你的 AI 每次对话都在重新推导知识。而一个由 Agent 自己维护、会复利增长的 Wiki,让它越用越聪明。
这篇文章不是教你怎么敲 CLI 命令。memex 的入口在 agent 对话里 ------你只需要说
/memex:capture、/memex:ingest、/memex:query,Agent 自己知道怎么做。
一、Karpathy 在 2026 年 4 月提出了一个思想
Andrej Karpathy 是 OpenAI 创始团队成员、前 Tesla AI 总监。2026 年 4 月 4 日,他在 GitHub Gist 上发布了一篇 LLM Wiki Pattern,系统阐述了一个思想:
为什么人类用 Wiki 积累知识,而 AI 每次对话都在从零推导?
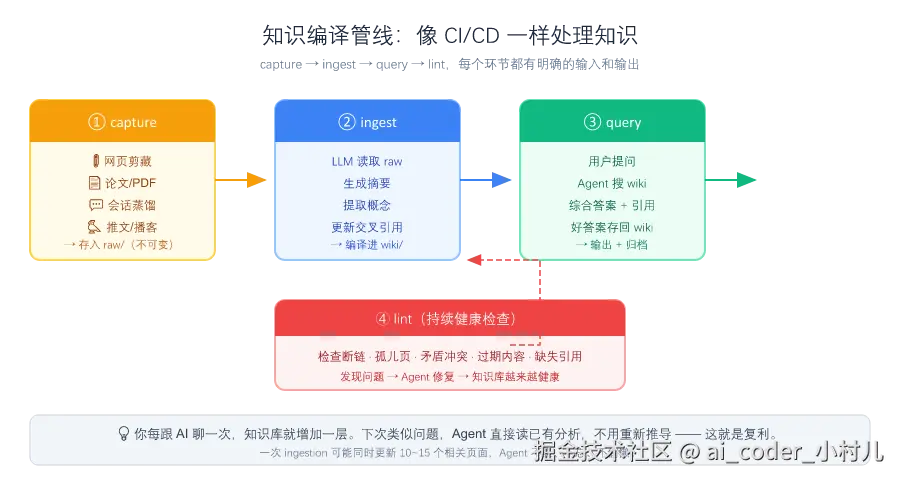
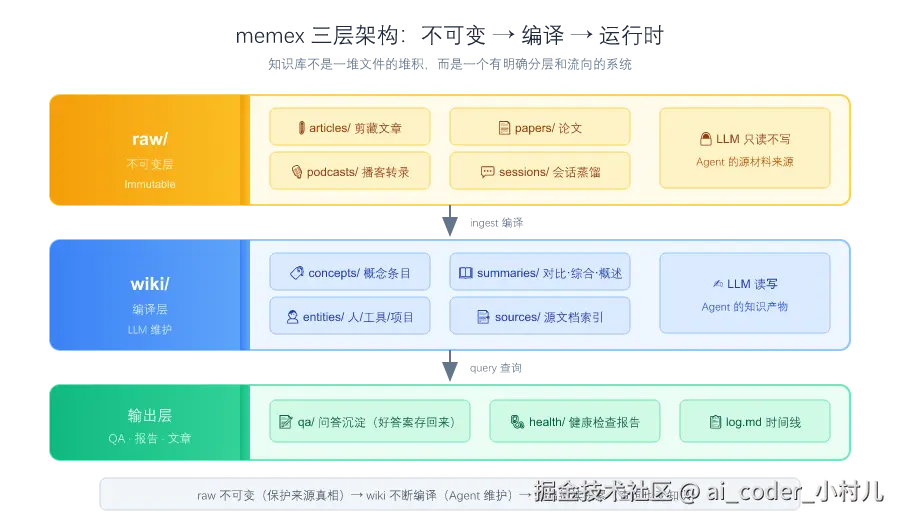
他的主张很直接:给 LLM 一个结构化 Markdown Wiki,让它自己维护。人类只负责往 raw/ 里扔源材料,LLM 负责把知识编译进 wiki/------更新概念页、建立交叉引用、标注矛盾、写综合页。每轮对话不是"检索",是"阅读一本已经写好的书"。
他打了个比方,传得很广:
"Obsidian is the IDE, the LLM is the programmer, the wiki is the codebase."
翻译过来就是:"Obsidian 是 IDE,LLM 是程序员,Wiki 是代码库。"
什么意思?你写代码时------IDE 是你的界面,程序员是写代码的人,代码库是持续构建的产物。类比到这里------Obsidian(或任意 Markdown 浏览器)只是你看知识的界面,LLM 才是真正写知识的人,Wiki 就是 LLM 持续构建和维护的知识产物。你不写 Wiki,你看 Wiki;LLM 不读 Wiki,LLM 写 Wiki。
Karpathy 的核心洞见其实用一句话就能说清------他把知识库当代码仓库管理:
| 软件工程 | → | 知识库工程 |
|---|---|---|
src/ |
→ | raw/(原始资料,不可变) |
build/ |
→ | wiki/(编译产物,LLM 自动生成) |
| 编译器 | → | LLM(把 raw 编译成结构化 wiki) |
| IDE | → | Obsidian / 任意 Markdown 浏览器 |
| Lint / CI | → | 健康检查(断链、矛盾、过期页) |
| 增量编译 | → | 每次只 ingest 新增的 raw,不改旧文件 |
我是开发出身,第一眼看到这张表就懂了。这不就是 CI/CD 的知识库版本吗?

而 Karpathy 用了一个词来概括这一切------编译(Compile) 。把原始资料编译成结构化知识。raw 是源码,wiki 是编译产物。你不会把 .class 和 .java 混在一起,笔记也一样。
核心区别在于:RAG 每次重推,Wiki 持续复利。
这句话拆开看------
| RAG | LLM Wiki | |
|---|---|---|
| 知识形态 | 文档切片,无关联 | 结构化页面,交叉引用 |
| 更新方式 | 重新索引 | Agent 直接编辑 Markdown |
| 查询 | 向量相似度拼凑 | 读已组织好的页面 |
| 累积性 | 没有复利 | 每次 ingest 在旧知识上修改、关联 |
| 所有权 | 在厂商的向量库里 | 在本地 Git 仓库里 |
Karpathy 给的是思想。我把它做成了工程:memex。
二、memex 怎么用?在 agent 对话里说话就行
最重要的概念先摆出来------
你不是在终端敲
memex distill、memex ingest。你是在 agent 对话框里说/memex:capture、/memex:ingest、/memex:query。CLI 只在 Agent 脚下跑,你感觉不到它。
memex 提供了 6 个 slash command,覆盖完整的知识生命周期:
| Slash Command | 你做什么 | Agent 做什么 |
|---|---|---|
/memex:capture |
给 Agent 一个 URL、一段文字、一个文件 | Agent 保存到 raw/,记录出处,不变形 |
/memex:ingest |
"把这些新东西消化进知识库" | Agent 读 raw 源材料,更新 concept/entity/source 页面,写交叉引用,更新 index |
/memex:query |
"关于 X,我们知道哪些?" | Agent 搜 wiki,综合答案,带引用 |
/memex:distill |
"这次对话有不少好结论,存下来" | Agent 把会话要点蒸馏成结构化 raw 笔记 |
/memex:lint |
"检查一下知识库健不健康" | Agent 跑机械检查 + 语义扫描,报问题,修问题 |
/memex:status |
"看看知识库现在什么状态" | Agent 报告页面数、最近变化、待处理项 |
你不需要记住命令参数。你只需要用自然语言告诉 Agent 你想干什么,Agent 自己调对应的 slash command。
别上来就搞 RAG
一提"AI + 笔记",很多人的第一反应是搭 RAG:选 Embedding 模型、搭向量数据库、调切片策略。整套架构搞了一个月,笔记库里还是只有 20 篇文章。
Karpathy 的思路反过来:先跑通流程,再优化基础设施。 知识库规模不大的时候(几百篇文章以内),维护几个索引文件就够了。LLM 先读 index.md 定位,再直接阅读相关内容。简单、可靠、零额外成本。等你的笔记真的过了一万条,搜东西开始找不到、找不全了,再考虑 RAG 不迟。
这道理写代码的人都懂,但轮到自己搭知识库的时候就忘了。
每次问答也能存回知识库
还有一个 Karpathy 特别强调的设计:好的问答结果应该存回 wiki,而不是消失在聊天记录里。 你问了一个复杂问题,Agent 查 wiki、综合答案、带引用------这个答案本身就是一份有价值的知识产物。把它存成新页面。下次类似问题,Agent 直接读已有的分析,不用重新推导。
你每跟 AI 聊一次,知识库就增加一层。这就是复利。
三、五个场景:memex 到底能带来什么价值
下面这五个场景,是我自己用了三个月的真实感受。
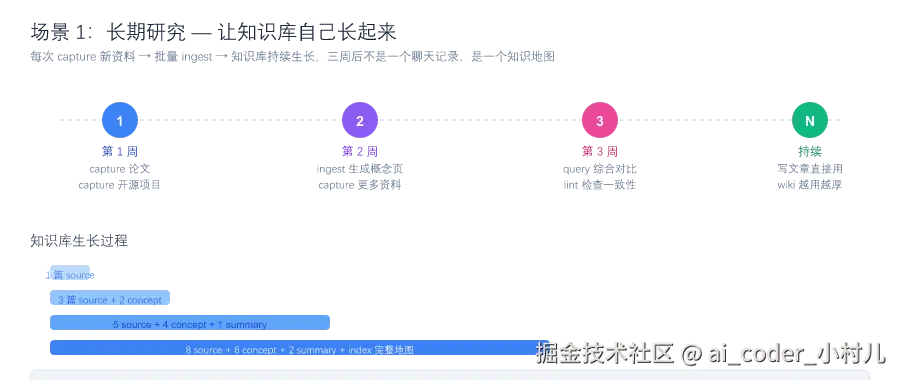
场景 1:长期研究 ------ 让知识库自己长起来
痛点:你在研究"Agent Memory vs RAG"这个话题,今天看一篇论文,明天读一个开源项目,后天和 AI 讨论两个小时。三周后你想写篇总结文章------发现所有讨论散落在十几个聊天窗口里,找不到线索。
怎么做:
bash
你:/memex:capture https://arxiv.org/abs/xxxx --scene research
你:读到新的论文或讨论出新想法时,继续 capture 进去
你:积累几份材料后------
你:/memex:ingest 把这些新研究材料消化进 wiki
你:/memex:query "agent memory 和 RAG 的设计取舍,我们目前知道哪些?"你始终在 agent 对话里。Agent 负责:
- 把每篇论文、每次讨论存成
raw/research/下的源文件 - ingest 时把新知识合并进
concepts/agent-memory.md、更新对比页summaries/agent-memory-vs-rag.md - query 时综合 wiki 里的所有内容,带引用回答
价值 :三周后,你拥有的不是十几个聊天窗口,而是一个结构化的知识地图------概念定义、方案对比、源材料索引、开放问题清单。写文章时,直接 /memex:query "agent memory 技术路线对比"。
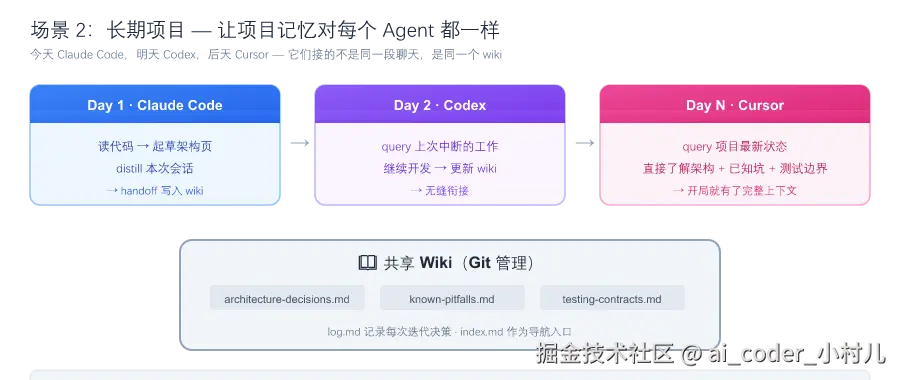
场景 2:长期项目 ------ 让项目记忆可继承
痛点:你的项目已经迭代了三个月。今天用 Claude Code,明天用 Codex,后天用 Cursor。每个新 Agent 都要重新理解架构、踩过的坑、命名的原因、测试的边界。
怎么做:
less
你:帮我连接这个项目到 memex 知识库
Agent:安装项目级别的 context 文件,记录相关的 scene
你:读当前代码和文档,然后起草这个项目的 architecture、command-design、known-pitfalls 页面
Agent:读源码,写带有文件路径引用的 code-reading 笔记到 raw/
你:/memex:ingest 把这次 code-reading 结论写进项目 wiki
Agent:更新架构决策页、命令设计页、已知坑页、测试契约页每次新会话开始:
bash
你:/memex:query "继续 ai-memex-cli 网站和文档工作"
Agent:从 wiki 拉出最近的 handoff 笔记、未完成的任务、需要遵守的测试契约
你:从上次中断的地方继续价值 :项目知识不再是散落在聊天里的只言片语。新 Agent 开局就能回答"为什么这么设计"、"哪些地方容易踩坑"、"上次改到哪了"。代码仓库本身就是 source of truth,wiki 存的是 Agent 从代码、文档、issue、反馈中提炼出来的可继承理解。
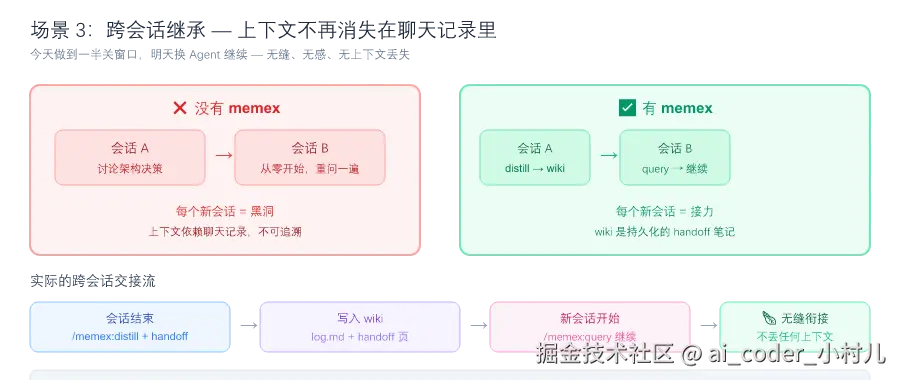
场景 3:跨会话继承 ------ 多次会话之间携带上下文
痛点:今天 Claude Code 做了一半,明天 Codex 继续,后天出差回来用 Cursor 检查。每个新会话都是一个黑洞------上下文全丢。
怎么做:
bash
你:/memex:distill 这次 Codex 会话,写清楚做到了哪、下一步做什么、有没有阻塞
Agent:找到当前 agent 的会话数据,蒸馏成 raw/sessions/ 下的结构化笔记
你:/memex:ingest 把这次 handoff 合并进项目记忆
Agent:更新项目 wiki 中的进度页和 log.md
------第二天,换了一个 agent------
你:/memex:query "上次中断的工作,下一步是什么"
Agent:从 wiki 里拉出 handoff 笔记和未完成项跨 Agent 完全无感------Claude Code 写的,Codex 能读;Codex 补充的,Cursor 继续改。它们不共享一个聊天窗口,它们共享 raw/、wiki/、index.md、log.md。
价值:连续性不再绑定任何一个厂商。你可以换 Agent、换模型、等一周再回来,任务状态还在同一个 wiki 里等你。
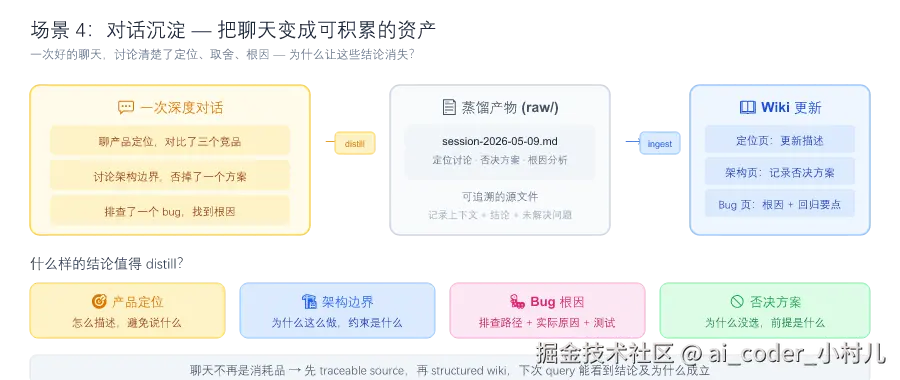
场景 4:对话沉淀 ------ 把聊天里的好结论留下
痛点:一场深入对话里,你们讨论了产品定位、架构边界、某个 bug 根因、三个被否决的方案。聊完很爽,一周后只记得大概------细节全丢了。
怎么做:
bash
你:/memex:distill 这次对话,我们聊清楚了产品定位和几个关键的取舍
Agent:把对话蒸馏成 source 页,保留上下文、决策、未解问题
你:/memex:ingest 只要这次确定的稳定结论,合并到已有的 positioning 页面里
Agent:读蒸馏产物,提取可复用的结论,增量更新已有页面,不复制已有内容什么样的结论值得沉淀?
- 产品定位:怎么描述产品、避免用什么说法
- 架构边界:为什么 CLI 不做语义层、为什么 raw 不可变
- Bug 根因:排查路径、实际原因、回归测试要点
- 被否决的方案:为什么没选、当时的前提是什么
价值:聊天不再是消耗品。重要推理先变成可追溯的 source,再变成结构化的 wiki 知识。下次 query 时,能同时看到结论和它为什么成立。如果前提变了,wiki 也能记录"老判断基于什么、新判断基于什么"。
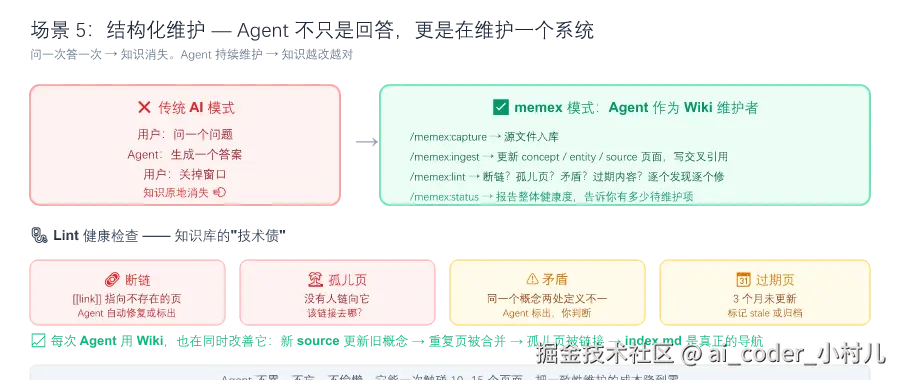
场景 5:结构化维护 ------ 让 Agent 持续维护知识,而不是只回答一次
痛点:大部分人用 AI 的模式是"问一次答一次"。知识在回答完后原地消失。没人去更新、去合并重复页、去修断链、去标记过期内容。
怎么做:
bash
你:/memex:status
Agent:报告 vault 整体健康状况------页面数、最近更新的 source、哪些页面过时了、哪些维护任务待处理
你:/memex:lint 检查断链、孤儿页、过期页、缺失的 frontmatter
Agent:跑机械 lint(路径、链接、frontmatter 正确性)+ 语义扫描(矛盾、重复、过时论断)
你:机械问题直接修,语义问题先给我看方案
arduino
你:把 Karpathy 的 LLM Wiki gist 加入知识库
Agent:capture 源文件 → 创建 concept 页 → 更新相关页面交叉引用 → 写 log
你:告诉我改了什么,还有什么需要 review价值:Wiki 不是一堆文件的堆积。它是一个被持续维护的结构化系统。每次 Agent 用它,也能同时改善它。重复页被合并或标注、孤儿页被找到、断链被修复、index.md 是真正的导航入口而非文件列表。
四、Agent 和 CLI 的分工边界
这里有一个设计决策需要讲清楚------CLI 永远只做机械正确性的事,不做语义判断。
| 层 | 谁负责 | 做什么 |
|---|---|---|
| Agent | Claude Code / Codex / Cursor | 判断哪些页面要更新、哪些概念要链接、哪些矛盾要保留、哪些总结要重写 |
| Slash Command | /memex:capture 等 6 个 |
把用户的自然语言意图翻译成底层 CLI 调用 |
| CLI | memex 命令行工具 |
文件读写、frontmatter 校验、链接检查、关键词搜索、会话解析------纯机械,不调 LLM API |
这意味着:
- 你的知识不绑定任何厂商------Agent 可以换,wiki 不变
- 你的知识是 Git 化的 Markdown------可以 diff、可以 blame、可以回退
- CLI 永远不帮你做语义决策------"这两个页面是不是该合并"这种问题,Agent 自己判断但会问你
CLI 的补充能力
上面 6 个 slash command 覆盖日常 90% 的交互。CLI 底层还提供几个高阶能力,但不建议作为日常入口:
| CLI 命令 | 用途 | 说明 |
|---|---|---|
memex watch |
自愈守护进程 | 监听 raw/ 变化,自动触发 ingest → lint 循环。适合长期跑 |
memex inject |
上下文注入 | 会话开始前,按任务描述从 wiki 拉最相关页面注入当前上下文 |
memex install-hooks |
安装 Agent hooks | 把 SessionStart / SessionEnd hook 写入 Agent 配置,自动 distill 和 inject |
memex search |
命令行搜索 | 全文搜索 wiki,适合脚本化场景 |
但这些不是入口。日常入口是 agent 对话框,是说 /memex:query 而不是敲 memex search。
五、两周跑通最小闭环
如果你想试,不需要什么额外工具。装好 memex,在你的 Agent 里说话就行。
第一周:搭 raw → wiki 的最小循环。 装好 memex,运行 memex onboard。然后开始往知识库喂东西------看到好文章、好推文、好想法,直接对 Agent 说 /memex:capture。攒够 5 到 10 条后,说 /memex:ingest 把这些新素材消化进知识库。Agent 会生成摘要、提取概念、更新索引。
第二周:让问答开始积累,跑第一次健康检查。 每次对知识库做复杂提问,结果让 Agent 存回 wiki。然后说 /memex:lint 给知识库做一次全面体检。Agent 会扫出断链、矛盾、过期页、孤儿页------先让它修机械问题,语义问题你看一下再决定。
两周之后你有一个能持续运转的小系统。规模不重要,流程跑通了就行。后面就是往 raw/ 里不断喂素材,让 Agent 持续编译。
六、知识库的"GitHub 时刻"
回到 Karpathy。他那篇 Gist 的最后一句话是:
这套东西目前仍然像一堆 hacky scripts,但有空间做成 incredible new product。
我想到 2006 年前的版本控制。那时候也是 svn、cvs、git 命令行,只有程序员在用。然后有人把它做成了 GitHub,整个协作方式都变了。
个人知识库可能正在类似的节点。今天它是 Obsidian + LLM + 手搓脚本的组合,看起来还很粗糙。但底层范式已经有了:把知识当代码管理。 有输入,有编译,有产物,有测试。
如果你是程序员,好消息是你不需要学任何新东西。代码仓库怎么管,知识库就怎么管。你积累了这么多年的工程直觉,终于可以用在自己的笔记上了。
Karpathy 原文里还有一段话:
人类放弃 Wiki 是因为维护负担的增长速度永远超过它带来的价值。你得亲手写每个页面、手动保持一致性、记住所有交叉引用。
但 LLM 不会无聊。它可以一次触碰 10-15 个页面,把新知识合并进去,更新索引,同时保持系统自洽。
人的工作:策展、取舍、提问、思考。LLM 的工作:剩下的全部。
memex 做的,就是把这句话变成可以跑的东西。
别让你的笔记腐烂。让它们被编译。
快速开始:
bash
npm install -g ai-memex-cli
memex onboard然后在你的 Claude Code / Codex / Cursor 里说第一句话:
bash
你:/memex:capture https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f --scene research
你:/memex:ingest Karpathy 的 LLM Wiki 思想,作为 research 场景的第一份材料
你:/memex:query "Karpathy 的 LLM Wiki 核心思想是什么?"给 AI 一份会生长的记忆。