在运维与云原生架构中,监控被称作运维的第三只眼 ,是保障业务稳定、故障快速定位、容量规划、SRE 运维落地的核心基石。随着微服务、容器化、云原生技术普及,传统监控已无法满足分布式复杂架构需求,可观测性与 Prometheus 时序监控体系成为行业标配。
本文从零梳理监控基础概念、SRE 三大指标 SLI/SLO/SLA、主流监控方法论,同时详解 Prometheus 架构、组件、时序数据库原理、二进制部署、Systemd 服务配置及核心配置文件解析,适合运维入门、云原生初学者学习收藏。
一、监控的基本概念与方法论
1.1 为什么要做监控
监控俗称运维的第三只眼,没有监控的运维如同 "瞎子",基础运维、业务运维都无从谈起。
在 DevOps 普及的当下,监控数据是运维工作的核心依据:
- 以数据说话,规避运维被动背锅;
- 提前预知系统隐患,实现故障事前预警;
- 支撑容量规划、性能调优、业务扩缩容决策;
- 标准化构建监控体系,是运维工程师必备核心能力。
1.2 SRE 核心:SLI、SLO、SLA 三者区别与详解
SRE 核心职责:服务可用性优化、延迟与性能优化、效率提升、变更管理、故障应急、容量规划,核心目标是提升服务整体质量,而 SLI、SLO、SLA 就是定义服务质量的三大核心标准。
1.2.1 SLI 服务水平指标
SLI(Service Level Indicator):服务质量度量指标,用来定义服务好坏的评判标准,是业务最核心的监控指标。
常见维度:延迟、可用性、吞吐率、请求成功率。示例:
- TCP 请求延迟小于 200ms;
- Pod 资源 1 分钟内完成交付。
SLI 制定需关注 5 个要点:
- 明确要测量的核心指标;
- 确定测量时的系统运行状态;
- 定义指标数据的聚合汇总方式;
- 指标能否真实反映服务质量;
- 测量数据的可靠性与可信度。
1.2.2 SLO 服务水平目标
SLO(Service Level Object) :基于 SLI 设定的服务达标目标,指一段时间内 SLI 指标达标的比例。
- 通常为百分比,必须绑定时间范围(月 / 季 / 年),脱离时间无意义;
- 行业常用多个 9来衡量服务可用率。
表格
| 可用率 | 可用 9 位数 | 30 天允许停机时长 |
|---|---|---|
| 90% | 1 个 9 | 3 天 |
| 99% | 2 个 9 | 7.2 小时 |
| 99.9% | 3 个 9 | 43.2 分钟 |
| 99.95% | 3.5 个 9 | 21.6 分钟 |
| 99.99% | 4 个 9 | 4.32 分钟 |
| 99.999% | 5 个 9 | 26 秒 |
示例:每月 99.99% 的 TCP 请求延迟(SLI)小于 200ms。
1.2.3 SLA 服务水平协议
SLA(Service Level Agreement) :具备法律效力的商业协议,约定未达成 SLO 目标时的赔付规则。
- 多用于云厂商与企业客户之间(如阿里云与用户);
- 简易区分:SLO 不达标有无明确赔付后果,有则是 SLA,无则仅为 SLO。
1.2.4 应用实例
网站业务周期:3 月 1 日~5 月 18 日
-
3 月:总请求 500,错误 20
-
4 月:总请求 600,错误 10,故障宕机 10 分钟
-
5.1-5.18:总请求 400,错误 15
-
SLI 请求成功率 :
1 - (20+10+15)/(500+600+400) = 97% -
SLO 可用率 :基于 79 天宕机 10 分钟计算可得约
99.991% -
SLA:若签订商业协议,未达到约定 99.999% 可用率,则按合同执行赔付。
1.3 主流监控方法论
业界三大经典监控方法论:Google 四大黄金指标、RED 方法、USE 方法。
1.3.1 Google 四大黄金指标
面向服务层面监控,核心 4 项:延迟、流量、错误、饱和度。
- 延迟:服务请求耗时,区分成功请求与失败请求延迟,延迟过高代表性能差、用户体验差;
- 流量:系统负载量级,Web 用 QPS/TPS、RPC 用调用量、数据库用事务量;
- 错误:分显式错误(500/404 状态码)、隐式错误(返回 200 但业务数据异常);
- 饱和度:资源占用饱和程度,如磁盘 IO、CPU 使用率,饱和过高会引发性能瓶颈。
1.3.2 RED 方法
基于 Google 黄金指标简化,面向 Web / 微服务 / 云原生应用,聚焦请求维度:
- Rate:请求速率(每秒请求数)
- Errors:错误请求数(每秒失败请求)
- Duration:请求延迟分布
RED 以用户请求为核心,快速感知业务体验异常,适配微服务架构。
1.3.3 USE 方法
面向主机 / 底层资源监控,缩写含义:
- Utilization 使用率:CPU、内存、磁盘 IO、网络带宽使用率;
- Saturation 饱和度:资源负载饱和阈值;
- Error 错误:网络丢包、接口报错、系统日志异常等。
适合主机级、物理资源性能瓶颈排查。
1.4 四大核心监控指标分类
完整监控体系分为 4 大类:
- 资源监控:服务器硬件、网络设备、连通性、网络质量、流量监控;
- 组件监控:Web 服务、数据库、中间件、容器等中间层组件监控;
- 应用监控:业务应用程序性能监控,适配 Google 四大指标、RED 方法论;
- 业务监控:核心业务指标(订单、支付、注册量),直接关联企业营收与用户体验,异常即故障。
1.5 监控与可观测性
1.5.1 监控局限性
传统监控只关注特定指标观测,仅能事后发现故障。
1.5.2 可观测性价值
云原生时代,可观测性逐步替代传统监控,实现:
- 提前预知系统潜在故障;
- 为服务扩缩容、容量规划提供数据支撑;
- 支撑中间件、系统参数性能调优;
- 洞察业务趋势,支撑业务决策。
1.5.3 可观测性三大核心要素
- 聚合指标:多节点 / 多实例指标聚合(如 CPU 平均利用率),简化整体性能分析;
- 事件日志:记录系统错误、警告、行为事件,用于故障排查与未知行为分析;
- 链路追踪:跟踪分布式系统请求全链路,定位微服务调用瓶颈、失败节点。
可观测性可解答:性能瓶颈位置、请求调用链路、微服务处理逻辑、故障根因等核心问题。
二、Prometheus 基础介绍
2.1 Prometheus 简介
Prometheus 是开源云原生监控告警框架,支持主机监控、微服务动态架构监控,具备多维度数据采集、强大 PromQL 查询能力,是云原生监控标配。
核心优势
- 部署简单,仅单个二进制文件,无第三方依赖,只需本地磁盘存储;
- 可深入监控服务内部运行状态;
- 内置强大 PromQL 查询语言,支持数据查询、聚合、告警规则编写;
- 高吞吐,每秒可处理数十万监控时序数据。
与 Zabbix 适用场景区别
- Zabbix:更适合传统主机、网络硬件、基础架构监控;
- Prometheus:更适合容器、微服务、云原生服务类监控。
2.2 Prometheus 核心组件与架构
生态组件多基于 Go 语言开发,大部分组件可选,核心组件:
-
Prometheus Server 核心组件,负责监控数据抓取、时序存储、PromQL 查询、告警规则评估。
-
PushGateway 推送网关接收短生命周期任务主动推送的指标,缓存后等待 Server 定时拉取。
-
Exporter 采集器各类组件数据采集代理,以 HTTP 接口暴露指标,常见:node_exporter、mysqld_exporter、redis_exporter、blackbox_exporter 等。
-
Alertmanager 告警管理器接收 Server 产生的告警,进行分组、抑制、静默,推送至钉钉、微信、邮件等渠道。
整体工作流程
- 通过静态配置 / 服务发现(K8s/DNS)自动发现监控目标;
- Server 定期从 Exporter/Pushgateway 拉取指标,存入内置 TSDB 时序数据库;
- 通过 Web UI/Grafana 借助 PromQL 查询可视化数据;
- 触发告警规则后,推送至 Alertmanager 分发告警;
- 临时任务通过 PushGateway 主动推送指标。
2.3 Pull 与 Push 模式对比
- Pull 拉模式:Prometheus Server 主动定时抓取目标 HTTP 接口指标,默认模式;优势:低耦合、监控端可控采集频率、被监控端无感知、稳定性强。
- Push 推模式:客户端主动推送指标到 PushGateway;适用场景:网络出网不入、短生命周期任务、无法暴露接口的老旧系统。
三、Prometheus 安装与配置详解
3.1 时序数据库基础
时序数据库 :专门存储带时间戳的序列数据,按时间顺序采样,适配物联网、运维监控场景。
核心特点
- 强依赖时间戳,以 UNIX 时间为标识;
- 写入频率高、并发量大,多为秒 / 毫秒级采样;
- 冷热数据明显,仅高频查询近期数据;
- 支持批量统计:求和、最大值、最小值、平均值。
常见时序库:InfluxDB、OpenTSDB、Prometheus 内置 TSDB。
时序数据结构
每条时序数据由 指标名称 + 标签键值对 唯一标识,同一指标不同标签、不同时间点均为独立时序。格式:<metric_name>{label1="value1",label2="value2"} 时间戳 指标值
3.2 Prometheus 指标概念与命名规范
- 指标(Metrics):监控采样数据统称,是度量系统状态的抽象单位;
- 时序构成:指标名 + 标签(Key/Value)+ 时间戳 + 浮点值;
- 命名规则 :
- 指标名:ASCII 字符、数字、下划线、冒号;
- 标签 Key:ASCII、数字、下划线,
__开头为系统保留标签; - 标签 Value:支持任意 Unicode 字符。
示例:
http_request_total{status="200", method="GET"} @1434417560938 = 94355
http_request_total{status="404", method="GET"} @1434417560938 = 384733.3 环境准备与时间同步
以 AlmaLinux9 / RHEL9 / RockyLinux9 为例,Prometheus 对系统时间要求极高,必须配置 NTP 同步:
# 设置时区
timedatectl set-timezone Asia/Shanghai
# 配置定时时间同步
crontab -e
# 添加定时任务
* * * * * ntpdate -u cn.pool.ntp.org3.4 Prometheus 二进制安装
-
官网下载:prometheus-2.44.0.linux-amd64.tar.gz
-
解压部署:
tar -xvzf prometheus-2.44.0.linux-amd64.tar.gz
mv prometheus-2.44.0.linux-amd64 /usr/local/prometheus -
临时前台启动(测试用):
cd /usr/local/prometheus
nohup ./prometheus &
3.5 配置 Systemd 系统服务
编写 systemd 服务文件,实现开机自启、统一管理:
vim /usr/lib/systemd/system/prometheus.service服务配置内容:
[Unit]
Description=Prometheus Server
Documentation=http://prometheus.io/docs/
After=network.target
[Service]
ExecStart=/usr/local/prometheus/prometheus \
--web.enable-lifecycle \
--storage.tsdb.retention=90d \
--storage.tsdb.path=/usr/local/prometheus/data \
--config.file=/usr/local/prometheus/prometheus.yml
Restart=always
RestartSec=15s
[Install]
WantedBy=multi-user.target启动参数说明
--config.file:指定主配置文件路径;--web.listen-address:监听端口,默认 9090;--web.enable-lifecycle:支持配置热重启,不中断服务;--storage.tsdb.retention:时序数据保留时长;--storage.tsdb.path:数据持久化存储目录。
重载并启动服务
systemctl daemon-reload
systemctl restart prometheus
systemctl enable prometheus
systemctl status prometheus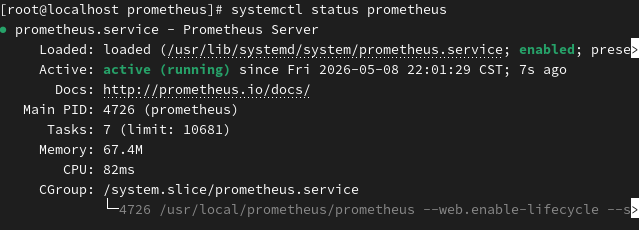
启动后默认监听 9090 端口 ,浏览器访问 http://IP:9090 即可进入内置 UI。
执行以下代码检查prometheus是否运行正常
up{job="prometheus"}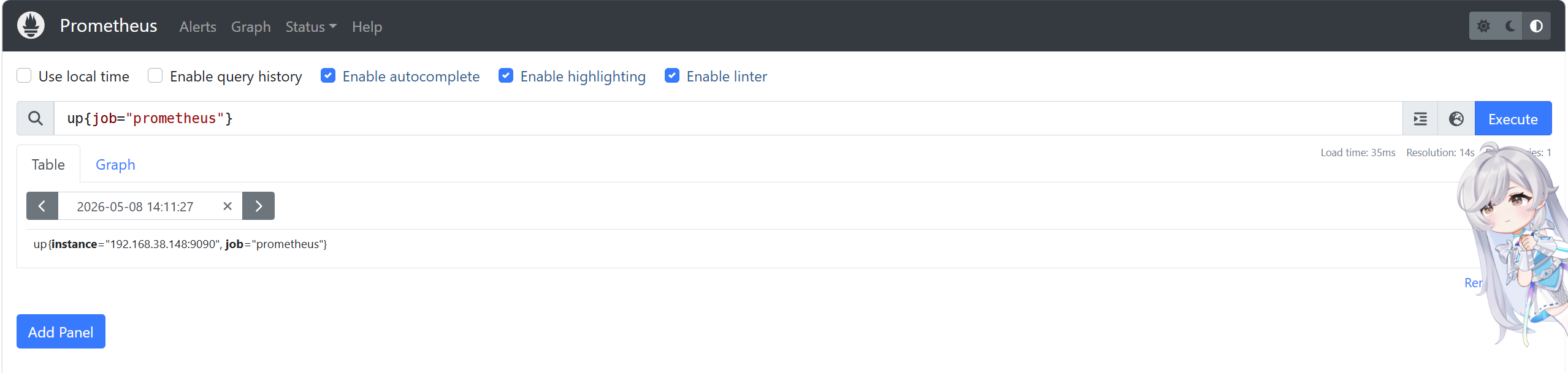
3.6 Prometheus 主配置文件 prometheus.yml 详解
默认配置精简版:
# 全局配置
global:
scrape_interval: 15s # 抓取间隔15秒
evaluation_interval: 15s # 告警规则评估间隔15秒
# 关联Alertmanager
alerting:
alertmanagers:
- static_configs:
- targets:
- 127.0.0.1:9093
# 告警规则文件
rule_files:
#- "first_rules.yml"
#- "second_rules.yml"
# 监控任务配置
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets:
- "localhost:9090"
- "172.16.213.50:9100"
- "172.16.213.186:9100"核心配置说明
- global:全局抓取间隔、规则评估间隔、抓取超时;
- alerting:配置 Alertmanager 地址,用于告警推送;
- rule_files:引入自定义告警规则文件;
- scrape_configs :定义监控任务 job,
static_configs静态指定监控目标 IP + 端口;9100 为 node_exporter 默认端口,用于主机监控。
3.7 配置文件校验
修改配置后,通过官方工具校验语法合法性,避免启动失败:
/usr/local/prometheus/promtool check config /usr/local/prometheus/prometheus.yml输出 SUCCESS 代表配置无误,报错则按提示修正格式。

总结
- 监控是运维基石,SLI/SLO/SLA 是 SRE 量化服务可用性的核心标准;
- 四大黄金指标、RED、USE 分别适配服务、微服务、主机资源三类监控场景;
- 可观测性包含指标、日志、链路追踪,是云原生监控进阶方向;
- Prometheus 采用 Pull 模式、TSDB 时序存储,架构轻量化、部署简单;
- 掌握二进制安装、Systemd 托管、主配置文件编写与校验,是 Prometheus 运维入门必备技能。