35b9014
parent,pid:936979,ppid:935902,count=0,&count=0x55c6b35b9014
child,pid:936980,ppid:936979,count=1,&count=0x55c6b35b9014
parent,pid:936979,ppid:935902,count=0,&count=0x55c6b35b9014
child,pid:936980,ppid:936979,count=2,&count=0x55c6b35b9014
^C-
父子进程中
&count的虚拟地址完全相同。 -
子进程修改后,父子进程读到的值与子进程不同(0和 0,1,2)。
3.5.2 原因分析
问题:同一个虚拟地址,为什么能对应不同的物理内存?
答案------写时拷贝(Copy-On-Write)
完整流程 :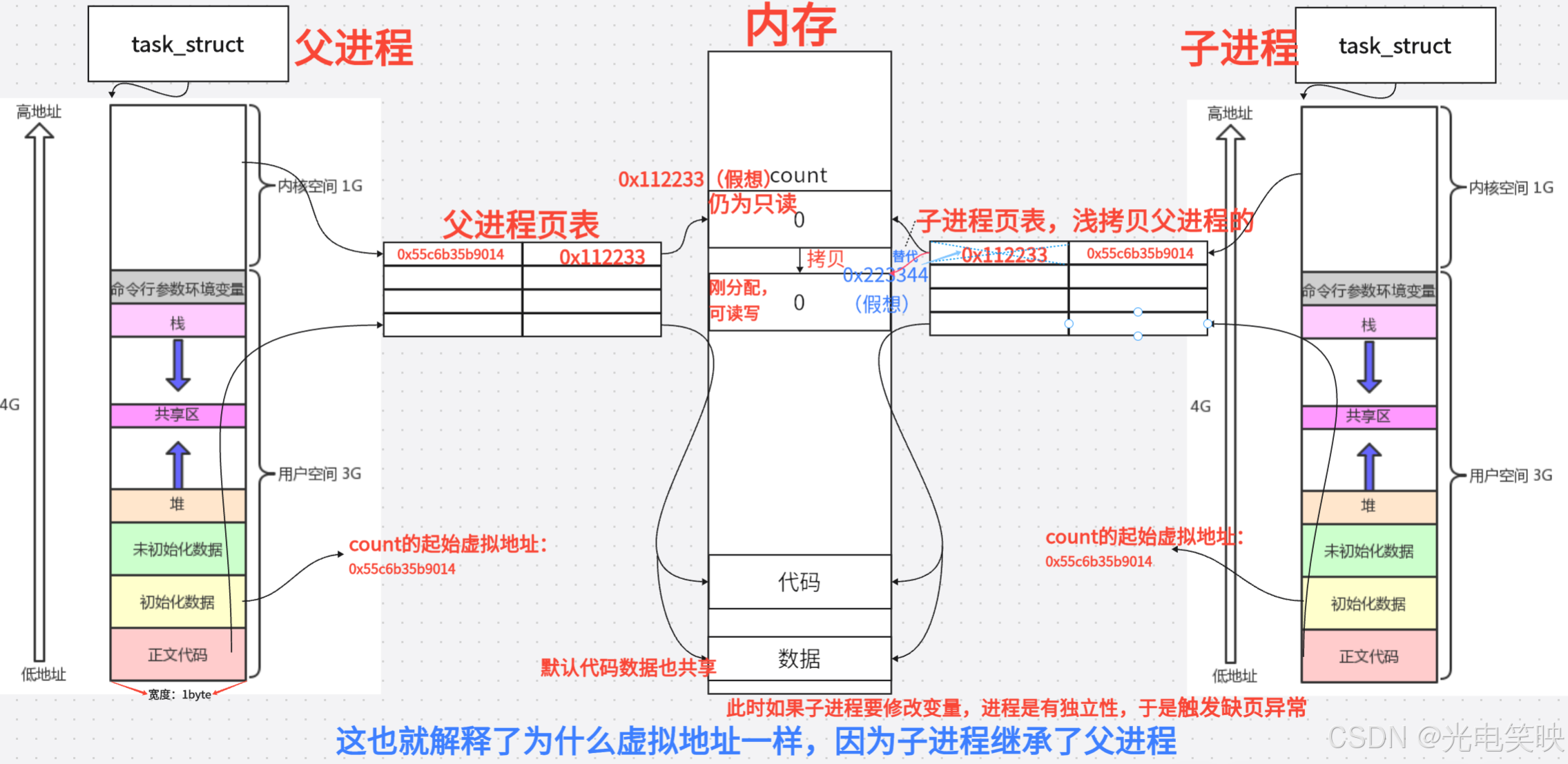
第一阶段:fork 刚完成时(共享状态)
-
子进程浅拷贝了父进程的页表,而非物理内存本身。
-
父子进程的同一虚拟地址
0x55c6b35b9014映射到了同一个物理页面。 -
该物理页面被页表标记为只读(read-only),以保证数据一致性。
第二阶段:子进程写入时(分离状态)
-
子进程执行count++,尝试向只读页面写入。
-
CPU 的 MMU 检查页表权限位,发现该页面是只读的,触发缺页中断(Page Fault)。
-
操作系统介入处理:
-
分配一块新的物理页面(如
0xB1)。 -
将原物理页面
0xA1的内容(count= 0)复制 到新页面0xB1。 -
修改子进程页表 ,将虚拟地址重新映射到新物理页面
0xB1。 -
设置新页面权限为可读写(rw),原页面保持只读不变。
-
-
子进程恢复执行,count++成功写入新页面。
最终结论:同一个虚拟地址(子进程继承父进程),两张不同的页表,指向两块不同的物理内存。这就是父子进程既共享初始数据、又互不影响对方修改的根本原因。
3.6 缺页中断与惰性分配
3.6.1 缺页中断机制
缺页中断(Page Fault) 是 CPU 访问一个"当前不可用"的虚拟地址时触发的硬件异常。它并非总是错误,很多场景下是正常的内存管理手段。
触发缺页中断的四种场景: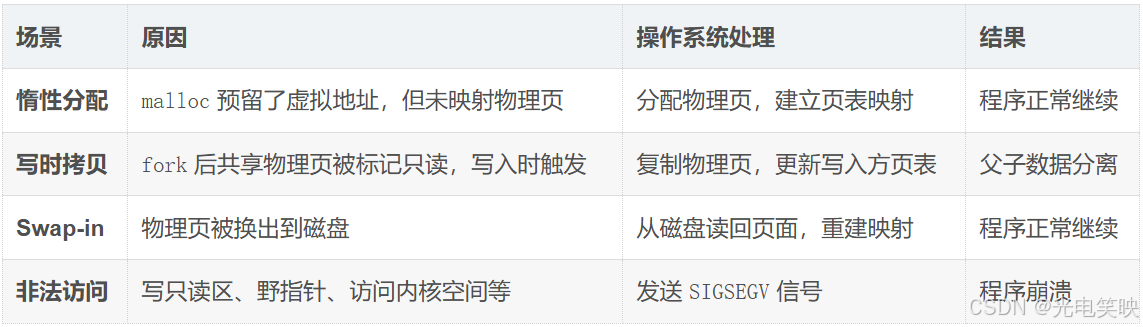
3.6.2 缺页中断处理流程
3.6.3 new / malloc 的惰性分配原理
当调用 malloc 或 new 申请内存时:
-
不会立即分配物理内存 。操作系统只在进程的虚拟地址空间中预留 一段连续的虚拟地址,更新堆区的边界(
brk上移),但不建立页表映射。 -
好处:
-
提升内存利用率:进程实际使用的物理内存往往远少于其申请的虚拟内存总量。延迟分配避免了分配了但从未使用的物理页的浪费。
-
提升
malloc/new速度:不涉及物理页查找和分配操作,系统调用更快返回。
-
-
首次写入时:
-
MMU 查页表发现该虚拟地址没有有效映射 → 触发缺页中断。
-
操作系统分配物理页 → 建立页表映射 → 恢复执行写入指令。
-
比喻:就像签一张支票------承诺时只记一笔账,兑现时才真掏钱。
3.7 内存保护与只读区域
3.7.1 为什么字面值常量不能被修改?
bash
xqq@ubuntu-server:~/linux/moduleVI$ cat test_w_inc.c
#include <stdio.h>
int main()
{
char* str="const str";//尝试在字符常量区写入
*str='H';//编译通过,运行段错误
return 0;
}
xqq@ubuntu-server:~/linux/moduleVI$ gcc test_w_inc.c -o test
xqq@ubuntu-server:~/linux/moduleVI$ ./test
Segmentation fault (core dumped)原因分析:
字符串字面量 "const str" 在编译时被放入只读数据段,该段在内存中的页表条目权限位仅设为可读(r),不具备写权限。
当程序执行 *str = 'H' 时:
-
CPU 尝试向该虚拟地址写入数据。
-
MMU 查询页表,检查权限位,发现该页面为只读。
-
MMU 阻止写入操作,触发缺页中断。
-
操作系统判断这是一次非法的写保护违规 ,向进程发送
SIGSEGV信号。 -
进程收到信号后默认终止,打印
Segmentation fault。
3.7.2 为什么建议加 const 修饰?
cpp
#include <stdio.h>
int main()
{
const char* str = "hello world!"; // 加了 const
*str = 'H'; // 编译不通过
return 0;
}好处 :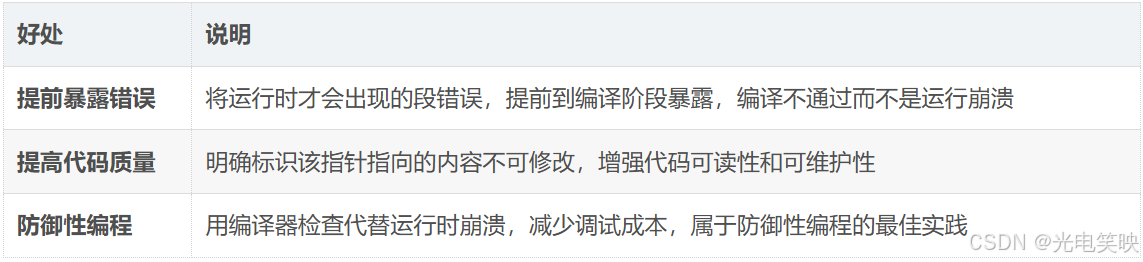
3.8 进程地址空间在内核中的数据结构
操作系统遵循"先描述,再组织"的原则。进程地址空间在内核中由 mm_struct 结构体描述,被 task_struct 的 mm 指针指向。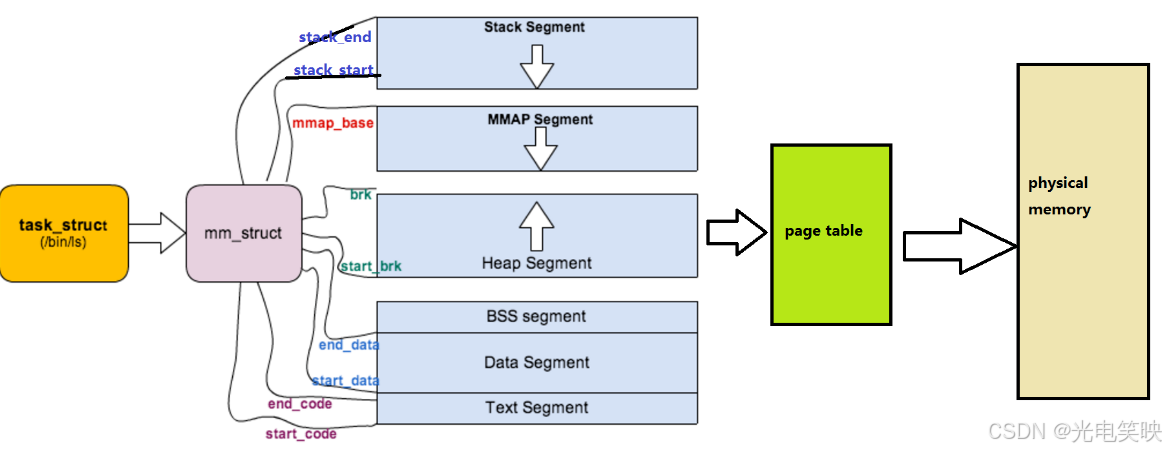
cpp
struct mm_struct {
struct vm_area_struct *mmap; // VMA 链表头,方便遍历
struct rb_root mm_rb; // VMA 红黑树根,方便查找
struct vm_area_struct *mmap_cache; // 缓存最近一次访问的 VMA
unsigned long start_code, end_code; // 代码段起止
unsigned long start_data, end_data; // 数据段起止
unsigned long start_brk, brk; // 堆区起止
unsigned long start_stack; // 栈底地址(栈最高处)
unsigned long arg_start, arg_end; // 命令行参数起止
unsigned long env_start, env_end; // 环境变量起止
};三个字段各司其职:

其中,VMA (struct vm_area_struct)描述每个连续的虚拟地址区间。进程的 Text、Data、BSS、Heap、Stack、共享库、mmap 映射等在内部都是一个独立的 VMA。
cpp
struct vm_area_struct {
unsigned long vm_start; //虚存区起始
unsigned long vm_end; //虚存区结束
struct vm_area_struct *vm_next, *vm_prev; //前后指针
struct rb_node vm_rb; //红⿊树中的位置
unsigned long rb_subtree_gap;
struct mm_struct *vm_mm; //所属的 mm_struct
pgprot_t vm_page_prot;
unsigned long vm_flags; //标志位
struct {
struct rb_node rb;
unsigned long rb_subtree_last;
} shared;
struct list_head anon_vma_chain;
struct anon_vma *anon_vma;
const struct vm_operations_struct *vm_ops; //vma对应的实际操作
unsigned long vm_pgoff; //⽂件映射偏移量
struct file * vm_file; //映射的⽂件
void * vm_private_data; //私有数据
atomic_long_t swap_readahead_info;
#ifndef CONFIG_MMU
struct vm_region *vm_region; /* NOMMU mapping region */
#endif
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endif
struct vm_userfaultfd_ctx vm_userfaultfd_ctx;
} __randomize_layout;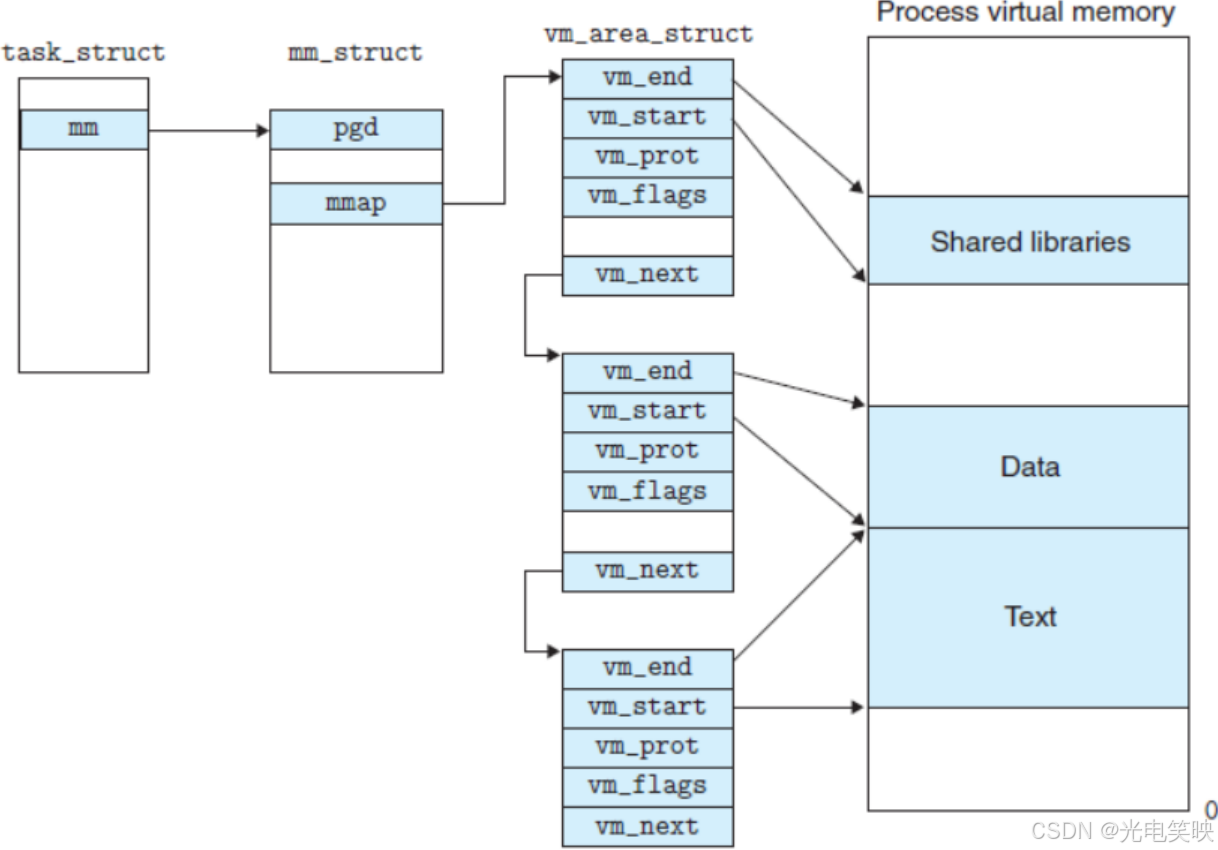
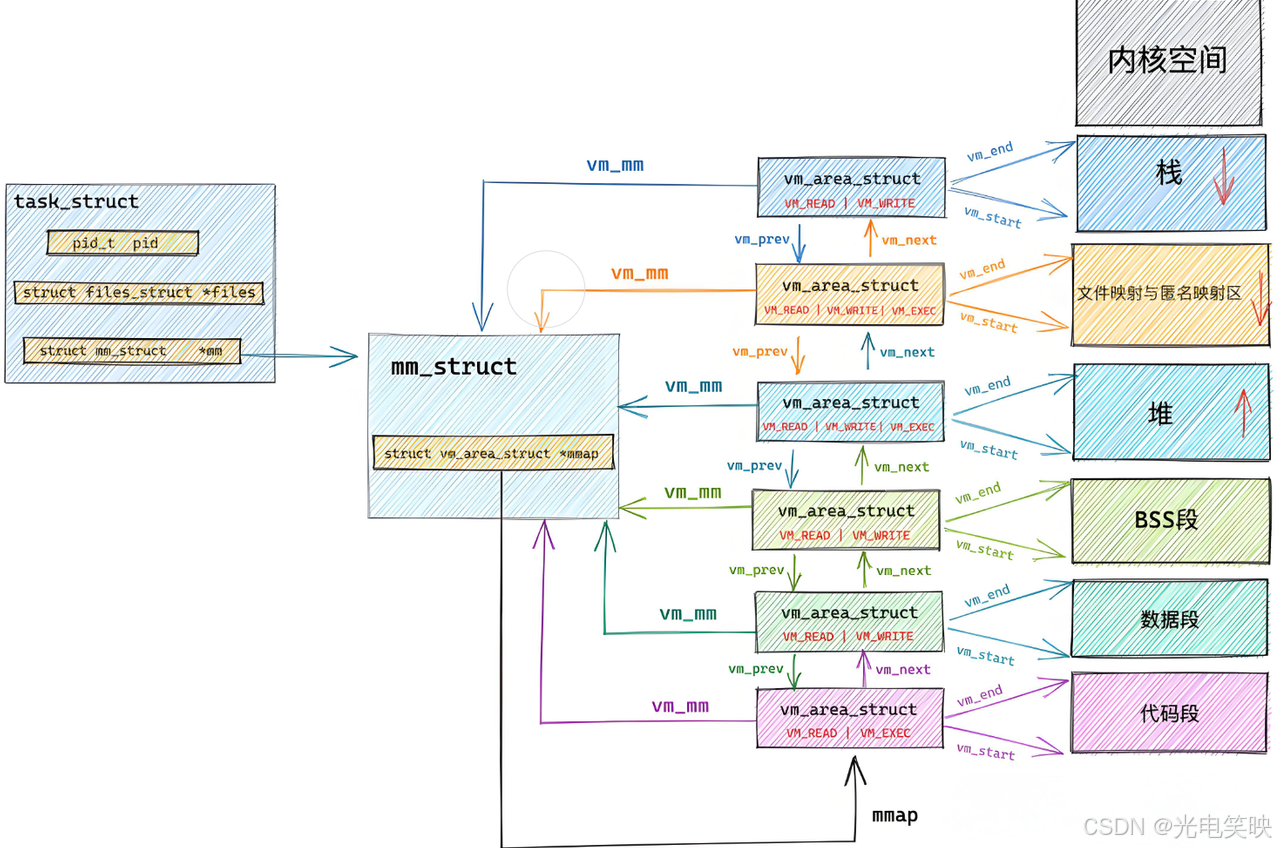
3.9 地址空间与页表存在的意义
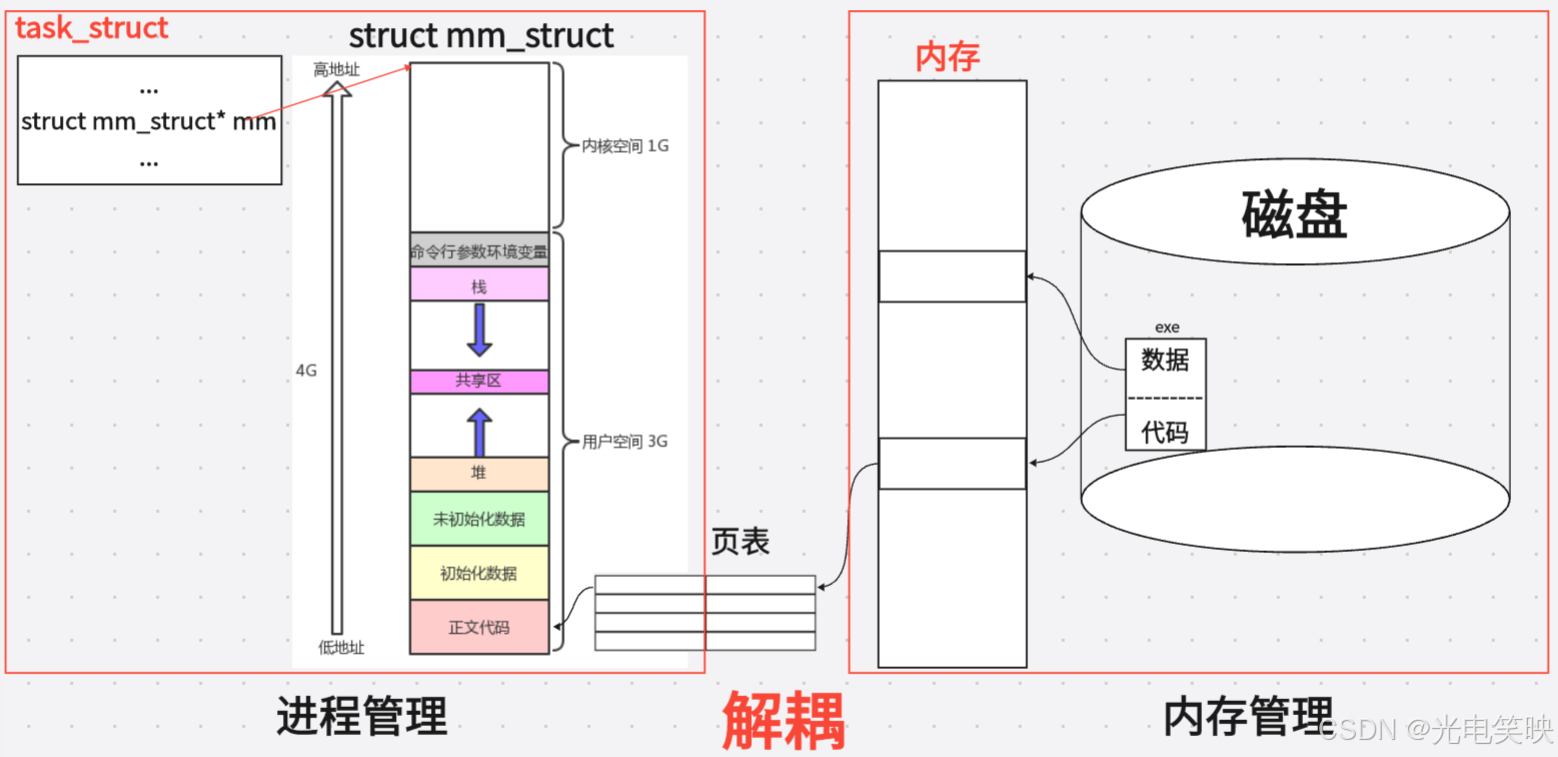
4.结尾:三者关系的核心比喻
三者关系的核心比
角色映射
大富翁是OS、10亿资产为物理内存、小A/B为独立的进程、饼为每个进程的进程地址空间。
有一个大富翁,有10亿美元,有好几个孩子,分别为A、B、C等,假设孩子们都互不相识。有一天大富翁对孩子们分别画饼。对A说 :"儿子,你好好干,等我走后,我的10亿资产全部是你的",对B说 :"闺女,你好好读书,努力考博,等我走后,我的10亿资产全部都是你的"...A/B等孩子都认为将来自己有10亿 ---所以:
- 进程地址空间是操作系统给进程画的一张"饼"------承诺你可以拥有这么大一块连续内存。怎么管理这个饼->先描述再组织
先描述:核心数据结构是
mm_struct和vm_area_struct(VMA)。mm_struct是总账本,VMA 是每一片切块的详细描述再组织 :有了
mm_struct和 VMA,接下来的问题就是:当缺页中断发生,内核需要极速判断某虚拟地址落在哪片 VMA 里、权限是否匹配,怎么高效管理这些 VMA?答案是------三种结构、三个字段,各司其职 :
页表是翻译官------把虚拟的承诺翻译成物理的现实。
物理内存是实际的资源------由操作系统精打细算、按需分配。
这套机制让操作系统既能对每个进程"大方承诺",又能在物理层面"精打细算、安全可控"。
程序从"磁盘上的文件"到"内存中运行的进程"所经历的三个核心步骤阶段1:在虚拟地址空间中申请指定大小的空间
这一阶段发生在
execve系统调用时。内核做的事情是**"画饼"------只记账,不付钱**。具体步骤:
解析可执行文件的 ELF 头,读取各段的起止地址和大小。
为进程创建新的
mm_struct。填充各边界字段:
为每个区域创建对应的
struct vm_area_struct,设置好vm_start、vm_end和vm_flags(权限位 r/w/x)。不分配物理内存,页表中这些虚拟地址都没有有效映射。
此时进程看到的是一个完整的、连续的虚拟地址空间,但这张"饼"还没真正落到物理内存里。
阶段2:加载程序,申请物理空间
这一阶段不是一次性完成的 ,而是程序运行时按需触发的。
当 CPU 第一次访问某个虚拟地址时:
MMU 查页表,发现该虚拟地址对应的页表项无效(Present 位为 0)。
CPU 触发缺页中断(Page Fault)。
内核缺页处理函数
do_page_fault()执行:
从 CR2 寄存器读取导致缺页的虚拟地址。
在
mm_rb红黑树中查找该地址属于哪个 VMA。判断合法性:不在任何 VMA →
SIGSEGV;在 VMA 内 → 继续。判断权限:要写只读区 →
SIGSEGV;权限 OK → 继续。分配物理页框(调用伙伴系统或 slub 分配器)。
如果是代码段或已初始化数据段,从磁盘读取对应内容到物理页。
这就是所说的"加载程序,申请物理空间"------但它是按页面粒度、按需触发的,不是程序启动时一股脑全部加载。
阶段3:经过页表映射
分配物理页后,还需要建立映射关系,让虚拟地址能找到这个物理页。
具体步骤:
内核修改当前进程的页表,填充对应的页表项(PTE):
物理页框号(PFN):指向刚分配的物理页。
权限位 :根据 VMA 的
vm_flags设置(可读 r、可写 w、可执行 x)。Present 位:置 1,表示该页已在物理内存中。
刷新对应的 TLB 条目(Translation Lookaside Buffer,页表缓存),确保旧映射不再被使用。
缺页中断处理完毕,CPU 从引发缺页的那条指令重新执行。
这次 MMU 再查页表,命中有效条目,正常翻译出物理地址,访问成功。
画饼 → 上菜 → 连线,三个阶段走完,进程才真正拥有了可用的内存。 这就是虚拟内存管理的完整闭环。
