备战软考中级:软件设计师历年高频错题与硬核解析(持续更新)
- [📢 前言](#📢 前言)
- [💻 一、计算机系统知识](#💻 一、计算机系统知识)
-
-
- [📌 错题 1:安全电子邮箱协议](#📌 错题 1:安全电子邮箱协议)
- [📌 错题 2:CPU 平均 CPI 与运算速度 MIPS 计算](#📌 错题 2:CPU 平均 CPI 与运算速度 MIPS 计算)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 3:内存寻址范围计算](#📌 错题 3:内存寻址范围计算)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 4:总线分类](#📌 错题 4:总线分类)
- [📌 错题 5:虚拟地址与物理地址](#📌 错题 5:虚拟地址与物理地址)
- [📌 错题 6:中断方式与 CPU 干预](#📌 错题 6:中断方式与 CPU 干预)
- [📌 错题 7:寻址方式速度对比](#📌 错题 7:寻址方式速度对比)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 8:循环冗余校验 (CRC)](#📌 错题 8:循环冗余校验 (CRC))
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 9:浮点数的数值计算](#📌 错题 9:浮点数的数值计算)
-
- [📝 深度解析](#📝 深度解析)
-
- [💻 二、程序设计语言基础](#💻 二、程序设计语言基础)
-
-
- [📌 错题 10:动态绑定与静态绑定](#📌 错题 10:动态绑定与静态绑定)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 11:编译过程的各个阶段](#📌 错题 11:编译过程的各个阶段)
-
- [📝 深度解析](#📝 深度解析)
-
- [💻 三、数据结构](#💻 三、数据结构)
-
-
- [📌 错题 12:优先队列与时间复杂度](#📌 错题 12:优先队列与时间复杂度)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 13:六大基础排序算法](#📌 错题 13:六大基础排序算法)
- [📌 错题 14:二叉排序树与平衡二叉树](#📌 错题 14:二叉排序树与平衡二叉树)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 15:B-树与 B+树的特性对比](#📌 错题 15:B-树与 B+树的特性对比)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 16:非连通图的最大边数定理](#📌 错题 16:非连通图的最大边数定理)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 17:深度优先遍历的时间复杂度](#📌 错题 17:深度优先遍历的时间复杂度)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 18:无向连通图的"边"与"路径"](#📌 错题 18:无向连通图的“边”与“路径”)
- [📌 错题 19:树的节点与度数计算](#📌 错题 19:树的节点与度数计算)
- [📌 错题 20:二叉树按层序编号的性质](#📌 错题 20:二叉树按层序编号的性质)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 21 & 22:哈夫曼树的构建过程](#📌 错题 21 & 22:哈夫曼树的构建过程)
-
- [📝 深度解析(画树铁律)](#📝 深度解析(画树铁律))
- [📌 错题 23:二维数组行优先存储的地址计算](#📌 错题 23:二维数组行优先存储的地址计算)
-
- [📝 深度解析](#📝 深度解析)
-
- [💻 四、操作系统知识](#💻 四、操作系统知识)
-
-
- [📌 错题 24:单处理机进程状态转换](#📌 错题 24:单处理机进程状态转换)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 25:非连续存放文件的磁盘读取时间](#📌 错题 25:非连续存放文件的磁盘读取时间)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 26:磁盘交替排列的最长与最短时间](#📌 错题 26:磁盘交替排列的最长与最短时间)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 27:死锁发生的最小资源需求计算](#📌 错题 27:死锁发生的最小资源需求计算)
-
- [📝 深度解析](#📝 深度解析)
-
- [🌐 五、计算机网络与信息安全](#🌐 五、计算机网络与信息安全)
-
-
- [📌 错题 28:防火墙的分类与监控层级](#📌 错题 28:防火墙的分类与监控层级)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 29:访问控制与入侵检测](#📌 错题 29:访问控制与入侵检测)
- [📌 错题 30:OSI 各层功能定义(数据链路层)](#📌 错题 30:OSI 各层功能定义(数据链路层))
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 31:电子邮件协议](#📌 错题 31:电子邮件协议)
- [📌 错题 32:DHCP 失效的后备机制 (APIPA)](#📌 错题 32:DHCP 失效的后备机制 (APIPA))
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 33:TCP/IP 与 OSI 模型的映射](#📌 错题 33:TCP/IP 与 OSI 模型的映射)
- [📌 错题 34:信息安全需求等级划分](#📌 错题 34:信息安全需求等级划分)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 35:DNS 查询顺序法则](#📌 错题 35:DNS 查询顺序法则)
- [📌 错题 36:网络诊断命令](#📌 错题 36:网络诊断命令)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 37:IPv4 地址分类判定](#📌 错题 37:IPv4 地址分类判定)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 38:TCP 与 UDP 的应用场景抉择](#📌 错题 38:TCP 与 UDP 的应用场景抉择)
- [📌 错题 39:ICMP 的协议分层与封装](#📌 错题 39:ICMP 的协议分层与封装)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 40:无线局域网标准](#📌 错题 40:无线局域网标准)
- [📌 错题 41:DNS IPv6 解析记录](#📌 错题 41:DNS IPv6 解析记录)
-
- [🏗️ 六、软件工程与结构化开发](#🏗️ 六、软件工程与结构化开发)
-
-
- [📌 错题 42:甘特图与 PERT 图的优劣势](#📌 错题 42:甘特图与 PERT 图的优劣势)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 43:模块耦合类型判断](#📌 错题 43:模块耦合类型判断)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 44:软件可维护性计算公式](#📌 错题 44:软件可维护性计算公式)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 45:ISO/IEC 9126 质量模型](#📌 错题 45:ISO/IEC 9126 质量模型)
- [📌 错题 46:软件设计核心活动](#📌 错题 46:软件设计核心活动)
- [📌 错题 47:四大开发方法论大杂烩](#📌 错题 47:四大开发方法论大杂烩)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 48:敏捷开发之"水晶法"](#📌 错题 48:敏捷开发之“水晶法”)
- [📌 错题 49:集成测试的策略对比](#📌 错题 49:集成测试的策略对比)
-
- [📝 深度解析](#📝 深度解析)
-
- [📦 七、面向对象技术与 UML](#📦 七、面向对象技术与 UML)
-
-
- [📌 错题 50:OOA 与 OOD 的区别](#📌 错题 50:OOA 与 OOD 的区别)
- [📌 错题 51:UML 活动图](#📌 错题 51:UML 活动图)
- [📌 错题 52:顺序图 (Sequence Diagram) 元素](#📌 错题 52:顺序图 (Sequence Diagram) 元素)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 53:面向对象测试层次](#📌 错题 53:面向对象测试层次)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 54:继承的本质定义](#📌 错题 54:继承的本质定义)
-
- [🗄️ 八、数据库技术与基础](#🗄️ 八、数据库技术与基础)
-
-
- [📌 错题 55:Armstrong 公理系统](#📌 错题 55:Armstrong 公理系统)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 56:OLAP vs OLTP](#📌 错题 56:OLAP vs OLTP)
- [📌 错题 57:概念结构设计步骤](#📌 错题 57:概念结构设计步骤)
- [📌 错题 58:分布式数据库的透明性](#📌 错题 58:分布式数据库的透明性)
-
- [📝 深度解析](#📝 深度解析)
-
- [🧮 九、算法设计、逻辑推导与杂项硬核计算](#🧮 九、算法设计、逻辑推导与杂项硬核计算)
-
-
- [📌 错题 59:子网划分数学题(C类网段借位计算)](#📌 错题 59:子网划分数学题(C类网段借位计算))
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 60:CIDR 子网块包含计算](#📌 错题 60:CIDR 子网块包含计算)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 61:非平凡子串的数学推导公式](#📌 错题 61:非平凡子串的数学推导公式)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 62:分页虚拟存储的缺页中断计算](#📌 错题 62:分页虚拟存储的缺页中断计算)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 63:文件逻辑记录跨块定位](#📌 错题 63:文件逻辑记录跨块定位)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 64:磁盘位图偏移量精算](#📌 错题 64:磁盘位图偏移量精算)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 65:最小生成树 (MST) 的算法取舍](#📌 错题 65:最小生成树 (MST) 的算法取舍)
- [📌 错题 66:语义错误识别(除数为0)](#📌 错题 66:语义错误识别(除数为0))
- [📌 错题 67:位运算妙用与底层屏蔽](#📌 错题 67:位运算妙用与底层屏蔽)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 68:RAID 5 阵列的木桶效应](#📌 错题 68:RAID 5 阵列的木桶效应)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 69:体系结构名词 VLIW 辨析](#📌 错题 69:体系结构名词 VLIW 辨析)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 70:国标与行标代码(标准化知识)](#📌 错题 70:国标与行标代码(标准化知识))
-
- [📝 深度解析](#📝 深度解析)
-
- [🌐 十、网络与信息安全基础知识](#🌐 十、网络与信息安全基础知识)
-
-
- [📌 错题 1:信息安全等级划分](#📌 错题 1:信息安全等级划分)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 2:DNS 的查询顺序法则](#📌 错题 2:DNS 的查询顺序法则)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 3:网络诊断命令的辨析](#📌 错题 3:网络诊断命令的辨析)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 4:IPv4 地址分类判定](#📌 错题 4:IPv4 地址分类判定)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 5:TCP 与 UDP 应用场景](#📌 错题 5:TCP 与 UDP 应用场景)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 6:ICMP 的协议分层与封装](#📌 错题 6:ICMP 的协议分层与封装)
-
- [📝 深度解析](#📝 深度解析)
-
- [📜 十一、标准化和软件知识产权基础知识](#📜 十一、标准化和软件知识产权基础知识)
-
-
- [📌 错题 1:国家/行业标准代号辨析](#📌 错题 1:国家/行业标准代号辨析)
-
- [📝 深度解析](#📝 深度解析)
-
- [🔥 其它(硬核计算与大招集锦)](#🔥 其它(硬核计算与大招集锦))
-
-
- [📌 错题 1:子网划分与掩码计算](#📌 错题 1:子网划分与掩码计算)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 2:分页系统的缺页中断计算](#📌 错题 2:分页系统的缺页中断计算)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 3:非平凡子串的数学推导](#📌 错题 3:非平凡子串的数学推导)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 4:文件逻辑记录到物理块定位](#📌 错题 4:文件逻辑记录到物理块定位)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 5:位图偏移量精算](#📌 错题 5:位图偏移量精算)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 6:DNS IPv6 记录名称](#📌 错题 6:DNS IPv6 记录名称)
- [📌 错题 7:WLAN 无线网络标准](#📌 错题 7:WLAN 无线网络标准)
- [📌 错题 8:CIDR 包含的子网数计算](#📌 错题 8:CIDR 包含的子网数计算)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 9:软件设计核心活动](#📌 错题 9:软件设计核心活动)
- [📌 错题 10:软件开发方法论大杂烩](#📌 错题 10:软件开发方法论大杂烩)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 11:语义错误(除数为0)](#📌 错题 11:语义错误(除数为0))
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 12:RAID 5 容量计算(木桶效应)](#📌 错题 12:RAID 5 容量计算(木桶效应))
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 13:位运算掩码技巧](#📌 错题 13:位运算掩码技巧)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 14:最小生成树 (MST) 的算法比较](#📌 错题 14:最小生成树 (MST) 的算法比较)
- [📌 错题 15:水晶法 (Crystal)](#📌 错题 15:水晶法 (Crystal))
- [📌 错题 16:自底向上集成测试](#📌 错题 16:自底向上集成测试)
-
- [📝 深度解析](#📝 深度解析)
- [📌 错题 17:超长指令字 (VLIW)](#📌 错题 17:超长指令字 (VLIW))
- [📌 错题 18:海明码校验位](#📌 错题 18:海明码校验位)
- [📌 错题 19:字号和位号的计算](#📌 错题 19:字号和位号的计算)
- [📌 错题 20:文件最大长度计算](#📌 错题 20:文件最大长度计算)
- [📌 错题 21:著作权](#📌 错题 21:著作权)
- [📌 错题 22:数据流加工](#📌 错题 22:数据流加工)
- [📌 错题 23:模块独立性(内聚类型)](#📌 错题 23:模块独立性(内聚类型))
- [📌 错题 24:结构图层数](#📌 错题 24:结构图层数)
- [📌 错题 25:链表](#📌 错题 25:链表)
- [📌 错题 26:IP地址计算](#📌 错题 26:IP地址计算)
-
- [🚀 结语](#🚀 结语)
📢 前言
在备战软考中级(软件工程师)的过程中,做真题是必不可少的环节。但这其中总有一些题目让人反复踩坑、频繁出错。
这一章我专门整理出了做题过程中那些最容易错、最容易混淆的题目,不仅记录了错题,更包含了详尽的推导过程与解析,希望能借此加深记忆,也希望能帮到同样在备考的你!
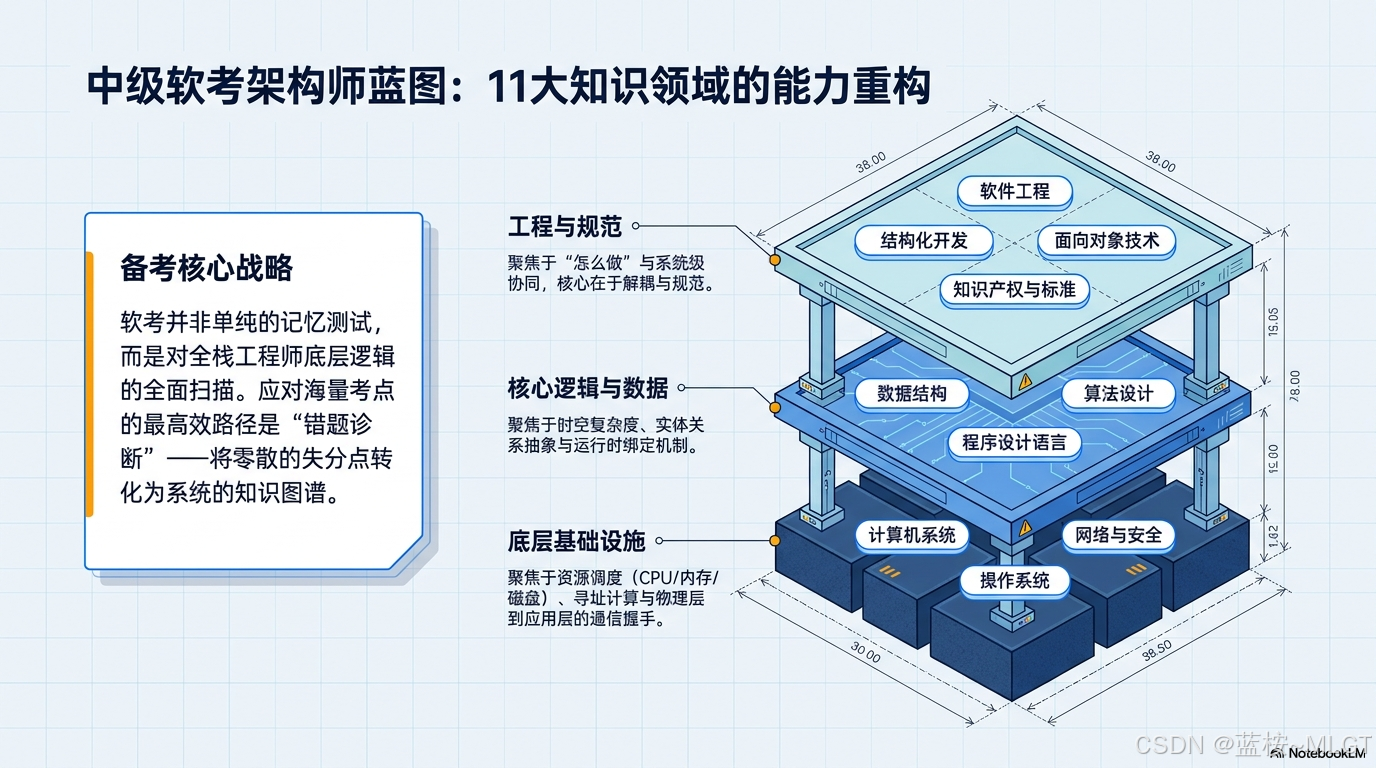
💻 一、计算机系统知识
📌 错题 1:安全电子邮箱协议
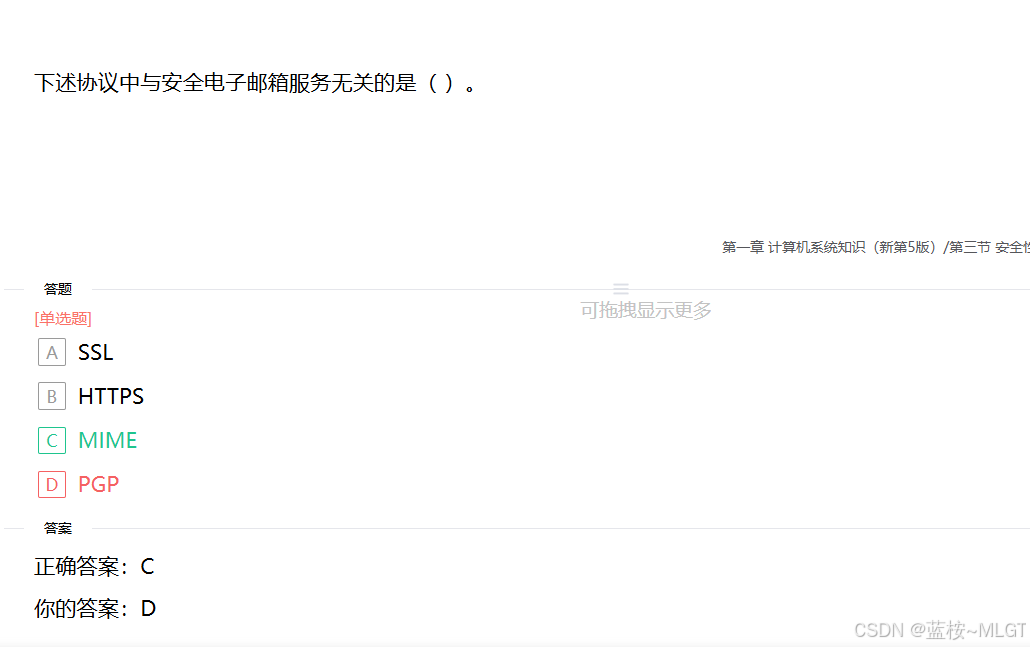
💡 避坑提示:本题考查安全电子邮箱服务相关基础知识。软考经常在缩写字母上设下陷阱。
- MIME :它是一个互联网标准,扩展了电子邮件标准,使其能够支持多媒体,但与安全无关。
- S/MIME:与安全电子邮件相关的是 S/MIME(安全多用途互联网邮件扩展协议)。
- A选项 SSL 和 B选项 HTTPS 涉及邮件传输过程的安全;D选项 PGP(全称:Pretty Good Privacy,优良保密协议),是一套用于信息加密、验证的应用程序,可用于加密电子邮件内容。
📌 错题 2:CPU 平均 CPI 与运算速度 MIPS 计算
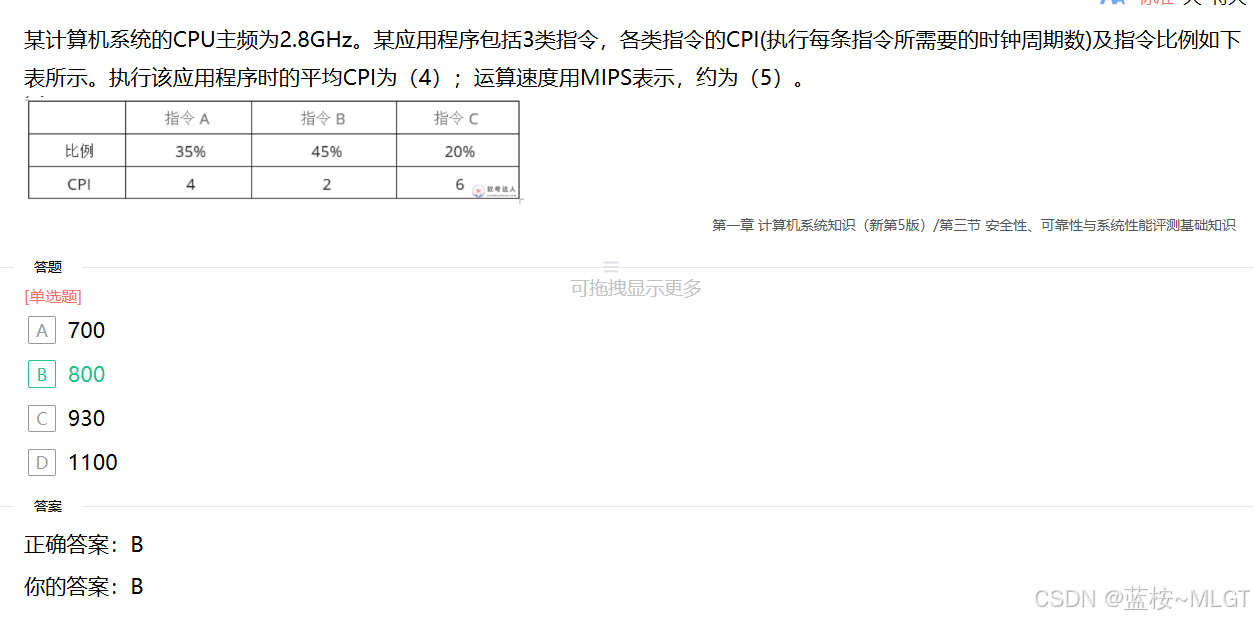
📝 深度解析
根据题目提供的信息,我们可以按照以下步骤进行计算:
1. 计算平均 CPI(每条指令所需的平均时钟周期数)
平均 CPI 是各类指令 CPI 的加权平均值。计算公式为:
平均 CPI = ∑ ( 各指令比例 × 各指令 CPI ) \text{平均 CPI} = \sum (\text{各指令比例} \times \text{各指令 CPI}) 平均 CPI=∑(各指令比例×各指令 CPI)
代入数据:
平均 CPI = 35 % × 4 + 45 % × 2 + 20 % × 6 \text{平均 CPI} = 35\% \times 4 + 45\% \times 2 + 20\% \times 6 平均 CPI=35%×4+45%×2+20%×6
平均 CPI = 0.35 × 4 + 0.45 × 2 + 0.20 × 6 \text{平均 CPI} = 0.35 \times 4 + 0.45 \times 2 + 0.20 \times 6 平均 CPI=0.35×4+0.45×2+0.20×6
平均 CPI = 1.4 + 0.9 + 1.2 = 3.5 \text{平均 CPI} = 1.4 + 0.9 + 1.2 = 3.5 平均 CPI=1.4+0.9+1.2=3.5
因此,(4) 的填空值为 3.5。
2. 计算运算速度 MIPS(每秒百万条指令)
MIPS 的计算公式为:
MIPS = 主频 (Hz) 平均 CPI × 10 6 = 主频 (MHz) 平均 CPI \text{MIPS} = \frac{\text{主频 (Hz)}}{\text{平均 CPI} \times 10^6} = \frac{\text{主频 (MHz)}}{\text{平均 CPI}} MIPS=平均 CPI×106主频 (Hz)=平均 CPI主频 (MHz)
已知 CPU 主频为 2.8 GHz 2.8\text{ GHz} 2.8 GHz,即 2800 MHz 2800\text{ MHz} 2800 MHz。代入数据:
MIPS = 2800 3.5 = 800 \text{MIPS} = \frac{2800}{3.5} = 800 MIPS=3.52800=800
因此,(5) 的填空值为 800。
📌 错题 3:内存寻址范围计算
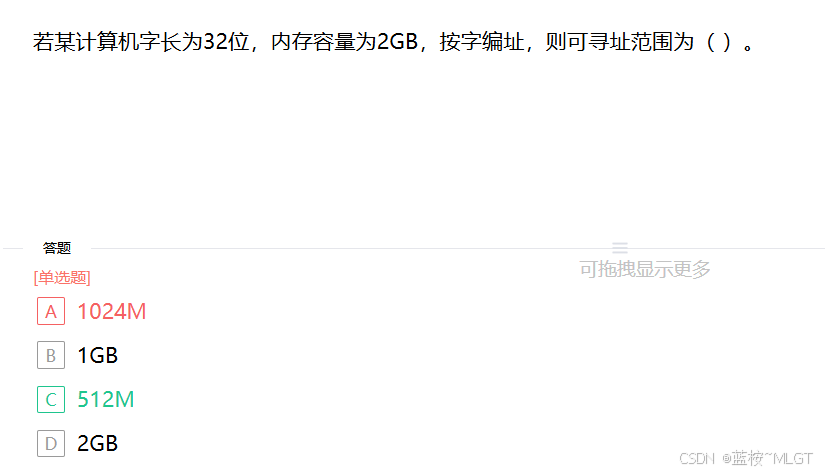
📝 深度解析
1. 理解已知条件
- 字长 (Word Length) : 32 32 32 位。在计算机中, 1 1 1 字节 (Byte) = 8 8 8 位 (bit),所以该计算机的字长为 32 / 8 = 4 32 / 8 = 4 32/8=4 字节。
- 内存容量 (Memory Capacity) : 2 GB 2\text{GB} 2GB。
- 编址方式 :按字编址。这意味着每一个地址单元对应一个"字"的大小(即 4 4 4 字节)。
2. 计算寻址范围
寻址范围指的是内存中总共有多少个可编址的单位(在这里是"字")。
计算公式为:
寻址范围 = 总容量 编址单位的大小 \text{寻址范围} = \frac{\text{总容量}}{\text{编址单位的大小}} 寻址范围=编址单位的大小总容量
代入数据:
寻址范围 = 2 GB 4 B \text{寻址范围} = \frac{2\text{GB}}{4\text{B}} 寻址范围=4B2GB
因为 1 GB = 1024 MB 1\text{GB} = 1024\text{MB} 1GB=1024MB,所以:
寻址范围 = 2 × 1024 MB 4 B = 2048 MB 4 = 512 M \text{寻址范围} = \frac{2 \times 1024\text{MB}}{4\text{B}} = \frac{2048\text{MB}}{4} = 512\text{M} 寻址范围=4B2×1024MB=42048MB=512M
📌 错题 4:总线分类

💡 解析 :PCI总线是目前微型机上广泛采用的内总线 ,采用并行传输方式。
📌 错题 5:虚拟地址与物理地址
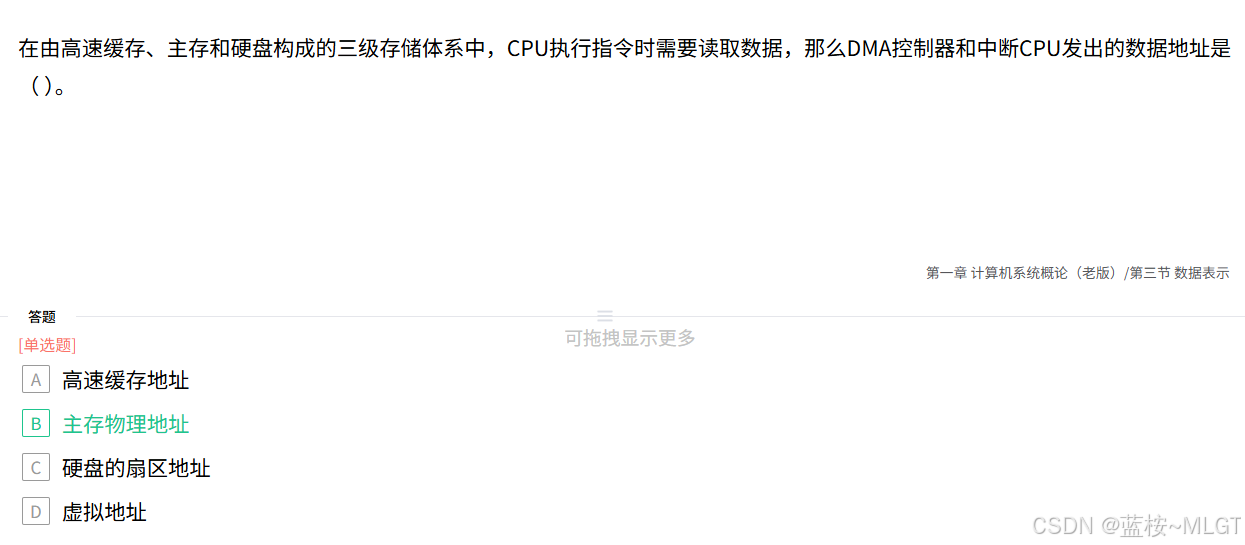
💡 解析:程序中用到的是虚拟地址,硬件中访问的通常是物理地址。
📌 错题 6:中断方式与 CPU 干预

⚠️ 避坑吐槽 :这个知识点很常见,不过这道题考得比较细致。我们经常会把"CPU的干预"和"CPU等待"搞混淆。正确的是两者都不需要CPU进行等待,保证了某种意义上的并行;但不是说不需要CPU干预,尤其是中断方式,是需要CPU搬运数据的。
📌 错题 7:寻址方式速度对比
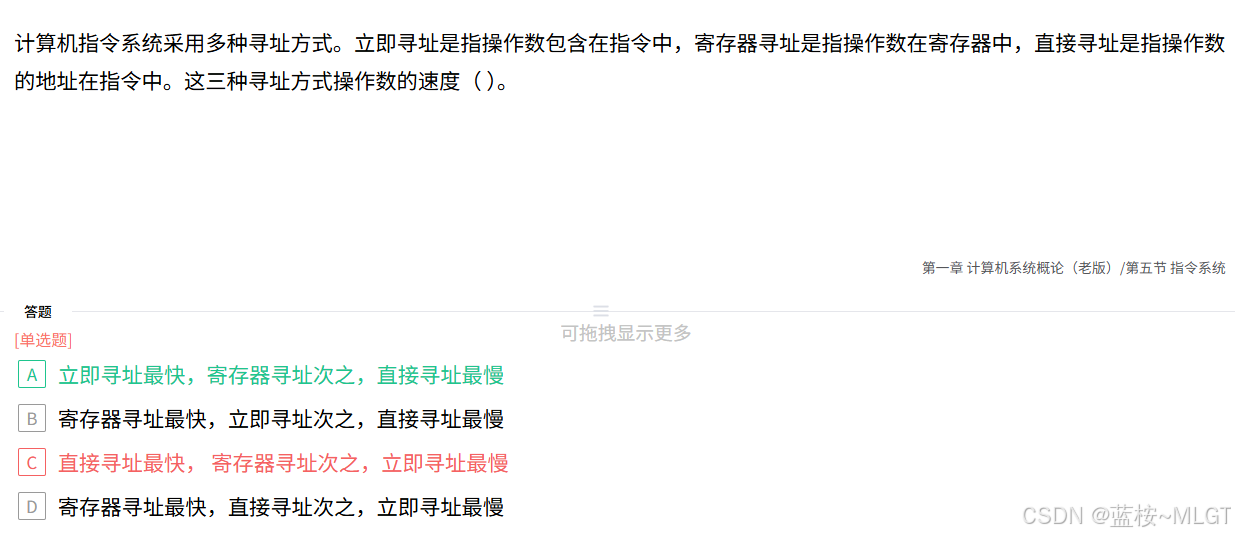
📝 深度解析
三种寻址方式的详细对比:
- 立即寻址 (Immediate Addressing) :操作数直接就在指令中。CPU 取指阶段,指令和操作数一起被取到内部。0 次额外访问 ,速度最快。
- 寄存器寻址 (Register Addressing) :指令中给出的是寄存器编号。CPU 需去指定的寄存器里读数据。1 次寄存器访问 ,速度次之。
- 直接寻址 (Direct Addressing) :指令中给出的是操作数在主存的地址。CPU 必须访问一次内存 才能拿到数据。内存速度远慢于 CPU,速度最慢。
按照获取操作数的速度从快到慢排列为:
立即寻址 > 寄存器寻址 > 直接寻址(若有间接寻址,它需要多次访存,速度更慢)。
📌 错题 8:循环冗余校验 (CRC)
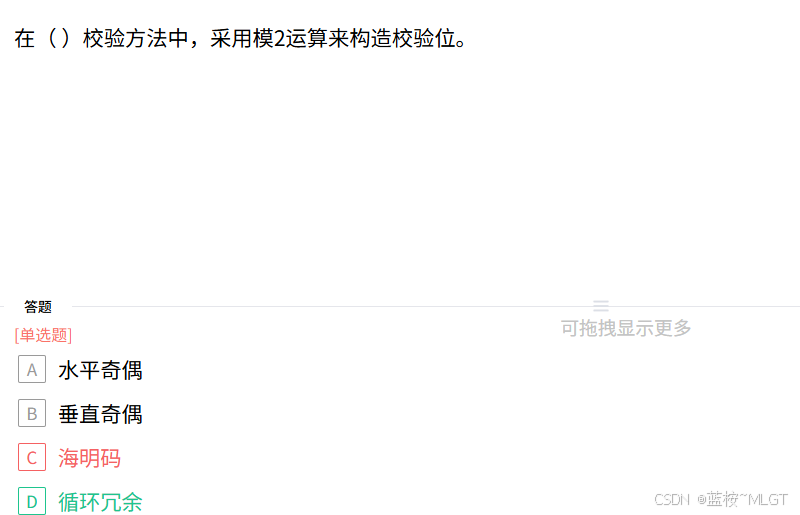
📝 深度解析
- 循环冗余校验 (CRC) :核心原理是利用多项式除法 。计算时将数据看作一个长多项式,除以一个固定的生成多项式,除法过程是模2运算。得到的余数即为校验位。
- 奇偶校验 (A和B):通常直接描述为"统计1的个数"。
- 海明码 ©:具备检错和纠错能力,最显著的标签是"纠错"。
在各类计算机水平考试中,**"模2运算"**是 CRC 的标志性关键词。因此选 D。
📌 错题 9:浮点数的数值计算
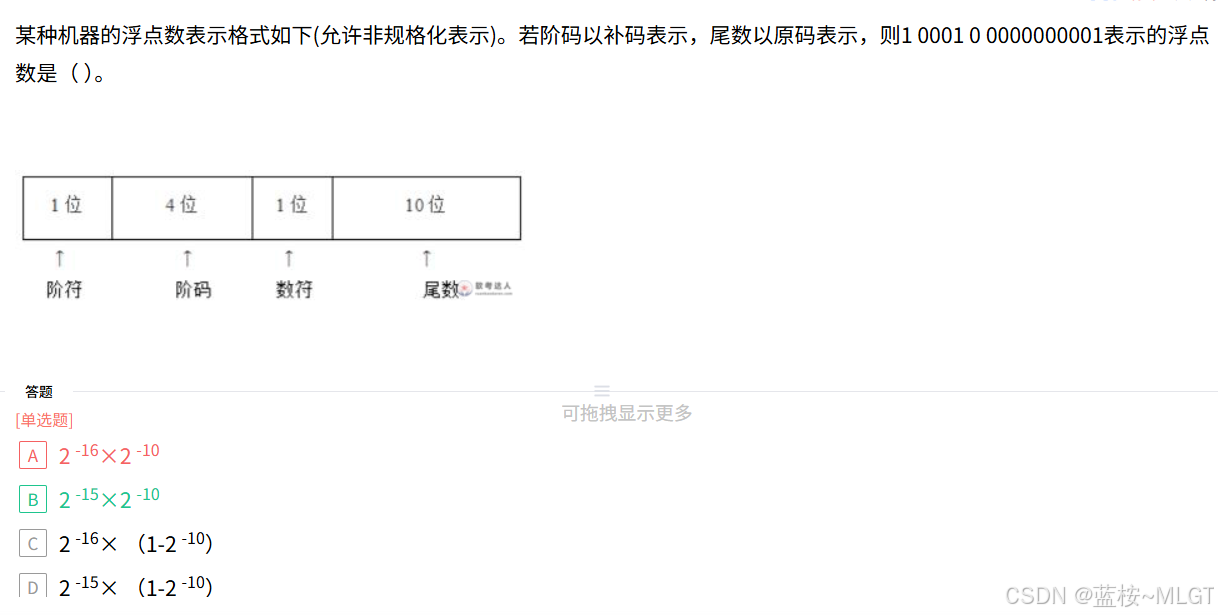
📝 深度解析
1. 拆解二进制序列 :给定的二进制串是 1 0001 0 0000000001
- 阶符(1位) :
1 - 阶码(4位) :
0001 - 数符(1位) :
0 - 尾数(10位) :
0000000001
2. 计算阶码(指数部分) :阶码为 5 位补码 10001。最高位 1 表示负数。取反加1得到绝对值 01111 ( 15 15 15),故真值为 − 15 -15 −15 。阶码 E = − 15 E = -15 E=−15。
3. 计算尾数(数值部分) :数符 0 表示正数。非规格化表示下,值为 0.0000000001 2 = 1 × 2 − 10 0.0000000001_2 = 1 \times 2^{-10} 0.00000000012=1×2−10。
4. 组合得到浮点数值 :公式 值 = 尾数 × 2 阶码 \text{值} = \text{尾数} \times 2^{\text{阶码}} 值=尾数×2阶码。即 2 − 10 × 2 − 15 2^{-10} \times 2^{-15} 2−10×2−15。与选项 B 完全吻合。
💻 二、程序设计语言基础
📌 错题 10:动态绑定与静态绑定
📝 深度解析
- 静态绑定 (Static Binding) :在编译或链接阶段就已经确定了调用哪个具体的函数。
- 动态绑定 (Dynamic Binding) :在程序运行时(Runtime) ,根据对象的实际类型来决定调用哪一段代码。
题目明确指出是在"运行时 "结合,所以正确答案是 D. 动态绑定。
📌 错题 11:编译过程的各个阶段
📝 深度解析
- 词法分析 :输入源程序,输出记号流(Token序列)(第一空答案)。检查非法的字符、拼写错误的关键字。
- 语法分析 :根据语法规则将单词组成语法单位。专门检查语法结构错误 ,例如:括号不配对、缺少分号等(第二空答案)。
- 语义分析:检查意思对不对。例如:变量未定义就使用、类型不匹配等。
💻 三、数据结构
📌 错题 12:优先队列与时间复杂度
📝 深度解析
- 第一空 :优先队列的每次出队都要求优先级最高。堆(Heap)(通常是二叉堆)是实现优先队列最有效、最常用的数据结构。
- 第二空 :基于二叉堆实现的优先队列,插入元素后需要进行"上滤"操作。由于堆是一个完全二叉树,其高度为 log 2 n \log_2 n log2n,所以插入操作的时间复杂度为 O ( log n ) O(\log n) O(logn)。
📌 错题 13:六大基础排序算法

💡 详情可看博客:中级软考(软件工程师)算法特辑------常考的六大基础排序算法,介绍得很详细。
📌 错题 14:二叉排序树与平衡二叉树
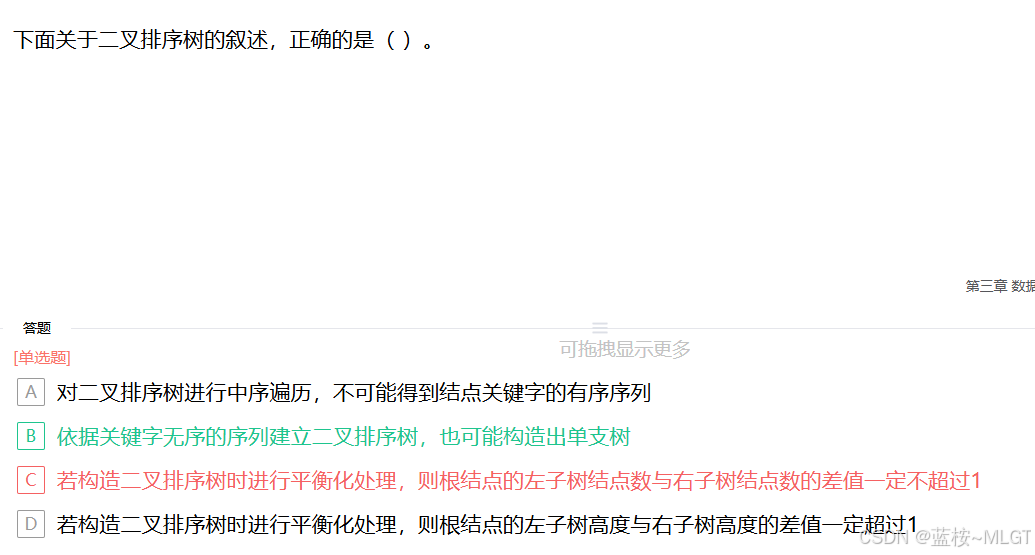
📝 深度解析
- A 错误 :对二叉排序树进行中序遍历(左-根-右)得到的结果一定是一个递增的有序序列。
- B 正确 :如果这组"无序"数据恰好是按递增或递减输入的,构造出来的树就会退化成一个单支树。
- C 错误 :平衡化处理控制的是子树的高度差 不超过 1,并不代表结点数的差值也不超过 1。
- D 错误 :平衡二叉树的要求是高度差绝对值不超过 1,而不是超过 1。
📌 错题 15:B-树与 B+树的特性对比
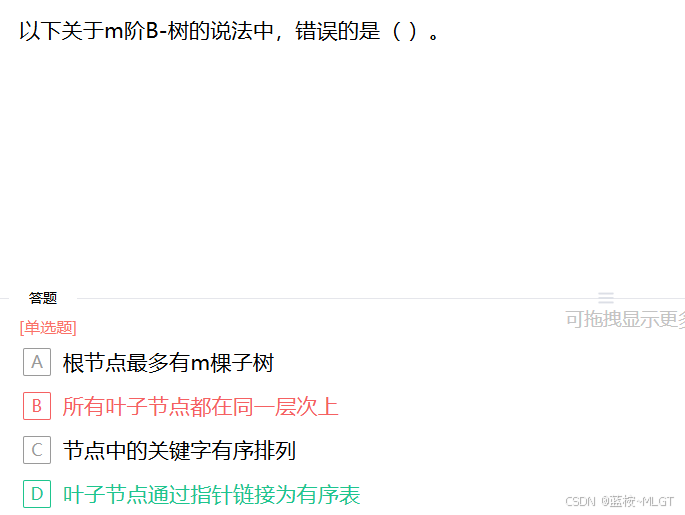
📝 深度解析
核心区别 :
B+树中只有叶子节点存数据 ,且所有叶子节点通过指针串联 形成有序链表,极其适合数据库的范围检索。
根据表格所述,D选项为B+树的特性,因此选D。
📌 错题 16:非连通图的最大边数定理

📝 深度解析
若一个无向图 G G G 有 n n n 个顶点且是非连通 的,则最极端的情况是其中 n − 1 n-1 n−1 个顶点构成一个完全图,而第 n n n 个顶点是孤立的。公式为:
E ≤ ( n − 1 ) ( n − 2 ) 2 E \le \frac{(n-1)(n-2)}{2} E≤2(n−1)(n−2)
代入边数 E = 28 E = 28 E=28,有 56 ≤ ( n − 1 ) ( n − 2 ) 56 \le (n-1)(n-2) 56≤(n−1)(n−2)。
当 n = 9 n=9 n=9 时, ( 9 − 1 ) × ( 9 − 2 ) = 56 (9-1) \times (9-2) = 56 (9−1)×(9−2)=56,条件恰好成立。因此图至少有 9 个顶点,选 B。
📌 错题 17:深度优先遍历的时间复杂度
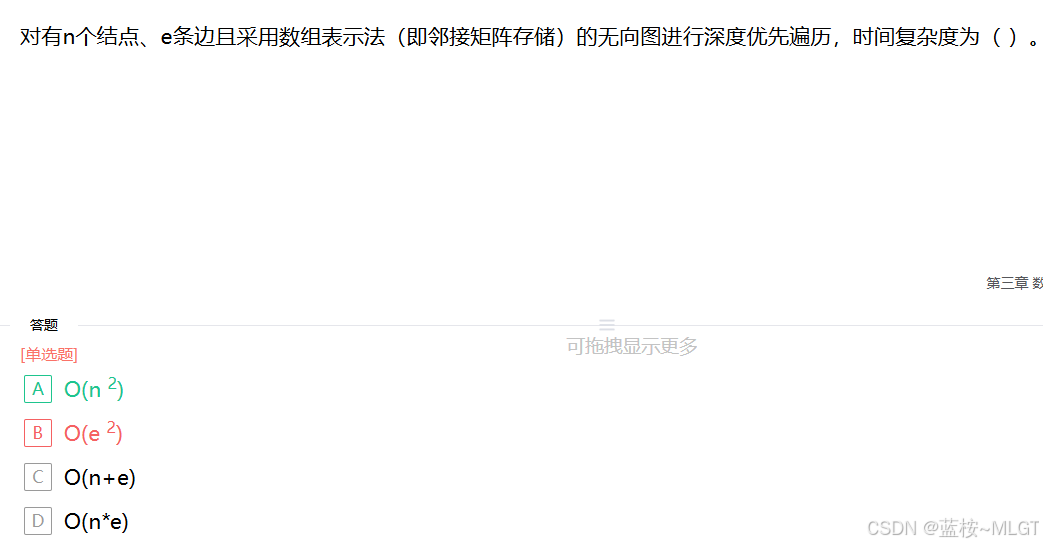
📝 深度解析
- 邻接矩阵(数组表示法) :查找一个顶点 i i i 的邻接点必须扫描矩阵的整行( n n n 个元素)。总共 n n n 个顶点,因此总时间复杂度为 n × O ( n ) = O ( n 2 ) n \times O(n) = \mathbf{O(n^2)} n×O(n)=O(n2)。选 A。
- 邻接表 :查找邻接点只需遍历链表,时间复杂度为 O ( n + e ) O(n+e) O(n+e)。
📌 错题 18:无向连通图的"边"与"路径"

⚠️ 避坑吐槽:"边"是直达,"路径"是转乘,所以无向连通图两个顶点之间不一定有边,但是路径是可以存在的。A 是错误的。
📌 错题 19:树的节点与度数计算
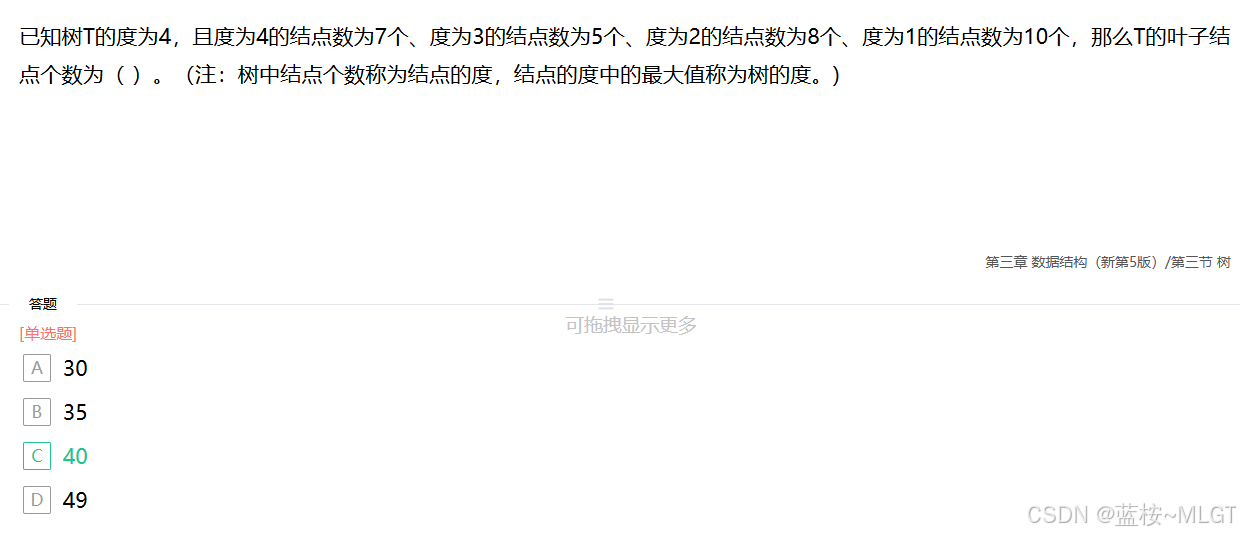
💡 解析 :在树结构中,总边数等于所有节点度数之和,同时等于总节点数减一。
设叶子结点数为 n 0 n_0 n0,总节点数为 7 + 5 + 8 + 10 + n 0 = 30 + n 0 7+5+8+10+n_0 = 30+n_0 7+5+8+10+n0=30+n0。
总度数 = 4 × 7 + 3 × 5 + 2 × 8 + 1 × 10 = 69 = 4 \times 7 + 3 \times 5 + 2 \times 8 + 1 \times 10 = 69 =4×7+3×5+2×8+1×10=69。
根据树的性质: 69 = ( 30 + n 0 ) − 1 69 = (30+n_0)-1 69=(30+n0)−1,解得 n 0 = 40 n_0 = 40 n0=40。选 C。
📌 错题 20:二叉树按层序编号的性质

📝 深度解析
从根结点开始按层序编号(从 1 开始),对于编号为 m m m 的结点:
- 左孩子 编号为: 2 m 2m 2m
- 右孩子 编号为:2 m + 1 2m + 1 2m+1
题目给出 n = 2 m + 1 n = 2m + 1 n=2m+1,这明确说明 n n n 是 m m m 的右孩子。选 D。
📌 错题 21 & 22:哈夫曼树的构建过程
💡 解析:哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近,D选项说法正确。构造中不保证是完全树或平衡树(A、B错),父结点权值等于左右孩子之和,必定大于孩子结点(C错)。

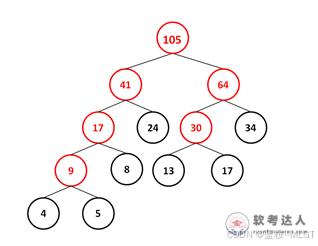
📝 深度解析(画树铁律)
哈夫曼树的每一个动作,都必须遵循一个铁律:在当前所有剩下的"数字"里,挑最小的两个。
- 初始状态:
[4, 5, 8, 13, 17, 24, 34] - 第一步:
4+5=9。池子变为:[8, 9, 13, 17, 24, 34]。 - 第二步:
8+9=17(内)。池子变为:[13, 17, 17(内), 24, 34]。 - 关键的第三步 :挑最小的两个,分别是 13 和 17。即使你心里想让 24 去凑热闹,规则也不允许。必须让 13 和 17 合并!
📌 错题 23:二维数组行优先存储的地址计算

📝 深度解析
二维数组 A i j Aij Aij 的地址公式为: Addr ( A i j ) = Base + ( i × N + j ) × L \text{Addr}(Aij) = \text{Base} + (i \times N + j) \times L Addr(Aij)=Base+(i×N+j)×L
1. 求出数组的列数 N N N
已知 Base = 100 , L = 2 , A 3 3 = 220 \text{Base}=100, L=2, A33=220 Base=100,L=2,A33=220。代入公式:
100 + ( 3 N + 3 ) × 2 = 220 ⇒ 3 N + 3 = 60 ⇒ N = 19 100 + (3N + 3) \times 2 = 220 \Rightarrow 3N+3 = 60 \Rightarrow N = 19 100+(3N+3)×2=220⇒3N+3=60⇒N=19。
2. 计算元素 A 5 5 A55 A55 的地址
Addr ( A 5 5 ) = 100 + ( 5 × 19 + 5 ) × 2 = 100 + 200 = 300 \text{Addr}(A55) = 100 + (5 \times 19 + 5) \times 2 = 100 + 200 = \mathbf{300} Addr(A55)=100+(5×19+5)×2=100+200=300。选 A。
💻 四、操作系统知识
📌 错题 24:单处理机进程状态转换

📝 深度解析
在单处理机系统中,同一时刻只能有一个进程处于"运行"状态。
目前状态:P1 运行,P2 就绪,P3/P4 等待。
无论 P1 发生何种情况导致其离开"运行"态(比如请求 I/O 被阻塞、时间片到期被挂起等),系统都会从就绪队列中选一个进程接手 CPU。
因为目前就绪队列中只有 P2 ,所以 P2 必定会变为"运行"态。其余等待特定外设的进程状态取决于资源是否被释放。常考答案是:P1 等待,P2 运行,P3 等待,P4 等待。
📌 错题 25:非连续存放文件的磁盘读取时间
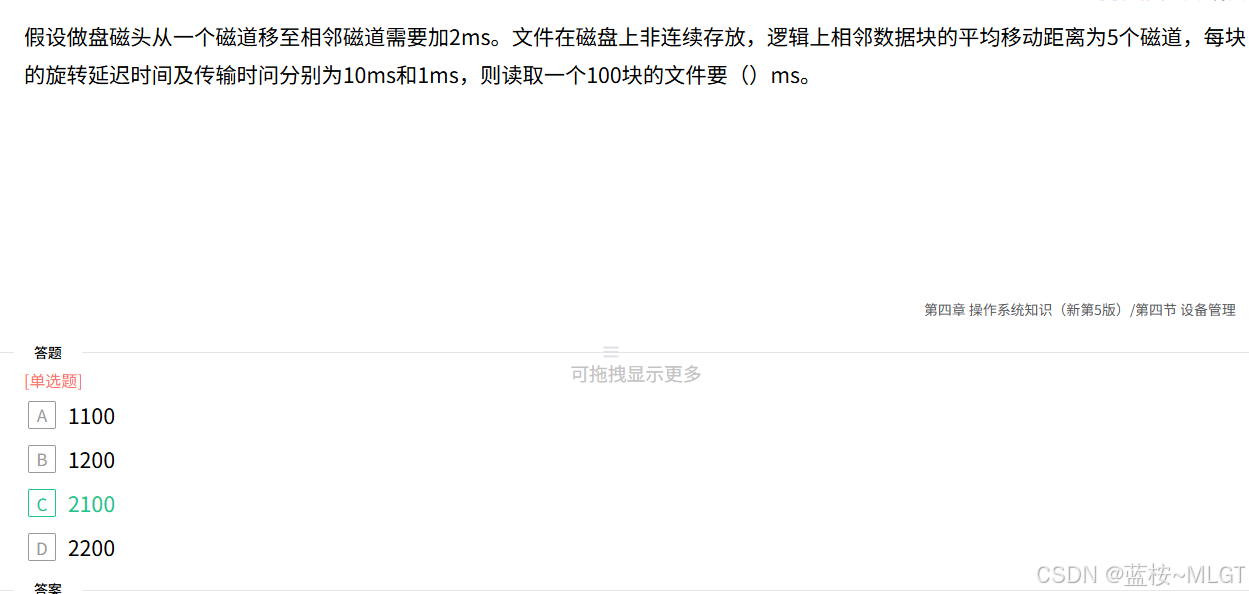
📝 深度解析
读取一个块的时间 = 寻道时间 + 旋转延迟时间 + 传输时间。
- 寻道时间 = 5 × 2 ms = 10 ms 5 \times 2\text{ms} = 10\text{ms} 5×2ms=10ms。
- 单块总时间 = 10 ms + 10 ms + 1 ms = 21 ms 10\text{ms} + 10\text{ms} + 1\text{ms} = 21\text{ms} 10ms+10ms+1ms=21ms。
由于文件是非连续存放 的,读下一块时磁头需要重新寻道和等待旋转。
总时间 = 21 ms/块 × 100 块 = 2100 m s 21\text{ms/块} \times 100\text{ 块} = \mathbf{2100 ms} 21ms/块×100 块=2100ms。选 C。
📌 错题 26:磁盘交替排列的最长与最短时间

📝 深度解析
- 磁盘读一块 1 ms 1\text{ms} 1ms,CPU 处理 2 ms 2\text{ms} 2ms。系统是单缓冲区(必须先读后处理,处理完才能读下一块)。
- 最长时间(顺序排列) :处理 R1 的 2 ms 2\text{ms} 2ms 期间,磁盘不停转。处理完时,磁头已经转到了块 4 开头。要想读块 2 里的 R2,必须等磁盘转一圈回到块 2(耗时 8 ms 8\text{ms} 8ms)。每个记录耗时 1 + 2 + 8 = 11 ms 1+2+8 = 11\text{ms} 1+2+8=11ms。总耗时 9 × 11 + 3 ( 最后一个不用等 ) = 102 m s 9 \times 11 + 3(\text{最后一个不用等}) = \mathbf{102ms} 9×11+3(最后一个不用等)=102ms。
- 最短时间(优化排列) :为了不等待,将逻辑上的下一个记录放在距离上一个记录 3 个物理块之后。这样 CPU 处理完时,磁头正好转到下一个记录。每个记录完美耗时 3 ms 3\text{ms} 3ms,总计 10 × 3 = 30 m s 10 \times 3 = \mathbf{30ms} 10×3=30ms。
📌 错题 27:死锁发生的最小资源需求计算
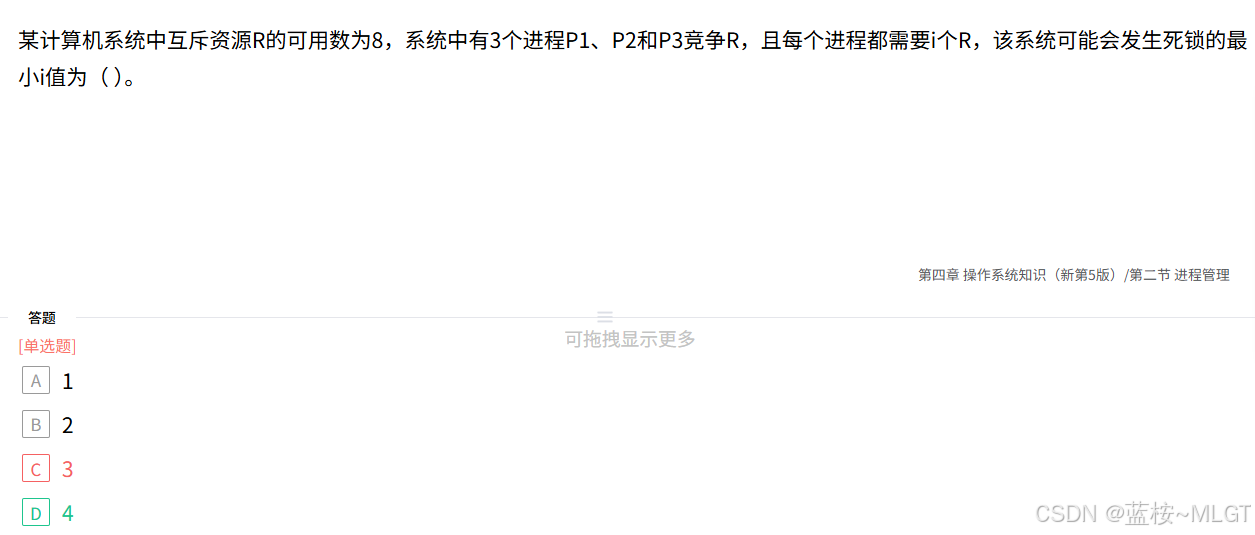
📝 深度解析
不发生死锁的绝对安全公式: m ≥ n × ( i − 1 ) + 1 m \ge n \times (i - 1) + 1 m≥n×(i−1)+1
代入资源总数 m = 8 m = 8 m=8,进程数 n = 3 n = 3 n=3:
8 ≥ 3 × ( i − 1 ) + 1 ⇒ 7 ≥ 3 × ( i − 1 ) ⇒ i ≤ 3.33 8 \ge 3 \times (i - 1) + 1 \Rightarrow 7 \ge 3 \times (i - 1) \Rightarrow i \le 3.33 8≥3×(i−1)+1⇒7≥3×(i−1)⇒i≤3.33
当需求量 i = 1 , 2 , 3 i = 1, 2, 3 i=1,2,3 时,系统永远安全。因此,第一个可能破坏安全条件的整数(即可能发生死锁的最小 i i i 值)是 4。选 D。
🌐 五、计算机网络与信息安全
软考中的网络和安全部分知识点非常碎,尤其是 OSI 模型映射、IP 子网计算和各种协议的归属,这部分丢分非常可惜。
📌 错题 28:防火墙的分类与监控层级

⚠️ 避坑吐槽:很多同学一看到防火墙就选包过滤,其实要看题干里强调的是哪一层的监控!
📝 深度解析
- 包过滤防火墙 (Packet Filtering) :工作在网络层 和传输层,只检查 IP 和端口,不看具体数据内容,速度快但防范浅。
- 应用级网关防火墙 (Application-level Gateway) :工作在应用层。它能拆开数据包理解 HTTP/FTP 等协议,完美符合题干"对应用层的通信数据流进行监控和过滤"的描述。选 B。
📌 错题 29:访问控制与入侵检测
💡 解析 :ACL (访问控制列表) 的核心功能就是通过规则"拦截"或"放行"数据包,明确禁止未授权访问。而 IDS (入侵检测) 只是"监控器",负责报警,通常不直接执行拦截操作。选 A。
📌 错题 30:OSI 各层功能定义(数据链路层)
📝 深度解析
- 物理层 :透明传送比特流,不保证可靠性。
- 数据链路层 :通过差错控制、帧同步等手段,将有差错的物理线路转变为逻辑上无差错的数据链路,提供物理线路上的可靠传输。
- 网络层 :负责路由选择和拥塞控制。
题目强调"物理线路上"提供"可靠传输",选 B。
📌 错题 31:电子邮件协议
💡 解析 :负责发送 (从客户端到服务器,或服务器之间)的是 SMTP 。负责接收 (下载到本地)的是 POP3 / IMAP4。MIME 是邮件内容的格式扩展标准。选 A。
📌 错题 32:DHCP 失效的后备机制 (APIPA)
📝 深度解析
当主机设置了自动获取 IP,但多次联系不上 DHCP 服务器时,操作系统会启动 APIPA(自动私有 IP 地址)机制。它会在 IANA 保留的 B 类网段 169.254.0.0/16 中给自己随机分配一个地址。选 D。
📌 错题 33:TCP/IP 与 OSI 模型的映射
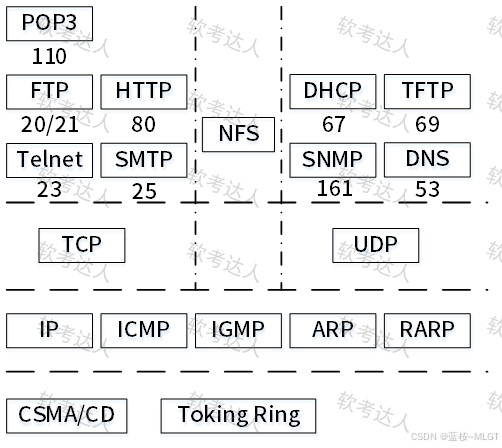
⚠️ 高能预警 :最后这张映射图一定要背下来!这几乎是每次必考的送分题。
- 负责"建立连接"和"提供可靠通信"(如三次握手、丢包重传),在 TCP/IP 中由 TCP 协议实现,它对应的正是 OSI 的传输层。选 D。
📌 错题 34:信息安全需求等级划分
📝 深度解析
- 物理层安全:机房安全。
- 网络层安全:入侵检测、防火墙。
- 系统安全 :侧重操作系统/环境,如漏洞补丁管理。
- 应用安全 :侧重业务软件,如数据库安全、Web服务安全。
📌 错题 35:DNS 查询顺序法则
⚠️ 避坑吐槽:万能逻辑"先本地后外部,先缓存后文件"。但要注意题干问的是谁!
- 如果是主机(电脑),会先查本地缓存,再查 hosts 文件。
- 题干问的是域名服务器 接到请求后的反应,服务器的第一步永远是先查自己的本地缓存,没有才会去查区域数据库或转发。选 C。
📌 错题 36:网络诊断命令
📝 深度解析
- nslookup:专用于诊断 DNS。
- ping / tracert:虽然测连通性和路由,但输入域名时底层会调用 DNS 解析,也可辅助诊断。
- netstat :查看本地端口监听和 TCP 连接状态,不能用于诊断 DNS。选 A。
📌 错题 37:IPv4 地址分类判定
📝 深度解析
背诵首字节范围:
- A类:1~126
- B类:128~191
- C类:192~223
选项 B(202.113.16.8)的首字节 202 落在 C 类范围内,属于 C 类网络地址。
📌 错题 38:TCP 与 UDP 的应用场景抉择

💡 解析 :求"稳"(不能丢包)用 TCP,如网页(HTTP)、邮件(SMTP)、远程(Telnet);求"快"(不能延迟)用 UDP,如VoIP(网络电话)、直播、游戏。选 C。
📌 错题 39:ICMP 的协议分层与封装

📝 深度解析
- ICMP (网际控制报文协议) 和 IP 协议同属于网络层。
- 但 ICMP 报文本身并不能独立传输,它需要作为"数据载荷"被封装在 IP 数据报 中,再交由下层发送。
📌 错题 40:无线局域网标准
💡 解析 :无线 WLAN 主要采用的是 IEEE 802.11 标准族。
📌 错题 41:DNS IPv6 解析记录
💡 解析 :将域名解析为 IPv4 是 A 记录;解析为 IPv6 因为地址长度是 v4 的四倍,所以叫 AAAA 记录。
🏗️ 六、软件工程与结构化开发
📌 错题 42:甘特图与 PERT 图的优劣势


📝 深度解析
这对"卧龙凤雏"是必考对比项:
- 甘特图 (Gantt) :横条图。优点是清晰表达时间进度、并行关系 ;缺点是难以表达任务依赖逻辑,看不出关键路径。
- PERT 图 :网络图。优点是清晰表达任务衔接关系、极易识别关键路径 ;缺点是看不出具体的日历时间和实际进度。
📌 错题 43:模块耦合类型判断
📝 深度解析
题干:传递的是"采购金额、收款方、日期"等基础数据,且全部被财务系统使用。
这是最理想、耦合度最低的方式,称为数据耦合 。如果传递了包含冗余信息的大数据结构(只用其中一部分)则是标记耦合 ;传递开关标志则是控制耦合。
📌 错题 44:软件可维护性计算公式
📝 深度解析
- MTTF (平均无故障时间) 代表可靠性。
- MTTR (平均故障修复时间) 代表可维护性。
可维护性评估分数在 0~1 之间,MTTR 越小(修得越快),可维护性越好。因此数学模型为 1 / ( 1 + MTTR ) 1 / (1 + \text{MTTR}) 1/(1+MTTR)。
📌 错题 45:ISO/IEC 9126 质量模型
⚠️ 避坑吐槽:反常识警告!日常觉得"安全性"属于"可靠性",但在 ISO 标准里并不是!
- 安全性 (Security) 在标准中被明确定义为功能性 (Functionality) 的子特性(因为它是一种保护数据的"能力/功能")。选 A。
📌 错题 46:软件设计核心活动

💡 解析 :软件设计的 4 个核心活动:数据设计、体系结构设计、接口设计、过程设计(详细设计)。选 C。
📌 错题 47:四大开发方法论大杂烩
📝 深度解析
这道题填了三个大坑:
- 强调"自顶向下、功能分解"的是结构化方法。
- 提出"螺旋上升"、分为宏观微观过程的是 Booch 方法。
- Booch/UML 动态模型描述对象状态变化用状态图,描述交互过程用交互图(包含了顺序图和协作图,选交互图更精准)。
📌 错题 48:敏捷开发之"水晶法"
💡 解析 :看到"每个项目不同 "、"量身定制 (不同颜色代表不同策略)",必定是水晶法 (Crystal)。XP 极限编程侧重于 TDD 和结对;Scrum 侧重于冲刺和会议。
📌 错题 49:集成测试的策略对比
📝 深度解析
- 自底向上策略 :从最底层叶子模块往上测。优点是底层模块是真实的现成代码,所以不需要写桩程序 (Stub) 去模拟。但由于上层还没准备好,必须写驱动程序 (Driver)。
- 自顶向下策略:优点是能尽早发现高层设计缺陷;缺点是底层都是假的,要写大量桩程序。
📦 七、面向对象技术与 UML
📌 错题 50:OOA 与 OOD 的区别

⚠️ 避坑吐槽:很多同学分不清面向对象分析(OOA)和面向对象设计(OOD)。
- OOA (分析):看"问题空间",提取对象。关键词是"认定对象、描述作用"。
- OOD (设计):看"解决方案"。一旦看到**"定义服务"、"定义实现接口"、"识别包"**等落地相关的词汇,一定属于 OOD 活动。选 D。
📌 错题 51:UML 活动图
💡 解析 :只要题干提到"工作流 "、"业务流程 "、"执行步骤的控制流",唯一解就是活动图 (Activity Diagram)。它能极好地展示分支与并行处理。
📌 错题 52:顺序图 (Sequence Diagram) 元素
📝 深度解析
顺序图经典四件套:
- 对象
- 生命线
- 控制焦点 (激活期)
- 消息
"链 (Link)"是对象图和通信图(协作图)里的元素,不在顺序图中出现。选 D。
📌 错题 53:面向对象测试层次
📝 深度解析
- 算法层:测单个方法。
- 类层:测单个类。
- 模板层 (簇层) :测一组协同工作的类之间的相互作用(正对应题干)。
- 系统层:测整体大系统。选 D。
📌 错题 54:继承的本质定义

💡 解析 :继承的本质是代码复用与扩展,即"在已存在的类的基础上创建新类",而不是去修改老类的方法。选 A。
🗄️ 八、数据库技术与基础
📌 错题 55:Armstrong 公理系统
📝 深度解析
Armstrong 三大核心公理:
- 自反律 :若 Y ⊆ X ⊆ U Y \subseteq X \subseteq U Y⊆X⊆U,则 X → Y X \rightarrow Y X→Y。(例如:有了"学号+姓名",当然能推出"学号")。题干描述正符合自反律,选 A。
- 增广律 :若 X → Y X \rightarrow Y X→Y,则 X Z → Y Z XZ \rightarrow YZ XZ→YZ。
- 传递律 :若 X → Y X \rightarrow Y X→Y 且 Y → Z Y \rightarrow Z Y→Z,则 X → Z X \rightarrow Z X→Z。
📌 错题 56:OLAP vs OLTP
💡 解析:
- OLTP (联机事务处理):日常业务,短小频繁,比如超市收银打单。
- OLAP (联机分析处理):针对数据仓库,做宏观统计、多维分析(如按时间、地区分析利润)。题干高管看多维数据,选 B。
📌 错题 57:概念结构设计步骤

💡 解析 :正确逻辑流:抽象数据分类 (②) → \rightarrow → 画各个局部 E-R 图 (①) → \rightarrow → 合并全局 E-R 图消除冲突 (④) → \rightarrow → 重构优化消除冗余 (③)。顺序是 ②①④③,选 D。
📌 错题 58:分布式数据库的透明性
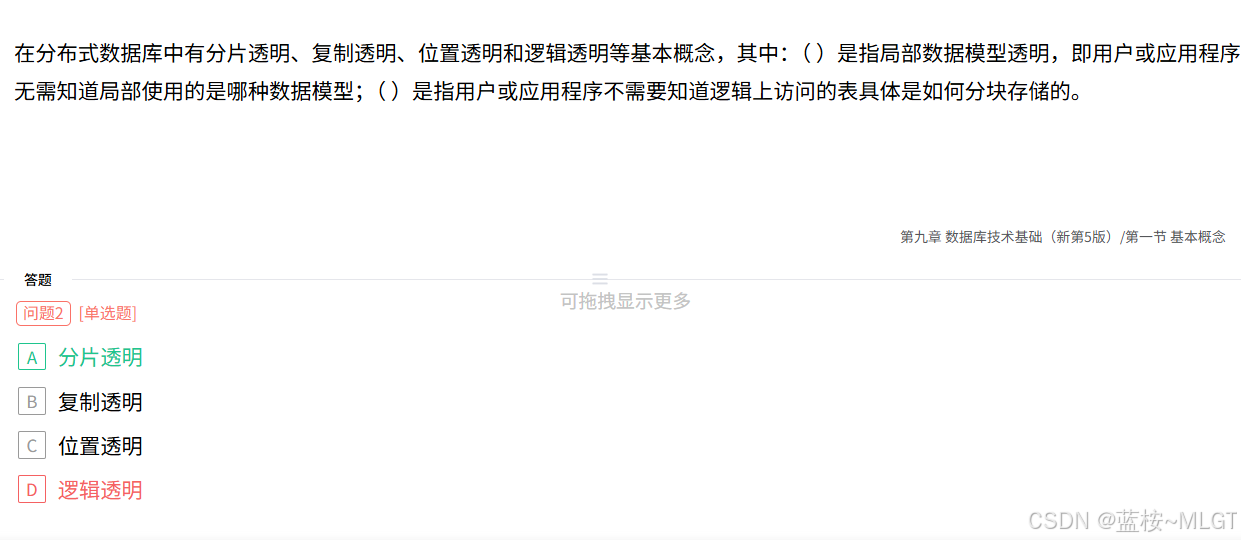
📝 深度解析
- 用户不关心底下跑的是关系库还是层次库:逻辑透明 (局部数据模型透明)。
- 用户不关心表被水平/垂直切成了几块存放:分片透明。
- 用户不关心数据存放在北京还是上海的服务器:位置透明 。
题目第二空问"不需知道表如何分块存储",对应分片透明 (A)。
🧮 九、算法设计、逻辑推导与杂项硬核计算
本章节汇集了历年考试中最容易算错的"硬核数学/数据结构推导题",掌握套路秒杀全场。
📌 错题 59:子网划分数学题(C类网段借位计算)
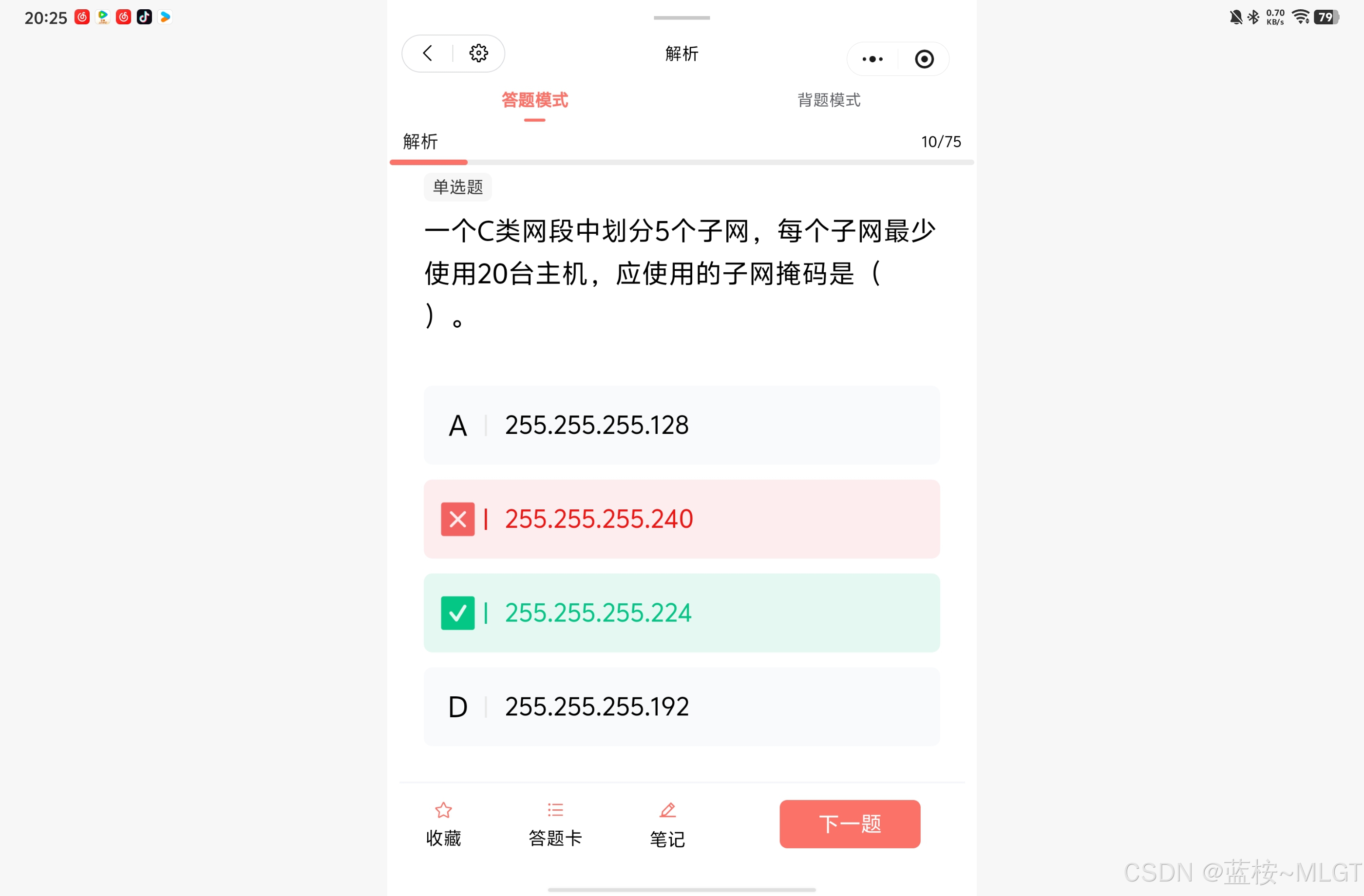
📝 深度解析
条件 :C类网,要分 ≥ 5 \ge 5 ≥5 个子网,每个子网 ≥ 20 \ge 20 ≥20 台主机。
- 满足子网数 :从 8 位主机位借 n n n 位, 2 n ≥ 5 2^n \ge 5 2n≥5。得 n = 3 n=3 n=3(借3位,子网数8个)。
- 验证主机数 :剩余主机位 8 − 3 = 5 8-3=5 8−3=5 位。可用主机 2 5 − 2 = 30 ≥ 20 2^5 - 2 = 30 \ge 20 25−2=30≥20,满足要求。
- 计算掩码 :最后字节的二进制变成
11100000。转换为十进制: 128 + 64 + 32 = 224 128+64+32 = \mathbf{224} 128+64+32=224。
完整的子网掩码为: 255.255.255.224 255.255.255.224 255.255.255.224,选 C。
📌 错题 60:CIDR 子网块包含计算
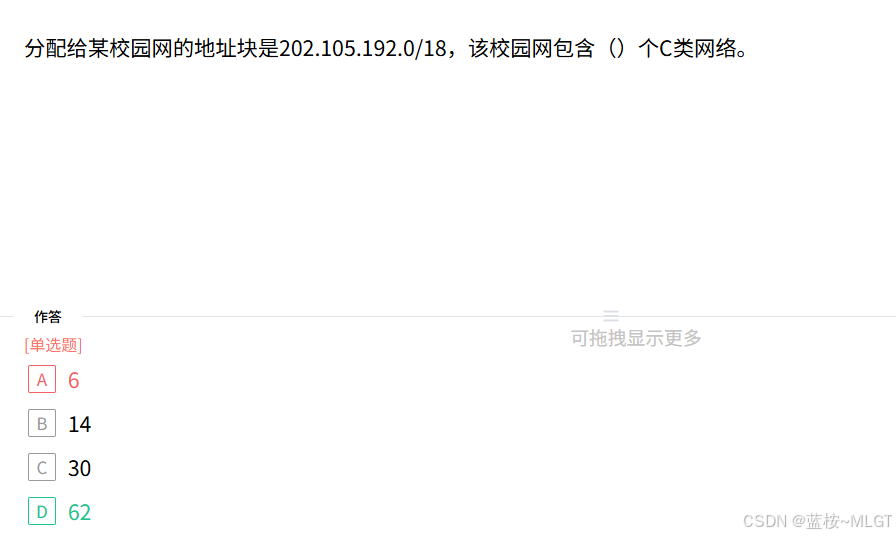
📝 深度解析
问:一个 /18 的大网络包含多少个标准 C 类(/24)网络?
- 位数差: 24 − 18 = 6 24 - 18 = 6 24−18=6 位。
- 理论包含数: 2 6 = 64 2^6 = 64 26=64 个。
- ⚠️ 陷阱 :在部分保守老式考试标准中,去掉全 0 和全 1 的子网,实际可用为 64 − 2 = 62 64 - 2 = \mathbf{62} 64−2=62 个。结合选项,选 D。
📌 错题 61:非平凡子串的数学推导公式
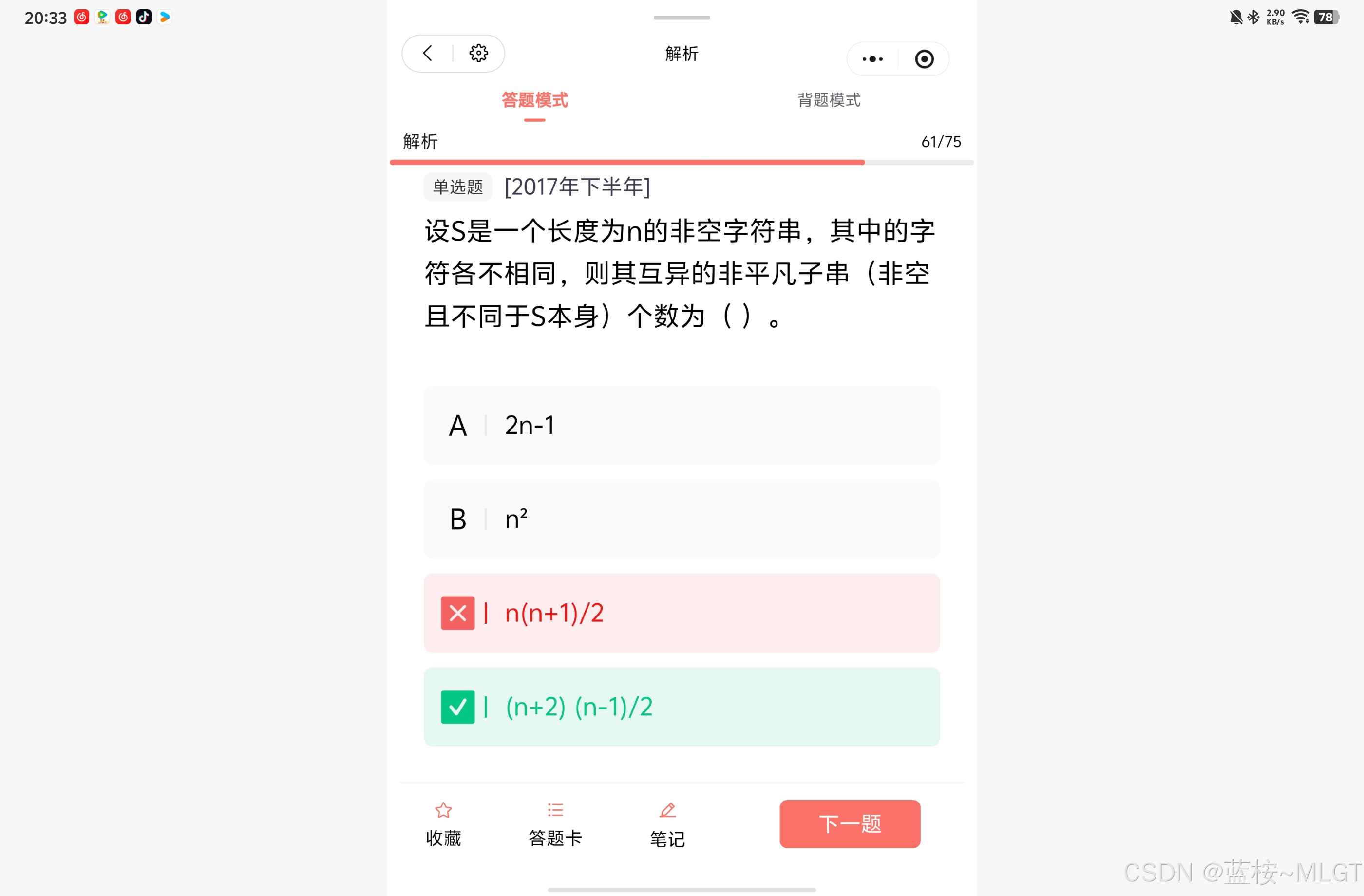
📝 深度解析
字符串 abc 的子串有:a, b, c, ab, bc, abc。
- 所有非空子串总数: n ( n + 1 ) 2 \frac{n(n+1)}{2} 2n(n+1)
- 非平凡子串(Non-trivial) :不能包含空串,且不能是原串本身。必须再减 1。
- 公式化简: n ( n + 1 ) 2 − 1 = n 2 + n − 2 2 = ( n + 2 ) ( n − 1 ) 2 \frac{n(n+1)}{2} - 1 = \frac{n^2 + n - 2}{2} = \mathbf{\frac{(n+2)(n-1)}{2}} 2n(n+1)−1=2n2+n−2=2(n+2)(n−1)。选 D。
📌 错题 62:分页虚拟存储的缺页中断计算

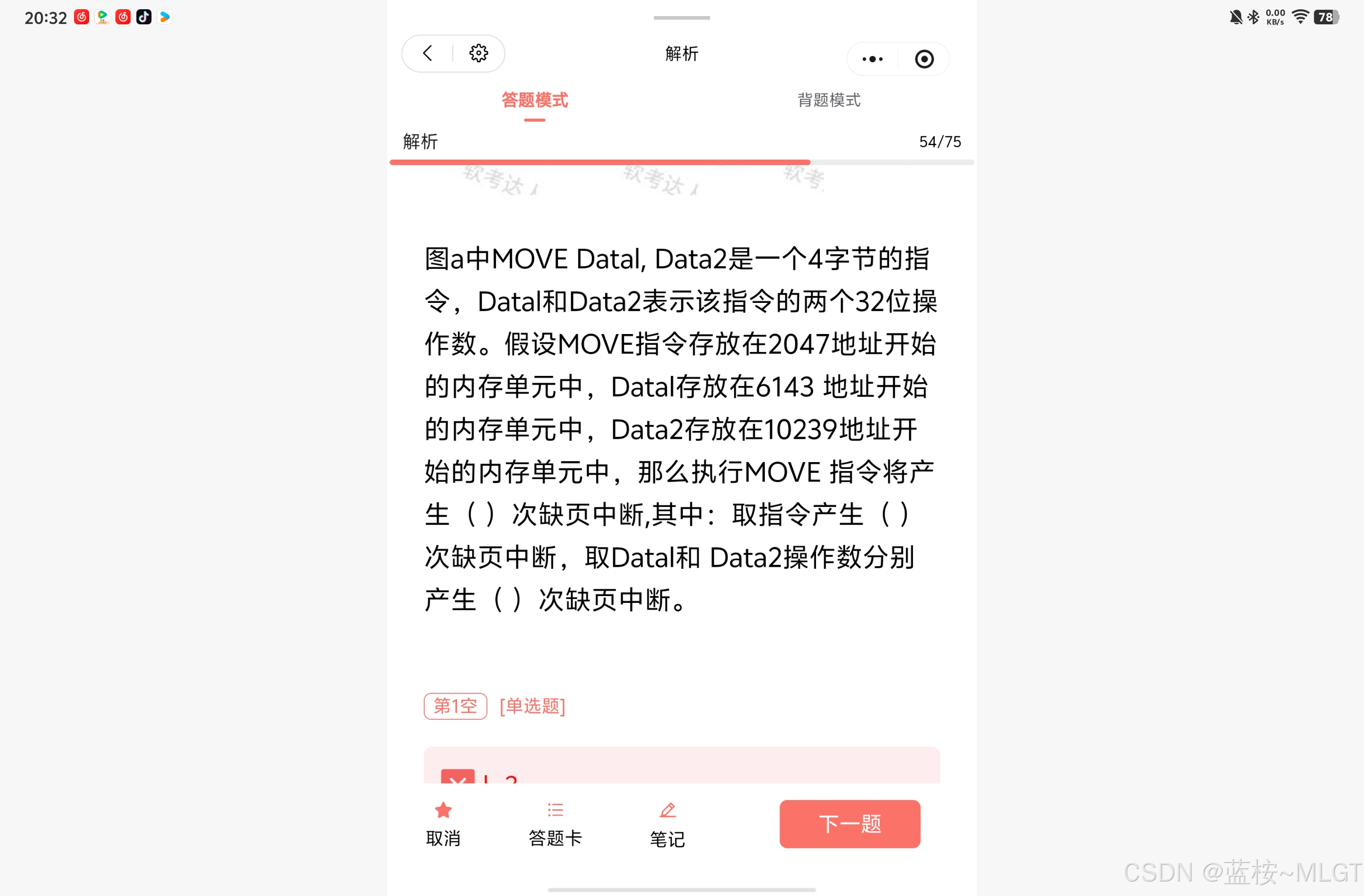
📝 深度解析
内存中目前只有第 0 页 。页面大小 2KB (地址 0~2047 为第 0 页,2048~4095 为第 1 页,以此类推)。
- 取指令 :起始 2047,长 4 字节。横跨了地址 2047(第0页) 和 2048(第1页)。第1页不在内存,发生 1 次缺页。
- 取操作数 1 :起始 6143,长 4 字节。横跨了第 2 页和第 3 页。均不在内存,发生 2 次缺页。
- 写操作数 2 :起始 10239,长 4 字节。横跨了第 4 页和第 5 页。发生 2 次 缺页。
合计产生 5 次缺页中断。
📌 错题 63:文件逻辑记录跨块定位
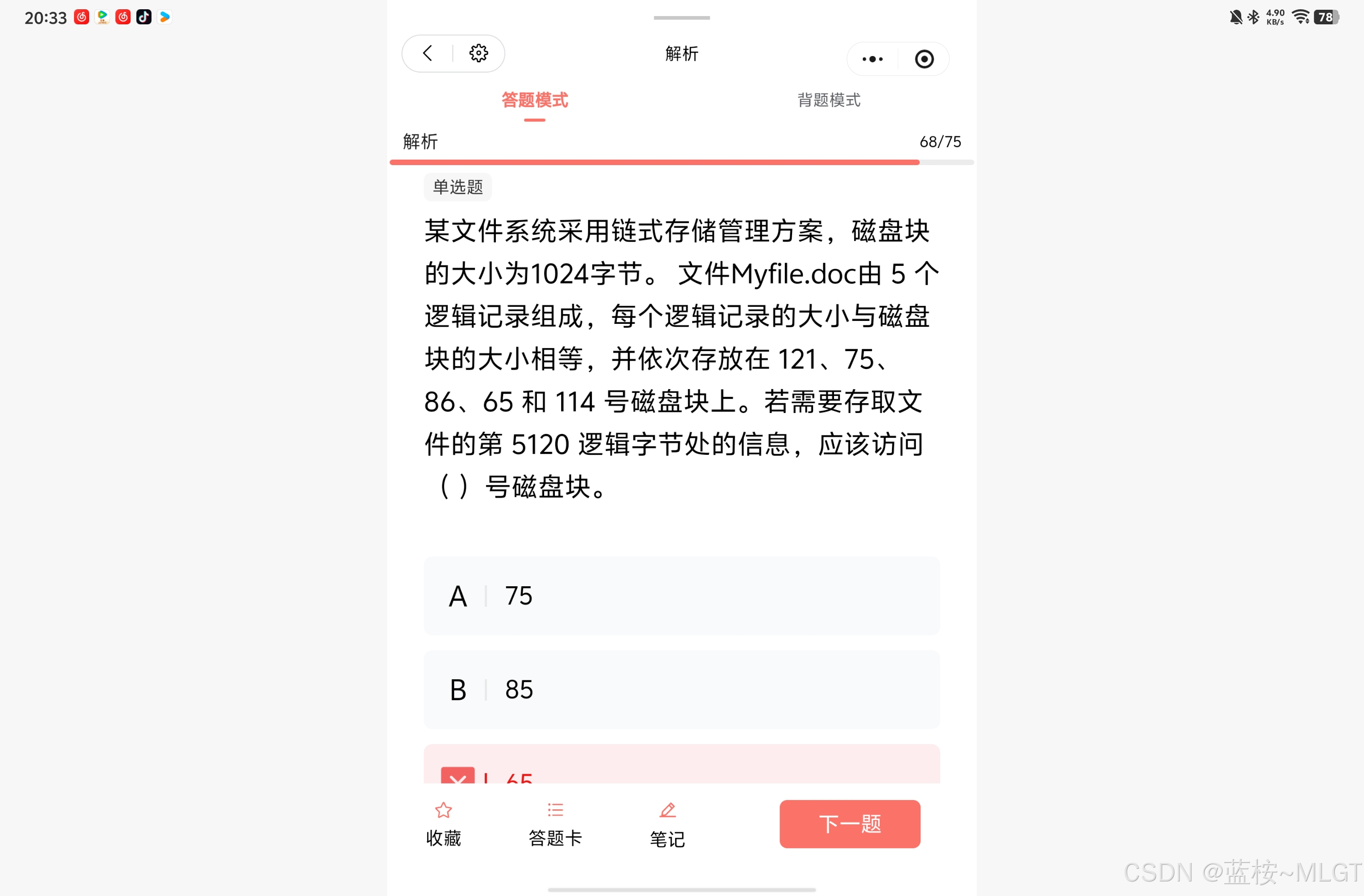
📝 深度解析
- 每块 1024 字节。第 5120 个逻辑字节是第几个块?
- 5120 ÷ 1024 = 5 5120 \div 1024 = 5 5120÷1024=5。说明它是第 5 个逻辑块的末尾字节。
- 查看物理块号顺序图: 121 , 75 , 86 , 65 , 114 121, 75, 86, 65, 114 121,75,86,65,114。第 5 块对应物理盘块 114 114 114。
📌 错题 64:磁盘位图偏移量精算
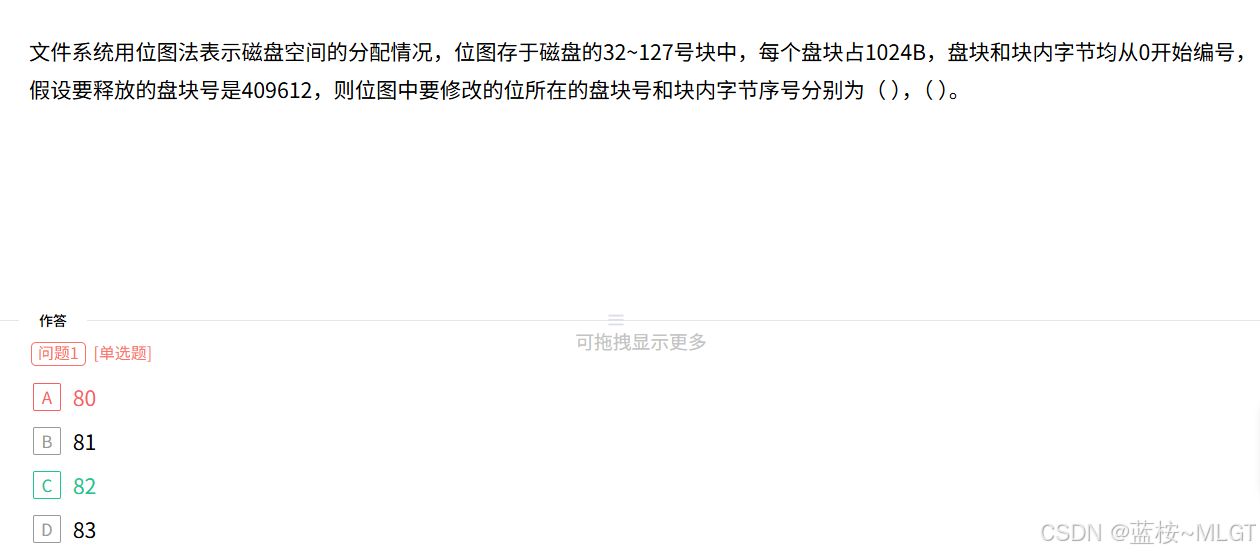
📝 深度解析
位图每一位对应一个盘块。一个物理块能存 1024 × 8 = 8192 1024 \times 8 = \mathbf{8192} 1024×8=8192 个位(即管理 8192 个盘块)。
我们要找第 409612 409612 409612 号块的状态位:
- 偏移块数 : 409612 ÷ 8192 = 50 ... 12 409612 \div 8192 = 50 \dots 12 409612÷8192=50...12。在位图偏移的第 50 块中。
- 物理块号 :起始块号 32 + 50 = 82 32 + 50 = \mathbf{82} 32+50=82。
- 字节序号 :余数 12,说明在该块的第 12 个 bit。字节序号为 ⌊ 12 ÷ 8 ⌋ = 1 \lfloor 12 \div 8 \rfloor = \mathbf{1} ⌊12÷8⌋=1。
📌 错题 65:最小生成树 (MST) 的算法取舍
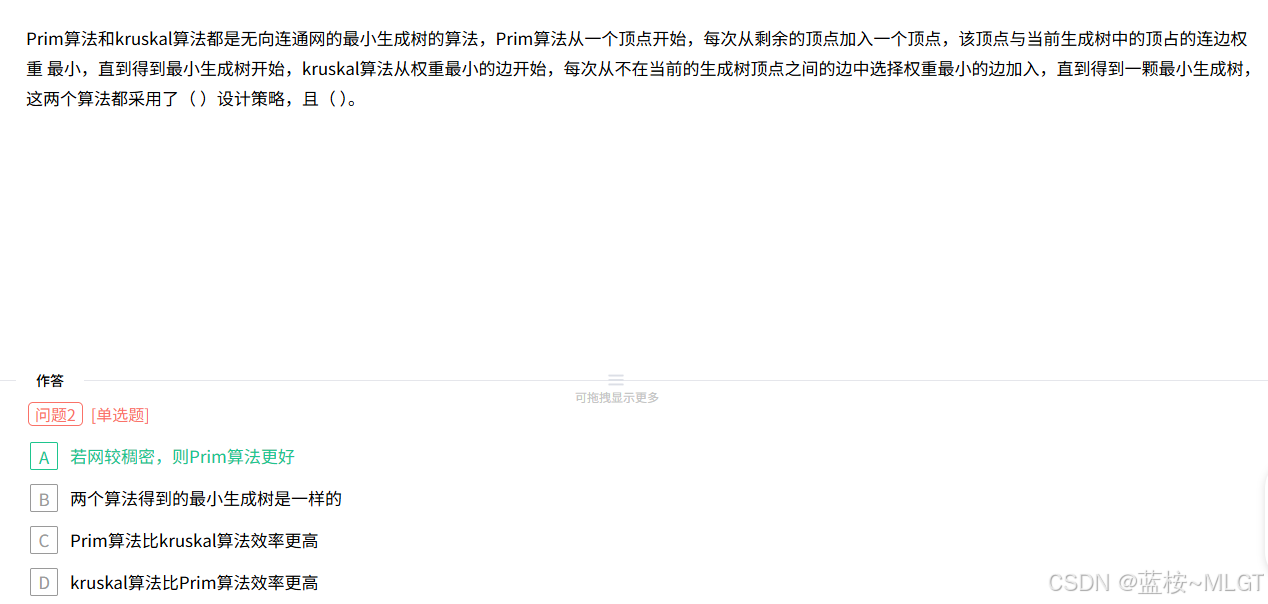
💡 解析:
- Prim (普里姆) 算法 :从"顶点"出发,时间复杂度主要受顶点影响,适合稠密图(边很多的情况)。
- Kruskal (克鲁斯卡尔) 算法 :从"边"出发挑最短,适合稀疏图 。
如果图较稠密,使用 Prim 算法更好。选 A。
📌 错题 66:语义错误识别(除数为0)
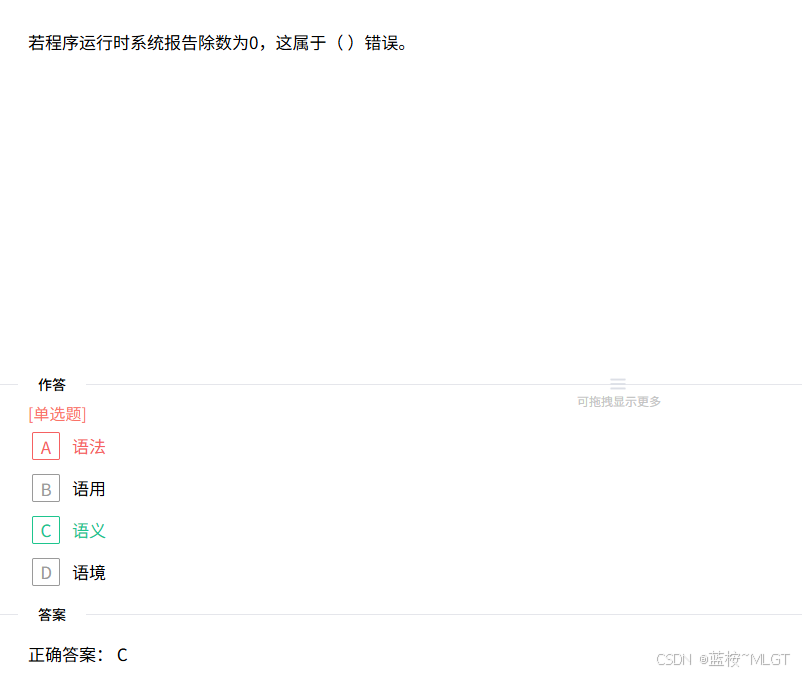
⚠️ 避坑吐槽 :在代码里写
a / b,语法绝对没问题,编译秒过!
- 语法错误:少括号、拼写错,编译直接报错。
- 语义错误 :逻辑或运行期错误。当 b = 0 b=0 b=0 抛出异常,这是由于程序运行到特定状态产生的行为偏差,属于运行期语义错误。选 C。
📌 错题 67:位运算妙用与底层屏蔽

📝 深度解析
想要判断一个数的"低四位"是不是全为 0:
- 提取低四位:使用掩码
0x000F(即二进制0000000000001111)与该数做逻辑与 (&) 操作。高位会全部被强行清零。 - 判断:若
(a & 0x000F) == 0成立,说明保留下来的低四位原本也全都是 0。选 A。
📌 错题 68:RAID 5 阵列的木桶效应

📝 深度解析
RAID 5 的硬盘容量如果不一样大,遵从"木桶效应",按最小的那块硬盘算。
- 已知有 5块 80G 和 2块 60G。基准为 60G。总盘数 N = 7 N=7 N=7。
- RAID 5 可用容量公式: ( N − 1 ) × 单盘容量 = ( 7 − 1 ) × 60 = 360 G (N - 1) \times \text{单盘容量} = (7-1) \times 60 = \mathbf{360G} (N−1)×单盘容量=(7−1)×60=360G。选 C。
📌 错题 69:体系结构名词 VLIW 辨析
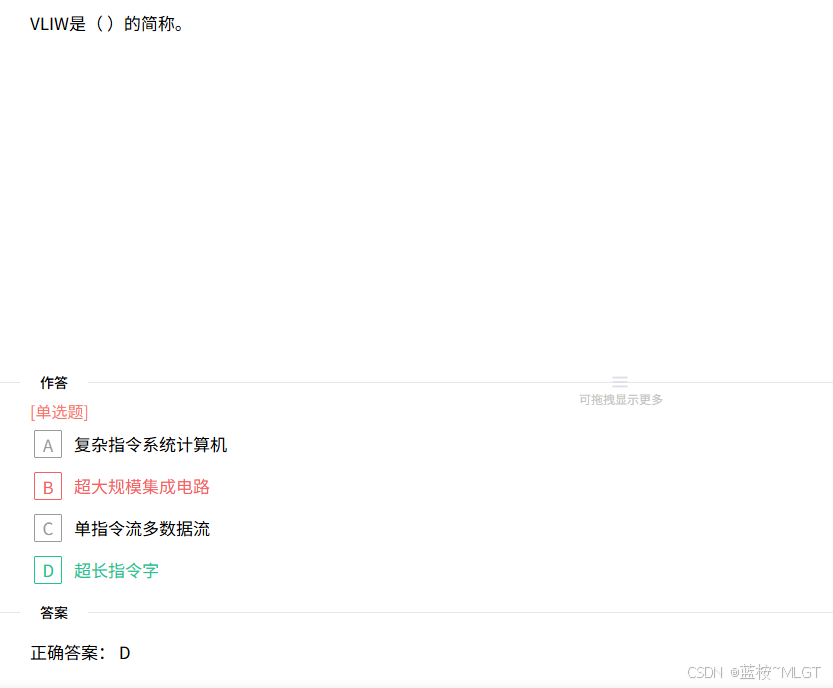
📝 深度解析
- CISC (Complex Instruction Set Computer):复杂指令系统计算机。
- VLSI (Very Large Scale Integration):超大规模集成电路(工艺层面)。
- VLIW (Very Long Instruction Word):超长指令字。靠编译器提前将多条操作打包成长指令以提升并行性。选 D。
📌 错题 70:国标与行标代码(标准化知识)

📝 深度解析
GB:国标。DB:地标。Q:企标。- 只有拼音缩写(如
SJ,JB):行业标准(SJ 是电子行业)。 - 带后缀
/T:推 荐性标准。不带/T的是强制性标准。
题目求"推荐性行业标准",结合规则选 SJ/T (A)。
🌐 十、网络与信息安全基础知识
网络安全部分的考题往往"咬文嚼字",大家在复习时要特别注意区分不同维度的安全防范手段。
📌 错题 1:信息安全等级划分
📝 深度解析
题目给出了四个维度的安全需求,我们逐一对应:
- 物理线路安全:涉及机房、设备(对应 A. 机房安全)。
- 网络安全:涉及传输、边界防护(对应 B. 入侵检测/防火墙)。
- 系统安全 :侧重于操作系统及其运行环境(对应 C. 漏洞补丁管理)。
- 应用安全 :侧重于具体的业务系统、数据库等(对应 D. 数据库安全)。
📌 错题 2:DNS 的查询顺序法则
⚠️ 避坑吐槽 :很多同学一看到 DNS 查询就找
hosts文件,那是你的电脑主机干的事!
📝 深度解析
题目问的是"域名服务器 "接到请求后的处理顺序。作为专门干活的服务端,它为了提高效率,第一步一定是先检查自己的"本地缓存"(选项 C)。如果缓存里没有,才会去查区域文件或向上级转发。
📌 错题 3:网络诊断命令的辨析
📝 深度解析
- nslookup:专门查 DNS 记录,诊断 DNS 最直接的工具。
- ping / tracert:虽然主要测连通性和路由追踪,但在输入域名时,系统第一步必须去解析 DNS。如果解析失败本身就能说明问题,因此也可用于辅助诊断。
- netstat :用于显示活动的 TCP 连接、本地监听的端口等。它不具备查询 DNS 或诊断解析过程的功能 ,正确答案选 A。
📌 错题 4:IPv4 地址分类判定
📝 深度解析
背熟各网络类的首字节范围:
- A类:1 ~ 126
- B类:128 ~ 191
- C类:192 ~ 223
选项中只有202.113.16.8的首段 202 落在 C 类范围内,因此选 B。
📌 错题 5:TCP 与 UDP 应用场景
💡 核心考点:求"稳"(不能丢字漏字)用 TCP;求"快"(不能有高延迟)用 UDP。
📝 深度解析
网页浏览、Telnet、发邮件都要求数据百分百完整,必须用 TCP。而 VoIP(网络电话) 要求通话流畅无延迟,宁可丢一两个包也不能容忍重传带来的卡顿,所以必须使用 UDP(选 C)。
📌 错题 6:ICMP 的协议分层与封装
📝 深度解析
- 第一空 :ICMP 协议与 IP 协议同工作在 网络层。
- 第二空 :ICMP 报文本身不能独立行走,而是作为数据载荷被直接封装在 IP 数据报 中传送的(选 D)。
📜 十一、标准化和软件知识产权基础知识
📌 错题 1:国家/行业标准代号辨析
📝 深度解析
代号命名规则非常死板,按规律套即可:
- GB = 国家标准,DB = 地方标准,Q = 企业标准。
- 字母组合 (如 SJ, JB) = 行业标准(SJ 是电子工业)。
- 带有
/T= 推 荐性标准(T 是"推"的拼音首字母);不带则为强制性。
题目要求找"推荐性行业标准 ",完美对应 SJ/T(选 A)。
🔥 其它(硬核计算与大招集锦)
这一部分汇集了整套错题本中最硬核的计算题和逻辑推断题。强烈建议大家在考前拿草稿纸跟着推导一遍!
📌 错题 1:子网划分与掩码计算
📝 深度解析
目标 :C类网,划分 ≥ 5 \ge 5 ≥5 个子网,每个子网 ≥ 20 \ge 20 ≥20 台主机。
- 借位算子网 :从主机位借 n n n 位。当 n = 3 n=3 n=3 时, 2 3 = 8 ≥ 5 2^3 = 8 \ge 5 23=8≥5(满足)。
- 验证主机数 :剩余主机位 m = 8 − 3 = 5 m = 8-3 = 5 m=8−3=5 位。可用主机 2 5 − 2 = 30 ≥ 20 2^5 - 2 = 30 \ge 20 25−2=30≥20(满足)。
- 算掩码 :前 3 位变网络位(置 1),后 5 位变主机位(置 0)。二进制即
11100000。
转为十进制: 128 + 64 + 32 = 224 128 + 64 + 32 = \mathbf{224} 128+64+32=224。因此子网掩码为 255.255.255.224 255.255.255.224 255.255.255.224(选 C)。
📌 错题 2:分页系统的缺页中断计算
📝 深度解析
页面大小 2 KB 2\text{KB} 2KB,目前只有第 0 页 在内存。操作指令长 4 4 4 字节。
- 取指令 :地址
2047~2050。横跨第 0 页和第 1 页。第 1 页不在内存,产生 1 次缺页。 - 取操作数 1 :地址
6143~6146。横跨第 2 页和第 3 页。均不在内存,产生 2 次缺页。 - 写操作数 2 :地址
10239~10242。横跨第 4 页和第 5 页。均不在内存,产生 2 次缺页。
执行该指令共产生 1 + 2 + 2 = 5 1 + 2 + 2 = \mathbf{5} 1+2+2=5 次缺页中断。
📌 错题 3:非平凡子串的数学推导
⚠️ 避坑吐槽:注意题干中的"非平凡(不同于 S 本身)",别死套常规公式!
📝 深度解析
- 包含自身的非空子串总数公式为: n ( n + 1 ) 2 \frac{n(n+1)}{2} 2n(n+1)
- 非平凡子串 需减去自身: n ( n + 1 ) 2 − 1 \frac{n(n+1)}{2} - 1 2n(n+1)−1
- 因式分解化简: n 2 + n − 2 2 = ( n + 2 ) ( n − 1 ) 2 \frac{n^2 + n - 2}{2} = \mathbf{\frac{(n+2)(n-1)}{2}} 2n2+n−2=2(n+2)(n−1)。选 D。
📌 错题 4:文件逻辑记录到物理块定位
📝 深度解析
每个记录/磁盘块均为 1024 字节。问第 5120 字节在哪一块?
5120 ÷ 1024 = 5 5120 \div 1024 = 5 5120÷1024=5。这说明它是第 5 个逻辑记录 的最后一块。
看题目的物理块顺序表:121, 75, 86, 65, 114。第 5 块对应的是 114 114 114 号。
📌 错题 5:位图偏移量精算
📝 深度解析
一块盘块能装 1024 × 8 = 8192 1024 \times 8 = \mathbf{8192} 1024×8=8192 个位(即管理 8192 个盘块)。
问 409612 号块在位图哪一块?
- 相对块号 : 409612 ÷ 8192 = 50 ... 12 409612 \div 8192 = 50 \dots 12 409612÷8192=50...12。在位图偏移的第 50 块中。
- 物理盘块号 :起始位 32 + 50 = 82 32 + 50 = \mathbf{82} 32+50=82。
- 字节序号 :在第 12 个 bit,即 ⌊ 12 ÷ 8 ⌋ = 1 \lfloor 12 \div 8 \rfloor = \mathbf{1} ⌊12÷8⌋=1(第 1 字节)。
📌 错题 6:DNS IPv6 记录名称
💡 解析 :IPv6 地址的长度是 IPv4 的 4 倍,所以记录名称用了 4 个 A,即 AAAA 记录(选 D)。
📌 错题 7:WLAN 无线网络标准
💡 解析 :无线局域网 (WLAN) 主要采用的是 IEEE 802.11 系列标准。
📌 错题 8:CIDR 包含的子网数计算
📝 深度解析
/18 的大网里能装多少个标准 C 类(/24)?
位数差为 24 − 18 = 6 24 - 18 = 6 24−18=6 位,子网数 = 2 6 = 64 2^6 = 64 26=64。
根据很多考试的保守计算法,去掉全 0 和全 1 的保留位,实际为 64 − 2 = 62 64 - 2 = \mathbf{62} 64−2=62 个(选 D)。
📌 错题 9:软件设计核心活动
💡 解析 :软件设计的四大过程为:数据设计、体系结构设计(选 C)、接口设计、过程设计。
📌 错题 10:软件开发方法论大杂烩
📝 深度解析
- 把系统功能视作整体再往下分解的,叫结构化方法。
- 主张开发是螺旋上升、并切分宏观微观的是 Booch 方法。
- Booch 的动态模型包含状态图和交互图。
📌 错题 11:语义错误(除数为0)
📝 深度解析
a / b 这种写法是完全符合语法规则的,编译器不会报错。但运行中遇到 b = 0 b=0 b=0 时产生的系统级崩溃,属于典型的运行期语义错误(选 C)。
📌 错题 12:RAID 5 容量计算(木桶效应)
📝 深度解析
RAID 5 的基准必须是最小的那块硬盘 (60G)。
共有 7 块盘,容量公式为 ( N − 1 ) × 单盘容量 (N-1) \times \text{单盘容量} (N−1)×单盘容量。
计算: ( 7 − 1 ) × 60 G = 360 G (7-1) \times 60G = \mathbf{360G} (7−1)×60G=360G(选 C)。
📌 错题 13:位运算掩码技巧
📝 深度解析
要想单独拿"低四位"出来做判断,需要用到逻辑与(&)。掩码 0x000F 可以将高 12 位强制清零,仅保留低四位。如果结果 == 0,说明原数的低四位确实全为 0(选 A)。
📌 错题 14:最小生成树 (MST) 的算法比较
💡 核心考点 :
稠密图(边多):用 Prim (按点计算,不受边多影响)。
稀疏图(边少):用 Kruskal(按边算,边少效率高)。选 A。
📌 错题 15:水晶法 (Crystal)
💡 解析 :看到"项目独特"、"不同项目用不同策略/颜色"、"量身定制",这指的就是敏捷开发里的水晶法。
📌 错题 16:自底向上集成测试
📝 深度解析
自底向上就是从叶子节点往上测。它的最大好处是,由于依赖的下层全是写好的真代码,所以不需要编写假装下层响应的"桩程序"(Stub)。但需要编写充当上层调用者的"驱动程序"(Driver)。(选 C)
📌 错题 17:超长指令字 (VLIW)
💡 解析 :
VLIW = V ery L ong I nstruction W ord(超长指令字),一种由编译器做主来榨干指令级并行的体系结构。不要和形容晶体管密度的 VLSI 搞混哦!
📌 错题 18:海明码校验位
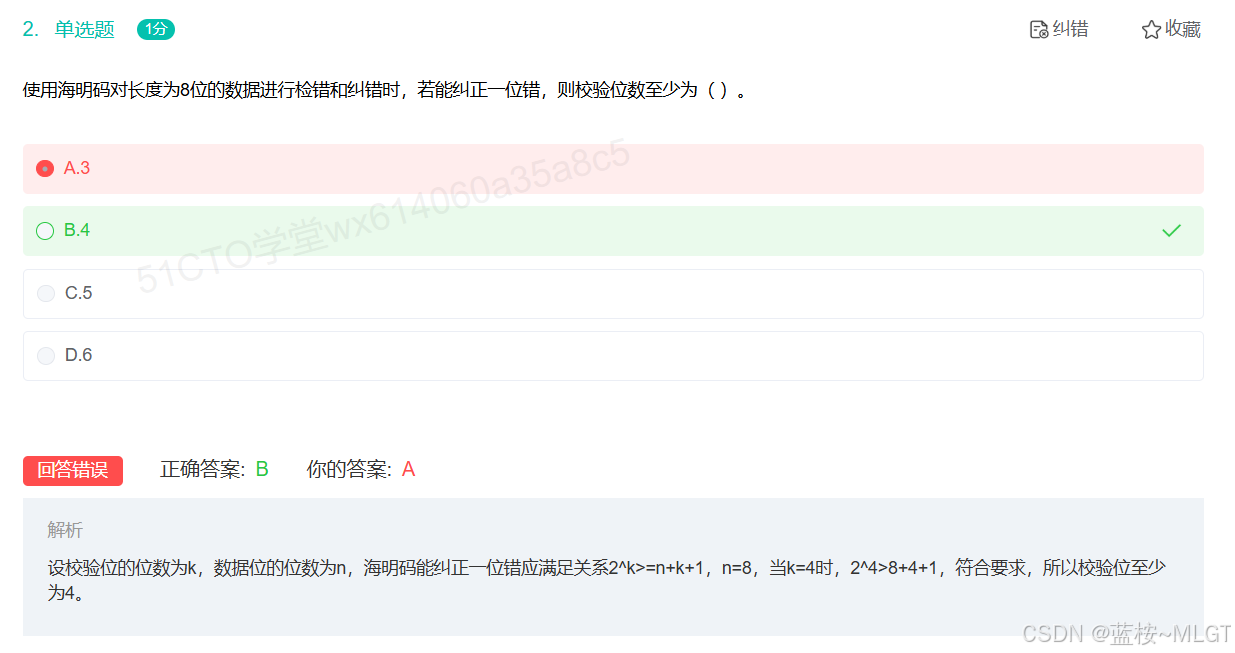
补充一下,可以不记公式,背下来8位就是4个校验位,16位就是5个校验位,32位则是6个。
📌 错题 19:字号和位号的计算
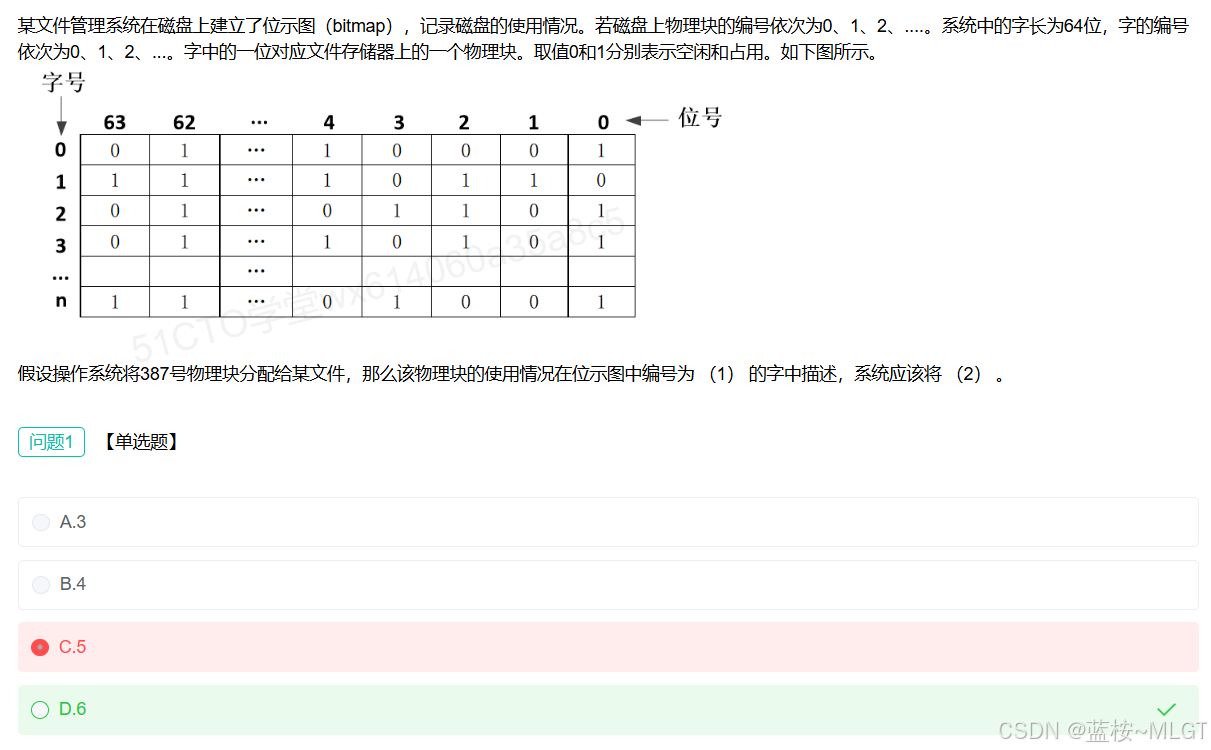
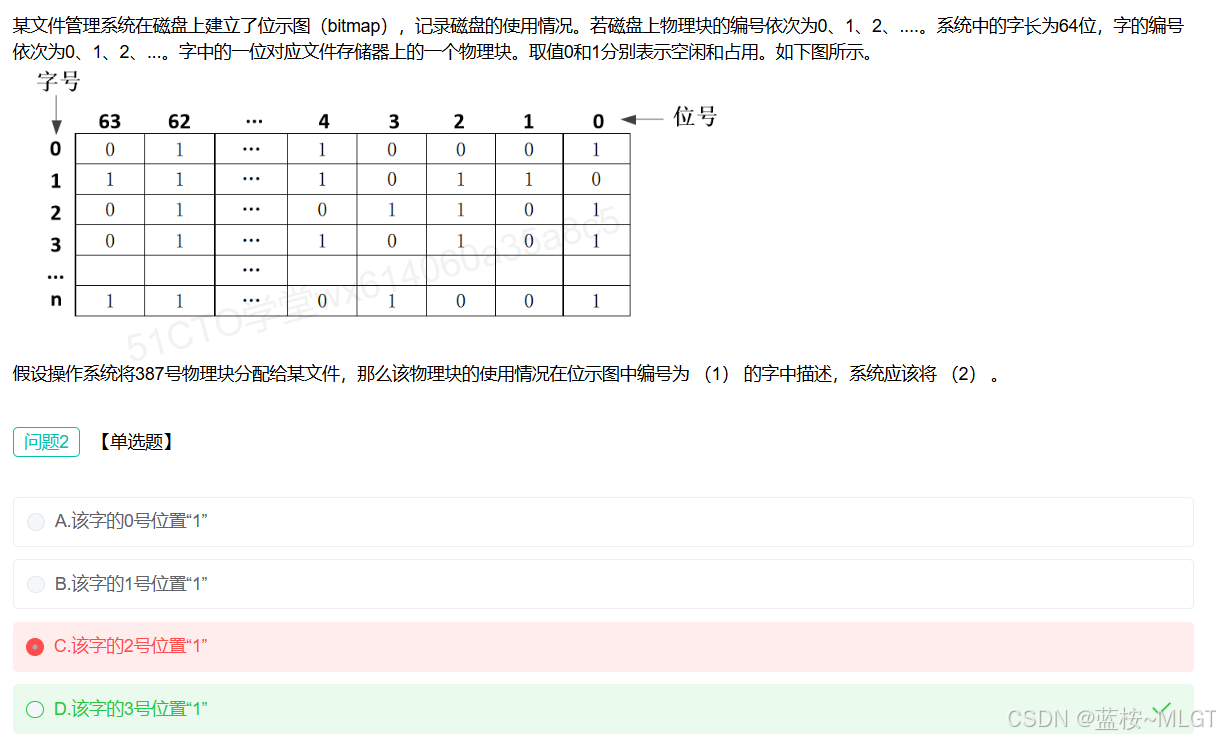
深度解析
1. 核心计算公式(前提:字长 W = 64 W=64 W=64,编号从0开始)
题目给出的是物理块编号 387 ,字长是 64位
- 字号 (Word Number) = ⌊ 物理块号 ÷ 字长 ⌋ = ⌊ 387 ÷ 64 ⌋ = 6 \lfloor 物理块号 \div 字长 \rfloor = \lfloor 387 \div 64 \rfloor = 6 ⌊物理块号÷字长⌋=⌊387÷64⌋=6
- 位号 (Bit Number) = 物理块号 ( m o d 字长 ) = 387 ( m o d 64 ) = 3 物理块号 \pmod{字长} = 387 \pmod{64} = 3 物理块号(mod字长)=387(mod64)=3
2. 为什么不用"减1"?(最关键的逻辑)
这通常发生在 "第N个"转换为"编号 的时候。但本题给出的已经是 编号了。
我们可以用小规模数据 做个简单的推演,逻辑就清晰了:
假设字长只有 4位(位号0, 1, 2, 3),物理块编号也是从0开始。
- 物理块0号: 0 ÷ 4 = 0 0 \div 4 = 0 0÷4=0 余 0 0 0 → \rightarrow → 字号0,位号0(正确)
- 物理块1号: 1 ÷ 4 = 0 1 \div 4 = 0 1÷4=0 余 1 1 1 → \rightarrow → 字号0,位号1(正确)
- 物理块4号(这是第5块): 4 ÷ 4 = 1 4 \div 4 = 1 4÷4=1 余 0 0 0 → \rightarrow → 字号1,位号0(正确)
发现规律了吗?
- 当你直接用从0开始的编号 去除以字长时,得到的商直接就是字号(索引),余数直接就是位号(索引)。
- 如果你"减了1":
- 块0变成 − 1 -1 −1,计算就出错了。
- 块4变成 3 3 3, 3 ÷ 4 = 0 3 \div 4 = 0 3÷4=0 余 3 3 3,你会算出它在"字号0,位号3",但这显然不对,因为块4应该是第二个字的开头。
3. 什么时候需要"减1"?
只有当题目说第387块物理块 (即从1开始数数)时,为了转换成计算机识别的0轴坐标,才需要先做 387 − 1 = 386 387 - 1 = 386 387−1=386 的操作,然后再进行计算。
但本题明确说了:"编号依次为0、1、2..." 并且问的是 "387号物理块",这意味着 387 已经是一个索引坐标了,直接套用公式即可。
4. 关于"商为6"的物理意义
- 商为 6,意味着在 387 号块之前,已经完整填满了 6 个字(即字号为 0, 1, 2, 3, 4, 5 的这六个字)。
- 既然已经填满了 6 个字,那么 387 号块自然就落在了接下来的那一个字 里,而这个字的编号正是 6。
- 同理,余数为 3,意味着在当前这个字(字号6)里,前面已经有了 3 位(0, 1, 2),所以它落在第 4 位 上,而其编号正是 3。
总结
在位示图题目中:
- 看清字长: 本题是 64 位。
- 看清起始: 编号从 0 开始。
- 直接除余: 只要是从 0 开始的编号,商 = 字号,余数 = 位号。不需要任何加减 1 的操作。
所以这道题:
- 问题1选 D (6)
- 问题2选 D (该字的3号位置"1") ------ 因为分配给文件,所以值要改为"1"表示占用。

注意了,这道题目啊还是和上面一样,,计算方式都是100 % 32 = 3 ... 4,我这里减去1多此一举了。
📌 错题 20:文件最大长度计算
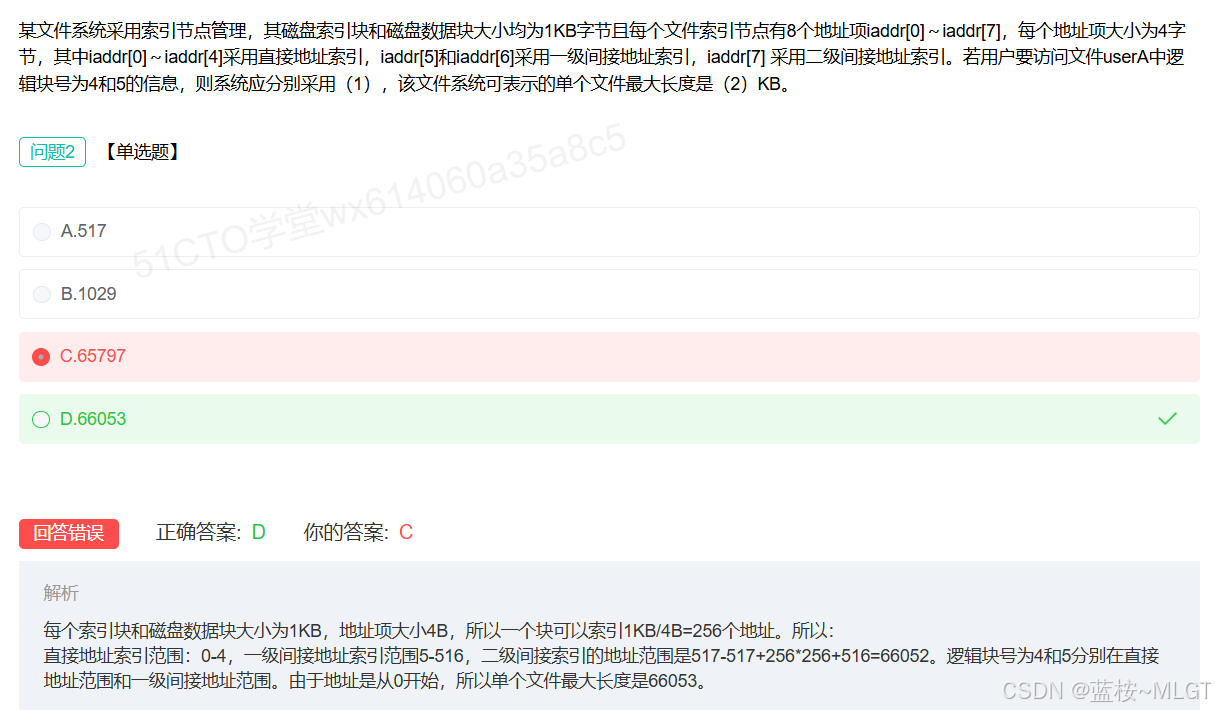
这道题计算失误的核心原因是题目审题不清楚,一级索引占位是2位,所以256要乘以2,这是非常大的陷阱啊。
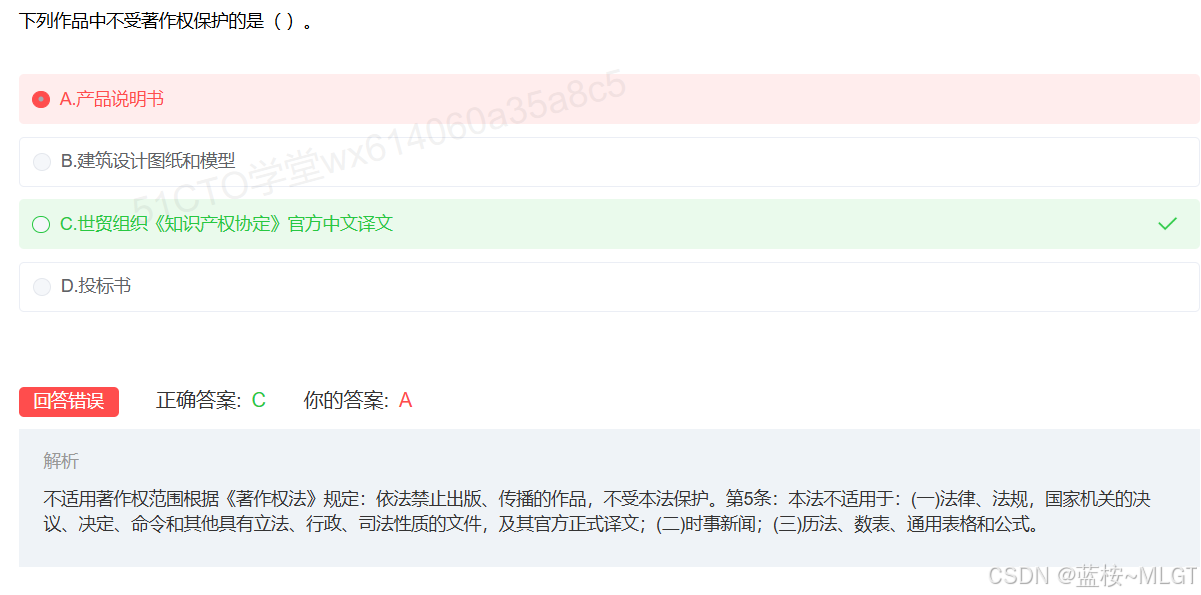
📌 错题 21:著作权
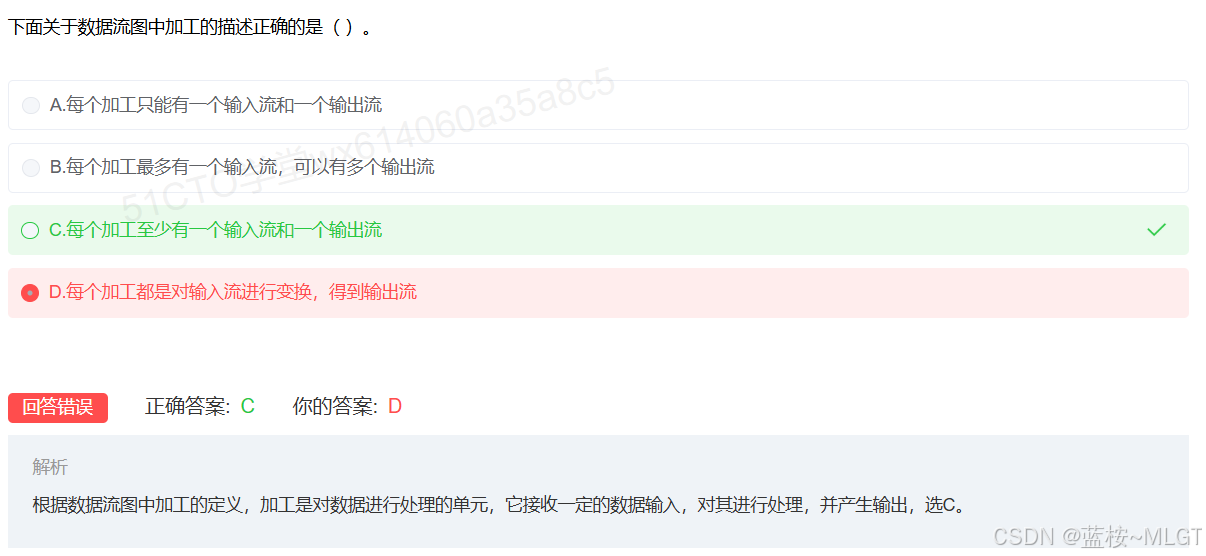
📌 错题 22:数据流加工
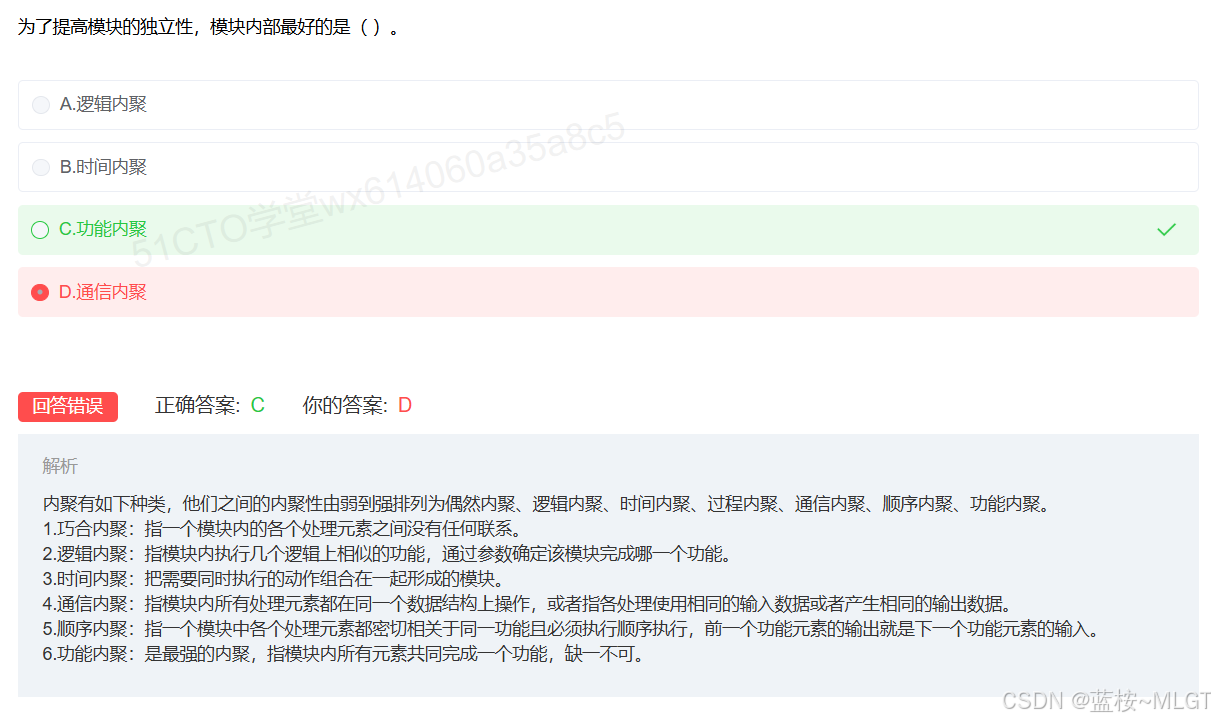
📌 错题 23:模块独立性(内聚类型)
📌 错题 24:结构图层数
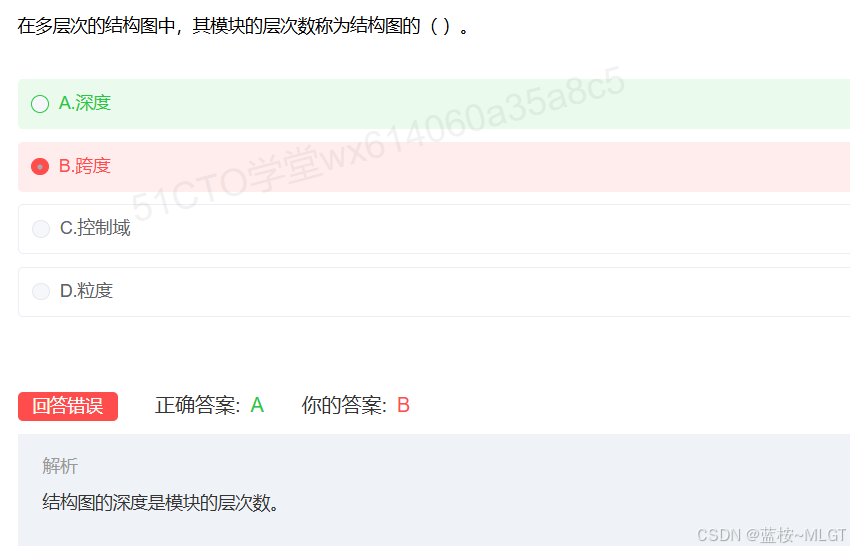
📌 错题 25:链表
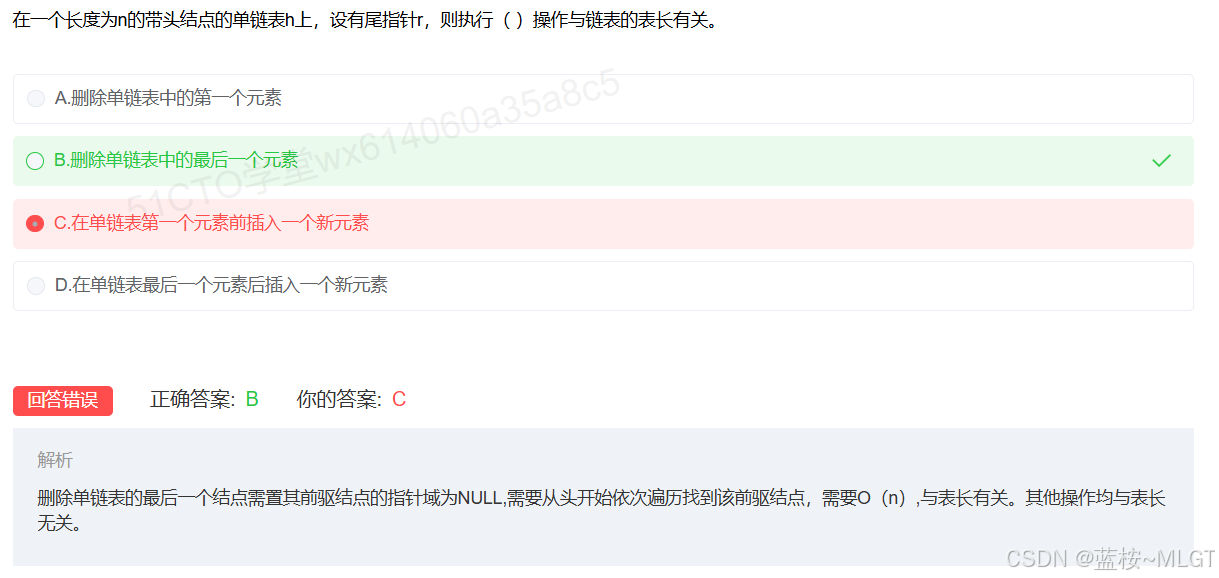
📌 错题 26:IP地址计算
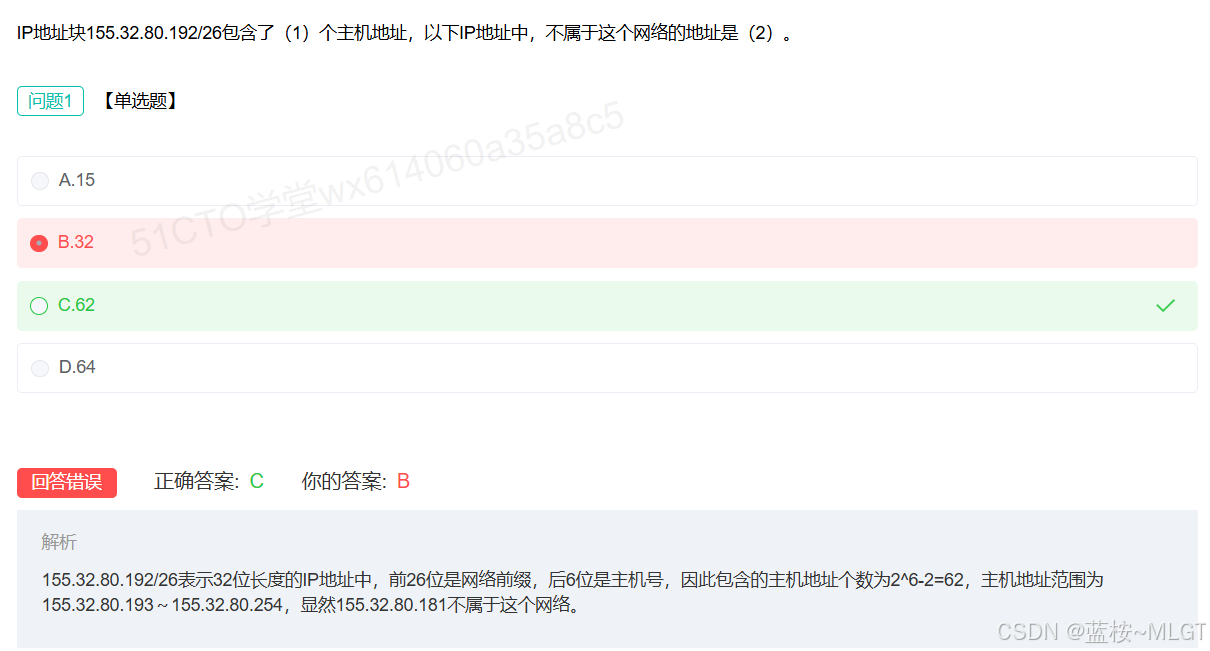

这里要注意,32是IPV4的长度,用它来减去网络前缀26就是主机位数。
🚀 结语
到此为止,软件设计师高频错题盘点就全部结束了!
从底层硬件到操作系统计算,从数据结构算法推导到网络安全体系架构,这一份超过 70 道题目的硬核解析,希望能帮你补齐所有的知识短板。
做错题不可怕,找到套路、理解原理,才能在考场上从容应对出题人的变招。
建议大家在考前几天,将本博客上下两篇加入收藏夹反复阅读,尤其是那些公式推导题(子网划分、缺页中断、寻址计算),考场上遇到就是送分!
如果这篇心血之作对你的复习有启发,别忘了点赞、收藏支持一波!祝大家逢考必过,旗开得胜!🎉