文章目录
-
- 前言
- [一、 为什么有反射?](#一、 为什么有反射?)
-
- [1.1 硬编码](#1.1 硬编码)
- [1.2 软编码](#1.2 软编码)
- [1.3 框架的核心诉求:对象工厂模式](#1.3 框架的核心诉求:对象工厂模式)
- [二、 什么是反射?](#二、 什么是反射?)
-
- [2.1 万物皆对象](#2.1 万物皆对象)
-
- [2.1.1 概念理解](#2.1.1 概念理解)
- [2.1.2 底层分析](#2.1.2 底层分析)
- [2.2 Class 对象](#2.2 Class 对象)
-
- [2.2.1 概念理解](#2.2.1 概念理解)
- [2.2.2 使用操作](#2.2.2 使用操作)
- [2.3 反射的定义](#2.3 反射的定义)
- [2.4 反射的核心 API 详解](#2.4 反射的核心 API 详解)
-
- [2.4.1 `Constructor`(构造器对象)](#2.4.1
Constructor(构造器对象)) - [2.4.2 `Field`(字段对象)](#2.4.2
Field(字段对象)) - [2.4.3 `Method`(方法对象)](#2.4.3
Method(方法对象))
- [2.4.1 `Constructor`(构造器对象)](#2.4.1
- 三、注解
-
- [3.1 为什么要使用注解?](#3.1 为什么要使用注解?)
- [3.2 注解是什么](#3.2 注解是什么)
-
- [3.2.1 基本概念](#3.2.1 基本概念)
-
- [1. JDK自带三种注解](#1. JDK自带三种注解)
- [2. 现代 Web 框架中的注解](#2. 现代 Web 框架中的注解)
- [3.3 注解的本质](#3.3 注解的本质)
- [3.4 为什么注解里的"属性"要带括号](#3.4 为什么注解里的“属性”要带括号)
- [3.5 既然是接口,那是谁实例化了它](#3.5 既然是接口,那是谁实例化了它)
- [3.6 自定义注解的使用举例](#3.6 自定义注解的使用举例)
- [四、 反射与注解的结合](#四、 反射与注解的结合)
-
- [4.1 结合的底层原理](#4.1 结合的底层原理)
- [4.2 Spring Boot 中的经典应用:依赖注入](#4.2 Spring Boot 中的经典应用:依赖注入)
- [4.3 代码实战](#4.3 代码实战)
- 总结
前言
初学 Java SE 时,我们习惯手动 new 对象、调用方法,一切直白可控。
但进入 Spring、MyBatis 等框架后,@Autowired 自动装配依赖,@Transactional 即可生效事务......看似神奇,其实底层依然是 反射与注解的默默支撑。
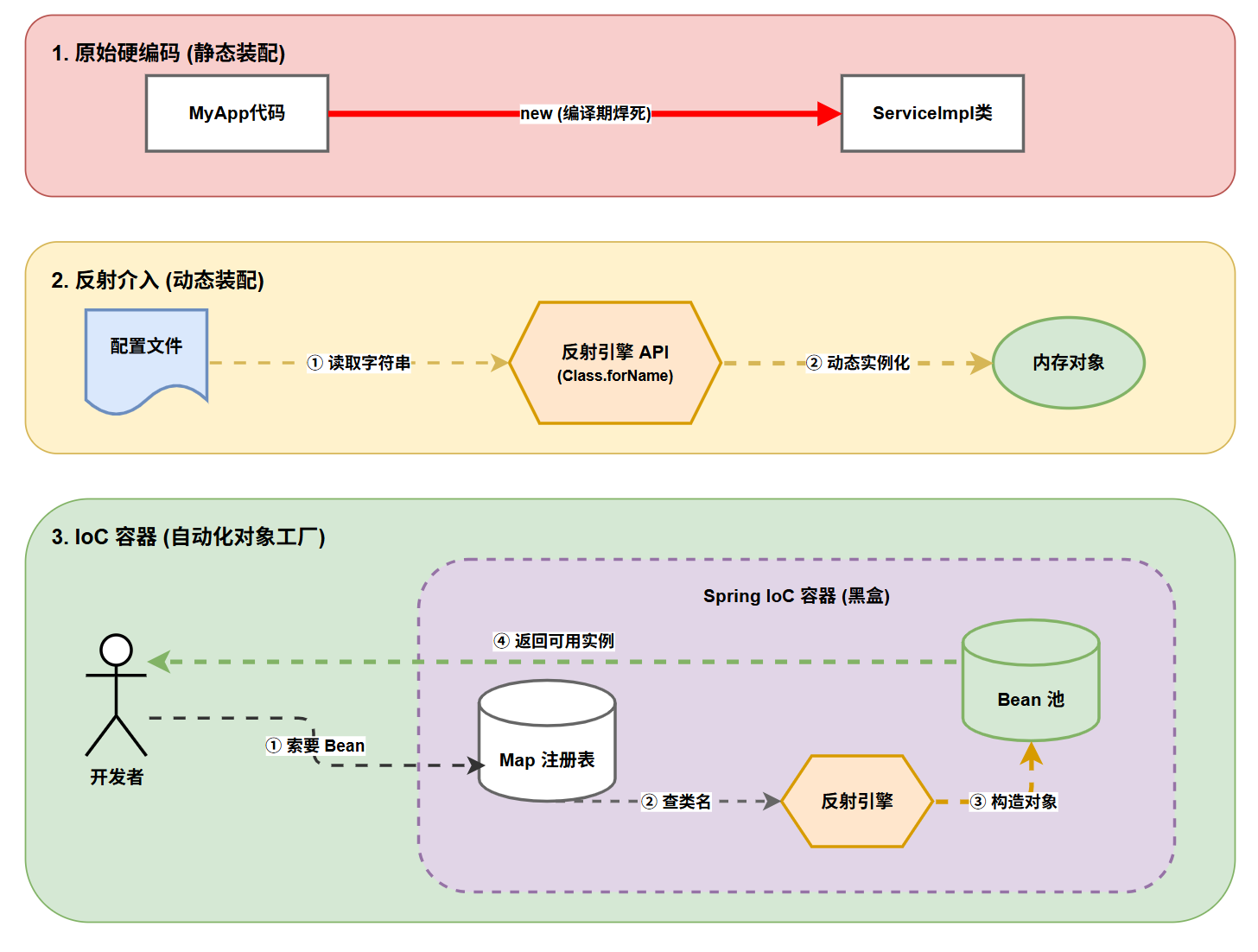
一、 为什么有反射?
在真正接触框架之前,很多开发者会觉得反射又慢又麻烦,直接 new 对象不好吗?
要回答这个问题,我们需要从代码的演进思维说起。
1.1 硬编码
日常业务开发中,我们绝大部分代码都是硬编码。所谓硬编码,就是在写代码的时候(编译期),就已经完全确定了要使用哪个具体的类。
代码演示:
Java
// 定义一个接口
public interface UserService {
void serve();
}
// 具体的实现类 A
public class UserServiceImpl implements UserService {
@Override
public void serve() { System.out.println("执行旧版业务逻辑..."); }
}
// 我们的主程序
public class MyApp {
public static void main(String[] args) {
// 【硬编码痛点】:主程序强依赖了 UserServiceImpl 这个具体的实现类
UserService service = new UserServiceImpl();
service.serve();
}
}分析:
编译器清清楚楚地知道你要实例化 UserServiceImpl。这种写法的优点是运行速度极快、类型绝对安全。
但它的缺点是极度僵化(高耦合) 。假设随着业务发展,你写了一个更好的实现类 UserServiceNewImpl,你必须打开 MyApp.java 的源代码,把 new UserServiceImpl() 改成 new UserServiceNewImpl(),然后重新编译整个项目,打包,停机发布。这在大型工程中是不可接受的。
1.2 软编码
为了解决硬编码带来的耦合问题,前人想出了一个聪明的办法:把"到底用哪个类"的决定权,从源代码里抽离出来,放到外部的配置文件里。
代码演示:
假设我们有一个外部配置文件 application.properties:
Properties
# 在不修改源代码的情况下,只需修改这里的字符串即可切换实现类
service.class=com.example.UserServiceNewImpl我们的主程序变成这样:
Java
public class MyApp {
public static void main(String[] args) throws Exception {
// 1. 读取外部配置文件,拿到类名的字符串(这里用硬编码字符串模拟读取过程)
String className = "com.example.UserServiceNewImpl";
// 2. 利用反射,把一个"字符串"变成活生生的"对象"
Class<?> clazz = Class.forName(className);
UserService service = (UserService) clazz.getDeclaredConstructor().newInstance();
service.serve();
}
}分析:
这时候,MyApp.java 在编译阶段根本不知道自己最终要创建什么对象,它只依赖 UserService 这个抽象的接口。
只有在程序运行那一刻,读取到了配置文件的字符串,才知道要加载谁。
这就是软编码 。而反射机制,就是跨越"字符串"和"运行时对象"之间那道鸿沟的唯一桥梁。
1.3 框架的核心诉求:对象工厂模式
Spring 这样的 IoC(控制反转)框架,本质上就是一个超级、通用的对象工厂(Object Factory)。
框架的作者(比如 Spring 的创始人 Rod Johnson)在写 Spring 的时候,完全不可能预知你(使用者)未来会写出什么奇怪的类(比如 OrderController、UserMapper)。
框架为了能帮你统一管理这些未知的对象,只能采用这样的设计:
代码演示(极简版 Spring 容器雏形):
Java
import java.util.HashMap;
import java.util.Map;
// 这是一个通用的对象工厂(模拟 Spring 的 ApplicationContext)
public class SimpleBeanFactory {
// 容器内部维护一个 Map,存放:<Bean的名字, 类的全限定名>
private Map<String, String> beanDefinitionMap = new HashMap<>();
public SimpleBeanFactory() {
// 框架在启动时,会去扫描你的 XML 配置文件或 @Component 注解
// 解析出你需要管理的类,并放进 Map 中
beanDefinitionMap.put("userService", "com.example.UserServiceNewImpl");
beanDefinitionMap.put("orderService", "com.example.OrderServiceImpl");
}
// 核心的工厂方法:你给我一个 Bean 的名字,我给你一个可用的对象
public Object getBean(String beanName) throws Exception {
String className = beanDefinitionMap.get(beanName);
if (className == null) {
throw new RuntimeException("容器中找不到对应的 Bean 定义");
}
// 框架利用反射,动态地替你把对象造出来
return Class.forName(className).getDeclaredConstructor().newInstance();
}
}
// 开发者使用框架时的样子:
public class DeveloperApp {
public static void main(String[] args) throws Exception {
SimpleBeanFactory factory = new SimpleBeanFactory();
// 开发者再也不需要自己去 new 对象了,全权交给框架的反射去创建
UserService userService = (UserService) factory.getBean("userService");
userService.serve();
}
}总结:
从这三个步骤的演进,你就能深刻体会到:没有反射,就没有软编码;没有软编码,就写不出任何具备扩展性的现代 Java 框架。
反射就是为了解决在"运行时处理未知类"这一核心诉求而诞生的。
二、 什么是反射?
2.1 万物皆对象
在 Java 中,"一切皆对象"这条箴言需要更精确的表述:不仅类的实例 是对象,类本身也是一个对象。
在常规的面向对象编程中,我们的认知是这样的:
- 类(Class) 是图纸、是模具。
- 对象(Object) 是根据图纸造出来的汽车、是模具刻出来的饼干。
图纸就是图纸,汽车就是汽车,两者截然不同。但是,在 JVM 的世界里,为了能让程序在运行时去读取和修改图纸,JVM 把"图纸"本身也封装成了一个"产品"(对象)。
2.1.1 概念理解
假设你现在就是詹姆斯·高斯林(Java 之父),你需要设计一种数据结构,用来在内存中保存程序员写出来的 User、Order、Product 等各种各样的类的信息。你会怎么设计?
你肯定会专门写一个类,用来描述"类"这种抽象事物。这个用来描述"类"的类,就叫 java.lang.Class。
它的底层逻辑(伪代码)大概长这样:
Java
// 这是 JDK 源码里真实存在的 java.lang.Class 类的缩影
public final class Class<T> {
private String name; // 记录类的全限定名(如 com.example.User)
private Field[] fields; // 记录类里面有哪些属性
private Method[] methods; // 记录类里面有哪些方法
private Constructor[] cons; // 记录类里面有哪些构造器
private Class superclass; // 记录它的父类是谁
// ... 各种获取这些信息的方法
}在 Java 中,实例化(创建对象)不仅发生在业务层面,也发生在底层系统层面。这其实是一个三层结构:
-
第一层:万物之母
java.lang.Class。-
这是 JDK 源码里自带的一个类。你可以把它理解为一家「专门生产 3D 打印机的工业母机」。
-
它的工作只有一个:定义"3D打印机(图纸)"应该长什么样(必须有类名、有字段数组、有方法数组)。
-
-
第二层:图纸对象
User.class(中间态)。-
当 JVM 启动,加载到你写的
User代码时,这台"工业母机"就自动启动了,它为你生产出了一台「印着 User 标签的专属 3D 打印机」**。 ** -
这台印着 User 标签的 3D 打印机,本身就是一个实实在在的 产品(对象) !它是
java.lang.Class生产出来的实例。
-
-
第三层:业务对象
new User()(最终态)。-
现在,你在代码里写下了
new User()(或者用反射newInstance),就相当于启动了这台专属的 User 3D 打印机。 -
最后打印出了一个个具体的「塑料小人(user 业务对象)」。
-
代码证明如下:
java
User userObj = new User(); // 这是一个 User 对象
// 证明 1:userObj 是谁的实例?
System.out.println(userObj instanceof User); // true (塑料小人是 3D 打印机印出来的)
Class<?> userClassObj = User.class; // 这是一个 Class 对象
// 证明 2:User.class 是谁的实例?
System.out.println(userClassObj instanceof java.lang.Class); // true (3D 打印机是工业母机造出来的)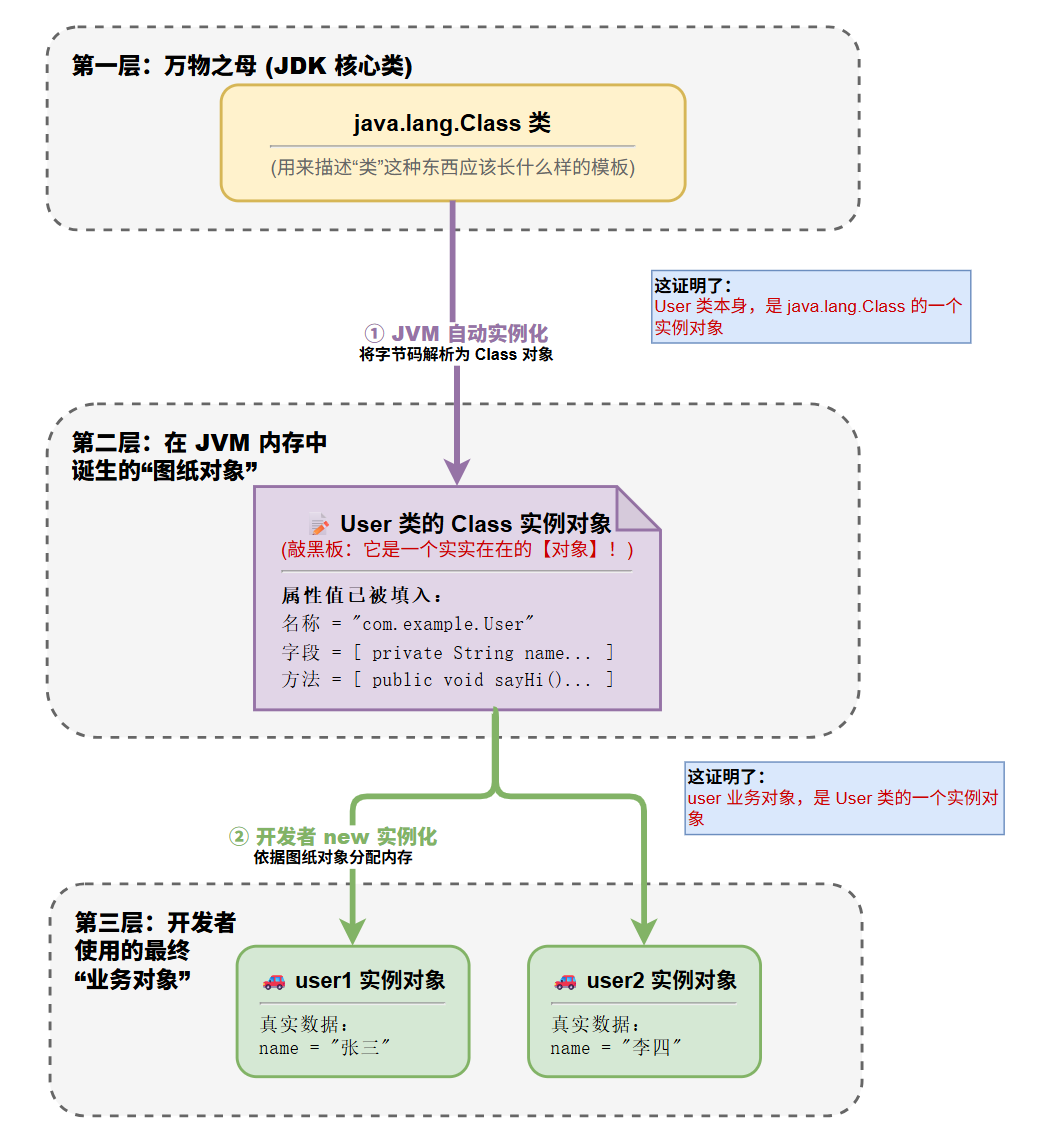
2.1.2 底层分析
当你的程序启动,执行到 User user = new User(); 时,背后发生了两件事:
- 印户口本(仅一次) :JVM 的类加载器读取了
User.class字节码文件,并在堆内存中实例化了一个java.lang.Class对象。这个对象里的name属性被填上了"com.example.User",fields数组被填上了你写的属性。这面"镜子"就此诞生。 - 造汽车(可无数次) :JVM 照着这面镜子(图纸),在堆内存的另一块区域,为你开辟空间,真正造出了那个包含数据的
user实例对象。
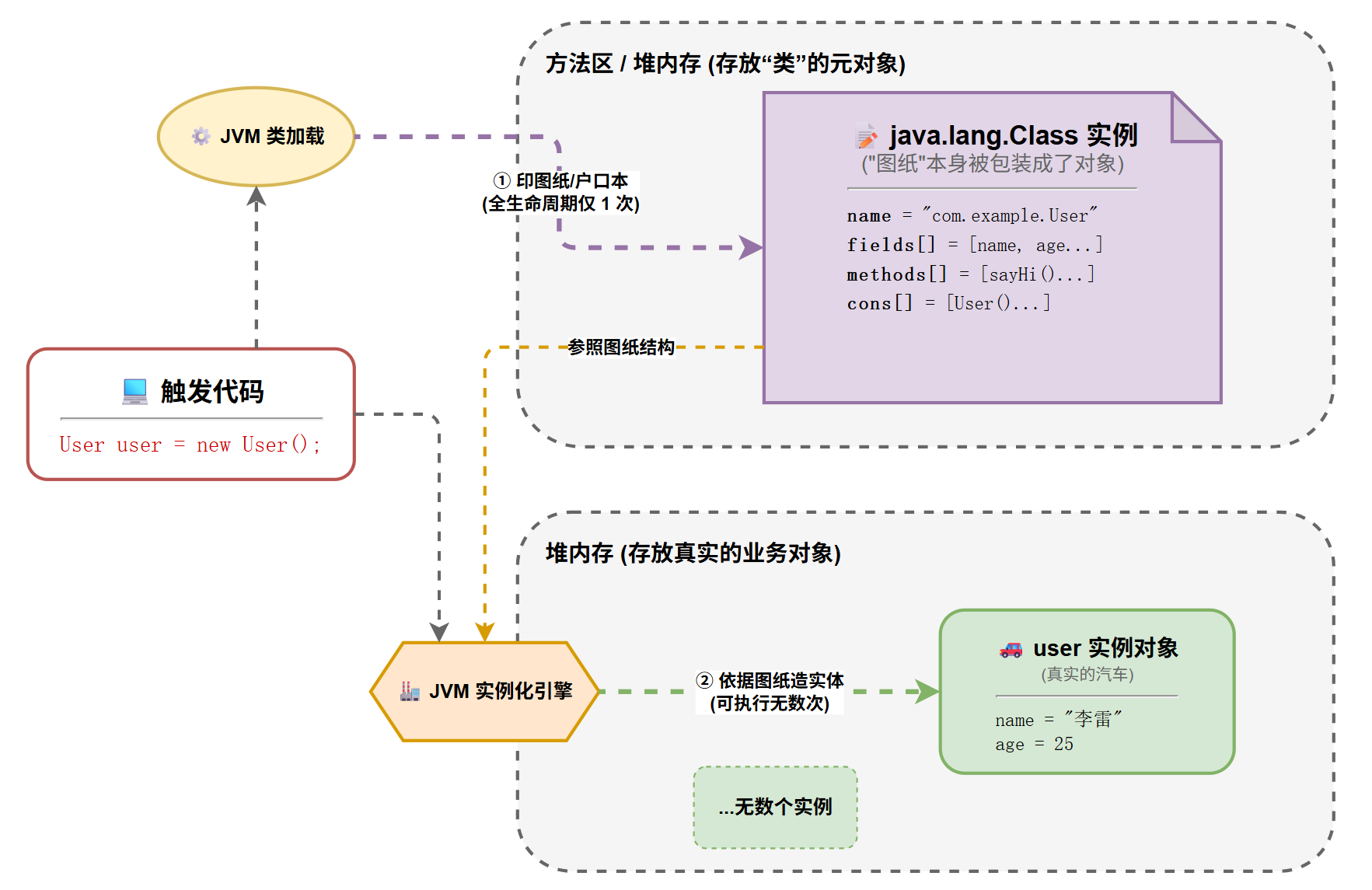
核心总结 :User 类的实例是 user 对象;而 User 类本身,则是 java.lang.Class 这个类的实例对象!这就是所谓的"万物皆对象"。
2.2 Class 对象
2.2.1 概念理解
Class 是 Java 中用来描述「类本身」的最终类 (java.lang.Class),无法被继承。
每一个被 JVM 加载的类 / 类型,在内存中 都会生成唯一的 Class 对象,这个对象封装了该类的全部元数据信息(类名、父类、接口、字段、方法、构造器等),是 Java 反射、动态代理、多态实现的核心基石。
通俗类比:
| 概念 | 生活类比 | 核心作用 |
|---|---|---|
| 类(Class 代码) | 建筑图纸 | 定义「结构、能力」的模板 |
| Class 对象(类对象) | 图纸的官方唯一备案档案 | 记录图纸的全部信息,全局唯一 |
| 实例对象(Instance) | 按图纸建成的房子 | 按模板生成的具体个体,有独立属性 |
三个核心概念的精准区分
| 概念 | 代码示例 | 核心本质 | 生命周期 |
|---|---|---|---|
| 类(普通类) | public class Dog {} |
编译期生成的.class字节码文件,是代码模板 |
编译期生成,运行期被 JVM 加载 |
| Class 对象(类对象) | Dog.class |
类加载后 JVM 在内存中生成的唯一对象,代表类本身 | 和类的生命周期绑定,类卸载时回收 |
| 实例对象 | new Dog() |
基于类模板创建的具体实例,堆内存中的对象 | 随 new 创建,无引用时被 GC 回收 |
Class 对象的核心特性(必记)
- 绝对单例性(有边界) :同一个类,在同一个 JVM 实例 + 同一个类加载器 下,只会生成一个 Class 对象,
==比对永远返回 true。 - 全类型覆盖:所有 Java 类型都有对应的 Class 对象,包括:
- 只读性:Class 对象封装的类元数据,运行期常规手段无法修改(仅可通过字节码注入等特殊技术修改)。
- JVM 私有创建 :Class 类的构造方法是 private,只有 JVM 能创建 Class 对象,开发者无法通过
new Class()手动生成。
2.2.2 使用操作
关于泛型 Class<?>:
平时代码中常看到 Class<?>。
这里的 ? 是通配符,表示未知的类型。因为我们在编写反射通用代码时,通常不知道要处理的具体是哪个类,使用 Class<?> 可以避免编译器的未经检查警告(Unchecked Warning),保持代码的泛型安全。
有三种常见方式,应用场景各不相同:
Java
// 1. Class.forName("全限定名"):最常用,适用于完全不知道类,只有类名字符串的情况(如加载数据库驱动)
Class<?> clazz1 = Class.forName("com.example.User");
// 2. 类名.class:适用于在编译前就已经明确知道并且引入了该类的情况(常用于锁对象、参数类型传递)
Class<?> clazz2 = User.class;
// 3. 对象.getClass():适用于已经有了该类的实例对象,想反推它属于哪个类
User user = new User();
Class<?> clazz3 = user.getClass();一个类在同一个类加载器中,只有一个唯一的 Class 对象。无论通过哪种方式获取,得到的都是同一个实例:
java
Class<User> c1 = User.class;
Class<?> c2 = Class.forName("com.example.User");
Class<?> c3 = new User().getClass();
System.out.println(c1 == c2); // true
System.out.println(c2 == c3); // true这个唯一性保障了同步锁(User.class 可作为同步监视器)、类型比较(instanceof 底层用到 Class 对象)等基础机制的正确运行。
2.3 反射的定义
反射(Reflection) 是 Java 语言提供的一种机制。它允许程序在运行时(Runtime):
-
动态探索:获取任意一个类的所有内部结构(包含私有属性、方法、构造器、注解等)。
-
动态操作:动态调用任意一个对象的方法,修改其属性。
理解编译期和运行期,可以看我的另一篇博客:java的运行机制:编译期、运行期和半编译半解释性-CSDN博客
反射的本质:
-
先拿到目标类的 Class 对象(反射的入口)
-
通过 Class 对象获取它的 "全息档案"(动态探索)
-
通过档案里的信息,去操作具体的实例对象(动态操作)
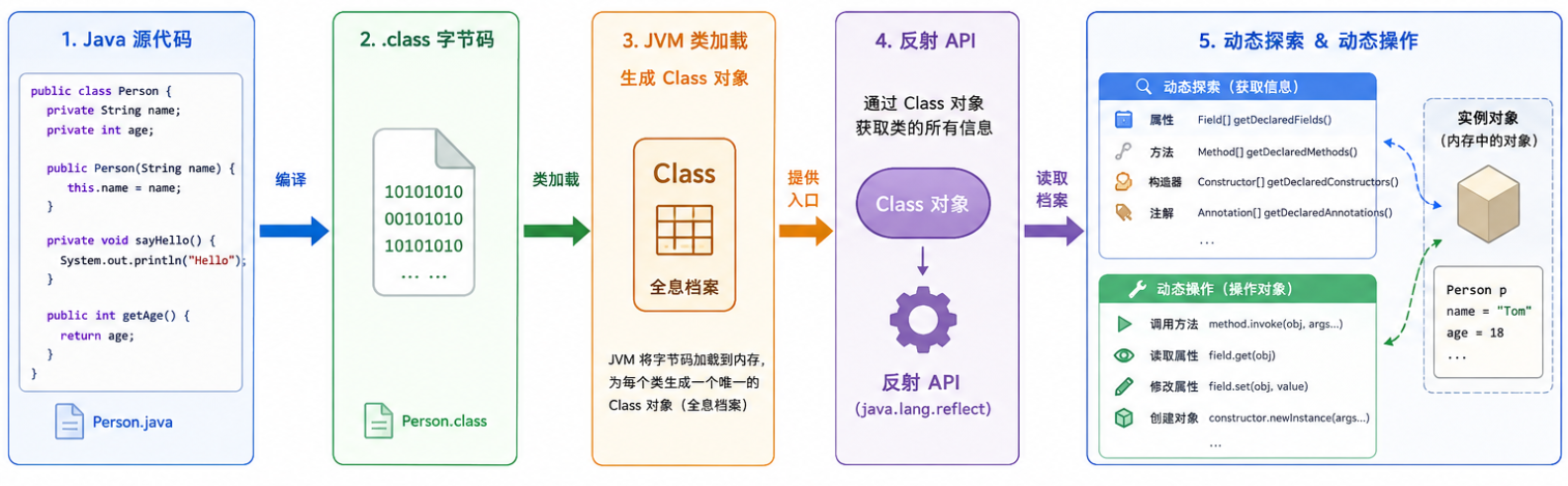
2.4 反射的核心 API 详解
java.lang.reflect 包下提供了反射的核心组件:
-
Constructor:用来「造对象」,核心是newInstance,私有构造器记得setAccessible(true)。 -
Field:用来「改属性」,核心是get和set,static 字段传null。 -
Method:用来「调方法」,核心是invoke,异常记得用getCause()解包。
它们就是三个类,和 String、ArrayList 一样:
java
java.lang.reflect.Constructor<T> // 代表一个构造方法
java.lang.reflect.Field // 代表一个成员变量(字段)
java.lang.reflect.Method // 代表一个成员方法当你调用 clazz.getConstructor() 时,JVM 并不是返回了一团神秘的东西,而是老老实实地 new 了一个 Constructor 对象给你。
同理,getDeclaredField() 返回一个 Field 实例,getMethod() 返回一个 Method 实例。
Java 虚拟机(JVM)在加载一个类时,不仅会把类本身封装成一个 Class 对象,还会把这个类里面的每一个成员(构造器、字段、方法)都解析并封装成对应的 Constructor、Field 和 Method 对象。
真正的构造器、字段、方法的定义,在 JVM 底层是以 C++ 数据结构的形式 ,存放在元空间(Metaspace) 的。
这些原始数据对 Java 程序是不可见的。
Constructor、Field、Method 的作用,就是把那些黑盒的底层元数据,包装成 Java 对象,让你能通过调用这些对象的方法,去间接操纵底层的实际内容。
在常规开发中,我们是这样想的:"我要调用 user 对象的 getName 方法"。
在反射开发中,思维模型要倒转过来:"我拿到了一个名为 getName 的 Method 对象,我要让这个 Method 对象去作用于 user 实例"。
2.4.1 Constructor(构造器对象)
用于动态创建实例。
getConstructor(Class<?>... parameterTypes):获取 public 构造器。getDeclaredConstructor(...):获取所有声明的构造器(包含 private)。newInstance(Object... initargs):执行构造器创建对象。setAccessible(true): 突破 private 限制
**注意:**当我们使用单例模式或某些隐藏了实例创建逻辑的框架时,类的构造器往往是 private 的。此时,必须配合 setAccessible(true) 使用,否则会抛出 IllegalAccessException。
java
public class User {
private String name;
// 私有构造器
private User(String name) {
this.name = name;
}
}
// 反射调用测试
Class<?> clazz = User.class;
// 1. 获取私有构造器 (注意:这里用 getDeclaredConstructor)
Constructor<?> constructor = clazz.getDeclaredConstructor(String.class);
// 2. 打破封装,允许访问私有成员
constructor.setAccessible(true);
// 3. 动态实例化对象
Object userInstance = constructor.newInstance("ReflectUser");2.4.2 Field(字段对象)
用于动态读取和修改属性。
getDeclaredField(String name):获取当前类声明的指定名称的字段(无论什么访问修饰符)。setAccessible(true):反射的破壁者。操作 private 字段前必须调用此方法打破封装。get(Object obj):获取指定对象obj中该字段的值。set(Object obj, Object value):将指定对象obj中该字段的值修改为value。
注意:
- 静态(static)字段操作 :由于静态字段属于类级别而不是对象级别,所以在调用
get()或set()时,传入的对象实例可以直接写null。 - 类型安全检查 :如果
set时传入的数据类型与字段实际类型不匹配,会引发IllegalArgumentException。
java
// 假设前面的 userInstance 已经创建
Field nameField = clazz.getDeclaredField("name");
// 打破私有属性的封装
nameField.setAccessible(true);
// 读取属性值
String currentName = (String) nameField.get(userInstance);
System.out.println("修改前: " + currentName); // 输出: ReflectUser
// 修改属性值
nameField.set(userInstance, "NewName");
System.out.println("修改后: " + nameField.get(userInstance)); // 输出: NewName2.4.3 Method(方法对象)
用于动态执行方法。
getDeclaredMethod(String name, Class<?>... parameterTypes):根据方法名和参数列表获取当前类声明的方法。invoke(Object obj, Object... args):核心执行方法 。obj:要执行该方法的具体对象实例。args:方法运行所需的实际参数。
注意:
- 静态方法调用 :如果反射调用的方法是
static的,invoke的第一个参数obj传null即可(因为静态方法不依赖于具体的对象实例)。 - 异常解包机制 :当被反射调用的目标方法内部抛出异常时,反射机制会将其包装成一个
InvocationTargetException抛出。要获取目标方法真实抛出的业务异常,必须调用exception.getCause()进行解包。
代码:
Java
public class Calculator {
private int add(int a, int b) {
return a + b;
}
public static void staticMethod() {
System.out.println("静态方法被调用");
}
}
Class<?> calcClass = Calculator.class;
Object calcInstance = calcClass.getDeclaredConstructor().newInstance();
// 1. 调用私有实例方法
Method addMethod = calcClass.getDeclaredMethod("add", int.class, int.class);
addMethod.setAccessible(true);
// obj 传实例对象,后面传实参
Object result = addMethod.invoke(calcInstance, 10, 20);
System.out.println("10 + 20 = " + result);
// 2. 调用静态方法
Method staticMethod = calcClass.getDeclaredMethod("staticMethod");
// 静态方法不需要实例,obj 传 null
staticMethod.invoke(null);三、注解
如果说反射是底层执行的引擎,那么注解就是指挥引擎运行的"路标"。
3.1 为什么要使用注解?
在早期 Spring 或 Struts,软编码大量依赖庞大且冗长的 XML 配置文件。
这被称为"XML 地狱"。开发人员不得不在 Java 代码和 XML 文件之间反复横跳。
案例:声明一个 UserService,并给它注入一个 Dao 对象。
Java 代码本身极其干净(但毫无线索):
Java
public class UserService {
private UserDao userDao;
// 必须写又长又啰嗦的 setter 方法供 XML 调用
public void setUserDao(UserDao userDao) {
this.userDao = userDao;
}
}对应的 XML 配置文件(灾难的开始):
XML
<!-- applicationContext.xml 里面可能堆积了成百上千个这样的标签 -->
<bean id="userDao" class="com.example.dao.UserDaoImpl" />
<bean id="userService" class="com.example.service.UserService">
<!-- 靠全限定类名和字符串来匹配,极易写错 -->
<property name="userDao" ref="userDao" />
</bean>痛点解析:
- 反复横跳 :开发者看代码时,不知道这个类被谁用、怎么配的;看 XML 时,又不知道这个类的具体逻辑。必须在
.java和.xml文件之间疯狂切换。 - 重构灾难:一旦修改了类名或包名,如果在 XML 里忘了同步修改(由于是纯字符串,编译器不会报错),程序在运行时就会直接崩溃。
- 极度臃肿:大型项目的 XML 文件动辄几千行,甚至需要拆分成几十个 XML 互相引入,维护成本极高。
注解的出现解决了这个问题:它允许将元数据(Metadata)直接标记在代码本身上(类、方法、字段上),做到了配置与代码的高内聚,大大提升了可读性和开发效率。
java
// @Service 路标:告诉 Spring 引擎,这是一个业务逻辑类,请帮我实例化
@Service
public class UserService {
// @Autowired 路标:告诉 Spring 引擎,请把我需要的 UserDao 自动拿过来给我
@Autowired
private UserDao userDao;
// 连 setter 方法都不需要写了!
}一个极其容易陷入误区的点:很多人认为 @Autowired 能自动注入对象,是因为这个注解里写了注入的代码。
其实不是,因为:"注解本身不包含任何逻辑,它没有任何行为能力。"
注意:注解在本质上只是一个标记、一个标签。就好比你在超市商品上贴了一个"打八折"的红色贴纸(注解)。贴纸本身不能改变商品的价格,真正改变价格的,是收银员(反射机制)看到了这个贴纸,然后按照收银机里的逻辑给你减钱。
3.2 注解是什么
3.2.1 基本概念
注解(Annotation),也叫元数据(Metadata)。简单来说,它就是一种代码级别的说明和标签。
它是 JDK 1.5 引入的特性,与类、接口、枚举属于同一个层次。它可以像"便利贴"一样,贴在包、类、字段、方法、局部变量、方法参数等的前面。
那么,贴上这些"便利贴"到底有什么用呢?总体来说,注解的作用可以分为三大类:
- 编译检查:通过注解让编译器实现基本的编译检查(比如告诉编译器这个方法是重写的,帮我盯紧点)。
- 编写文档:配合工具(如 javadoc),通过代码里标识的注解生成 API 文档。
- 代码分析与运行(核心):在运行期,框架可以通过反射机制读取这些注解,进而动态地改变程序的运行逻辑。
JDK 提供的最常用的三个基础注解,它们主要负责编译阶段的检查与提示。
@Override: 标记在成员方法上,用于标识当前方法是重写父类(父接口)方法,编译器在对该方法进行编译时会检查是否符合重写规则,如果不符合,编译报错。
@Deprecated: 用于标记当前类、成员变量、成员方法或者构造方法过时如果开发者调用了被标记为过时的方法,编译器在编译期进行警告。
@SuppressWarnings: 压制警告注解,可放置在类和方法上,该注解的作用是阻止编译器发出某些警告信息。
1. JDK自带三种注解
-
@Override:这个注解只能标记在方法上,用来告诉编译器:"我这个方法是重写父类(或接口)的,请帮我检查一下方法名和参数对不对"。javapublic class Animal { public void speak() { System.out.println("动物发声"); } } public class Dog extends Animal { // 加上 @Override 后,如果下面方法名错写成 spaek(),编译器会直接标红报错! // 如果不加注解,写成 spaek() 编译器只会认为你写了一个新方法,导致潜藏 bug。 @Override public void speak() { System.out.println("汪汪汪"); } } -
@Deprecated:随着软件迭代,有些老方法或老类存在缺陷或性能问题,不推荐大家继续使用了,但为了向前兼容又不能直接删除。这时就可以用它。javapublic class StringUtils { // 标记为已过时。如果你在其他地方调用这个方法,IDEA 会给它划上一条删除线 @Deprecated public static void oldFormat() { System.out.println("这个方法太老了,不安全,别用了!"); } public static void newFormat() { System.out.println("请使用全新的格式化方法"); } } -
@SuppressWarnings:有时候我们的代码会产生一些黄色的警告(比如未使用的变量、未经检查的泛型转换等)。如果你确信代码没问题,可以用它来让编译器"闭嘴"。javapublic class Test { // 压制"未使用"和"未检查的强转"警告,让代码看起来干干净净 @SuppressWarnings({"unused", "unchecked"}) public void doSomething() { int a = 10; // 虽然没被使用,但加了注解后,IDEA 不会再报黄色的警告 List list = new ArrayList(); list.add("Hello"); // 泛型强转警告也会被压制 List<String> strList = (List<String>) list; } }
2. 现代 Web 框架中的注解
JDK 内置注解只是牛刀小试。
注解真正的威力,在于结合反射机制,彻底改变了现代 Java 后端(如 Spring MVC)的开发模式,改进了老版本的了让人头疼的"XML 配置文件"。
在现代开发中,注解就像是指挥框架运行的路标。
Java
// @RestController:告诉 Spring,这是一个处理 Web 请求的类,帮我把它变成一个 Bean 放到容器里。
@RestController
// @RequestMapping:定义这个类处理所有以 "/api/users" 开头的请求。
@RequestMapping("/api/users")
public class UserController {
// @Autowired:自动装配。告诉 Spring,请帮我在内存里找一个 UserService 对象,强行塞到这个字段里,不用我自己 new 了!
@Autowired
private UserService userService;
// @GetMapping:处理 HTTP 的 GET 请求。如果浏览器访问 "/api/users/1",就会进到这里。
// @PathVariable:告诉框架,把 URL 里的 "{id}" 抠出来,赋值给入参 userId。
@GetMapping("/{id}")
public User getUserById(@PathVariable("id") Long userId) {
return userService.findById(userId);
}
}在这个例子中,代码极其简洁,没有任何多余的配置代码。
这全都归功于注解:开发者负责贴标签 ,Spring 框架在底层负责用反射读取标签并执行对应的操作。
3.3 注解的本质
注解并不是什么凭空出现的全新数据结构,它的本质,就是一个普普通通的 Java 接口(Interface)。
我们可以通过代码反编译,来拆穿编译器的这层"语法糖"。
假设我们自定义了一个极其简单的注解:
Java
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.reflect.Method;
// 【步骤一:定义注解】
@Retention(RetentionPolicy.RUNTIME) // 关键:告诉JVM在运行时保留这个注解
public @interface MyAnnotation {
String value() default "Hello";
int age();
}
// 【步骤二:使用注解(贴标签)】
@MyAnnotation(value = "张三", age = 18) // 贴在类上
public class Student {
@MyAnnotation(age = 20) // 贴在方法上(value有默认值,可以省略)
public void study() {
System.out.println("好好学习!");
}
}
// 【步骤三:解析注解(读标签)】
public class Main {
public static void main(String[] args) throws Exception {
// 1. 获取类上的注解数据
MyAnnotation classAnno = Student.class.getAnnotation(MyAnnotation.class);
if (classAnno != null) {
System.out.println("类上的注解 -> 值: " + classAnno.value() + ", 年龄: " + classAnno.age());
}
// 2. 获取方法上的注解数据
Method method = Student.class.getMethod("study");
MyAnnotation methodAnno = method.getAnnotation(MyAnnotation.class);
if (methodAnno != null) {
System.out.println("方法上的注解 -> 值: " + methodAnno.value() + ", 年龄: " + methodAnno.age());
}
}
}赋值 :在 Student 类中写下 @MyAnnotation(value = "张三", age = 18) 时,其实就是给注解的属性赋了值。
取值 :在 Main 类中,通过 getAnnotation() 方法,就可以把刚刚赋进去的 "张三" 和 18 动态拿出来。
本质 :注解本身是不包含任何逻辑的,它仅仅是用来"存数据"的标签。必须配合反射把数据取出来,它才有意义。
当我们使用 javac 将其编译成 .class 字节码文件,然后再使用 javap -c 命令对其进行反编译后,你看到的真实代码形态是这样的:
Java
// 是一个接口
public interface MyAnnotation extends java.lang.annotation.Annotation {
// 所谓的属性,变成了抽象方法
public abstract String value();
public abstract int age();
}解析:
- 隐式继承 :所有的注解类,在编译后都会自动继承
java.lang.annotation.Annotation接口。 - **
@interface**:仅仅是 Java 编译器提供的一个语法糖,作用是告诉编译器:"嘿,请帮我把这个类编译成继承了Annotation的接口"。
3.4 为什么注解里的"属性"要带括号
注解声明属性时,一般要在后面加上一对括号,比如 String value(); 而不是 String value;。
现在知道了它的本质是接口,一切就豁然开朗了:
- 在 Java 的接口中,不允许定义普通的成员变量(只能定义
public static final的常量)。 - 为了让接口能够"携带"数据,Java 的设计者只能利用抽象方法来模拟属性。
- 当你写下
String value();时,你不是在定义一个变量,而是在定义一个有返回值的方法 。当你在代码中使用@MyAnnotation(value = "Test")时,其实是在告诉 JVM:"待会儿如果有人调用value()这个方法,你就给他返回"Test"这个字符串"。
3.5 既然是接口,那是谁实例化了它
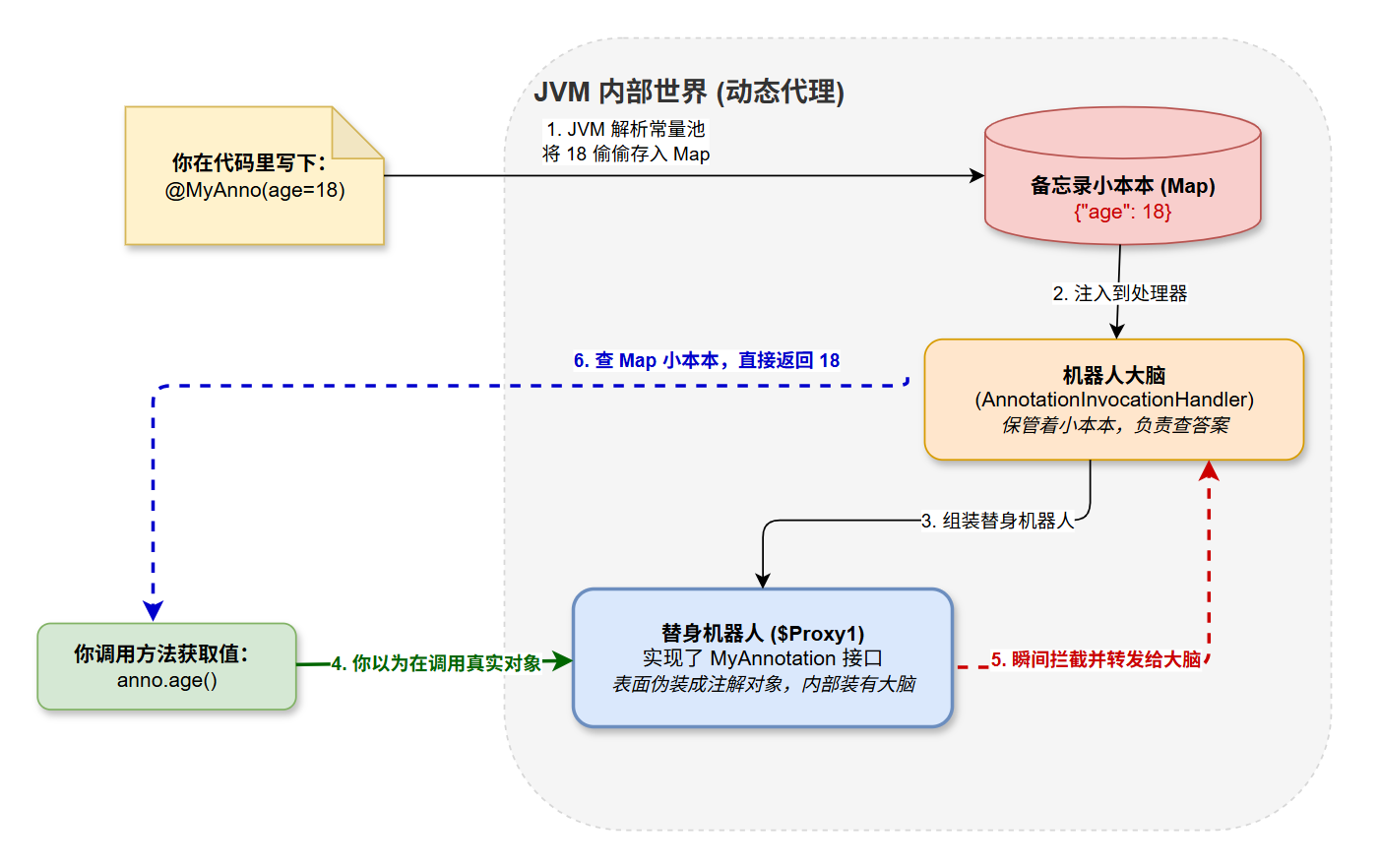
我们知道,接口是不能直接 new 的。既然注解是接口,那么当我们在运行期通过反射调用 clazz.getAnnotation(MyAnnotation.class) 时,拿到的那个注解对象,究竟是个什么东西?是谁实现了这个接口?
答案是:JDK 动态代理。
当我们在代码里写下 @MyAnnotation 并通过反射去获取它时,JVM 在底层做了一系列非常隐蔽的操作:
- 解析常量池:JVM 会读取 .class 文件常量池中关于这个注解的配置信息。
- 生成代理类 :JVM 在内存中动态生成了一个实现了
MyAnnotation接口的代理类(类似于$Proxy1)。 - 拦截方法调用 :这个代理类内部持有一个
AnnotationInvocationHandler(注解调用处理器)。这个处理器内部维护了一个Map<String, Object>,里面存储了你写在代码里的属性名和属性值(比如key="value",value="Test")。 - 返回结果 :当你调用
myAnnotation.value()时,实际上是被代理类拦截了。代理类会去那个 Map 里面,根据方法名("value")取出对应的值,并返回给你。
所以整体流程是这样的:
- 编写期 :你写下
@interface,看起来像个标签。 - 编译期 :编译器把它转成
interface extends Annotation,属性变方法。 - 运行期 :JVM 通过 动态代理 生成这个接口的实现类对象,并通过反射把你在代码里配的值,存进代理对象内部的 Map 里。最后,你调用方法获取值。
简单总结:
-
表象 :反射拿到的并不是真正的注解实现类,而是 JVM 在运行期临时生成的一个动态代理对象(Proxy)。
-
核心 :这个代理对象内部持有一个名为
AnnotationInvocationHandler的调用处理器。 -
机制 :这个处理器里面维护了一个
Map,里面存着我们写注解时赋的值(比如age=18)。当我们通过反射调用注解的属性方法时,其实是被这个处理器拦截了,它直接从 Map 里查出对应的值返回给我们。所以调用注解方法,本质上是在查 Map 字典!
3.6 自定义注解的使用举例
"元注解"就是用来标注注解的注解,它们定义了你的自定义注解的作用域和生命周期。
-
@Retention(保留策略)定义注解存活的时间,由
RetentionPolicy枚举控制:-
SOURCE:只在源码中存在,编译后被抹除(如@Override,只是给编译器看的)。 -
CLASS:保留到字节码文件中,但 JVM 运行时不加载。 -
RUNTIME:最重要! 保留到运行时,可以通过反射读取。所有需要配合反射使用的注解,必须设置为 RUNTIME。
-
-
@Target(作用目标)
定义注解可以贴在谁身上,由 ElementType 枚举控制:
-
TYPE:类、接口。 -
FIELD:字段属性。 -
METHOD:方法。 -
PARAMETER:方法参数。
代码测试:
Java
import java.lang.annotation.*;
// 元注解:指定注解的保留策略为运行时(只有这个策略才能被反射读取)
@Retention(RetentionPolicy.RUNTIME)
// 元注解:指定注解可以标注在字段和方法上
@Target({ElementType.FIELD, ElementType.METHOD})
public @interface MyAnnotation {
// 注解的属性,本质上是接口的抽象方法
boolean required() default true;
}
// 类上的注解
@MyAnnotation("类注解")
public class User {
// 字段上的注解
@MyAnnotation("字段注解")
private String name;
// 方法上的注解
@MyAnnotation("方法注解")
public void sayHi() {}
}
// 反射读取注解
public class AnnotationReadDemo {
public static void main(String[] args) throws Exception {
Class<User> userClass = User.class;
// 1. 读取类上的注解
if (userClass.isAnnotationPresent(MyAnnotation.class)) {
MyAnnotation classAnnotation = userClass.getAnnotation(MyAnnotation.class);
System.out.println("类注解值:" + classAnnotation.value());
}
// 2. 读取字段上的注解
Field nameField = userClass.getDeclaredField("name");
if (nameField.isAnnotationPresent(MyAnnotation.class)) {
MyAnnotation fieldAnnotation = nameField.getAnnotation(MyAnnotation.class);
System.out.println("字段注解值:" + fieldAnnotation.value());
}
// 3. 读取方法上的注解
Method sayHiMethod = userClass.getDeclaredMethod("sayHi");
if (sayHiMethod.isAnnotationPresent(MyAnnotation.class)) {
MyAnnotation methodAnnotation = sayHiMethod.getAnnotation(MyAnnotation.class);
System.out.println("方法注解值:" + methodAnnotation.value());
}
}
}四、 反射与注解的结合
只有反射,只能盲目地操作类;
只有注解,它只是一堆不会生效的死文本;
当反射去读取注解时,两个机制就产生了非常好的效果。
4.1 结合的底层原理
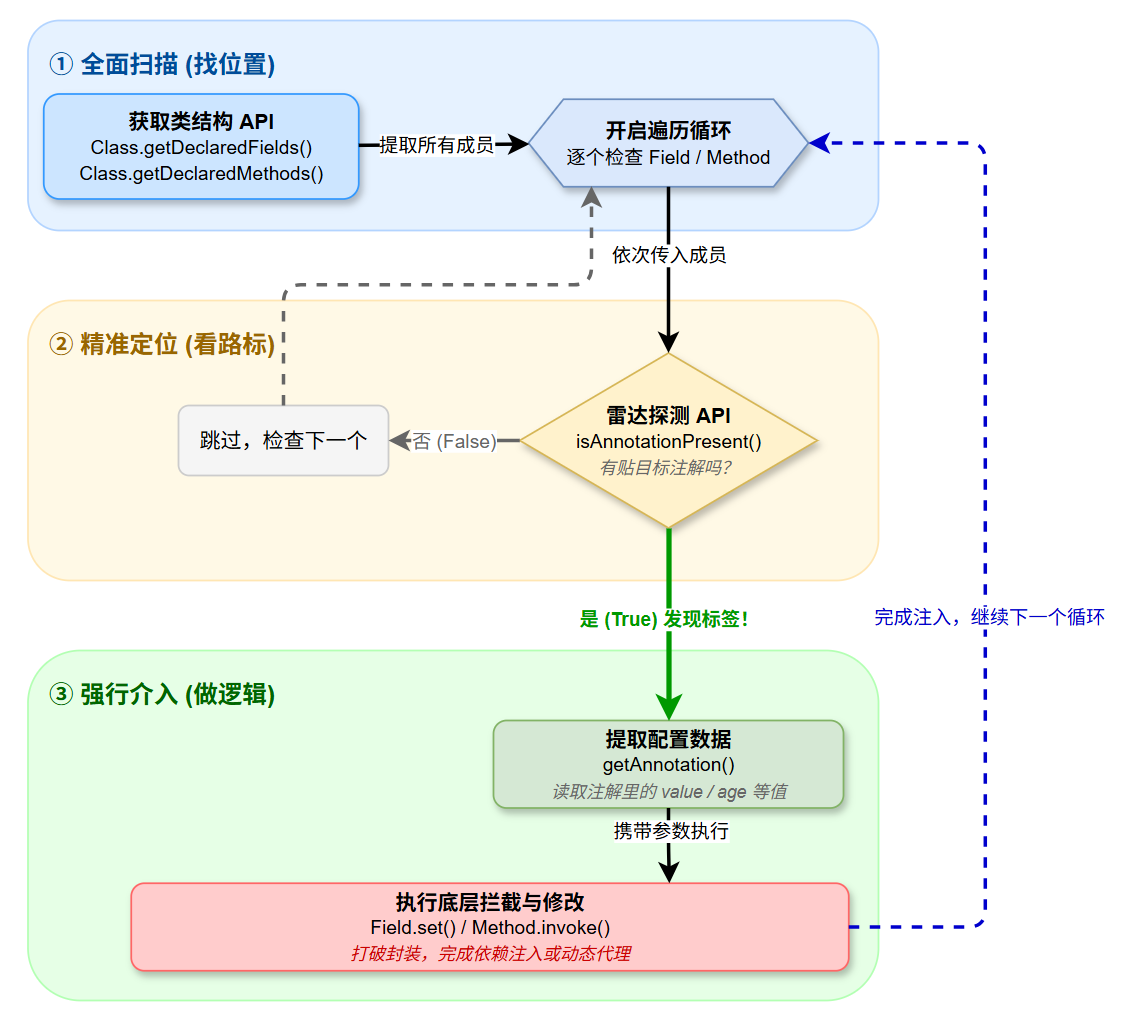
怎么让注解生效?原理其实极其朴素,归纳起来就是"一套 API,三个步骤"。
在程序运行时,框架的底层其实就在无限循环地做下面这三件事:
- 全面扫描(找位置) :利用反射 API 获取目标类的所有结构(
Class.getDeclaredFields()、getDeclaredMethods()等)。 - 精准定位(看路标) :遍历这些结构,调用
isAnnotationPresent(TargetAnnotation.class)方法,像雷达一样探测上面有没有贴特定的注解。 - 强行介入(做逻辑) :一旦探测到注解(返回
true),就利用getAnnotation()把注解里配置的数据(如value)读出来。然后根据业务需求,利用反射 API(如Field.set()或Method.invoke())打破封装,执行特殊的逻辑。
4.2 Spring Boot 中的经典应用:依赖注入
在 Spring 时代之前,我们写代码最大的痛苦就是无休止地 new 对象。而现在,我们在开发 Spring MVC 或 Spring Boot 项目时,极其常用 @Autowired 注解来实现依赖注入(Dependency Injection)。
当我们写下这行极简的代码时:
Java
@Autowired
private UserService userService;表面上看: 我们只是声明了一个私有变量,连对象都没创建,更没有写 setter 方法。
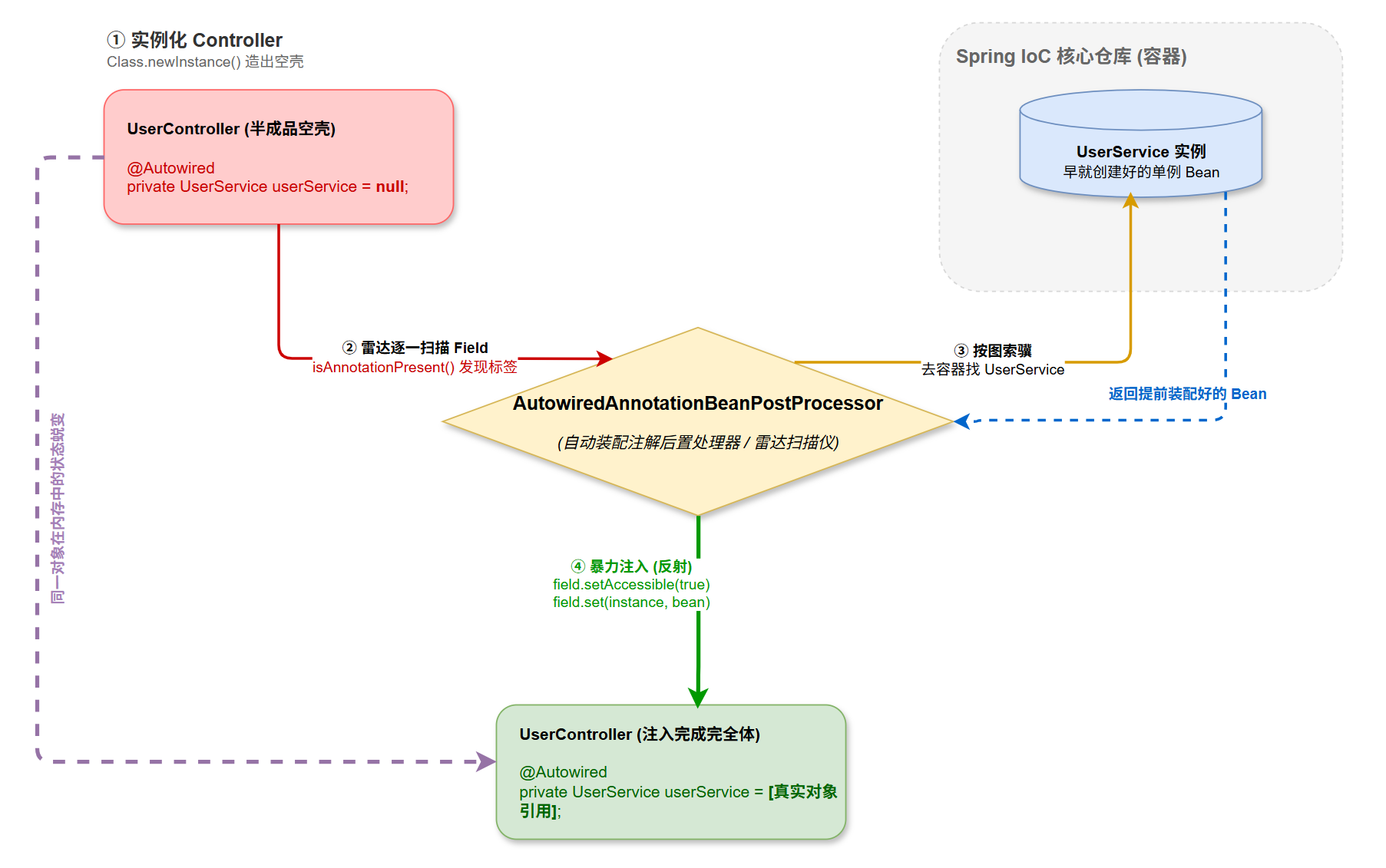
实际上: Spring 容器在后台偷偷把一切都打理好了,简单来说步骤如下:
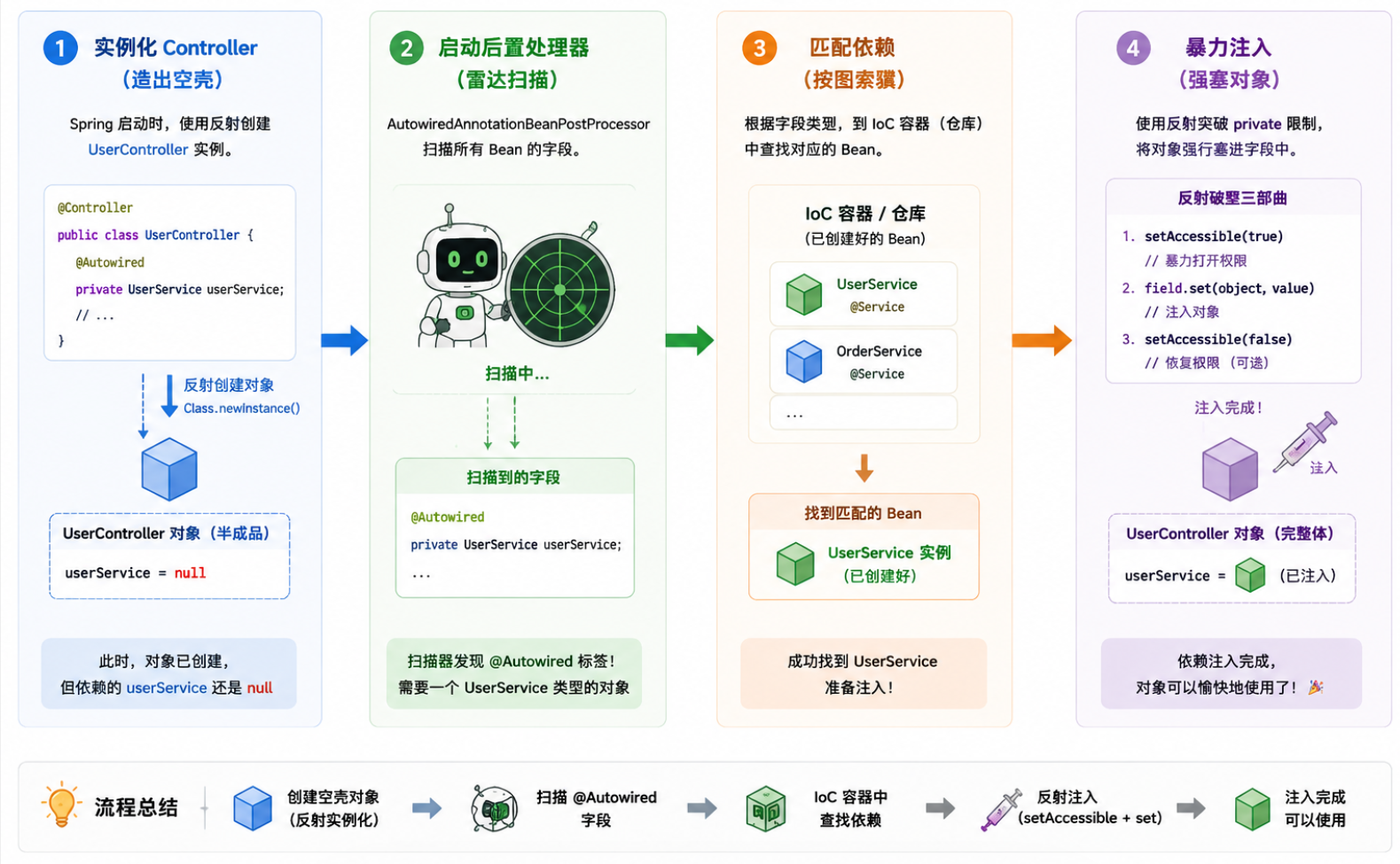
流程如下:
4.3 代码实战
结合我们上面学到的所有知识,写一个最简陋的 DI 容器来展示这一过程:
Java
import java.lang.reflect.Field;
// 1. 定义测试类
class OrderService {
public void pay() { System.out.println("订单支付成功!"); }
}
class OrderController {
@AutoInject // 使用我们刚才自定义的注解
private OrderService orderService;
public void doOrder() {
orderService.pay();
}
}
// 2. 手写迷你容器
public class MiniDiContainer {
public static void main(String[] args) throws Exception {
// 第一步:反射实例化目标对象 (模拟框架启动)
Class<?> controllerClass = OrderController.class;
Object controllerObj = controllerClass.getDeclaredConstructor().newInstance();
// 第二步:依赖注入的核心逻辑
Field[] fields = controllerClass.getDeclaredFields();
for (Field field : fields) {
// 检查字段上是否有 @AutoInject 注解
if (field.isAnnotationPresent(AutoInject.class)) {
// 拿到需要注入的类型 (这里是 OrderService)
Class<?> fieldType = field.getType();
// 实例化依赖的对象
Object dependencyObj = fieldType.getDeclaredConstructor().newInstance();
// 暴力注入!
field.setAccessible(true);
field.set(controllerObj, dependencyObj);
System.out.println("完成自动注入: " + field.getName());
}
}
// 第三步:测试调用
OrderController controller = (OrderController) controllerObj;
controller.doOrder(); // 如果不报错并打印成功,说明注入生效了!
}
}总结
- 反射:让程序在运行时动态探索类的结构,并操作对象,实现软编码与高度可扩展的框架设计。
- 注解:提供元数据标记,告诉框架"做什么",自身不具逻辑,通过反射才能生效。
- 结合应用:现代框架(如 Spring)靠反射读取注解,实现依赖注入、事务控制、路由映射等"开箱即用"的功能。
核心理念:反射是执行引擎,注解是指令标记,两者结合才成就现代 Java 框架的便捷。