一.哈希表是什么
哈希表是一种通过哈希函数将键值(key)映射到数组索引,从而实现平均时间O(1)时间复杂度的插入,查找,删除操作的数据结构
核心原理
哈希表本质是数组+哈希函数+冲突解决机制的组合:
1.底层数组:存储数据的"桶"(bucket),每个桶可存一个或者多个键值
2.哈希函数:index = hash(key)%capacity,把任意key转化为数组下标 p:hash("张三") = 123,数组长度为8->123%8 = 3,存入下标3
3.哈希冲突:不同key算出同一个index
工作流程
cpp
输入键(Key)
↓
哈希函数(Hash Function)
↓
哈希值(Hash Code)
↓
数组索引(Index)
↓
访问数组对应位置二.哈希函数
定义:把任意长度,任意类型的输入key(数字,字符串,对象)映射成固定范围整的
hash(key)->整数下标
特性:
1.确定性:同一个key每次哈希结果一致
2.散列均匀:结果尽量分散,减少扎堆(降低哈希冲突)
3.计算高效:算法简单,直接
操作步骤
哈希化
哈希化就是将任意类型的输入,通过某种算法转换成固定长度输出(通常是一个整数)的函数,这个整数就是输入的哈希值。
我们这里介绍一下**BKDR算法,**该算法是将字符串转化为整数
cpp
size_t hash = 0;
for (auto& ch : str) {
hash *= 131;
hash += ch;
}
return hash;每次加字符串的 ASCII 前,该值先乘上 131
映射
获取哈希值后,我们就需要将该值映射到我们的指定区间的某个位置上,一般采取的运算就是取模运算(模的大小就是哈希表的大小,这样才能让表的每一个位置被映射到)。
三.哈希冲突
当两个不同的键经过哈希函数计算后得到相同的索引时,就发生了哈希冲突。这是哈希表设计中的核心问题。
cpp
abandon 和 apple的首字母都是a,在基本算法下造成索引相同
hash("abandon") = a%10 = 7;
hash("apple") = a%10 = 7;解决方法
开放定址法
当冲突发生时,在哈希表中寻找 **下一个空位置,**知道找到空位并存入
我们初始化一个大小为7的数组,在数组中我们存入16,23,43
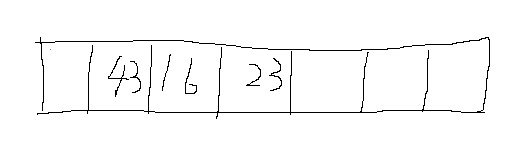
我们算出16,23对7进行mod操作之后,余数都为2,因为16已经占据了索引为2的数组空间,所以23就放在索引为3的位置,简单来讲就是 我的位置没了,我就需要去抢别人的位置
cpp
// 线性探测:依次检查下一个位置
public int linearProbe(int index, int attempt, int capacity) {
return (index + attempt) % capacity;
}
// 示例:插入键"apple"和"avocado"(哈希值都是7)
// table[7] = "apple"
// table[8] = "avocado"(因为7被占用,检查下一个位置8)链地址法
每个数组位置不直接存储元素,而是存储一个链表(或其他数据结构),所有哈希到同一位置的元素都放在这个链表中。
cpp
//链地址法
class HashMap<k, v> {
class Node<k, v> {
k _key;
v _value;
Node<k, v> next;
Node(k key v value)
{
this _key = key;
this _value = value;
}
};
private Node<k, v>[]table;
private int capacity;
//插入元素
public void insert(k key, v value) {
int index = hash(key) % capacity;
Node<k, v> newNode = new Node<>(key, value);
if (table[index] == nullptr) {
table[index] = newNode;//第一个节点
}
else
{
//头插
newNode->next = table[index];
table[index] = newNode;
}
}
//查找元素
public v find(k key)
{
int index = hash(key) % capacity;
Node<k, v> cur = table[index];
while (cur != nullptr)
{
if(cur.key == key)
{
return cur.value;
}
else
{
cur = cur->next;
}
}
return nullptr;
}
};四.负载因子
1.负载因子越大,发生哈希冲突的概率越大,数组长度就会偏小,但节省空间
2.负载因子越小,发生哈希冲突的概率越小,数组长度就会偏大,但浪费空间
3.当元素个数/负载因子>=数组长度 ,此时我们认为冲突比较严重 ,需要进行扩容,即假设此时HashMap的哈希表长度为16,当元素个数超过12就会发生扩容。(0.75)
五.哈希表实现
cpp
class MyHashMap {
private:
//节点结构
struct Node {
int key;
int value;
Node* next;
Node(int k ,int v,Node*n)
:key(k)
,value(v)
,next(n)
{ }
};
//当前哈希表中时机存储元素个数
int size;
//默认哈希表长度
static const int DEFAULT_CAPACITY = 16;
//默认负载因子
static constexpr double LOAD_FACTOR = 0.75;
//MOD
int M;
//存储数据的数组
Node** data;
//哈希函数
int hash(int key)
{
return abs(key) % M;
}
public:
MyHashMap()
:MyHashMap(DEFAULT_CAPACITY)
{ }
MyHashMap(int intiCapacity)
:size(0)
, M(initCapacity)
{
//创建Node*数组,初始化为nullptr
data = new Node * [initCapacity]();
}
~MyHashMap()
{
for (int i = 0; i < M; ++i)
{
Node* cur = data[i];
while (cur)
{
Node* next = cur->next;
delete cur;
cur = next;
}
}
delete[] data;
}
/**
* 添加/更新键值对
* @return 旧值(存在则返回,不存在返回新值)
*/
int add(int key, int value)
{
//1.计算索引
int index = hash(key);
//2.遍历链表,查看key是否存在
for (Node* x = data[index]; x != nullptr; x = x->next)
{
if (x->key == key)
{
//key存在,更新value
int OldValue = x->value;
x->value = value;
return OldValue;
}
}
//3.key不存在,头插法插入新节点
Node* node = new Node(key, value, data[index]);
data[index] = node;
size++;
//4.判断是否需要扩容
if ((double(size) / data.length >= LOAD_FACTOR))
{
//扩容 resize()
}
return value;
}
};我们主要来实现 扩容操作
cpp
//扩容
void resize()
{
//1.新容量为原来的2倍
int newM = M * 2;
Node** newData = new Node * [newM]();
//2.遍历原哈希表的每个桶
for (int i = 0; i < M; i++)
{
Node* cur = data[i];
while (cur)
{
//记录下一个节点位置
Node* next = cur->next;
//3.计算在新表中的下标
int newIdx = abs(cur->key) % newM;
//头插法放入新桶
cur->next = newData[newIdx];
newData[newIdx] = cur;
cur = next;
}
//4.释放原数组
delete[] data;
//5.替换为新表
data = newData;
M = newM;
}
}六.其余类型的哈希
在上述代码中,我们只是实现了整型的哈希,如果是其他类型,我们需要如何操作呢???
要是浮点型或者char类型,还比较好处理
比如string,或者其它的自定义类型
字符型 浮点型
仿函数
如果是对于double,char这些能够隐式类型转换为整型的,那我们的仿函数这样写就行了
cpptemplate<class K> struct keyToInt { size_t operator()(const K& key) { return key; } }; template<class K,class V,class keyToInt> class HashTable { typedef HashNode<K, V>Node; public: ------------------------------------------ };
如果是string类型的话,可以用我上面提到过的BKDR算法来操作,在每个字母挂入哈希表之前,先*131;
七.尾声
本文仅为个人的一些理解,尚有许多并未完满的方面,共勉