论文信息
- 标题:Hierarchical Text-Conditional Image Generation with CLIP Latents
- 会议:arXiv 2022
- 单位:OpenAI
- 代码:未开源
- 论文:https://arxiv.org/pdf/2204.06125
一、开篇:为什么unCLIP能成为文生图的里程碑?
在unCLIP诞生前,文生图领域一直困在一个死胡同里:以GLIDE为代表的扩散模型,能生成高度逼真的图像,但引导强度一拉高,生成多样性就直接崩盘;以DALL-E为代表的自回归模型,多样性尚可,但逼真度和文本对齐度又差强人意。
而此时CLIP模型已经证明,它能把文本和图像映射到同一个联合隐空间,学到的特征既能精准捕捉语义,又能完美复刻风格,简直是文生图的"天选向导"。OpenAI团队就此提出了一个颠覆性思路:不一步到位从文本生成图像,而是把任务拆成两步走------先从文本生成CLIP图像嵌入,再从CLIP图像嵌入还原出图像。
这个两阶段框架就是unCLIP,也是后续大名鼎鼎的DALL·E 2的核心技术底座。它不仅在几乎不损失逼真度的前提下,把生成多样性拉到了新高度,还解锁了零样本图像变体、插值、文本引导编辑等一系列黑科技,彻底改写了文生图的技术范式。
二、unCLIP核心框架:两阶段生成的数学本质
unCLIP的核心逻辑,是把文生图的条件概率分布做了链式拆解,把一个高难度的端到端任务,拆成了两个可解耦的子任务。
核心概率公式
P(x∣y)=P(x,zi∣y)=P(x∣zi,y)P(zi∣y)P(x|y) = P(x,z_i|y) = P(x|z_i,y)P(z_i|y)P(x∣y)=P(x,zi∣y)=P(x∣zi,y)P(zi∣y)
公式中每个符号的含义与通俗解释:
- xxx:最终生成的高清图像(通俗理解:我们想要AI输出的最终画作)
- yyy:输入的文本提示词(Prompt,通俗理解:我们给AI的绘画指令)
- ziz_izi:图像对应的CLIP图像嵌入(Image Embedding,通俗理解:CLIP模型给图像生成的"灵魂向量",把一张图压缩成固定长度的向量,里面封装了图像的语义、风格、主体等核心信息)
- P(zi∣y)P(z_i|y)P(zi∣y):先验模型(Prior),输入文本yyy,输出符合文本描述的CLIP图像嵌入ziz_izi(通俗理解:先根据文字指令,生成对应画作的"灵魂蓝图")
- P(x∣zi,y)P(x|z_i,y)P(x∣zi,y):解码器模型(Decoder),输入CLIP图像嵌入ziz_izi(可选搭配文本yyy),输出最终图像xxx(通俗理解:根据"灵魂蓝图",把画作完整还原出来)
公式的底层逻辑:因为ziz_izi是xxx的确定性函数(一张图像对应唯一的CLIP图像嵌入),所以文生图的条件分布可以完美拆分为先验+解码器两个独立步骤。推理时,我们先通过先验采样得到ziz_izi,再通过解码器采样得到最终图像xxx,大幅降低了任务的学习难度。
整体架构可视化
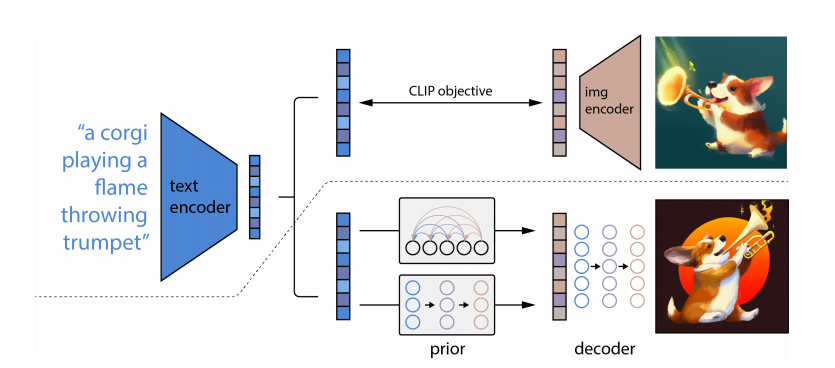
图1 unCLIP整体架构(出处:原论文图2)
架构分析:
- 上半部分是CLIP的预训练流程,通过图文对比学习,得到文本和图像的联合隐空间,这部分在unCLIP训练全程是完全冻结的,无需重新训练。
- 下半部分是unCLIP的文生图全流程:文本先通过CLIP文本编码器得到文本嵌入,输入先验模型生成匹配的CLIP图像嵌入,再通过扩散解码器生成基础分辨率图像,最后经过两级上采样器得到1024×1024高清图像。
三、第一核心模块:Decoder解码器------把CLIP嵌入还原成图像
解码器的核心任务,是做CLIP图像编码器的逆过程 :给定一个CLIP图像嵌入ziz_izi,还原出对应的高清图像xxx。更关键的是,这个逆过程是非确定性的------同一个ziz_izi可以生成多张语义、风格完全一致,仅非核心细节不同的图像。
1. 模型架构选型与改造
unCLIP直接基于GLIDE扩散模型做解码器,针对CLIP嵌入做了两处核心改造:
- 将CLIP图像嵌入做线性投影后,叠加到扩散模型的时间步嵌入中,让模型在去噪的每一步,都能感知到目标图像的核心语义信息。
- 将CLIP图像嵌入投影为4个额外的上下文Token,拼接在GLIDE原生文本编码器的输出序列后,进一步强化文本-图像的对齐能力。
同时保留了GLIDE原生的文本条件通路,原本是为了学习CLIP没捕捉到的语言细节(比如属性绑定),但论文实验证明这部分几乎没有增益。
2. 训练核心:无分类器引导
为了提升生成质量,同时兼顾多样性,unCLIP解码器采用了无分类器引导(Classifier-free Guidance)策略:
- 训练时,10%的概率将CLIP图像嵌入置零,50%的概率丢弃输入文本,让模型学会在条件缺失的情况下也能完成去噪。
- 通俗解释:就像老师训练学生,偶尔会把关键知识点隐藏起来,倒逼模型掌握核心的生成逻辑。这样推理时,给模型完整的条件信息,生成效果会大幅提升,还能通过引导尺度灵活控制生成的保真度。
3. 高清生成:两级扩散上采样器
为了实现1024×1024高清图像生成,unCLIP设计了两级级联的扩散上采样器,避免直接在高分辨率像素空间做扩散带来的巨额算力开销:
- 第一级:64×64 → 256×256,训练时对条件图像施加高斯模糊退化,提升模型鲁棒性。
- 第二级:256×256 → 1024×1024,训练时采用更丰富的BSR退化策略,适配真实场景的图像降质。
两个上采样器均采用无注意力的ADMNet架构,不依赖文本条件,训练时用目标尺寸1/4的随机裁剪,推理时可直接泛化到目标分辨率,效率极高。

图2 unCLIP生成的1024×1024高清样例(出处:原论文图1)
效果分析:通过两级上采样,unCLIP生成的1024×1024图像细节拉满,无论是写实肖像、科幻创意还是静物插画,都能实现高度逼真的渲染,同时完美匹配文本提示词的语义要求。
四、第二核心模块:Prior先验模型------文本到CLIP嵌入的桥梁
先验模型是unCLIP的灵魂,它的任务是:给定文本提示词yyy,生成和文本高度匹配的CLIP图像嵌入ziz_izi。如果说解码器是"画师",那先验就是"策划",直接决定了生成内容的方向和文本对齐度。
论文中对比了两种先验方案:自回归(AR)先验和扩散先验,最终实验证明扩散先验在效果和计算效率上全面胜出。
1. 自回归(AR)先验
自回归先验的核心思路,是把连续的CLIP嵌入转化为离散序列,用Transformer做自回归预测,核心步骤:
- PCA降维:对原始1024维的CLIP图像嵌入做主成分分析,仅保留前319个主成分,就能保留99%以上的信息(重构MSE<1%),大幅降低序列长度。
- 离散量化:将319个主成分按特征值从大到小排序,每个维度量化为1024个离散桶,转化为离散Token序列。
- 条件注入 :将文本Caption、CLIP文本嵌入编码为序列前缀,额外增加一个Token表示文本嵌入与图像嵌入的点积zi⋅ztz_i·z_tzi⋅zt(点积越高,图文匹配度越好),训练时采样分布前50%的点积,提升文本对齐度。
- 模型训练:用带因果注意力掩码的Transformer,自回归预测离散化的嵌入序列。
2. 扩散先验(论文首选方案)
扩散先验直接对连续的CLIP嵌入向量建模,无需离散化,避免了量化带来的信息损失,同时训练和推理效率更高。
核心架构
采用带因果注意力掩码的Decoder-only Transformer,输入序列按固定顺序排列:
编码后的文本 → CLIP文本嵌入 → 扩散时间步嵌入 → 加噪的CLIP图像嵌入 → 最终输出嵌入
Transformer的最终输出,直接用于预测无噪的原始CLIP图像嵌入ziz_izi。
训练损失函数
Lprior=Et∼1,T,zi(t)∼qt∥fθ(zi(t),t,y)−zi∥2L_{prior }=\mathbb{E}{t \sim1, T, z{i}^{(t)} \sim q_{t}}\left\\left\\\| f_{\\theta}\\left(z_{i}\^{(t)}, t, y\\right)-z_{i}\\right\\\| \^{2}\\rightLprior=Et∼1,T,zi(t)∼qt fθ(zi(t),t,y)−zi 2
公式中每个符号的含义与通俗解释:
- LpriorL_{prior}Lprior:先验模型的训练损失,采用均方误差(MSE)
- E\mathbb{E}E:数学期望,通俗理解为对所有随机变量的取值取平均值
- ttt:扩散时间步,取值范围为1到T(默认T=1000),表示当前加噪的步数
- zi(t)z_i^{(t)}zi(t):第t步加噪后的CLIP图像嵌入,即给干净的ziz_izi逐步添加高斯噪声后的结果
- qtq_tqt:前向加噪过程的概率分布
- fθf_\thetafθ:待训练的先验网络,可学习参数为θ\thetaθ
- yyy:输入的文本条件(提示词)
- ziz_izi:原始干净的CLIP图像嵌入,即网络的预测目标
和原生DDPM预测噪声不同,unCLIP的扩散先验直接预测干净的ziz_izi,论文实验证明这种方式在嵌入生成任务上效果更优。
推理优化
推理时,会生成2个ziz_izi样本,选择和文本嵌入ztz_tzt点积更高的那个,无需像AR先验那样额外添加条件,就能进一步提升图文匹配度。
3. PCA维度可视化分析

图3 不同PCA维度下的CLIP嵌入重建效果(出处:原论文图7)
分析:从图中可以清晰看到,低维度的PCA分量保留了粗粒度的语义信息(比如场景中物体的类别),而高维度的分量编码了细粒度的细节(物体的具体形状、纹理、位置)。这也是AR先验能做PCA降维的核心依据------前319维就几乎保留了CLIP嵌入的全部有效信息。
五、unCLIP的三大黑科技:零样本图像操控
unCLIP最大的魅力之一,是基于CLIP的联合隐空间,解锁了三大零样本图像操控能力,完全无需重新训练或微调模型,就能实现丰富的图像编辑效果。
unCLIP将任意一张输入图像,编码为二元隐表示(zi,xT)(z_i, x_T)(zi,xT):
- ziz_izi:由CLIP图像编码器生成,描述图像中CLIP可识别的核心语义与风格信息
- xTx_TxT:通过DDIM反演得到的潜变量,编码了还原原始图像所需的全部剩余细节信息
1. 图像变体(Variations)
核心原理 :给定输入图像的二元隐表示(zi,xT)(z_i, x_T)(zi,xT),用DDIM采样时设置η>0\eta>0η>0,即可生成和原图核心语义、风格完全一致,仅非核心细节不同的变体。
- η=0\eta=0η=0时,解码器是确定性的,会完美重建原始图像
- η\etaη越大,采样的随机性越强,生成图像的细节变化越大

图4 图像变体生成效果(出处:原论文图3)
效果分析:生成的变体完美保留了原图的核心语义(画作中的时钟、logo的笔画结构)和风格(超现实主义画风、渐变色彩),仅变化了非必要的细节,证明CLIP嵌入能精准锁定图像的核心信息,过滤掉无关的细节噪声。
2. 图像插值(Interpolations)
核心原理 :对两张输入图像的CLIP图像嵌入做球面插值(Slerp),公式如下:
ziθ=slerp(zi1,zi2,θ),θ∈0,1z_{i_{\theta}}=slerp(z_{i_{1}}, z_{i_{2}}, \theta), \theta\in0,1ziθ=slerp(zi1,zi2,θ),θ∈0,1
其中θ\thetaθ为插值系数,从0到1变化时,嵌入会从第一张图平滑过渡到第二张图,解码后即可得到两张图的自然渐变效果。

图5 双图插值效果(出处:原论文图4)
效果分析:固定解码器的随机种子后,插值过程中两张图的内容和风格实现了丝滑过渡,没有出现语义断层,证明CLIP隐空间是高度线性的,不同图像的语义可以平滑融合。
3. 文本差分编辑(Text Diffs)
这是unCLIP最惊艳的能力,基于CLIP图文同空间的特性,实现零样本的文本引导图像编辑,无需任何微调。
核心步骤:
- 得到原始图像的CLIP图像嵌入ziz_izi,原始图像描述的文本嵌入zt0z_{t0}zt0,目标描述的文本嵌入ztz_tzt
- 计算归一化的文本差分向量:zd=norm(zt−zt0)z_d = norm(z_t - z_{t0})zd=norm(zt−zt0)
- 对原始图像嵌入和差分向量做球面插值,得到编辑后的嵌入:zθ=slerp(zi,zi+αzd,θ)z_\theta=slerp(z_i, z_i+\alpha z_d, \theta)zθ=slerp(zi,zi+αzd,θ)
- 解码zθz_\thetazθ,得到编辑后的图像,其中α\alphaα和θ\thetaθ控制编辑强度

图6 文本差分零样本图像编辑效果(出处:原论文图5)
效果分析:零样本就能实现"写实猫→超级赛亚猫""冬季风景→秋季风景""成年狮子→幼狮"等精准的语义编辑,完全无需重新训练模型。这就是CLIP联合隐空间的核心优势------文本和图像的语义完全对齐,用文本就能直接操控图像的语义属性。
六、CLIP隐空间深度探究:嵌入里藏着比分类结果更多的信息
unCLIP的解码器,给我们提供了一个可视化CLIP隐空间的窗口,能直接看到CLIP图像编码器到底"看到了什么"。
论文中做了一个经典的对抗攻击实验:给苹果的图像上叠加"iPod"的文字,CLIP分类器会把这张图以99.98%的概率分类为iPod,几乎完全忽略了苹果本身。

图7 CLIP对抗攻击样本的解码效果(出处:原论文图6)
实验结论:即便CLIP分类器把图像判定为iPod,unCLIP的解码器依然能完美还原出苹果,而不是iPod。这证明:
- CLIP的图像嵌入中,依然完整保留了原始图像的核心视觉信息,分类器的输出只是对嵌入的一个极简解读。
- 解码器能挖掘出CLIP分类器没有用到的视觉细节,CLIP嵌入的信息丰富度,远超过最终的分类概率。
七、实验结果与核心结论
论文通过多组严谨的实验,全面验证了unCLIP的性能优势,核心实验如下。
1. 先验的必要性验证
论文对比了三种不同的条件输入方式,验证先验模型的核心作用:
- 仅给解码器输入文本,CLIP嵌入置零
- 给解码器输入文本+CLIP文本嵌入(零样本)
- 给解码器输入文本+先验生成的CLIP图像嵌入
实验结果显示,三种方式的FID分别为9.16、16.55、7.99,完整的unCLIP栈(先验+解码器)取得了最低的FID,人类评估中,57.0%的概率更偏好其逼真度,53.1%的概率更偏好其文本相似度,直观证明了先验模型是unCLIP性能的核心保障。

图8 不同条件信号的解码器生成效果对比(出处:原论文图8)
效果分析:第一行仅输入文本,生成效果最差,细节模糊、语义偏差大;第二行输入文本+CLIP文本嵌入,效果有提升但仍有明显缺陷;第三行输入文本+先验生成的CLIP图像嵌入,生成效果最好,细节最丰富,和文本的匹配度最高。
2. 人类评估:逼真度与多样性的双赢
论文针对unCLIP和同期SOTA模型GLIDE,做了大规模人类评估,从逼真度、文本相似度、多样性三个维度做了对比。
表1 unCLIP与GLIDE的人类评估结果(出处:原论文表1)
| unCLIP Prior | Photorealism(逼真度) | Caption Similarity(文本相似度) | Diversity(多样性) |
|---|---|---|---|
| AR | 47.1% ± 3.1% | 41.1% ± 3.0% | 62.6% ± 3.0% |
| Diffusion | 48.9% ± 3.1% | 45.3% ± 3.0% | 70.5% ± 2.8% |
表格分析:
- 表中数值为人类认为unCLIP优于GLIDE的概率,数值越高,优势越明显。
- 逼真度上,GLIDE仅以微弱优势领先,扩散先验版unCLIP的48.9%几乎和GLIDE五五开,逼真度差距可以忽略不计。
- 多样性上,unCLIP实现了碾压式领先,扩散先验版有70.5%的概率被人类认为更具多样性,完美实现了"几乎不损失逼真度,大幅提升多样性"的设计目标。
3. 引导强度的鲁棒性:解决多样性崩塌痛点
传统扩散模型有一个致命缺陷:引导强度越高,生成质量越好,但多样性会快速崩塌。而unCLIP完美解决了这个问题。

图9 不同引导强度下unCLIP与GLIDE的生成效果对比(出处:原论文图9)
效果分析:
- 随着引导强度提升,GLIDE的生成内容快速收敛,相机角度、色彩、物体大小都变得高度单一,多样性完全丢失。
- 而unCLIP的核心语义信息已经被固定在CLIP图像嵌入中,引导强度提升只会优化光影、阴影等细节质量,不会改变核心语义,完美保留了生成多样性。
4. MS-COCO零样本基准测试
在文生图领域的标准基准MS-COCO上,unCLIP取得了零样本SOTA的成绩,证明了其极强的泛化能力。
表2 MS-COCO 256×256零样本FID对比(出处:原论文表2)
| Model | Zero-shot FID | Zero-shot FID (filt) |
|---|---|---|
| DALL-E | ∼ 28 | - |
| LAFITE | 26.94 | - |
| GLIDE | 12.24 | 12.89 |
| Make-A-Scene | - | 11.84 |
| unCLIP (AR prior) | 10.63 | 11.08 |
| unCLIP (Diffusion prior) | 10.39 | 10.87 |
表格分析:FID数值越低,代表生成图像的分布和真实图像越接近,效果越好。unCLIP扩散先验版,在完全没有在MS-COCO上训练的零样本场景下,取得了10.39的FID,远超同期的DALL-E、GLIDE等模型,刷新了零样本文生图的SOTA纪录。
5. 美学质量评估
论文用GPT-3生成了512个艺术化提示词,基于AVA数据集训练的CLIP线性探针,评估了模型的美学生成能力。
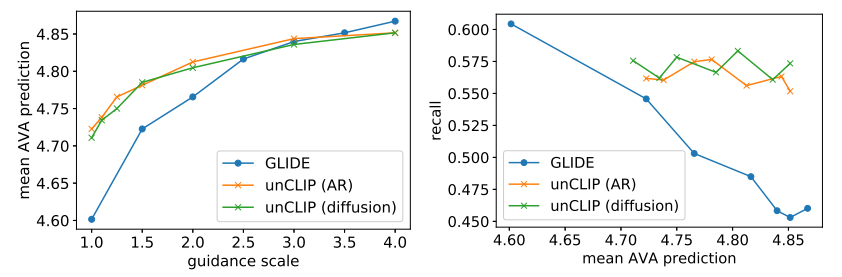
图10 美学质量与Recall的对比(出处:原论文图13)
效果分析:随着引导强度提升,GLIDE的美学得分上升,但代表多样性的Recall指标快速下降,本质是牺牲多样性换取美学效果;而unCLIP的美学得分稳步上升的同时,Recall几乎没有下降,真正实现了逼真度、美学质量、多样性三者的平衡。
八、核心代码实现
以下是unCLIP核心模块的PyTorch实现,贴合论文的原生设计,包含扩散先验、解码器条件注入、文本差分编辑三大核心逻辑。
1. 扩散先验核心实现
python
import torch
import torch.nn as nn
import math
from transformers import CLIPTextModel, CLIPTokenizer
# 时间步嵌入
def get_timestep_embedding(timesteps, dim: int):
half_dim = dim // 2
emb = math.log(10000) / (half_dim - 1)
emb = torch.exp(torch.arange(half_dim, device=timesteps.device) * -emb)
emb = timesteps[:, None] * emb[None, :]
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=-1)
return emb
# 扩散先验模型
class DiffusionPrior(nn.Module):
def __init__(
self,
clip_embed_dim=1024,
text_embed_dim=1024,
time_embed_dim=512,
transformer_dim=2048,
num_layers=24,
num_heads=32
):
super().__init__()
self.clip_embed_dim = clip_embed_dim
# 时间步嵌入层
self.time_mlp = nn.Sequential(
nn.Linear(time_embed_dim, transformer_dim),
nn.SiLU(),
nn.Linear(transformer_dim, transformer_dim)
)
# 文本嵌入投影
self.text_proj = nn.Linear(text_embed_dim, transformer_dim)
# 带噪CLIP嵌入投影
self.noisy_embed_proj = nn.Linear(clip_embed_dim, transformer_dim)
# 输出投影
self.out_proj = nn.Linear(transformer_dim, clip_embed_dim)
# Decoder-only Transformer
transformer_layer = nn.TransformerDecoderLayer(
d_model=transformer_dim,
nhead=num_heads,
dim_feedforward=transformer_dim * 4,
batch_first=True,
activation="gelu"
)
self.transformer = nn.TransformerDecoder(transformer_layer, num_layers=num_layers)
# 因果注意力掩码
self.register_buffer("causal_mask", nn.Transformer.generate_square_subsequent_mask(4))
def forward(self, noisy_clip_embed, timesteps, text_embed):
"""
前向传播
:param noisy_clip_embed: 加噪的CLIP图像嵌入 [batch_size, 1024]
:param timesteps: 扩散时间步 [batch_size]
:param text_embed: CLIP文本嵌入 [batch_size, 1024]
:return: 预测的干净CLIP图像嵌入 [batch_size, 1024]
"""
batch_size = noisy_clip_embed.shape[0]
# 各特征投影
time_emb = get_timestep_embedding(timesteps, 512)
time_emb = self.time_mlp(time_emb).unsqueeze(1) # [B, 1, D]
text_emb = self.text_proj(text_embed).unsqueeze(1) # [B, 1, D]
noisy_emb = self.noisy_embed_proj(noisy_clip_embed).unsqueeze(1) # [B, 1, D]
# 拼接序列:文本嵌入 → 时间步嵌入 → 带噪嵌入
seq = torch.cat([text_emb, time_emb, noisy_emb], dim=1) # [B, 3, D]
# Transformer推理
out = self.transformer(seq, memory=seq, tgt_mask=self.causal_mask[:3, :3])
# 输出干净嵌入
clean_embed = self.out_proj(out[:, -1, :])
return clean_embed
# 先验损失函数
def prior_loss_fn(model, clean_clip_embed, text_embed, timesteps, noise_scheduler):
"""
计算先验模型的MSE损失
"""
# 生成随机噪声
noise = torch.randn_like(clean_clip_embed)
# 前向加噪
noisy_embed = noise_scheduler.add_noise(clean_clip_embed, noise, timesteps)
# 预测干净嵌入
pred_embed = model(noisy_embed, timesteps, text_embed)
# 计算MSE损失
loss = nn.functional.mse_loss(pred_embed, clean_clip_embed)
return loss2. 解码器CLIP条件注入实现
python
class UNetDecoder(nn.Module):
def __init__(self, in_channels=3, clip_embed_dim=1024, time_embed_dim=512):
super().__init__()
# 时间步嵌入
self.time_mlp = nn.Sequential(
nn.Linear(time_embed_dim, time_embed_dim * 4),
nn.SiLU(),
nn.Linear(time_embed_dim * 4, time_embed_dim)
)
# CLIP嵌入投影
self.clip_proj = nn.Sequential(
nn.Linear(clip_embed_dim, clip_embed_dim * 4),
nn.SiLU(),
nn.Linear(clip_embed_dim * 4, time_embed_dim)
)
# 简化的UNet实现(完整实现参考GLIDE)
self.init_conv = nn.Conv2d(in_channels, 64, kernel_size=3, padding=1)
# 此处省略UNet的编码器-解码器主体,核心是条件融合
self.final_conv = nn.Conv2d(64, in_channels, kernel_size=3, padding=1)
def forward(self, x_t, timesteps, clip_embed):
"""
解码器前向传播,注入CLIP嵌入条件
:param x_t: 带噪图像 [B, 3, H, W]
:param timesteps: 扩散时间步 [B]
:param clip_embed: CLIP图像嵌入 [B, 1024]
:return: 预测的噪声
"""
# 时间步嵌入
time_emb = get_timestep_embedding(timesteps, 512)
time_emb = self.time_mlp(time_emb)
# CLIP嵌入投影
clip_emb = self.clip_proj(clip_embed)
# 条件融合:CLIP嵌入 + 时间步嵌入
cond_emb = time_emb + clip_emb
# UNet前向传播(此处简化,完整实现需将cond_emb注入每个残差块)
x = self.init_conv(x_t)
# 此处省略UNet的编码器-解码器流程
out = self.final_conv(x)
return out3. 文本差分编辑核心代码
python
def text_diff_edit(
image,
original_caption,
target_caption,
clip_model,
clip_processor,
decoder,
ddim_sampler,
edit_strength=0.3
):
"""
文本差分零样本图像编辑
:param image: 原始输入图像
:param original_caption: 原始图像的描述文本
:param target_caption: 目标编辑的描述文本
:param clip_model: 预训练CLIP模型
:param clip_processor: CLIP图像/文本处理器
:param decoder: unCLIP解码器
:param ddim_sampler: DDIM采样器
:param edit_strength: 编辑强度
:return: 编辑后的图像
"""
# 1. 提取原始图像的CLIP嵌入
image_input = clip_processor(images=image, return_tensors="pt").pixel_value
with torch.no_grad():
z_i = clip_model.get_image_features(image_input)
z_i = z_i / z_i.norm(dim=-1, keepdim=True)
# 2. 计算文本差分向量
tokenizer = clip_processor.tokenizer
orig_text_input = tokenizer(original_caption, return_tensors="pt")
target_text_input = tokenizer(target_caption, return_tensors="pt")
with torch.no_grad():
z_t0 = clip_model.get_text_features(**orig_text_input)
z_t = clip_model.get_text_features(**target_text_input)
z_t0 = z_t0 / z_t0.norm(dim=-1, keepdim=True)
z_t = z_t / z_t.norm(dim=-1, keepdim=True)
# 3. 计算归一化的文本差分
z_d = z_t - z_t0
z_d = z_d / z_d.norm(dim=-1, keepdim=True)
# 4. 球面插值,得到编辑后的嵌入
theta = edit_strength
z_edit = (1 - theta) * z_i + theta * (z_i + z_d)
z_edit = z_edit / z_edit.norm(dim=-1, keepdim=True)
# 5. DDIM反演得到原始图像的x_T,固定噪声保证编辑前后结构一致
x_T = ddim_sampler.invert(image, z_i, decoder)
# 6. 解码编辑后的嵌入,得到最终图像
edited_image = ddim_sampler.sample(z_edit, decoder, x_T=x_T)
return edited_image九、模型局限性与风险
1. 技术局限性
- 属性绑定能力弱:对于需要精准绑定多个物体和属性的提示词(比如"红色方块放在蓝色方块上面"),unCLIP容易出现属性混淆,比如把两个方块的颜色搞混。核心原因是CLIP嵌入没有显式地对"物体-属性"的绑定关系建模。
- 文本生成能力差:很难生成清晰、连贯的文字,比如提示词"写着deep learning的牌子",生成的文字大多是乱码。因为CLIP嵌入没有精准编码文字的拼写信息,BPE分词也进一步模糊了单词的拼写特征。
- 复杂场景细节不足:基础生成分辨率为64×64,再通过上采样得到高清图,对于复杂场景(比如城市街景、密集人群),容易出现细节丢失。提升基础分辨率能缓解这个问题,但会带来指数级增长的算力开销。
2. 安全与伦理风险
- 生成能力的提升,也带来了生成欺骗性、有害内容的风险,AI生成的图像痕迹越来越少,难以区分真假,可能被用于虚假信息传播。
- 模型会学习到训练数据中的偏见,可能生成带有性别、种族、地域偏见的内容,需要额外的安全对齐和过滤机制。
- 生成内容的版权归属、侵权风险,也是需要解决的重要问题。
十、总结与核心贡献
unCLIP的诞生,彻底改写了文生图的技术范式,其核心贡献可以总结为5点:
- 提出了文本→CLIP图像嵌入→图像的两阶段层级生成框架,在几乎不损失逼真度的前提下,大幅提升了文生图的生成多样性,解决了传统扩散模型"保真度-多样性不可兼得"的痛点。
- 全面对比了自回归先验和扩散先验,证明扩散先验在效果、计算效率上全面胜出,为后续文生图模型的先验设计提供了标准范式。
- 基于CLIP的联合图文隐空间,解锁了零样本图像变体、插值、文本差分编辑三大核心能力,大幅拓展了文生图模型的应用边界。
- 实现了引导强度的鲁棒性,提升引导强度优化生成质量的同时,不会导致生成多样性崩塌,为后续扩散模型的引导策略设计提供了新思路。
- 成为了DALL·E 2的核心技术底座,其设计思想也深刻影响了Stable Diffusion等后续主流文生图模型,推动了AIGC技术的爆发式发展。