一、ELK概述
1、概述
ELK 是三个开源软件的缩写,分别代表 Elasticsearch, Logstash 和 Kibana。这三个工具常常被用来处理和分析日志数据。
- Elasticsearch 是一个基于 Lucene 的搜索和分析引擎,它可以帮助你存储、搜索和分析大量的数据。
- Logstash 是一个服务器端的日志处理管道,它可以用来收集不同源的日志数据,并对这些数据进行处理和转发。
- Kibana 是一个数据可视化工具,它可以与 Elasticsearch 协同工作,提供日志分析和可视化的功能。
- Kafka 是一种分布式流式处理平台,它可以用来处理和转发实时数据。
在这个架构中,将 ELK 和 Kafka 结合起来使用:使用 Kafka 作为 Logstash 的输入源,将 Logstash 当作 Kafka 的消费者来接收数据,然后通过 Logstash 将数据发送给 Elasticsearch。
二、logstash
1.概述
1)概述
Logstash 是一个具有实时管道功能的开源数据收集引擎。Logstash 可以动态统一来自不同来源的数据,并将数据规范化到您选择的目标中。为了多样化的高级下游分析和可视化用例,清理和使所有数据平等化。
虽然 Logstash 最初在日志收集方面推动了创新,但它的能力远远超出了该用例。任何类型的事件都可以通过广泛的输入、过滤和输出插件进行增强和转换,许多本地编解码器进一步简化了摄入过程。Logstash 通过利用更多的数据量和种类加速您的洞察力。
官网地址:https://www.elastic.co/guide/en/logstash/current/index.html
2)组件
- inputs 模块负责收集数据
- filters 模块可以对收集到的数据进行格式化、过滤、简单的数据处理
- outputs 模块负责将数据同步到目的地
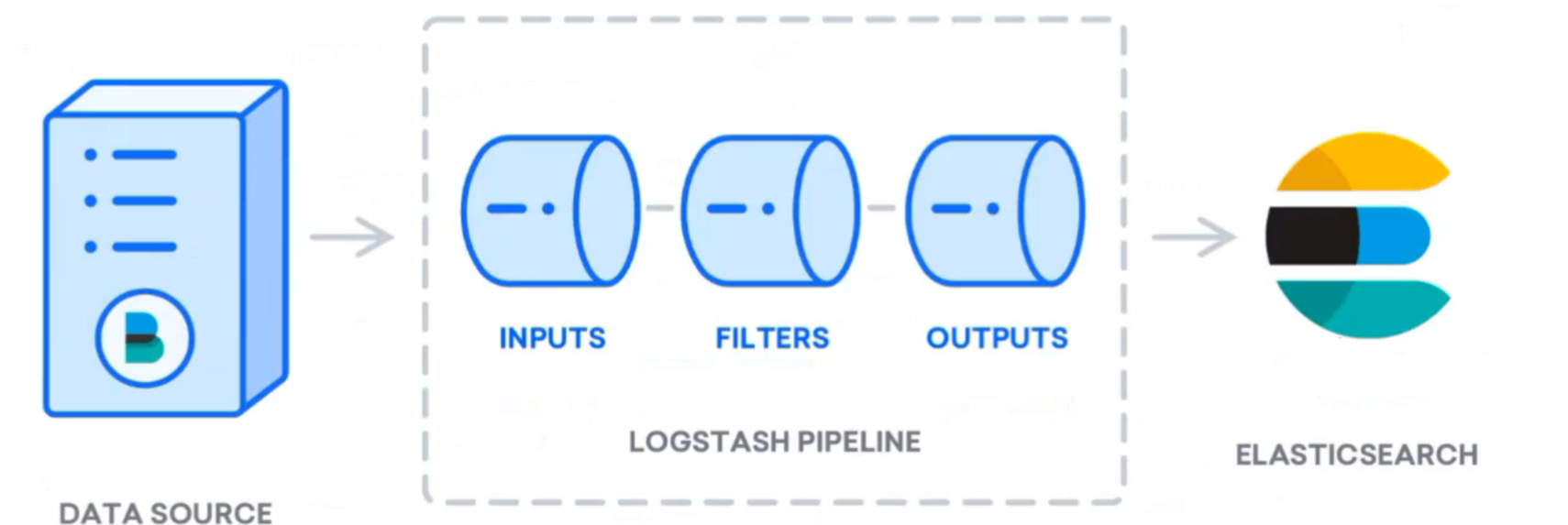
3)原理
Logstash 事件处理管道有三个阶段:输入 → 过滤器 → 输出。
- inputs 模块负责收集数据,filters 模块可以对收集到的数据进行格式化、过滤、简单的数据处理,outputs 模块负责将数据同步到目的地,Logstash 的处理流程,就像管道一样,数据从管道的一端,流向另外一端。
inputs 和 outputs 支持编解码器,使您能够在数据进入或离开管道时对数据进行编码或解码,而无需使用单独的过滤器。
2.安装
3.简单使用
配置输入输出,配置logstash读取nignx日志,输出到屏幕
1)添加 logstash 的读取 nginx 的配置文件
bash
vim /usr/local/logstash-7.13.2/config/nginx_test.conf
#####################################################
input {
file {
path => ["/var/log/nginx/access.log"]
start_position => "beginning"
}
}
output {
stdout {}
}2)启动 logstash 并读取 nginx-test.conf
bash
# 启动之前先停止 logstash
ps -ef | grep logstash
kill -9 <进程号>
# 启动 logstash 并读取 nginx-test.conf
/usr/local/logstash-7.13.2/bin/logstash -f /usr/local/logstash-7.13.2/config/nginx_test.conf这里读取到了日志
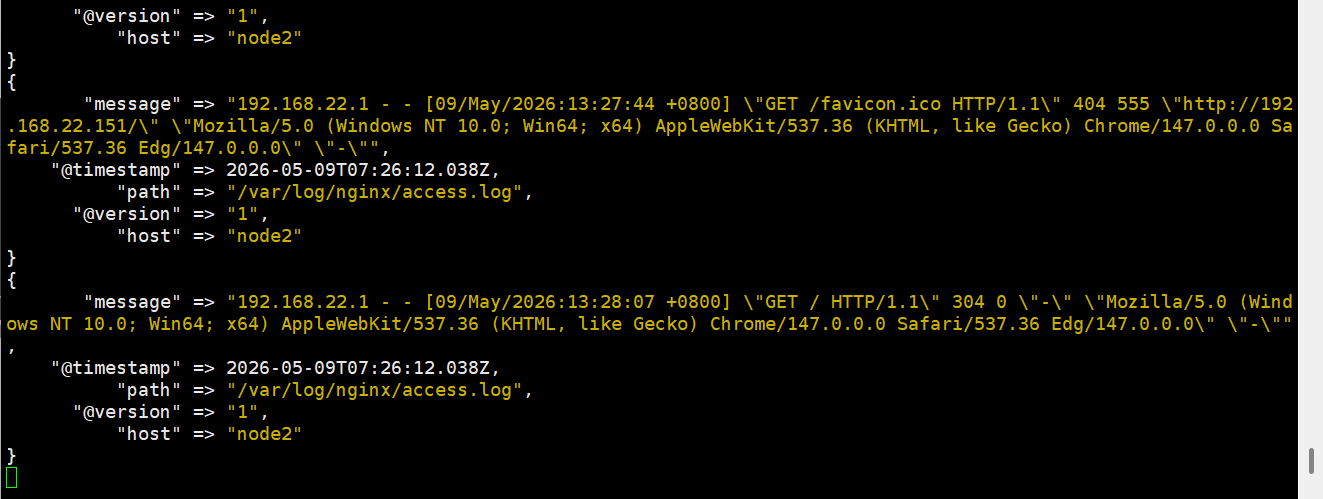
你的虚拟机里面得有nginx日志才能读取到,要么安装一个,要么就写一个文件进去
4.过滤器插件
1)描述
logstash 拿到的数据还是一整条数据,message中包含了日志的全部内容,我们希望能把一整条日志拆分成很多个字段,这样存储到 ES 中就方便数据的搜索。
2)插件概述
现在有了一个工作管道,但是日志消息的格式不是理想的。你想解析日志消息,以便能从日志中创建特定的命名字段。为此,应该使用 grok 过滤器插件。
- 使用 grok 过滤器插件,可以将非结构化日志数据解析为结构化和可查询的内容。
- grok 会根据你感兴趣的内容分配字段名称,并把这些内容和对应的字段名称进行绑定。
- grok 如何知道哪些内容是你感兴趣的呢?它是通过自己预定义的模式来识别感兴趣的字段的。这个可以通过给其配置不同的模式来实现。
3)使用
bash
vim /usr/local/logstash-7.13.2/config/nginx_test.conf
##########################################################
input {
file {
path => ["/var/log/nginx/access.log"]
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{IPORHOST:remote_addr} - %{DATA:remote_user} \[%{HTTPDATE:time_local}\] \"%{WORD:request_method} %{DATA:uri} HTTP/%{NUMBER:http_version}\" %{NUMBER:response_code} %{NUMBER:body_sent_bytes} \"%{DATA:http_referrer}\" \"%{DATA:http_user_agent}\"" }
}
geoip {
source => "remote_addr"
}
date {
match => [ "time_local", "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
output {
stdout {}
}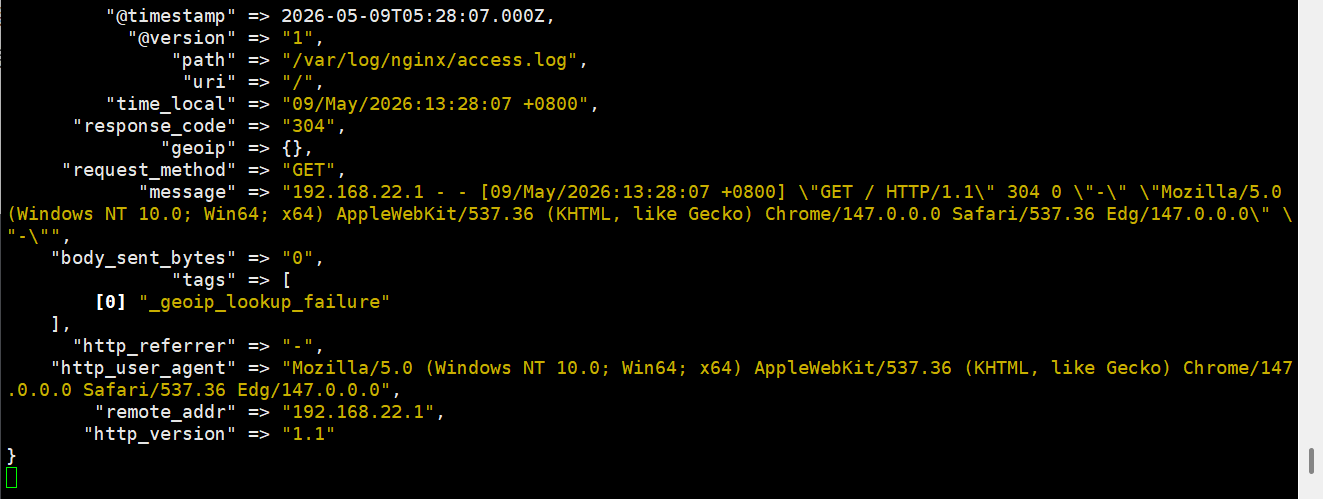
这里格式就修改了
三、kafuka
1.概述
1)概述
Kafka 是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于 大数据实时处理领域
2)架构
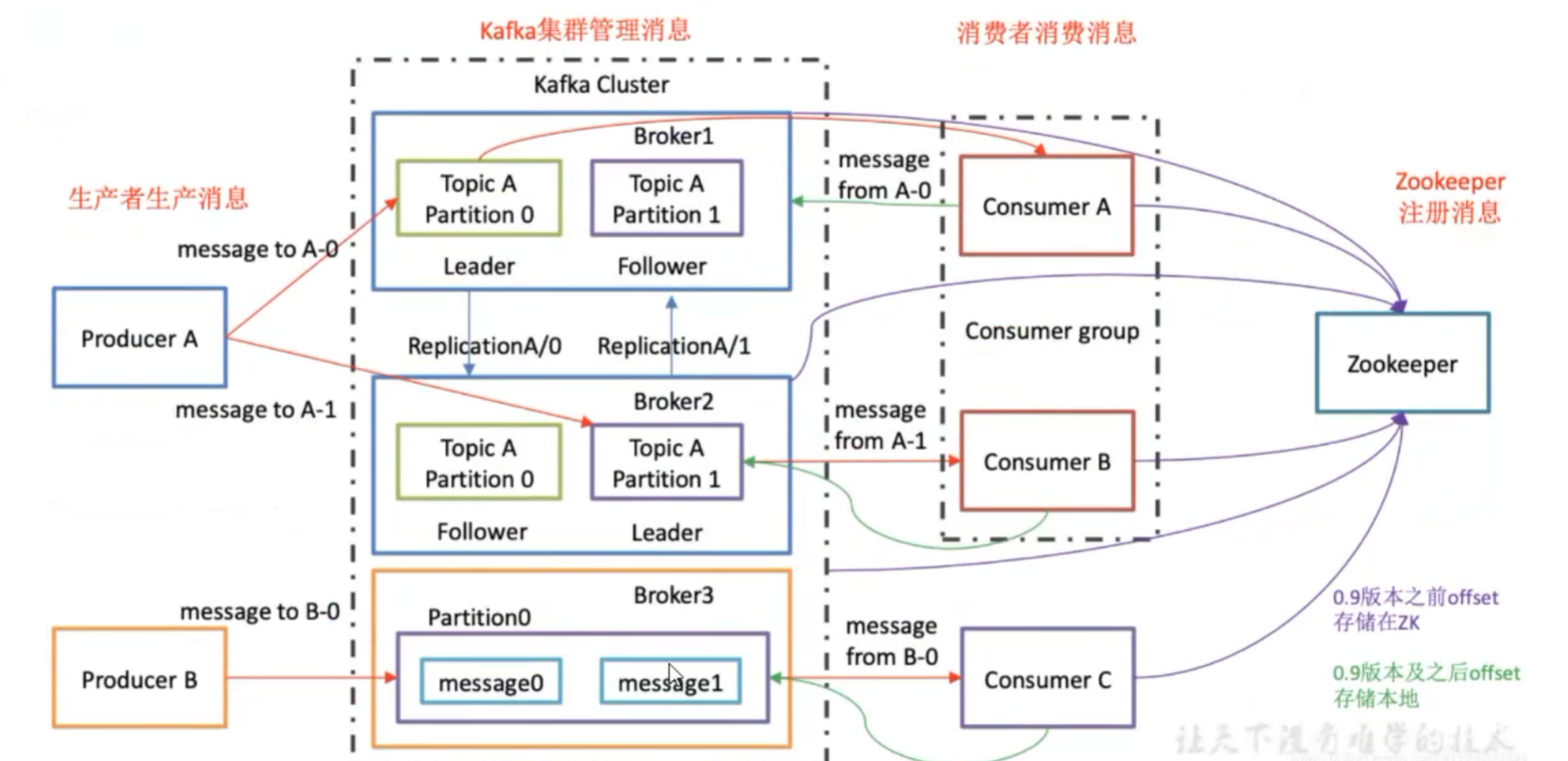
Producer:消息生产者,就是向 kafka broker 发消息的客户端
Consumer:消息消费者,向 kafka broker 取消息的客户端
Consumer Group(CG):消费者组,由多个 consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者
Broker:一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker 可以容纳多个topic
Topic:可以理解为一个队列,生产者和消费者面向的都是一个 topicPartition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列
Replica:副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且 kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 leader 和若干个
followerleader:每个分区多个副本的 "主",生产者发送数据的对象,以及消费者消费数据的对象都是
leaderfollower:每个分区多个副本中的 "从",实时从 leader 中同步数据,保持和 leader 数据的同步。leader 发生故障时,某个 follower 会成为新的 leader
2.安装
1)ZooKeeper
ZooKeeper 是一个分布式协调服务,它的主要作用是为分布式系统提供一致性服务,提供的功能包括:配置维护、分布式同步等。Kafka 的运行依赖 ZooKeeper,它也是 Java 微服务里常用的注册中心服务。
ZooKeeper 主要用来协调 Kafka 的各个 broker,不仅可以实现 broker 的负载均衡,而且当增加了 broker 或者某个 broker 故障时,ZooKeeper 将会通知生产者和消费者,这样可以保证整个系统正常运转。
在 Kafka 中,一个 topic 会被分成多个分区并被分到多个 broker 上,分区的信息、broker 的分布情况与消费者当前消费的状态信息,都存储在 ZooKeeper 中。
Kafka 运行依赖 ZK,Kafka 官网提供的 tar 包中,已经包含了 ZK,这里不再额外下载 ZK 程序。
2)安装JDK
已经安装过了
3)安装kafka
三台虚拟机都需要安装
bash
# 上传压缩包
kafka_2.12-2.8.0.tgz
# 解压缩即安装
tar xzvf kafka_2.12-2.8.0.tgz -C /usr/local/
# 修改包名
mv /usr/local/kafka_2.12-2.8.0/ /usr/local/kafka/4)修改配置zookeeper
bash
# 修改配置文件
sed -i 's/^[^#]/#&/' /usr/local/kafka/config/zookeeper.properties
vim /usr/local/kafka/config/zookeeper.properties
dataDir=/opt/data/zookeeper/data # 需要创建,所有节点一致
dataLogDir=/opt/data/zookeeper/logs # 需要创建,所有节点一致
clientPort=2181
tickTime=2000
initLimit=20
syncLimit=10
# 以下 IP 信息根据自己服务器的 IP 进行修改
server.1=192.168.22.151:2888:3888
server.2=192.168.22.147:2888:3888
server.3=192.168.22.148:2888:3888
# 创建data、log目录
mkdir -p /opt/data/zookeeper/{data,logs}
# 创建myid文件
echo 1 > /opt/data/zookeeper/data/myid其中最后一行每一个服务器的myid需要不一致,一般node1就是1,node2就是2,node3就是3
3.使用
1) 启动zookeeper集群
三个节点依次启动
bash
nohup /usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties &
# 启动成功后验证端口
netstat -tnlp | grep 21812)启动kafka
三节点依次启动
bash
nohup /usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties &3)验证
bash
# 在node1上创建topic
/usr/local/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testtopic
# 在node2上查看topic
/usr/local/kafka/bin/kafka-topics.sh --zookeeper localhost:2181 --list这里内存配置有要求,内存配置不够可能启动不了
四、项目实战
1.filebeat 日志到 kafka
1) 修改 filebeat 的配置,将采集到的日志输出到 kafka
bash
vim /usr/local/filebeat-7.13.2-linux-x86_64/filebeat.yml
########################################################
# 修改输出目标为kafka集群
output.kafka:
# initial brokers for reading cluster metadata
hosts: ["node1:9092", "node2:9092", "node3:9092"]
topic: 'nginx' # 监控nginx
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 1000000
bash
vim /usr/local/filebeat-7.13.2-linux-x86_64/modules.d/nginx.yml
#########################################
- module: nginx
access:
enabled: true
tags: ["access"]
error:
enabled: true
tags: ["error"]2)重启filebeat
bash
systemctl restart filebeat3)验证 kafka 集群中是否生成 nginx 的 topic
bash
/usr/local/kafka/bin/kafka-topics.sh --zookeeper localhost:2181 --list2.logstash 从 kafka 获取日志
1)修改 logstash 配置文件
bash
vim /usr/local/logstash-7.13.2/config/nginx_test.conf
############################################
input {
kafka {
type => "nginx_log"
codec => "json"
topics => ["nginx"]
decorate_events => true
bootstrap_servers => "192.168.22.151:9092, 192.168.22.147:9092, 192.168.22.148:9092"
}
}
filter {
grok {
match => { "message" => "%{IPORHOST:remote_addr} - %{DATA:remote_user} \[%{HTTPDATE:time_local}\] \"%{WORD:request_method} %{DATA:uri} HTTP/%{NUMBER:http_version}\" %{NUMBER:response_code} %{NUMBER:body_sent_bytes} \"%{DATA:http_referrer}\" \"%{DATA:http_user_agent}\"" }
}
geoip {
source => "remote_addr"
}
date {
match => [ "time_local", "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
output {
stdout {}
}2)将日志保存到ES中
bash
vim /usr/local/logstash-7.13.2/config/nginx_test.conf
###########################################################
input {
kafka {
type => "nginx_log"
codec => "json"
topics => ["nginx"]
decorate_events => true
bootstrap_servers => "192.168.22.151:9092, 192.168.22.147:9092, 192.168.22.148:9092"
}
}
filter {
grok {
match => { "message" => "%{IPORHOST:remote_addr} - %{DATA:remote_user} \[%{HTTPDATE:time_local}\] \"%{WORD:request_method} %{DATA:uri} HTTP/%{NUMBER:http_version}\" %{NUMBER:response_code} %{NUMBER:body_sent_bytes} \"%{DATA:http_referrer}\" \"%{DATA:http_user_agent}\"" }
}
geoip {
source => "remote_addr"
}
date {
match => [ "time_local", "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
output {
stdout {}
if [type] == "nginx_log" {
elasticsearch {
index => "nginx-%{+YYYY.MM.dd}"
codec => "json"
hosts => ["192.168.22.151:9200","192.168.22.147:9200","192.168.22.148:9200"]
}
}
}3)重启 logstash
bash
# 检查语法
/usr/local/logstash-7.13.2/bin/logstash --config.test_and_exit -f /usr/local/logstash-7.13.2/config/nginx_test.conf
# 重启logstash
/usr/local/logstash-7.13.2/bin/logstash -f /usr/local/logstash-7.13.2/config/nginx_test.conf3.kibana读取数据
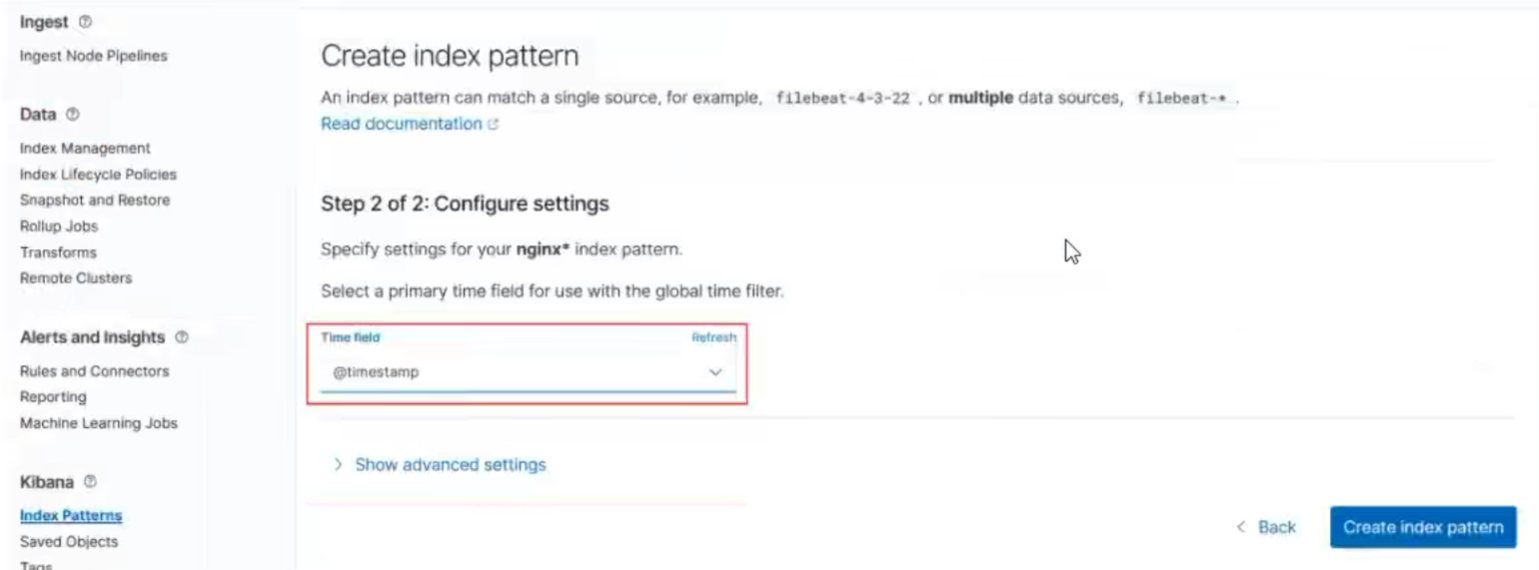
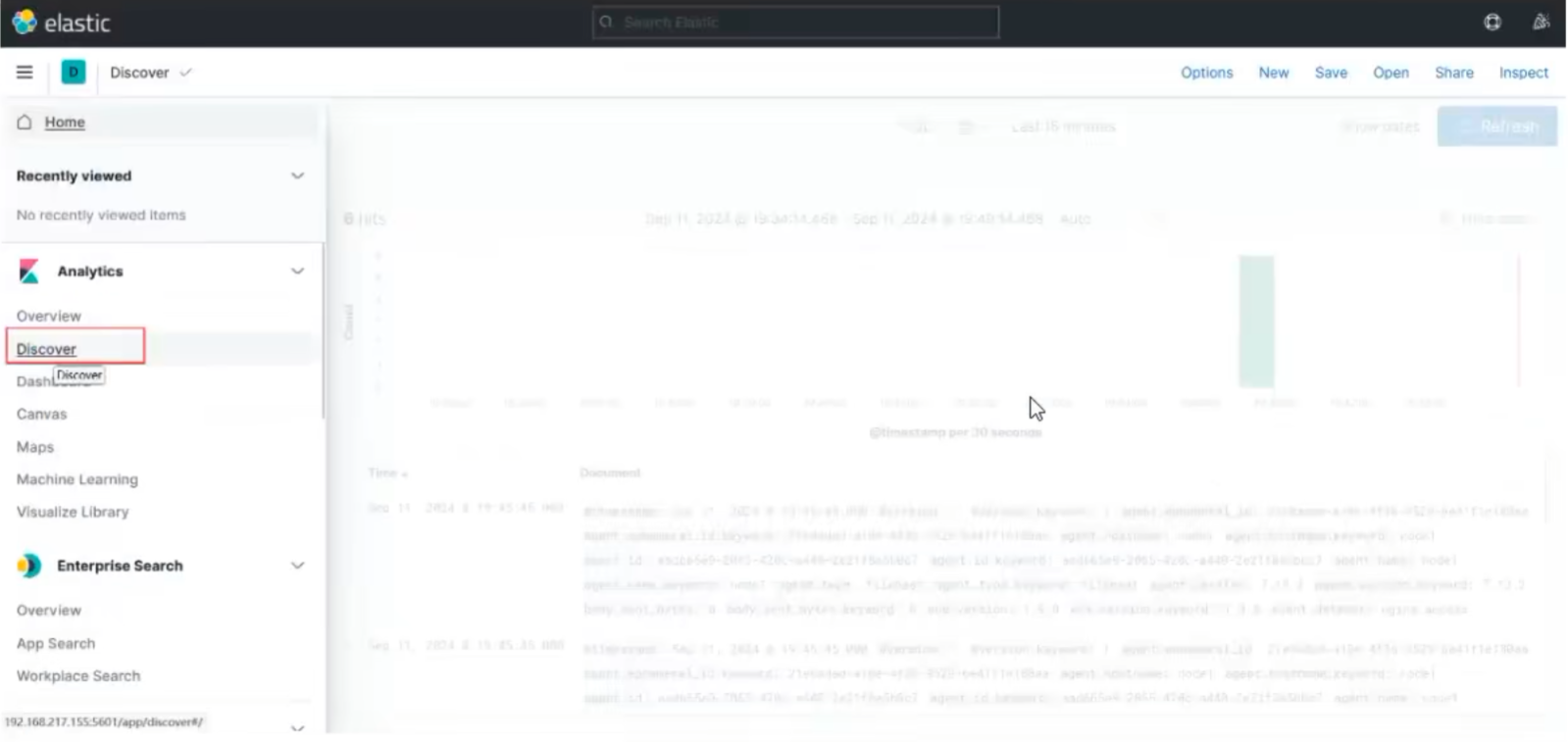
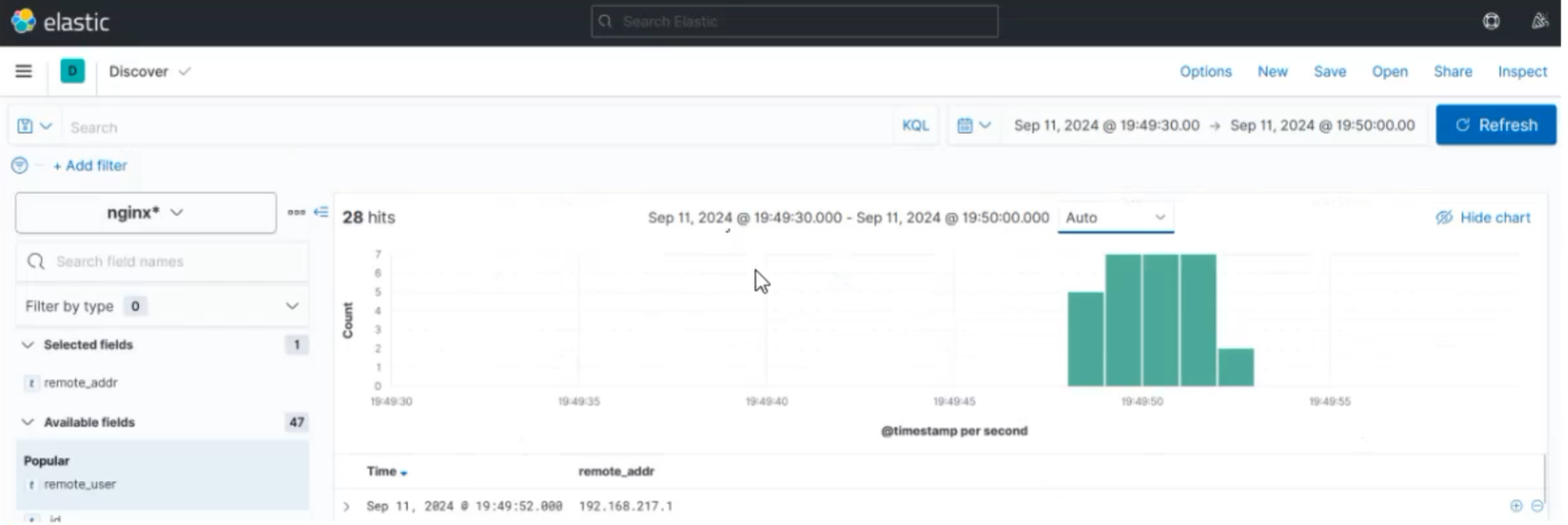
启动不起来只有视频图片
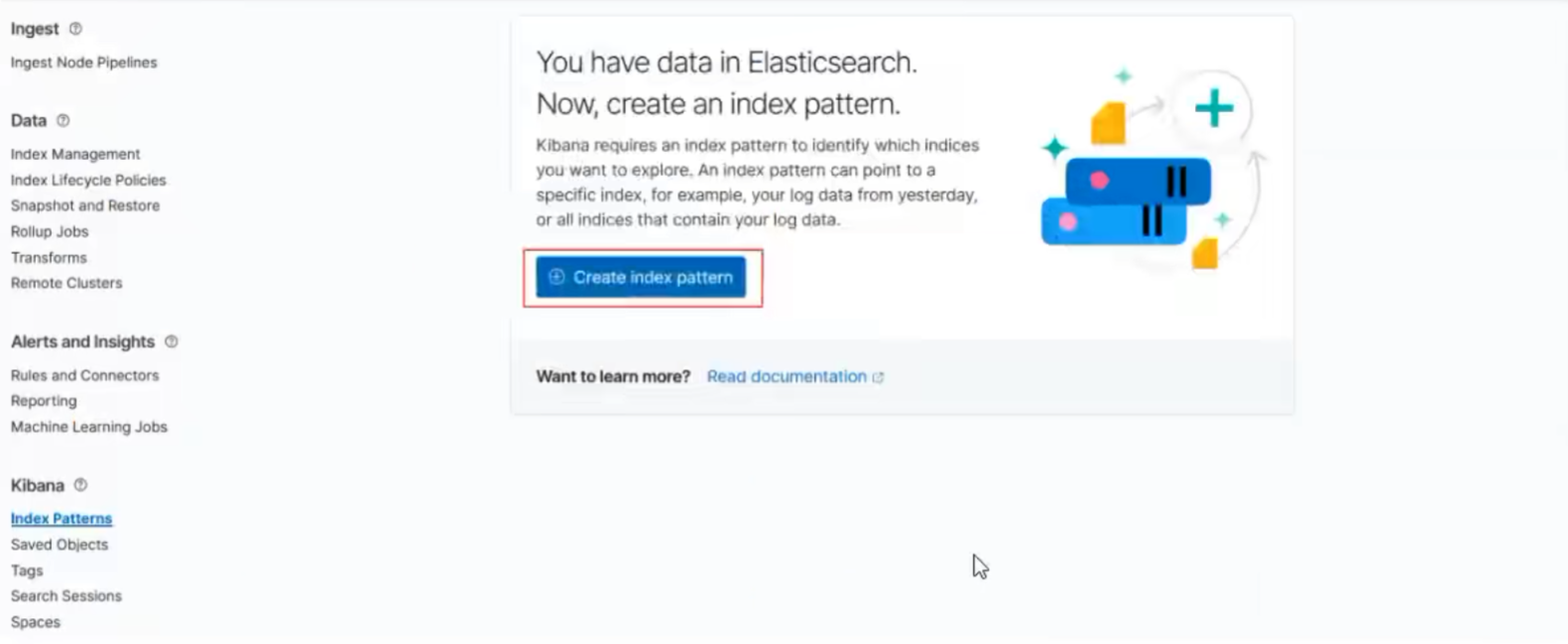
我们创建了nginx的消息队列,下面应该就能看到,直接添加,取到数据