引言:为什么企业离不开IP地址段查询?
某互联网公司的安全运营团队在一次例行日志分析中发现,某IP段(103.123.56.0/24)在24小时内对其首页发起了超过50万次请求,峰值QPS高达8000+,明显是自动化爬虫或DDoS攻击。安全团队立即封禁该IP段,成功化解了这次危机。
但就在封禁后的第三天,运营团队发现了一个严重问题:该IP段的"误伤"率高达35%------数百个正常用户因为IP被整体封禁而无法访问网站,导致用户投诉激增。问题的根源在于:安全团队在进行IP段封禁时,没有精确区分该IP段内哪些IP是恶意的,哪些是正常的。
这个案例揭示了一个核心问题:在企业安全运营中,单IP查询远远不够 ,你需要的是IP地址段查询 能力------能够批量分析、识别甚至按需筛选整个IPv4网段的归属地、运营商和网络类型信息。
IP地址段与单IP查询的本质区别
什么是IP地址段?
IP地址段(IP Address Range)是指一段连续的IPv4地址空间,通常以两种形式表示:
1. CIDR表示法(最常用)
103.123.56.0/24其中:
103.123.56.0是起始IP(网络地址)/24表示子网掩码为255.255.255.0,即前24位固定- 该IP段包含256个IP(从103.123.56.0到103.123.56.255)
| CIDR前缀 | 子网掩码 | IP数量 | 典型应用 |
|---|---|---|---|
| /24 | 255.255.255.0 | 256 | 小型网站 |
| /22 | 255.255.252.0 | 1024 | 中型网站 |
| /16 | 255.255.0.0 | 65536 | 大型机构 |
| /8 | 255.0.0.0 | 16777216 | 国家级 |
2. 起止IP表示法
103.123.56.0 - 103.123.56.255这种表示法更直观,但不如CIDR简洁。
IP地址段查询 vs 单IP查询
| 维度 | 单IP查询 | IP地址段查询 |
|---|---|---|
| 查询粒度 | 精确到1个IP | 批量256-65536个IP |
| 返回数据 | 单条归属地 | 网段聚合统计 |
| 适用场景 | 个案分析 | 批量风控、威胁情报 |
| 技术难度 | 简单API调用 | 需要去重、聚合算法 |
| 性能要求 | 毫秒级 | 秒级/批量处理 |
IP地址段查询的核心技术
1. CIDR与整数的相互转换
理解IP段查询的第一步是掌握IP与整数的转换。IPv4地址本质是一个32位二进制数:
203.0.113.45 → 11001011.00000000.01110001.00101101
→ 3402396973 (十进制整数)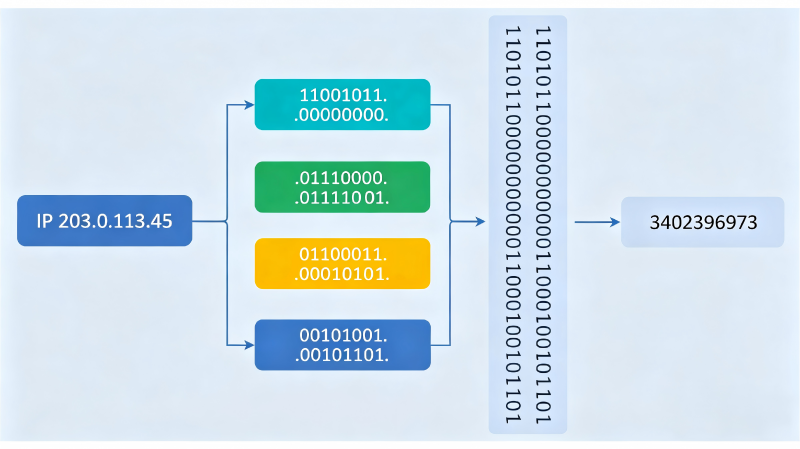
这一转换是高效查询的基础:
import struct
import socket
def ip_to_int(ip: str) -> int:
"""IP地址转32位整数"""
try:
return struct.unpack(">I", socket.inet_aton(ip))[0]
except Exception:
return 0
def int_to_ip(num: int) -> str:
"""整数转IP地址"""
try:
return socket.inet_ntoa(struct.pack(">I", num))
except Exception:
return ""
def cidr_to_range(cidr: str) -> tuple[str, str]:
"""
CIDR表示法转起止IP
例如: 103.123.56.0/24 → (103.123.56.0, 103.123.56.255)
"""
ip, prefix = cidr.split('/')
prefix = int(prefix)
ip_int = ip_to_int(ip)
# 计算掩码:全1前置位
mask = (1 << 32) - (1 << (32 - prefix))
start = ip_int & mask
# 排除网络地址(通常第一个IP是网络地址,不分配)
start = start + 1
end = start + (1 << (32 - prefix)) - 2
# 排除广播地址(通常最后一个IP是广播地址,不分配)
end = min(end, ip_int | (32 - prefix))
return int_to_ip(start), int_to_ip(end)
# 使用示例
if __name__ == "__main__":
start_ip, end_ip = cidr_to_range("103.123.56.0/24")
print(f"IP段范围: {start_ip} - {end_ip}")
# 输出: IP段范围: 103.123.56.1 - 103.123.56.2542. IP地址段的批量归属地查询
当需要查询整个IP段的归属地时,核心思路是采样+聚合:
-
采样:在IP段中均匀抽取若干个IP进行查询(如每16个取1个,共16个样本)
-
聚合:统计样本的归属地分布,判断网段的整体属性
import ipaddress
from collections import Counter
from typing import List, Dict, Tupleclass IPRangeQuery:
"""IP地址段批量查询工具"""def __init__(self, api_key: str = None): self.api_key = api_key def expand_cidr(self, cidr: str, max_ips: int = 256) -> List[str]: """ 展开CIDR为IP列表(限制最大数量) """ try: network = ipaddress.ip_network(cidr, strict=False) ips = list(network.hosts()) # 太小的网段直接返回,太大的网段采样返回 if len(ips) <= max_ips: return [str(ip) for ip in ips] else: # 均匀采样 step = len(ips) // max_ips return [str(ips[i]) for i in range(0, len(ips), step)] except Exception as e: print(f"CIDR解析错误: {e}") return [] def range_to_ips(self, start: str, end: str) -> List[str]: """ 起止IP转IP列表 """ try: start_int = ip_to_int(start) end_int = ip_to_int(end) ips = [] for i in range(start_int, min(end_int + 1, start_int + 256)): ips.append(int_to_ip(i)) return ips except Exception as e: print(f"范围解析错误: {e}") return [] def query_range_summary(self, cidr: str, sample_size: int = 16) -> Dict: """ 查询IP段的聚合归属地信息 Args: cidr: CIDR格式,如 "103.123.56.0/24" sample_size: 采样数量,默认16个 Returns: { "cidr": "103.123.56.0/24", "ip_count": 254, "province": "广东省", "city": "深圳市", "isp": "云厂商", "distribution": {...} } """ # 获取IP列表 ips = self.expand_cidr(cidr, sample_size) # 模拟API查询(实际需要调用IP查询API) results = self._mock_batch_query(ips) # 聚合统计 province_counter = Counter() city_counter = Counter() isp_counter = Counter() for r in results: if r.get("province"): province_counter[r["province"]] += 1 if r.get("city"): city_counter[r["city"]] += 1 if r.get("isp"): isp_counter[r["isp"]] += 1 # 取众数 dominant_province = province_counter.most_common(1)[0][0] if province_counter else "未知" dominant_city = city_counter.most_common(1)[0][0] if city_counter else "未知" dominant_isp = isp_counter.most_common(1)[0][0] if isp_counter else "未知" return { "cidr": cidr, "ip_count": len(list(ipaddress.ip_network(cidr, strict=False).hosts())), "sampled_count": len(ips), "province": dominant_province, "city": dominant_city, "isp": dominant_isp, "province_distribution": dict(province_counter), "city_distribution": dict(city_counter), "isp_distribution": dict(isp_counter) } def _mock_batch_query(self, ips: List[str]) -> List[Dict]: """模拟批量查询(实际请替换为真实API调用)""" # 这里应该调用真实的IP查询API # 示例返回值 results = [] for ip in ips: # 模拟返回数据 results.append({ "ip": ip, "province": "广东省", "city": "深圳市", "isp": "云厂商", "usage_type": "数据中心" }) return results使用示例
if name == "main":
query = IPRangeQuery(api_key="your_key")# 查询单个CIDR result = query.query_range_summary("103.123.56.0/24", sample_size=16) print(f"IP段: {result['cidr']}") print(f"IP总数: {result['ip_count']}") print(f"归属地: {result['province']} {result['city']}") print(f"运营商: {result['isp']}") print(f"省份分布: {result['province_distribution']}")
3. 高效查询:二分查找优化
当本地存储了数十万条IP区间数据时,线性遍历的O(n)复杂度无法满足性能要求。二分查找算法可以将复杂度降至O(log n):
from bisect import bisect_right
from typing import List, Tuple, Optional
class IPLocationDB:
"""
基于二分查找的高效IP归属地查询
数据预处理:
1. 将每个IP区间的起始IP和结束IP转换为32位整数
2. 按起始IP整数值升序排序
3. 使用二分查找定位候选区间
"""
def __init__(self):
# 存储格式: [(start_int, end_int, province, city, isp), ...]
self.ranges: List[Tuple[int, int, str, str, str]] = []
self.starts: List[int] = [] # 仅存储起始IP,用于二分查找
def add_range(self, start_ip: str, end_ip: str,
province: str, city: str, isp: str):
"""添加IP区间数据"""
start_int = ip_to_int(start_ip)
end_int = ip_to_int(end_ip)
self.ranges.append((start_int, end_int, province, city, isp))
def build_index(self):
"""构建索引(排序)"""
self.ranges.sort(key=lambda x: x[0]) # 按起始IP排序
self.starts = [r[0] for r in self.ranges]
def query(self, ip: str) -> Optional[Dict]:
"""
O(log n)复杂度的IP归属地查询
算法:
1. 将目标IP转为整数
2. 在starts数组中用bisect_right找第一个 > target 的位置
3. 前一个位置即为候选区间的索引
4. 验证target是否在候选区间内
"""
target = ip_to_int(ip)
n = len(self.ranges)
if n == 0:
return None
# 二分查找:找最后一个起始IP <= target的区间
pos = bisect_right(self.starts, target) - 1
if pos < 0:
return None
start, end, province, city, isp = self.ranges[pos]
# 验证是否在区间内
if start <= target <= end:
return {
"ip": ip,
"province": province,
"city": city,
"isp": isp,
"start_ip": int_to_ip(start),
"end_ip": int_to_ip(end)
}
return None
def batch_query(self, ips: List[str]) -> List[Optional[Dict]]:
"""批量查询"""
return [self.query(ip) for ip in ips]
# 使用示例
if __name__ == "__main__":
db = IPLocationDB()
# 添加示例数据(实际应从数据库加载)
db.add_range("1.0.1.0", "1.0.1.255", "福建省", "福州市", "电信")
db.add_range("1.0.2.0", "1.0.2.255", "广东省", "广州市", "联通")
db.add_range("1.0.8.0", "1.0.15.255", "上海市", "上海市", "电信")
db.add_range("36.152.0.0", "36.159.255.255", "广东省", "深圳市", "移动")
db.add_range("42.176.0.0", "42.191.255.255", "北京市", "北京市", "联通")
db.build_index()
# 查询单个IP
result = db.query("1.0.2.100")
if result:
print(f"IP: {result['ip']}")
print(f"归属地: {result['province']} {result['city']}")
print(f"运营商: {result['isp']}")
# 批量查询
results = db.batch_query(["1.0.1.100", "1.0.2.100", "36.152.100.100"])
for r in results:
if r:
print(f"{r['ip']} → {r['province']}{r['city']} {r['isp']}")
主流IP地址段查询工具与服务
| 工具 | 网址 | 特点 | 批量支持 |
|---|---|---|---|
| IP数据云 | ipdatacloud.com | 高精度,支持批量 | 批量API |
| 站长工具IP查询 | ip.chinaz.com | 免费,批量查询 | 批量Web |
| IP138 | ip138.com | 免费,ASN信息 | 单个 |
| 一起查 | 17cha.cn | 免费,简单 | 单个 |
方法二:Python脚本(技术推荐)
import pandas as pd
import requests
from concurrent.futures import ThreadPoolExecutor, as_completed
def query_ip_batch(ip_list: list, api_key: str) -> pd.DataFrame:
"""批量IP查询,返回DataFrame"""
results = []
def query_single(ip):
try:
resp = requests.get(
f"https://api.ipdatacloud.com/v2/query?ip={ip}&key={api_key}",
timeout=3
)
data = resp.json()
if data.get("code") == 200:
d = data.get("data", {})
return {
"ip": ip,
"province": d.get("province", ""),
"city": d.get("city", ""),
"isp": d.get("isp", ""),
"usage_type": d.get("usage_type", "")
}
except:
pass
return {"ip": ip, "province": "", "city": "", "isp": "", "usage_type": ""}
# 并发查询(控制并发数)
with ThreadPoolExecutor(max_workers=10) as executor:
futures = {executor.submit(query_single, ip): ip for ip in ip_list}
for future in as_completed(futures):
results.append(future.result())
return pd.DataFrame(results)
# 使用示例
if __name__ == "__main__":
ips = [
"1.0.1.1", "1.0.2.2", "36.152.1.1",
"42.176.1.1", "103.56.1.1"
]
df = query_ip_batch(ips, api_key="your_key")
print(df)IP地址段查询的典型应用场景
场景一:安全运营与威胁溯源
案例:DDoS攻击防御
当遭遇DDoS攻击时,安全团队需要快速判断攻击IP的归属:
def analyze_attack_source(ip_list: list) -> dict:
"""
分析攻击来源聚合统计
Returns:
{
"total_ips": 数量,
"unique_provinces": [...],
"top_provinces": [...],
"unique_isps": [...],
"suspicious_ips": [...] # 来自数据中心/代理的IP
}
"""
db = IPLocationDB() # 假设已加载数据
province_counter = Counter()
isp_counter = Counter()
suspicious = []
for ip in ip_list:
result = db.query(ip)
if result:
province_counter[result["province"]] += 1
isp_counter[result["isp"]] += 1
# 数据中心IP通��是攻击源
if result.get("usage_type") == "数据中心":
suspicious.append(ip)
return {
"total_ips": len(ip_list),
"unique_provinces": list(province_counter.keys()),
"top_provinces": province_counter.most_common(5),
"unique_isps": list(isp_counter.keys()),
"suspicious_count": len(suspicious),
"suspicious_ips": suspicious[:10] # 只返回前10个
}场景二:CDN节点选择与优化
通过分析IP段归属地,选择最优的CDN节点:
def select_best_cdn_node(user_ips: list, cdn_nodes: dict) -> str:
"""
根据用户IP归属地选择最近CDN节点
Args:
user_ips: 用户IP地址列表
cdn_nodes: CDN节点字典 {"节点名": "IP段"}
Returns:
最优CDN节点名
"""
user_locations = []
db = IPLocationDB()
for ip in user_ips[:100]: # 采样前100个
result = db.query(ip)
if result:
user_locations.append(result["province"])
# 找众数
if not user_locations:
return "默认节点"
dominant_province = Counter(user_locations).most_common(1)[0][0]
# 匹配最近的CDN节点(简化逻辑)
cdn_province_map = {
"阿里云cdn": ["广东省", "北京市", "上海市"],
"腾讯云cdn": ["广东省", "上海市", "北京市"],
"网宿cdn": ["上海市", "广东省", "北京市"]
}
for cdn, provinces in cdn_province_map.items():
if dominant_province in provinces:
return cdn
return "默认节点"场景三:广告投放反欺诈
识别批量虚假流量:

IP地址段查询的常见问题
Q1:为什么同一个IP段内,不同IP的归属地不同?
这是正常现象。一个/24网段(256个IP)通常由ISP分配给一个城市或区域,但随着用户增加,ISP会将部分IP分配到邻近区域。查询时建议采样多个IP取众数,而不是简单地使用第一个IP的归属地。
Q2:IP段查询需要多长时间?
- 单次查询(采样16个IP):约0.5-2秒
- 批量查询(100个IP段):约10-30秒(取决于API限速)
- 本地数据库查询(10万条区间):毫秒级(使用二分查找)
总结
- 批量处理:需要高效的数据结构和算法(如二分查找将O(n)降至O(log n))
- 采样聚合:取众数判断网段整体属性,而非依赖单个IP的结果
- 场景适配:不同场景需要不同的查询策略(安全运营需要高精度,CDN优化需要低延迟)
掌握IP段查询技术,不仅是"能查到",更是"查得准、查得快、用得活"------将IP段信息转化为实际业务决策的支持能力,才是企业真正的核心竞争力。